中文NLP的分词真有必要吗?李纪为团队四项任务评测一探究竟 | ACL 2019
作者| Yuxian Meng、Xiaoya Li、Xiaofei Sun、Qinghong Han、Arianna Yuan、 Jiwei Li
译者 | Rachel
责编 | Jane
出品 | AI科技大本营(ID: rgznai100)
【导读】通常,中文文本处理的第一步称为分词,这好像已经成为一种“共识”,但对其必要性的研究与探讨很少看到。本文中,作者就提出了一个非常基础的问题:基于深度学习方法的自然语言处理过程中,中文分词(CWS)是必要的吗?
近日,香侬科技 AI 团队与斯坦福大学联合联合发表了一篇研究《Is Word Segmentation Necessary for Deep Learning of Chinese Representations》,并被 ACL 2019 接收。
在这项研究中,作者在四个端到端 NLP 基线任务中进行评测,对比基于分词的 word model (“词”级别)和无需分词的 char model (“字”级别)两种模型的效果,评测内容包括语言建模、机器翻译、句子匹配/改写和文本分类。实验结果显示,基于char model 比 word model 效果更优。

论文中,本文还进一步通过实验分析了两种模型存在差异的原因。作者认为,除了大家都认为的 OOV(out-of-vocabulary) 带来的影响, word model 的 data sparsity (数据稀疏)问题也是导致过拟合的一个重要原因。也正是希望这项研究,可以让大家发现分词有意思的地方,还有它还未曾被大家挖掘、探索的一面,以及 rethinking 分词在基于深度学习模型的 NLP 任务的必要性。
论文作者之一,香侬科技(Shannon AI)李纪为也参与到这项研究中,还在知乎上回答了大家对这篇研究的疑问。
问:如何评价李纪为的论文Is Word Segmentation Necessary?
李纪为:中文分词确实是个非常有意思、也很重要的话题,这篇文章尝试抛砖引玉去探究一下这个问题,也希望这一问题获得学术界更广泛的重视。因为之前的工作,分词本身的优缺点并没有详尽地被探讨。鉴于笔者本身的局限性,文章在 intro 的结尾也提到:Instead of making a conclusive (and arrogant) argument that Chinese word segmentation is not necessary, we hope this paper could foster more discussions and explorations on the necessity of the long-existing task of CWS in the community, alongside with its underlying mechanisms.
这个问题涉及到的更本质的问题,就是语言学的structure在深度学习的框架下有多重要 (因为词是一种基本的语言学structure)。这个问题近两年学者有不同的争论,有兴趣的同学可以看 manning 和 lecun的 debate。更早的15年,manning 和 andrew ng 就有过讨论,当时 andrew的想法比lecun还要激进,认为如果有足够的训练数据和强有力的算法,哪怕英文都不需要word,char就够了。
debate 链接:
https://www.youtube.com/watch?v=fKk9KhGRBdI
也有网友质疑论文中的实验:
@Cyunsiu To :这类论文是有意义的,但是这篇论文的实验持质疑态度。
这篇文章在分析分词不 work 的时候,很大一部分把不 work 的原因归因于 oov 太多,我个人不认同,至少分类动不动就能开十万+ 级别的词表,一方面 oov 不会太多,另一方面即使 oov 太多,也应该分析一下哪些 oov 导致模型不 work 吧,其实我个人认为根本不是 oov 的原因造成的。要不然英文里面的 word 也不会 work 了。
对此,李纪为回答道:
李纪为:文章提到几个方面,OOV 是其中一个方面,但并不是所有。除了 OOV 之外, data sparsity 也是一个重要原因。从文章的图2上看,在同样的数据集上,对于不同 OOV 的frequency bar (意思是 frequency 小于 1 算作 OOV,还是 frequency 小于 5 算作 OOV),实验结果是先升再降的。这个其实也比较好理解,如果 frequency bar 小,对于那些 infrequent 的词会单独认为是词,而不是 OOV。因为 data sparsity 的问题,会使学习不充分,从而影响了效果。 从这个角度,char 模型比 word 模型会学习得更充分。
以上回答来源
https://www.zhihu.com/question/324672243
究竟这项论文中是如何实验对比得出 char 模型效果优于 word 模型效果的?OOV 和 data sparsity 又带来了哪些影响?下面我们就为大家解读分析。
一、介绍
英文(以及其他基于拉丁字母的语言)和中文(以及其他没有明显的词语分隔符的语言,如韩文和日文)存在一个明显的差别:根据空格就能很明显、直接地识别每个英文词,但中文中并不存在这样的词语分隔符,这也是中文分词任务(CWS)的来源。在深度学习中,词往往是操作的基本单位,本文将此种模型称为基于词语的模型(word model)。在模型中,分词后得到的词语,再使用固定长度的向量来表示,这就和英语词语的处理方式相同了。那 word model 存在哪些缺陷呢?
首先,data sparsity 会导致模型出现过拟合,OOV 则会限制模型的学习能力。根据齐普夫定律(Zipf’s law),很多中文词的出现频率都非常低,这使得模型难以学习到词语的语义信息。以使用较为广泛的 Chinese Treebank 数据集(Chinese Treebank dataset, CTB)为例进行说明。通过使用结巴分词对 CTB 数据集进行切词,可以得到615,194个词语,其中不同词语50,266个。这些词语中,有24,458个词仅出现一次,占总词数的48.7%,仅占语料的4%。表1展示了针对这一语料的统计数据,可以看出基于词语的数据集非常稀疏。由于词语数的增加会使模型参数增多,数据稀疏很容易引起过拟合问题。另外,由于维护大规模的词语-向量表存在难度,很多词语都会被处理为OOV,进一步限制了模型的学习能力。
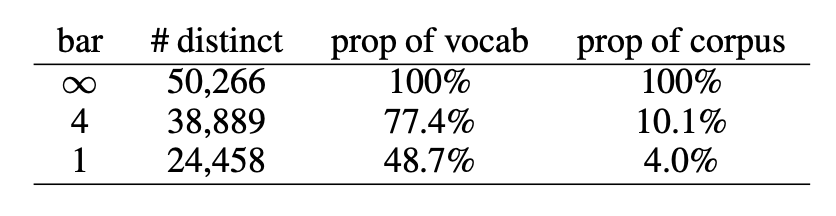
表1 CTB 词语统计数据
第二,现在的分词技术还存在很多问题,分词不当产生的错误会导致 NLP 任务出现偏差。中文中词语并没有清晰的边界,增加了中文分词的难度和复杂性。从不同的语言学角度来看,中文分词也可以有不同的标准。从表2展示的例子可以看出,在使用最广泛的两个中文分词数据库 PKU 和 CTB 中,相同的句子存在不同的分词结果。
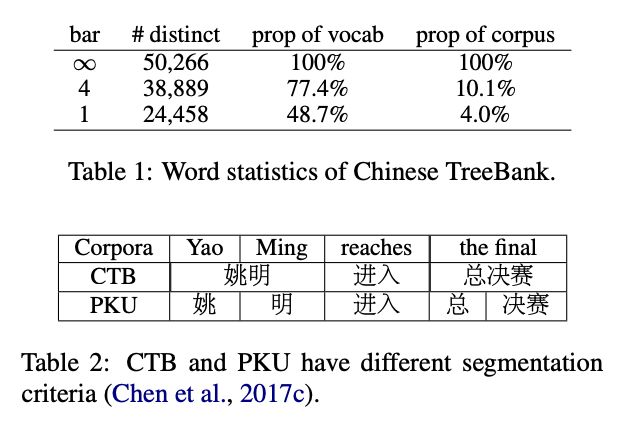
表2 CTB 和 PKU 不同的分词标准
第三,分词产生的收益效果尚不明确。还取决于带标签的 CWS 数据能够带来附加语义信息的多少。对于word model 和 char model 而言,两者的差异在于是否使用了带标签的 CWS 数据作为模型学习使用的信号。但在现有研究中,针对这一问题讨论较少。举例来说,在机器翻译模型中,学者往往使用百万级的样例进行训练,但带标签的 CWS 数据集规模往往较小( CTB 有6.8万 条数据,PKU 有2.1 万条数据),而且领域较为狭窄。这一数据似乎并不能为模型效果带来明显的增益。
其实在大规模使用神经网络模型方法之前,就有学者对分词是否必要及其能够带来增益的多少进行了讨论。在信息检索领域,有学者指出,如果在查询词和检索内容中应用相同的分词方法,就能提升检索效果。但如果在char model 中使用 bigram 对字符进行表示,则word model 的优势就会大大减弱;在机器翻译的相关研究中,有学者指出,分词并不能带来明显的效果提升,也并非提升模型效果的关键因素。
在本文中,探讨基于深度学习的中文自然语言处理任务中分词的必要性,作者首先在不涉及分词的任务中比较了word model 和 char model 的效果差异。作者通过语言建模、文本分类、机器翻译和句子匹配四个 NLP 任务比较了两个模型的效果,并发现char model 的效果更佳,比混合模型的效果更佳或等同。这一结果说明,实际上cahr model 已经对足够的语义信息进行了编码。
