【AI】caffe使用步骤(二):设计网络模型prototxt
【一】以 lenet_train_test.prototxt 为例
name: "LeNet"
layer {name: "mnist"type: "Data"top: "data"top: "label"include {phase: TRAIN}transform_param {scale: 0.00390625}data_param {source: "examples/mnist/mnist_train_lmdb"batch_size: 64backend: LMDB}
}
layer {name: "mnist"type: "Data"top: "data"top: "label"include {phase: TEST}transform_param {scale: 0.00390625}data_param {source: "examples/mnist/mnist_test_lmdb"batch_size: 100backend: LMDB}
}
layer {name: "conv1"type: "Convolution"bottom: "data"top: "conv1"param {lr_mult: 1}param {lr_mult: 2}convolution_param {num_output: 20kernel_size: 5stride: 1weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}
layer {name: "pool1"type: "Pooling"bottom: "conv1"top: "pool1"pooling_param {pool: MAXkernel_size: 2stride: 2}
}
layer {name: "conv2"type: "Convolution"bottom: "pool1"top: "conv2"param {lr_mult: 1}param {lr_mult: 2}convolution_param {num_output: 50kernel_size: 5stride: 1weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}
layer {name: "pool2"type: "Pooling"bottom: "conv2"top: "pool2"pooling_param {pool: MAXkernel_size: 2stride: 2}
}
layer {name: "ip1"type: "InnerProduct"bottom: "pool2"top: "ip1"param {lr_mult: 1}param {lr_mult: 2}inner_product_param {num_output: 500weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}
layer {name: "relu1"type: "ReLU"bottom: "ip1"top: "ip1"
}
layer {name: "ip2"type: "InnerProduct"bottom: "ip1"top: "ip2"param {lr_mult: 1}param {lr_mult: 2}inner_product_param {num_output: 10weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}
layer {name: "accuracy"type: "Accuracy"bottom: "ip2"bottom: "label"top: "accuracy"include {phase: TEST}
}
layer {name: "loss"type: "SoftmaxWithLoss"bottom: "ip2"bottom: "label"top: "loss"
}
}
【二】参数详解
包级参数
name :定义网络名称
可以随便起,例子中为"LeNet"
layer {定义层结构
name :层的名称
例如,输入层名称为“mnist”
type :层的类型
例如,输入层的类型为“Data”、卷积层“Convolution”、池化层“Pooling”、全连接层“InnerProduct”、激活层“ReLU”、计算精度“Accuracy”、Softmax损失层“SoftmaxWithLoss”
top :用来标记输出数据(blob)。例如,在训练中,输入层有两个top分别为“data”和“label”,分别存放了数据和标签。
bottom :用来标记输入数据(blob)
它的上层的top相同,输入层是顶层,因此没有bottom blob。如果该层的bottom和top相同,则该层的输入和输出占用了一个blob。
include {当前层所属的阶段
一般训练的时候和测试的时候,模型的层是不一样的。该层(layer)是属于训练阶段的层,还是属于测试阶段的层,需要用include来指定。 如果没有include参数,则表示该层既在训练模型中,又在测试模型中。
phase:当前层的阶段;TRAIN:训练;TEST:测试;
}
data_param {定义数据参数、数据来源等等
source : 包含数据库的目录名称,如examples/mnist/mnist_train_lmdb
batch_size : 每次处理的数据个数,如64
rand_skip : 在开始的时候,路过某个数据的输入。通常对异步的SGD很有用。
backend : 选择是采用LevelDB还是LMDB, 默认是LevelDB.
