媲美Pandas?一文入门Python的Datatable操作

作者 | Parul Pandey
译者 | linstancy
责编 | Jane
出品 | Python大本营(id:pythonnews)
【导读】工具包 datatable 的功能特征与 Pandas 非常类似,但更侧重于速度以及对大数据的支持。此外,datatable 还致力于实现更好的用户体验,提供有用的错误提示消息和强大的 API 功能。通过本文的介绍,你将学习到如何在大型数据集中使用 datatable 包进行数据处理,特别在数据量特别大的时候你可以发现它可能比 Pandas 更加强大。
前言
data.table 是 R 中一个非常通用和高性能的包,使用简单、方便而且速度快,在 R 语言社区非常受欢迎,每个月的下载量超过 40 万,有近 650 个 CRAN 和 Bioconductor 软件包使用它。如果你是 R 的使用者,可能已经使用过 data.table 包。
而对于 Python 用户,同样存在一个名为 datatable 包,专注于大数据支持、高性能内存/内存不足的数据集以及多线程算法等问题。 在某种程度上,datatable 可以被称为是 Python 中的 data.table。
Datatable初教程
为了能够更准确地构建模型,现在机器学习应用通常要处理大量的数据并生成多种特征,这已成为必要的。而 Python 的 datatable 模块为解决这个问题提供了良好的支持,以可能的最大速度在单节点机器上进行大数据操作 (最多100GB)。datatable 包的开发由 H2O.ai 赞助,它的第一个用户是 Driverless.ai。

接下来,我们就开始初体验一下 datatable 的简单使用。
安装
在 MacOS 系统上,datatable 包可以通过 pip 命令安装,如下图所示:
pip install datatable
在 Linux 平台上,安装过程需要通过二进制分布来实现,如下所示:
# If you have Python 3.5
pip install https://s3.amazonaws.com/h2o-release/datatable/stable/datatable-0.8.0/datatable-0.8.0-cp35-cp35m-linux_x86_64.whl
# If you have Python 3.6
pip install https://s3.amazonaws.com/h2o-release/datatable/stable/datatable-0.8.0/datatable-0.8.0-cp36-cp36m-linux_x86_64.whl很遗憾的是,目前 datatable 包还不能在 Windows 系统上工作,但 Python 官方也在努力地增加其对 Windows 的支持。更多的信息可以查看 Build instructions 的说明。
地址:
https://datatable.readthedocs.io/en/latest/install.html

