轻松练:如何从900万张图片中对600类照片进行分类|技术头条
 点击上方↑↑↑蓝字关注我们~
点击上方↑↑↑蓝字关注我们~
「2019 Python开发者日」7折优惠最后2天,请扫码咨询 ↑↑↑
作者 | Aleksey Bilogur
译者 | 风车云马
责编 | Jane
出品 | AI科技大本营(公众号id:rgznai100)
【导语】完成一个简单的端到端的机器学习模型需要几步?在本文中,我们将从一个完整的工作流:下载数据→图像分割与处理→建模→发布模型,教大家如何对 900 万张图像进行分类,分类标签多达 600 个。可是如此庞大的数据集又是从何而来呢?上周,AI科技大本营为大家介绍过一篇文章在过去十年间,涵盖 CV、NLP 和语音等领域,有 68 款大规模数据集,本文所用的数据集也在其中,大家也可以以此为借鉴,学习如何利用好这些数据。
前言
如果您想构建一个图像分类器,哪里可以得到训练数据呢?这里给大家推荐 Google Open Images,这个巨大的图像库包含超过 3000 万张图像和 1500 万个边框,高达 18tb 的图像数据!并且,它比同级别的其他图像库更加开放,像 ImageNet 就有权限要求。
但是,对单机开发人员来说,在这么多的图像数据中筛选过滤并不是一件易事,需要下载和处理多个元数据文件,还要回滚自己的存储空间,也可以申请使用谷歌云服务。另一方面,实际中并没有那么多定制的图像训练集,实话讲,创建、共享这么多的训练数据是一件头疼的事情。
在今天的教程中,我们将教大家如何使用这些开源图像创建一个简单的端到端机器学习模型。
先来看看如何使用开源图像中自带的 600 类标签来创建自己的数据集。下面以类别为“三明治”的照片为例,展示整个处理过程。
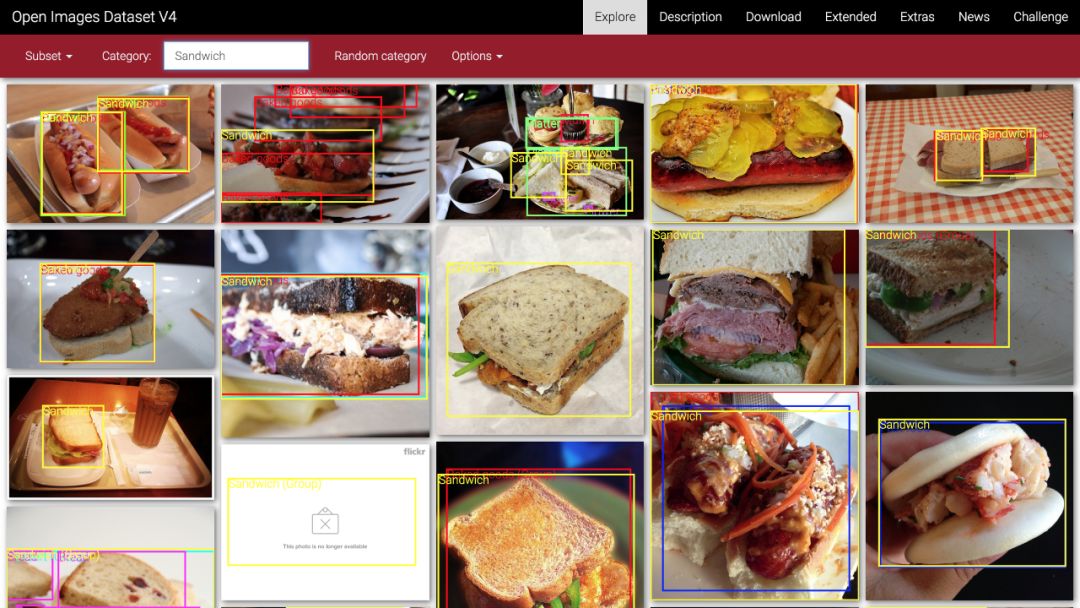
谷歌开源图像-三明治图片
一、下载数据
首先需要下载相关数据,然后才能使用。这是使用谷歌开源图像(或其他外部数据集)的第一步。而下载数据集需要编写相关脚本,没有其他简单的方法,不过不用担心,我写了一个Python脚本,大家可以直接用。思路:首先根据指定的关键字,在开源数据集中搜索元数据,找到对应图像的原始 url(在 Flickr 上),然后下载到本地,下面是实现的 Python 代码:
1import sys
2import os
3import pandas as pd
4import requests
5
6from tqdm import tqdm
7import ratelim
8from checkpoints import checkpoints
9checkpoints.enable()
10
11
12def download(categories):
13 # Download the metadata
14 kwargs = {'header': None, 'names': ['LabelID', 'LabelName']}
15 orig_url = "https://storage.googleapis.com/openimages/2018_04/class-descriptions-boxable.csv"
16 class_names = pd.read_csv(orig_url, **kwargs)
17 orig_url = "https://storage.googleapis.com/openimages/2018_04/train/train-annotations-bbox.csv"
18 train_boxed = pd.read_csv(orig_url)
19 orig_url = "https://storage.googleapis.com/openimages/2018_04/train/train-images-boxable-with-rotation.csv"
20 image_ids = pd.read_csv(orig_url)
21
22 # Get category IDs for the given categories and sub-select train_boxed with them.
