推荐系统遇上深度学习,9篇阿里推荐论文汇总!

作者 | 石晓文
转载自小小挖掘机(ID: wAIsjwj)
业界常用的推荐系统主要分为两个阶段,召回阶段和精排阶段,当然有时候在最后还会接一些打散或者探索的规则,这点咱们就不考虑了。
前面九篇文章中,有三篇是召回阶段的文章,六篇是排序阶段的文章。在召回阶段,主要是基于item的embedding来做的,因此前两篇我们介绍一下大规模商品集下的embedding策略。第三篇将介绍一下深度树匹配召回模型。在排序阶段,主要是进行CTR或者CVR的预估,我们先来介绍一下MLR模型,然后介绍一下主要基于用户历史行为来做推荐的DIN、DIEN、DSIN和BST模型。最后介绍一下多任务模型ESMM。
本文主要简单介绍一下论文中提出的模型的内容,以及为什么要这么做。至于详细的内容,可以通过给出的文章链接以及论文进行进一步的学习。
1、Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
这篇文章中,使用图嵌入(Graph Embedding)的方法来学习十亿级商品的Embedding。基本的过程如下:
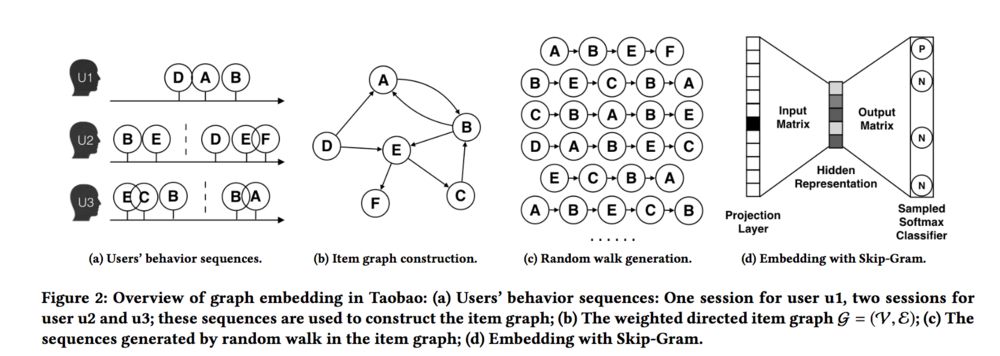
首先,将用户的历史行为切割为不同的Session,每个Session表示一个行为序列;随后,将这些行为序列表示为有向带权图,图中的权重代表所有行为序列中两个物品的行为转移次数;然后,基于随机游走的方式,从图中得到更多的行为序列;最后,通过Skip-Gram的方式,学习每个物品的Embedding。
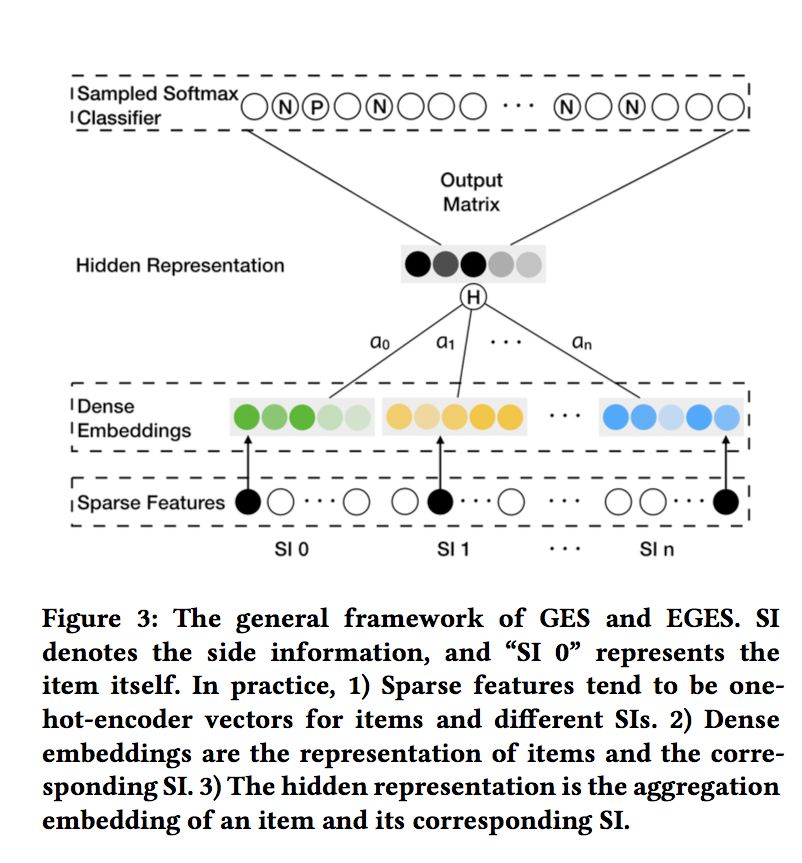
为了更好的解决冷启动问题,在学习物品Embedding时,进一步加入辅助信息Side-Information。这样,一个物品可表示为[w0,w1,..,wn],其中w0代表物品本身的Embedding,w1,..,wn代表n中side-information对应的Embedding。这样,聚合后的物品aggregated embeddings计算有两种方式,直接平均和加权平均:
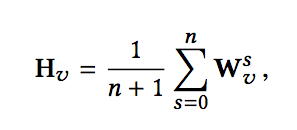
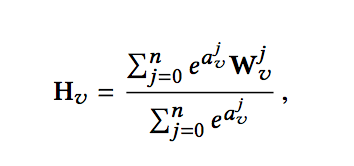
直接平均的方式称为Graph Embedding with Side information (GES),加权平均的方式称为 Enhanced Graph Embedding with Side information (EGES)。二者的流程如下:
在加入了side-information之后,新加入的物品的embedding可以通过其side-information对应的embedding的平均值来表示了。一般来说新的物品都有对应的side-information。同时embedding基本会按天进行更新。
关于该方法更多的介绍,参考文章:推荐系统遇上深度学习(四十六)-阿里电商推荐中亿级商品的embedding策略
2、Learning and Transferring IDs Representation in E-commerce
本文提到的方法,大体的过程跟上一篇文章是类似的。但是行为序列直接使用用户日志中的行为序列,没有通过随机游走的方式从构造的图中产生。
在得到行为序列之后,同样通过Skip-Gram来学习物品的Embedding。每一个物品对应多组Embedding:
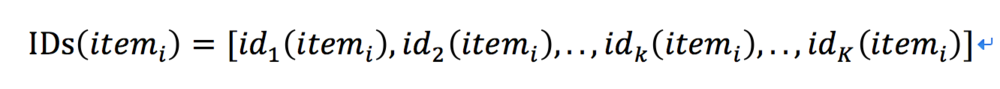
这里,id1(itemi)代表物品本身,id2(itemi)代表产品ID,id3(item3)代表店铺ID等等。
此时计算物品之间共现概率的公式如下:
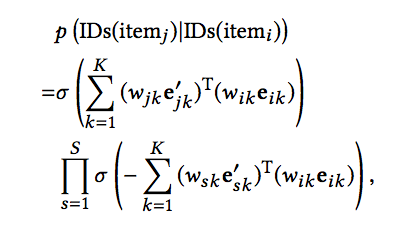
与第一篇文章通过平均把物品本身的Embedding和Side-Information对应的Embedding进行聚合的方式不同。这里分别计算了两个物品自身的Embedding和Side-Information对应的Embedding之间的相似性,随后进行求和作为两个物品的共现概率。第一种方式中,每个Embedding的长度必须一致,但是在后一种方式中,每种embedding的长度则无须一致。
而权重也是定义好的,并非像第一篇文章一样通过模型学习得到。权重定义如下:
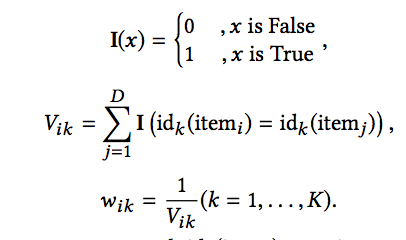
上面的D是整个商品集,举个例子来说明一下上面的流程,假设当前是计算品牌这个side-information的权重,商品i的品牌是阿迪达斯,遍历所有的商品集D,发现共有10个品牌是阿迪达斯的物品,那么此时的Vik=10,wik=1/10 。而wi1=1是确定的,因为第i个物品在商品集中是唯一出现的。
除了上面计算的item之间的共现概率外,我们还希望,属性ID和itemID之间也要满足一定的关系,简单理解就是希望itemID和其对应的属性ID关系越近越好,于是定义:
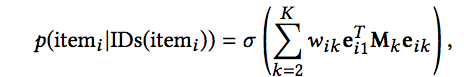
由于每种Embedding长度不同,使用Mk来进行线性变换为一样的长度。
于是,我们期望最大化的式子为:
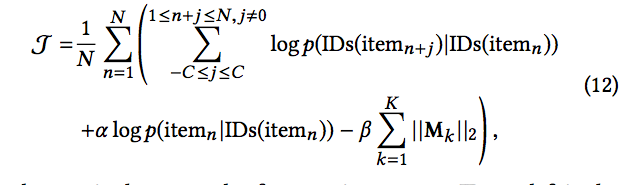
此时,对于新的物品,同样通过其side-information来表示其embedding:
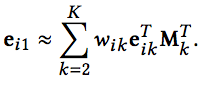
关于该方法更多的介绍,参考文章:推荐系统遇上深度学习(三十六)-Learn and Transferr IDs Repre in E-commerce
3、TDM:Learning Tree-based Deep Model for Recommender Systems
推荐系统中的召回策略主要有协同过滤、向量化召回。使用协同过滤进行召回的时候,并不能真正的面向全量商品库来做检索,如itemCF方法,系统只能在用户历史行为过的商品里面找到侯选的相似商品来做召回,使得整个推荐结果的多样性和发现性比较差。向量化召回是目前推荐召回核心发展的一代技术,但是它对模型结构做了很大的限制,必须要求模型围绕着用户和向量的embedding展开,同时在顶层进行内积运算得到相似性。
基于上面的缺点,阿里提出了深度树匹配的召回策略。深度树匹配的核心是构造一棵兴趣树,其叶子结点是全量的物品,每一层代表一种细分的兴趣:
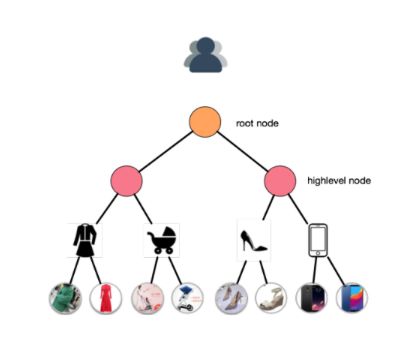
接下来,我们主要介绍三个方面的内容:
1)怎么基于树来实现高效的检索
2)怎么在树上面做兴趣建模
3)兴趣树是怎么构建的
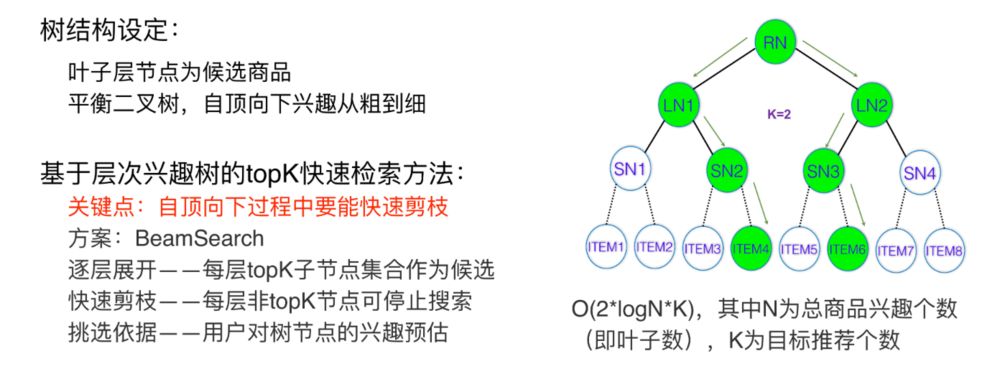
3.1 怎么基于树来实现高效的检索
在这里,假设已经得到深度树的情况下,高效检索采用的是Beam-Search的方式:
3.2 怎么在树上面做兴趣建模
在已经得到深度树的情况下,一个新来的用户,我们怎么知道他对哪个分支的兴趣更大呢?我们首先需要将树建立为一棵最大堆树。
