从原理到代码,轻松深入逻辑回归模型!

整理 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导语】学习逻辑回归模型,今天的内容轻松带你从0到100!阿里巴巴达摩院算法专家、阿里巴巴技术发展专家、阿里巴巴数据架构师联合撰写,从技术原理、算法和工程实践3个维度系统展开,既适合零基础读者快速入门,又适合有基础读者理解其核心技术;写作方式上避开了艰涩的数学公式及其推导,深入浅出。
0、前言
简单理解逻辑回归,就是在线性回归基础上加一个 Sigmoid 函数对线性回归的结果进行压缩,令其最终预测值 y 在一个范围内。这里 Sigmoid 函数的作用就是将一个连续的数值压缩到一定范围内,它将最终预测值 y 的范围压缩到在 0 到 1 之间。虽然逻辑回归也有回归这个词,但由于这里的自变量和因变量呈现的是非线性关系,因此严格意义上讲逻辑回归模型属于非线性模型。逻辑回归模型通常用来处理二分类问题,如图 4-4 所示。在逻辑回归中,计算出的预测值是一个 0 到 1 的概率值,通常的,我们以 0.5 为分界线,如果预测的概率值大于 0.5 则会将最终结果归为 1 这个类别,如果预测的概率值小于等于 0.5 则会将最终结果归为 0 这个类别。而 1 和 0 在实际项目中可能代表了很多含义,比如 1 代表恶性肿瘤,0 代表良性肿瘤,1 代表银行可以给小王贷款,0 代表银行不能给小王贷款等等。
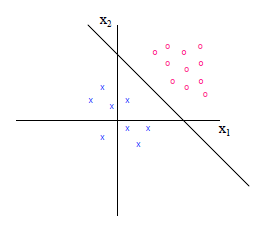
图4-4 逻辑回归分类示意图
虽然逻辑回归很简单,但它被广泛应用在实际生产之中,而且通过改造逻辑回归也可以处理多分类问题。逻辑回归不仅本身非常受欢迎,它同样也是我们将在第 5 章介绍的神经网络的基础。普通神经网络中,常常使用 Sigmoid 对神经元进行激活。关于神经网络的神经元,第 5 章会有详细的介绍(第 5 章会再次提到 Sigmoid 函数),这里只是先提一下逻辑回归和神经网络的关系,读者有个印象。
1、Sigmoid 函数
Sigmoid 的函数表达式如下:
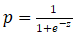
该公式中,e 约等于 2.718,z 则是线性回归的方程式,p 为计算出来的概率,范围在 0 到 1 之间。接下来我们将这个函数绘制出来,看看它的形状。使用 Python 的 Numpy 以及 Matplotlib 库进行编写,代码如下:
import numpy as np
import matplotlib.pyplot as plt def sigmoid(x): y = 1.0 / (1.0 + np.exp(-x)) return y plot_x = np.linspace(-10, 10, 100)
plot_y = sigmoid(plot_x)
plt.plot(plot_x, plot_y)
plt.show()效果如图 4-5 所示:
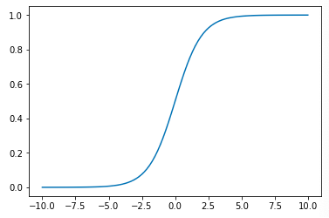
图4-5 Sigmoid函数
我们对上图做一个解释,当 x 为 0 的时候,Sigmoid 函数值为 0.5,随着 x 的不断增大,对应的 Sigmoid 值将无线逼近于 1;而随着 x 的不断的减小,Sigmoid 值将不断逼近于 0 。所以它的值域是在 (0,1) 之间。由于 Sigmoid 函数将实数范围内的数值压缩到(0,1)之间,因此也被称为压缩函数。但这里多提一下,压缩函数其实可以有很多,比如 tanh 可以将实数范围内的数值压缩到(-1,1)之间,因此 tanh 有时也会被成为压缩函数。
2、 梯度下降法
在学习 4.1.1 小节的时候,我们在介绍一元线性回归模型的数学表达之后又介绍了一元线性回归模型的训练过程。类似的,在 4.2.1 小节学习完逻辑回归模型的数学表达之后我们来学习逻辑回归模型的训练方法。首先与 4.1.1 小节类似,我们首先需要确定逻辑回归模型的评价方式,也就是模型的优化目标。有了这个目标,我们才能更好地“教”模型学习出我们想要的东西。这里的目标也和 4.1.1 一样,定义为
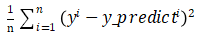
接下来是选择优化这个目标的方法,也就是本小节中重点要介绍的梯度下降法。
首先带大家简单认识一下梯度下降法。梯度下降算法(Gradient Descent Optimization)是常用的最优化方法之一。“最优化方法”属于运筹学方法,它指在某些约束条件下,为某些变量选取哪些的值,使得设定的目标函数达到最优的问题。最优化方法有很多,常见的有梯度下降法、牛顿法、共轭梯度法等等。由于本书重点在于带大家快速掌握“图像识别”技能,因此暂时不对最优化方法进行展开,感兴趣的读者可以自行查阅相关资料进行学习。由于梯度下降是一种比较常见的最优化方法,而且在后续第 5 章、第 7 章的神经网络中我们也将用到梯度下降来进行优化,因此我们将在本章详细介绍该方法。
接下来我们以图形化的方式带领读者学习梯度下降法。