23 label_map = dict(class_names.set_index('LabelName').loc[categories, 'LabelID']
24 .to_frame().reset_index().set_index('LabelID')['LabelName'])
25 label_values = set(label_map.keys())
26 relevant_training_images = train_boxed[train_boxed.LabelName.isin(label_values)]
27
28 # Start from prior results if they exist and are specified, otherwise start from scratch.
29 relevant_flickr_urls = (relevant_training_images.set_index('ImageID')
30 .join(image_ids.set_index('ImageID'))
31 .loc[:, 'OriginalURL'])
32 relevant_flickr_img_metadata = (relevant_training_images.set_index('ImageID').loc[relevant_flickr_urls.index]
33 .pipe(lambda df: df.assign(LabelValue=df.LabelName.map(lambda v: label_map[v]))))
34 remaining_todo = len(relevant_flickr_urls) if checkpoints.results is None else\
35 len(relevant_flickr_urls) - len(checkpoints.results)
36
37# Download the images
38 with tqdm(total=remaining_todo) as progress_bar:
39 relevant_image_requests = relevant_flickr_urls.safe_map(lambda url: _download_image(url, progress_bar))
40 progress_bar.close()
41
42 # Write the images to files, adding them to the package as we go along.
43 if not os.path.isdir("temp/"):
44 os.mkdir("temp/")
45 for ((_, r), (_, url), (_, meta)) in zip(relevant_image_requests.iteritems(), relevant_flickr_urls.iteritems(),
46 relevant_flickr_img_metadata.iterrows()):
47 image_name = url.split("/")[-1]
48 image_label = meta['LabelValue']
49
50 _write_image_file(r, image_name)
51
52
53
54def _download_image(url, pbar):
55 """Download a single image from a URL, rate-limited to once per second"""
