五年12篇顶会论文综述!一文读懂深度学习文本分类方法

作者 | 何从庆
来源 | AI算法之心(ID:AIHeartForYou)
最近有很多小伙伴想了解深度学习在文本分类的发展,因此,笔者整理最近几年比较经典的深度文本分类方法,希望帮助小伙伴们了解深度学习在文本分类中的应用。笔者整理了近些年的相关深度文本分类论文。
Convolutional Neural Networks for Sentence Classification (EMNLP 2014)
Kim在EMNLP2014提出的TextCNN方法,在多个数据集上取得了很好的效果。由于其计算速度快以及可并行性,在产业界得到了广泛使用。TextCNN的模型示意图如下图所示。
TextCNN模型首先将文本映射成向量,然后利用多个滤波器来捕捉文本的局部语义信息,接着使用最大池化,捕捉最重要的特征。最近将这些特征输入到全连接层,得到标签的概率分布。
代码参考:
1) https://github.com/alexander-rakhlin/CNN-for-Sentence-Classification-in-Keras
2) https://github.com/brightmart/text_classification
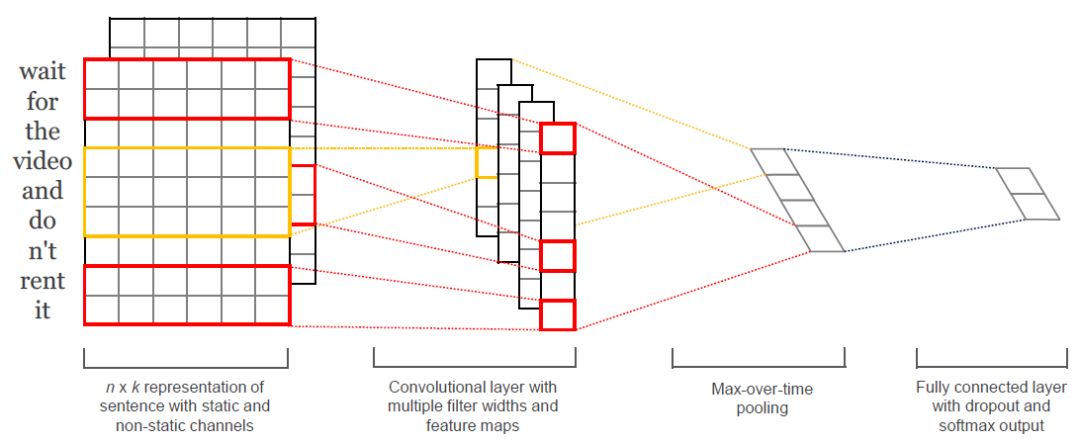
图1:TextCNN模型架构
Document Modeling with Gated Recurrent Neural Network for Sentiment Classification (EMNLP 2015)
Tang等人提出了一种利用GRU对文档进行建模的情感分类模型。模型如下图所示。
该模型首先将文本映射为向量,然后利用CNN/LSTM(论文中使用3个滤波器的CNN)进行句子表示。另外,为了捕获句子的全局语义表征,将其输送给平均池化层,再接入tanh激活函数。最后将整个句子的不同宽度卷积核的向量表示接入一个Average层,从而得到句子平均向量表示。
然后将得到的句子表示,输入到GRU中,得到文档向量表示。最后将文档向量输送给softmax层,得到标签的概率分布。
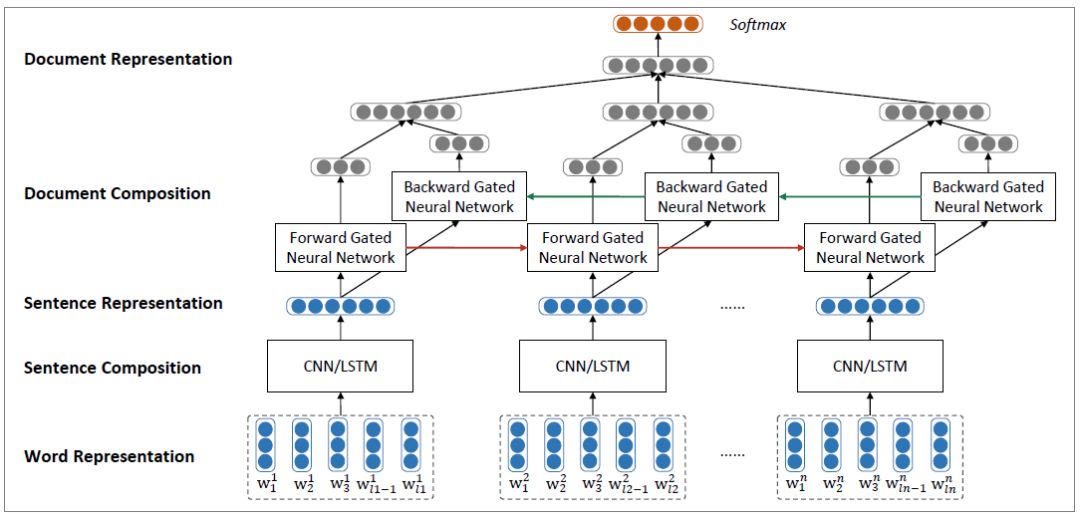
图2:文档级别情感分类的神经网络模型
Recurrent Convolutional Neural Networks for Text Classification (AAAI 2015)
Lai等人提出了一种无人工特征的循环卷积神经网络分类方法,简称RCNN。
