【AI】caffe源码分析(一)
【一】caffe依赖开源库
【C++】google gflags详解
【C++】google glog详解
【C++】Google Protocol Buffer(protobuf)详解(一)
【C++】Google Protocol Buffer(protobuf)详解(二)
【C++】google gtest 详解
【二】基本模块分析
1、 Blob
Blob的维度:图像数量N x 通道数K x 图像高度H x 图像宽度W;
坐标为:(n, k, h, w),指定偏移的计算:((n*K+k)*H+h)*W+w;
主要成员变量:
protected:shared_ptr<SyncedMemory> data_; // 存储网络中传递的普通参数valuesshared_ptr<SyncedMemory> diff_; // 存储相对于自身的梯度误差gradientsshared_ptr<SyncedMemory> shape_data_; //vector<int> shape_; //维度表示,如:shape(0)=num; shape(1)=channels; shape(2)=height; shape(3)=widthint count_;int capacity_;
主要成员函数:
1) void Reshape(const vector& shape); //更改blob的大小,必要时分配新内存。
可以调用此函数来创建内存的初始分配,并在Layer:: rename或Layer::Forward期间调整顶部blob的大小。
当更改blob的大小时,只有在没有足够的内存时才会重新分配内存,并且永远不会释放多余的内存。
注意,重新构造输入blob并立即调用Net::Backward是一个错误;要将新的输入形状传播到更高的层,需要调用Net::Forward或Net::Reshape。
2) int shape(int index); //返回第index维度的大小(如果索引为负,则从末尾返回负index维度的大小)
3) int count(int start_axis, int end_axis) //计算切片的体积,一系列维度之间的尺寸乘积
4) int count(int start_axis) //计算从一个特定的维度到最后一个维度的切片的体积。
5) int offset(const int n, const int c = 0, const int h = 0, const int w = 0) //换算出第n个、第c通道、第h行、第w列的偏移量
6) int offset(const vector& indices) //将indices换算成偏移量(可以超出四维)
7) void CopyFrom(const Blob& source, bool copy_diff = false, bool reshape = false) //复制source Blob(最终调用memcpy)
参数说明:copy_diff=true,复制差值;reshape=true,改变本Blob成和source Blob相同的维度(形状),否则在本Blob和source Blob不同时,将会报错
8) Dtype data_at(const int n, const int c, const int h, const int w) //返回数据data指定位置的值
9) Dtype diff_at(const int n, const int c, const int h, const int w) //返回差分diff指定位置的值
10) Dtype data_at(const vector& index) //同上
11) Dtype diff_at(const vector& index) //同上
12) const shared_ptr& data() //返回数据指针
13) const shared_ptr& diff() //返回差分指针
14) void FromProto(const BlobProto& proto, bool reshape = true); //从proto中恢复Blob
15) void ToProto(BlobProto* proto, bool write_diff = false) const; //将Blob转换成proto
16) Dtype asum_data() const; //计算数据data绝对值(L1范数)的和。
17) Dtype asum_diff() const; //计算差diff的绝对值(L1范数)的和。
18) Dtype sumsq_data() const; //计算数据data的平方和(L2范数的平方)。
19) Dtype sumsq_diff() const; //计算差diff的平方和(L2范数的平方)。
20) void scale_data(Dtype scale_factor); //将blob数据data 缩放一个常数因子。
21) void scale_diff(Dtype scale_factor); //将blob差分diff 缩放一个常数因子。
22) void ShareData(const Blob& other); //将本Blob中的data_和shared_ptr指针指向other中的,在layer层中转发它们的副本时,很有用。
当shared_ptr在使用“=”操作符重置时调用析构函数时,它会释放保存这个Blob的data_的SyncedMemory。
23) void ShareDiff(const Blob& other); //参见上
24) bool ShapeEquals(const BlobProto& other); //判断维度是否相同
25)const Dtype* cpu_data() const;
26)void set_cpu_data(Dtype* data);
2、 Layer
主要成员变量:
protected:LayerParameter layer_param_; //存储层参数protobufPhase phase_; //阶段:训练 或者 测试vector<shared_ptr<Blob<Dtype> > > blobs_; //将可学习参数存储为一组blob的向量vector<bool> param_propagate_down_; //该向量用于指示是否计算每个参数blob的diff。vector<Dtype> loss_; //表示目标函数中每个顶部blob的权值是否为非零的向量
主要成员函数:
1) Layer(const LayerParameter& param) //不要自己实现构造函数,应该通过SetUp()函数来设置
2) void SetUp(const vector<Blob>& bottom, const vector<Blob>& top) //实现公共层设置功能。
bottom:预先输入的blobs;
top:分配但未成形的输出块,将通过整形来成形;
调用LayerSetUp为各个层类型执行特殊的层设置,然后进行重新塑形以设置顶部块和内部缓冲区的大小。为任何非零损耗权值设置损耗权乘法器blob。
此方法不可重写。
3) virtual void LayerSetUp(const vector<Blob>& bottom, const vector<Blob>& top) {} //执行特定于层的设置:您的层应该实现此功能以及重新塑造。
bottom:预压缩的输入块,其数据字段存储该层的输入数据
top:分配但未成形的输出块
此方法应一次性执行特定于层的设置。这包括从layer_param_读取和处理相关参数。
设置顶部blobs和内部缓冲区的形状应在 Reshape 中完成,该操作将在向前传播之前调用,以调整顶部blob的大小。
4) virtual void Reshape(const vector<Blob>& bottom, const vector<Blob>& top) = 0; //调整顶部blobs和内部缓冲器的形状(维度),以适应底部blobs的形状(维度)。
bottom:根据输入形状(维度)要求的输入blobs
top:根据需求的顶部blobs
