一文掌握异常检测的实用方法 | 技术实践

作者 | Vegard Flovik
译者 | Tianyu
责编 | Jane
出品 | AI科技大本营(ID: rgznai100)
【导读】今天这篇文章会向大家介绍几个有关机器学习和统计分析的技术和应用,并展示如何使用这些方法解决一些具体的异常检测和状态监控实例。相信对一些开发者们来说可以提供一些学习思路,应用于自己的工作中。
现在,机器学习和数据分析有什么值得大家关注?
“数字化转型、数字化、工业 4.0”……你一定对这些术语有所耳闻,其背后的主要意图是利用技术和数据来提升生产力和效率。信息和数据与设备及传感器间的连通产生了丰富的数据,关键之处在于可利用获取到的大量数据和提取出的有用信息,来减少成本、优化功率、最小化停机时间。这是最近机器学习和数据分析的热点之一。
在实际业务和场景中,离不开两项技术:异常检测与状态监控。
什么是异常检测?
异常检测是一个发现“少数派”的过程,由于它们与大多数数据不一样而引起我们的注意。在几个典型场景中,异常数据能为我们关联到一些潜在的问题,如银行欺诈行为、药品问题、结构缺陷、设备故障等。这些关联关系能帮助我们挑出哪些点可能是异常的,从商业角度来看,查出这些事件是非常有价值的。
这样就引出我们的主要目标:我们如何分辨每个点是正常还是异常呢?在一些简单的场景中,如下图所示,数据可视化就可以给出重要信息。
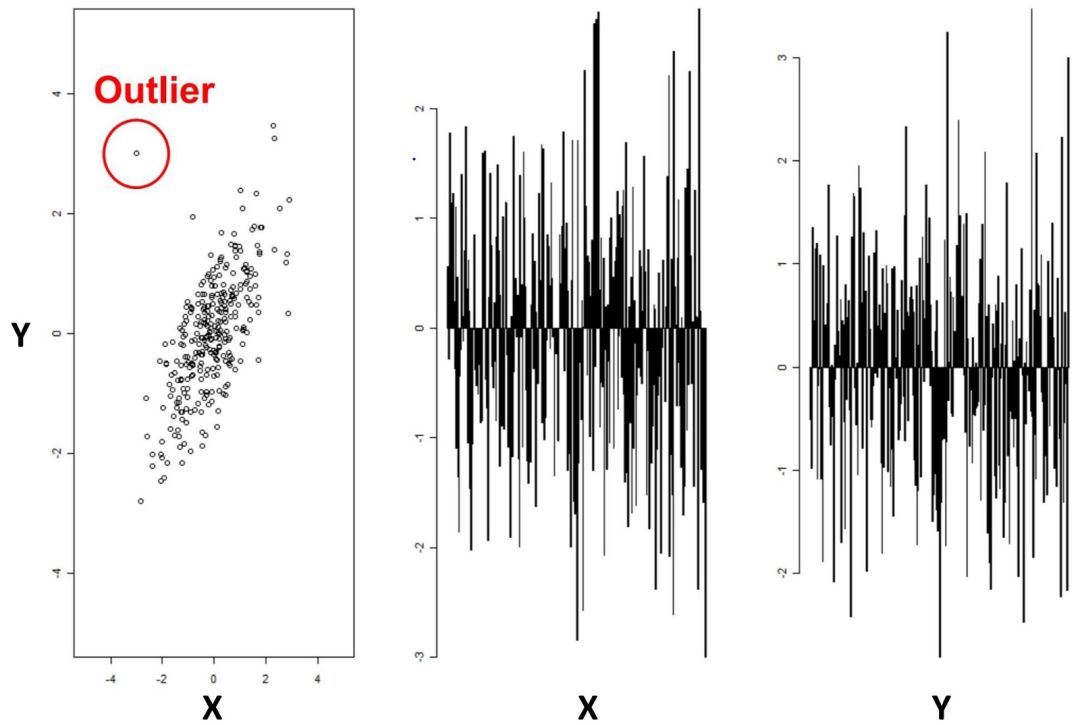
图 1:两个变量的异常
在这个二维数据(X 和 Y)的例子中,判断异常点是非常容易的,只需要观察数据点在二维平面上的分布即可。然而,观察右图可以发现,只观察一个变量是无法看出异常的,只有把变量 X 和变量 Y 结合起来观察,才能发现异常点。当我们把数据维度从 2 提升到 10-100,这件事情就极其复杂了,实际场景的异常检测也是如此。
什么是状态监控?