RCNN首先利用Bi-RNN来捕捉前后的上下文表征,然后将其concat起来,接着使用滤波器filter_size=1的卷积层,并使用最大池化操作得到与文档最相关的向量表征,最后将这些向量输入到softmax层,得到标签的概率表征。
代码参考:
1) https://github.com/roomylee/rcnn-text-classification
2) https://github.com/brightmart/text_classification
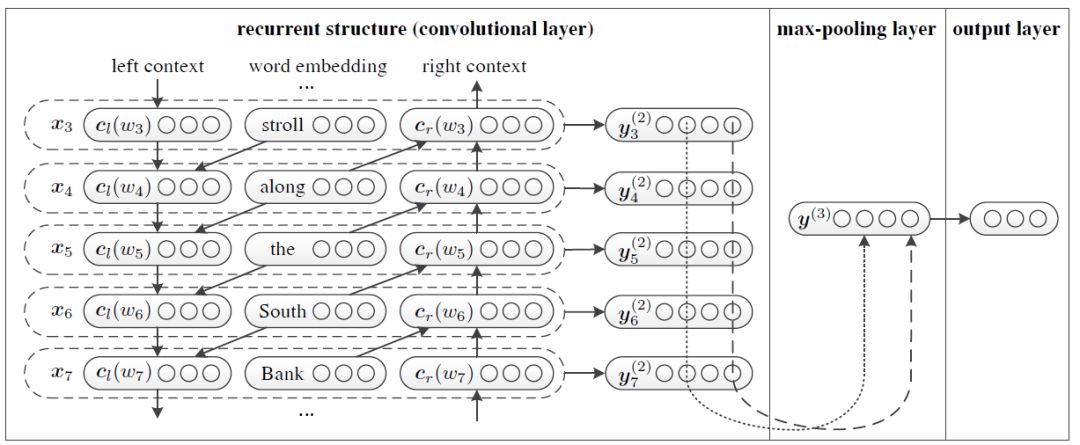
图3: RCNN的模型结构示意图
Recurrent Neural Network for Text Classification with Multi-Task Learning (IJCAI 2016)
Liu等人针对文本多分类任务,提出了基于RNN的三种不同的共享信息机制对具有特定任务和文本进行建模。
模型1(Uniform-Layer Architecture):所有任务共享同一个LSTM层,并在每个特定任务后面拼接一个随机生成可训练的向量。LSTM层的最后一个时刻的隐藏层作为输入传入到softmax层。
模型2(Coupled-Layer Architecture): 每个任务具有自己独立的LSTM层,但是每一时刻所有任务的hidden state则会和下一时刻的character一起作为输入,最后一个时刻的hidden state进行分类。
模型3(Shared-Layer Architecture):除了一个共享的BI-LSTM层用于获取共享信息,每个任务有自己独立的LSTM层,LSTM的输入包括每一时刻的character和BI-LSTM的hidden state。
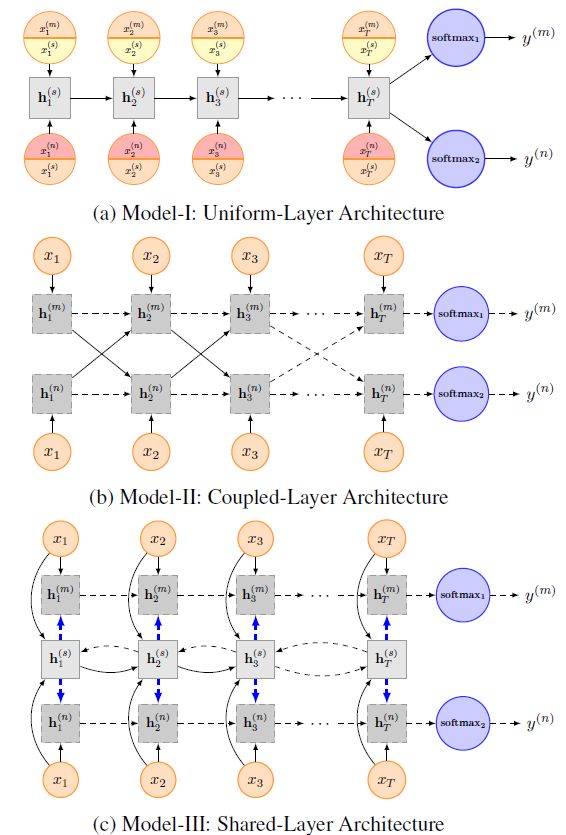
图4:三种架构进行多任务学习建模
Hierarchical Attention Networks for Document Classification (NAACL 2016)
Yang等人提出了一种用于文档分类的层次注意力机制网络,简称HAN。这篇文章和Tang等人都是针对于文档分类的问题,然而,这篇文章在句子级别以及文档级别提出了注意力机制,使得模型在构建文档时是能够赋予重要内容不同的权重,同时,也可以缓解RNN在捕捉文档的序列信息产生的梯度消失问题。HAN模型的模型示意图如下所示。
HAN模型首先利用Bi-GRU捕捉单词级别的上下文信息。由于句子中的每个单词对于句子表示并不是同等的贡献,因此,作者引入注意力机制来提取对句子表示有重要意义的词汇,并将这些信息词汇的表征聚合起来形成句子向量。具体的注意力机制的原理可以参考:
FEED-FORWARD NETWORKS WITH ATTENTION CAN SOLVE SOME LONG-TERM MEMORY PROBLEMS
然后,对于所有的句子向量输入到Bi-GRU中,捕捉句子级别的上下文信息,得到文档向量。同样地,为了奖励对文档进行正确分类的线索句,作者再次使用注意力机制,来衡量句子的重要性,得到文档向量。最后将文档向量均输入到softmax层,得到标签的概率分布。
代码参考:
1) https://github.com/richliao/textClassifier
2) https://github.com/brightmart/text_classification
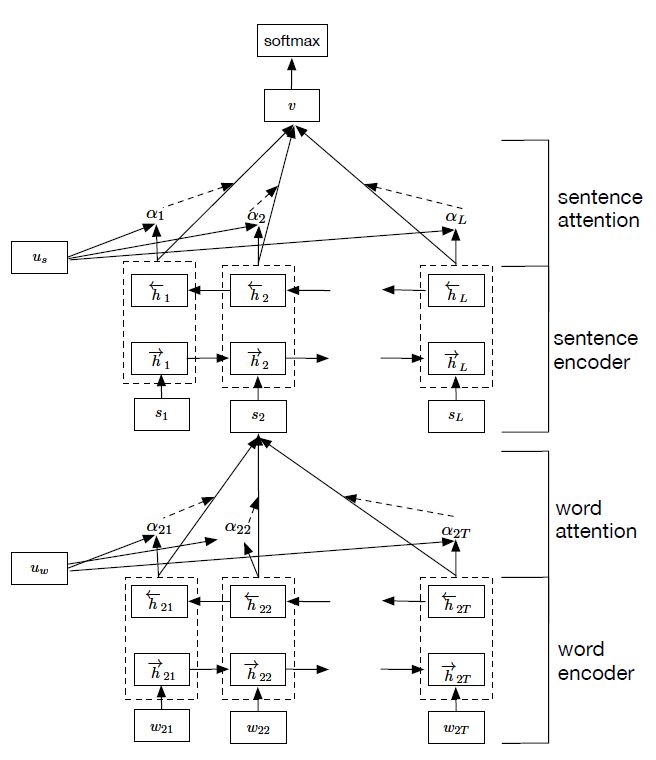
图3: HAN模型结构示意图
Bag of Tricks for Efficient Text Classification (EACL 2017)
Joulin等人提出了一种简单而又有效的文本分类模型,简称fastText。
fastText模型输入一个词序列(一段文本或者一句话),序列中的词与词组成特征向量,然后特征向量通过线性变换映射到中间层,中间层再映射到标签。输出这个词序列属于不同类别的概率。其中fastText在预测标签是使用了非线性激活函数,但在中间层不使用非线性激活函数。
代码参考:
1) https://github.com/facebookresearch/fastText
2) https://radimrehurek.com/gensim/models/fasttext.html
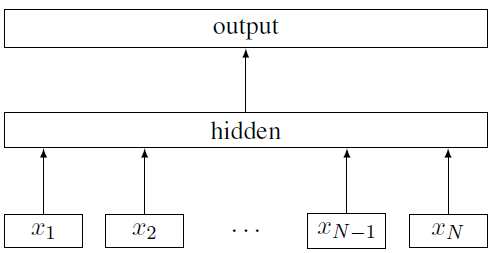
图4:fastText模型结构示意图
Deep Pyramid Convolutional Neural Networks for Text Categorization (ACL 2017)
Johnson 和Zhang 提出了一种单词级别的深层CNN模型,来捕捉文本的全局语义表征,该模型在不增加太多的计算开销的情况下,通过增加网络深度可以获得最佳的性能,简称DPCNN。模型结构示意图如下所示。
DPCNN模型首先利用“text region embedding”,将常用的word embedding 推广到包含一个或多个单词的文本区域的embedding,类似于增加一层卷积神经网络。
然后是卷积快的叠加(两个卷积层和一个shortcut连接,其中shortcut连接类似于残差连接),与步长为2的最大池化层进行下采样。最后使用一个最大池化层,得到每个文档的文档向量。
代码参考:
https://github.com/Cheneng/DPCNN
