黄浴:基于深度学习的超分辨率图像技术发展轨迹一览

作者 | 黄浴
转载自知乎
导读:近年来,使用深度学习技术的图像超分辨率(SR)取得了显著进步。本文中,奇点汽车自动驾驶首席科学家黄浴对基于深度学习技术的图像超分辨率技术进行了一次全面的总结,分析了这门技术近年来的发展轨迹。
我们一般可以将现有的 SR 技术研究大致分为三大类:监督 SR ,无监督 SR 和特定领域 SR (人脸)。
监督SR
如今已经有各种深度学习的超分辨率模型。这些模型依赖于有监督的超分辨率,即用LR图像和相应的基础事实( GT )HR 图像训练。 虽然这些模型之间的差异非常大,但它们本质上是一组组件的组合,例如模型框架,上采样方法,网络设计和学习策略等。从这个角度来看,研究人员将这些组件组合起来构建一个用于拟合特定任务的集成 SR 模型。
由于图像超分辨率是一个病态问题,如何进行上采样(即从低分辨率产生高分辨率)是关键问题。基于采用的上采样操作及其在模型中的位置, SR 模型可归因于四种模型框架:预先采样 SR ,后上采样 SR ,渐进上采样 SR 和迭代上下采样 SR ,如图所示。
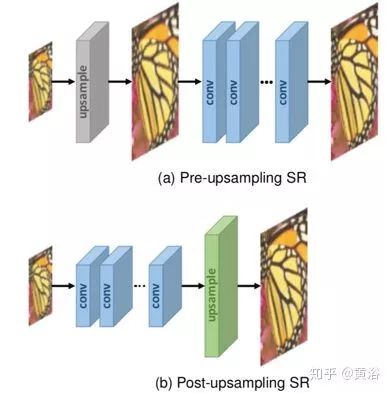
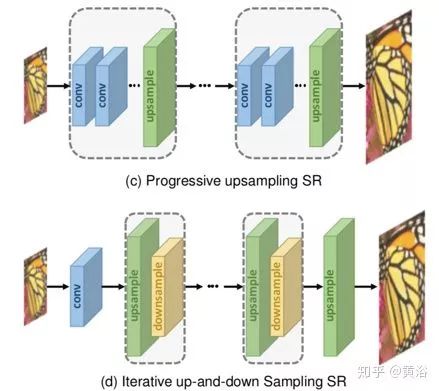
除了在模型中的位置之外,上采样操作如何实现它们也非常重要。为了克服插值法的缺点,并以端到端的方式学习上采样操作,转置卷积层(Transposed Convolution Layer)和亚像素层(Sub-pixel Layer)可以引入到超分辨率中。
转置卷积层,即反卷积层,基于尺寸类似于卷积层输出的特征图来预测可能的输入。具体地说,它通过插入零值并执行卷积来扩展图像,从而提高了图像分辨率。为了简洁起见,以 3×3 内核执行 2 次上采样为例,如图所示。首先,输入扩展到原始大小的两倍,其中新添加的像素值被设置为 0(b)。然后应用大小为 3×3、步长 1 和填充 1 的内核卷积(c)。这样输入特征图实现因子为2 的上采样,而感受野最多为 2×2 。
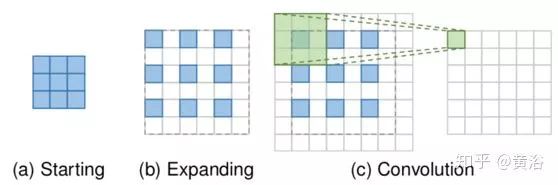
由于转置卷积层可以以端到端的方式放大图像大小,同时保持与 vanilla 卷积兼容的连接模式,因此它被广泛用作 SR 模型的上采样层。然而,它很容易在每个轴上产生“不均匀重叠(uneven overlapping)”,并且在两个轴的乘法进一步产生了特有的不同幅度棋盘状图案,从而损害了 SR 性能。
亚像素层也是端到端学习的上采样层,通过卷积生成多个通道然后重新整形,如图所示。首先卷积产生具有 s2 倍通道的输出,其中 s 是上采样因子(b)。假设输入大小为 h×w×c ,则输出大小为 h×w×s2c。之后,执行整形( shuffle )操作产生大小为 sh×sw×c 的输出(c)。感受野大小可以达到 3×3 。
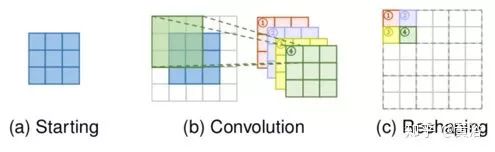
由于端到端的上采样方式,亚像素层也被 SR 模型广泛使用。与转置卷积层相比,亚像素层的最大优势是具有较大的感知场,提供更多的上下文信息,能帮助生成更准确的细节。然而,亚像素层的感受野的分布是不均匀的,块状区域实际上共享相同的感受野,这可能导致在块边界附近的一些畸变。
各种深度学习的模型已经被用于 SR ,如图所示。
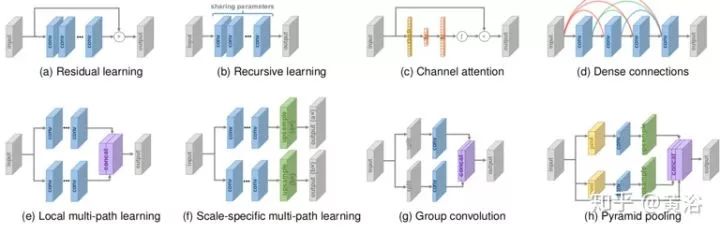
ResNet 学习残差而不是彻底的映射,已被 SR 模型广泛采用,如上图(a)所示。其中,残差学习策略可以大致分为两种类型,即全局和局部残差学习。
