速度提升270倍!微软和浙大联合推出全新语音合成系统FastSpeech

作者 | 谭旭
转载自微软研究院AI头条(ID: MSRAsia)
【编者按】目前,基于神经网络的端到端文本到语音合成技术发展迅速,但仍面临不少问题——合成速度慢、稳定性差、可控性缺乏等。为此,微软亚洲研究院机器学习组和微软(亚洲)互联网工程院语音团队联合浙江大学提出了一种基于Transformer的新型前馈网络FastSpeech,兼具快速、鲁棒、可控等特点。与自回归的Transformer TTS相比,FastSpeech将梅尔谱的生成速度提高了近270倍,将端到端语音合成速度提高了38倍,单GPU上的语音合成速度达到了实时语音速度的30倍。
近年来,基于神经网络的端到端文本到语音合成(Text-to-Speech,TTS)技术取了快速发展。与传统语音合成中的拼接法(concatenative synthesis)和参数法(statistical parametric synthesis)相比,端到端语音合成技术生成的声音通常具有更好的声音自然度。但是,这种技术依然面临以下几个问题:
合成语音的速度较慢:端到端模型通常以自回归(Autoregressive)的方式生成梅尔谱(Mel-Spectrogram),再通过声码器(Vocoder)合成语音,而一段语音的梅尔谱通常能到几百上千帧,导致合成速度较慢;
合成的语音稳定性较差:端到端模型通常采用编码器-注意力-解码器(Encoder-Attention-Decoder)机制进行自回归生成,由于序列生成的错误传播(Error Propagation)以及注意力对齐不准,导致出现重复吐词或漏词现象;
缺乏可控性:自回归的神经网络模型自动决定一条语音的生成长度,无法显式地控制生成语音的语速或者韵律停顿等。
为了解决上述的一系列问题,微软亚洲研究院机器学习组和微软(亚洲)互联网工程院语音团队联合浙江大学提出了一种基于Transformer的新型前馈网络FastSpeech,可以并行、稳定、可控地生成高质量的梅尔谱,再借助声码器并行地合成声音。
在LJSpeech数据集上的实验表明,FastSpeech除了在语音质量方面可以与传统端到端自回归模型(如Tacotron2和Transformer TTS)相媲美,还具有以下几点优势:
快速:与自回归的Transformer TTS相比,FastSpeech将梅尔谱的生成速度提高了近270倍,将端到端语音合成速度提高了近38倍,单GPU上的语音合成速度是实时语音速度的30倍;
鲁棒:几乎完全消除了合成语音中重复吐词和漏词问题;
可控:可以平滑地调整语音速度和控制停顿以部分提升韵律。
模型框架
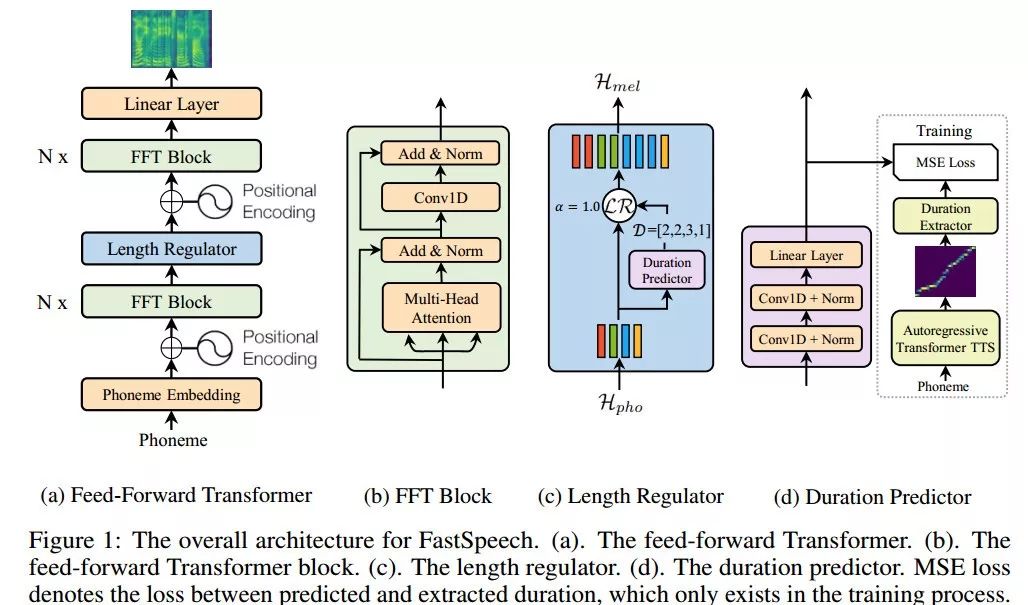
图1. FastSpeech网络架构
前馈Transformer架构