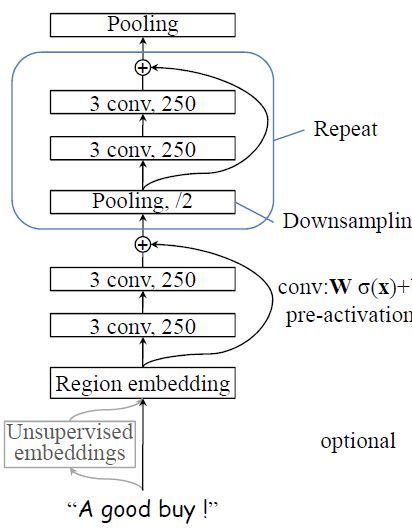
图4:DPCNN模型结构示意图
Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm (EMNLP 2017)
Felbo等人使用数以百万计的表情符号来学习任何领域的表情符号来检测情绪、情绪和讽刺,提出了DeepMoji模型,并取得了具有竞争性的效果。同时,DeepMoji模型在文本分类任务上也可以取得不错的结果。
DeepMoji模型首先使用embedding层将单词映射成向量,并将每个embedding维度使用双正切函数映射到[-1,1]。然后,作者使用两层的Bi-LSTM捕捉上下文特征。接着作者提出了一种新的注意力机制,分别将embeddding层以及2层的Bi-LSTM作为输入,得到文档的向量表征。最后,将向量输入到softmax层,得到标签的概率分布。
代码参考:
https://github.com/bfelbo/DeepMoji
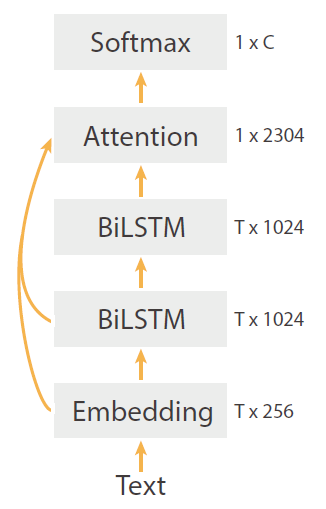
图5:DeepMoji模型结构示意图
Investigating Capsule Networks with Dynamic Routing for Text Classification (EMNLP 2018)
Zhao等人提出了一种基于胶囊网络的文本分类模型,并改进了Sabour等人提出的动态路由,提出了三种稳定动态路由。模型如下所示:
该模型首先利用标准的卷积网络,通过多个卷积滤波器提取句子的局部语义表征。然后将CNN的标量输出替换为向量输出胶囊,从而构建Primary Capsule层。接着输入到作者提出的改进的动态路由(共享机制的动态路由和非共享机制的动态路由),得到卷积胶囊层。最后将卷积胶囊层的胶囊压平,送入到全连接胶囊层,每个胶囊表示属于每个类别的概率。
代码参考:
https://github.com/andyweizhao/capsule_text_classification
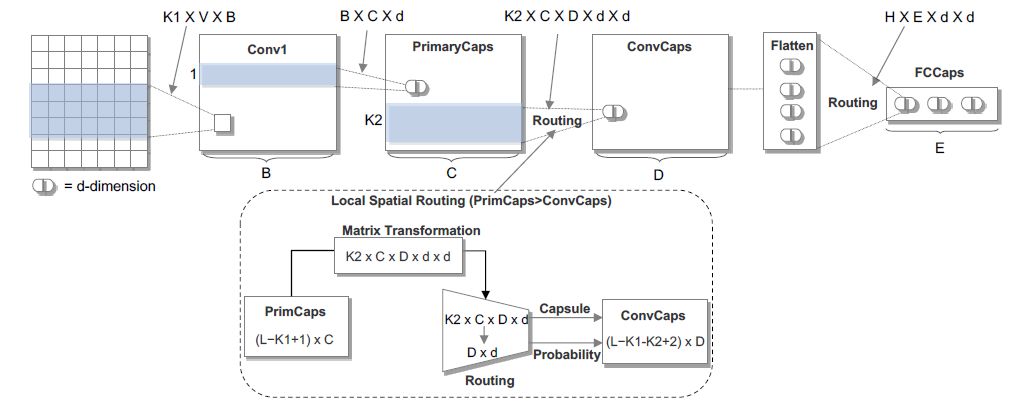
图6:文本分类的胶囊网络体系结构
Sentiment Analysis by Capsules (WWW 2018)
Wang等人提出了一种用于情感分类的RNN胶囊网络模型,简称RNN-Capsule。(这篇文章在可视化方面做的还是不错的)模型结构示意图如下所示。