由于超分辨率是图像到图像的转换任务,其中输入图像与目标图像高度相关,全局残差学习仅学习两个图像之间的残差。在这种情况下,它避免学习从完整图像到另一个图像的复杂转换,而只需要学习残差图来恢复丢失的高频细节。由于大多数区域残差接近于零,模型的复杂性和学习难度都大大降低。这种方法在预上采样的 SR 框架普遍采用。
局部残差学习类似于 ResNet 的残差学习,用于缓解不断增加的网络深度引起的退化问题并提高学习能力。
实践中,上述方法都是通过快捷连接(通常有小常数因子的缩放)和逐元素加法操作实现的。区别在于,前者直接连接输入图像和输出图像,而后者通常在不同深度的网络中层之间添加多个快捷方式。
• 递归学习
递归学习(以递归方式多次应用相同模块)也被超分辨率采用,如上图 (b)所示。在实践中,递归学习固有地带来了消失(vanishing)或爆涨(exploding)梯度问题,因此残差学习和多信号监督等一些技术通常与递归学习相结合,以减轻这些问题。
• 通道关注
考虑到不同通道之间特征表征的相互依赖和作用,一种“挤压-激发(SAE,squeeze-and-excitation)”模块明确对通道相互依赖性建模,来提高表示能力,如上图(c)所示。其中用全局平均池化将每个输入通道压缩到通道描述子(即一个常数)中,然后将这些描述子馈送到两个全连接层产生通道尺度因子。基于通道乘法,用尺度因子重新缩放输入通道得到最终输出。
• 致密连接
致密连接在视觉任务中变得越来越流行。在致密块的每个层,所有前层的特征图用作输入,并且其自身特征图用作所有后续层的输入,在一个有 l 层致密块中带来 l·(l - 1)/ 2 个连接。致密连接,不仅有助于缓解梯度消失问题、增强信号的传播并促进特征重用,而且在连接之后采用小增长率(即致密块的通道数)和通道缩减来大大减少参数量。
为了融合低级和高级特征以提供更丰富的信息来重建高质量的细节,致密连接被引入 SR 领域,如上图(d)所示。
• 多路径学习
多路径学习指模型存在多个路径传递特征,这些路径执行不同的操作以提供更好的建模功能。具体而言,它可以分为三种类型:全局法、局部法和特定尺度法。
全局多路径学习是指用多个路径提取图像不同方面的特征。这些路径可以在传播中相互交叉,从而大大增强了特征提取的能力。
本地多路径学习用新块进行多尺度特征提取,如上图(e)所示。该块采用不同内核大小的卷积同时提取特征,然后将输出连接起来并再次进行相同的操作。快捷方式通过逐元素添加来连接该块的输出和输入。通过这种局部多路径学习,SR 模型可以更好地从多个尺度提取图像特征,进一步提高性能。
特定尺度多路径学习共享模型的主要部分(即特征提取的中间部分),并分别在网络的开头和结尾附加特定尺度的预处理路径和上采样路径,如上图(f)所示。在训练期间,仅启用和更新与所选尺度对应的路径。这样大多数参数在不同尺度上共享。
• 高级卷积
卷积运算是深度神经网络的基础,改进卷积运算可获得更好的性能或更快的速度。这里给出两个方法:扩张卷积( Dilated Convolution )和群卷积( Group Convolution )。 众所周知,上下文信息有助于在图像超分辨率生成逼真的细节。扩张卷积能将感受野增加两倍,最终实现更好的性能。群卷积以很少的性能损失可减少大量的参数和操作,如上图( g )所示。
• 像素递归学习
大多数 SR 模型认为这是一个与像素无关的任务,因此无法正确地确定生成像素之间的相互依赖性。在人注意力转移机制推动下,一种递推网络可依次发现参与的补丁并进行局部增强。以这种方式,模型能够根据每个图像自身特性自适应地个性化最佳搜索路径,从而充分利用图像全局的内依赖性( intra-dependence )。不过,需要长传播路径的递归过程,特别对超分辨率的 HR 图像,大大增加了计算成本和训练难度。