56 r = requests.get(url)
57 r.raise_for_status()
58 pbar.update(1)
59 return r
60
61
62def _write_image_file(r, image_name):
63 """Write an image to a file"""
64 filename = f"temp/{image_name}"
65 with open(filename, "wb") as f:
66 f.write(r.content)
67
68
69if __name__ == '__main__':
70 categories = sys.argv[1:]
71 download(categories)
该脚本可以下载原始图像的子集,其中包含我们选择的类别的边框信息:
1$ git clone https://github.com/quiltdata/open-images.git
2$ cd open-images/
3$ conda env create -f environment.yml
4$ source activate quilt-open-images-dev
5$ cd src/openimager/
6$ python openimager.py "Sandwiches" "Hamburgers"
图像类别采用多级分层的方式。例如,类别三明治和汉堡包还都属于食物类标签。我们可以使用 Vega 将其可视化为径向树:
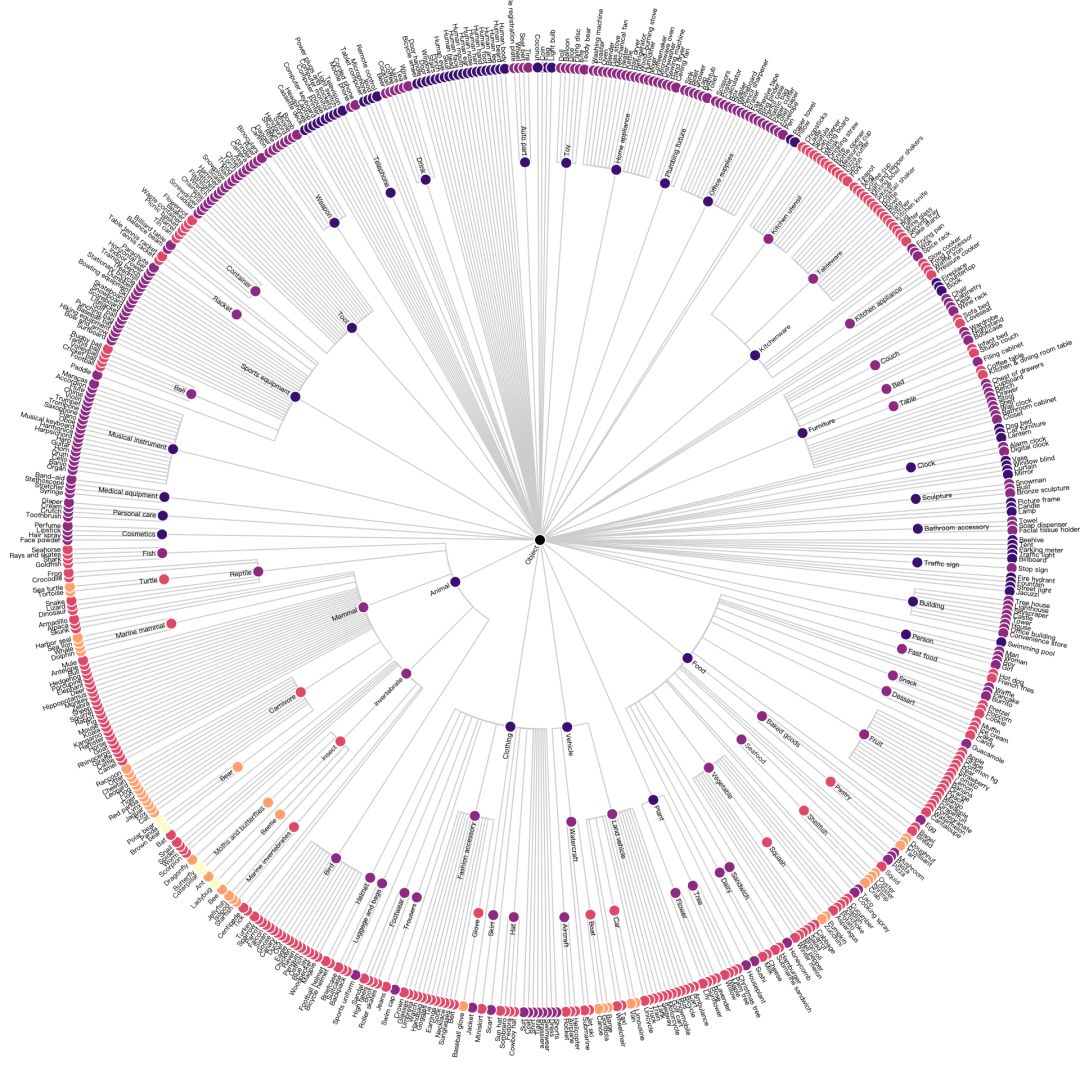
并不是开源图像中的所有类别都有与之关联的边框数据。但这个脚本可以下载 600 类标签中的任意子集, 本文主要通过”汉堡包“和”三明治“两个类别展开讨论。
football, toy, bird, cat, vase, hair dryer, kangaroo, knife,
briefcase, pencil case, tennis ball, nail, high heels, sushi,
skyscraper, tree, truck, violin, wine, wheel, whale, pizza cutter,
bread, helicopter, lemon, dog, elephant, shark, flower, furniture,
airplane, spoon, bench, swan, peanut, camera, flute, helmet,
pomegranate, crown…
二、图像分割和处理
我们在本地处理图像时,可以使用 matplotlib 显示这些图片:
1import matplotlib.pyplot as plt
2from matplotlib.image import imread
3%matplotlib inline
4import os
5fig, axarr = plt.subplots(1, 5, figsize=(24, 4))
6for i, img in enumerate(os.listdir('../data/images/')[:5]):
7 axarr[i].imshow(imread('../data/images/' + img))

可见这些图像并不容易训练,也存在其他网站的源数据集所面临的所有问题。比如目标类中可能存在不同大小、不同方向和遮挡等问题。有一次,我们甚至没有成功下载到实际的图像,只是得到一个占位符——我们想要的图像已经被删除了!