我们在 Pycharm 新建一个 python 文件,然后键入以下代码:
import numpy as np
import matplotlib.pyplot as plt
if __name__ == '__main__': plot_x = np.linspace(-1, 6, 141) #从-1到6选取141个点 plot_y = (plot_x - 2.5) ** 2 – 1 #二次方程的损失函数 plt.scatter(plot_x[5], plot_y[5], color='r') #设置起始点,颜色为红色 plt.plot(plot_x, plot_y) # 设置坐标轴名称 plt.xlabel('theta', fontproperties='simHei', fontsize=15) plt.ylabel('损失函数', fontproperties='simHei', fontsize=15) plt.show()通过上述代码,我们就能画出如图 4-6 所示的损失函数示意图,其中 x 轴代表的是我们待学习的参数 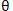 (theta),y 轴代表的是损失函数的值(即 loss 值),曲线 y 代表的是损失函数。我们的目标是希望通过大量的数据去训练和调整参数,使损失函数的值最小。想要达到二次方程的最小值点,可以通过求导数的方式,使得导数为 0 即可。也就是说,横轴上 2.5 的位置对应损失最小,在该点上一元二次方程
(theta),y 轴代表的是损失函数的值(即 loss 值),曲线 y 代表的是损失函数。我们的目标是希望通过大量的数据去训练和调整参数,使损失函数的值最小。想要达到二次方程的最小值点,可以通过求导数的方式,使得导数为 0 即可。也就是说,横轴上 2.5 的位置对应损失最小,在该点上一元二次方程 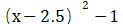 切线的斜率则为 0。暂且将导数描述为
切线的斜率则为 0。暂且将导数描述为 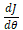 ,其中 J 为损失函数,为待求解的参数。
,其中 J 为损失函数,为待求解的参数。
梯度下降中有个比较重要的参数:学习率 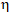 (读作eta,有时也称其为步长),它控制着模型寻找最优解的速度。加入学习率后的数学表达为
(读作eta,有时也称其为步长),它控制着模型寻找最优解的速度。加入学习率后的数学表达为 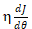 。
。
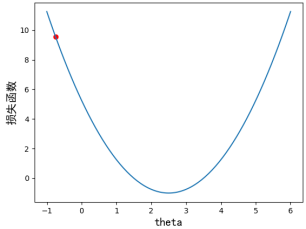
图4-6 损失函数示意图
接下来我们画图模拟梯度下降的过程。
1. 首先定义损失函数及其导数
def J(theta): #损失函数 return (theta-2.5)**2 -1 def dJ(theta): #损失函数的导数 return 2 * (theta - 2.5)2. 通过 Matplotlib 绘制梯度下降迭代过程,具体代码如下:
theta = 0.0 #初始点
theta_history = [theta]
eta = 0.1 #步长
epsilon = 1e-8 #精度问题或者eta的设置无法使得导数为0
while True: gradient = dJ(theta) #求导数 last_theta = theta #先记录下上一个theta的值 theta = theta - eta * gradient #得到一个新的theta theta_history.append(theta) if(abs(J(theta) - J(last_theta)) < epsilon): break #当两个theta值非常接近的时候,终止循环
plt.plot(plot_x,J(plot_x),color='r')
plt.plot(np.array(theta_history),J(np.array(theta_history)),color='b',marker='x')
plt.show() #一开始的时候导数比较大,因为斜率比较陡,后面慢慢平缓了
print(len(theta_history)) #一共走了46步我们来看下所绘制的图像是什么样子的,可以观察到 从初始值 0.0 开始不断的向下前进,一开始的幅度比较大,之后慢慢趋于缓和,逐渐接近导数为 0,一共走了 46 步。如图 4-7 所示:
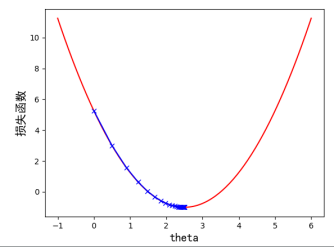
图4-7 一元二次损失函数梯度下降过程示意图
3、学习率的分析
上一小节我们主要介绍了什么是梯度下降法,本小节主要介绍学习率对于梯度下降法的影响。
第一个例子,我们将 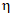 设置为 0.01(之前是 0.1 ),我们会观察到,步长减少之后,蓝色的标记更密集,说明步长减少之后,从起始点到导数为 0 的步数增加了。步数变为了 424 步,这样整个学习的速度就变慢了。效果如图 4-8 所示:
设置为 0.01(之前是 0.1 ),我们会观察到,步长减少之后,蓝色的标记更密集,说明步长减少之后,从起始点到导数为 0 的步数增加了。步数变为了 424 步,这样整个学习的速度就变慢了。效果如图 4-8 所示:
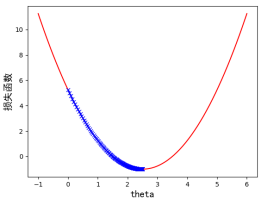
图4-8 学习率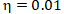 时,一元二次损失函数梯度下降过程示意图
时,一元二次损失函数梯度下降过程示意图
第二个例子,我们将 设置为 0.8,我们会观察到,代表蓝色的步长在损失函数之间跳跃了,但在跳跃过程中,损失函数的值依然在不断的变小。步数是 22 步,因此当学习率为 0.8 时,优化过程时间缩短,但是最终也找到了最优解。效果如图 4-9 所示:
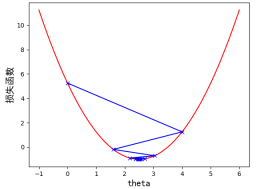
图4-9 学习率 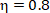 时,一元二次损失函数梯度下降过程示意图
时,一元二次损失函数梯度下降过程示意图
第三个例子,我们将设置为1.1,看一下效果。这里注意,学习率本身是一个 0 到 1 的概率,因此 1.1 是一个错误的值,但为了展示梯度过大会出现的情况,我们暂且用这个值来画图示意。我们会发现程序会报这个错误 OverflowError: ( 34, 'Result too large' )。我们可以想象得到,这个步长跳跃的方向导致了损失函数的值越来越大,所以才报了“Result too large”效果,我们需要修改下求损失函数的程序:
def J(theta): try: return (theta-2.5)**2 -1 except: return float('inf')i_iter= 0 n_iters = 10 while i_iter < n_iters: gradient = dJ(theta) last_theta = theta theta = theta - eta * gradient i_iter += 1 theta_history.append(theta) if (abs(J(theta) - J(last_theta)) < epsilon): break # 当两个theta值非常接近的时候,终止循环另外我们需要增加一下循环的次数。
我们可以很明显的看到,我们损失函数在最下面,学习到的损失函数的值在不断的增大,也就是说模型不会找到最优解。如图 4-10 所示:
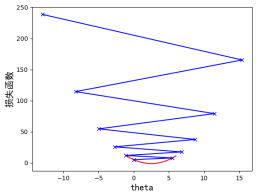
图4-10 学习率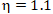 时,一元二次损失函数不收敛
时,一元二次损失函数不收敛
通过本小节的几个例子,简单讲解了梯度下降法,以及步长 的作用。从三个实验我们可以看出,学习率是一个需要认真调整的参数,过小会导致收敛过慢,而过大可能导致模型不收敛。
4、逻辑回归的损失函数
逻辑回归中的 Sigmoid 函数用来使值域在(0,1)之间,结合之前所讲的线性回归,我们所得到的完整的公式其实是: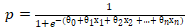 ,其中的
,其中的 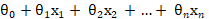 就是之前所介绍的多元线性回归。
就是之前所介绍的多元线性回归。
现在的问题就比较简单明了了,对于给定的样本数据集 X,y,我们如何找到参数 theta ,来获得样本数据集 X 所对应分类输出 y(通过p的概率值)
需要求解上述这个问题,我们就需要先了解下逻辑回归中的损失函数,假设我们的预测值为:
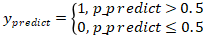
损失函数假设为下面两种情况,y 表示真值;表示为预测值:
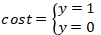
结合上述两个假设,我们来分析下,当 y 真值为 1 的时候,p 的概率值越小(越接近0),说明y的预测值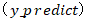 偏向于0,损失函数 cost 就应该越大;当 y 真值为 0 的时候,如果这个时候 p 的概率值越大则同理得到损失函数 cost 也应该越大。在数学上我们想使用一个函数来表示这种现象,可以使用如下这个:
偏向于0,损失函数 cost 就应该越大;当 y 真值为 0 的时候,如果这个时候 p 的概率值越大则同理得到损失函数 cost 也应该越大。在数学上我们想使用一个函数来表示这种现象,可以使用如下这个:
我们对上面这个函数做一定的解释,为了更直观的观察上述两个函数,我们通过 Python 中的 Numpy 以及 Matplotlib 库进行绘制。
我们先绘制下 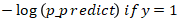 ,代码如下:
,代码如下:
import numpy as np
import matplotlib.pyplot as plt def logp(x): y = -np.log(x) return y plot_x = np.linspace(0.001, 1, 50) #取0.001避免除数为0 plot_y = logp(plot_x)
plt.plot(plot_x, plot_y)
plt.show() 如下图4-9所示:
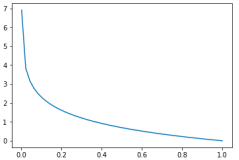
图4-9 损失函数if y=1
当p=0的时候,损失函数的值趋近于正无穷,根据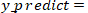
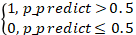 说明y的预测值 偏向于0,但实际上我们的 y 真值为 1 。当 p 达到 1 的时候,y 的真值和预测值相同,我们能够从图中观察到损失函数的值趋近于 0 代表没有任何损失。
说明y的预测值 偏向于0,但实际上我们的 y 真值为 1 。当 p 达到 1 的时候,y 的真值和预测值相同,我们能够从图中观察到损失函数的值趋近于 0 代表没有任何损失。
我们再来绘制一下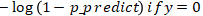 ,代码如下:
,代码如下:
import numpy as np
imort matplotlib.pyplot as plt def logp2(x): y = -np.log(1-x) return y plot_x = np.linspace(0, 0.99, 50) #取0.99避免除数为0
plot_y = logp2(plot_x)
plt.plot(plot_x, plot_y)
plt.show() 效果如图4-10所示:
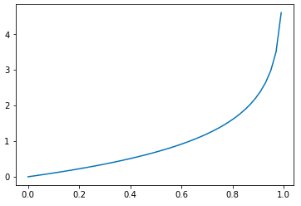
图4-10 损失函数 if y=0
当p=1的时候,损失函数的值趋近于正无穷,根据 说明y的预测值 偏向于 1,但实际上我们的 y 真值为 0 。当 p 达到 0 的时候,y 的真值和预测值相同,我们能够从图中观察到损失函数的值趋近于 0 代表没有任何损失。
我们再对这两个函数稍微整理下,使之合成一个损失函数:
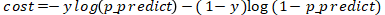
对这个函数稍微解释下,当 y=1 的时候,后面的式子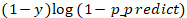 就变为了 0 ,所以整个公式成为了
就变为了 0 ,所以整个公式成为了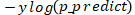 ;当 y=0 的时候前面的式子
;当 y=0 的时候前面的式子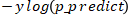 变为了 0,整个公式就变为了
变为了 0,整个公式就变为了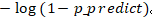 。
。
最后就变为了,对m个样本,求一组值使得损失函数最小。
公式如下:
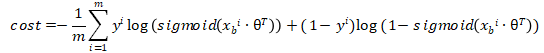
(其中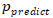 = sigmoi
= sigmoi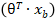 ;其中
;其中 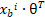 代表了
代表了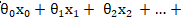
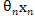 ;
;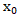 恒等于1;
恒等于1;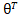 为列向量)。
为列向量)。
当公式变为上述的时候,对于我们来说,只需要求解一组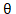 使得损失函数最小就可以了,那么对于如此复杂的损失函数,我们一般使用的是梯度下降法进行求解。
使得损失函数最小就可以了,那么对于如此复杂的损失函数,我们一般使用的是梯度下降法进行求解。
5、Python实现逻辑回归
结合之前讲的理论,本小节开始动手实现一个逻辑回归算法。首先我们定义一个类,名字为 LogisticRegressionSelf ,其中初始化一些变量:维度、截距、theta 值,代码如下:
class LogisticRegressionSelf: def __init__(self): """初始化Logistic regression模型""" self.coef_ = None #维度 self.intercept_ = None #截距 self._theta = None接着我们实现下在损失函数中的 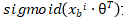 这个函数,我们之前在
