如何用Python和BERT做中文文本二元分类?| 程序员硬核评测
 点击上方↑↑↑蓝字关注我们~
点击上方↑↑↑蓝字关注我们~
「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑
作者 | 王树义
来源 | 王树芝兰(ID:nkwangshuyi)
兴奋
去年, Google 的 BERT 模型一发布出来,我就很兴奋。
因为我当时正在用 fast.ai 的 ULMfit 做自然语言分类任务(还专门写了《如何用 Python 和深度迁移学习做文本分类?》一文分享给你)。ULMfit 和 BERT 都属于预训练语言模型(Pre-trained Language Modeling),具有很多的相似性。
所谓语言模型,就是利用深度神经网络结构,在海量语言文本上训练,以抓住一种语言的通用特征。
上述工作,往往只有大机构才能完成。因为花费实在太大了。
这花费包括但不限于:
存数据
买(甚至开发)运算设备
训练模型(以天甚至月计)
聘用专业人员
……
预训练就是指他们训练好之后,把这种结果开放出来。我们普通人或者小型机构,也可以借用其结果,在自己的专门领域文本数据上进行微调,以便让模型对于这个专门领域的文本有非常清晰的认识。
所谓认识,主要是指你遮挡上某些词汇,模型可以较准确地猜出来你藏住了什么。
甚至,你把两句话放在一起,模型可以判断它俩是不是紧密相连的上下文关系。
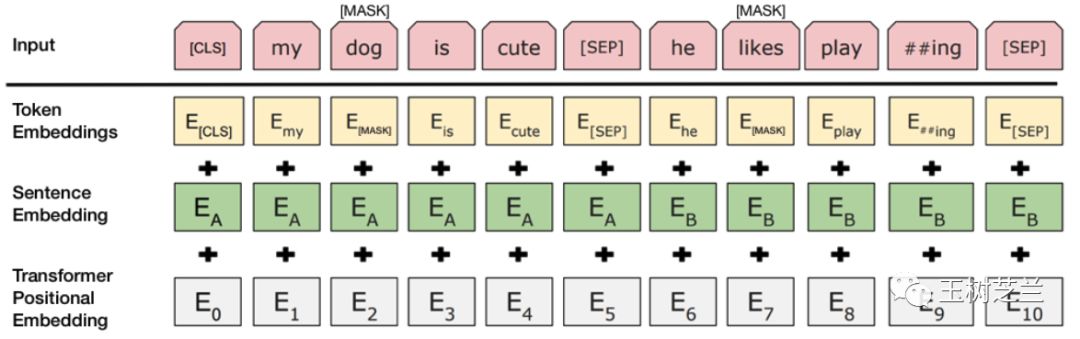
这种“认识”有用吗?
当然有。
BERT 在多项自然语言任务上测试,不少结果已经超越了人类选手。
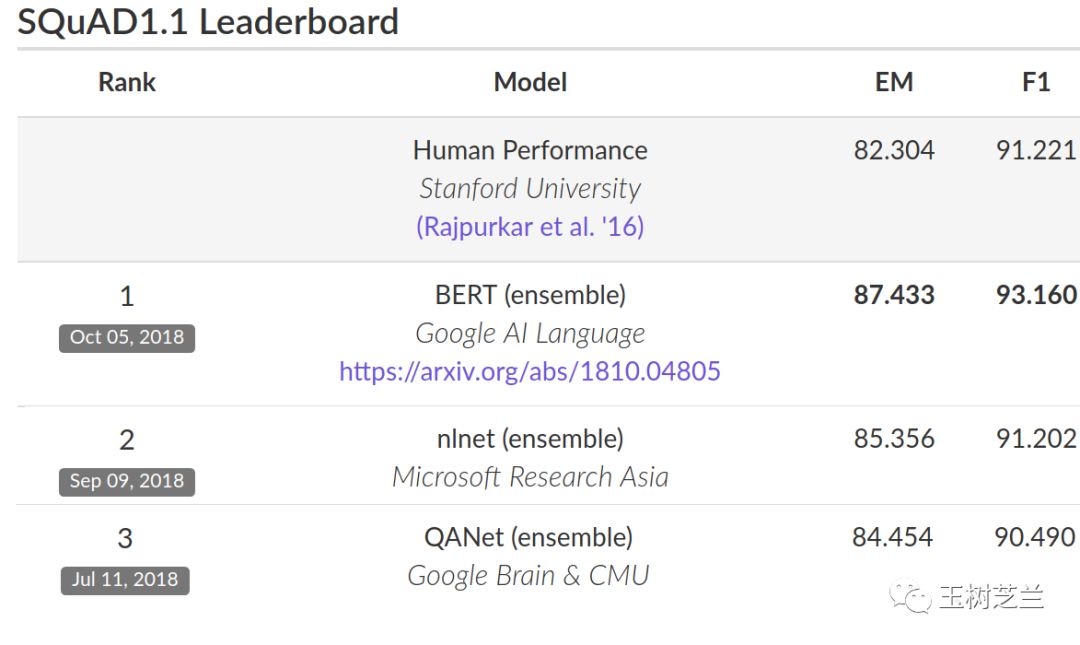
BERT 可以辅助解决的任务,当然也包括文本分类(classification),例如情感分类等。这也是我目前研究的问题。
痛点
然而,为了能用上 BERT ,我等了很久。
Google 官方代码早已开放。就连 Pytorch 上的实现,也已经迭代了多少个轮次了。
但是我只要一打开他们提供的样例,就头晕。
单单是那代码的行数,就非常吓人。
而且,一堆的数据处理流程(Data Processor) ,都用数据集名称命名。我的数据不属于上述任何一个,那么我该用哪个?
还有莫名其妙的无数旗标(flags) ,看了也让人头疼不已。
让我们来对比一下,同样是做分类任务,Scikit-learn 里面的语法结构是什么样的。
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target)
即便是图像分类这种数据吞吐量大,需要许多步骤的任务,你用 fast.ai ,也能几行代码,就轻轻松松搞定。
!git clone https://github.com/wshuyi/demo-image-classification-fastai.git
from fastai.vision import *
path = Path("demo-image-classification-fastai/imgs/")
data = ImageDataBunch.from_folder(path, test='test', size=224)
learn = cnn_learner(data, models.resnet18, metrics=accuracy)
learn.fit_one_cycle(1)
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_top_losses(9, figsize=(8, 8))
别小瞧这几行代码,不仅帮你训练好一个图像分类器,还能告诉你,那些分类误差最高的图像中,模型到底在关注哪里。