这种方法应该根据底部(输入)blobs块的形状根据需要重新塑造顶部块,以及重新塑造任何内部缓冲区和进行任何其他必要的调整,以便该层可以容纳底部块。
5) Dtype Forward(const vector<Blob>& bottom, const vector<Blob>& top); //给定底部的blobs,计算顶部的blobs和损失。
bottom:输入块,其数据字段存储该层的输入数据
top:预压缩的输出块,其数据data字段将存储该层的输出
return:这一层的总损失。
Forward函数调用与设备相关的函数(Forward_cpu或Forward_gpu)来计算给定底部blob的顶部blob值。
如果该层有任何非零的loss_weights,那么Forward函数将计算并返回损耗。
自己实现的层应该实现Forward_cpu和Forward_gpu(可选)。
6) void Backward(const vector<Blob>& top, const vector& propagate_down, const vector<Blob>& bottom);
给定顶部的blob梯度误差,计算底部的blob梯度误差。
top:输出blobs,其diff字段存储相对于自身的梯度误差
propagate_down:与底部长度相等的向量,每个索引表示是否将梯度误差向下传播到对应索引处的底部blob
bottom:输入blobs,其diff字段存储向后传播Backward时相对于自身的梯度误差
Backward函数调用与设备相关的函数(Backward_cpu或Backward_gpu)来计算给定顶部blob差异的底部blob差异。
自己实现的层应该实现Backward_cpu和Backward_gpu(可选)。
7) vector<shared_ptr<Blob > >& blobs() {return blobs_;} //返回可学习参数blob的向量。
8) const LayerParameter& layer_param() const { return layer_param_; } //返回层参数
9) virtual void ToProto(LayerParameter* param, bool write_diff = false);//将层参数写入协议缓冲区protocol
10) Dtype loss(const int top_index) //返回给定索引处与顶部blob关联的标量损失。
11) void set_loss(const int top_index, const Dtype value) //设置给定索引处与顶部blob关联的损失。
12) virtual inline int ExactNumBottomBlobs() const { return -1; } //返回该层所需的底部blobs的确切数目,如果不需要确切数目,则返回-1. 如果需要,则应重写此方法以返回非负值。
13) virtual inline int MinBottomBlobs() const { return -1; } //返回底部blobs最小数量
14) virtual inline int MaxBottomBlobs() const { return -1; } //返回底部blobs最大数量
15) virtual inline int ExactNumTopBlobs() const { return -1; } //返回顶部blobs的确切数量
16) virtual inline int MinTopBlobs() const { return -1; } //返回顶部blobs最小数量
17) virtual inline int MaxTopBlobs() const { return -1; } //返回顶部blobs最大数量
18) virtual inline bool EqualNumBottomTopBlobs() const { return false; } //顶部blobs和底部blobs的数量是否相同
19) virtual inline bool AutoTopBlobs() const { return false; } //返回该层是否自动创建“匿名”顶块top blobs。
如果这个方法返回true, Net::Init将创建足够的“匿名”top blob来满足ExactNumTopBlobs()或MinTopBlobs()指定的需求。
20) virtual inline bool AllowForceBackward(const int bottom_index) const { return true; } //返回是否允许对给定的底部blob索引使用force_backwards。
如果If AllowForceBackward(i) == false, 我们将忽略force_back设置,仅当它需要梯度信息时才将其反向传播到blob i(当force_backer_= = false时就是这样做的)。
21) bool param_propagate_down(const int param_id)
//指定该层是否应该计算特定引索param_id处的梯度 w.r.t。* ;您可以安全地忽略假false值,并始终为所有参数计算梯度,但可能会造成计算的浪费。
22) void set_param_propagate_down(const int param_id, const bool value)
//设置该层是否应该计算param_id处梯度w.r.t。
3、 Net
主要成员变量:
protected:string name_; //网络名Phase phase_; //阶段:训练或者测试(TRAIN or TEST)vector<shared_ptr<Layer<Dtype> > > layers_; //网络中的各个层vector<string> layer_names_;map<string, int> layer_names_index_;vector<bool> layer_need_backward_;vector<shared_ptr<Blob<Dtype> > > blobs_; //在层之间存储中间结果的块。vector<string> blob_names_;map<string, int> blob_names_index_;vector<bool> blob_need_backward_;vector<vector<Blob<Dtype>*> > bottom_vecs_; //bottom_vecs存储包含每个层输入的向量。它们并不是这些团块的宿主,所以我们只存储指针。vector<vector<int> > bottom_id_vecs_;vector<vector<bool> > bottom_need_backward_;vector<vector<Blob<Dtype>*> > top_vecs_; //top_vecs存储包含每个层输出的向量vector<vector<int> > top_id_vecs_;vector<Dtype> blob_loss_weights_; //每个网络blob的损失(或目标)函数中的权重向量,由blob_id索引vector<vector<int> > param_id_vecs_;vector<int> param_owners_;vector<string> param_display_names_;vector<pair<int, int> > param_layer_indices_;map<string, int> param_names_index_;vector<int> net_input_blob_indices_; //blob索引用于网络的输入和输出vector<int> net_output_blob_indices_;vector<Blob<Dtype>*> net_input_blobs_;vector<Blob<Dtype>*> net_output_blobs_;vector<shared_ptr<Blob<Dtype> > > params_; //网络中的参数。