数据读取
这里使用的数据集是来自 Kaggle 竞赛中的 Lending Club Loan Data 数据集, 该数据集包含2007-2015期间所有贷款人完整的贷款数据,即当前贷款状态 (当前,延迟,全额支付等) 和最新支付信息等。整个文件共包含226万行和145列数据,数据量规模非常适合演示 datatable 包的功能。
# Importing necessary Libraries
import numpy as np
import pandas as pd
import datatable as dt
首先将数据加载到 Frame 对象中,datatable 的基本分析单位是 Frame,这与Pandas DataFrame 或 SQL table 的概念是相同的:即数据以行和列的二维数组排列展示。
datatable 读取
%%time
datatable_df = dt.fread("data.csv")
____________________________________________________________________
CPU times: user 30 s, sys: 3.39 s, total: 33.4 s
Wall time: 23.6 s
如上图,fread() 是一个强大又快速的函数,能够自动检测并解析文本文件中大多数的参数,所支持的文件格式包括 .zip 文件、URL 数据,Excel 文件等等。此外,datatable 解析器具有如下几大功能:
能够自动检测分隔符,标题,列类型,引用规则等。
能够读取多种文件的数据,包括文件,URL,shell,原始文本,档案和 glob 等。
提供多线程文件读取功能,以获得最大的速度。
在读取大文件时包含进度指示器。
可以读取 RFC4180 兼容和不兼容的文件。
pandas 读取
下面,使用 Pandas 包来读取相同的一批数据,并查看程序所运行的时间。
%%time
pandas_df= pd.read_csv("data.csv")
___________________________________________________________
CPU times: user 47.5 s, sys: 12.1 s, total: 59.6 s
Wall time: 1min 4s
由上图可以看到,结果表明在读取大型数据时 datatable 包的性能明显优于 Pandas,Pandas 需要一分多钟时间来读取这些数据,而 datatable 只需要二十多秒。
帧转换 (Frame Conversion)
对于当前存在的帧,可以将其转换为一个 Numpy 或 Pandas dataframe 的形式,如下所示:
numpy_df = datatable_df.to_numpy()
pandas_df = datatable_df.to_pandas()下面,将 datatable 读取的数据帧转换为 Pandas dataframe 形式,并比较所需的时间,如下所示:
%%time
datatable_pandas = datatable_df.to_pandas()
___________________________________________________________________
CPU times: user 17.1 s, sys: 4 s, total: 21.1 s
Wall time: 21.4 s
看起来将文件作为一个 datatable frame 读取,然后将其转换为 Pandas dataframe比直接读取 Pandas dataframe 的方式所花费的时间更少。因此,通过 datatable 包导入大型的数据文件再将其转换为 Pandas dataframe 的做法是个不错的主意。
type(datatable_pandas)
___________________________________________________________________
pandas.core.frame.DataFrame帧的基础属性
下面来介绍 datatable 中 frame 的一些基础属性,这与 Pandas 中 dataframe 的一些功能类似。
print(datatable_df.shape) # (nrows, ncols)
print(datatable_df.names[:5]) # top 5 column names
print(datatable_df.stypes[:5]) # column types(top 5)
______________________________________________________________
(2260668, 145)
('id', 'member_id', 'loan_amnt', 'funded_amnt', 'funded_amnt_inv')
(stype.bool8, stype.bool8, stype.int32, stype.int32, stype.float64)也可以通过使用 head 命令来打印出输出的前 n 行数据,如下所示:
datatable_df.head(10)
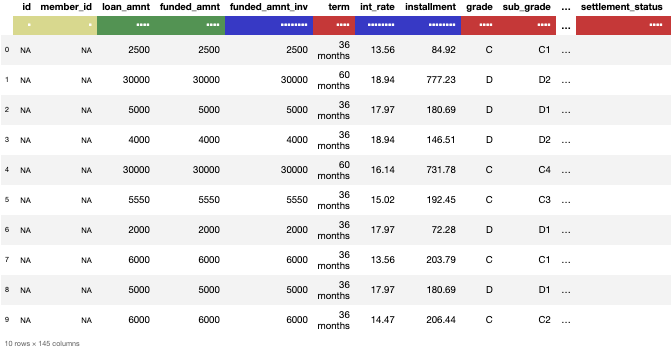
注意:这里用颜色来指代数据的类型,其中红色表示字符串,绿色表示整型,而蓝色代表浮点型。
统计总结
在 Pandas 中,总结并计算数据的统计信息是一个非常消耗内存的过程,但这个过程在 datatable 包中是很方便的。如下所示,使用 datatable 包计算以下每列的统计信息:
datatable_df.sum() datatable_df.nunique()
datatable_df.sd() datatable_df.max()
datatable_df.mode() datatable_df.min()
datatable_df.nmodal() datatable_df.mean()
下面分别使用 datatable 和Pandas 来计算每列数据的均值,并比较二者运行时间的差异。
datatable 读取
%%time
datatable_df.mean()
_______________________________________________________________
CPU times: user 5.11 s, sys: 51.8 ms, total: 5.16 s
Wall time: 1.43 s
Pandas 读取
pandas_df.mean()
__________________________________________________________________
Throws memory error.
可以看到,使用 Pandas 计算时抛出内存错误的异常。
数据操作
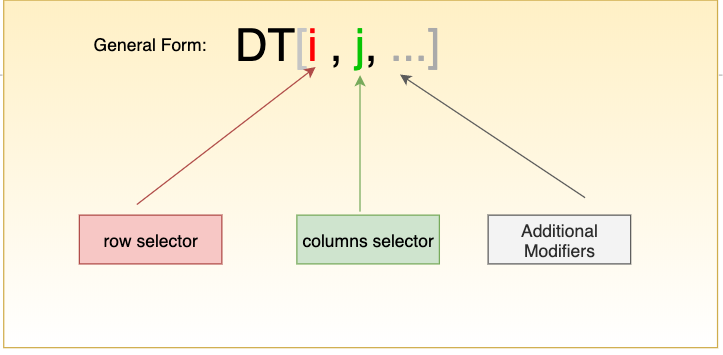
和 dataframe 一样,datatable 也是柱状数据结构。在 datatable 中,所有这些操作的主要工具是方括号,其灵感来自传统的矩阵索引,但它包含更多的功能。诸如矩阵索引,C/C++,R,Pandas,Numpy 中都使用相同的 DT[i,j] 的数学表示法。下面来看看如何使用 datatable 来进行一些常见的数据处理工作。
▌选择行/列的子集
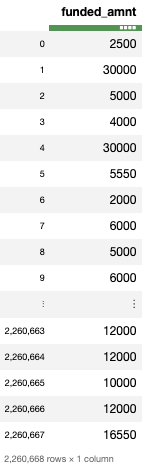
下面的代码能够从整个数据集中筛选出所有行及 funded_amnt 列:
datatable_df[:,'funded_amnt']
这里展示的是如何选择数据集中前5行3列的数据,如下所示:
datatable_df[:5,:3]