另外,本文对word model 的不足也做了进一步的探究,并指出了导致模型缺陷的主要原因,例如,OOV、data sparsity 会导致过拟合,以及领域转换能力较差。
二、回顾
对分词的研究并不是一项新研究,曾经大家都是如何进行实验与研究的呢?
自2003年第一个国际中文分词库出现以来,中文分词取得了很多进展。在早期,大多时候,分词都基于一个预定义的词典进行。在这一时期,一个最为简单且具有健壮性的模型即最大匹配模型,该模型最简单的版本即从左至右的最大匹配模型(maxmatch)。这一时期,新模型的提出主要来源于出现新的分词标准。
随着统计机器学习模型的出现, CWS 问题逐渐变为打标签问题。例如,使用 BEMS 标签进行标注,确认句子的起始词(Start),结尾词(End),中间词(Middle)或独立词(Single)。传统的序列标注方法包括 HMM,、MEMN,、CRF 等。
到了神经网络时代,基于神经元的 CWS 模型包括CNN、RNN、LSTM等。这类模型能更灵活地使用上下文语义信息对词语进行标注,并且使特征工程更简单易行。词语的神经元表示可以作为 CRF 模型的特征,也可作为决策层的输入。
三、实验结果
在这一部分,我们将为大家展示研究中作者将两种模型在 4 个 NLP 任务中实验的评测结果。在模型训练中,为便于比较,作者使用网格搜索对超参数进行了微调,包括学习率、dropout、batch size 等。
3.1 语言建模
该任务要求模型通过给定的前述语境信息的表示,预测后续词语。在语言建模任务中使用CTB 6.0 数据集来对比两模型效果。将数据划分为训练集、验证集和测试集,占比分别为80%,10%,10%,使用 Jieba 进行分词,LSTM 模型对字符和词语进行了编码。
实验中,对比了不同维度下,单独的 word、char 模型和混合模型的效果。可以发现,char 模型的效果都优于 word 模型,维度为 2048 时,ppl 达到最优的结果差距明显 。作者在标准 CWS 包和 LTP 包也进行了实验,并获得了相同的结果。
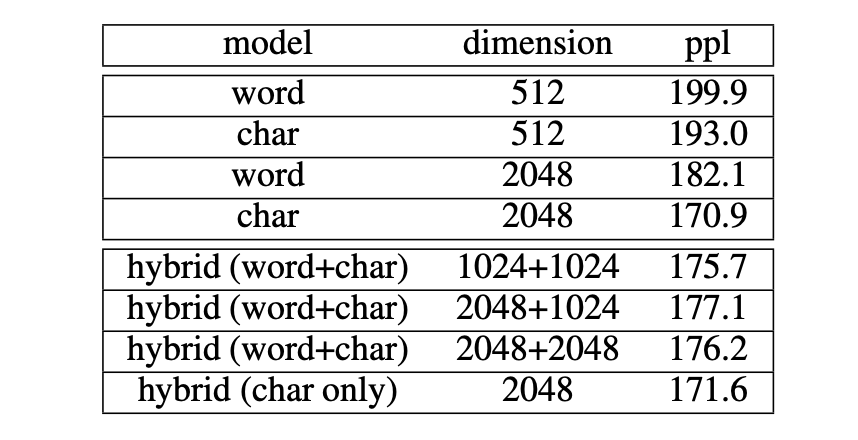
表3 语言建模结果:char model 优于 word model
另外,本文对混合模型的效果也进行了探究,为便于比较,本文构建了两种不同的混合模型,对 word+char 及 only char 进行表示。词的表示由其组成词的表示向量和剩余字符的表示向量联合构成。由于中文词语的构成字符数量不定,为保证输出数据维度一致,本文使用 CNN 对字符向量的结合进行了处理。
可以发现,在语言建模任务中,分词没有带来明显的模型增益,加入词嵌入信息还降低了模型效果。
3.2 机器翻译
本部分评测使用中英翻译,使用语料为从 LDC 语料中抽取的125万个句子对。验证数据使用的是NIST 2002 ,测试数据使用的是NIST 2003,2004,2005,2006和2008。实验使用了出现频次最高的前30,000个英语词语,以及前27,500个中文词语。char model 的词语量设置为4500。作者对中译英和英译中两种任务都进行了评测,表4所示中译英结果,表5表示英译中结果。
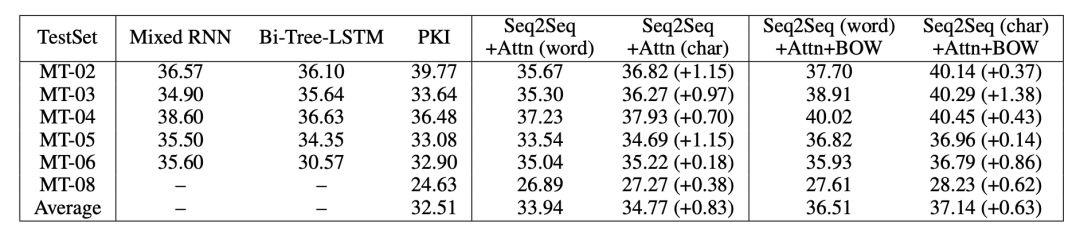
表4 中译英机器翻译评测结果(Mixed RNN, Bi-Tree-LSTM, PKI 模型效果)
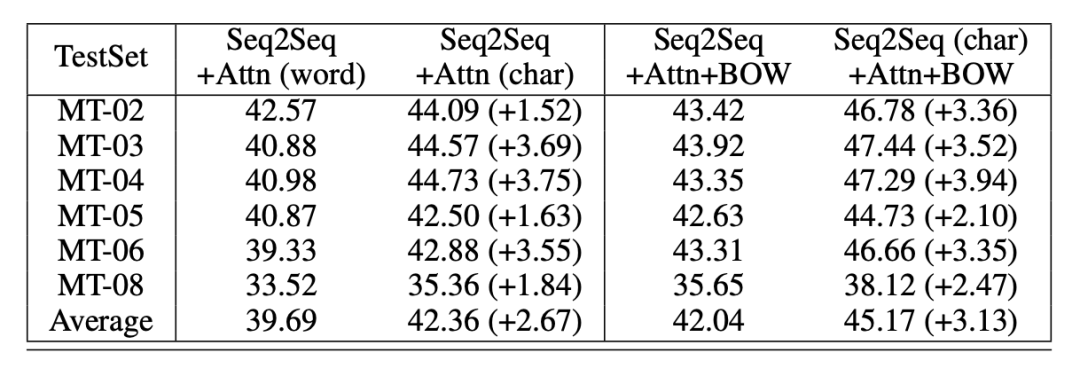
表5 英译中机器翻译评测结果
在机器翻译中,无论是「中译英」还是「英译中」任务,char 模型效果都优于word 模型。
3.3 句子匹配
作者基于 BQ 和 LCQMC 两个语料对句子匹配任务进行了评测。这两个语料为每一个语句对提供了一个二元标签,以标示两个句子是否具有相似性(或相同意图)。在这部分实验中,评测内容为使用不同模型对语句对的二元标签进行预测。评测结果如表6所示。在句子匹配任务中,基于char 模型效果优于基于word 的模型效果,表明 char 模型更能捕捉单元之间的语义联系。