对比一下,你觉得 BERT 样例和 fast.ai 的样例区别在哪儿?
我觉得,后者是给人用的。
教程
我总以为,会有人把代码重构一下,写一个简明的教程。
毕竟,文本分类任务是个常见的机器学习应用。应用场景多,也适合新手学习。
但是,这样的教程,我就是没等来。
当然,这期间,我也看过很多人写的应用和教程。
有的就做到把一段自然语言文本,转换到 BERT 编码。戛然而止。
有的倒是认真介绍怎么在官方提供的数据集上,对 BERT 进行“稍微修改”使用。所有的修改,都在原始的 Python 脚本上完成。那些根本没用到的函数和参数,全部被保留。至于别人如何复用到自己的数据集上?人家根本没提这事儿。
我不是没想过从头啃一遍代码。想当年读研的时候,我也通读过仿真平台上 TCP 和 IP 层的全部 C 代码。我确定眼前的任务,难度更低一些。
但是我真的懒得做。我觉得自己被 Python 机器学习框架,特别是 fast.ai 和 Scikit-learn 宠坏了。
后来, Google 的开发人员把 BERT 弄到了 Tensorflow Hub 上。还专门写了个 Google Colab Notebook 样例。
看到这个消息,我高兴坏了。
我尝试过 Tensorflow Hub 上的不少其他模型。使用起来很方便。而 Google Colab 我已在《如何用 Google Colab 练 Python?》一文中介绍给你,是非常好的 Python 深度学习练习和演示环境。满以为双剑合璧,这次可以几行代码搞定自己的任务了。
且慢。

真正打开一看,还是以样例数据为中心。
普通用户需要什么?需要一个接口。
你告诉我输入的标准规范,然后告诉我结果都能有什么。即插即用,完事儿走人。
一个文本分类任务,原本不就是给你个训练集和测试集,告诉你训练几轮练多快,然后你告诉我准确率等结果吗?
你至于让我为了这么简单的一个任务,去读几百行代码,自己找该在哪里改吗?
好在,有了这个样例做基础,总比没有好。
我耐下心来,把它整理了一番。
声明一下,我并没有对原始代码进行大幅修改。
所以不讲清楚的话,就有剽窃嫌疑,也会被鄙视的。
这种整理,对于会 Python 的人来说,没有任何技术难度。
可正因为如此,我才生气。这事儿难做吗?Google 的 BERT 样例编写者怎么就不肯做?
从 Tensorflow 1.0 到 2.0,为什么变动会这么大?不就是因为 2.0 才是给人用的吗?
你不肯把界面做得清爽简单,你的竞争者(TuriCreate 和 fast.ai)会做,而且做得非常好。实在坐不住了,才肯降尊纡贵,给普通人开发一个好用的界面。
教训啊!为什么就不肯吸取呢?
我给你提供一个 Google Colab 笔记本样例,你可以轻易地替换上自己的数据集来运行。你需要去理解(包括修改)的代码,不超过10行。
我先是测试了一个英文文本分类任务,效果很好。于是写了一篇 Medium 博客,旋即被 Towards Data Science 专栏收录了。
Towards Data Science 专栏编辑给我私信,说:
Very interesting, I like this considering the default implementation is not very developer friendly for sure.
有一个读者,居然连续给这篇文章点了50个赞(Claps),我都看呆了。