▌帧排序
datatable 排序
在 datatable 中通过特定的列来对帧进行排序操作,如下所示:
%%time
datatable_df.sort('funded_amnt_inv')
_________________________________________________________________
CPU times: user 534 ms, sys: 67.9 ms, total: 602 ms
Wall time: 179 ms
Pandas 排序
%%time
pandas_df.sort_values(by = 'funded_amnt_inv')
___________________________________________________________________
CPU times: user 8.76 s, sys: 2.87 s, total: 11.6 s
Wall time: 12.4 s可以看到两种包在排序时间方面存在明显的差异。
▌删除行/列
下面展示如何删除 member_id 这一列的数据:
del datatable_df[:, 'member_id']
▌分组 (GroupBy)
与 Pandas 类似,datatable 同样具有分组 (GroupBy) 操作。下面来看看如何在 datatable 和 Pandas 中,通过对 grade 分组来得到 funded_amout 列的均值:
datatable 分组
%%time
for i in range(100): datatable_df[:, dt.sum(dt.f.funded_amnt), dt.by(dt.f.grade)]
____________________________________________________________________
CPU times: user 6.41 s, sys: 1.34 s, total: 7.76 s
Wall time: 2.42 s
pandas 分组
%%time
for i in range(100): pandas_df.groupby("grade")["funded_amnt"].sum()
____________________________________________________________________
CPU times: user 12.9 s, sys: 859 ms, total: 13.7 s
Wall time: 13.9 s▌.f 代表什么
在 datatable 中,f 代表 frame_proxy,它提供一种简单的方式来引用当前正在操作的帧。在上面的例子中,dt.f 只代表 dt_df。
▌过滤行
在 datatable 中,过滤行的语法与GroupBy的语法非常相似。下面就来展示如何过滤掉 loan_amnt 中大于 funding_amnt 的值,如下所示。
datatable_df[dt.f.loan_amnt>dt.f.funded_amnt,"loan_amnt"]▌保存帧
在 datatable 中,同样可以通过将帧的内容写入一个 csv 文件来保存,以便日后使用。如下所示:
datatable_df.to_csv('output.csv')有关数据操作的更多功能,可查看 datatable 包的说明文档
地址:
https://datatable.readthedocs.io/en/latest/using-datatable.html
总结
在数据科学领域,与默认的 Pandas 包相比,datatable 模块具有更快的执行速度,这是其在处理大型数据集时的一大优势所在。 然而,就功能而言,目前 datatable 包所包含的功能还不如 pandas 完善。相信在不久的将来,不断完善的 datatable 能够更加强大。
本文所涉及的代码可以从 Github 或 binder 上获取:
Github 地址:
https://github.com/parulnith/An-Overview-of-Python-s-Datatable-package)
binder 地址:
https://mybinder.org/v2/gh/parulnith/An-Overview-of-Python-s-Datatable-package/master?filepath=An%20Overview%20of%20Python%27s%20Datatable%20package.ipynb
原文链接:
https://towardsdatascience.com/an-overview-of-pythons-datatable-package-5d3a97394ee9
(*本文为 AI科技大本营转载文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
大会开幕倒计时6天!
2019以太坊技术及应用大会特邀以太坊创始人V神与众多海内外知名技术专家齐聚北京,聚焦区块链技术,把握时代机遇,深耕行业应用,共话以太坊2.0新生态。即刻扫码,享优惠票价。