FastSpeech采用一种新型的前馈Transformer网络架构,抛弃掉传统的编码器-注意力-解码器机制,如图1(a)所示。其主要模块采用Transformer的自注意力机制(Self-Attention)以及一维卷积网络(1D Convolution),我们将其称之为FFT块(Feed-Forward Transformer Block, FFT Block),如图1(b)所示。前馈Transformer堆叠多个FFT块,用于音素(Phoneme)到梅尔谱变换,音素侧和梅尔谱侧各有N个FFT块。特别注意的是,中间有一个长度调节器(Length Regulator),用来调节音素序列和梅尔谱序列之间的长度差异。
长度调节器
长度调节器如图1(c)所示。由于音素序列的长度通常小于其梅尔谱序列的长度,即每个音素对应于几个梅尔谱序列,我们将每个音素对齐的梅尔谱序列的长度称为音素持续时间。长度调节器通过每个音素的持续时间将音素序列平铺以匹配到梅尔谱序列的长度。我们可以等比例地延长或者缩短音素的持续时间,用于声音速度的控制。此外,我们还可以通过调整句子中空格字符的持续时间来控制单词之间的停顿,从而调整声音的部分韵律。
音素持续时间预测器
音素持续时间预测对长度调节器来说非常重要。如图1(d)所示,音素持续时间预测器包括一个2层一维卷积网络,以及叠加一个线性层输出标量用以预测音素的持续时间。这个模块堆叠在音素侧的FFT块之上,使用均方误差(MSE)作为损失函数,与FastSpeech模型协同训练。我们的音素持续时间的真实标签信息是从一个额外的基于自回归的Transformer TTS模型中抽取encoder-decoder之间的注意力对齐信息得到的,详细信息可查阅文末论文。
实验评估
为了验证FastSpeech模型的有效性,我们从声音质量、生成速度、鲁棒性和可控制性几个方面来进行了评估。
声音质量
我们选用LJSpeech数据集进行实验,LJSpeech包含13100个英语音频片段和相应的文本,音频的总长度约为24小时。我们将数据集分成3组:300个样本作为验证集,300个样本作为测试集,剩下的12500个样本用来训练。
我们对测试样本作了MOS测试,每个样本至少被20个英语母语评测者评测。MOS指标用来衡量声音接近人声的自然度和音质。我们将FastSpeech方法与以下方法进行对比:1) GT, 真实音频数据;2) GT (Mel + WaveGlow), 用WaveGlow作为声码器将真实梅尔谱转换得到的音频;3) Tacotron 2 (Mel + WaveGlow);4) Transformer TTS (Mel + WaveGlow);5) Merlin (WORLD), 一种常用的参数法语音合成系统,并且采用WORLD作为声码器。
从表1中可以看出,我们的音质几乎可以与自回归的Transformer TTS和Tacotron 2相媲美。