vector<Blob<Dtype>*> learnable_params_;/*** The mapping from params_ -> learnable_params_: we have learnable_param_ids_.size() == params_.size(), and learnable_params_[learnable_param_ids_[i]] == params_[i].get() if and only if params_[i] is an "owner"; otherwise, params_[i] is a sharer and learnable_params_[learnable_param_ids_[i]] gives its owner.*/vector<int> learnable_param_ids_;vector<float> params_lr_; //学习速率因子,和learnable_params_一起使用vector<bool> has_params_lr_;vector<float> params_weight_decay_; //权重衰减因子,和learnable_params_一起使用vector<bool> has_params_decay_;size_t memory_used_; //这个网络使用的内存字节bool debug_info_; //是否为网络计算和显示调试信息。// Callbacks回调函数vector<Callback*> before_forward_;vector<Callback*> after_forward_;vector<Callback*> before_backward_;vector<Callback*> after_backward_;
主要成员函数:
1) void Init(const NetParameter& param); //使用NetParameter初始化网络
2) const vector<Blob>& Forward(Dtype loss = NULL); 向前运行并返回结果。
3) Dtype ForwardFromTo(int start, int end);
4) Dtype ForwardFrom(int start);
5) Dtype ForwardTo(int end);
// 前向和后向的From和To变体按指定网络的(拓扑)顺序操作。
// 对于一般的DAG网络,请注意(1)从一个层到另一个层的计算可能需要在不相关的分支上进行额外的计算;(2)如果所有层不包含fan-in,则从中间开始的计算可能是不正确的。
6) void ClearParamDiffs(); //将所有网络参数的差异归零。应该在向后运行Backward之前运行。
7) void Backward(); //反向网络不需要输入和输出,因为它只计算梯度w.r。t参数,数据已在转发过程中提供。
void BackwardFromTo(int start, int end);
void BackwardFrom(int start);
void BackwardTo(int end);
8) void Reshape(); //从底部到顶部重新塑造所有图层。这对于将更改传播到层大小而不运行前向传递非常有用,例如计算输出特性大小。
9) void Update(); //根据计算的差异值更新网络权重。
10) void ShareWeights(); //与共享的blob共享所有者blob的权重数据。注意:这是由Net::Init调用的,因此通常不应手动调用。
11) void ShareTrainedLayersWith(const Net* other); //对于已初始化的网络,隐式复制(即(不使用额外内存)来自另一个网络的预训练层。
12)void CopyTrainedLayersFrom(const NetParameter& param); //对于已经初始化的网络,CopyTrainedLayersFrom()从另一个net参数实例复制已经训练好的层。
void CopyTrainedLayersFrom(const string& trained_filename);
void CopyTrainedLayersFromBinaryProto(const string& trained_filename);
void CopyTrainedLayersFromHDF5(const string& trained_filename);
13)void ToProto(NetParameter* param, bool write_diff = false) const; //将网络写入原型proto。
14)void ToHDF5(const string& filename, bool write_diff = false) const; //将网络写入HDF5文件。
15)返回成员变量的值
inline const string& name() const { return name_; } // 返回网络名称。
inline const vector& layer_names() const { return layer_names_; } // 返回层名称
inline const vector& blob_names() const { return blob_names_; } // 返回blob名称
inline const vector<shared_ptr<Blob > >& blobs() const { return blobs_; } //返回blobs
inline const vector<shared_ptr<Layer > >& layers() const { return layers_; } //返回层layers
inline Phase phase() const { return phase_; } //返回阶段:训练或测试TRAIN or TEST
inline const vector<shared_ptr<Blob > >& params() const { return params_; } //返回参数
inline const vector<Blob>& learnable_params() const { return learnable_params_; } //返回学习参数
inline const vector& params_lr() const { return params_lr_; } //返回学习速率因子
inline const vector& has_params_lr() const { return has_params_lr_; }
inline const vector& params_weight_decay() const { return params_weight_decay_; } //返回可学习参数衰减乘法器
inline const vector& has_params_decay() const { return has_params_decay_; }
const map<string, int>& param_names_index() const { return param_names_index_; }
inline const vector& param_owners() const { return param_owners_; }
inline const vector& param_display_names() const { return param_display_names_; }
inline int num_inputs() const { return net_input_blobs_.size(); } 输入和输出blob数
inline int num_outputs() const { return net_output_blobs_.size(); }
inline const vector<Blob>& input_blobs() const { return net_input_blobs_; }
inline const vector<Blob*>& output_blobs() const { return net_output_blobs_; }