我们下载得到了几千张这样的图片之后就要利用边界框信息将这些图像分割成三明治,汉堡。下面给出一组包含边框的图像:
 带边界框
带边界框
此处省略了这部分代码,它有点复杂。下面要做的就是重构图像元数据,剪裁分割图像;再提取匹配的图像。在运行上述代码之后,本地会生成一个 images_ cropped 文件夹,其中包含所有分割后的图像。
三、建模
完成了下载数据,图像分割和处理,就可以训练模型了。接下来,我们对数据进行卷积神经网络(CNN)训练。卷积神经网络利用图像中的像素点逐步构建出更高层次的特征。然后对图像的这些不同特征进行得分和加权,最终生成分类结果。这种分类的方式很好的利用了局部特征。因为任何一个像素与附近像素的特征相似度几乎都远远大于远处像素的相似度。
CNNs 还具有其他吸引之处,如噪声容忍度和(一定程度上的)尺度不变性。这进一步提高了算法的分类性能。
接下来就要开始训练一个非常简单的卷积神经网络,看看它是如何训练出结果的。这里使用 Keras 来定义和训练模型。
1、首先把图像放在一个特定的目录下
1images_cropped/
2 sandwich/
3 some_image.jpg
4 some_other_image.jpg
5 ...
6 hamburger/
7 yet_another_image.jpg
8 ...
然后 Keras 调用这些文件夹,Keras会检查输入的文件夹,并确定是二分类问题,并创建“图像生成器”。如以下代码:
1from keras.preprocessing.image import ImageDataGenerator
2
3train_datagen = ImageDataGenerator(
4 rotation_range=40,
5 width_shift_range=0.2,
6 height_shift_range=0.2,
7 rescale=1/255,
8 shear_range=0.2,
9 zoom_range=0.2,
10 horizontal_flip=True,
11 fill_mode='nearest'
12)
13
14test_datagen = ImageDataGenerator(
15 rescale=1/255
16)
17
18train_generator = train_datagen.flow_from_directory(
19 '../data/images_cropped/quilt/open_images/',
20 target_size=(128, 128),
21 batch_size=16,
22 class_mode='binary'
23)
24
25validation_generator = test_datagen.flow_from_directory(
26 '../data/images_cropped/quilt/open_images/',
27 target_size=(128, 128),
28 batch_size=16,
29 class_mode='binary'
30)
我们不只是返回图像本身,而是要对图像进行二次采样、倾斜和缩放等处理(通过train_datagen.flow_from_directory)。其实,这就是实际应用中的数据扩充。数据扩充为输入数据集经过图像分类后的裁剪或失真提供必要的补偿,这有助于我们克服数据集小的问题。我们可以在单张图像上多次训练算法模型,每次用稍微不同的方法预处理图像的一小部分。
2、定义了数据输入后,接下来定义模型本身
1from keras.models import Sequential
2from keras.layers import Conv2D, MaxPooling2D
3from keras.layers import Activation, Dropout, Flatten, Dense
4from keras.losses import binary_crossentropy
5from keras.callbacks import EarlyStopping
6from keras.optimizers import RMSprop
7
8
9model = Sequential()
10model.add(Conv2D(32, kernel_size=(3, 3), input_shape=(128, 128, 3), activation='relu'))
11model.add(MaxPooling2D(pool_size=(2, 2)))
12
13model.add(Conv2D(32, (3, 3), activation='relu'))
14model.add(MaxPooling2D(pool_size=(2, 2)))
15
16model.add(Conv2D(64, (3, 3), activation='relu'))
17model.add(MaxPooling2D(pool_size=(2, 2)))
18
19model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
20model.add(Dense(64, activation='relu'))
21model.add(Dropout(0.5))
22model.add(Dense(1))
23model.add(Activation('sigmoid'))
24
25model.compile(loss=binary_crossentropy,
26 optimizer=RMSprop(lr=0.0005), # half of the default lr
27 metrics=['accuracy'])
这是一个简单的卷积神经网络模型。它只包含三个卷积层:输出层之前的后处理层,强正则化层和 Relu 激活函数层。这些层因素共同作用以保证模型不会过拟合。这一点很重要,因为我们的输入数据集很小。
3、最后一步是训练模型
1import pathlib
2
3sample_size = len(list(pathlib.Path('../data/images_cropped/').rglob('./*')))