}
transform_param {数据的预处理,可以将数据变换到定义的范围内。
scale :0.00390625,实际上就是1/255, 即将输入数据由0-255归一化到0-1之间
mean_file_size: "examples/cifar10/mean.binaryproto" ,用一个配置文件来进行均值操作
mirror: 1 ,1表示开启镜像,0表示关闭,也可用ture和false来表示
crop_size: 227 ,剪裁一个 227*227的图块,在训练阶段随机剪裁,在测试阶段从中间裁剪
}
param {定义weight或bias的学习速率和衰减因子参数。
lr_mult : weight或bias的学习速率decay_mult :weight或bias的衰减因子}
convolution_param {定义卷积层的参数。
num_output :输出的个数;即卷积核的个数;pad :填充边缘的大小。可使用pad_h和pad_w来分别设定kernel_size :卷积核的大小,如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定group :分组,默认为1组。卷积分组可以减少网络的参数。 weight_filler :权值初始化,若设置为constant, 则默认为0。也可使用"xavier"或者”gaussian"进行初始化bias_filler :偏置项的初始化,参考weight_filler
}
lrn_param {定义归一化层的参数
local_size :对于cross channel LRN为需要求和的邻近channel的数量;对于within channel LRN为需要求和的空间区域的边长alpha :缩放参数;默认为1;beta :β系数;默认为5norm_region : [default ACROSS_CHANNELS]: 选择哪种LRN的方法ACROSS_CHANNELS 或者WITHIN_CHANNEL
}
pooling_param {定义池化层的参数
kernel_size :必选;(or kernel_h and kernel_w):过滤器的大小pool :可选;池化的方法,最大值池化MAX、平均值池化AVE 和 随机池化STOCHASTIC;默认MAXstride :可选(or stride_h and stride_w) [default1]:指定过滤器的步长
}
inner_product_param {定义全连接层的参数
inner_product_param级别参数num_output :过滤器个数。必选;weight_filler :[default type: 'constant' value: 0]:参数的初始化方法bias_filler :偏置的初始化方法 {weight_filler 和 bias_filler级别参数type :初始化类型;有 常量“constant” 高斯分布“gaussian” “uniform” “Xavier”等等。常用的是“constant”和“gaussian”std :标准差;如果是 gaussian,则可选的设置它;默认值为1;mean :均值;如果是 gaussian,则可选的设置它;默认值为0;value :定值;如果是“constant”,则设置它;默认值为0;}
}
dropout_param :定义Dropout层的参数
accuracy_param :定义Accuracy层的参数
}
}
【三】官方说明
参见:caffe/src/caffe/proto/caffe.proto中message ParamSpec
// Specifies training parameters (multipliers on global learning constants, and the name and other settings used for weight sharing).
// 指定训练参数(全局学习常数的乘数,以及用于权重共享的名称和其他设置)。
message ParamSpec {// The names of the parameter blobs -- useful for sharing parameters among layers, but never required otherwise. To share a parameter between two layers, give it a (non-empty) name.// 参数块的名称——用于在层之间共享参数,但在其他情况下不需要。要在两个层之间共享一个参数,请给它一个(非空)名称。optional string name = 1;// Whether to require shared weights to have the same shape, or just the same count -- defaults to STRICT if unspecified.// 是否要求共享的权重具有相同的形状,或者只是相同的计数——如果未指定,默认为STRICT。optional DimCheckMode share_mode = 2;enum DimCheckMode {// STRICT (default) requires that num, channels, height, width each match. STRICT(默认值)要求num、通道、高度和宽度都匹配STRICT = 0;// PERMISSIVE requires only the count (num*channels*height*width) to match. PERMISSIVE只要求count(num*channels*height*width)匹配PERMISSIVE = 1;}// The multiplier on the global learning rate for this parameter.全局学习率的乘数。optional float lr_mult = 3 [default = 1.0];// The multiplier on the global weight decay for this parameter.全局权值的乘数衰减。optional float decay_mult = 4 [default = 1.0];
}// NOTE
// Update the next available ID when you add a new LayerParameter field. 在添加新LayerParameter字段时更新下一个可用ID。
//
// LayerParameter next available layer-specific ID: 149 (last added: clip_param)
message LayerParameter {optional string name = 1; // the layer nameoptional string type = 2; // the layer typerepeated string bottom = 3; // the name of each bottom blobrepeated string top = 4; // the name of each top blob// The train / test phase for computation.optional Phase phase = 10;// The amount of weight to assign each top blob in the objective.// Each layer assigns a default value, usually of either 0 or 1, to each top blob.// 在目标中分配每个顶部blob的权重。每个层为每个顶部blob分配一个默认值,通常为0或1。repeated float loss_weight = 5;// Specifies training parameters (multipliers on global learning constants, and the name and other settings used for weight sharing).// 指定训练参数(全局学习常数的乘数,以及用于权重共享的名称和其他设置)。repeated ParamSpec param = 6;// The blobs containing the numeric parameters of the layer. 包含该层的数值参数的块。