• 金字塔池化
金字塔池化模块更好地利用全局和局部的上下文信息,如上图( h )所示。 具体地,对于尺寸为 h×w×c 的特征图,每个特征图被划分为 M×M 个区间,并经历全局平均池化产生 M×M×c 个输出。 然后,执行 1×1 卷积输出压缩到一个单信道。 之后,通过双线性插值将低维特征图上采样到与原始特征图相同的大小。 使用不同的 M,该模块可以有效地整合全局和局部的上下文信息。
• 小波变换
众所周知,小波变换( WT )是一种高效的图像表示,将图像信号分解为表示纹理细节的高频小波和包含全局拓扑信息的低频小波。将 WT 与基于深度学习的 SR 模型相结合,这样插值 LR 小波的子带作为输入,并预测相应 HR 子带的残差。 WT 和逆 WT 分别用于分解LR输入和重建 HR 输出。
另外学习策略问题,涉及损失函数的设计(包括像素损失,内容损失,纹理损失,对抗损失和周期连续损失)、批处理归一化(BN)、课程学习(Curriculum Learning)和多信号监督( Multi-supervision )等等。
无监督SR
现有的超分辨率工作主要集中在监督学习上,然而难以收集不同分辨率的相同场景的图像,因此通常通过对 HR 图像预定义退化来获得 SR 数据集中的 LR 图像。为了防止预定义退化带来的不利影响,无监督的超分辨率成为选择。在这种情况下,只提供非配对图像( HR 或 LR )用于训练,实际上得到的模型更可能应对实际场景中的 SR 问题。
• 零击(zero shot)超分辨率
单个图像内部的统计数据足以提供超分辨率所需的信息,所以零击超分辨率(ZSSR)在测试时训练小图像特定的 SR 网络进行无监督 SR ,而不是在大数据集上训练通用模型。具体来说,核估计方法直接从单个测试图像估计退化内核,并在测试图像上执行不同尺度因子的退化来构建小数据集。然后在该数据集上训练超分辨率的小 CNN 模型用于最终预测。
ZSSR 利用图像内部特定信息的跨尺度复现这一特点,对非理想条件下(非 bi-cubic 退化核获得的图像,受模糊、噪声和压缩畸变等影响)更接近现实世界场景的图像,比以前的方法性能提高一大截,同时在理想条件下( bi-cubic 插值构建的图像),和以前方法结果差不多。尽管这样,由于需要在测试期间为每个图像训练单个网络,使得其测试时间远比其他 SR 模型长。
• 弱监督 SR
为了在超分辨率中不引入预退化,弱监督学习的 SR 模型,即使用不成对的 LR-HR 图像,是一种方案。一些方法学习 HR-LR 退化模型并用于构建训练 SR 模型的数据集,而另外一些方法设计周期循环( cycle-in-cycle )网络同时学习 LR-HR 和 HR-LR 映射。
由于预退化是次优的,从未配对的 LR-HR 数据集中学习退化是可行的。一种方法称为“两步法”:
- 1)训练 HR-LR 的 GAN 模型,用不成对的 LR-HR 图像学习退化;
- 2)基于第一个 GAN 模型,使用成对的 LR-HR 图像训练 LR- HR 的 GAN 模型执行 SR 。
对于 HR 到 LR 的 GAN 模型,HR 图像被馈送到生成器产生 LR 输出,不仅需要匹配 HR 图像缩小(平均池化)获得的 LR 图像,而且还要匹配真实LR图像的分布。训练之后,生成器作为退化模型生成 LR-HR 图像对。
对于 LR 到 HR 的 GAN 模型,生成器(即 SR 模型)将生成的 LR 图像作为输入并预测 HR 输出,不仅需要匹配相应的 HR 图像而且还匹配 HR 图像的分布 。在“两步法”中,无监督模型有效地提高了超分辨率真实世界LR图像的质量,比以前方法性能获得了很大改进。