inline const vector& input_blob_indices() const { return net_input_blob_indices_; }
inline const vector& output_blob_indices() const { return net_output_blob_indices_; }
inline const vector<vector<Blob> >& bottom_vecs() const { return bottom_vecs_; } //返回每一层的底部向量(通常不需要这样做,除非您对每一层进行诸如渐变之类的检查)。
inline const vector<vector<Blob> >& top_vecs() const { return top_vecs_; } //返回每一层的顶部向量——通常不需要这样做,除非您对每一层进行诸如渐变之类的检查。
16)inline const vector & top_ids(int i) //返回第i层的顶部块top blobs的id
inline const vector & bottom_ids(int i) //返回第i层底部块bottom blobs 的id
17)static void FilterNet(const NetParameter& param, NetParameter* param_filtered); //删除用户指定的层,除了当前阶段、级别和阶段
18)static bool StateMeetsRule(const NetState& state, const NetStateRule& rule, const string& layer_name); //返回NetState状态是否满足NetStateRule规则
4、 Solver
主要成员变量:
protected:SolverParameter param_;int iter_;int current_step_;shared_ptr<Net<Dtype> > net_;vector<shared_ptr<Net<Dtype> > > test_nets_;vector<Callback*> callbacks_;vector<Dtype> losses_;Dtype smoothed_loss_;ActionCallback action_request_function_; //由求解程序的客户端设置的一个函数,该函数提供它希望保存快照和/或提前退出的指示。bool requested_early_exit_; //如果收到提前停止的请求,则为真。Timer iteration_timer_; //定时信息,便于调整,如nbr的gpufloat iterations_last_;
主要成员函数:
1) 初始化
void Init(const SolverParameter& param);
void InitTrainNet();
void InitTestNets();
2)void SetActionFunction(ActionCallback func); //求解器的客户端可以选择性地调用这个函数,以便设置求解器用来查看应该采取什么操作的函数(例如快照或提前退出培训)。
SolverAction::Enum GetRequestedAction();
3)virtual void Solve(const char* resume_file = NULL); //求解器函数的主要入口。默认情况下,iter为零。输入一个非零的iter数字,为一个预先训练过的网络恢复训练。
inline void Solve(const string& resume_file) { Solve(resume_file.c_str()); }
void Step(int iters);
4)void Restore(const char* resume_file); //还原方法简单地将数据分派给RestoreSolverStateFrom___ (protected方法)。您应该实现这些方法来从适当的快照类型恢复状态。
5)void Snapshot(); //Solver::Snapshot函数实现了存储学习网络的基本快照实用程序。您应该实现SnapshotSolverState()函数,该函数生成一个SolverState协议缓冲区,该缓冲区需要与所学习的网络一起写入磁盘。
5、解码器solver注册和使用SolverRegistry SolverRegisterer
6、 层注册和使用 LayerRegisterer LayerRegistry
6.1 宏定义:
#define REGISTER_LAYER_CREATOR(type, creator) \static LayerRegisterer<float> g_creator_f_##type(#type, creator<float>); \static LayerRegisterer<double> g_creator_d_##type(#type, creator<double>) \
#define REGISTER_LAYER_CLASS(type) \template <typename Dtype> \shared_ptr<Layer<Dtype> > Creator_##type##Layer(const LayerParameter& param) \{ \return shared_ptr<Layer<Dtype> >(new type##Layer<Dtype>(param)); \} \REGISTER_LAYER_CREATOR(type, Creator_##type##Layer)#define INSTANTIATE_CLASS(classname) \char gInstantiationGuard##classname; \template class classname<float>; \template class classname<double>
6.2 宏使用例子
以 DataLayer 为例
源码:
INSTANTIATE_CLASS(DataLayer);REGISTER_LAYER_CLASS(Data);
展开:
char gInstantiationGuardDataLayer; \template class DataLayer<float>; \template class DataLayer<double>template <typename Dtype> shared_ptr<Layer<Dtype> > Creator_DataLayer(const LayerParameter& param) { return shared_ptr<Layer<Dtype> >(new DataLayer<Dtype>(param)); } // 创建LayerRegisterer<float>静态实例g_creator_f_Data,构造函数的参数:"Data", Creator_DataLayer<float>static LayerRegisterer<float> g_creator_f_Data("Data", Creator_DataLayer<float>); static LayerRegisterer<double> g_creator_d_Data("Data", Creator_DataLayer<double>)
6.3 LayerRegisterer 类,实现上面用的构造函数
template <typename Dtype>class LayerRegisterer {public:LayerRegisterer(const string& type, shared_ptr<Layer<Dtype> > (*creator)(const LayerParameter&)) {LayerRegistry<Dtype>::AddCreator(type, creator);}};
6.4 LayerRegistry::AddCreator(type, creator);的实现