FastSpeech合成的声音Demo:
文字:“The result of the recommendation of the committee of 1862 was the Prison Act of 1865”
更多声音Demo:
https://speechresearch.github.io/fastspeech/
合成速度
我们比较FastSpeech与具有近似参数量的Transformer TTS的语音合成速度。从表2可以看出,在梅尔谱的生成速度上,FastSpeech比自回归的Transformer TTS提速将近270倍;在端到端(合成语音)的生成速度上,FastSpeech比自回归的Transformer TTS提速将近38倍。FastSpeech平均合成一条语音的时间为0.18s,由于我们的语音平均时长为6.2s,我们的模型在单GPU上的语音合成速度是实时语音速度的30倍(6.2/0.18)。
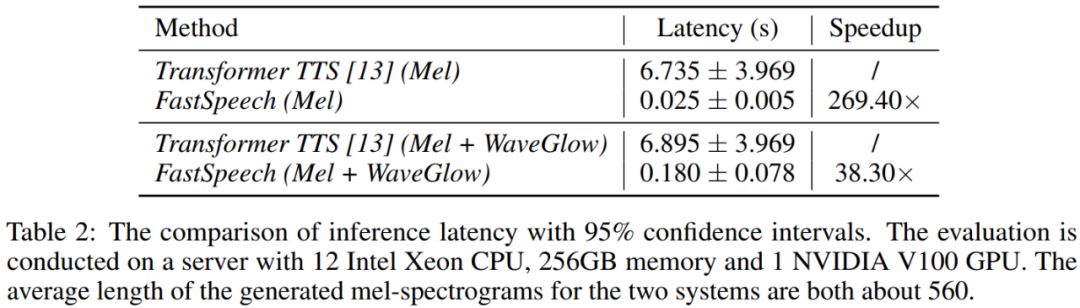
图2展示了测试集上生成语音的耗时和生成的梅尔谱长度(梅尔谱长度与语音长度成正比)的可视化关系图。可以看出,随着生成语音长度的增大,FastSpeech的生成耗时并没有发生较大变化,而Transformer TTS的速度对长度非常敏感。这也表明我们的方法非常有效地利用了GPU的并行性实现了加速。
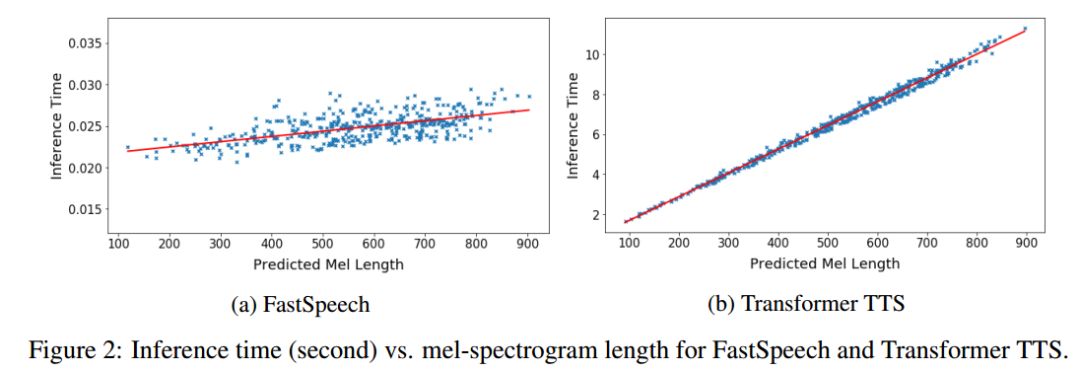
图2. 生成语音的耗时与生成的梅尔谱长度的可视化关系图
鲁棒性
自回归模型中的编码器-解码器注意力机制可能导致音素和梅尔谱之间的错误对齐,进而导致生成的语音出现重复吐词或漏词。为了评估FastSpeech的鲁棒性,我们选择微软(亚洲)互联网工程院语音团队产品线上使用的50个较难的文本对FastSpeech和基准模型Transformer TTS鲁棒性进行测试。从下表可以看出,Transformer TTS的句级错误率为34%,而FastSpeech几乎可以完全消除重复吐词和漏词。