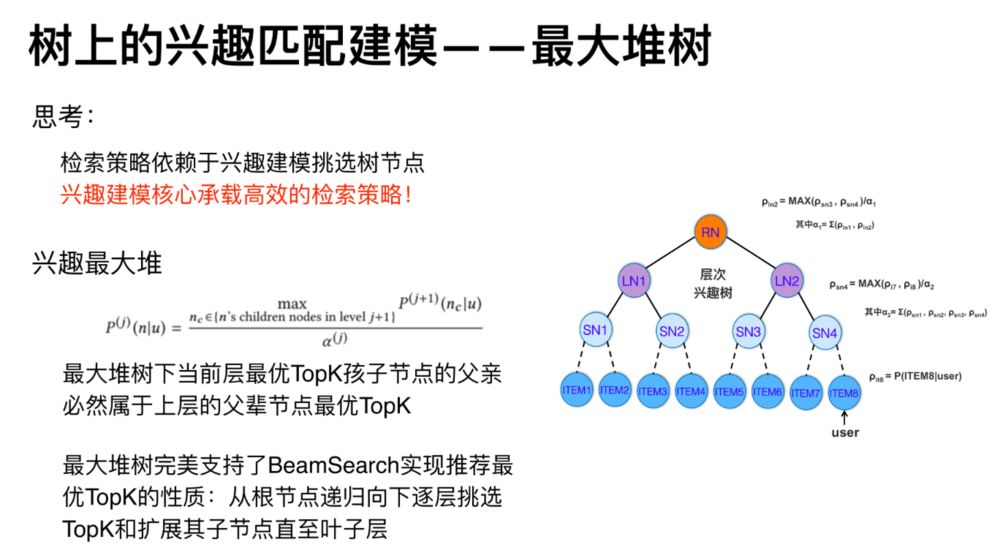
在实践中,构造最大堆树可以举个简单的例子,假设用户对叶子层 ITEM6 这样一个节点是感兴趣的,那么可以认为它的兴趣是 1,同层其他的节点兴趣为 0,从而也就可以认为 ITEM6 的这个节点上述的路径的父节点兴趣都为 1,那么这一层就是 SN3 的兴趣为 1,其他的为 0,这层就是 LN2 的兴趣为 1,其他为 0。如下图所示:
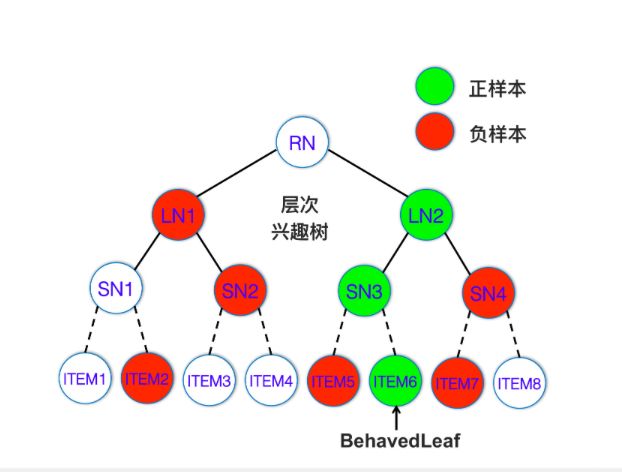
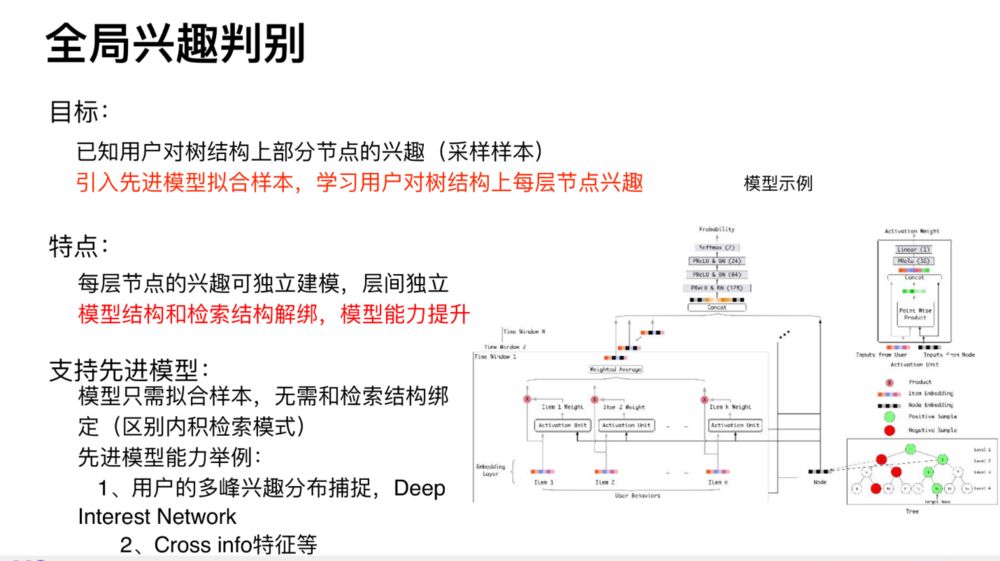
当建立起如上的树之后,我们就可以在每一层构建一定的正负样本,通过构建模型来学习用户对于每一层节点的兴趣偏好。注意的是,每层的偏好都要学习,也就是说每层都要构建一个模型。同时,模型只需要关心是否足够拟合样本就可以了,并没有要求模型一定要把用户特征和 item 特征转换为顶层向量内积的形式,这样就给了模型很大的自由度,只要去拟合好足够的样本,那么任意的模型都是 OK 的。下面是一个模型的示例:
3.3 兴趣树是怎么构建的
前面两个问题,都是在给定树结构的情况下来介绍的,那么怎么来构建一棵兴趣树呢?每层是怎么分叉的呢?
树的叶节点对应具体的 item,目标是构建一个好的树结构来优化我们的检索效果。通过前面的分析知道,在进行兴趣建模时,对于叶子层的样本我们通过用户行为反馈得到,而中间层的样本则通过树结构采样得到。所以树结构决定了中间层的样本。
在进行快速检索时,采用从顶向下的检索策略,利用的是对每一层节点兴趣建模进行快速剪枝。要保证最终的检索效果,就需要每一层的兴趣判别模型能力足够强。由于树结构负责我们中间层的样本生成,所以我们的思路是通过优化树结构影响样本生成进而提升模型能力。具体来说,通过树结构优化降低中间层的样本混淆度,让中间层样本尽可能可分。
所以,整个树结构的生成创建和优化的过程,实际上是围绕着怎么来生成更好的样本、帮助模型学习的视角进行的,而不是只是考虑相似、聚类这样的模式。那么这里的核心方案是什么呢?
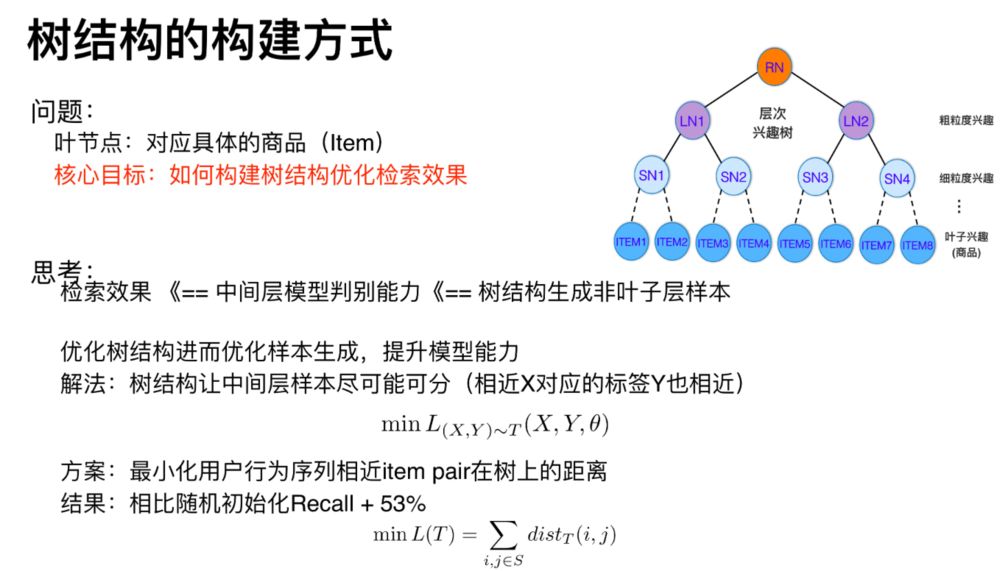
方案总结来说,就是最小化用户行为序列中相近的item-pair在树上的距离。假设用户的行为序列为A-》B-》D-》C,那么我们希望(A,B),(B,D),(D,C)在树上的距离越近越好。两个叶子结点的距离通过其最近的公共祖先确定。
好了,到这里,对深度树匹配模型做一个简单的总结:
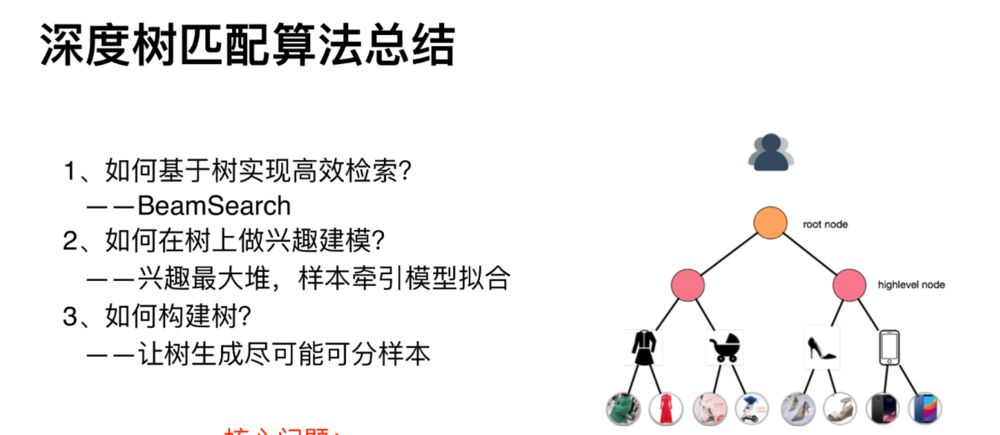
关于该方法更多的介绍,参考文章:推荐系统遇上深度学习(三十九)-推荐系统中召回策略演进!
4、Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction
这篇文章介绍的方法就是我们所熟知的MLR(mixed logistic regression)算法。MLR可以看做是对LR的一个自然推广,它采用分而治之的思路,用分片线性的模式来拟合高维空间的非线性分类面,其形式化表达如下:
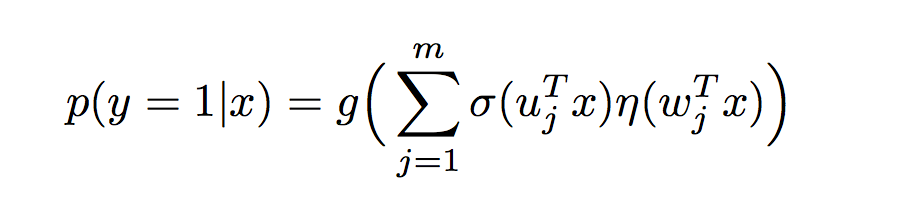
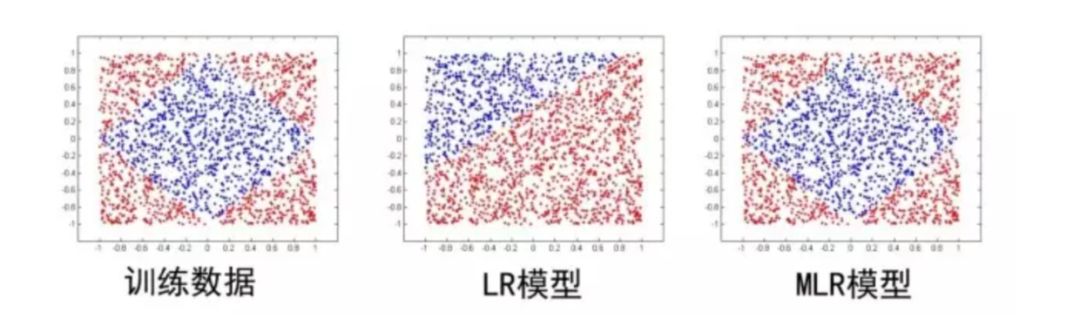