看来,这种忍受已久的痛点,不止属于我一个人。
估计你的研究中,中文分类任务可能遇到得更多。所以我干脆又做了一个中文文本分类样例,并且写下这篇教程,一并分享给你。
咱们开始吧。
代码
请点击这个链接(http://t.cn/E6twZEG),查看我在 Github 上为你做好的 IPython Notebook 文件。
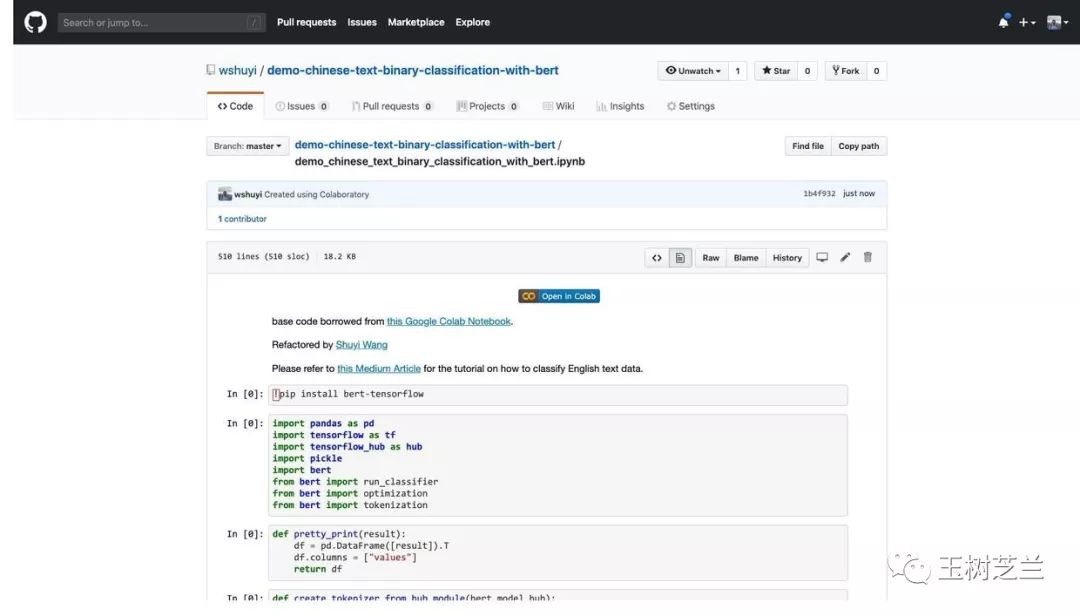
Notebook 顶端,有个非常明显的 "Open in Colab" 按钮。点击它,Google Colab 就会自动开启,并且载入这个 Notebook 。
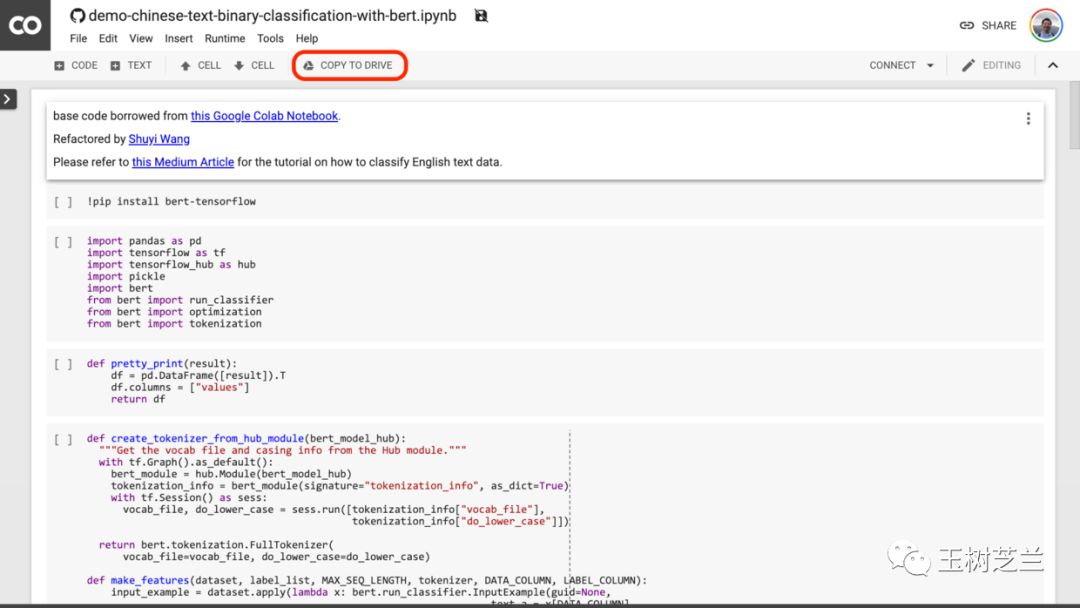
我建议你点一下上图中红色圈出的 “COPY TO DRIVE” 按钮。这样就可以先把它在你自己的 Google Drive 中存好,以便使用和回顾。
这件事做好以后,你实际上只需要执行下面三个步骤:
你的数据,应该以 Pandas 数据框形式组织。如果你对 Pandas 不熟悉,可以参考我的这篇文章。
如有必要,可以调整训练参数。其实主要是训练速率(Learning Rate)和训练轮数(Epochs)。
执行 Notebook 的代码,获取结果。
当你把 Notebook 存好之后。定睛一看,或许会觉得上当了。
老师你骗人!说好了不超过10行代码的!
别急。
在下面这张图红色圈出的这句话之前,你不用修改任何内容。
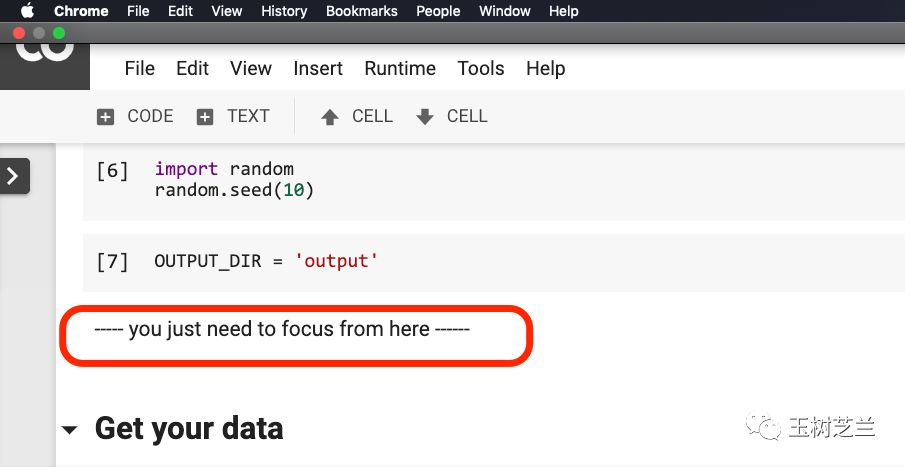