关于鲁棒性测试的声音demo,请访问:
https://speechresearch.github.io/fastspeech/
语速调节
FastSpeech可以通过长度调节器很方便地调节音频的语速。通过实验发现,从0.5x到1.5x变速,FastSpeech生成的语音清晰且不失真。
语速调节以及停顿调节的声音Demo:
https://speechresearch.github.io/fastspeech/
消融对比实验
我们也比较了FastSpeech中一些重要模块和训练方法(包括FFT中的一维卷积、序列级别的知识蒸馏技术和参数初始化)对生成音质效果的影响,通过CMOS的结果来衡量影响程度。由下表可以看出,这些模块和方法确实有助于我们模型效果的提升。

未来,我们将继续提升FastSpeech模型在生成音质上的表现,并且将会把该模型应用到其它语言(例如中文)、多说话人和低资源场景中。我们还会尝试将FastSpeech与并行神经声码器结合在一起训练,形成一个完全端到端训练的语音到文本并行架构。
论文
详细内容请查阅论文:
https://arxiv.org/pdf/1905.09263.pdf
Demo
更多Demo声音,请访问:
https://speechresearch.github.io/fastspeech/
这个工作在Reddit社区中也获得了许多业界人士和热心网友的关注,也欢迎大家与我们交流讨论。
Reddit讨论链接:
https://www.reddit.com/r/MachineLearning/comments/brzwi5/r_fastspeech_fast_robust_and_controllable_text_to/
我们也将在不久后开放论文源代码,敬请关注!
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆

推荐阅读
“爱装X”开源组织:“教科书级”AI知识树究竟长什么样?
MNIST重生,测试集增加至60000张!
基础必备 | Python处理文件系统的10种方法
500行Python代码打造刷脸考勤系统
前端开发20年变迁史
刚出炉!AI指数报告:AI人才需求暴涨35倍,薪酬问鼎No.1
ARM 发布新一代CPU和GPU,实现20%性能提升!
北漂杭漂的程序员,是如何买到第一套房子?
权游播完了, 你在骂烂尾, 有人却悄悄解锁了新操作……

点击阅读原文,查看更多精彩内容。
相关文章:

Linux —— 目录(文件夹)及文件相关处理指令
可参考这篇文章:https://mp.weixin.qq.com/s?__bizMzU4MTU3OTI0Mg&mid2247484269&idx1&sn38869a1df48d8cdb6278518b51601ce0&chksmfd443be8ca33b2fe937531e061c406786f0e587d8ab10ff15594442265658d08cd8271ae52c5&mpshare1&scene23&s…

工业级3G路由器
宏电工业级3G路由器的特点,工业级标准设计,适应零上60度的高温,零下30度的低温,存工业级制造工艺,适应交通,环保,矿山,电力等工业级应用,欢迎来电索取解决方案,沈阳宏电办事处 刘冰 15940556464 024-31296279 限东三省地区.转载于:https://blog.51cto.com/lbing/916441
【FFmpeg】AVOutputFormat/AVInputFormat 成员变量 flags 总结
1、分类 AVOutputFormat中flags允许的值: AVFMT_NOFILE, AVFMT_NEEDNUMBER, AVFMT_GLOBALHEADER, AVFMT_NOTIMESTAMPS, AVFMT_VARIABLE_FPS, AVFMT_NODIMENSIONS, AVFMT_NOSTREAMS, AVFMT_ALLOW_FLUSH, AVFMT_TS_NONSTRICT, AVFMT_TS_NEGATIVEAVInputFormat中flags允许的值…

基础必备 | Python处理文件系统的10种方法
作者 | Jeff Hale 译者 | 风车云马;责编 | Jane,Rachel出品 | Python大本营(ID:pythonnews)【导读】在编写一些Python程序的时候,我们常常需要与文件系统进行交互。在本文中,营长为大家整理了10…
安装Oracle11g先决条件检查失败
体系结构 - 此先决条件将测试系统是否具有认证的体系结构。预期值:?N/A实际值:?N/A?错误列表:?-?PRVF-7536 : 无法在节点 "mywin7" 上执行体系结构检查 ?- Cause:? 无法确定系统体系结构。 ?-Action:? 确保正在使用正确的软件包。 处理 转载于:https://www.…
Windows Forms高级界面组件-使用状态栏控件
状态栏(StatusStrip)控件通常显示在窗体的底部,向用户提供有关应用程序状态的信息。如Word应用程序使用状态栏提供页码、行数和列数的信息。StatusStrip派生于ToolStrip,通常由ToolStripStatusLabel对象组成,用于显示指…
【Qt】在QtCreator中编译log4cplus
在QtCreator中编译log4cplus 一、在QtCreator中配置cmake二、编译log4cplus1、下载2、编译、安装一、在QtCreator中配置cmake 参见博客:https://blog.csdn.net/u010168781/article/details/107613606 log4cplus使用cmake来编译,因此需要QtCreator支持cmake 二、编译log4cpl…