4batch_size = 16
5
6hist = model.fit_generator(
7 train_generator,
8 steps_per_epoch=sample_size // batch_size,
9 epochs=50,
10 validation_data=validation_generator,
11 validation_steps=round(sample_size * 0.2) // batch_size,
12 callbacks=[EarlyStopping(monitor='val_loss', min_delta=0, patience=4)]
13)
14
15model.save("clf.h5")
epoch 步长的选择是由图像样本大小和批处理量决定的。然后对这些数据进行 50 次训练。因为回调函数 EarlyStopping 训练可能会提前暂停。如果在前 4 个 epoch 中没有看到训练性能的改进,那么它会在 50 epoch 内返回一个相对性能最好的模型。之所以选择这么大的步长,是因为模型验证损失存在很大的可变性。
这个简单的训练方案产生的模型的准确率约为75%。
precision recall f1-score support
0 0.90 0.59 0.71 1399
1 0.64 0.92 0.75 1109
micro avg 0.73 0.73 0.73 2508
macro avg 0.77 0.75 0.73 2508
weighted avg 0.78 0.73 0.73 2508
有趣的是,我们的模型在分类汉堡包为第 0 类时信心不足,而在分类汉堡包为第 1 类时信心十足。90% 被归类为汉堡包的图片实际上是汉堡包,但是只分类得到 59% 的汉堡。
另一方面,只有 64% 的三明治图片是真正的三明治,但是分类得到的是 92% 的三明治。这与 Francois Chollet 采用相似的模型,应用到一个相似大小的经典猫狗数据集中,所得到的结果为 80% 的准确率基本是一致的。这种差异很可能是谷歌 Open Images V4 数据集中的遮挡和噪声水平增加造成的。数据集还包括其他插图和照片,使分类更加困难。如果自己构建模型时,也可以先删除这些。
使用迁移学习技术可以进一步提高算法性能。要了解更多信息,可以查阅 Francois Chollet 的博客文章:Building powerful image classification models using very little data,使用少量数据集构建图像分类模型
https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html
四、模型发布
现在我们构建好了一个定制的数据集和训练模型,非常高兴可以与大家分享。基于此也进行了一些总结,机器学习项目应该是模块化的可复制的,体现在:
将模型因素分为数据、代码和环境组件
数据版本控制模型定义和训练数据
代码版本控制训练模型的代码
环境版本控制用于训练模型的环境。比如环境可能是一个Docker文件,也可能在本地使用pip或conda
如果其他人要使用该模型,提供相应的{数据、代码、环境}元组即可
遵循这些原则,就可以通过几行代码,训练出需要的模型副本:
git clone https://github.com/quiltdata/open-images.git
conda env create -f open-images/environment.yml
source activate quilt-open-images-dev
python -c "import t4; t4.Package.install('quilt/open_images', dest='open-images/', registry='s3://quilt-example')"
结论
在本文中,我们演示了一个端到端的图像分类的机器学习实现方法。从下载/转换数据集到训练模型的整个过程。最后以一种模块化的、可复制的便于其他人重构的方式发布出来。由于自定义数据集很难生成和发布,随着时间的积累,形成了这些广泛使用的示例数据集。并不是因为他们好用,而是因为它们很简单。例如,谷歌最近发布的机器学习速成课程大量使用了加州住房数据集。这些数据有将近 20 年的历史了!在此基础上应用新的数据,使用现实生活的一些有趣的图片,或许会变得比想象中更容易!
有关文中使用的数据、代码、环境等信息,可通过下面的链接获取更多:
https://storage.googleapis.com/openimages/web/index.html
https://github.com/quiltdata/open-images
https://alpha.quiltdata.com/b/quilt-example/tree/quilt/open_images/
https://blog.quiltdata.com/reproduce-a-machine-learning-model-build-in-four-lines-of-code-b4f0a5c5f8c8
原文链接:
https://medium.freecodecamp.org/how-to-classify-photos-in-600-classes-using-nine-million-open-images-65847da1a319
(本文为 AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
「2019 Python开发者日」7折票限时开售!这一次我们依然“只讲技术,拒绝空谈”10余位一线Python技术专家共同打造一场硬核技术大会。更有深度培训实操环节,为开发者们带来更多深度实战机会。
目前演讲嘉宾议题已确认,扫描海报二维码,即刻抢购7折优惠票价!更多详细信息请咨询13581782348(微信同号)。

推荐阅读:
特朗普盯上谷歌在华AI中心,CEO皮查伊上演“拉锯战”
教育部发文35所高校新增AI本科专业!想回去重新高考
儿科医生的眼泪,全被数据看见了
让苹果“沦为配角”的华为都发布了什么?