RNN-Capsule首先使用RNN捕捉文本上下文信息,然后将其输入到capsule结构中,该capsule结构一共由三部分组成:representation module, probability module,和reconstruction module。具体地,首先用注意力机制计算capsule 表征;然后用capsule表征计算capsule状态的概率;最后用capsule表征以及capsule状态概率重构实例的表征。
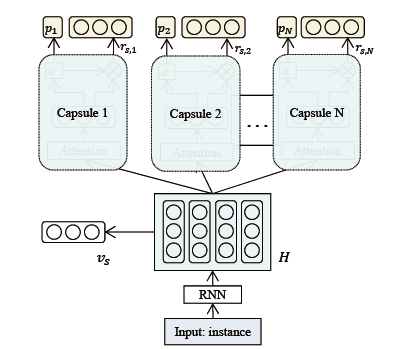
图7: RNN-Capsule模型结构示意图
Graph Convolutional Networks for Text Classification (AAAI 2019)
Yao等人提出了一种基于graph convolutional networks(GCN)进行文本分类。作者构建了一个包含word节点和document节点的大型异构文本图,显式地对全局word利用co-occurrence信息进行建模,然后将文本分类问题看作是node分类问题。
代码参考:
https://github.com/yao8839836/text_gcn
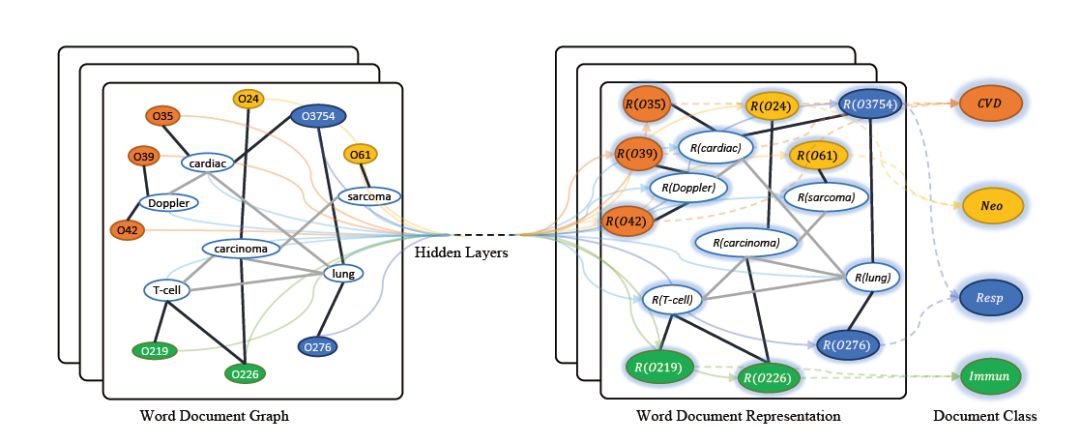
图7:Text GCN的模型结构
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (NAACL 2019)
Google提出的BERT模型,突破了静态词向量无法解决一词多义的问题。BERT是基于语言模型的动态词向量,在自然语言处理的多项任务中取得了最优秀的结果。笔者对BERT模型进行微调,在文本分类的多个领域,诸如法律、情感等,取得了非常有竞争性的性能。
BERT的模型架构是一个多层的双向Transformer编码器(Transformer的原理及细节可以参考 Attention is all you need)。作者采用两套参数分别生成BERTBASE模型和BERTLARGE模型(细节描述可以参考原论文),所有下游任务可以在这两套模型进行微调。
代码参考:
https://github.com/google-research/bert
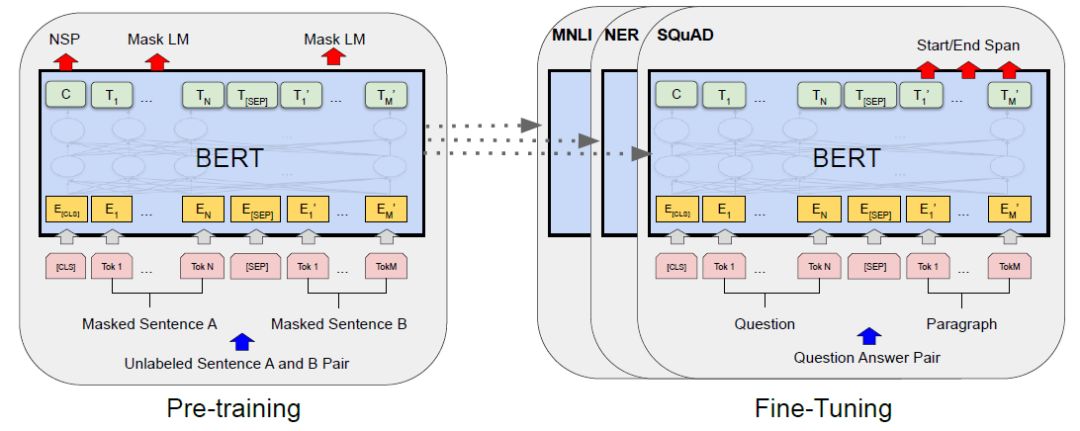
图8:BERT的Pre-training结构和Fine-Tuning结构
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
6月29-30日,2019以太坊技术及应用大会 特邀以太坊创始人V神与以太坊基金会核心成员,以及海内外知名专家齐聚北京,聚焦前沿技术,把握时代机遇,深耕行业应用,共话以太坊2.0新生态。
扫码或点击阅读原文,既享优惠购票!