表6 LCQMC 和 BQ 语料库的评测结果
3.4 文本分类
文本分类任务中使用的评测基线包括 ChinaNews, Ifeng, JD_Full, JD _binary, Dianping。作者使用双向 LSTM 模型对基于word 和基于char 的模型分别进行训练用于评测,评测结果如表7所示。除 ChinaNews语料库外,基于字符的模型的表现均优于基于词语的模型。
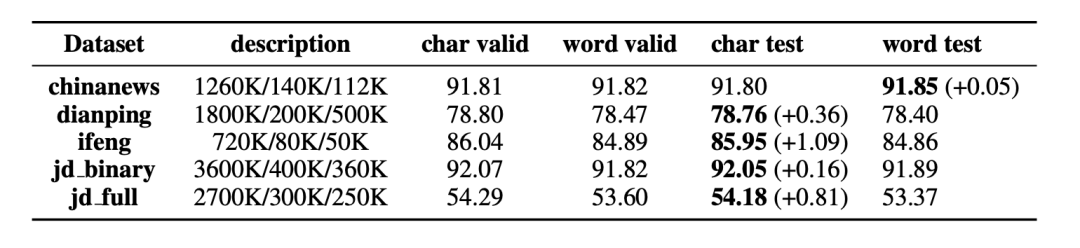
表7 文本分类任务的验证和测试情况
领域适应能力
模型的领域适应能力展现了模型基于对已有数据分布(源领域)的训练,学习新数据分布(目标领域)的能力。作者基于不同的情感分析数据库对两种模型进行了评测,结果如表8所示。可以发现,基于字符的模型具有更强的领域适应能力,且表现更优。
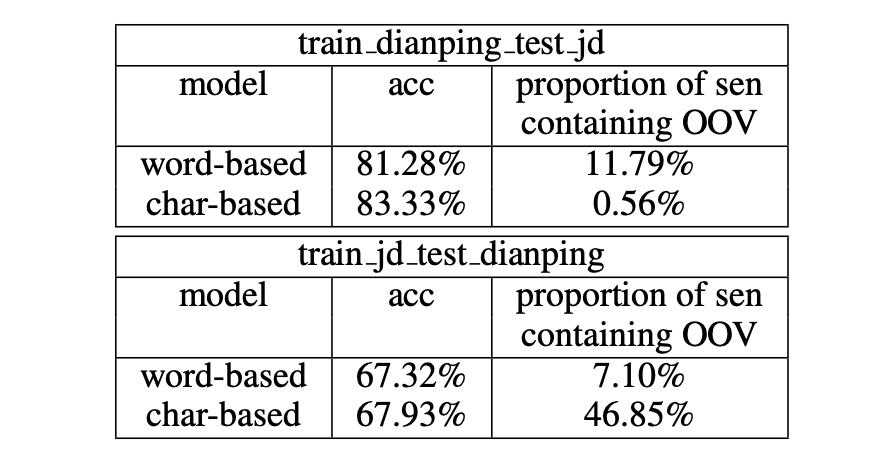
表8 基于字符的模型和基于词语的模型的领域适应能力
四、分析
在这一部分,作者探究了 char model 效果优于 word model 的原因,尽管未能完全指出基于词语的模型的运行机制,但作者尝试分析了几个主要的影响因素。
4.1 数据稀疏性
防止词规模过大的常用方法是设置词频率的阈值,并使用 UNK 字符替代所有未达到阈值的词语。阈值的设置对词规模的大小有直接影响,并进一步影响了模型参数的数量。图2展示了词汇量、频率阈值以及模型效果之间的联系。无论是char 模型还是model 模型,当词规模过大,模型效果都会明显下降。模型对于低频词的语义的学习是存在困难的。因此,要获得较好的基于词语或字符的模型训练效果,必须保证词语或字符的出现频率。但对于word 模型,这一条件更难以达到。
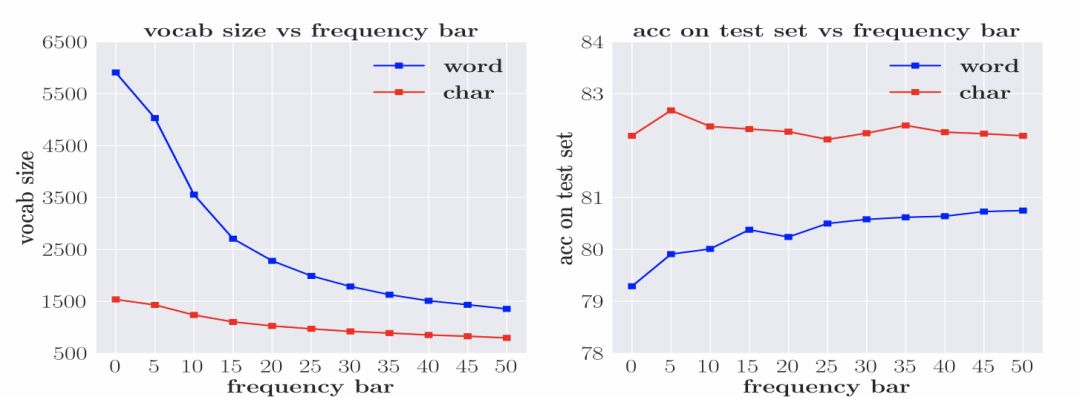
图2 数据稀疏性对基于词语和基于字符的模型的影响
4.2 OOV