@程序员,编程语言大乱斗,今天你真香了吗?
社交电商的诅咒
人间真实!一行代码引发的恐惧
阿里带火的中台,究竟是个啥?
姚期智提出的"百万富翁"难题被破解? 多方安全计算MPC到底是个什么鬼?
曝光!月薪5万的程序员面试题:73%人都做错,你敢试吗?

你也可以点击阅读原文,查看大会详情。
相关文章:

介绍两个好玩的和Github相关的Chrome扩展
1. Octotree 默认的github网页里的代码显示没有我们在IDE里看到的直观,即代码文件所在的文件夹无法以树形层级结构显示在屏幕左边。 安装Octotree之后: 方便多了。 2. Isometric Contributions github commit的统计页面比较平淡: 安装了Isome…

Schema约束模式实例
book.xsd <?xml version"1.0" encoding"UTF-8"?> <!-- xmlns:默认命名空间 xmlns:xs:当前的文档的标记来自http://www.w3.org/2001/XMLSchema命名空间 前缀:xs elementFormDefault:当前文档使用的标记必须是使用http://www.w3.…
【leetcode】力扣刷题(2):两数相加(go语言)
一、问题描述 给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。 如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。 您可…
“GANs之父”Ian Goodfellow被爆已从Google离职
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」7折优惠最后2天,请扫码咨询 ↑↑↑整理 | 一一出品 | AI科技大本营(ID:rgznai100)3 月 28 日,深度学习大牛李沐在知乎爆料称,他从某机器学习大佬处获悉,…
Gulp快速入门教程
Gulp是基于流的前端自动化的构建工具,虽说如今是webpack盛行的时代,但是gulp和webpack整合效果更美味的,鱼与熊掌都可兼得哦!本文只介绍下Gulp的基本使用和一些常用的Gulp插件,废话不多说,一起来看看吧。 g…
linux 防火墙 命令
-- 永久设置防火墙(重启不恢复) 开启:chkconfig iptables on 关闭:chkconfig iptables off-- 暂时设置防火墙(重启后恢复) 开启:service iptables start 关闭:service i…
如何将TensorFlow Serving的性能提高超过70%?
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」7折优惠最后2天,请扫码咨询 ↑↑↑译者 | Major出品 | AI科技大本营(ID:rgznai100)TensorFlow已经发展成为事实上的ML(机器学习)平台,在业界和研究领域都很流行。对TensorFlow…
【leetcode】力扣刷题(3):无重复字符的最长子串(go语言)
一、问题描述 给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: “abcabcbb” 输出: 3 解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。 示例 2: 输入: “bbbbb” 输出: 1 解释: 因为无重复字符的最长子串是…

单点登录与权限管理本质:session和cookie介绍
本篇开始写「单点登录与权限管理」系列的第一部分:单点登录与权限管理本质,这部分主要介绍相关的知识概念、抽象的处理过程、常见的实现框架。通过这部分的介绍,能够对单点登录与权限管理有整体上的了解,对其相关概念、处理流程、…

【.Net MF网络开发板研究-04】Socket编程之服务端
前几篇文章介绍了Http相关的应用,其实从技术角度而言,应该先介绍Socket编程,然后再介绍Http,毕竟Http是用Socket相关函数编程实现的。 .NET Micro Framework的Socket函数和桌面版.NET Framework中的函数完全兼容,换句话…