无论任何机器,旋转电机(泵、压气机、燃气或蒸汽轮机等)或非旋转机器(热交换器、分裂蒸馏塔、阀门等),都会最终出现运转异常的情况。出现这种情况时,机器并不一定是彻底坏掉了,可能只是无法以最佳状态运转,它可能需要进行维修以恢复完全的运转能力。简而言之,识别设备的“健康状态”就是状态监控领域所研究的问题。
在状态监控中,最常用的方法是观测机器的每个传感器,并对其设置一个最小值和最大值。如果当前值在所设置范围之内,说明机器运转正常。如果当前值超出范围,系统会给出预警信号,提醒机器运转不正常。
对机器硬性施加报警阈值这一过程,会导致系统发出大量假的预警信号,即机器运转正常时却收到了异常报警。同时也存在预警信号遗漏的问题,即机器运转异常却没有收到警示。第一个问题不仅浪费时间精力,也影响机器寿命。第二个问题更为严重,可能导致机器损坏,进而损失大量维修费用和生产损失。
而两个问题都源于一个原因:设备的健康程度是一个高维的复杂问题,不能依赖于某个单独的指标进行判断(和图 1 展示的异常检测问题同理)。我们必须结合考虑多个检测值,从而获得一个更为真实的信号。
主要方法
说到异常检测,很难把机器学习和统计分析全部覆盖,我会避免在理论知识上过于深入(但会提供一些有详细介绍的链接)的同时介绍一些常用方法。如果你对机器学习和统计分析在状态监控方面的实际应用更感兴趣,可以往下看“状态监控实例”部分。
方法一:多变量统计分析
使用主成分分析法进行降维:PCA
处理高维数据总是充满挑战的,减少变量个数(降维)的方法有很多。其中最主要的方法是主成分分析法(PCA, principal component analysis),该方法将数据映射到一个低维空间,使数据在低维空间的方差最大化。在实际应用中,需要建立数据的协方差矩阵,并计算矩阵的特征向量。对应最大特征值(即主要成分)的特征向量可用作重新构建原数据集。如今原特征空间被减小了(部分数据丢失了,但保留了最重要的信息),得到了由部分特征向量构成的空间。
降维:
https://en.wikipedia.org/wiki/Dimensionality_reduction
PCA:
https://en.wikipedia.org/wiki/Principal_component_analysis
协方差矩阵:
https://en.wikipedia.org/wiki/Covariance_matrix
特征向量:
https://en.wikipedia.org/wiki/Eigenvalues_and_eigenvectors
多变量异常检测
当处理单变量或两个变量的异常检测时,数据可视化常常是一个好的方法。然而,当拓展到高维数据时(同时也是大多数实际应用中的情况),这种方法就会极其难处理。幸运的是,多变量分析可以帮得上忙。
当处理一个数据点的集合时,这些点会有典型的特定分布(如高斯分布)。要想定量地检测异常点,我们要先计算数据点的概率分布 p(x)。之后出现新的点 x,我们就可以用 p(x) 与阈值 r 作对比了。如果 p(x)<r,可以认作该点是异常点。这是因为正常的点一般有一个大的 p(x),但异常点趋于小的 p(x)。
状态监控场景中的异常检测很有趣,因为异常可以告诉我们有关被监控设备是否“健康”的讯息:当设备临近故障或非最优操作所产生的数据,与设备正常运转所产生的数据在分布上不同。
多变量统计/多元统计:
https://en.wikipedia.org/wiki/Multivariate_statistics