推荐阅读
华为最强自研NPU问世,麒麟810“抛弃”寒武纪
真正的博士是如何参加AAAI, ICML, ICLR等AI顶会的?
Python最抢手、Java最流行、Go最有前途,7000位程序员揭秘2019软件开发现状
程序员学Python编程或许不知的十大提升工具
不要让 Chrome 成为下一个 IE!
这位博士跑赢“地震波”:提前 10 秒预警宜宾地震!
一张图告诉你到底学Python还是Java!
鸿蒙将至,安卓安否?
25岁创立加密城堡, 曾经独角兽创始人社会名流天才黑客是这里的沙发客, 如今却无人问津……
352万帧标注图片,1400个视频,亮风台推最大单目标跟踪数据集
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

java并发编程——并发容器类介绍
2019独角兽企业重金招聘Python工程师标准>>> 并发容器的简单介绍 JDK5中添加了新的concurrent包,相对同步容器而言,并发容器通过一些机制改进了并发性能。因为同步容器将所有对容器状态的访问都串行化了,这样保证了线程的安全性&a…

CV_IMAGE_ELEM参数赋值时注意的问题
转自:http://hi.baidu.com/wangruiy01/blog/item/041ab03e8abd33c57d1e71a0.html CV_IMAGE_ELEM是一个宏, #define CV_IMAGE_ELEM( image, elemtype, row, col ) /(((elemtype*)((image)->imageData (image)->widthStep*(row)))[(col)])#define …
公司内部exchange2010 下删除误发邮件
1、Add-PSSnapin Microsoft.Exchange.Management.PowerShell.E20102、get-mailbox | search-mailbox -SearchQuery 填写误发邮件标题 -TargetMailbox "administrator" -TargetFolder "SearchAndDeleteLog" -DeleteContent转载于:https://blog.51cto.com/wo…

从代码设计到应用开发,入坑深度学习看这本书就够了
深度学习(Deep Learning)是机器学习中一种基于对数据进行表征学习的方法。近年来,深度学习已经在科技界、工业界日益广泛地应用。随着全球各领域多样化数据的极速积累和计算资源的成熟化商业服务,深度学习已经成为人工智能领域最有…
小波矩特征提取matlab代码
这是我上研究生时写的小波矩特征提取代码: %新归一化方法小波矩特征提取---------------------------------------------------------- Fimread(a1.bmp);Fim2bw(F);Fimresize(F,[128 128]);%求取最上点for i1:128 for j1:128 if (F(i,j)1) yt…
hadoop生态搭建(3节点)-06.hbase配置
# http://archive.apache.org/dist/hbase/1.2.4/ # 安装 hbase tar -zxvf ~/hbase-1.2.4-bin.tar.gz -C /usr/local rm –r ~/hbase-1.2.4-bin.tar.gz # 配置环境变量# node1 node2 node3 vi /etc/profile# 在export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL下添…