无监督 SR 的另一种方法是将 LR 空间和 HR 空间视为两个域,并使用周期循环结构学习彼此之间的映射。这种情况下,训练目的包括推送映射结果去匹配目标的域分布,并通过来回( round trip )映射使图像恢复。
• 深度图像先验知识
CNN 结构在逆问题之前捕获大量的低级图像统计量,所以在执行 SR 之前可使用随机初始化的 CNN 作为手工先验知识。具体地讲,定义生成器网络,将随机向量 z 作为输入并尝试生成目标 HR 图像 I 。训练目标是网络找到一个 Iˆ y,其下采样 Iˆy 与 LR 图像 Ix 相同。 因为网络随机初始化,从未在数据集上进行过训练,所以唯一的先验知识是 CNN 结构本身。 虽然这种方法的性能仍然比监督方法差很多,但远远超过传统的 bicubic 上采样。此外,表现出的 CNN 架构本身合理性,促使将深度学习方法与 CNN 结构或自相似性等先验知识相结合来提高超分辨率。
特定SR
特定 SR 领域主要包括深度图、人脸图像、高光谱图像和视频等内容的 SR 应用。
面部图像超分辨率,即面部幻觉( FH, face hallucination ),通常可以帮助其他与面部相关的任务。与通用图像相比,面部图像具有更多与面部相关的结构化信息,因此将面部先验知识(例如,关键点,结构解析图和身份)结合到 FH 中是非常流行且有希望的方法。利用面部先验知识的最直接的方式是约束所生成的HR图像具有与基础事实(GT)的 HR 图像相同的面部相关信息。
与全色图像( PAN,panchromatic images ),即具有 3 个波段的 RGB 图像相比,有数百个波段的高光谱图像( HSI,hyperspectral images )提供了丰富的光谱特征并有助于各种视觉任务。 然而,由于硬件限制,收集高质量的 HSI 比收集 PAN 更困难,收集的 HSI 分辨率要低得多。 因此,超分辨率被引入该领域,研究人员倾向于将 HR PAN 和 LR HSI 结合起来预测 HR HSI 。就视频超分辨率而言,多个帧提供更多的场景信息,不仅有帧内空间依赖性而且有帧间时间依赖性(例如,运动、亮度和颜色变化)。 大多数方法主要集中在更好地利用时空依赖性,包括显式运动补偿(例如,光流算法、基于学习的方法)和递归方法等。
参考文献
- Z Wang, J Chen, S Hoi,“Deep Learning for Image Super-resolution: A Survey”, Arxiv 1902.06068,2019
- W Yang et al.,“Deep Learning for Single Image Super-Resolution: A Brief Review”, Archiv 1808.03344, 2018
- Z Li et al.,“Feedback Network for Image Super-Resolution”, CVPR 2019
- C Chen et al.,“Camera Lens Super-Resolution”, CVPR 2019
- K Zhang et al.,“Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels”, CVPR 2019
原文链接:https://zhuanlan.zhihu.com/p/76820438
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
AI ProCon 2019 邀请到了亚马逊首席科学家@李沐,在大会的前一天(9.5)亲授「深度学习实训营」,通过动手实操,帮助开发者全面了解深度学习的基础知识和开发技巧。