repeated BlobProto blobs = 7;// Specifies whether to backpropagate to each bottom. If unspecified, Caffe will automatically infer whether each input needs backpropagation to compute parameter gradients. // If set to true for some inputs, backpropagation to those inputs is forced; if set false for some inputs, backpropagation to those inputs is skipped.// The size must be either 0 or equal to the number of bottoms.// 指定是否反向传播到每个底部。如果未指定,Caffe将自动推断每个输入是否需要反向传播来计算参数梯度。// 如果对某些输入设置为true,则强制反向传播到这些输入;如果某些输入设置为false,则跳过对这些输入的反向传播。大小必须是0或等于底部的数量。repeated bool propagate_down = 11;// Rules controlling whether and when a layer is included in the network,based on the current NetState. // You may specify a non-zero number of rules to include OR exclude, but not both. If no include or exclude rules are specified, the layer is always included. // If the current NetState meets ANY (i.e., one or more) of the specified rules, the layer is included/excluded.// 根据当前网络状态控制网络中是否包含层以及何时包含层的规则。// 你可以指定一个非零数的规则来包含或排除,但不能同时包含或排除。如果没有指定包含或排除规则,则始终包含该层。// 如果当前网络状态满足任何,一个或多个)指定的规则,该层被包括/排除。repeated NetStateRule include = 8;repeated NetStateRule exclude = 9;// Parameters for data pre-processing. 用于数据预处理的参数。optional TransformationParameter transform_param = 100;// Parameters shared by loss layers. 损耗层共享的参数。optional LossParameter loss_param = 101;// Layer type-specific parameters. Layer特定类型参数。//// Note: certain layers may have more than one computational engine for their implementation. // These layers include an Engine type and engine parameter for selecting the implementation.// The default for the engine is set by the ENGINE switch at compile-time.// 注意:某些层的实现可能有多个计算引擎。 这些层包括用于选择实现的引擎类型和引擎参数。 引擎的默认值由引擎开关在编译时设置。optional AccuracyParameter accuracy_param = 102;optional ArgMaxParameter argmax_param = 103;optional BatchNormParameter batch_norm_param = 139;optional BiasParameter bias_param = 141;optional ClipParameter clip_param = 148;optional ConcatParameter concat_param = 104;optional ContrastiveLossParameter contrastive_loss_param = 105;optional ConvolutionParameter convolution_param = 106;optional CropParameter crop_param = 144;optional DataParameter data_param = 107;optional DropoutParameter dropout_param = 108;optional DummyDataParameter dummy_data_param = 109;optional EltwiseParameter eltwise_param = 110;optional ELUParameter elu_param = 140;optional EmbedParameter embed_param = 137;optional ExpParameter exp_param = 111;optional FlattenParameter flatten_param = 135;optional HDF5DataParameter hdf5_data_param = 112;optional HDF5OutputParameter hdf5_output_param = 113;optional HingeLossParameter hinge_loss_param = 114;optional ImageDataParameter image_data_param = 115;optional InfogainLossParameter infogain_loss_param = 116;optional InnerProductParameter inner_product_param = 117;optional InputParameter input_param = 143;optional LogParameter log_param = 134;optional LRNParameter lrn_param = 118;optional MemoryDataParameter memory_data_param = 119;optional MVNParameter mvn_param = 120;optional ParameterParameter parameter_param = 145;optional PoolingParameter pooling_param = 121;optional PowerParameter power_param = 122;optional PReLUParameter prelu_param = 131;optional PythonParameter python_param = 130;optional RecurrentParameter recurrent_param = 146;optional ReductionParameter reduction_param = 136;optional ReLUParameter relu_param = 123;optional ReshapeParameter reshape_param = 133;optional ScaleParameter scale_param = 142;optional SigmoidParameter sigmoid_param = 124;optional SoftmaxParameter softmax_param = 125;optional SPPParameter spp_param = 132;optional SliceParameter slice_param = 126;optional SwishParameter swish_param = 147;optional TanHParameter tanh_param = 127;optional ThresholdParameter threshold_param = 128;optional TileParameter tile_param = 138;optional WindowDataParameter window_data_param = 129;
}
相关文章:

南大和中大“合体”拯救手残党:基于GAN的PI-REC重构网络,“老婆”画作有救了 | 技术头条...