请你点击这句话所在位置,然后从菜单中如下图选择 Run before 。
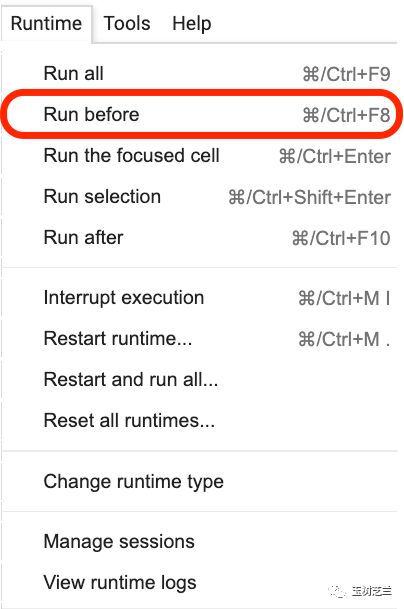
下面才都是紧要的环节,集中注意力。
第一步,就是把数据准备好。
!wget https://github.com/wshuyi/demo-chinese-text-binary-classification-with-bert/raw/master/dianping_train_test.pickle
with open("dianping_train_test.pickle", 'rb') as f:
train, test = pickle.load(f)
这里使用的数据,你应该并不陌生。它是餐饮点评情感标注数据,我在《如何用Python和机器学习训练中文文本情感分类模型?》和《如何用 Python 和循环神经网络做中文文本分类?》中使用过它。只不过,为了演示的方便,这次我把它输出为 pickle 格式,一起放在了演示 Github repo 里,便于你下载和使用。
其中的训练集,包含1600条数据;测试集包含400条数据。标注里面1代表正向情感,0代表负向情感。
利用下面这条语句,我们把训练集重新洗牌(shuffling),打乱顺序。以避免过拟合(overfitting)。
train = train.sample(len(train))
这时再来看看我们训练集的头部内容。
train.head()