推荐阅读
Python从入门到精通,这篇文章为你列出了25个关键技术点(附代码)
基础必备 | Python处理文件系统的10种方法
B站超全分享!2万人收藏的免费计算机科学速成课
如何正确的获取数据?
苹果 SwiftUI 踢馆谷歌 Flutter!
惊!为拯救美国落伍的 STEM 教育,纷纷出手教老师编程?!
超级黑幕:开发者千万别被算法迷惑了!
程序员爬取 42 年高考数据,告诉你高考为什么这么难?
把病毒写到区块链上可以永远不死? 我们做了一个大胆的实验…… | 技术头条
新一代私有云来了!看透基于开源生态的产品化

点击阅读原文,查看更多精彩内容。
相关文章:

Failed to fetch http://mirrors.cloud.aliyuncs.com/
服务器版本:阿里云 ubuntu 16.04 问题:阿里云安装软件时,提示 W: Failed to fetch http://mirrors.cloud.aliyuncs.com/ubuntu/dists/xenial/InRelea se Could not resolve mirrors.cloud.…

【FFmpeg】使用sws_scale将AVFrame转换后的图像数据放入cv::Mat中
1、方法一,伪代码如下 cv::Mat mat; AVFrame avFrame; const int stride[] = {static_cast<int>(mat.step[0])}; ret =

Android之Adapter用法总结
本文转自http://kb.cnblogs.com/a/2328334/,转载请注明原出处。 Android之Adapter用法总结 作者:Devin Zhang 来源:博客园 发布时间:2012-01-20 22:33 阅读:1193 次 原文链接 [收藏] 1.概念 Adapter是连接后端数…
【FFmpeg】ffmpeg命令详解(一)
ffmpeg命令详解(一) 1、命令格式2、简述3、详细说明3.1 过滤器3.1.1 简单的过滤器图3.1.2 复杂的过滤器图3.2 流拷贝1、命令格式 ffmpeg [global_options] {[input_file_options] -i input_url} ... {[output_file_options] output_url} ...global_options:全局选项 input_…

从流感预测到智能决策,深度学习能帮企业做哪些事?
未来将只有两种公司,一种是有人工智能的,一种是不赚钱的。这句话大概可以总结两层意思,一方面人工智能让更多的企业面对更广阔的商业前景,另一方面是如果要运用人工智能创造价值,就必须拥抱技术,实现真正的…
寻找隐形冠军 支付宝、微信用得那么溜,可谁知道背后有一名“上海功臣
下午三点半,离晚饭时间还有一段时间,可新沪路上的熟食店“尚老居”门口已经人头攒动。 “阿姨你来啦,今天要点什么?” “老样子,称点烧鹅和蹄髈,阿拉孙子老欢喜吃的,买好正好去接伊放学。” “阿…
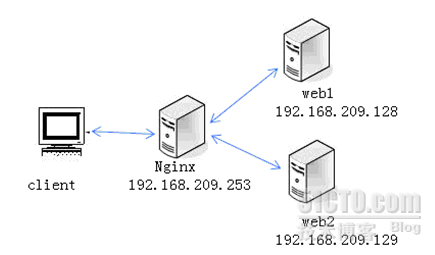
Lnmp安装与配置笔记
——————————————安装与配置——————————————1.相关软件:yum -y install gcc gcc-c autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-…
【FFmpeg】ffmpeg命令详解(二)
ffmpeg命令详解(二) 4、流选择4.1 自动选择流4.2 手动选择流5、命令行选择详解5.1 命令行选项的值说明:5.2 流说明符5.3 通用选项5.4 主选项5.5 视频相关选项5.6 高级视频选项5.7 音频选项5.8 高级音频选项5.9 字幕选项5.10 高级字幕选项4、流选择 FFmpeg提供了“-map”选项…

谷歌开源张量网络库TensorNetwork,GPU处理提升100倍!