9大技术论坛、60+主题分享,百余家企业、千余名开发者共同相约 2019 AI ProCon!技术驱动产业,聚焦技术实践,倾听大牛分享,和万千开发者共成长。5折优惠票抢购中!

社群福利
扫码添加小助手,回复:大会,加入2019 AI开发者大会福利群,每周一、三、五 更新学习资源、技术福利,还有抽奖活动~

推荐阅读
最前沿:堪比E=mc2,Al-GA才是实现AGI的指标性方法论
1万+字原创读书笔记,机器学习的知识点全在这篇文章里
开源之战
别再造假数据了,来试试Faker这个库吧!
国外大神制作的超棒NumPy可视化教程
突发!Python再次第一,Java和C下降,凭什么?
白话中台战略:中台是个什么鬼?
伟创力回应扣押华为物资;谷歌更新图片界面;Python 3.8.0b3 发布 | 极客头条
沃尔玛也要发币了,Libra忙活半天为他人做了嫁衣?
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢相关文章:

Qt简介、安装及在Ubuntu14.04 32位上简单使用举例
Qt是一个跨平台的C图形用户界面应用程序开发框架。它既可以开发GUI程序,也可用于开发非GUI程序。Qt是面向对象的框架,很容易扩展。Qt是一个C工具包,它由几百个C类构成,你在程序中可以使用这些类。Qt具有OOP的所有优点。 跨平台的…
FOSCommentBundle功能包:设置Doctrine ODM映射(投票)
原文出处:12b-mapping_mongodb.md原文作者:FriendsOfSymfony授权许可:创作共用协议翻译人员:FireHare校对人员:适用版本:FOSCommentBundle 2.0.5文章状态:草译阶段Step 12b: Setup MongoDB mapp…
Python最大堆排序实现方法
Python最大堆排序实现方法,具体代码如下: # -*- coding: utf-8 -*- def merge_sort(seq, cmpcmp, sentinelNone): """合并排序,伪码如下: MERGE(A, p, q, r) 1 n1 ← q - p 1 // 前个子序列长度 2 …