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑编译 | 一一出品 | AI科技大本营(ID:rgznai100)对于喜欢画画的你来说,总是画得七零八落,不堪入目,但现在,有一…

区块链技术应用领域和优势
区块链的应用正成为很多人关注的领域 ,有很多的新应用正在逐步的实施当中,各种的区块链应用也是让众人惊喜不断, 随着区块链技术的发展 ,各行各业在应用中所获取的成效也是越来越大, 这大大激发了人们对于区块链技术的…

Kataspace:用HTML5和WebGL创建基于浏览器的虚拟世界
源自斯坦福的创业公司Katalabs发布了一个用于创建基于浏览器的虚拟世界的开源框架。名叫KataSpace的软件,利用了新兴的HTML5技术,以及WebGL和WebSockets,允许用户无需安装任何插件,直接在浏览器的3D环境中展开互动。Katalabs已经推…
十问陆奇:努力、能力和机遇,谁能帮你跑赢未来?
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑作者 | 陆奇转载自36氪陆奇说:在创业者从0到1的过程中,我们看到的主要挑战有以下几个方面:对需求的理解和判断不够,与目标用户/客户的…
【AI】caffe使用步骤(三):编写求解文件solver.prototxt
【一】参考博客 caffe solver 配置详解:http://www.mamicode.com/info-detail-2620709.html Caffe学习系列(7):solver及其配置:https://www.cnblogs.com/denny402/p/5074049.html 【二】solver求解文件详解 1、solver求解文件例子如下 ne…

MySQL 8.0 Invisible Indexes 和 RDS 5.6 Invisible Indexes介绍
mysql 在8.0的时候支持了不可见索引,称为隐式索引 索引默认是可以的,控制索引的可见性可以使用Invisible,visible关键字作为create table,create index,alter table 来进行定义。RDS 5.6 Invisible Indexes 也是最近刚刚上线的功能。新购买实例目前已经支…
大有可为的“正则表达式”(二)
5.3. 基本和扩展正则表达式Unix支持两种的正则表达式的版本:(1)现代版本:扩展正则表达式(extended regular expression,ERE),属于IEEE1003.2标准,拥有比BRE更多的功能。…
【AI】caffe使用步骤(四):训练和预测
一、训练 1、直接训练 ./build/tools/caffe train --solverexamples/mnist/lenet_solver.prototxt ./build/tools/caffe train --solverexamples/mnist/lenet_solver.prototxt -gpu all //使用全部的gpu来训练2、采用微调funing-tuning训练法 ./build/tools/caffe train --s…
Github免费中文书《Go入门指南》,带你从零学Go | 极客头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑作者 | 无闻整理 | Jane出品 | AI科技大本营(ID:rgznai100)【导语】Go(也称 Golang)是 Google 开发的一种静态强类型、编…
sql语句中having的作用是?
HAVING对由sum或其它集合函数运算结果的输出进行限制。比如,我们可能只希望看到Store_Information数据表中销售总额超过1500美圆的商店的信息,这时我们就需要使用HAVING从句。语法格式为: SELECT "column_name1", SUM("column…