对word model 来说,OOV 是另一重要影响因素。但考虑到简单降低词频率的阈值以减少OOV,会使数据稀疏问题更加严重,因此本文采用了一个替代性策略,即基于不同的词频率阈值,分别移除验证集和测试集中包含OOV 的句子。图4展示了训练集词汇数量、准确度和词频率阈值间的关系。随着词频率阈值的增加,两种模型效果的差异在逐渐减小。
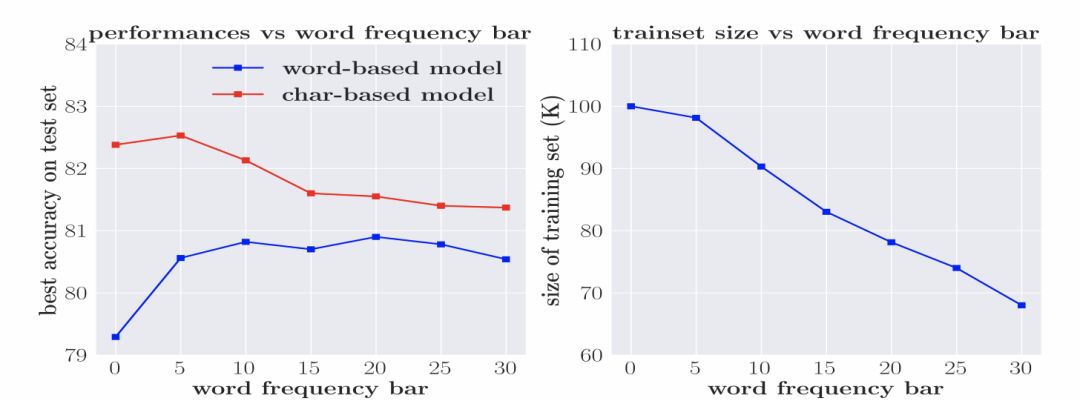
图4 移除包含OOV 的训练实例带来的影响
4.3 过拟合
数据稀疏导致模型需要学习的参数增加,使得模型更加容易过拟合。本文在 BQ 数据集上进行了实验,结果如图1所示。要获得与基于词语的模型相似的效果,基于词语的模型需要设置更高的 dropout 值。
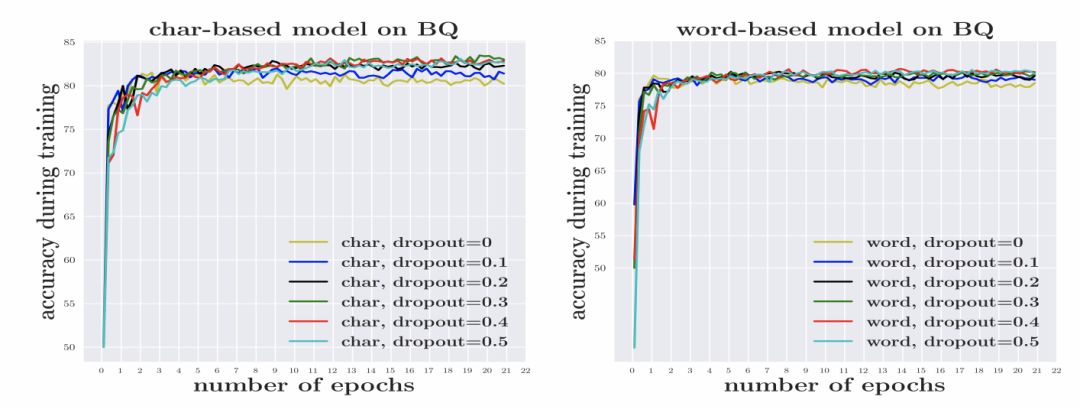
图1 dropout 对基于词语和基于字符的模型的影响
4.4 可视化
图3 展示了char model 在 BQ 数据集上获得更好的语义匹配效果的原因。该热图展示了 BiPMP 计算出的两句子间的注意力匹配值。对于char model 而言,句子间的映射更加容易。
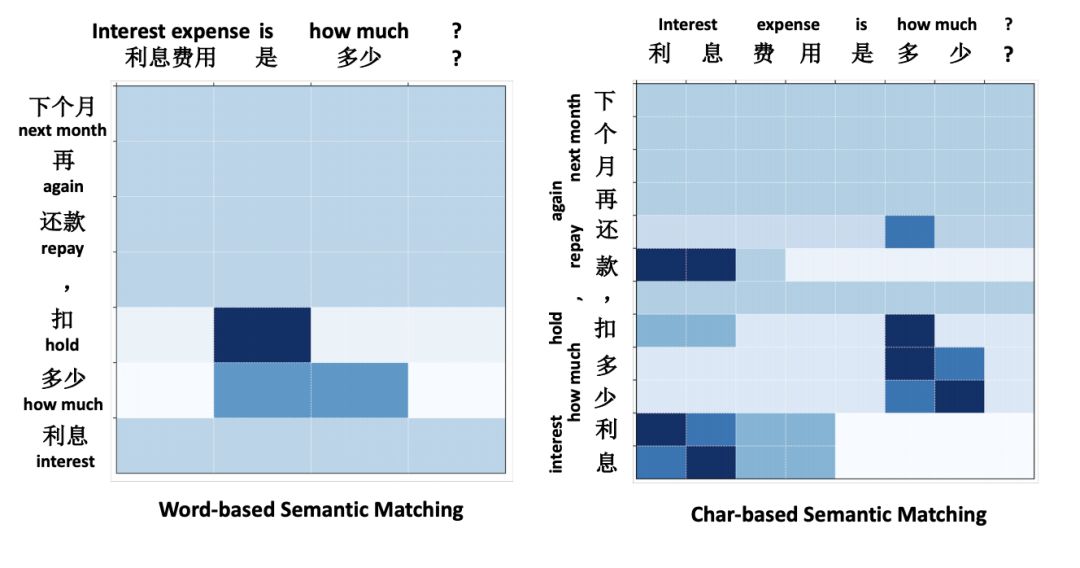
图4 基于词语和基于字符的模型对两个中文语句的语义匹配情况
五、结论
这项研究探究了基于深度学习方法中文 NLP 任务中,分词的必要性这一基础性问题,并在四类端到端自然语言处理任务上发现char 模型效果更优于 word 模型。本文认为,word 模型效果不佳的原因在于OOV、数据稀疏导致的过拟合和领域转换能力差问题。也希望这篇论文可以启发更多针对中文分词必要性的探讨工作。
原文链接:
https://arxiv.org/abs/1905.05526
(*本文为 AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
大会开幕倒计时6天!
2019以太坊技术及应用大会特邀以太坊创始人V神与众多海内外知名技术专家齐聚北京,聚焦区块链技术,把握时代机遇,深耕行业应用,共话以太坊2.0新生态。即刻扫码,享优惠票价。