static void AddCreator(const string& type, Creator creator) {CreatorRegistry& registry = Registry();CHECK_EQ(registry.count(type), 0) << "Layer type " << type << " already registered.";registry[type] = creator;}
6.5 静态函数 Registry() 实现单例模式,返回静态全局 g_registry_
static CreatorRegistry& Registry() {static CreatorRegistry* g_registry_ = new CreatorRegistry();return *g_registry_;}
6.6 CreatorRegistry的定义
typedef shared_ptr<Layer<Dtype> > (*Creator)(const LayerParameter&);typedef std::map<string, Creator> CreatorRegistry;
6.7 registry[type] = creator; 说明
registry 的类型是 CreatorRegistry --> typedef std::map<string, Creator> CreatorRegistry;
是一个std::map类型,而std::map类型对“[]”运算符重载了:创建键值对 type --> creator
至此成功注册了 DataLayer 类到 g_registry_ 中。
6.8 何时创建 DataLayer,在 LayerRegistry::CreateLayer 函数中
static shared_ptr<Layer<Dtype> > CreateLayer(const LayerParameter& param) {if (Caffe::root_solver()) {LOG(INFO) << "Creating layer " << param.name();}const string& type = param.type();CreatorRegistry& registry = Registry();CHECK_EQ(registry.count(type), 1) << "Unknown layer type: " << type << " (known types: " << LayerTypeListString() << ")";return registry[type](param);}
根据 LayerParameter 中的 type 字段(这里是Data)找到,上面注册的 Creator_DataLayer 函数并执行,使用参数 param,创建 DataLayer
6.9 何时调用 LayerRegistry::CreateLayer
在 Net 的构造函数中调用 Init(const NetParameter& param) 时,循环调用了 LayerRegistry::CreateLayer layers_.push_back(LayerRegistry::CreateLayer(layer_param));
如果 layer_param 参数 type() = “Data”,则会创建 DataLayer 层
6.10 layer_param 从 param 中来,param从哪来的
train() 中 caffe::ReadSolverParamsFromTextFileOrDie(FLAGS_solver, &solver_param); 将*solver.prototxt 读取到求解器参数 caffe::SolverParameter solver_param 中,
然后调用 SolverRegistry::CreateSolver(solver_param),使用求解器参数 solver_param 创建求解器 Solver
在求解器 Solver 构造函数中调用 Init(param); --> InitTrainNet();
在 InitTrainNet() 中 将 SolverParameter::net 指定的 *train_test.prototxt 文件读取到网络参数 NetParameter net_param 中:ReadNetParamsFromTextFileOrDie(param.net(), &net_param);
然后使用网络参数 net_param 创建网络:net_.reset(new Net(net_param));
7、 读取 *_solver.prototxt 和 *_train_test.prototxt :
7.1 ReadSolverParamsFromTextFileOrDie
void ReadSolverParamsFromTextFileOrDie(const string& param_file, SolverParameter* param) {CHECK(ReadProtoFromTextFile(param_file, param)) << "Failed to parse SolverParameter file: " << param_file;UpgradeSolverAsNeeded(param_file, param);UpgradeSnapshotPrefixProperty(param_file, param);
}
其中 ReadProtoFromTextFile的源码如下
bool ReadProtoFromTextFile(const char* filename, Message* proto) {int fd = open(filename, O_RDONLY);CHECK_NE(fd, -1) << "File not found: " << filename;FileInputStream* input = new FileInputStream(fd);bool success = google::protobuf::TextFormat::Parse(input, proto);delete input;close(fd);return success;
}
7.2 ReadNetParamsFromTextFileOrDie
void ReadNetParamsFromTextFileOrDie(const string& param_file, NetParameter* param) {CHECK(ReadProtoFromTextFile(param_file, param)) << "Failed to parse NetParameter file: " << param_file;UpgradeNetAsNeeded(param_file, param);
}
8、 序列化 *.caffemodel
以 void Solver::Snapshot(); 中序列化为例
8.1 Snapshot 序列化
template <typename Dtype>
void Solver<Dtype>::Snapshot() { // 检查当前是否是root_solver(多GPU模式下,只有root_solver才运行这一部分的代码)CHECK(Caffe::root_solver());// 根据 solver.prototxt 文件中 snapshot_format 字段(默认值是 BINARYPROTO),将proto序列化为二进制格式或者HDF5格式string model_filename;switch (param_.snapshot_format()) {case caffe::SolverParameter_SnapshotFormat_BINARYPROTO:model_filename = SnapshotToBinaryProto();break;case caffe::SolverParameter_SnapshotFormat_HDF5:model_filename = SnapshotToHDF5();break;default:LOG(FATAL) << "Unsupported snapshot format.";}SnapshotSolverState(model_filename);
}