其中u是聚类参数,决定了空间的划分,w是分类参数,决定空间内的预测。这里面超参数分片数m可以较好地平衡模型的拟合与推广能力。当m=1时MLR就退化为普通的LR,m越大模型的拟合能力越强,但是模型参数规模随m线性增长,相应所需的训练样本也随之增长。因此实际应用中m需要根据实际情况进行选择。例如,在阿里的场景中,m一般选择为12。下图中MLR模型用4个分片可以完美地拟合出数据中的菱形分类面。
在实际中,MLR算法常用的形式如下,使用softmax作为分片函数:
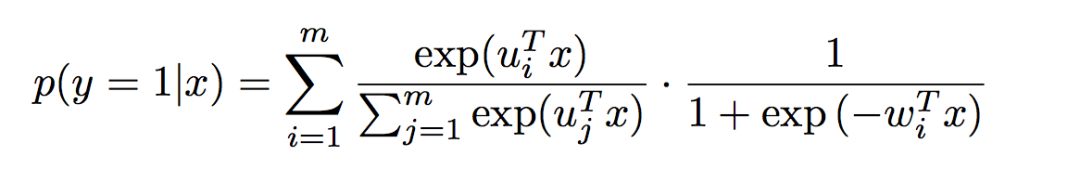
关于损失函数的设计,采用了logloss以及L1,L2正则,形式如下:
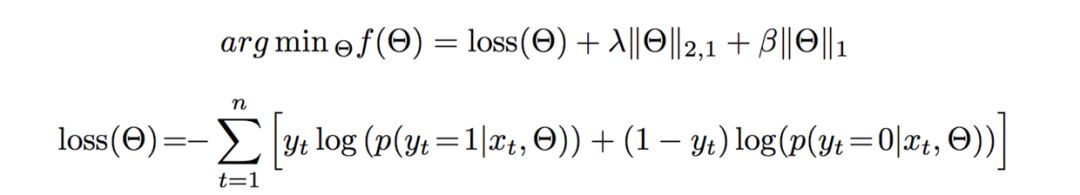
关于该方法更多的介绍,参考文章:推荐系统遇上深度学习(十七)--探秘阿里之MLR算法浅析及实现
5、Deep Interest Network for Click-Through Rate Prediction
阿里相关人员通过观察收集到的线上数据,发现了电商领域用户行为数据中两个很重要的特性,分别是Diversity和Local activation。Diversity指用户在浏览电商网站的过程中显示出的兴趣是十分多样性的;Local activation指由于用户兴趣的多样性,只有部分历史数据会影响到当次推荐的物品是否被点击,而不是所有的历史记录。
针对上面提到的用户行为中存在的两种特性,阿里将其运用于自身的推荐系统中,推出了深度兴趣网路DIN,其架构如下:
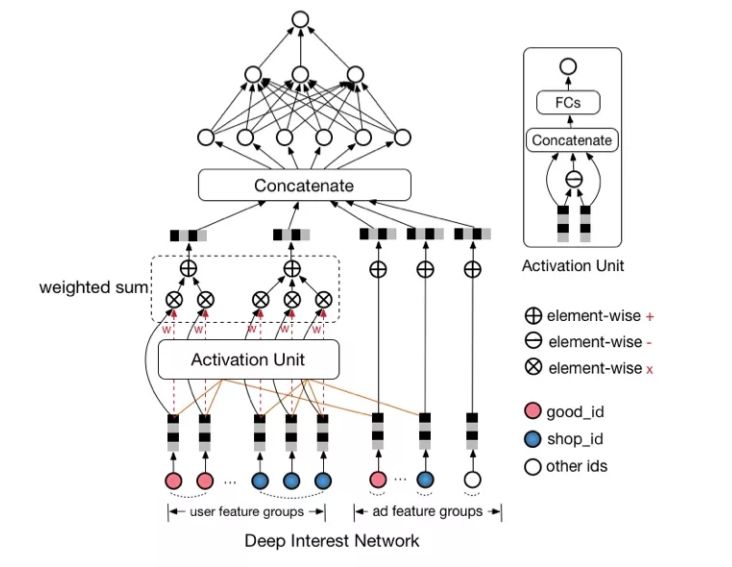
DIN模型结构相对还是简单的,用户历史行为序列中每一个物品都对应着物品ID和店铺ID,目标物品(广告)也有物品ID和店铺ID,物品ID和店铺ID都会转换为对应的Embedding。随后,行为序列中物品ID对应的Embedding会分别与目标物品ID的Embedding计算attention score,并根据attention score求加权平均;行为序列中物品对应店铺ID的Embedding会分别与目标物品对应店铺ID的Embedding计算attention score,并根据attention score求加权平均。最后,所有的向量拼接后,通过全连接神经网络得到最终的输出。
关于该方法更多的介绍,参考文章:推荐系统遇上深度学习(十八)--探秘阿里之深度兴趣网络(DIN)浅析及实现
6、Deep Interest Evolution Network for Click-Through Rate Prediction
DIN中存在两个缺点,首先用户的兴趣是不断进化的,而DIN抽取的用户兴趣之间是独立无关联的,没有捕获到兴趣的动态进化性,其次是通过用户的显式的行为来表达用户隐含的兴趣,这一准确性无法得到保证。
基于以上两点,阿里提出了深度兴趣演化网络DIEN来CTR预估的性能,其模型结构如下:
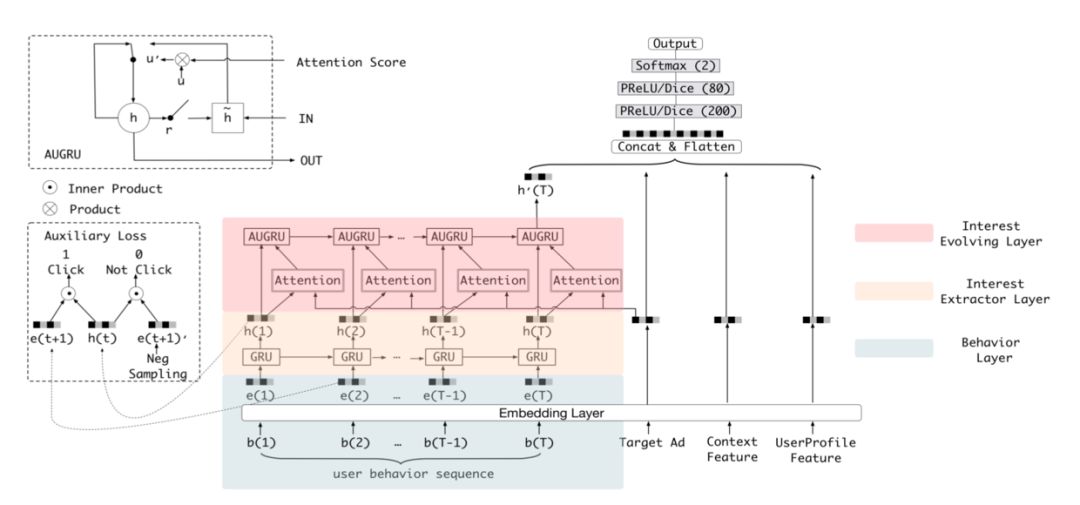
DIEN
DIEN中包含Embedding层、兴趣抽取层Interest Extractor Layer、兴趣进化层Interest Evolution Layer和全连接层。
兴趣抽取层Interest Extractor Layer的主要目标是从embedding数据中提取出interest。但一个用户在某一时间的interest不仅与当前的behavior有关,也与之前的behavior相关,所以作者们使用GRU单元来提取interest。在兴趣抽取层,为了判定兴趣是否表示的合理,文中别出心裁的增加了一个辅助loss,来提升兴趣表达的准确性:

这里,作者设计了一个二分类模型来计算兴趣抽取的准确性,我们将用户下一时刻真实的行为e(t+1)作为正例,负采样得到的行为作为负例e(t+1)',分别与抽取出的兴趣h(t)结合输入到设计的辅助网络中,得到预测结果,并通过logloss计算一个辅助的损失。
兴趣进化层Interest Evolution Layer的主要目标是刻画用户兴趣的进化过程。用户的兴趣在变化过程中遵循如下规律:1)interest drift:用户在某一段时间的interest会有一定的集中性。比如用户可能在一段时间内不断买书,在另一段时间内不断买衣服。2)interest individual:一种interest有自己的发展趋势,不同种类的interest之间很少相互影响,例如买书和买衣服的interest基本互不相关。为了利用这两个时序特征,这里通过attention机制以找到与target AD相关的interest。同时把attention score加入到GRU单元中。
关于该方法更多的介绍,参考文章:推荐系统遇上深度学习(二十四)--深度兴趣进化网络DIEN原理及实战!
7、Deep Session Interest Network for Click-Through Rate Prediction
从用户行为中呢,我们发现,在每个会话中的行为是相近的,而在不同会话之间差别是很大的。为了刻画这种与行为密切相关的行为表现,阿里提出了深度会话兴趣网络Deep Session Interest Network。其模型结构如下:
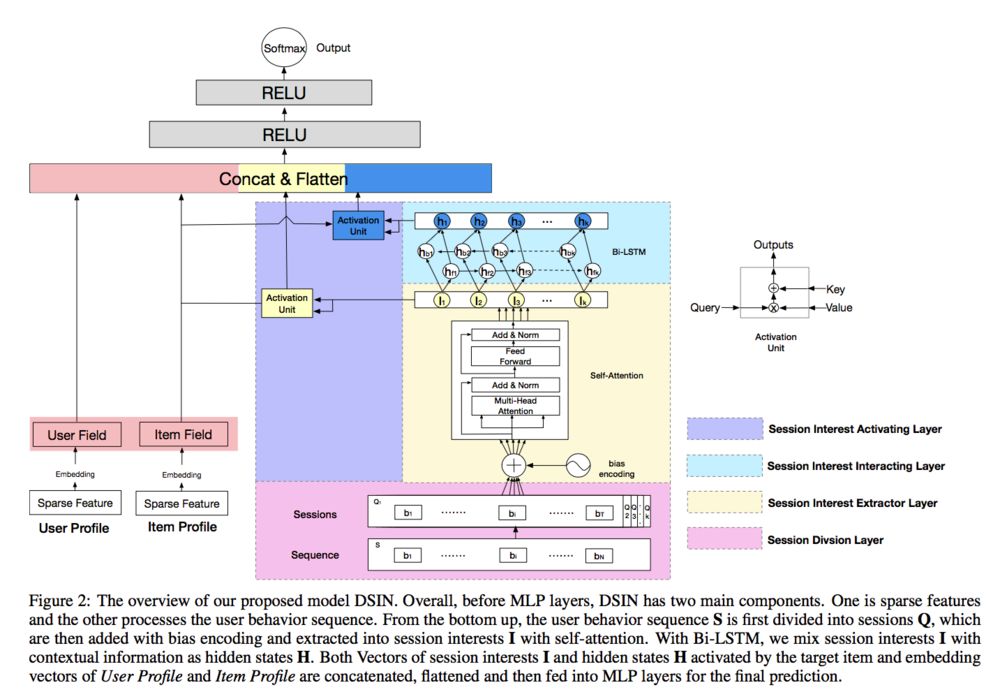
DSIN在全连接层之前,分成了两部分,左边的那一部分,将用户特征和物品特征转换对应的向量表示,这部分主要是一个embedding层。右边的那一部分主要是对用户行为序列进行处理,从下到上分为四层:
1)序列切分层session division layer
2)会话兴趣抽取层session interest extractor layer
3)会话间兴趣交互层session interest interacting layer
4)会话兴趣激活层session interest acti- vating layer
Session Division Layer这一层将用户的行文进行切分,首先将用户的点击行为按照时间排序,判断每两个行为之间的时间间隔,前后的时间间隔大于30min,就进行切分。切分后,我们可以将用户的行为序列S转换成会话序列Q。第k个会话Qk=[b1;b2;...;bi;...;bT],其中,T是会话的长度,bi是会话中第i个行为,是一个d维的embedding向量。所以Qk是T * d的。而Q,则是K * T * d的
在Session Interest Extractor Layer,使用transformer对每个会话的行为进行处理。同时在Transformer中,对输入的序列会进行Positional Encoding。经过Transformer处理之后,经过一个avg pooling操作,将每个session兴趣转换成一个d维向量。
在Session Interest Interacting Layer,通过一个双向LSTM(bi-LSTM)来获取用户的会话兴趣,得到的隐藏层状态Ht,我们可以认为是混合了上下文信息的会话兴趣。
在Session Interest Activating Layer,通过注意力机制来刻画用户的会话兴趣与目标物品的相关性,attention分成了两个部分,分别是目标物品与原始会话兴趣的相关性(没有通过bi-LSTM前的会话向量)以及目标物品与混合了上下文信息的会话兴趣(通过bi-LSTM后得到的隐藏层向量)的相关性。
最后的话,就是把四部分的向量:用户特征向量、待推荐物品向量、会话兴趣加权向量UI、带上下文信息的会话兴趣加权向量UH进行横向拼接,输入到全连接层中,得到输出。
关于该方法更多的介绍,参考文章:推荐系统遇上深度学习(四十五)-探秘阿里之深度会话兴趣网络DSIN