异类框架BigDL,TensorFlow的潜在杀器!
作者 | Nandita Dwivedi译者 | 风车云马责编 | Jane出品 | AI 科技大本营(id:rgznai100)【导读】你能利用现有的 Spark 集群构建深度学习模型吗?如何分析存储在 HDFS、Hive 和 HBase 中 tb 级的数据吗?企业想用深度学习…
对IsUnderPostmaster变量初步学习
开始 在postmaster.c 中的 BackendStartup 中,有如下的代码: 其中定义了 IsUnderPostmastertrue。 而bgwriter 作为 postmaster 的子进程,它的 IsUnderPostmaster 也是为真。 * BackendStartup -- start backend process** returns: STATUS_…
C++读写ini配置文件GetPrivateProfileString()WritePrivateProfileString()
转自:http://hi.baidu.com/andywangcn/blog/item/10ba730f48160eeb37d122e9.html 配置文件中经常用到ini文件,在VC中其函数分别为: #include <Windows.h> //wince,WMobile.ppc不支持这几个函数 写入.ini文件:bool WritePriv…

地图下载2之天超图瓦片格式
接上一篇《地图下载1之天地图瓦片解析》,我们已经知道了天地图的瓦片格式,现在来分析一下超图中瓦片的存储结构。 其实,在GIS领域,只有像ESRI这样强大公司的SHP文件等能通用外,很多数据、格式等都不通用,都…
server 2003登录界面黑屏的解决办法
1、备份注册表(为了安全起见)具体办法:开始-> 运行窗口输入“regedit.exe”->回车->找到注册表->文件->导出->完成; 2、复制下面的文件内容到记事本然后另存为格式为.reg注册表扩展名导入注册表; Wi…

“学了半年后,我要揭开Python 3宗罪!”
有人曾说,未来只有2种人,会Python的人和....不懂Python的小学生,虽有夸张,这也意味着Python越来越重要了,究竟这门语言厉害在哪里?以下为你总结了Python3宗“罪”!Python凭啥这么优秀࿱…
连表/子查询/计算的sql
看不懂的sql语句 1.select om.*,money,cus.c_type,cus.c_weixin_name,isnull(cus.c_discount,0) c_discount,isnull(om.o_money-om.o_money*cus.c_discount,0) money1,isnull(money*(i_year_pointi_month_potinti_piece_point),0) money2,isnull((om.o_money-om.o_money*cus.c_…
vc6静态库的生成和调用
1、静态库的生成: 在vc6.0中CtrlN选择Projects下的Win32 Static Library,Project name:SumLib,点击OK,下一页中的两项可选可不选,点击Finish完成。 在此工程中新建lib.h和lib.cpp两个文件,源码如下: //lib.…

实例变量的访问及数据封装
你已经看到处理分数的方法如何通过名称直接访问两个实例变量numerator和denominator。事实上,实例方法总是可以直接访问它的实例变量的。然而,类方法则不能,因为它只处理本身,并不处理任何类实例(仔细想想)…

清华成立视觉智能研究中心,邓志东任中心主任
整理 | 阿司匹林出品 | AI科技大本营(ID: rgznai100)6月21日,清华大学人工智能研究院视觉智能研究中心正式成立,清华大学副校长、清华大学人工智能研究院管委会主任尤政院士,清华大学人工智能研究院院长张钹院士出席成…

Java并发编程(一)Thread详解
一、概述 在开始学习Thread之前,我们先来了解一下 线程和进程之间的关系: 线程(Thread)是进程的一个实体,是CPU调度和分派的基本单位。 线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。 线…
MFC如何打开文件路径
转自:http://linyangmumu.blog.163.com/blog/static/6903134920101024419380/ 1.void OpenFile() { CString m_FileDir; BROWSEINFO bi; ZeroMemory(&bi, sizeof(BROWSEINFO)); bi.hwndOwner m_hWnd; bi.ulFlags BIF_RETURNONL…
HDOJ_ACM_数塔
Problem Description在讲述DP算法的时候,一个经典的例子就是数塔问题,它是这样描述的:有如下所示的数塔,要求从顶层走到底层,若每一步只能走到相邻的结点,则经过的结点的数字之和最大是多少?已经…