如果你后面要替换上自己的数据集,请注意格式。训练集和测试集的列名称应该保持一致。
第二步,我们来设置参数。
myparam = {
"DATA_COLUMN": "comment",
"LABEL_COLUMN": "sentiment",
"LEARNING_RATE": 2e-5,
"NUM_TRAIN_EPOCHS":3,
"bert_model_hub":"https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1"
}
前两行,是把文本、标记对应的列名,指示清楚。
第三行,指定训练速率。你可以阅读原始论文,来进行超参数调整尝试。或者,你干脆保持默认值不变就可以。
第四行,指定训练轮数。把所有数据跑完,算作一轮。这里使用3轮。
如果你希望学习如何使用这些参数,推荐《Python深度学习》这本教材。
最后一行,是说明你要用的 BERT 预训练模型。咱们要做中文文本分类,所以使用的是这个中文预训练模型地址。如果你希望用英文的,可以参考我的 Medium 博客文章以及对应的英文样例代码。
最后一步,我们依次执行代码就好了。
result, estimator = run_on_dfs(train, test, **myparam)
注意,执行这一句,可能需要花费一段时间。做好心理准备。这跟你的数据量和训练轮数设置有关。
在这个过程中,你可以看到,程序首先帮助你把原先的中文文本,变成了 BERT 可以理解的输入数据格式。
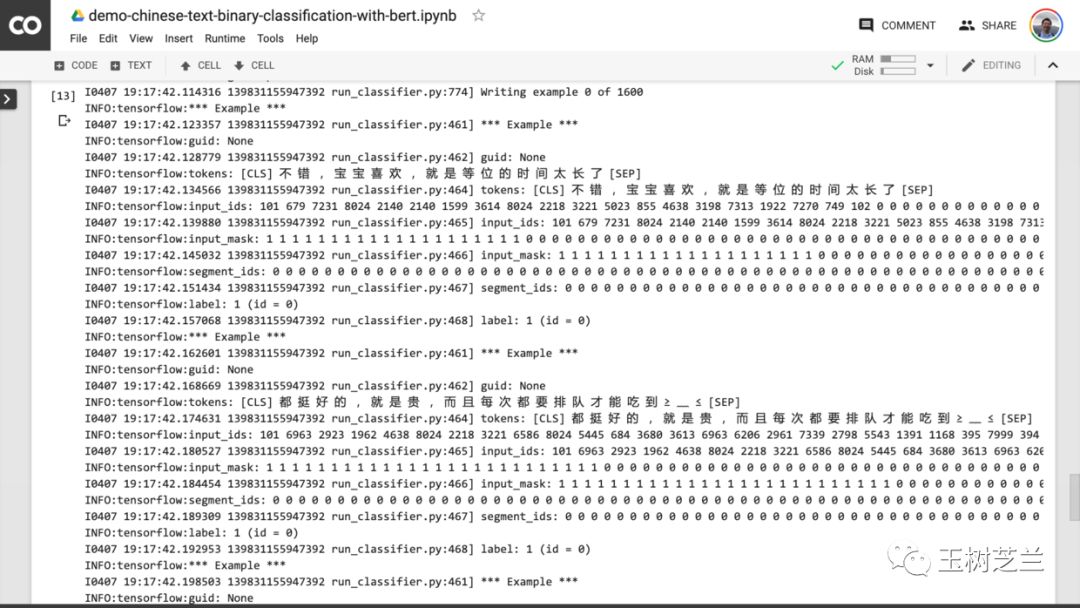
当你看到下图中红色圈出文字时,就意味着训练过程终于结束了。
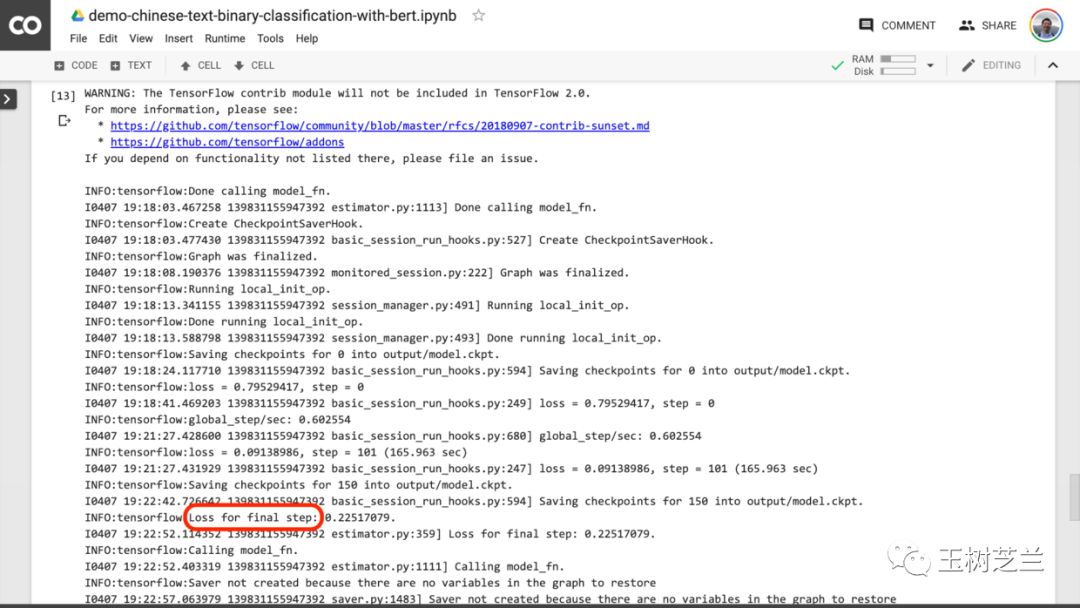
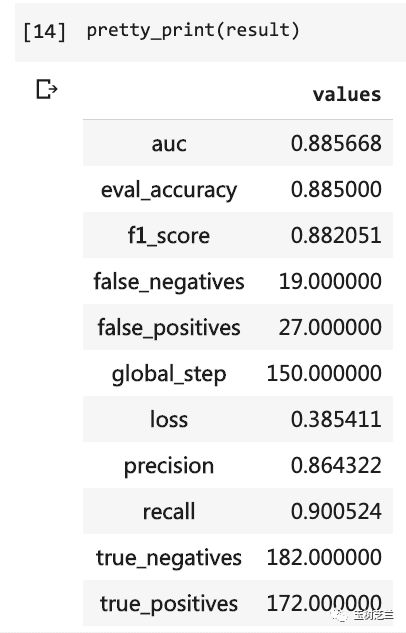
然后你就可以把测试的结果打印出来了。
pretty_print(result)
跟咱们之前的教程(使用同一数据集)对比一下。
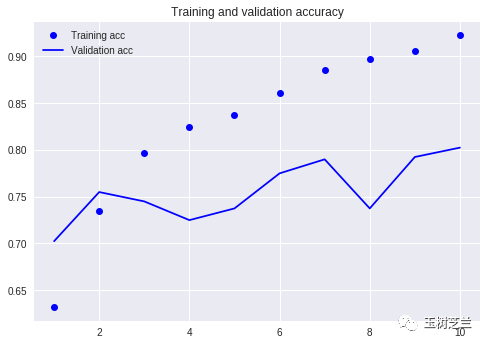
当时自己得写那么多行代码,而且需要跑10个轮次,可结果依然没有超过 80% 。这次,虽然只训练了3个轮次,但准确率已经超过了 88% 。
在这样小规模数据集上,达到这样的准确度,不容易。
BERT 性能之强悍,可见一斑。
小结
讲到这里,你已经学会了如何用 BERT 来做中文文本二元分类任务了。希望你会跟我一样开心。
如果你是个资深 Python 爱好者,请帮我个忙。
还记得这条线之前的代码吗?
能否帮我把它们打个包?这样咱们的演示代码就可以更加短小精悍和清晰易用了。
欢迎在咱们的 Github 项目上提交你的代码。如果你觉得这篇教程对你有帮助,欢迎给这个 Github 项目加颗星。谢谢!
祝深度学习愉快!
(本文为 AI大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
「2019 Python开发者日」演讲议题全揭晓!这一次我们依然“只讲技术,拒绝空谈”10余位一线Python技术专家共同打造一场硬核技术大会。更有深度培训实操环节,为开发者们带来更多深度实战机会。更多详细信息请咨询13581782348(微信同号)。