8、Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
为了能够将用户行为序列以及序列中商品与待推荐商品之间的相关性等因素加入到模型中,阿里尝试用NLP领域中大放异彩的Transformer模型来做推荐任务,提出了Behavior Sequence Transformer,简称BST模型,其整体的架构如下:
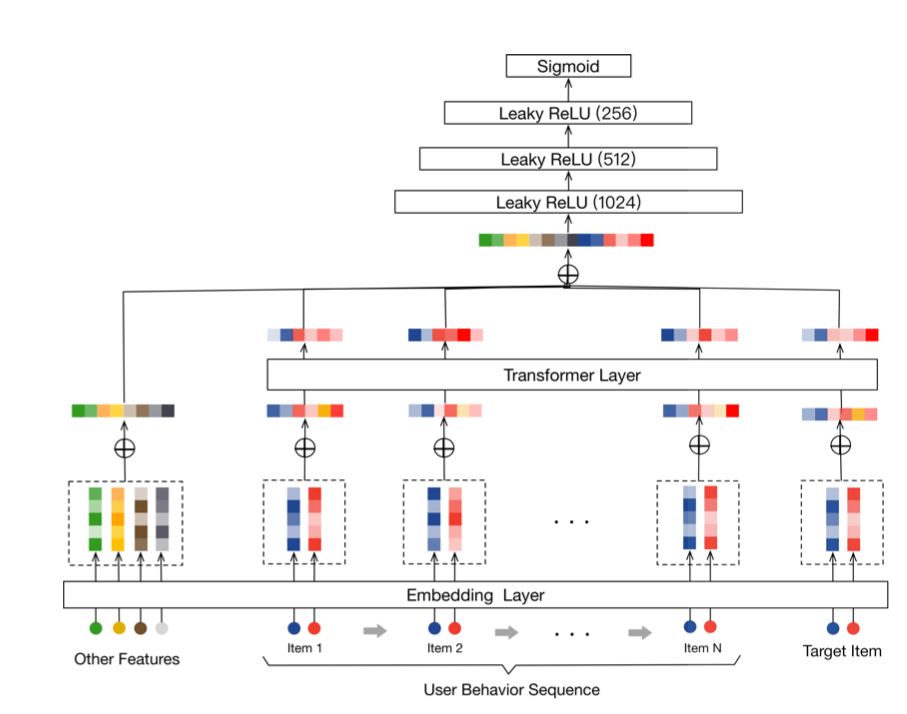
模型分为Embedding Layer、Transformer Layer和MLP Layer
为了将行为序列信息加入到模型中,在Embedding Layer中,加入了位置特征的Embedding,第i个位置的位置特征计算方式为pos(vi)=t(vt)-t(vi),其中,t(vt) 表示推荐的时间戳,t(vi) 表示用户点击商品vi时的时间戳。至于如何将一个时间戳转化为低维向量,可能是进行离散化后再转化为embedding。
在Transformer Layer,并不是只有行为序列中商品来做multi-head attention,待推荐的商品也会加入其中,这样其实就包含了行为序列中商品与待推荐商品之间的相关性。
关于该方法更多的介绍,参考文章:推荐系统遇上深度学习(四十八)-BST:将Transformer用于淘宝电商推荐
9、Entire Space Multi-Task Model: An E ective Approach for Estimating Post-Click Conversion Rate
本文介绍的是一个Multi-Task的方法,称为ESMM。其关注的焦点是CVR预估,CVR代表从点击到购买的转化。不过传统的CVR预估问题存在着两个主要的问题:样本选择偏差和稀疏数据。如下图:
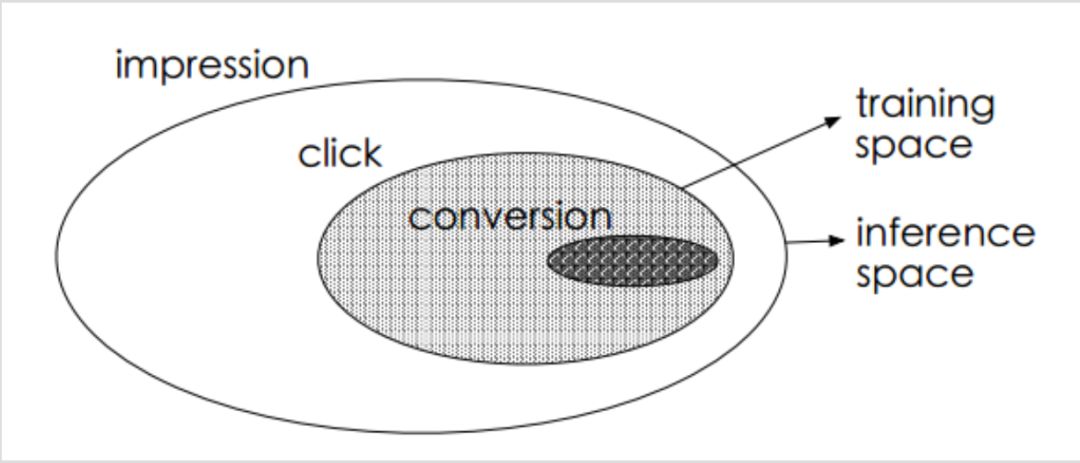
样本选择偏差(sample selection bias,SSB)指训练模型仅通过有点击行为的样本空间即途中灰色椭圆部分来进行,但训练好的模型是在整个样本空间X去做推断的。数据稀疏(data sparsity,DS)指点击行为的样本空间相对于整个样本空间来说是很小的。
ESMM模型借鉴了多任务学习的思路,引入了两个辅助的学习任务,分别用来拟合pCTR和pCTCVR,从而同时消除了上文提到的两个挑战。ESMM模型能够充分利用用户行为的顺序性模式,其模型架构下图所示:
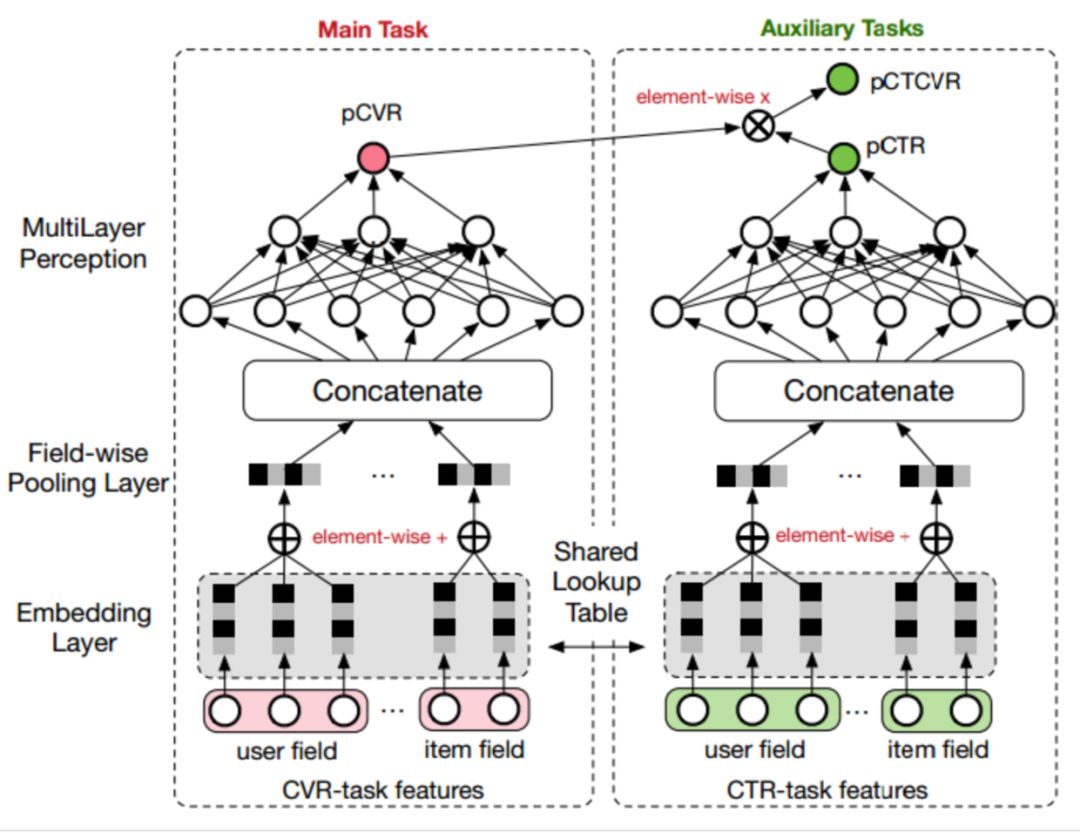
可以看到,ESMM模型由两个子网络组成,左边的子网络用来拟合pCVR,右边的子网络用来拟合pCTR,同时,两个子网络的输出相乘之后可以得到pCTCVR。因此,该网络结构共有三个子任务,分别用于输出pCTR、pCVR和pCTCVR。
假设我们用x表示feature(即impression),y表示点击,z表示转化,那么根据pCTCVR = pCTR * pCVR,可以得到:
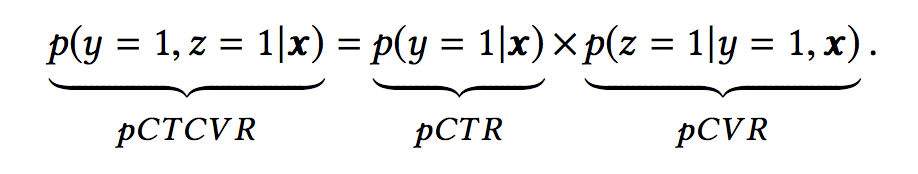
将乘法转化为除法,我们可以得到pCVR的计算:
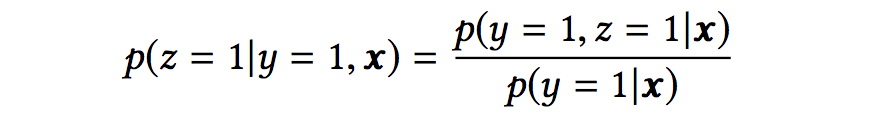
由上面提到的等式可以看出,pCVR是可以通过pCTR和pCTCVR的预估推导出来的。因此,我们只需要关注pCTR和pCTCVR两个任务即可。为什么是这两个任务呢?其实就是为了消除样本选择偏差嘛,因为CVR是从click到conversion,而CTCVR是从impression到conversion,CTR是从impression到conversion,所以CTR和CTCVR都可以从整个样本空间进行训练,一定程度的消除了样本选择偏差。
(*本文由 AI科技大本营转载,转载请联系原作者)
◆
精彩推荐
◆
6月29-30日,2019以太坊技术及应用大会 特邀以太坊创始人V神与以太坊基金会核心成员,以及海内外知名专家齐聚北京,聚焦前沿技术,把握时代机遇,深耕行业应用,共话以太坊2.0新生态。
扫码或点击阅读原文,既享优惠购票!