会数据分析的人别再低调了,我怕你会因此错失100万奖金
大家好我是一般周一不冒头一冒头就不一般的柚柚今天我给大家带来了一个好消息那就是“易观方舟Argo杯数据创客大赛”开始接受报名了!请不要怀疑就是那个国内领先的大数据公司——『易观』联合20家创新企业筹备了整整两个月的大赛正规、专业、含金量极高!…
CxImage类库的简介
转自:http://www.sudu.cn/info/html/edu/20080403/259688.html CxImage类库是个优秀的图像操作类库。他能快捷地存取、显示、转换各种图像。有的读者可能说,有那么多优秀的图像库,如OpenIL,FreeImage,PaintLib等等,他们可谓是功能…
MySQL 5.5 服务器变量详解(二)
innodb_adaptive_flushing{ON|OFF} 设定是否允许MySQL服务器根据工作负载动态调整刷写InnoDB buffer pool中的脏页的速率。动态调整刷写速率的目的在于避免出现IO活动尖峰。默认值为ON。作用范围为全局级别,可用于选项文件,属动态变量。innodb_adaptive_…

一文掌握异常检测的实用方法 | 技术实践
作者 | Vegard Flovik译者 | Tianyu责编 | Jane出品 | AI科技大本营(ID: rgznai100)【导读】今天这篇文章会向大家介绍几个有关机器学习和统计分析的技术和应用,并展示如何使用这些方法解决一些具体的异常检测和状态监控实例。相信对一些开发…
票据自动处理系统著名研究团队
国际上对票据自动处理系统的研究始于上世纪80年代,俄罗斯、美国、加拿大、日本、巴西等国在这个领域的研究工作开展得比较深入,著名的研究团体如加拿大Concordia大学的CENPARMI中心、MIT的PROFIT实验室、俄罗斯ABBYY软件公司、Mitek Systems公司CheckQue…
iOS开发之AVKit框架使用
2019独角兽企业重金招聘Python工程师标准>>> iOS开发之AVKit框架使用 一、引言 在iOS开发框架中,AVKit是一个非常上层,偏应用的框架,它是基于AVFoundation的一层视图层封装。其中相关文件和类都十分简单,本篇博客主要整…
DirectX10 学习笔记2:在多文档框架中初始化DirectX 10
显示功能是在视图类中完成的,所以DX10的初始化及绘制工作都是视图类中完成。 首先建立一个多文档工程,工程名为02_01,在视图类头文件中加载相关的库,并包含头文件: 在视图类的头文件中添加DX10相关的成员: …

碾压Bert?“屠榜”的XLnet对NLP任务意味着什么
作者张俊林,中国中文信息学会理事,中科院软件所博士。目前担任新浪微博机器学习团队 AI Lab 负责人。在此之前,张俊林曾经在阿里巴巴任资深技术专家并负责新技术团队,以及在百度和用友担任技术经理及技术总监等职务。他是技术书籍…
ORACLE中通过DBMS_CRYPTO包对表敏感字段进行加密
http://doc.primeton.com/pages/viewpage.action?pageId4917998

02 使用百度地图获得当前位置的经纬度
O 需求 通过百度地图,获取用户当前位置的经纬度 一 准备 确保你已按照上篇《01 如何将百度地图加入IOS应用程序?》完成了相关功能。本篇将在上一篇的基础上进行修改。 二 编码 (New标示本次新添加的代码;Delete表示本次需要删除的代码&#x…
中文NLP的分词真有必要吗?李纪为团队四项任务评测一探究竟 | ACL 2019
作者| Yuxian Meng、Xiaoya Li、Xiaofei Sun、Qinghong Han、Arianna Yuan、 Jiwei Li译者 | Rachel责编 | Jane出品 | AI科技大本营(ID: rgznai100)【导读】通常,中文文本处理的第一步称为分词,这好像已经成为一种“共识”&#…