编译 | 琥珀出品 | AI科技大本营(ID:rgznai100)世界上许多最严峻的科学挑战,如开发高温超导体和理解时空的本质,都涉及处理量子系统的复杂性。然而,这些系统中量子态的数量程指数级增长,使得暴力计算并不可…

Python基础之逻辑运算符
1.在没有()的情况下,not的优先级高于and,and的优先级高于or,即优先级关系为()>not>and>or,同一优先级从左往右计算。 例题,判断下列逻辑语句的结果: 3 > 4 or 4 < 3 and 1 1 1 < 2 a…
《Android开发从零开始》——11.AbsoluteLayoutFrameLayout学习
本节课的主要内容有: 1.介绍AbsoluteLayout布局的使用 2.介绍FrameLayout布局的使用 课程下载地址:http://u.115.com/file/f15a9d5411 课件及地址:http://u.115.com/file/f1b56ce345 【转】转载于:https://blog.51cto.com/professor/1573001
【FFmpeg】ffmpeg命令详解(三)高级选项
ffmpeg命令详解(三)高级选项 1、-map2、-ignore_unknown3、-copy_unknown4、-map_channel5、-map_metadata6、-map_chapters7、-benchmark8、-benchmark_all9、-timelimit10、-dump11、-hex12、-readrate13、-re14、-vsync15、-frame_drop_threshold16、-async17、-adrift_th…
重磅!Google推出了Python最牛X的编辑器......
随着和大数据、人工智能绑定在一起,Python可畏是越来越厉害了!前几天, PYPL(即编程语言流行指数,基于 Google 搜索频率而定)出炉了 6 月编程语言排行榜,Python 拿下 NO.1,成为最流行的编程语言。…
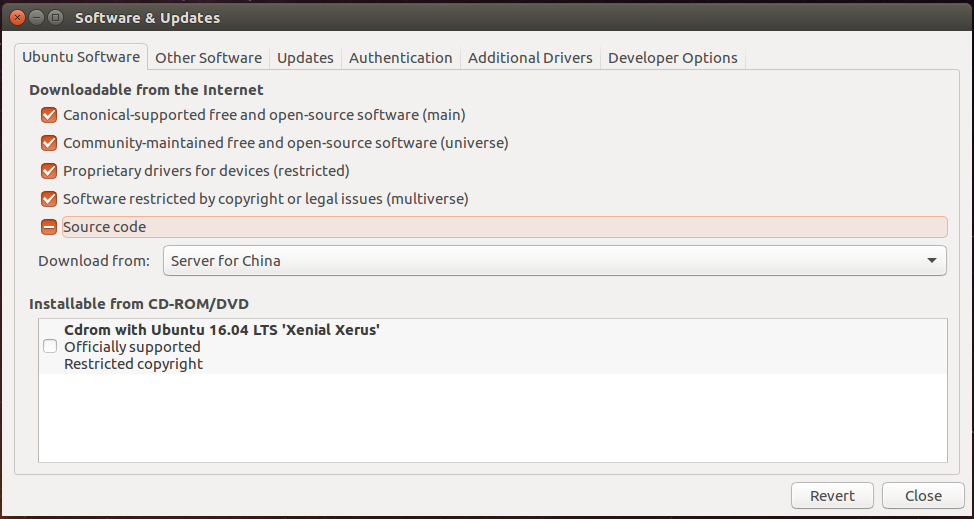
ubuntu16.04 ROS安转及RVIZ启动
1、软件中心配置 首先打开软件和更新对话框,打开后按照下图进行配置(确保你的"restricted", "universe," 和 "multiverse."前是打上勾的): 2、添加源 $ sudo sh -c echo &qu…
Ubuntu下自动挂载Windows分区的方法
用过Ubuntu的都知道,在Ubuntu开机时,Windows的文件系统是不会自动挂载的,每次开机都得手动挂载,确实不方便。多次的手动挂载实在是让我有些烦躁了,遂决定要让我的系统开机时自动挂载文件系统。看了一些网上的教程&…
poj3009
一、题意:给定一个矩形区域,代表冰球场。每个单元格可有四种数值:2是冰球的起始位置;3代表冰球最后需要到达的位置;0代表空,球可通过;1代表障碍物,球碰撞一次后,1变成0&a…

谷歌开源新模型EfficientNet,或成计算机视觉任务新基础
作者 | Mingxing Tan,Quoc V. Le,Google AI译者 | 刘畅责编 | 夕颜出品 | AI科技大本营(id:rgznai100)开发一个卷积神经网络(CNN)的成本通常是固定的。在获得更多资源时,我们通常会按…
【FFmpeg】使用过的命令汇总(持续更新中...)