推荐阅读
Python从入门到精通,这篇文章为你列出了25个关键技术点(附代码)
IEEE“撑不住”了?声明解除对华为评审限制
基础必备 | Python处理文件系统的10种方法
如何正确的获取数据?
Chrome 成为互联网看门人?!
从沉迷游戏到信奥冠军、保送清华,这位天才少年是如何做到的?| 人物志
刚刚,Python内幕被爆出!老码农:没控制住,心态已崩!
被小公司毁掉的名校毕业生 | 程序员有话说
Unix风雨五十年:老兵远去,新秀崛起
如何在厕所、垃圾桶或小树林捡一枚BCH?看完后我笑了...

点击阅读原文,查看更多精彩内容。
相关文章:

ReSharper修改命名风格
默认情况下,ReSharper会建议你全局变量命名使用下划线开头,且第一个字母小写。否则,会给你标记出来,如下: 但我个人不喜欢这种风格,一般使用首字母大写且不带下划线,可以通过配置来调整…

【Qt】Log4Qt(一)下载、编译
Log4Qt(一)下载、编译 1、下载2、编译2.1 单独编译成库2.2 将源码添加到项目中2.2.1 log4qt.pri分析2.2.2 pro示例如下1、下载 github上星最多的是这个:https://github.com/MEONMedical/Log4Qt 下载log4qt最新(截止2021-12-04)的稳定版本v1.5.1(Qt版本需要Qt5.7.0以上)…
android:退出程序
http://kofi1122.blog.51cto.com/2815761/703751 使用的是定义全局变量的方法

ubuntu中使用apt命令安装ipython失败解决方案
在最近使用ubuntu安装ipython时,出现如下报错: 出现这个问题,主要是因为apt还在运行,故解决方案为: 1、找到并且杀掉所有的apt-get 和apt进程 运行下面的命令来生成所有含有 apt 的进程列表,使用ps和grep命…
【Qt】Log4Qt(二)使用
Log4Qt(二)使用 1、使用TTCCLayout 格式化输出1.1 添加头文件1.2 配置根记录器的输出格式1.3 注册记录器,并输出日志2、最简代码3、将日志写入文件4、使用配置文件:log4qt.properties5、使用配置文件:QSettings6、周期性生成日志文件7、滚动生成日志文件(可以指定日志文件…

B站超全分享!2万人收藏的免费计算机科学速成课
整理 | 一一出品 | AI科技大本营(ID:rgznai100)作为一枚程序员,很多人可能都不太能清晰地说出计算机发展脉络,要想成为优秀的程序员,只会编程是不够的。“读史使人明智”,我们还要了解计算机理论知识&#…

图说:Windows 8使用搜索,快速开启应用
在Windows 8中,“开始菜单”变成的“开始屏幕”,想快速找到需要的应用不是件容易的事,毕竟桌面可以安装太多的应用。 怎么快速找到需要的应用的,其实方法也非常简单,只需在“开始屏幕”下使用键盘,键入需要…

一个可以卷起来的蓝牙键盘,简直是办公码字神器!
作为一个办公室码字党,熊大大一直觉得ipad最大的bug就是码字不方便。以前,我每次码字都会把平板先平放,打字才能顺手╮(╯﹏╰)╭后来买了蓝牙键盘,码字方便了,但键盘又大又厚重,日常携带巨不方…

比较v-bind和v-model
简单来说,区别如下:1.v-bind用来绑定数据和属性以及表达式,缩写为:2.v-model使用在表单中,实现双向数据绑定的,在表单元素外使用不起作用 一、v-model v-model多在表单中使用,在表单元素上创建双…
【Qt】Log4Qt(四):周期性输出日志,并且限制日志文件数量
在Log4Qt中存在一个比较大的问题,当使用 DailyRollingFileAppender对日志进行输出时,会无限输出文件,也就是说,当系统运行很久时,日志文件有可能很大,大到无法想象。因此,很多开发者希望在DailyRollingFileAppender中加一个属性,用于配置日志文件的个数。 1、dailyrol…

g13 root
1.官方解锁: 官方已经给出了wildfire S的解锁bootloader教程。需要注意的是,这个解锁之后虽然仍是s-on状态(但下边一行显示了unlock),不影响我们将来随意刷机,说白了就相当于s-off了。 准备工作,…
【Qt】Log4Qt(三)源码分析
Log4Qt(三)源码分析 1、分层架构1.1 核心对象1.2 支持对象2、源码分析2.1 宏2.1.1 LOG4QT_DECLARE_QCLASS_LOGGER2.1.2 LOG4QT_DECLARE_STATIC_LOGGER2.2类2.2.1 Log4Qt::ClassLogger2.2.2 LogManager2.2.3 PropertyConfigurator2.3 深入理解 rootLogger、logLogger、qtLogge…