推荐阅读:
南大和中大“合体”拯救手残党:基于GAN的PI-REC重构网络,“老婆”画作有救了
技术头条
如何在面试中展示你对Python的coding能力?
10位技术大咖,想和你聊聊Python!
一个月修复20个漏洞获23675美元赏金, 原来是黑客队伍里出了无间道
救救中国 996 程序员!GitHub 近 230,000 Star、Python 之父伸张正义!
“入职 6 年,新人工资高我 2 千”:老板不加钱,不是嫌你老
微服务进阶避坑指南 | 技术头条
刺激!我31岁敲代码10年,明天退休!

❤点击“阅读原文”,了解「2019 Python开发者日」
相关文章:

【C++】Google Protocol Buffer(protobuf)详解(二)
代码走读:caffe中protobuf的详细使用过程 【一】proto文件,以caffe.proto中BlobShape为例 syntax "proto2"; //指明protobuf版本,默认是v2,其它版本:"proto3"package caffe; // 最终生成c代码…
Linux使用
软件操作 软件包管理 yum安装 yum install ...卸载 yum remove ...搜索 yum serach ...清理缓存 yum clean packages列出已安装 yum list软件包信息 yum info ...硬件资源信息 内存free -m 硬盘df -h 负载(w或top)w 12:53:49 up 2:33, 3 users, load ave…
通过进程ID获得该进程主窗口的句柄
一个进程可以拥有很多主窗口,也可以不拥有主窗口,所以这样的函数是不存在的,所幸的是,相反的函数是有的。所以我们可以调用EnumWindows来判断所有的窗口是否属于这个进程。 typedef struct tagWNDINFO{ DWORD dwProcessId; …
【AI】caffe源码分析(一)
【一】caffe依赖开源库 【C】google gflags详解 【C】google glog详解 【C】Google Protocol Buffer(protobuf)详解(一) 【C】Google Protocol Buffer(protobuf)详解(二) 【C】goog…
专访博世王红星:大数据和AI将是中国制造业升级新动力
数据分析挖掘与工业大数据是智能制造与工业互联网的核心,其本质是通过促进数据的自动流动与智能决策去解决控制和业务问题,有效减少决策过程所带来的不确定性,并尽量克服人工决策的缺点,从而推动智能制造进程与智能工厂的建设&…
C进阶 - 内存四驱模型
一.内存四驱模型 不知我们是否有读过 《深入理解 java 虚拟机》这本书,强烈推荐读一下。在 java 中我们将运行时数据,分为五个区域分别是:程序计数器,java 虚拟机栈,本地方法栈,java 堆,方法区。…