8.2 以序列化为二进制格式为例 SnapshotToBinaryProto
template <typename Dtype>
string Solver<Dtype>::SnapshotToBinaryProto() {string model_filename = SnapshotFilename(".caffemodel"); // 生成文件名LOG(INFO) << "Snapshotting to binary proto file " << model_filename;NetParameter net_param;net_->ToProto(&net_param, param_.snapshot_diff()); // 递归获取网络参数WriteProtoToBinaryFile(net_param, model_filename); // 将网络参数序列化到二进制文件中return model_filename;
}void WriteProtoToBinaryFile(const Message& proto, const char* filename) {fstream output(filename, ios::out | ios::trunc | ios::binary);CHECK(proto.SerializeToOstream(&output)); // 原型bool Message::SerializeToOstream(ostream* output) const; // 将 Message 序列化到c++标准输出流中,必须设置所有必需字段。
}
8.3 序列化函数汇总
bool SerializeToFileDescriptor(int file_descriptor) const; // 将 Message 序列化到文件描述符中,必须设置所有必需字段。bool SerializePartialToFileDescriptor(int file_descriptor) const; // 同上,但是允许缺少必需的字段。bool SerializeToOstream(ostream* output) const; // 将 Message 序列化到c++标准输出流中,必须设置所有必需字段。bool SerializePartialToOstream(ostream* output) const; // 同上,但是允许缺少必需的字段。
9、 反序列化 *.caffemodel
以void Solver::Restore(const char* resume_file); 反序列化为例
9.1 Restore反序列化
template <typename Dtype>
void Solver<Dtype>::Restore(const char* state_file) {string state_filename(state_file);if (state_filename.size() >= 3 && state_filename.compare(state_filename.size() - 3, 3, ".h5") == 0) {RestoreSolverStateFromHDF5(state_filename);} else {RestoreSolverStateFromBinaryProto(state_filename);}
}
9.2 以反序列化二进制文件为例 RestoreSolverStateFromBinaryProto
emplate <typename Dtype>
void SGDSolver<Dtype>::RestoreSolverStateFromBinaryProto(const string& state_file) {SolverState state;ReadProtoFromBinaryFile(state_file, &state);this->iter_ = state.iter();if (state.has_learned_net()) {NetParameter net_param;ReadNetParamsFromBinaryFileOrDie(state.learned_net().c_str(), &net_param);this->net_->CopyTrainedLayersFrom(net_param);}this->current_step_ = state.current_step();CHECK_EQ(state.history_size(), history_.size()) << "Incorrect length of history blobs.";LOG(INFO) << "SGDSolver: restoring history";for (int i = 0; i < history_.size(); ++i) {history_[i]->FromProto(state.history(i));}
}bool ReadProtoFromBinaryFile(const char* filename, Message* proto) {int fd = open(filename, O_RDONLY);CHECK_NE(fd, -1) << "File not found: " << filename;ZeroCopyInputStream* raw_input = new FileInputStream(fd);CodedInputStream* coded_input = new CodedInputStream(raw_input);coded_input->SetTotalBytesLimit(kProtoReadBytesLimit, 536870912);bool success = proto->ParseFromCodedStream(coded_input); // 原型 bool ParseFromCodedStream(io::CodedInputStream* input);delete coded_input;delete raw_input;close(fd);return success;
}
9.3 其它反序列化函数
bool ParsePartialFromCodedStream(io::CodedInputStream* input); // 同 ParseFromCodedStream ,但是接受缺少必需字段的消息。bool ParseFromZeroCopyStream(io::ZeroCopyInputStream* input); // 从 io::ZeroCopyInputStream 流中获取bool ParsePartialFromZeroCopyStream(io::ZeroCopyInputStream* input); // 同上,但是接受缺少必需字段的消息。bool ParseFromBoundedZeroCopyStream(io::ZeroCopyInputStream* input, int size); // 同上,指定 message 大小必须是 sizebool ParsePartialFromBoundedZeroCopyStream(io::ZeroCopyInputStream* input, , int size); // 同上,但是接受缺少必需字段的消息。
相关文章:

专访博世王红星:大数据和AI将是中国制造业升级新动力
数据分析挖掘与工业大数据是智能制造与工业互联网的核心,其本质是通过促进数据的自动流动与智能决策去解决控制和业务问题,有效减少决策过程所带来的不确定性,并尽量克服人工决策的缺点,从而推动智能制造进程与智能工厂的建设&…

C进阶 - 内存四驱模型
一.内存四驱模型 不知我们是否有读过 《深入理解 java 虚拟机》这本书,强烈推荐读一下。在 java 中我们将运行时数据,分为五个区域分别是:程序计数器,java 虚拟机栈,本地方法栈,java 堆,方法区。…

ATEN—第十章OSPF的高级配置(4)
实验使用的工具:小凡模拟器一、在路由器R1上,配置接口,启动ospf路由进程和rip,宣告网段,并配置路由重分发★☆R1☆★☆→Router>Router>enableRouter#config terminalRouter(config)#hostname R1-jinR1-jin(config)#interfa…