IEEE“撑不住”了?声明解除对华为评审限制
整理 | 琥珀出品 | AI科技大本营(ID:rgznai100)6 月 2 日,IEEE 官方发表声明表示:经美国商务部就出口管制条例在 IEEE 出版活动中的适用性做出的说明,华为及其子公司的员工可以参加 IEEE 出版过程的同行评审和编辑工作…
关于软件产业的两个契机
软件产业是一个产业 , 和其它的产业一样 , 有各种角色分工 。 未来的软件是跨行业的 。 未来 , 软件会将各个行业联系在一起 。 云计算是第一代互联网发展到成熟的标志 。 网格计算是第二代互联网的开始 。 软件产业 在 未来 会 分为 平台&a…
java继承中的一些该注意的问题
关于继承,我想大多数人都知道,它是面向对象语言中的三大特性之一,所以在这里,关于继承的概念等我就不做详细介绍了,我主要就讲一下大家对他的认识中一些比较容易犯的错误吧。 错误认识1、继承,是将父类中所…
【C】printf warning: unknown conversion type character ‘l‘ in format [-Wformat=]
1、问题描述 在使用printf、fprintf打印long long类型时报错 printf warning: unknown conversion type character l in format [-Wformat=]2、原因分析 “%lld” 和 “%llu” 是 linux 下 gcc/g++ 用于 long long int 类型 (64 bits) 输入输出的格式符。 而 “%I64d” 和 “…

史上最强最贵Mac Pro诞生,iPadOS和iOS分家!WWDC19全面总结
作者 | 俞佳兴、胡巍巍转载自CSDN(ID:CSDNnews)图片&视频 | 余佳兴摄自美国圣何塞WWDC现场一年一度的WWDC终于来了!43岁的苹果,产品经验位居世界前列。一个迈入中年的公司,该如何持续做出让人惊艳的产品…
Java 抽象类与接口的区别
接口和抽象类有什么区别 你选择使用接口和抽象类的依据是什么? 接口和抽象类的概念不一样。接口是对动作的抽象,抽象类是对根源的抽象 抽象类表示的是,这个对象是什么。接口表示的是,这个对象能做什么。比如,男人&…

XMOVE3.0手持终端——软件介绍(五):在2KB内存的单片机上实现的T9中文输入法
编者注: X-MOVE是作者在业余时间于2010年6月份启动的以运动传感开发,算法和应用的平台,目前已经发展了三个版本,第四版的开发接近尾声。发布在博客园仅为交流技术,不存在商业目的,作者保留一切权利。 一. 综…

推荐系统遇上深度学习,9篇阿里推荐论文汇总!
作者 | 石晓文转载自小小挖掘机(ID: wAIsjwj)业界常用的推荐系统主要分为两个阶段,召回阶段和精排阶段,当然有时候在最后还会接一些打散或者探索的规则,这点咱们就不考虑了。前面九篇文章中,有三篇是召回阶…

ReSharper修改命名风格
默认情况下,ReSharper会建议你全局变量命名使用下划线开头,且第一个字母小写。否则,会给你标记出来,如下: 但我个人不喜欢这种风格,一般使用首字母大写且不带下划线,可以通过配置来调整…
【Qt】Log4Qt(一)下载、编译
Log4Qt(一)下载、编译 1、下载2、编译2.1 单独编译成库2.2 将源码添加到项目中2.2.1 log4qt.pri分析2.2.2 pro示例如下1、下载 github上星最多的是这个:https://github.com/MEONMedical/Log4Qt 下载log4qt最新(截止2021-12-04)的稳定版本v1.5.1(Qt版本需要Qt5.7.0以上)…
android:退出程序
http://kofi1122.blog.51cto.com/2815761/703751 使用的是定义全局变量的方法

ubuntu中使用apt命令安装ipython失败解决方案
在最近使用ubuntu安装ipython时,出现如下报错: 出现这个问题,主要是因为apt还在运行,故解决方案为: 1、找到并且杀掉所有的apt-get 和apt进程 运行下面的命令来生成所有含有 apt 的进程列表,使用ps和grep命…
【Qt】Log4Qt(二)使用
Log4Qt(二)使用 1、使用TTCCLayout 格式化输出1.1 添加头文件1.2 配置根记录器的输出格式1.3 注册记录器,并输出日志2、最简代码3、将日志写入文件4、使用配置文件:log4qt.properties5、使用配置文件:QSettings6、周期性生成日志文件7、滚动生成日志文件(可以指定日志文件…