GitHub五万星登顶,程序员命令行最全技巧宝典!
作者 | 唐小引封图 | CSDN出品 | CSDN(ID:CSDNnews)一个项目 Get 所有命令行技巧!最近两天,「The Art of Command Line(命令行的艺术)」这个开源项目雄踞了 GitHub TOP 榜,直接以 51…
开源硬件:极客们的伟大理想
自 Dennis Allison 在 1975 年发布它的 Tiny BASIC 以来,他倡导的开放、共享的思想得到了多数开发者的认同,这些年,软件开源取得了令人瞩目的成绩。同时,他那句 “让我们站在彼此的肩膀,而不是彼此的脚趾上。”也变成了…

五年12篇顶会论文综述!一文读懂深度学习文本分类方法
作者 | 何从庆来源 | AI算法之心(ID:AIHeartForYou)最近有很多小伙伴想了解深度学习在文本分类的发展,因此,笔者整理最近几年比较经典的深度文本分类方法,希望帮助小伙伴们了解深度学习在文本分类中的应用。…

Failed to fetch http://mirrors.cloud.aliyuncs.com/
服务器版本:阿里云 ubuntu 16.04 问题:阿里云安装软件时,提示 W: Failed to fetch http://mirrors.cloud.aliyuncs.com/ubuntu/dists/xenial/InRelea se Could not resolve mirrors.cloud.…
【FFmpeg】使用sws_scale将AVFrame转换后的图像数据放入cv::Mat中
1、方法一,伪代码如下 cv::Mat mat; AVFrame avFrame; const int stride[] = {static_cast<int>(mat.step[0])}; ret =

Android之Adapter用法总结
本文转自http://kb.cnblogs.com/a/2328334/,转载请注明原出处。 Android之Adapter用法总结 作者:Devin Zhang 来源:博客园 发布时间:2012-01-20 22:33 阅读:1193 次 原文链接 [收藏] 1.概念 Adapter是连接后端数…
【FFmpeg】ffmpeg命令详解(一)
ffmpeg命令详解(一) 1、命令格式2、简述3、详细说明3.1 过滤器3.1.1 简单的过滤器图3.1.2 复杂的过滤器图3.2 流拷贝1、命令格式 ffmpeg [global_options] {[input_file_options] -i input_url} ... {[output_file_options] output_url} ...global_options:全局选项 input_…

从流感预测到智能决策,深度学习能帮企业做哪些事?
未来将只有两种公司,一种是有人工智能的,一种是不赚钱的。这句话大概可以总结两层意思,一方面人工智能让更多的企业面对更广阔的商业前景,另一方面是如果要运用人工智能创造价值,就必须拥抱技术,实现真正的…
寻找隐形冠军 支付宝、微信用得那么溜,可谁知道背后有一名“上海功臣
下午三点半,离晚饭时间还有一段时间,可新沪路上的熟食店“尚老居”门口已经人头攒动。 “阿姨你来啦,今天要点什么?” “老样子,称点烧鹅和蹄髈,阿拉孙子老欢喜吃的,买好正好去接伊放学。” “阿…
Lnmp安装与配置笔记
——————————————安装与配置——————————————1.相关软件:yum -y install gcc gcc-c autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-…
【FFmpeg】ffmpeg命令详解(二)
ffmpeg命令详解(二) 4、流选择4.1 自动选择流4.2 手动选择流5、命令行选择详解5.1 命令行选项的值说明:5.2 流说明符5.3 通用选项5.4 主选项5.5 视频相关选项5.6 高级视频选项5.7 音频选项5.8 高级音频选项5.9 字幕选项5.10 高级字幕选项4、流选择 FFmpeg提供了“-map”选项…

谷歌开源张量网络库TensorNetwork,GPU处理提升100倍!
编译 | 琥珀出品 | AI科技大本营(ID:rgznai100)世界上许多最严峻的科学挑战,如开发高温超导体和理解时空的本质,都涉及处理量子系统的复杂性。然而,这些系统中量子态的数量程指数级增长,使得暴力计算并不可…

Python基础之逻辑运算符
1.在没有()的情况下,not的优先级高于and,and的优先级高于or,即优先级关系为()>not>and>or,同一优先级从左往右计算。 例题,判断下列逻辑语句的结果: 3 > 4 or 4 < 3 and 1 1 1 < 2 a…
《Android开发从零开始》——11.AbsoluteLayoutFrameLayout学习
本节课的主要内容有: 1.介绍AbsoluteLayout布局的使用 2.介绍FrameLayout布局的使用 课程下载地址:http://u.115.com/file/f15a9d5411 课件及地址:http://u.115.com/file/f1b56ce345 【转】转载于:https://blog.51cto.com/professor/1573001
【FFmpeg】ffmpeg命令详解(三)高级选项
ffmpeg命令详解(三)高级选项 1、-map2、-ignore_unknown3、-copy_unknown4、-map_channel5、-map_metadata6、-map_chapters7、-benchmark8、-benchmark_all9、-timelimit10、-dump11、-hex12、-readrate13、-re14、-vsync15、-frame_drop_threshold16、-async17、-adrift_th…
重磅!Google推出了Python最牛X的编辑器......
随着和大数据、人工智能绑定在一起,Python可畏是越来越厉害了!前几天, PYPL(即编程语言流行指数,基于 Google 搜索频率而定)出炉了 6 月编程语言排行榜,Python 拿下 NO.1,成为最流行的编程语言。…
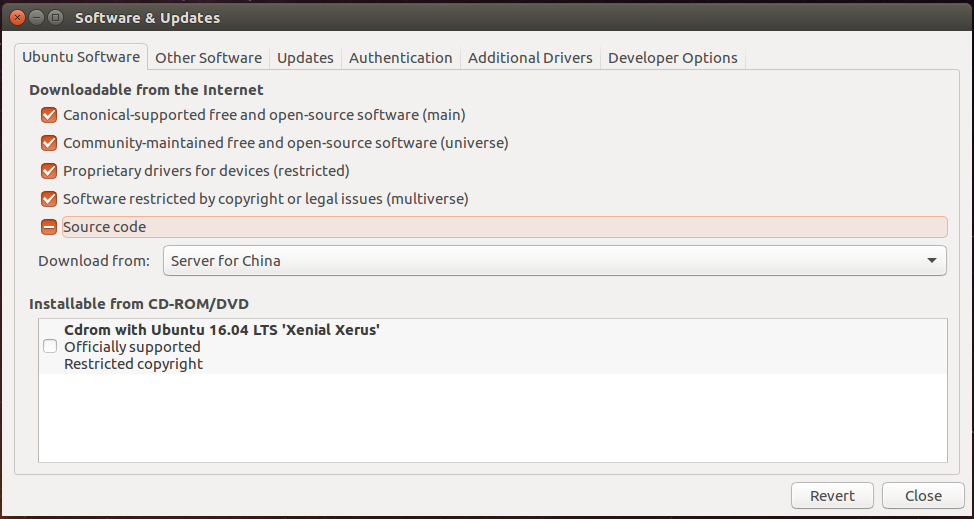
ubuntu16.04 ROS安转及RVIZ启动
1、软件中心配置 首先打开软件和更新对话框,打开后按照下图进行配置(确保你的"restricted", "universe," 和 "multiverse."前是打上勾的): 2、添加源 $ sudo sh -c echo &qu…
Ubuntu下自动挂载Windows分区的方法
用过Ubuntu的都知道,在Ubuntu开机时,Windows的文件系统是不会自动挂载的,每次开机都得手动挂载,确实不方便。多次的手动挂载实在是让我有些烦躁了,遂决定要让我的系统开机时自动挂载文件系统。看了一些网上的教程&…