【Qt】Qt中调用python接口
在Qt程序中调用python函数从步骤 1、在pro中添加python的头文件路径和库 INCLUDEPATH += /usr/include/python3.4 LIBS += -L /usr/lib/python3.4/config-3.4m-x86_64-linux-gnu -lpython3.42、添加python头文件 #undef slots #include <python3.4/Python.h> #define …
优雅的理解 call 和 apply 的使用方法
作者在看到一篇优雅的使用 js 的各种方法解决算法的时候产生的疑问,到底什么时候使用 apply 和 call 啦? 每次看到别人用 apply 和 call 其实从以前的懵懵懂懂到现在的明白,但是自己从来未下手去用过,最近比较闲。开始打一下 Jav…

何恺明等人提TensorMask框架:比肩Mask R-CNN,4D张量预测新突破
整理 | 刘畅、Jane 责编 | Jane 出品 | AI科技大本营(id:rgznai100) 看到今天要给大家介绍的论文,也许现在大家已经非常熟悉 Ross Girshic、Piotr Dollr 还有我们的大神何恺明的三人组了。没错,今天这篇重磅新作还是他们的产出&am…
init.rc的disabled含义
http://www.kandroid.org/android_pdk/bring_up.htmlhttp://androidnote.com/Article_show.asp?ArticleID649如果该服务选项中没有disabled定义,则在init.rc中解析到这个服务的时候,会马上执行这个服务。而如果在服务的选项中增加了disabled定义&#x…
【Qt】在ubuntu14.04上安装Qt5.12(失败)
注意 在ubuntu14.04上安装Qt5.12最终失败了,Qt5.12需要的libdbus库的版本和ubuntu14.04中的不一致,如果强行升级libdbus库版本,会导致系统桌面无法启动。 再次提示:不要按照下述步骤操作,它只是一个记录失败操作的笔记。 如果有大神安装成功了,还请不吝赐教。 1、安装Q…

80+机器学习数据集,还不快收藏
整理 | suiling 出品 | AI科技大本营(ID:rgznai100) 对于从事机器学习的小伙伴来说,机器学习必须以大量的数据为基础,否则构建再好的模型也不能达到你想要的效果。同时,不同质量的数据集也会影响到模型训练的效果。之…
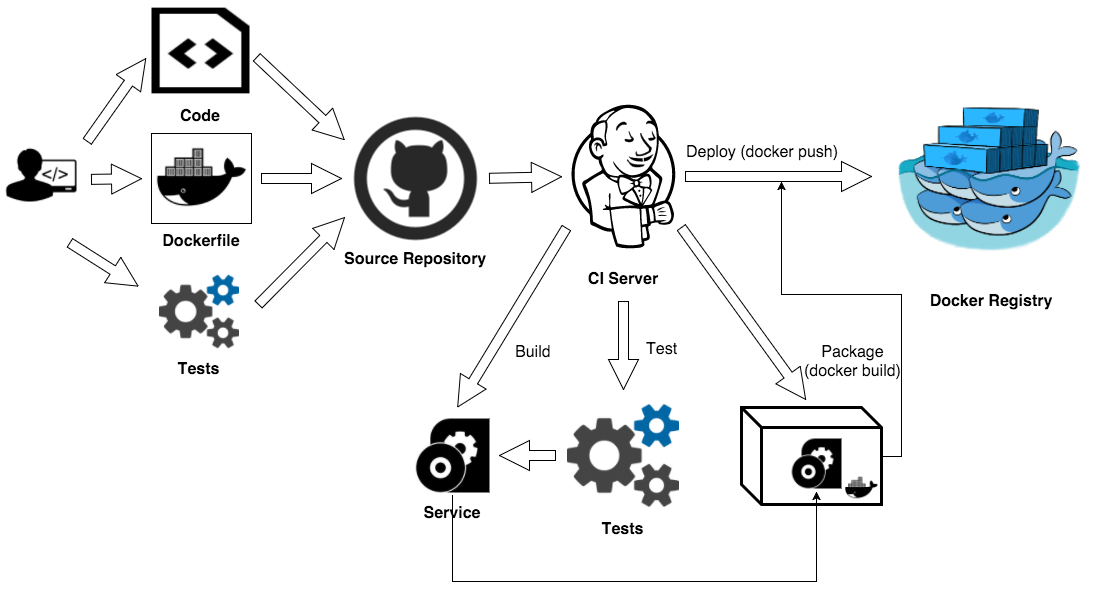
SpringBoot+Docker+Git+Jenkins实现简易的持续集成和持续部署
前言 本篇文章引导你使用Jenkins部署[SpringBoot项目],同时使用Docker和Git实现简单的持续集成和持续部署。(项目地址:sso-merryyou) 流程图如下: push代码到Github触发WebHook。(因网络原因,本篇使用gitee…
LINUX下用C语言历遍目录 C语言列出目录
(被考了一题遍历目录,连需要的系统库函数我都不知道...打击中...)小羽给了一个答案:#include<stdio.h> #include<dirent.h>int main(int argc,char **argv) { DIR *p; struct dirent *dirp; if (argc ! 2) …
【linux】ubuntu14.04升级dbus到1.13.8,杯具了,无法进入桌面
一、问题描述 在ubuntu14.04中安装了Qt5.12,启动QtCreator报错,需要高版本的dbus。 将dbus升级到1.13.8后,杯具了,无法进入桌面 二、尝试解决 1、尝试恢复之前的版本(失败) 进入终端界面:Ct…
线下教育地位遭冲击?“AI+教育”公司同台讲了这些事实
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」7折优惠最后1天,请扫码咨询 ↑↑↑整理 | 一一出品 | AI科技大本营(ID:rgznai100)近日,网易新闻、网易有道、清华大学数据科学研究院在清华大学举办了“中国AI创新者论坛”。当…