这个函数,我们之前在
Sigmoid 函数那个小节已经实现过了,对于这个函数我们输入的值为多元线性回归中的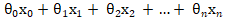 (其中恒等于1),为了增加执行效率,我们建议使用向量化来处理,而尽量避免使用 for 循环,所以对于
(其中恒等于1),为了增加执行效率,我们建议使用向量化来处理,而尽量避免使用 for 循环,所以对于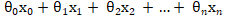 我们使用
我们使用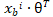 来代替,具体代码如下:
来代替,具体代码如下:
def _sigmoid(x): y = 1.0 / (1.0 + np.exp(-x)) return y接着我们来实现损失函数,
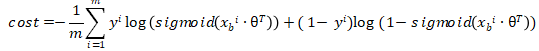
代码如下:
#计算损失函数 def J(theta,X_b,y): p_predcit = self._sigmoid(X_b.dot(theta)) try: return -np.sum(y*np.log(p_predcit) + (1-y)*np.log(1-p_predcit)) / len(y) except: return float('inf')然后我们需要实现下损失函数的导数。具体求导过程读者可以自行百度,我们这边直接给出结论,对于损失函数cost,得到的导数值为: 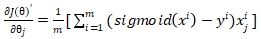 ,其中
,其中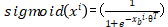 ,之前提过考虑计算性能尽量避免使用 for 循环实现累加,所以我们使用向量化计算。
,之前提过考虑计算性能尽量避免使用 for 循环实现累加,所以我们使用向量化计算。
完整代码如下:
import numpy as np class LogisticRegressionSelf: def __init__(self): """初始化Logistic regression模型""" self.coef_ = None #维度 self.intercept_ = None #截距 self._theta = None #sigmoid函数,私有化函数 def _sigmoid(self,x): y = 1.0 / (1.0 + np.exp(-x)) return y def fit(self,X_train,y_train,eta=0.01,n_iters=1e4): assert X_train.shape[0] == y_train.shape[0], '训练数据集的长度需要和标签长度保持一致' #计算损失函数 def J(theta,X_b,y): p_predcit = self._sigmoid(X_b.dot(theta)) try: return -np.sum(y*np.log(p_predcit) + (1-y)*np.log(1-p_predcit)) / len(y) except: return float('inf') #求sigmoid梯度的导数 def dJ(theta,X_b,y): x = self._sigmoid(X_b.dot(theta)) return X_b.T.dot(x-y)/len(X_b) #模拟梯度下降 def gradient_descent(X_b,y,initial_theta,eta,n_iters=1e4,epsilon=1e-8): theta = initial_theta i_iter = 0 while i_iter < n_iters: gradient = dJ(theta,X_b,y) last_theta = theta theta = theta - eta * gradient i_iter += 1 if (abs(J(theta,X_b,y) - J(last_theta,X_b,y)) < epsilon): break return theta X_b = np.hstack([np.ones((len(X_train),1)),X_train]) initial_theta = np.zeros(X_b.shape[1]) #列向量 self._theta = gradient_descent(X_b,y_train,initial_theta,eta,n_iters) self.intercept_ = self._theta[0] #截距 self.coef_ = self._theta[1:] #维度 return self def predict_proba(self,X_predict): X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict]) return self._sigmoid(X_b.dot(self._theta)) def predict(self,X_predict): proba = self.predict_proba(X_predict) return np.array(proba > 0.5,dtype='int')小结