高斯分布:
https://en.wikipedia.org/wiki/Normal_distribution
概率分布:
https://en.wikipedia.org/wiki/Probability_distribution
马氏距离
试考虑一个数据点是否属于某一分布的概率问题。第一个步骤是找到质心或者说样本点的质量中心。直观上来看,该点离质心越近,越可能属于这个集合。然而,我们也要注意该集合的范围大小,这样我们才能判断给定的离质心的距离是否值得注意。简化的方法是去估计样本点与质心距离的标准差。将其插入标准分布中,我们可以得出数据点是否属于同一分布的概率值。
上述方法也存在缺陷,我们假设了样本点相对于质心是球形分布的。如果它们的分布不是球状的,而是椭圆状的,我们在判断测试点是否属于该集合时,不仅要考虑与质心的距离,还要考虑方向。在那些椭圆短轴的方向上,测试点的距离一定更近,但那些长轴方向上测试点是远离质心的。从数学角度看,我们可以通过计算样本的协方差矩阵,来估计出最能代表集合分布的椭圆。马氏分布是指从测试点到质心的距离除以椭圆在测试点方向上的宽度。
为了使用马氏距离来判别一个测试点属于 N 个分类中的哪一个,首先应该基于已知样本与各个分类的对应情况,来估计每个类的协方差矩阵。在我们的例子中,我们只对“正常”和“异常”两个类别感兴趣,我们使用只包含正常操作状态的数据作为训练数据,来计算协方差矩阵。接下来,拿来测试样本,计算出它们与“正常”类别的马氏距离,如果距离高于所设置的阈值,则说明该测试点为“异常”。
马氏距离:
https://en.wikipedia.org/wiki/Mahalanobis_distance
方法二:人工神经网络
自动编码器网络
第二种方法是基于自动编码器神经网络。它的基本思想与上面的统计分析相似,但略有差异。
自动编码器是一种人工神经网络,通过无监督的方式学习有效的数据编码。自动编码器的目的是学习一组数据的表示(编码),通常用于降维过程。与降维的一层一起,通过学习得到重建层,自动编码器尝试将降维层进行编码,得到尽可能接近于原数据集的结果。
在结构上,最简单的自动编码器形式是前馈非循环神经网络,与许多单层感知器类似,它们构成了包含输入层、输出层和用于连接的一个或多个隐藏层的多层感知器(MLP, multilayer perceptron),但输出层的节点数与输入层相同,目的是对自身的输入进行重建。
自动编码器:
https://en.wikipedia.org/wiki/Autoencoder
人工神经网络:
https://en.wikipedia.org/wiki/Artificial_neural_network
有效数据编码:
https://en.wikipedia.org/wiki/Feature_learning
无监督:
https://en.wikipedia.org/wiki/Unsupervised_learning
多层感知器:
https://en.wikipedia.org/wiki/Multilayer_perceptron
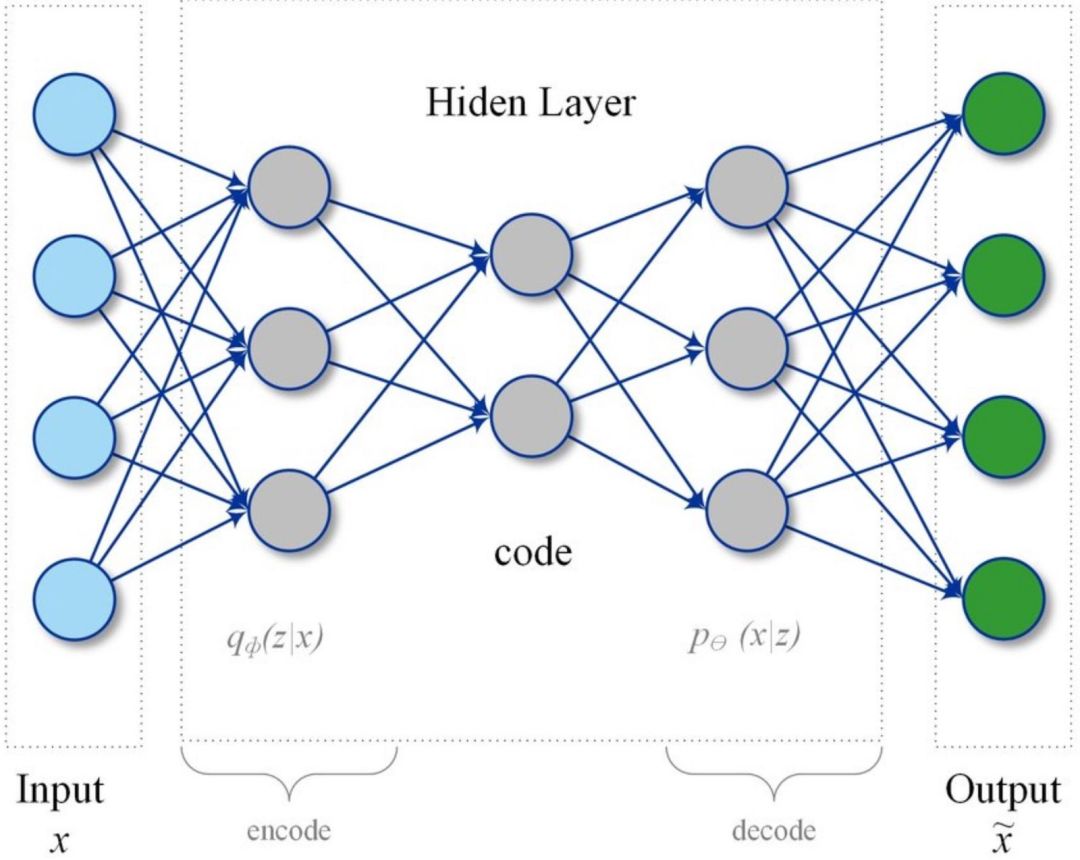
图2:自动编码器网络
在异常检测和状态监控场景中,基本思想是使用自动编码器网络将传感器的读数进行“压缩”,映射到低维空间来表示,获取不同变量间的联系和相互影响。(与 PCA 模型的基本思想类似,但在这里我们也允许变量间存在非线性的影响)