ATEN—第十章OSPF的高级配置(4)
实验使用的工具:小凡模拟器一、在路由器R1上,配置接口,启动ospf路由进程和rip,宣告网段,并配置路由重分发★☆R1☆★☆→Router>Router>enableRouter#config terminalRouter(config)#hostname R1-jinR1-jin(config)#interfa…
【ubuntu】ubuntu14.04、16.04、18.04 LTS版本支持时间
0、历史版本下载地址 http://old-releases.ubuntu.com/releases/ http://mirrors.163.com/ubuntu-releases/ 1、官网说明 https://wiki.ubuntu.com/Kernel/LTSEnablementStack 2、简要记录 如下图: 14.04.0(v3.13) 14.04.1(v3.13) 14.04.5(v4.4) LTS 支持至 20…
BERT拿下最佳长论文奖!NAACL 2019最佳论文奖公布
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑作者 | 刘静编辑 | 李尔客本文经授权转自公众号图灵Topia(ID:turingtopia)今日,自然语言处理顶会NAACL 2019最佳论文奖公布ÿ…
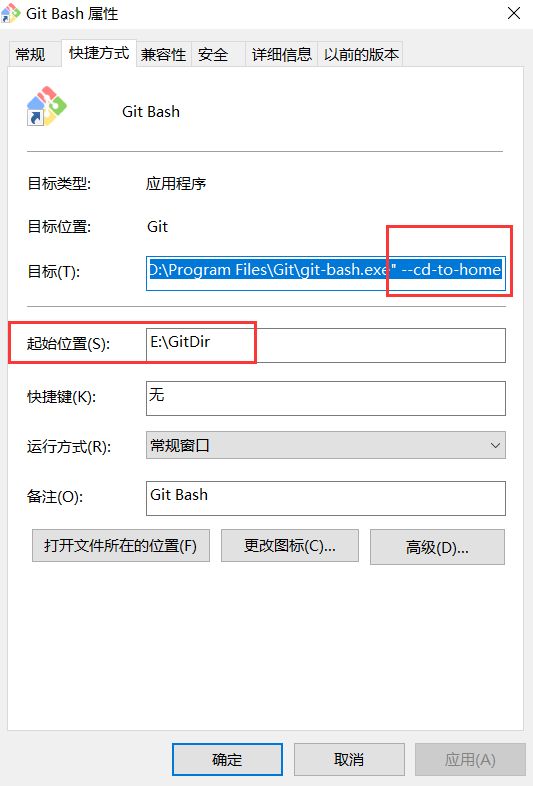
Git Bash修改默认路径
Git Bash默认安装在C:/user目录下,如果管理其他目录的代码库,需要切换目录。 修改Git Bash的默认路径,不需要每次切换了。 方法: 桌面Git Bash快捷方式,右键-->属性-->“快捷方式”标签 1,修改“起止…

NextGEN Gallery ~ 最强WordPress相册插件
博客照片很多?上传和管理图片太烦?想幻灯显示相册?在博客中任意插入动态图片效果?…… 你和我一样,需要NextGEN Gallery,最强WordPress相册插件! 其实网上可以搜到不少关于这个插件的介绍&#…
【经验】网络加速:pip
一、python pip下载加速 参考博客:让PIP源使用国内镜像,提升下载速度和安装成功率。 pip/anaconda修改镜像源,加快python模块安装速度 1、Linux下 修改 ~/.pip/pip.conf (没有就创建一个文件夹及文件。文件夹要加“.”,表示是隐…
iframe 有那些缺
*iframe 会阻塞主页面的 Onload 事 *iframe 和主页面共享连接池,而浏览器对相同域的连接有限制(6-8前),所以会影响页面的并行加 使用 iframe 之前需要考虑这两个缺点。如果需要使用 iframe,最通过 javascrit 动态给 iframe 添加 src 属性值&a…
用Python让蔡徐坤在我的命令行里打篮球!|附完整代码
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑来源 | 01二进制(ID:gh_d1999add1857)编辑 | Jane【导语】作者自称是一个经常逛 B 站的肥宅。最近 B 站上流行的视频素材除了“换脸”,其次就要属…
javascript 操作Word和Excel的实现代码
1.保存html页面到word 复制代码 代码如下:<HTML> <HEAD> <title> </title> </HEAD> <body> <form id"form"> <table id "PrintA" width"100%" border"1" cellspacing"0" cel…
【C++】C++11新增关键字详解
目录一、auto1、auto 用来声明自动变量,表明变量存储在栈(C11之前)2、auto用于推断变量类型示例(C11)3、声明或定义函数时作为函数返回值的占位符,此时需要与关键字 decltype 一起使用。(C11&am…
linux批量创建用户和密码
老男孩教育第五关实战考试题:批量创建10个用户stu01-stu10,并且设置随机8位密码,要求不能用shell的循环(例如:for,while等),只能用linux命令及管道实现。 方法1:[rootoldboy /]# ech…
“重构”黑洞:26岁MIT研究生的新算法 | 人物志
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑整理 | 若名出品 | AI科技大本营(ID:rgznai100)这是一个重要时刻。除了发布跟丈夫的两张合照外,Katie Bouman 在 Facebook 上鲜有内容更新&#…