微软重新释出MS10-015 解决蓝屏问题
微软于周二(3/2)重新释出MS10-015修补程序。由于先前使用者安装该程序时,若电脑中含有Alureon rootkit就会出现更新错误,因而微软也提醒使用者先行杀毒,并避免安装后可能造成的蓝屏画面。 MS10-015是微软在今年2月用来…
share_ptr_c++11
C智能指针 shared_ptr shared_ptr 是一个标准的共享所有权的智能指针, 允许多个指针指向同一个对象. 定义在 memory 文件中(非memory.h), 命名空间为 std. std::shared_ptr<int> sp1 std::make_shared<int>(10);std::shared_ptr<std::string> sp2 std::…
【Python】ubuntu14安装pycaffe环境:python2.7及依赖库
1、问题描述 ubuntu14自带的python2.7版本是python2.7.5,安装pycaffe环境时,出现错误,提示版本低。在bing上搜索源码安装python2.7.16的步骤,后续使用时,又报错,缺少SLL模块: Cant connect to…

周志华、张潼亲自辅导AI课程,DeeCamp 2019正式启动
4 月 8 日,创新工场对外宣布 DeeCamp 2019 人工智能训练营正式启动。 据介绍,DeeCamp 2019 将于 7 月 15 日至 8 月 23 日在北京、上海、南京、广州四地同时举办。今年招生规模也将扩大,计划招收 600 名大学生,进行为期 5 周的理…

No.2 条件
2019独角兽企业重金招聘Python工程师标准>>> clojure中不仅有if 还有when 还有什么when-do when-first when-let 一堆 首先介绍if (defn if? [x](if (pos? x)x(- x))) 这事一个取绝对值的方法,方法名改了下,pos? 是判断是否为正数 参数只能为数字 能看明白吧…
如何用Python和BERT做中文文本二元分类?| 程序员硬核评测
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑作者 | 王树义来源 | 王树芝兰(ID:nkwangshuyi)兴奋去年, Google 的 BERT 模型一发布出来,我就很兴奋。因为我当时正在用 fast.ai 的…
【C++】Google Protocol Buffer(protobuf)详解(二)
代码走读:caffe中protobuf的详细使用过程 【一】proto文件,以caffe.proto中BlobShape为例 syntax "proto2"; //指明protobuf版本,默认是v2,其它版本:"proto3"package caffe; // 最终生成c代码…
Linux使用
软件操作 软件包管理 yum安装 yum install ...卸载 yum remove ...搜索 yum serach ...清理缓存 yum clean packages列出已安装 yum list软件包信息 yum info ...硬件资源信息 内存free -m 硬盘df -h 负载(w或top)w 12:53:49 up 2:33, 3 users, load ave…
通过进程ID获得该进程主窗口的句柄
一个进程可以拥有很多主窗口,也可以不拥有主窗口,所以这样的函数是不存在的,所幸的是,相反的函数是有的。所以我们可以调用EnumWindows来判断所有的窗口是否属于这个进程。 typedef struct tagWNDINFO{ DWORD dwProcessId; …
【AI】caffe源码分析(一)
【一】caffe依赖开源库 【C】google gflags详解 【C】google glog详解 【C】Google Protocol Buffer(protobuf)详解(一) 【C】Google Protocol Buffer(protobuf)详解(二) 【C】goog…