接下来,用自动编码器网络对表示“正常”运转状态的数据进行训练,首先对其进行压缩然后将输入变量重建。在降维过程中,网络学习不同变量间的联系(例如温度、压力、振动情况等)。当这种情况发生时,我们会看到通过网络重构后的输入变量的异常报错增多了。通过对重构后的报错进行监控,工作人员能够收到所监控设备的“健康”信号,因为当设备状态变差时,报错会增多。与基于马氏距离的第一种方法类似,我们在这里使用重建误差的概率分布来判断一个数据点是正常还是异常。
状态监控实例:齿轮轴承故障
在这个部分,我会介绍上述两个不同方法在状态监控实例中的应用。由于实际工作中大部分客户的数据是无法公开的,我们选择使用 NASA 的数据来展示两种方法,读者也可以通过链接自行下载。
NASA 数据下载:
http://data-acoustics.com/measurements/bearing-faults/bearing-4/
在该实例中,目的是检测发动机上的齿轮轴承退化,并发送警告,以帮助工作人员及时采取措施以免齿轮故障。
实验细节和数据准备
在恒定负载和运行条件下,三个数据集各包含四个轴承运行出现异常的数据。数据集提供了轴承生命周期内的振动测量信号,直到出现故障。前连天的运行数据被用作训练数据,以表示正常且“健康”的设备。剩余部分的数据包含轴承运转直到故障的过程,这部分数据用作测试数据,以评估不同方法是否能在运转故障前检测到其轴承异常。
方法一:PCA + 马氏距离
正如本文“技术部分”中所介绍的,第一种方法先进行主成分分析,然后计算其马氏距离,来辨别一个数据点是正常的还是异常的(即设备退化的信号)。代表“健康”设备的训练数据的马氏距离的分布如下图所示:
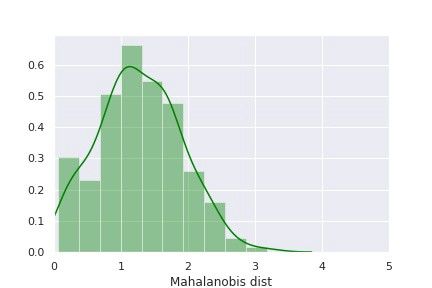
图3:“健康”设备的马氏距离分布
利用“健康”设备的马氏距离分布,我们可以设定判断是否为异常点的阈值。从上面的分布图来看,我们可以定义马氏距离大于 3 的部分为异常。这种检测设备老化的估计方法,需要计算测试集中全部数据点的马氏距离,并将其与所设置的阈值进行比较,来标记其是否异常。
基于测试数据的模型评估
利用上述方法,我们计算测试数据,即运转直到轴承故障这一时间段内数据的马氏距离,如下图所示:
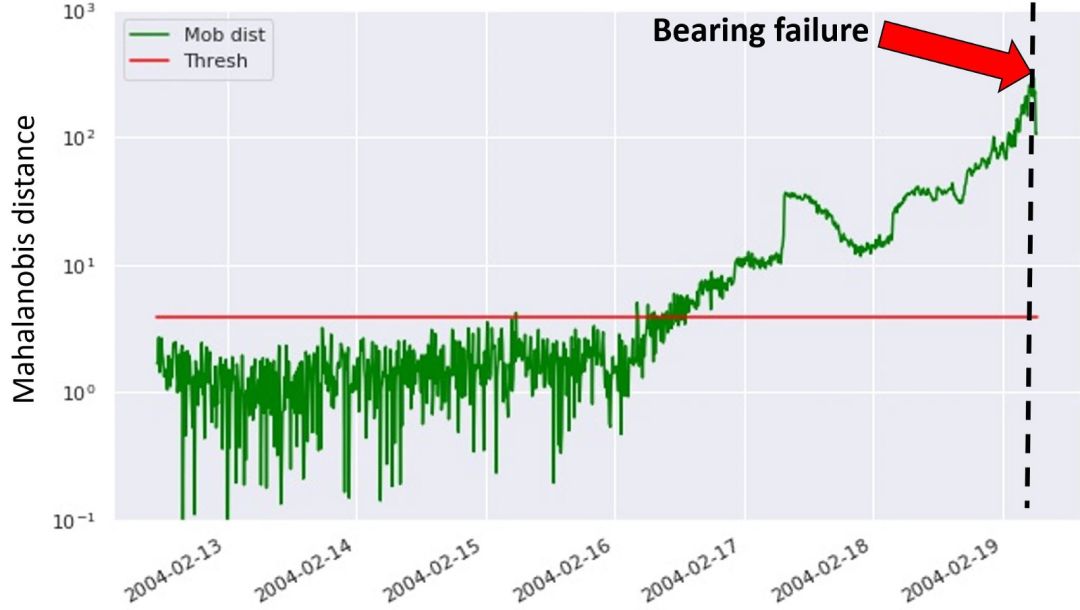
图 4:利用方法一检测轴承故障
在上图中,绿色点对应计算得到的马氏距离,而红线表示所设置的异常阈值。轴承故障发生在数据集的最末端,即黑色虚线标记处。这说明第一种方法可以检测到 3 天后即将发生的设备故障。
现在我们用第二种建模方法做类似的实验,以评估哪种方法更好。
方法二:人工神经网络
如本文“技术部分”中所写的,第二种方法包括使用自动编码器神经网络来寻找异常点。和第一种方法类似,我们在此也是用模型输出的分布,用表示“健康”设备的数据作为训练数据,来进行异常检测。训练数据集的重建损失分布如下图所示:
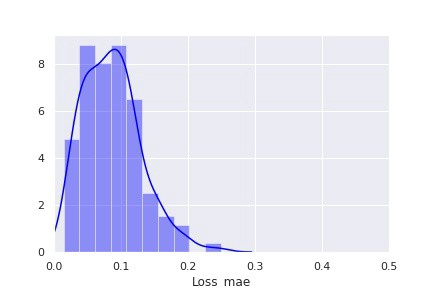
图 5::“健康”设备的重建损失分布
利用“健康”设备的重建损失分布,我们可以设置判断数据是否异常的阈值。由上图中的分布,我们可以设置损失大于 0.25 的部分为异常。这种检测设备老化的评估方法包括计算测试集中全部数据点的重建损失,将该损失与所设置阈值作比较,来判别其是否异常。
基于测试数据的模型评估