以上内容主要讲述了线性回归模型和逻辑回归模型,并做了相应的实现。其中线性回归是逻辑回归的基础,而逻辑回归经常被当做神经网络的神经元,因此逻辑回归又是神经网络的基础。我们借逻辑回归模型介绍了机器学习中离不开的最优化方法,以及最常见的最优化方法——梯度下降。了解本节内容会对接下来第 5 章神经网络的学习有着很大的帮助。本文摘自《深度学习与图像识别:原理与实践》,经出版方授权发布。

作者介绍
魏溪含
爱丁堡大学人工智能硕士,阿里巴巴达摩院算法专家,在计算机视觉、大数据领域有8年以上的算法架构和研发经验。
在大数据领域,曾带领团队对阿里巴巴个性化推荐系统进行升级;计算机视觉领域,主导并攻克了光伏 EL 全自动瑕疵识别的世界难题,并在行为识别领域带领团队参赛打破世界纪录等。
涂铭
阿里巴巴数据架构师,对大数据、自然语言处理、图像识别、Python、Java 相关技术有深入的研究,积累了丰富的实践经验。在工业领域曾参与了燃煤优化、设备故障诊断项目,正泰光伏电池片和组件 EL 图像检测项目;在自然语言处理方面,担任导购机器人项目的架构师,主导开发机器人的语义理解、短文本相似度匹配、上下文理解,以及通过自然语言检索产品库,在项目中构建了 NoSQL+文本检索等大数据架构,也同时负责问答对的整理和商品属性的提取,带领 NLP 团队构建语义解析层。
张修鹏
毕业于中南大学,阿里巴巴技术发展专家,长期从事云计算、大数据、人工智能与物联网技术的商业化应用,在阿里巴巴首次将图像识别技术引入工业,并推动图像识别产品化、平台化,擅于整合前沿技术解决产业问题,主导多个大数据和AI为核心的数字化转型项目成功实施,对技术和商业结合有着深刻的理解。
◆
精彩推荐
◆
AI ProCon 2019 邀请到了亚马逊首席科学家@李沐,在大会的前一天(9.5)亲授「深度学习实训营」,通过动手实操,帮助开发者全面了解深度学习的基础知识和开发技巧。

9大技术论坛、60+主题分享,百余家企业、千余名开发者共同相约 2019 AI ProCon!技术驱动产业,聚焦技术实践,倾听大牛分享,和万千开发者共成长。5折优惠票抢购中!

社群福利
扫码添加小助手,回复:大会,加入2019 AI开发者大会福利群,每周一、三、五 更新学习资源、技术福利,还有抽奖活动~

推荐阅读
最前沿:堪比E=mc2,Al-GA才是实现AGI的指标性方法论?
开源之战《乐队的夏天》很酷?程序员式的摇滚才燃爆了!
60 岁的人工智能,会是“人类历史最后的事件”吗?
AI“生死”落地:谁有资格入选AI Top 30+案例?
没看完这11 条,别说你精通Python装饰器
Zend 创始人欲创建 PHP 方言,暂名为 P++;鸿蒙 OS 面世;中国首个开源协议诞生 | 开发者周刊
再见!微服务
屌!小哥用 12 个月的时间开发了12款比特币Dapp, 0.00000001 BTC就能玩区块链版"蚂蚁庄园"
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

JVM内存管理学习总结(一)
I.JVM进程的生命周期 JVM实例的生命周期和java程序的生命周期保持一致,即一个新的程序启动则产生一个新的JVM进程实例,程序结束则JVM进程实例伴随着消失。那么程序启动和程序终止就是JVM实例生命周期的两个边界,两个边界点可以这么理解&#…
开源库Simd在vs2010中的编译及简单使用
Simd是开源的图像处理库,它提供了很多高性能的算法,这些优化算法主要由SIMD指令来实现,包括SSE、SSE2、SSSE3、SSE4.1、SSE4.2、AVX等,此库可以应用在windows/linux 32bit/64bit等系统中。此库更新较频繁。此库的license是MIT。下…
Dubbo2.6.5+Nacos注册中心(代替Zookeeper)
在上一节的小栗子的基础上,只需要更改两个地方 第一个:父工程的pom依赖增加 <!-- Dubbo Nacos registry dependency --><dependency><groupId>com.alibaba</groupId><artifactId>dubbo-registry-nacos</artifactId>…

Nginx(二) 配置与调试
nginx 主配置文件在安装目录下的conf中,名字为nginx.conf:主配置文件主要分为4部分:main(全局设置)、server(主机设置)、upstream(负载均衡服务器设置)和location&#x…
AI编程语言图鉴
作者 | 元宵大师责编 | 胡巍巍来源 | CSDN(CSDNnews)当前最炙手可热的领域非“人工智能”(Artificial Intelligence)莫属。其实,“人工智能”的火热并非一蹴而就,早在1956年“人工智能”概念就已经被提出了…