推荐阅读
华为最强自研NPU问世,麒麟810“抛弃”寒武纪
真正的博士是如何参加AAAI, ICML, ICLR等AI顶会的?
Python最抢手、Java最流行、Go最有前途,7000位程序员揭秘2019软件开发现状
程序员学Python编程或许不知的十大提升工具
不要让 Chrome 成为下一个 IE!
这位博士跑赢“地震波”:提前 10 秒预警宜宾地震!
一张图告诉你到底学Python还是Java!
鸿蒙将至,安卓安否?
25岁创立加密城堡, 曾经独角兽创始人社会名流天才黑客是这里的沙发客, 如今却无人问津……
352万帧标注图片,1400个视频,亮风台推最大单目标跟踪数据集
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

Netty 粘包 拆包 编码 解码 序列化 介绍
目录: 粘包 & 拆包及解决方案 ByteToMessageDecoder基于长度编解码器基于分割符的编解码器google 的 Protobuf 序列化介绍其他的前言 Netty 作为一个网络框架,对 TCP 连接中的问题都做了全面的考虑,比如粘包拆包导致的半包问题࿰…

matlab 全局变量
转自:http://matlab.net.cn/matlabjichu/2010/201005/265.html 如果你要多于一个函数共用一个简单的变量,简单的处理方法就是把这个变量在所有函数中定义为global全局变量。在命令行做同样的事情,如果你要工作空间访问上述变量。这个全局变量…

java 解决Html table的rowspan问题(osc处女作)
2019独角兽企业重金招聘Python工程师标准>>> 假如有如下html代码需要解析 <table border"1"><tr><td rowspan"3">1</td><td>1</td><td>1</td><td>1</td></tr><tr>&l…
基于C++的OpenCV常用函数
C版本的好处: 1、在于可以尽量避免使用指针这种危险的东西; 2、不用费心去release资源了,因为在其destructor里面,系统会自动帮你搞定。 3、在某些情况下会比C版本运行速度快。 在文件中包含 using namespace cv; 1. i…

基于GAN的图像水印去除器,效果堪比PS高手
作者 | 李翔转载自视说AI(ID:techtalkai)简介:李翔,国内某互联网大厂AI民工,前携程酒店图像技术负责人,计算机视觉和深度学习重度爱好者,在ICCV和CVPR等会议上发表论文十余篇。写在前面当前互联…

Flink最锋利的武器:Flink SQL入门和实战 | 附完整实现代码
作者 | 机智的王知无转载自大数据技术与架构(ID: import_bigdata)一、Flink SQL 背景Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。自 2015 年开始,阿里巴巴开始…
SQL SERVER中ROLLUP的用法
cube操作符 要使用cube,首先要了解group by 其实cube和rollup区别不太大,只是在基于group by 子句创建和汇总分组的可能的组合上有一定差别, cube将返回的更多的可能组合。如果在 group by 子句中有n个列或者是有n个表达式的话, s…