利用上述方法,我们计算测试数据,即运转直到轴承故障这一时间段内数据的重建损失,如下图所示:
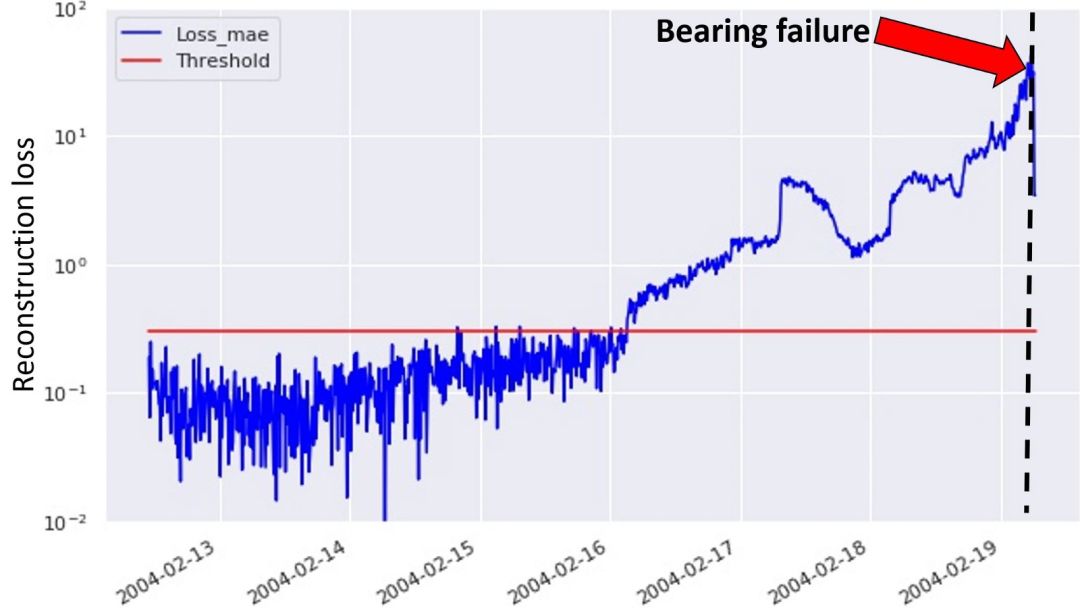
图 6:利用方法二检测轴承故障
在上图中,蓝色点对应重建损失,而红线表示所设置的异常阈值。轴承异常发生在数据集的末端,即黑色虚线标记处。这表示该建模方法也能够检测到未来 3 天即将发生的设备异常。
总结
综上所述,两种不同的方法都能用作异常检测,在机器实际发生故障前几天就检测到即将发生的事故。在现实生活场景中,这项技术可以帮助我们早在故障前就采取预防措施,不仅可以节约开销,也在设备故障的 HSE 方面具有潜在的重要性。
展望
使用传感器收集数据的成本越来越低,设备间的连通度也日益提升,从数据中提取有价值的信息变得越来越重要。从大量数据中挖掘模式是机器学习和统计的重要领域,利用这些数据背后隐藏的信息来改善不同领域有极大的可能性。异常检测和状态监控只是诸多可能性中的一种。
原文链接:
https://towardsdatascience.com/how-to-use-machine-learning-for-anomaly-detection-and-condition-monitoring-6742f82900d7
(*本文为 AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
大会开幕倒计时5天!
2019以太坊技术及应用大会特邀以太坊创始人V神与众多海内外知名技术专家齐聚北京,聚焦区块链技术,把握时代机遇,深耕行业应用,共话以太坊2.0新生态。即刻扫码,享优惠票价。

推荐阅读
6月技术福利限时免费领
中文NLP的分词真有必要吗?李纪为团队四项任务评测一探究竟 | ACL 2019
异类框架BigDL,TensorFlow的潜在杀器!
华为最强自研 NPU 问世,麒麟 810 “抛弃”寒武纪
使用Python高效操作文件,3条超实用的建议分享给你
搞不懂SDN?那是因为你没看这个小故事…
有答案了!一张图告诉你到底学Python还是Java!你咋看?
北邮通信博士万字长文,带你秒懂 4G/5G 区别!
LinkedIn最新报告: 区块链成职位需求增长最快领域, 这些地区对区块链人才渴求度最高……
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

票据自动处理系统著名研究团队
国际上对票据自动处理系统的研究始于上世纪80年代,俄罗斯、美国、加拿大、日本、巴西等国在这个领域的研究工作开展得比较深入,著名的研究团体如加拿大Concordia大学的CENPARMI中心、MIT的PROFIT实验室、俄罗斯ABBYY软件公司、Mitek Systems公司CheckQue…

iOS开发之AVKit框架使用
2019独角兽企业重金招聘Python工程师标准>>> iOS开发之AVKit框架使用 一、引言 在iOS开发框架中,AVKit是一个非常上层,偏应用的框架,它是基于AVFoundation的一层视图层封装。其中相关文件和类都十分简单,本篇博客主要整…
DirectX10 学习笔记2:在多文档框架中初始化DirectX 10
显示功能是在视图类中完成的,所以DX10的初始化及绘制工作都是视图类中完成。 首先建立一个多文档工程,工程名为02_01,在视图类头文件中加载相关的库,并包含头文件: 在视图类的头文件中添加DX10相关的成员: …