【Ubuntu】VirtualBox显卡驱动VBoxVGA、VBoxSVGA、VMSVGA +3D对播放视频的影响
一、VBOXVGA、VMSVGA、VBOXSVGA简述 VBOXVGA和VBOXSVGA是vbox自己的,SVGA比VGA先进一点, VBoxSVGA: 使用Linux或者 Windows 7或者更高版本的新vm的默认图形控制器。 与传统的VBoxVGA选项相比,此图形控制器可提高性能和3D支持。 VBoxVGA: 将这…

MFC中利用CFileDialog选择文件并读取文件所遇到的问题和解决方法
在用MFC编写一个上位机时,需要实现选择和读取一个二进制文件,本来以为很简单的但是在实现过程中遇到很多问题,所幸都一一解决,这里做一下记录。 首先在实现文件选择,在界面上设置一个按钮,并在点击事件函数…

百度智能云一口气发布 14 个新产品,三大视频解决方案,产品最高降价 50%
产业智能化的浪潮正在加速传统互联网行业的升级,视频行业将成为最大的受益者。4 月 11 日,在 2019ABC INSPIRE 百度云智峰会上,百度副总裁、百度智能云总经理尹世明宣布,“百度云” 品牌全面升级为 “百度智能云”,以 …

开源代码hosting openfoundryfrom tw
http://www.openfoundry.org

倒计时1天!「2019 Python开发者日」报名即将关闭(附参会提醒)
「2019 Python开发者日」倒计时最后1天,仅剩少量余票,请扫码咨询 ↑↑↑相信很多人听过之前的 Python 进入小学课本、Python 进入浙江省高考等新闻,那么,有这么多头衔加持的 Python 究竟魅力在哪?与人工智能、大数据捆…
【Gstreamer】在虚拟机中无法使用硬件加速:gstreamer1.0-vaapi
1、问题描述 在虚拟机中,使用gstreamer播放视频,在没有安装gstreamer1.0-vaapi库时,还是正常的;在安装gstreamer1.0-vaapi后,不能播放视频。 错误信息如下: libva info: VA-API version 0.39.0 libva info: va_getDriverName() returns -1 libva error: va_getDriverNa…

如何在阿里云上安全的存放您的配置 - 续
在《如何在阿里云上安全的存放您的配置》一文中,我们介绍了如何通过ACM存放您的敏感配置,并进行加密。这样做的目的有两个: 在应用程序或对应生产环境容器或系统中,无需持久化任何敏感数据信息(如数据库连接串,等)&…
VLAN-VTP-Trunk
VLAN(Virtual LAN) VLAN可以隔离2层的广播域。A VLAN =(一个) 广播域 = (一个)逻辑子网路由器是隔离广播域的单个端口只能承载单个VLAN的流量。使用VLAN好处:1.有效的带宽利用2.提高了安全性3…
科大讯飞刷新纪录,机器阅读理解如何超越人类平均水平? | 技术头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」明日开启,扫码咨询 ↑↑↑记者 | 琥珀出品 | AI科技大本营(公众号ID:rgznai100)对于日常从事模型训练的研究人员来讲,无论是图像处理还是语音识别,都离…
【经验】Lenovo/ThinkPad 进入BIOS的方法汇总
1、快捷汇总 联想电脑进入BIOS的快捷键有“F2、F1、Del/Delete、NOVO开机”,部分机型按F2、F1时需要FN键配合 2、常用键 Lenovo笔记本:F2 Fn Lenovo台式机:F2 ThinkPad:F1 联系官网说明: http://tsonline.lenovo.…
NO.7 今天我们是实用派,看看业务选择和部署以及常用故障解决方案是怎么做的...
Hello,大家好,这是第七期 上云用户必看期刊,本期我们主打实用派的相关业务选择和部署以及一些常用故障解决方案做分享。 今天我们不平凡,成为实用派 运维工程师需要掌握的技能https://yq.aliyun.com/articles/591171?spma2c4e.11…
php基础知识
一:php变量#一、PHP的变量定义:变量用于存储值,比如数字、文本字符串或数组、五中:string /integer /double /array /object 命名规则:1、PHP的变量名是区分大小写的。 2、变量名必须以$开头 3、变量名开头可以是下划线 4、变量名…