Mybait缓存机制
MyBatis同大多数ORM框架一样,提供了一级缓存和二级缓存的支持。 一级缓存:其作用域为session范围内,当session执行flush或close方法后,一级缓存会被清空。 二级缓存:二级缓存和一级缓存机制相同,但是可以自…
vs2008常用操作汇总
1、OpenCV2.1环境配置: (1)、Tools-->Options-->Projects and Solutions-->VCDrectories: Show directories for选择include files,加入目录 D:/Program Files/OpenCV2.1/include/opencv ;Show directories for选择libra…

深度学习已至“瓶颈”?英特尔:数据处理是一剂良药
【导读】霍金弟子Alan Yuille在前不久发表言论称,至少在计算机视觉领域,深度学习的瓶颈已至。然而,人工智能与大数据的发展相辅相成,数据将会推动人工智能的发展,促进更多技术应用落地,将人工智能带入一个新…
WIN32 C++ 遍历文件夹
转自:http://blog.csdn.net/lizhigang770/archive/2010/11/30/6045242.aspx 一、先介绍一个结构 WIN32_FIND_DATA typedef struct _WIN32_FIND_DATA { DWORD dwFileAttributes; // 文件属性 FILETIME ftCreationTime; // 文件创建时间 FILETIME ft…
UIView淡入淡出动画
小小原创,转载请注明出处:http://iphone.xiaoxiaostudio.net 如果你觉得为某个UIView 加载一个全新的View在这个UIView上面时,想要隐藏时setHidden显得太突兀了,我们可以给它增加一些动画,iOS上默认提供了一些动画&…
sass的继承,混合宏,占位符的用法总结
SCSS中混合宏使用 mixin mt($var){ margin-top: $var; }.block { include mt(5px);span { display:block; include mt(5px); } }extend如何工作 .icon {transition: background-color ease .2s;margin: 0 .5em;}.error-icon {extend .icon;/*错误图标指定的样式... */}.info-i…
js中cookie的使用详细分析
2019独角兽企业重金招聘Python工程师标准>>> JavaScript中的另一个机制:cookie,则可以达到真正全局变量的要求。 cookie是浏览器 提供的一种机制,它将document 对象的cookie属性提供给JavaScript。可以由JavaScript对其进行控制&a…

从事JAVA 20年最终却败给了Python,哭了!
之前遇到一个老师,他从事Java行业20年了,在Python兴起的时候,他周围的其他同行们都在纷纷学习Python方面的知识,连他的学生也问他“老师,你为什么不学Python呢?”。当这位听到学生这个问题的时候࿰…
c++删除文件夹
转自:http://blog.csdn.net/sshhbb/archive/2010/12/07/6061029.aspx c语言本身是不能删除文件或文件夹的,他们是windows操作系统里的东西,所以得借助其api函数。 其一:使用shell 接口: void FileDelete(CString di…
解决bootstrap下的图片自适应问题
.img-responsive {display: block; height: auto; max-width: 100%; }转载于:https://www.cnblogs.com/qjuly/p/9809910.html

边缘检测、Hough变换、轮廓提取、种子填充、轮廓跟踪
转自:http://blog.sina.com.cn/s/blog_6c083cdd0100nm4s.html 7.1 边沿检测 我们给出一个模板 和一幅图象 。不难发现原图中左边暗,右边亮,中间存在着一条明显的边界。进行模板操作后的结果如下: 。 可以看出,第3…
JS Array 中 shift 和 pop 的妙用
在 JS Array 中支持两个方法,shift() 和 pop(),分别是指从一个数据中的最前面和最后面删除一个值,并返删除值。看一个示例就明白了: var arr [s,o,f,i,s,h]; arr.shift(); // 返回 s arr; // 目前是 [o,f,i,s,h…

当今主流分割网络有哪些?12篇文章一次带你看完
作者 | 孙叔桥来源 | 转载自有三AI(ID: yanyousan_ai)本文的12篇文章总结了当前主流的分割网络及其结构,涵盖从编解码结构到解码器设计;从感受野到多尺度融合;从CNN到RNN与CRF;从2D分割到3D分割;…
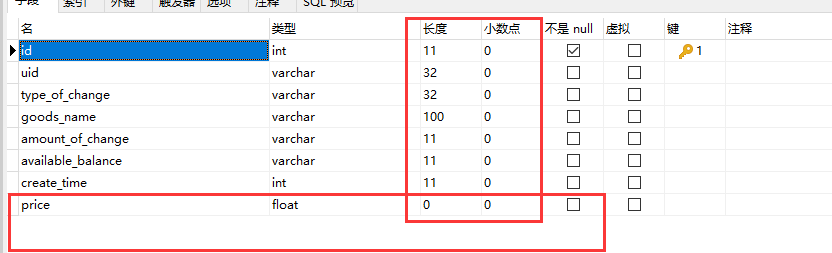
正确生成浮点型的方法,解决sqlachemy Float浮点型的坑,生成float类型时,长度和精度均为0,导致查询不到结果!...
问题描述 在使用flask_sqlachemy时,给price字段选择了Float类型,数据库用的mysql,生成数据库表后,发现 from sqlalchemy import Float,Column price Column(Float,default0.00) 虽然能存储float类型,结果如下 但是查询…
图像轮廓的提取和绘制
转自:http://blog.csdn.net/gnuhpc/archive/2009/06/18/4278105.aspx <>var ultimaFecha ; <>document.write(ultimaFecha); #include "highgui.h" #include "cv.h" #include <iostream> #include <iomanip> using …
上海交大张拳石:神经网络的可解释性,从经验主义到数学建模
作者 | 张拳石来源 | 转载自知乎Qs.Zhang张拳石本来想把题目取为“从炼丹到化学”,但是这样的题目太言过其实,远不是近期可以做到的,学术研究需要严谨。但是,寻找适当的数学工具去建模深度神经网络表达能力和训练能力,…