内含福利 | 世界人工智能大会:对话大咖,深挖机器学习的商业应用
机器学习作为人工智能时代的关键技术突破,已经在日常生活中广泛应用,给用户带来便利。越来越多的企业也通过机器学习,解决生产和经营中的难题。传统制造业:应用机器学习,部署系统异常检测方案,预测组件寿命…
windows7 64位操作系统上使vs2010和vs2013能够并存的处理方法
之前机子上是只安装有vs2010,后来在没有卸载vs2010的情况下想装个vs2013,使vs2010与vs2013同时并存在windows764位机上。需要依次安装cn_visual_studio_ultimate_2013_x86_dvd_3009109.iso、vs2013.2.iso和vc_mbcsmfc.exe。在安装过程中遇到的问题有: (…
Spring Cloud Alibaba 基础教程:Nacos 生产级版本 0.8.0
Spring Cloud Alibaba 基础教程:Nacos 生产级版本 0.8.0 昨晚Nacos社区发布了第一个生产级版本:0.8.0。由于该版本除了Bug修复之外,还提供了几个生产管理非常重要的特性,所以觉得还是有必要写一篇讲讲这次升级,在后续的…
awk命令使用和取出数据的最大值,最小值和平均值
得到取出数据的最大值:cat manager.txt |grep monitor|awk {print$9}|sort -rn|head -1得到取出数据的最小值:cat manager.txt|grep monitor |awk {print $9}|sort -n|head -1得到取出数据的平均值:cat manager.txt|grep monitor |awk {print…
windows7 64位机上CUDA7.0配置及在VS2010中的简单使用举例
1. 查看本机配置,查看显卡类型是否支持NVIDIA GPU,选中计算机--> 右键属性 --> 设备管理器 --> 显示适配器:NVIDIA GeForce GT 610,从https://developer.nvidia.com/cuda-gpus可以查到相应显卡的compute capabili…
用友云平台,真正的云原生架构,加速云应用落地
数字化经济的出现,企业需要通过新技术实现数字化转型,完成企业管理和业务模式变革。而云计算是数字化中尤为重要且能够更快实现的技术手段。真正的云应用必须是基于云原生架构的,PaaS是一个重要的步骤,因为这是云原生的第一接触点…
从ACM班、百度到亚马逊,深度学习大牛李沐的开挂人生
“大神”,是很多人对李沐的印象。作为一经推出便大受追捧的 MXNet 深度学习框架的主要贡献者之一,李沐功不可没。值得注意的是,这个由 DMLC(Distributed Machine Learning Community)打造的深度学习框架,创…
Linux基础介绍
Linux的创始人Linus Torvalds。Linux的官方标准发音为[linəks]。Linux和Unix是非常像的,Linux就是根据Unix演变过来的。Linux是免费的,其实只是说Linux的内核免费。在Linux内核的基础上产生了众多的Linux版本。Linux的发行版说简单点就是将Linux内核与应…
Go在区块链的发展和演进
Go语言发展至今已经过去十年多了,是目前最流行的新兴语言,云计算领域的首选语言,而且目前随着区块链的流行,Go再次成为了这个领域的第一语言,以太坊,IBM的fabric等重量级的区块链项目都是基于Go开发。 原文…

一天掌握AI核心技术,上手应用,开发者该划哪些重点?
Alpha Go 只会下棋,却并不擅长垃圾分类;智能助手已经可以执行很多任务,但距离真正的人机自然交互还很远。如今 AI 的发展面临着诸多瓶颈,基础理论研究缺失,深度学习的黑箱属性无解,把一切托付于未知并不可靠…

学会这21条,你离Vim大神就不远了
来源 | Python编程时光(ID: Python-Time)导语:作者本人是 Vim 的重度使用者,就因为喜欢上这种双手不离键盘就可以操控一切的feel,Vim 可以让人对文本的操作更加精准、高效。对于未使用过 Vim 的朋友来说,可…
C 语言 和 C++语言的对比学习 二 数据类型
不管是什么语言,我们最习惯的是通过 “hello world” ,来昭告世界,我们有了新的语言来向这个世界问好,尽管真正属于我们自己的其实是哭声。(呵呵,笑点有点低),下面我们来介绍最为基础…
Makefile语法基础介绍
在Linux下,make是一个命令工具,是一个解释Makefile中指令的命令工具。make命令执行时,需要一个Makefile文件,以告诉make命令需要怎么样去编译和链接程序。 make如何工作:在默认的方式下,只输入make命令&am…

MaxCompute studio与权限那些事儿
背景知识 MaxCompute拥有一套强大的安全体系,来保护项目空间里的数据安全。用户在使用MaxCompute时,应理解权限的一些基本概念: 权限可分解为三要素,即主体(用户账号或角色),客体(表…
GitHub标星3w+的项目,全面了解算法和数据结构知识
作者 | 程序员小吴来源 | 五分钟学算法(ID: CXYxiaowu)导语:今天分享一个开源项目,里面汇总了程序员技术面试时需要了解的算法和数据结构知识,并且还提供了相应的代码,目前 GitHub 上标星 35000 star&#…
Shell脚本基础介绍
shell基础简介:编写脚本通常使用某种基于解释器的编程语言。而shell脚本不过就是一些文件,我们能将一系列需要执行的命令写入其中,然后通过shell来执行这些脚本。进入Linux系统(Ubuntu),打开终端Terminal,”$”表示普通…