C++动态二维数组演示的代码
将代码过程中经常用到的代码珍藏起来,下边资料是关于C动态二维数组演示的代码。 #include <iostream> #include <string>using namespace std;{for( int i 0; i < x; i ){List[i] new int[y];for( int j 0; j < y; j ){List[i][j] 0;}}for( i…

linux发送email错误 501 Syntax: HELO hostname
2019独角兽企业重金招聘Python工程师标准>>> 查看你的hostname hostnamecentos58 然后vi /etc/hosts 添加hostname对应的ip 103.24.3.171 centos58 参考http://blog.csdn.net/tammy_zhu/article/details/5563383 转载于:https://my.oschina.net/u/257088/bl…
redux-thunk使用教程
从无到有一步一步创建一个react-redux、redux-thunk使用教程:本教程GitHub地址:https://github.com/chunhuigao/react-redux-thunk创建react工程在电脑上找一个文件夹,在命令窗使用create-react-app 创建我的react工程;这一步应该…
VLC SDK在VS2010中的配置及简单使用举例
1. 从http://www.videolan.org/vlc/download-windows.html下载vlc-2.2.0-win32.7z,解压缩;2. 新建一个VLCtest控制台工程;3. 将/vlc-2.2.0-win32/vlc-2.2.0/sdk/include添加到工程属性中,C/C -->General …

百万奖金悬赏AI垃圾分类,就问你来不来?
也许我们从来没有想过,看似简单的垃圾分类居然给“聪明”的人类带来如此大的困扰2019年7月1日,史称“最严格的垃圾分类法”《上海市生活垃圾管理条例》正式开始施行一夜之间上海人最常用的见面语从“侬好”变成了“侬是什么垃圾?”虽然只有可…
资质申报 - 系统集成企业资质等级评定条件(2012年修定版)
关于发布《计算机信息系统集成企业资质等级评定条件(2012年修定版)》的通知工信计资[2012]6号各省、自治区、直辖市、计划单列市工业和信息化主管部门、新疆生产建设兵团工业和信息化委员会、各级资质评审机构,各有关单…
@HostListener 可接收的事件列表
下面有一个文档详细介绍Angular 中的事件列表: https://github.com/angular/angular/blob/master/packages/compiler/src/schema/dom_element_schema_registry.ts#L78。 星号代表的是事件 (no prefix): property is a string.*: property represents an event.!: pr…
GraphSAGE: GCN落地必读论文
作者 | William L. Hamilton, Rex Ying, Jure Leskovec来源 | NIPS17导读:图卷积网络(Graph Convolutional Network,简称GCN)最近两年大热,取得不少进展。作为 GNN 的重要分支之一,很多同学可能对它还是一知…
Ubuntu14.04 32位上编译VLC2.2.0源码操作步骤
1. 首先安装必须的依赖软件,打开终端,执行:sudo apt-get install git libtool build-essential pkg-config autoconf2. 从 http://www.videolan.org/vlc/download-sources.html 下载vlc-2.2.0源码,将其存放到/home/spring/VLC目录…
根据PromiseA+规范实现Promise
Promise是ES6出现的一个异步编程的一个解决方案,改善了以往回调函数的回调地狱(虽然写起来也挺像的)。不会Promise的可以移步阮一峰的Promise,这里讲的非常清晰。 就现在的发展情况而言,Promise这种解决方案频繁的在我们的代码中出现…

黄浴:基于深度学习的超分辨率图像技术发展轨迹一览
作者 | 黄浴转载自知乎导读:近年来,使用深度学习技术的图像超分辨率(SR)取得了显著进步。本文中,奇点汽车自动驾驶首席科学家黄浴对基于深度学习技术的图像超分辨率技术进行了一次全面的总结,分析了这门技术…
Qt简介、安装及在Ubuntu14.04 32位上简单使用举例
Qt是一个跨平台的C图形用户界面应用程序开发框架。它既可以开发GUI程序,也可用于开发非GUI程序。Qt是面向对象的框架,很容易扩展。Qt是一个C工具包,它由几百个C类构成,你在程序中可以使用这些类。Qt具有OOP的所有优点。 跨平台的…