B站超全分享!2万人收藏的免费计算机科学速成课
整理 | 一一出品 | AI科技大本营(ID:rgznai100)作为一枚程序员,很多人可能都不太能清晰地说出计算机发展脉络,要想成为优秀的程序员,只会编程是不够的。“读史使人明智”,我们还要了解计算机理论知识&#…

图说:Windows 8使用搜索,快速开启应用
在Windows 8中,“开始菜单”变成的“开始屏幕”,想快速找到需要的应用不是件容易的事,毕竟桌面可以安装太多的应用。 怎么快速找到需要的应用的,其实方法也非常简单,只需在“开始屏幕”下使用键盘,键入需要…

一个可以卷起来的蓝牙键盘,简直是办公码字神器!
作为一个办公室码字党,熊大大一直觉得ipad最大的bug就是码字不方便。以前,我每次码字都会把平板先平放,打字才能顺手╮(╯﹏╰)╭后来买了蓝牙键盘,码字方便了,但键盘又大又厚重,日常携带巨不方…

比较v-bind和v-model
简单来说,区别如下:1.v-bind用来绑定数据和属性以及表达式,缩写为:2.v-model使用在表单中,实现双向数据绑定的,在表单元素外使用不起作用 一、v-model v-model多在表单中使用,在表单元素上创建双…
【Qt】Log4Qt(四):周期性输出日志,并且限制日志文件数量
在Log4Qt中存在一个比较大的问题,当使用 DailyRollingFileAppender对日志进行输出时,会无限输出文件,也就是说,当系统运行很久时,日志文件有可能很大,大到无法想象。因此,很多开发者希望在DailyRollingFileAppender中加一个属性,用于配置日志文件的个数。 1、dailyrol…

g13 root
1.官方解锁: 官方已经给出了wildfire S的解锁bootloader教程。需要注意的是,这个解锁之后虽然仍是s-on状态(但下边一行显示了unlock),不影响我们将来随意刷机,说白了就相当于s-off了。 准备工作,…
【Qt】Log4Qt(三)源码分析
Log4Qt(三)源码分析 1、分层架构1.1 核心对象1.2 支持对象2、源码分析2.1 宏2.1.1 LOG4QT_DECLARE_QCLASS_LOGGER2.1.2 LOG4QT_DECLARE_STATIC_LOGGER2.2类2.2.1 Log4Qt::ClassLogger2.2.2 LogManager2.2.3 PropertyConfigurator2.3 深入理解 rootLogger、logLogger、qtLogge…

GitHub五万星登顶,程序员命令行最全技巧宝典!
作者 | 唐小引封图 | CSDN出品 | CSDN(ID:CSDNnews)一个项目 Get 所有命令行技巧!最近两天,「The Art of Command Line(命令行的艺术)」这个开源项目雄踞了 GitHub TOP 榜,直接以 51…
开源硬件:极客们的伟大理想
自 Dennis Allison 在 1975 年发布它的 Tiny BASIC 以来,他倡导的开放、共享的思想得到了多数开发者的认同,这些年,软件开源取得了令人瞩目的成绩。同时,他那句 “让我们站在彼此的肩膀,而不是彼此的脚趾上。”也变成了…

五年12篇顶会论文综述!一文读懂深度学习文本分类方法
作者 | 何从庆来源 | AI算法之心(ID:AIHeartForYou)最近有很多小伙伴想了解深度学习在文本分类的发展,因此,笔者整理最近几年比较经典的深度文本分类方法,希望帮助小伙伴们了解深度学习在文本分类中的应用。…