碾压Bert?“屠榜”的XLnet对NLP任务意味着什么
作者张俊林,中国中文信息学会理事,中科院软件所博士。目前担任新浪微博机器学习团队 AI Lab 负责人。在此之前,张俊林曾经在阿里巴巴任资深技术专家并负责新技术团队,以及在百度和用友担任技术经理及技术总监等职务。他是技术书籍…
ORACLE中通过DBMS_CRYPTO包对表敏感字段进行加密
http://doc.primeton.com/pages/viewpage.action?pageId4917998

02 使用百度地图获得当前位置的经纬度
O 需求 通过百度地图,获取用户当前位置的经纬度 一 准备 确保你已按照上篇《01 如何将百度地图加入IOS应用程序?》完成了相关功能。本篇将在上一篇的基础上进行修改。 二 编码 (New标示本次新添加的代码;Delete表示本次需要删除的代码&#x…
中文NLP的分词真有必要吗?李纪为团队四项任务评测一探究竟 | ACL 2019
作者| Yuxian Meng、Xiaoya Li、Xiaofei Sun、Qinghong Han、Arianna Yuan、 Jiwei Li译者 | Rachel责编 | Jane出品 | AI科技大本营(ID: rgznai100)【导读】通常,中文文本处理的第一步称为分词,这好像已经成为一种“共识”&#…

Netty 粘包 拆包 编码 解码 序列化 介绍
目录: 粘包 & 拆包及解决方案 ByteToMessageDecoder基于长度编解码器基于分割符的编解码器google 的 Protobuf 序列化介绍其他的前言 Netty 作为一个网络框架,对 TCP 连接中的问题都做了全面的考虑,比如粘包拆包导致的半包问题࿰…
matlab 全局变量
转自:http://matlab.net.cn/matlabjichu/2010/201005/265.html 如果你要多于一个函数共用一个简单的变量,简单的处理方法就是把这个变量在所有函数中定义为global全局变量。在命令行做同样的事情,如果你要工作空间访问上述变量。这个全局变量…
java 解决Html table的rowspan问题(osc处女作)
2019独角兽企业重金招聘Python工程师标准>>> 假如有如下html代码需要解析 <table border"1"><tr><td rowspan"3">1</td><td>1</td><td>1</td><td>1</td></tr><tr>&l…
基于C++的OpenCV常用函数
C版本的好处: 1、在于可以尽量避免使用指针这种危险的东西; 2、不用费心去release资源了,因为在其destructor里面,系统会自动帮你搞定。 3、在某些情况下会比C版本运行速度快。 在文件中包含 using namespace cv; 1. i…

基于GAN的图像水印去除器,效果堪比PS高手
作者 | 李翔转载自视说AI(ID:techtalkai)简介:李翔,国内某互联网大厂AI民工,前携程酒店图像技术负责人,计算机视觉和深度学习重度爱好者,在ICCV和CVPR等会议上发表论文十余篇。写在前面当前互联…

Flink最锋利的武器:Flink SQL入门和实战 | 附完整实现代码
作者 | 机智的王知无转载自大数据技术与架构(ID: import_bigdata)一、Flink SQL 背景Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。自 2015 年开始,阿里巴巴开始…