mysql查看正在执行的sql语句
有2个方法: 1、使用processlist,但是有个弊端,就是只能查看正在执行的sql语句,对应历史记录,查看不到。好处是不用设置,不会保存。 -- use information_schema; -- show processlist; 或者: -- …

poj2472
最短路,bellman View Code #include <iostream>#include <cstdio>#include <cstdlib>#include <cstring>#include <cmath>using namespace std;#define inf 0x3f3f3f3f#define maxn 100#define maxm 10000#define eps 10e-9int n, m…

.net core 2.0 部署到centos 7生产环境
.netcore的跨平台如此之火,忍不住想试试 在linux下部署 .net 程序。 借鉴此篇博文:将ASP.NET Core应用程序部署至生产环境中(CentOS7) 虽然是借鉴,但过程坎坷。对从未使用过linux的我难度可想而知,但万事有…

微软沈向洋:写给AI新潮流——人工智能创作的五点建议
2019年EmTech 数字大会 本周,我有幸在旧金山举行的EmTech数字大会上发言,为大家讲述了当今人工智能发展的现状,以及未来的发展方向。我想与大家分享的是,面对新一轮的人工智能创新大潮,人们最该思考的五件大事。 1)技…
【Linux】在VirtualBox-6.0中安装Manjaro18.0
1、参考博客: VMware虚拟机下Manjaro17.1.6安装详细教程 2、在VirtualBox-6.0中安装Manjaro18.0 1)基本步骤和博客中安装17.1.6相同,下面只记录不同的。 * VirtualBox中没有Manjaro的选项,可以选择 ArchLinux; * 本…

netty里集成spring注入mysq连接池(一)
netty的性能非常高,能达到8000rps以上,见 各个web服务器的性能对比测试 1.准备好需要的jar包 spring.jar //spring包 netty-3.2.4.Final.jar // netty库 commons-dbcp.jar // dbcp数据库连接池 mysql-connector-java-5.1.6.jar // d…
图很难理解?看这篇图论基础与图存储结构就够了
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」,购票请扫码咨询 ↑↑↑作者 | 程序员吴师兄转载自五分钟学算法(ID:CXYxiaowu)1 前言打算先普及一下图的相关理论支持,本文不建议一口气阅读完毕,可以先浏览一遍&a…
【Linux】修改/etc/fstab时参数设错,导致启动异常,无法进入系统(已解决)
1、问题描述 在ubuntu14.04上设置自动挂载硬盘分区时,修改/etc/fstab时,将defaults错误写成default,导致启动异常,无法进入系统。 2、解决方法 1)ubuntu启动时有两种模式:普通模式(ubuntu&am…
gitlab安装
根据官方文档安装:https://www.gitlab.com.cn/installation/#centos-6 centos6: 1、没有安装lokkit,yum search lokkit后安装lokkit sudo yum install -y curl policycoreutils-python openssh-server cronie sudo lokkit -s http -s ssh2、安…

如何将Android带入互联网数字家庭? 第一篇转载
前言:很有幸通过ARM Group认识了 ARM的家庭软件架构师 --- 章立(Leon Zhang) (他也是ARM战略软件联盟部门的一员. Leon 拥有多年产品开发和项目管理经验, 曾经参与了数字录像机、机顶盒、数字电视,网络电视以及智能电视࿰…