「小程序JAVA实战」小程序的举报功能开发(68)
转自:https://idig8.com/2018/09/25/xiaochengxujavashizhanxiaochengxudeweixinapicaidancaozuo66-2/ 通过点击举报按钮,跳转到举报页面完成举报操作。 后台开发 获取发布人的userId,videoId,创建者的Id controllerUserControlle…

tar常见文件解压法
2019独角兽企业重金招聘Python工程师标准>>> tar常见文件解压法:.gz - z 小写.bz2 - j 小写.xz - J 大写.Z - Z大写 转载于:https://my.oschina.net/open1900/blog/149238
cookie的作用域
当我们给网站设置cookie时,大家有没有发现在网站的其他域名下也接收到了这些cookie。这些没用的cookie看似不占多少流量,但如果对一个日PV千万的站点来说,那浪费的资源就不是一点点了。因此在设置cookie时,对它的作用域一定要设置…
必看,10篇定义计算机视觉未来的论文
译者 | Major编辑 | 赵雪出品 | AI科技大本营(ID:rgznai100)导语:如果你没能参加 CVPR 2019 , 别担心。本文列出了会上人们最为关注的 10 篇论文,覆盖了 DeepFakes(人脸转换), Facial Recogniti…
有效的rtsp流媒体测试地址汇总
以下是从网上搜集的一些有效的rtsp流媒体测试地址: 1. rtsp://218.204.223.237:554/live/1/0547424F573B085C/gsfp90ef4k0a6iap.sdp 2. rtsp://218.204.223.237:554/live/1/66251FC11353191F/e7ooqwcfbqjoo80j.sdp 3. rtsp://211.139.194.251:554…
java简单的ID生成器
2019独角兽企业重金招聘Python工程师标准>>> https://www.cnblogs.com/hongdada/p/9324473.html https://github.com/apache/incubator-shardingsphere 转载于:https://my.oschina.net/u/3005325/blog/3006311
安装、设置与启动MySql5.1.30绿色版的方法
1、解压 mysql-noinstall-5.1.30-win32.zip(下载地址http://dev.mysql.com/downloads/mysql/5.1.html)2、在 F 盘建立目录 MySql\MySqlServer5.1\ 3、把解压的内容复制到 F:\MySql\MySqlServer5.1\4、在 F:\MySql\MySqlServer5.1\ 中找 my-large.ini 把它复制成 my.ini5、在…
网页中插入VLC播放器播放rtsp视频流步骤
1. 仿照http://download.csdn.net/detail/haowenxin123456789/8044245 中步骤; 2. 从http://www.videolan.org/vlc/index.html 中下载 vlc-2.2.1-win32.exe 并安装到D:\\ProgramFiles文件夹下; 3. 运行:regsvr32 D:\\ProgramFil…

@程序员,“10倍工程师”都在追这四大AI风向
技术的发展,驱动着产业变革,从而改变着我们的生活方式。当5GAI 时代来临,核心的技术生产力就是开发者:开发者研究前沿的科学创新,推动技术发展,将技术应用于实际场景中。开发者是企业实现商业价值必不可少的…
End Credits
我不知道怎么把他删掉... 今晚WC文艺汇演wwww(等待唱歌.jpg 要是能截到屏一定发上来qwqqqqq 话说这首曲子是新发现的QAQ(Xeuphoria的还是那么好听qwqqq 今天学了快读qvq 还有...dpwww P2015 二叉苹果树 有一棵苹果树,如果树枝有分叉,一定是分2叉…

三十六亿的《哪吒》历时五年,如何用AI解决动画创作难题?
作者 | 神经小姐姐来源 | HyperAI超神经( ID: HyperAI )【导读】《哪吒之魔童降世》自 7 月 26 日上映以来,好评如潮,票房一路高歌猛进,目前已突破 36 亿。这款火爆的动画背后,是主创团队历时 5 年的细致打磨。而这漫长…