SQL SERVER中ROLLUP的用法
cube操作符 要使用cube,首先要了解group by 其实cube和rollup区别不太大,只是在基于group by 子句创建和汇总分组的可能的组合上有一定差别, cube将返回的更多的可能组合。如果在 group by 子句中有n个列或者是有n个表达式的话, s…

Mybait缓存机制
MyBatis同大多数ORM框架一样,提供了一级缓存和二级缓存的支持。 一级缓存:其作用域为session范围内,当session执行flush或close方法后,一级缓存会被清空。 二级缓存:二级缓存和一级缓存机制相同,但是可以自…
vs2008常用操作汇总
1、OpenCV2.1环境配置: (1)、Tools-->Options-->Projects and Solutions-->VCDrectories: Show directories for选择include files,加入目录 D:/Program Files/OpenCV2.1/include/opencv ;Show directories for选择libra…

深度学习已至“瓶颈”?英特尔:数据处理是一剂良药
【导读】霍金弟子Alan Yuille在前不久发表言论称,至少在计算机视觉领域,深度学习的瓶颈已至。然而,人工智能与大数据的发展相辅相成,数据将会推动人工智能的发展,促进更多技术应用落地,将人工智能带入一个新…
WIN32 C++ 遍历文件夹
转自:http://blog.csdn.net/lizhigang770/archive/2010/11/30/6045242.aspx 一、先介绍一个结构 WIN32_FIND_DATA typedef struct _WIN32_FIND_DATA { DWORD dwFileAttributes; // 文件属性 FILETIME ftCreationTime; // 文件创建时间 FILETIME ft…
UIView淡入淡出动画
小小原创,转载请注明出处:http://iphone.xiaoxiaostudio.net 如果你觉得为某个UIView 加载一个全新的View在这个UIView上面时,想要隐藏时setHidden显得太突兀了,我们可以给它增加一些动画,iOS上默认提供了一些动画&…
sass的继承,混合宏,占位符的用法总结
SCSS中混合宏使用 mixin mt($var){ margin-top: $var; }.block { include mt(5px);span { display:block; include mt(5px); } }extend如何工作 .icon {transition: background-color ease .2s;margin: 0 .5em;}.error-icon {extend .icon;/*错误图标指定的样式... */}.info-i…
js中cookie的使用详细分析
2019独角兽企业重金招聘Python工程师标准>>> JavaScript中的另一个机制:cookie,则可以达到真正全局变量的要求。 cookie是浏览器 提供的一种机制,它将document 对象的cookie属性提供给JavaScript。可以由JavaScript对其进行控制&a…

从事JAVA 20年最终却败给了Python,哭了!