专访博世王红星:大数据和AI将是中国制造业升级新动力
数据分析挖掘与工业大数据是智能制造与工业互联网的核心,其本质是通过促进数据的自动流动与智能决策去解决控制和业务问题,有效减少决策过程所带来的不确定性,并尽量克服人工决策的缺点,从而推动智能制造进程与智能工厂的建设&…
C进阶 - 内存四驱模型
一.内存四驱模型 不知我们是否有读过 《深入理解 java 虚拟机》这本书,强烈推荐读一下。在 java 中我们将运行时数据,分为五个区域分别是:程序计数器,java 虚拟机栈,本地方法栈,java 堆,方法区。…

ATEN—第十章OSPF的高级配置(4)
实验使用的工具:小凡模拟器一、在路由器R1上,配置接口,启动ospf路由进程和rip,宣告网段,并配置路由重分发★☆R1☆★☆→Router>Router>enableRouter#config terminalRouter(config)#hostname R1-jinR1-jin(config)#interfa…
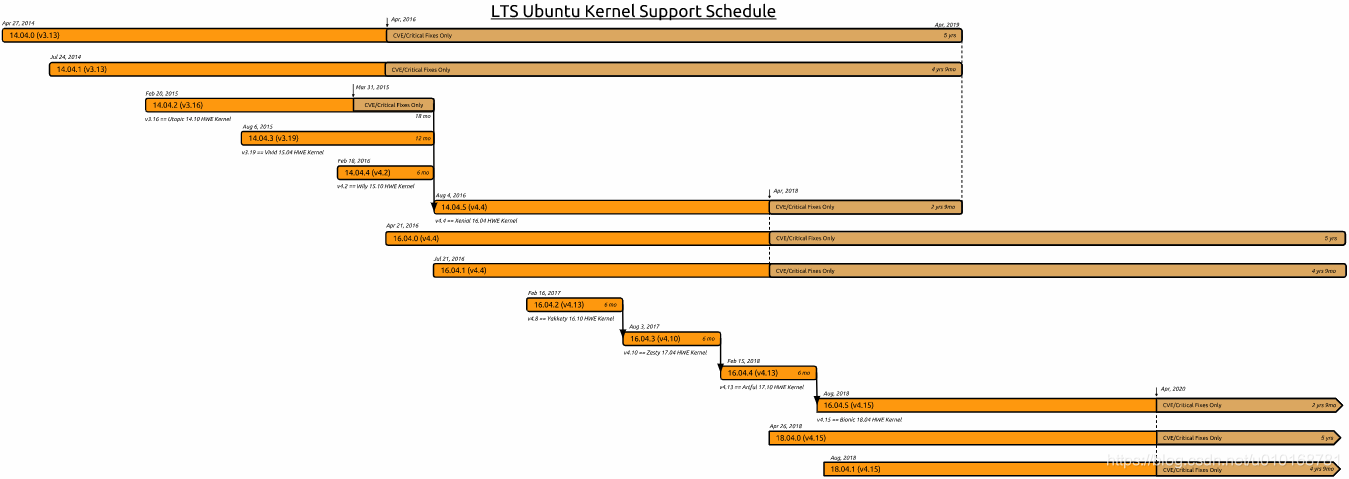
【ubuntu】ubuntu14.04、16.04、18.04 LTS版本支持时间
0、历史版本下载地址 http://old-releases.ubuntu.com/releases/ http://mirrors.163.com/ubuntu-releases/ 1、官网说明 https://wiki.ubuntu.com/Kernel/LTSEnablementStack 2、简要记录 如下图: 14.04.0(v3.13) 14.04.1(v3.13) 14.04.5(v4.4) LTS 支持至 20…
BERT拿下最佳长论文奖!NAACL 2019最佳论文奖公布
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑作者 | 刘静编辑 | 李尔客本文经授权转自公众号图灵Topia(ID:turingtopia)今日,自然语言处理顶会NAACL 2019最佳论文奖公布ÿ…
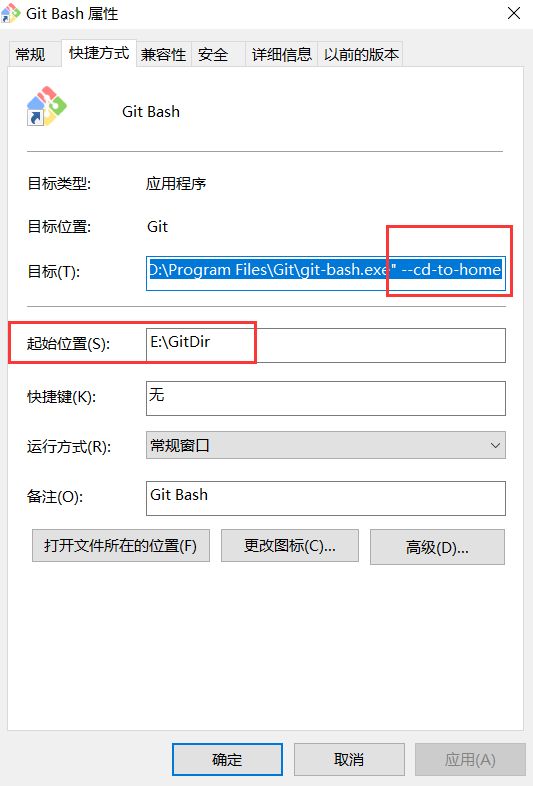
Git Bash修改默认路径
Git Bash默认安装在C:/user目录下,如果管理其他目录的代码库,需要切换目录。 修改Git Bash的默认路径,不需要每次切换了。 方法: 桌面Git Bash快捷方式,右键-->属性-->“快捷方式”标签 1,修改“起止…

NextGEN Gallery ~ 最强WordPress相册插件
博客照片很多?上传和管理图片太烦?想幻灯显示相册?在博客中任意插入动态图片效果?…… 你和我一样,需要NextGEN Gallery,最强WordPress相册插件! 其实网上可以搜到不少关于这个插件的介绍&#…
【经验】网络加速:pip
一、python pip下载加速 参考博客:让PIP源使用国内镜像,提升下载速度和安装成功率。 pip/anaconda修改镜像源,加快python模块安装速度 1、Linux下 修改 ~/.pip/pip.conf (没有就创建一个文件夹及文件。文件夹要加“.”,表示是隐…
iframe 有那些缺
*iframe 会阻塞主页面的 Onload 事 *iframe 和主页面共享连接池,而浏览器对相同域的连接有限制(6-8前),所以会影响页面的并行加 使用 iframe 之前需要考虑这两个缺点。如果需要使用 iframe,最通过 javascrit 动态给 iframe 添加 src 属性值&a…
用Python让蔡徐坤在我的命令行里打篮球!|附完整代码
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑来源 | 01二进制(ID:gh_d1999add1857)编辑 | Jane【导语】作者自称是一个经常逛 B 站的肥宅。最近 B 站上流行的视频素材除了“换脸”,其次就要属…