1、将输出文件的视频比特率设置为 64 kbit/s: ffmpeg -i input.avi -b:v 64k -bufsize 64k output.avi2、将输出文件的帧速率强制为 24 fps: ffmpeg -i input.avi -r 24 output.avi3、将输入文件的帧速率(仅对原始格式有效)强制为 1 fps,将输出文件的帧速率强制为 24 fp…
HLG 1481 Attack of the Giant n-pus【二分+二分图完全匹配】
题意: 有 p 个水手和一个章鱼,章鱼有 n 个脚,知道了所有单位的坐标,和船长以及船员的速度,船长想去攻击章鱼的头部,但是只有在章鱼所有的脚都被水手控制的情况下才会开始朝章鱼头部进攻,问如何分…

美亚排名超高的Docker入门书,不止简单易懂
在美国亚马逊,有一本书的影响力超高的Docker入门书,在操作系统分类中排行第一,超越了众多实力派Docker书,众多五星好评。也许你有所耳闻,这本书就是《深入浅出Docker》。这是一本关于Docker的图书。这本书的宗旨是从零…
虚拟机配置参数
标准参数:保证所有JVM的实现都可以支持-client设置Hotspot client jvm,64位jdk会忽略该参数并设置-server-Dpropertyvalue用于设置系统属性,如果value中有空格,则需要设置-Dproperty"value value"-server选择Hotspot Se…
【Qt】QAudioDeviceInfo获取不到音频设备
1、问题描述 使用QAudioDeviceInfo在开发机上可以获取本地的音频设备,但是在目标机上获取不到。 已经将libQt5Multimedia库拷贝到目标机上(如果没有将会报错)。 2、原因 没有将audio的插件拷贝到目标机上,audio插件在Qt安装目录…
异常:android.os.NetworkOnMainThreadException
Android 4.1项目:使用新浪微博分享时报: android.os.NetworkOnMainThreadException 网上搜索后知道是因为版本问题,在4.0之后在主线程里面执行Http请求都会报这个错,也许是怕Http请求时间太长造成程序假死的情况吧。那么网上的朋友…

阿里带火的中台到底是什么?白话中台战略
作者 | 王健,ThoughtWorks首席咨询师。 十多年国内外大型企业软件设计开发,团队组织转型经验。一直保持着对技术的热爱,热衷于技术分享。目前专注在企业平台化转型、中台战略规划,微服务架构与实施,大型遗留系统服务化…
【Qt】Ubuntu18.04下解决Qt出现qt.qpa.plugin:Could not load the Qt platform plugin “xcb“问题
1、问题描述 在ubuntu18.04中第一次安装QT5,运行时报错 qtcreator.sh qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "" even though it was found. This application failed to start because no Qt platform plugin could be init…
Bootstrap4 更新笔记
在bootstrap4里, 1. 旧版本bootstrap well变成了什么? well原本是‘’淡灰墙‘’样式。 Bootstrap 4 Beta card-block is now card-body, and bg-faded is now bg-light: <div class"card card-body bg-light"> Well </div>ref&am…
二、JavaScript基础 学好jQuery要了解的
JavaScript与ECMAScript ECMAScript 通过ECMA-262标准的脚本程序设计语言 ECMAScript标准下有 javascript jscript actionscript JavaScript分为值类型和引用类型两大类,有时也称为原始值和引用值。值类型:存储在栈(stack)中,一个值类型的变量…

一文综述经典的深度文本分类方法
作者 | 何从庆转载自AI算法之心(ID:AIHeartForYou)笔者整理最近几年比较经典的深度文本分类方法,希望帮助小伙伴们了解深度学习在文本分类中的应用。Convolutional Neural Networks for Sentence Classification (EMNLP 2014)Kim在EMNLP2014…
【FFmpeg】便捷函数汇总(持续更新中...)
音频相关: 1、由通道布局获取通道数 int av_get_channel_layout_nb_channels(uint64_t channel_layout);2、由通道数获取默认的通道布局 int64_t av_get_default_channel_layout(int nb_channels);3、返回采样格式对应的字符串名字 const char *av_get_sample_fm…
云服务器代金券
最近腾讯云与阿里云的促销活动都很好,有需要云服务器的可以领取代金券购买 https://www.art-china.club/ 至于配置调试的问题,可以问我,友情帮忙。转载于:https://blog.51cto.com/dnuser/2167896