计算机网络模型到底是七层?五层?四层?
1.Introduction 本篇文章的初衷是在做Android网络开发时经常接触各种协议,比如HTTP、XMPP、HLS、RTSP、TCP等协议,对网络的模型和层次有个直观的了解可以做到心中有数。OSI参考模型是七层,TCP/IP模型是四层,计算机网络(…
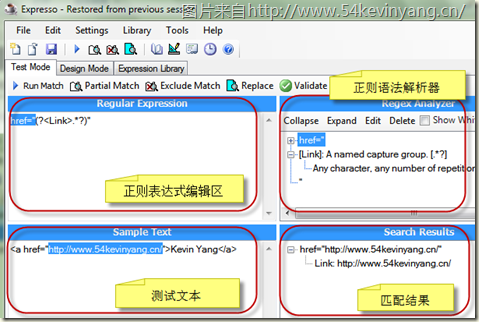
【推荐】使用Ultrapico Expresso学习正则表达式
推荐理由Ultrapico Expresso是我工作中经常使用的一个非常强大的正则表达式构建、测试以及代码生成工具。它能够对你构建的正则表达式进行解析、验证,并输出解析结果,提供性能测试工具,支持C#、VB等代码生成,最重要的是࿰…

OpenCV中常用到的轮廓处理函数汇总
转自:http://fsa.ia.ac.cn/opencv-doc-cn/opencv-doc-cn-0.9.7/ref/opencvref_cv.cn.htm ApproxChains 用多边形曲线逼近 Freeman 链 CvSeq* cvApproxChains( CvSeq* src_seq, CvMemStorage* storage,int methodCV_CHAIN_APPROX_SIMPLE,double parameter0, int mi…
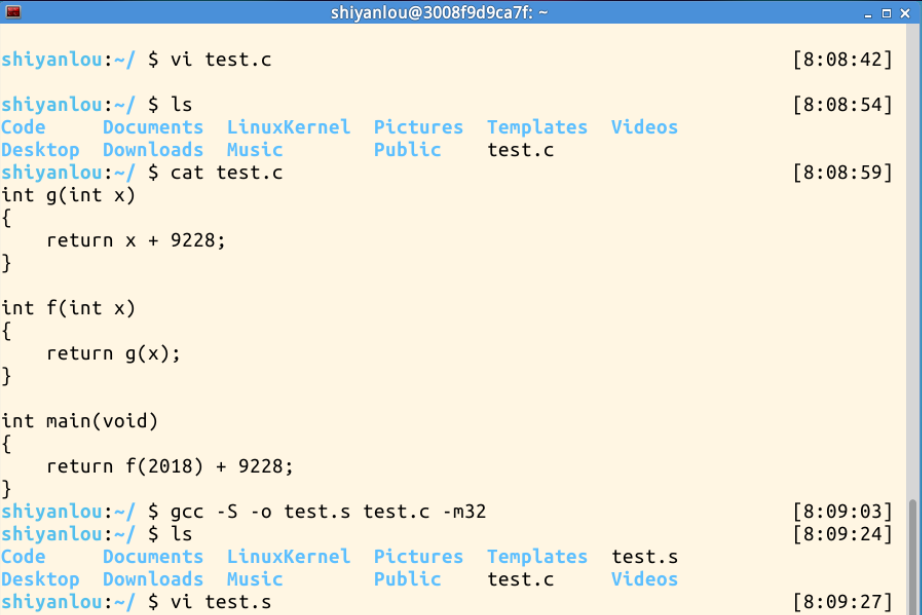
《Linux内核原理与分析》第二周作业
反汇编一个简单的C程序 1、实验要求 使用: gcc –S –o test.s test.c -m32 命令编译成汇编代码,对汇编代码进行分析总结。其中test.c的具体内容如下: int g(int x) {return x 3; }int f(int x) {return g(x); }int main(void) {return f(8)…

首次!腾讯全面公开整体开源路线图
6月25日,由Cloud Native Computing Foundation (CNCF) 主办的云原生技术大会在上海举办,腾讯开源联盟主席、腾讯开源管理办公室委员、Apache Member堵俊平首次公开了腾讯整体的开源战略路线图。 堵俊平表示:“腾讯开源提倡‘开放、共享、合力…
201771010111李瑞红《面向对象的程序设计》第八周实验总结
实验八接口的定义与使用 实验时间 2018-10 理论部分 6.1 接口:用interface声明,是抽象方法和常量值定义的集 合。从本质上讲,接口是一种特殊的抽象类。 在Java程序设计语言中,接口不是类,而是对类 的一组需求描述,由常…

崛起的Python,真的影响了76万人?
随着AI的兴起,Python彻底火了。据Stack Overflow调研报告:Python的月活用户已超越了Java、成为第一,全民Python已为“大势所趋”。那么,程序员有必要学Python吗?如何高效掌握Python?程序员为啥要学Python&a…