FOSCommentBundle功能包:设置Doctrine ODM映射(投票)
原文出处:12b-mapping_mongodb.md原文作者:FriendsOfSymfony授权许可:创作共用协议翻译人员:FireHare校对人员:适用版本:FOSCommentBundle 2.0.5文章状态:草译阶段Step 12b: Setup MongoDB mapp…
Python最大堆排序实现方法
Python最大堆排序实现方法,具体代码如下: # -*- coding: utf-8 -*- def merge_sort(seq, cmpcmp, sentinelNone): """合并排序,伪码如下: MERGE(A, p, q, r) 1 n1 ← q - p 1 // 前个子序列长度 2 …

内含福利 | 世界人工智能大会:对话大咖,深挖机器学习的商业应用
机器学习作为人工智能时代的关键技术突破,已经在日常生活中广泛应用,给用户带来便利。越来越多的企业也通过机器学习,解决生产和经营中的难题。传统制造业:应用机器学习,部署系统异常检测方案,预测组件寿命…
windows7 64位操作系统上使vs2010和vs2013能够并存的处理方法
之前机子上是只安装有vs2010,后来在没有卸载vs2010的情况下想装个vs2013,使vs2010与vs2013同时并存在windows764位机上。需要依次安装cn_visual_studio_ultimate_2013_x86_dvd_3009109.iso、vs2013.2.iso和vc_mbcsmfc.exe。在安装过程中遇到的问题有: (…
Spring Cloud Alibaba 基础教程:Nacos 生产级版本 0.8.0
Spring Cloud Alibaba 基础教程:Nacos 生产级版本 0.8.0 昨晚Nacos社区发布了第一个生产级版本:0.8.0。由于该版本除了Bug修复之外,还提供了几个生产管理非常重要的特性,所以觉得还是有必要写一篇讲讲这次升级,在后续的…
awk命令使用和取出数据的最大值,最小值和平均值
得到取出数据的最大值:cat manager.txt |grep monitor|awk {print$9}|sort -rn|head -1得到取出数据的最小值:cat manager.txt|grep monitor |awk {print $9}|sort -n|head -1得到取出数据的平均值:cat manager.txt|grep monitor |awk {print…
windows7 64位机上CUDA7.0配置及在VS2010中的简单使用举例
1. 查看本机配置,查看显卡类型是否支持NVIDIA GPU,选中计算机--> 右键属性 --> 设备管理器 --> 显示适配器:NVIDIA GeForce GT 610,从https://developer.nvidia.com/cuda-gpus可以查到相应显卡的compute capabili…
用友云平台,真正的云原生架构,加速云应用落地
数字化经济的出现,企业需要通过新技术实现数字化转型,完成企业管理和业务模式变革。而云计算是数字化中尤为重要且能够更快实现的技术手段。真正的云应用必须是基于云原生架构的,PaaS是一个重要的步骤,因为这是云原生的第一接触点…
从ACM班、百度到亚马逊,深度学习大牛李沐的开挂人生
“大神”,是很多人对李沐的印象。作为一经推出便大受追捧的 MXNet 深度学习框架的主要贡献者之一,李沐功不可没。值得注意的是,这个由 DMLC(Distributed Machine Learning Community)打造的深度学习框架,创…
Linux基础介绍
Linux的创始人Linus Torvalds。Linux的官方标准发音为[linəks]。Linux和Unix是非常像的,Linux就是根据Unix演变过来的。Linux是免费的,其实只是说Linux的内核免费。在Linux内核的基础上产生了众多的Linux版本。Linux的发行版说简单点就是将Linux内核与应…
Go在区块链的发展和演进
Go语言发展至今已经过去十年多了,是目前最流行的新兴语言,云计算领域的首选语言,而且目前随着区块链的流行,Go再次成为了这个领域的第一语言,以太坊,IBM的fabric等重量级的区块链项目都是基于Go开发。 原文…

一天掌握AI核心技术,上手应用,开发者该划哪些重点?
Alpha Go 只会下棋,却并不擅长垃圾分类;智能助手已经可以执行很多任务,但距离真正的人机自然交互还很远。如今 AI 的发展面临着诸多瓶颈,基础理论研究缺失,深度学习的黑箱属性无解,把一切托付于未知并不可靠…

学会这21条,你离Vim大神就不远了
来源 | Python编程时光(ID: Python-Time)导语:作者本人是 Vim 的重度使用者,就因为喜欢上这种双手不离键盘就可以操控一切的feel,Vim 可以让人对文本的操作更加精准、高效。对于未使用过 Vim 的朋友来说,可…