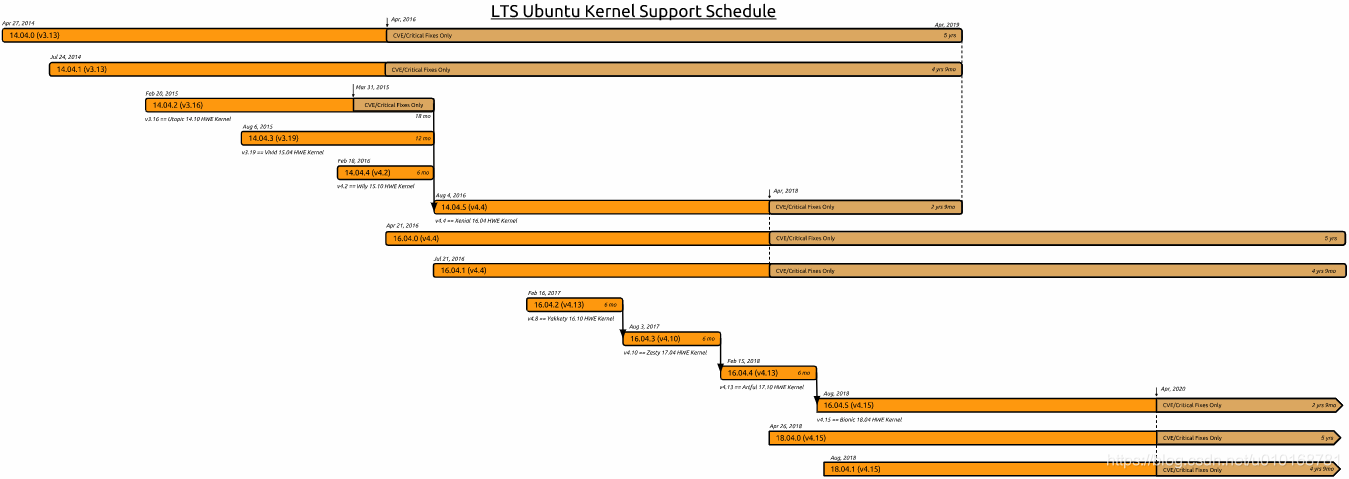
【ubuntu】ubuntu14.04、16.04、18.04 LTS版本支持时间
0、历史版本下载地址 http://old-releases.ubuntu.com/releases/ http://mirrors.163.com/ubuntu-releases/ 1、官网说明 https://wiki.ubuntu.com/Kernel/LTSEnablementStack 2、简要记录 如下图: 14.04.0(v3.13) 14.04.1(v3.13) 14.04.5(v4.4) LTS 支持至 20…

BERT拿下最佳长论文奖!NAACL 2019最佳论文奖公布
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑作者 | 刘静编辑 | 李尔客本文经授权转自公众号图灵Topia(ID:turingtopia)今日,自然语言处理顶会NAACL 2019最佳论文奖公布ÿ…
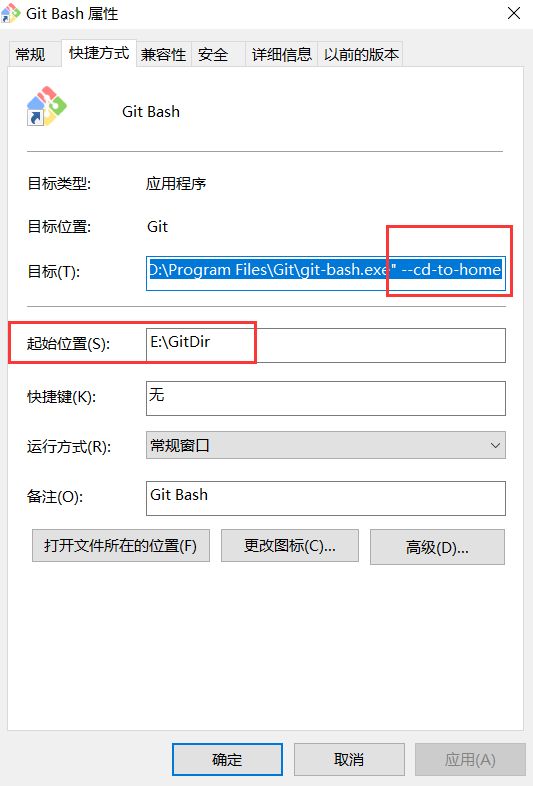
Git Bash修改默认路径
Git Bash默认安装在C:/user目录下,如果管理其他目录的代码库,需要切换目录。 修改Git Bash的默认路径,不需要每次切换了。 方法: 桌面Git Bash快捷方式,右键-->属性-->“快捷方式”标签 1,修改“起止…

NextGEN Gallery ~ 最强WordPress相册插件
博客照片很多?上传和管理图片太烦?想幻灯显示相册?在博客中任意插入动态图片效果?…… 你和我一样,需要NextGEN Gallery,最强WordPress相册插件! 其实网上可以搜到不少关于这个插件的介绍&#…
【经验】网络加速:pip
一、python pip下载加速 参考博客:让PIP源使用国内镜像,提升下载速度和安装成功率。 pip/anaconda修改镜像源,加快python模块安装速度 1、Linux下 修改 ~/.pip/pip.conf (没有就创建一个文件夹及文件。文件夹要加“.”,表示是隐…
iframe 有那些缺
*iframe 会阻塞主页面的 Onload 事 *iframe 和主页面共享连接池,而浏览器对相同域的连接有限制(6-8前),所以会影响页面的并行加 使用 iframe 之前需要考虑这两个缺点。如果需要使用 iframe,最通过 javascrit 动态给 iframe 添加 src 属性值&a…
用Python让蔡徐坤在我的命令行里打篮球!|附完整代码
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑来源 | 01二进制(ID:gh_d1999add1857)编辑 | Jane【导语】作者自称是一个经常逛 B 站的肥宅。最近 B 站上流行的视频素材除了“换脸”,其次就要属…
javascript 操作Word和Excel的实现代码
1.保存html页面到word 复制代码 代码如下:<HTML> <HEAD> <title> </title> </HEAD> <body> <form id"form"> <table id "PrintA" width"100%" border"1" cellspacing"0" cel…
【C++】C++11新增关键字详解
目录一、auto1、auto 用来声明自动变量,表明变量存储在栈(C11之前)2、auto用于推断变量类型示例(C11)3、声明或定义函数时作为函数返回值的占位符,此时需要与关键字 decltype 一起使用。(C11&am…
linux批量创建用户和密码
老男孩教育第五关实战考试题:批量创建10个用户stu01-stu10,并且设置随机8位密码,要求不能用shell的循环(例如:for,while等),只能用linux命令及管道实现。 方法1:[rootoldboy /]# ech…
“重构”黑洞:26岁MIT研究生的新算法 | 人物志
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑整理 | 若名出品 | AI科技大本营(ID:rgznai100)这是一个重要时刻。除了发布跟丈夫的两张合照外,Katie Bouman 在 Facebook 上鲜有内容更新&#…

【Ubuntu】VirtualBox显卡驱动VBoxVGA、VBoxSVGA、VMSVGA +3D对播放视频的影响
一、VBOXVGA、VMSVGA、VBOXSVGA简述 VBOXVGA和VBOXSVGA是vbox自己的,SVGA比VGA先进一点, VBoxSVGA: 使用Linux或者 Windows 7或者更高版本的新vm的默认图形控制器。 与传统的VBoxVGA选项相比,此图形控制器可提高性能和3D支持。 VBoxVGA: 将这…

MFC中利用CFileDialog选择文件并读取文件所遇到的问题和解决方法
在用MFC编写一个上位机时,需要实现选择和读取一个二进制文件,本来以为很简单的但是在实现过程中遇到很多问题,所幸都一一解决,这里做一下记录。 首先在实现文件选择,在界面上设置一个按钮,并在点击事件函数…

百度智能云一口气发布 14 个新产品,三大视频解决方案,产品最高降价 50%
产业智能化的浪潮正在加速传统互联网行业的升级,视频行业将成为最大的受益者。4 月 11 日,在 2019ABC INSPIRE 百度云智峰会上,百度副总裁、百度智能云总经理尹世明宣布,“百度云” 品牌全面升级为 “百度智能云”,以 …

开源代码hosting openfoundryfrom tw
http://www.openfoundry.org

倒计时1天!「2019 Python开发者日」报名即将关闭(附参会提醒)
「2019 Python开发者日」倒计时最后1天,仅剩少量余票,请扫码咨询 ↑↑↑相信很多人听过之前的 Python 进入小学课本、Python 进入浙江省高考等新闻,那么,有这么多头衔加持的 Python 究竟魅力在哪?与人工智能、大数据捆…
【Gstreamer】在虚拟机中无法使用硬件加速:gstreamer1.0-vaapi
1、问题描述 在虚拟机中,使用gstreamer播放视频,在没有安装gstreamer1.0-vaapi库时,还是正常的;在安装gstreamer1.0-vaapi后,不能播放视频。 错误信息如下: libva info: VA-API version 0.39.0 libva info: va_getDriverName() returns -1 libva error: va_getDriverNa…

如何在阿里云上安全的存放您的配置 - 续
在《如何在阿里云上安全的存放您的配置》一文中,我们介绍了如何通过ACM存放您的敏感配置,并进行加密。这样做的目的有两个: 在应用程序或对应生产环境容器或系统中,无需持久化任何敏感数据信息(如数据库连接串,等)&…
VLAN-VTP-Trunk
VLAN(Virtual LAN) VLAN可以隔离2层的广播域。A VLAN =(一个) 广播域 = (一个)逻辑子网路由器是隔离广播域的单个端口只能承载单个VLAN的流量。使用VLAN好处:1.有效的带宽利用2.提高了安全性3…
科大讯飞刷新纪录,机器阅读理解如何超越人类平均水平? | 技术头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」明日开启,扫码咨询 ↑↑↑记者 | 琥珀出品 | AI科技大本营(公众号ID:rgznai100)对于日常从事模型训练的研究人员来讲,无论是图像处理还是语音识别,都离…
【经验】Lenovo/ThinkPad 进入BIOS的方法汇总
1、快捷汇总 联想电脑进入BIOS的快捷键有“F2、F1、Del/Delete、NOVO开机”,部分机型按F2、F1时需要FN键配合 2、常用键 Lenovo笔记本:F2 Fn Lenovo台式机:F2 ThinkPad:F1 联系官网说明: http://tsonline.lenovo.…
NO.7 今天我们是实用派,看看业务选择和部署以及常用故障解决方案是怎么做的...