之前遇到一个老师,他从事Java行业20年了,在Python兴起的时候,他周围的其他同行们都在纷纷学习Python方面的知识,连他的学生也问他“老师,你为什么不学Python呢?”。当这位听到学生这个问题的时候࿰…
c++删除文件夹
转自:http://blog.csdn.net/sshhbb/archive/2010/12/07/6061029.aspx c语言本身是不能删除文件或文件夹的,他们是windows操作系统里的东西,所以得借助其api函数。 其一:使用shell 接口: void FileDelete(CString di…
解决bootstrap下的图片自适应问题
.img-responsive {display: block; height: auto; max-width: 100%; }转载于:https://www.cnblogs.com/qjuly/p/9809910.html

边缘检测、Hough变换、轮廓提取、种子填充、轮廓跟踪
转自:http://blog.sina.com.cn/s/blog_6c083cdd0100nm4s.html 7.1 边沿检测 我们给出一个模板 和一幅图象 。不难发现原图中左边暗,右边亮,中间存在着一条明显的边界。进行模板操作后的结果如下: 。 可以看出,第3…
JS Array 中 shift 和 pop 的妙用
在 JS Array 中支持两个方法,shift() 和 pop(),分别是指从一个数据中的最前面和最后面删除一个值,并返删除值。看一个示例就明白了: var arr [s,o,f,i,s,h]; arr.shift(); // 返回 s arr; // 目前是 [o,f,i,s,h…

当今主流分割网络有哪些?12篇文章一次带你看完
作者 | 孙叔桥来源 | 转载自有三AI(ID: yanyousan_ai)本文的12篇文章总结了当前主流的分割网络及其结构,涵盖从编解码结构到解码器设计;从感受野到多尺度融合;从CNN到RNN与CRF;从2D分割到3D分割;…
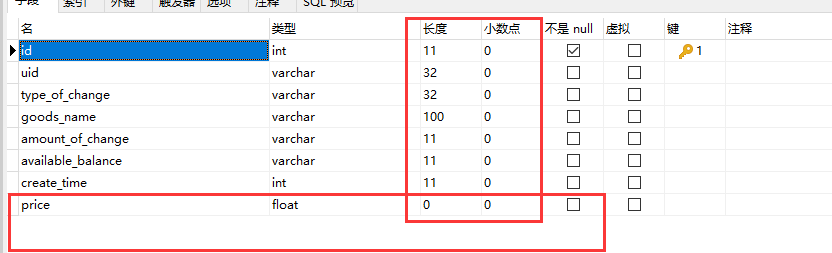
正确生成浮点型的方法,解决sqlachemy Float浮点型的坑,生成float类型时,长度和精度均为0,导致查询不到结果!...
问题描述 在使用flask_sqlachemy时,给price字段选择了Float类型,数据库用的mysql,生成数据库表后,发现 from sqlalchemy import Float,Column price Column(Float,default0.00) 虽然能存储float类型,结果如下 但是查询…
图像轮廓的提取和绘制
转自:http://blog.csdn.net/gnuhpc/archive/2009/06/18/4278105.aspx <>var ultimaFecha ; <>document.write(ultimaFecha); #include "highgui.h" #include "cv.h" #include <iostream> #include <iomanip> using …
上海交大张拳石:神经网络的可解释性,从经验主义到数学建模
作者 | 张拳石来源 | 转载自知乎Qs.Zhang张拳石本来想把题目取为“从炼丹到化学”,但是这样的题目太言过其实,远不是近期可以做到的,学术研究需要严谨。但是,寻找适当的数学工具去建模深度神经网络表达能力和训练能力,…