Hello,大家好,这是第七期 上云用户必看期刊,本期我们主打实用派的相关业务选择和部署以及一些常用故障解决方案做分享。 今天我们不平凡,成为实用派 运维工程师需要掌握的技能https://yq.aliyun.com/articles/591171?spma2c4e.11…
php基础知识
一:php变量#一、PHP的变量定义:变量用于存储值,比如数字、文本字符串或数组、五中:string /integer /double /array /object 命名规则:1、PHP的变量名是区分大小写的。 2、变量名必须以$开头 3、变量名开头可以是下划线 4、变量名…
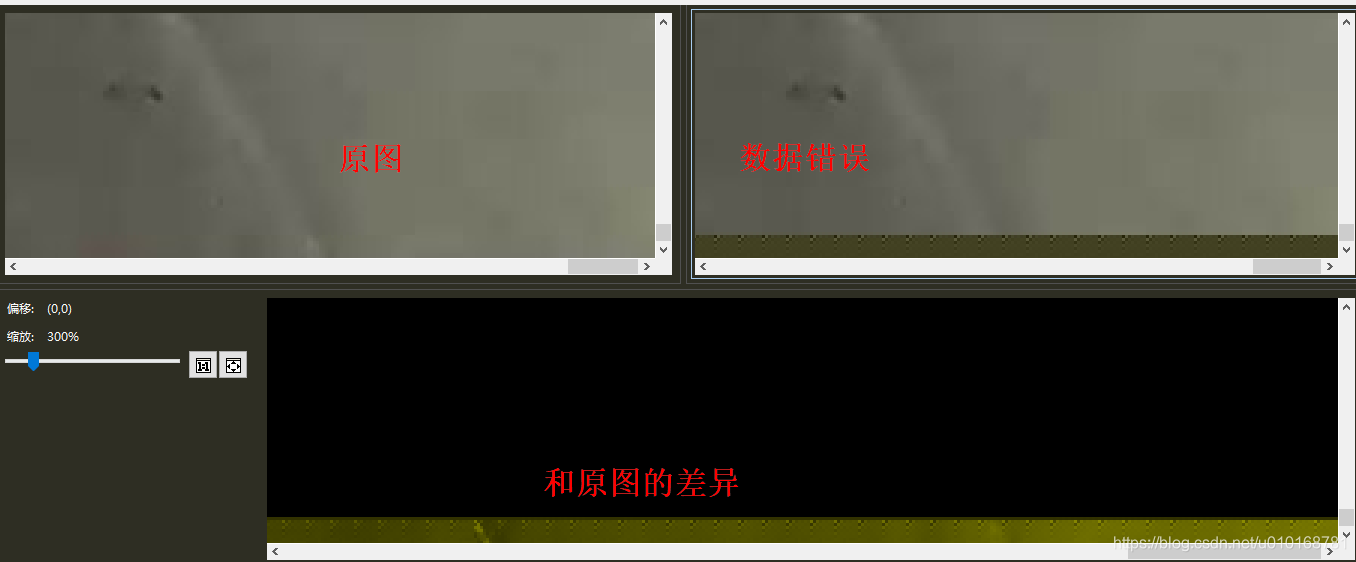
【Qt】QPixmap加载图片报错:Corrupt JPEG data: premature end of data segment Didn‘t expect more than one scan
1、问题描述 在使用QPixmap加载图片时失败,错误信息如下 Corrupt JPEG data: premature end of data segment Didnt expect more than one scan使用QPicture加载时错误信息如下: QPicturePaintEngine::checkFormat: Incorrect header QPicturePaintEng…
Python超越Java,Rust持续称王!Stack Overflow 2019开发者报告
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」明日开启,扫码咨询 ↑↑↑作者 | 郭芮出品 | CSDN(ID:CSDNnews)导语:2019 年 Stack Overflow 开发者调查报告最新出炉了!今年,近 90,000 名…

electron打包可选择安装位置,可自动更新
Electron打包调参软件(windows版) ----------------------------------可选安装位置,可自动更新,手动更新 一:引包:electron,electron-builder,electron-updater** npm i electron --save-dev n…
osi 模型 tcpip网络模型
OSI网络分层参考模型 网络协议设计者不应当设计一个单一、巨大的协议来为所有形式的通信规定完整的细节,而应把通信问题划分成多个 小问题,然后为每一个小问题设计一个单独的协议。这样做使得每个协议的设计、分析、时限和测试比较容易。协议划分的一…