Dropout、梯度消失/爆炸、Adam优化算法,神经网络优化算法看这一篇就够了

作者 | mantch
来源 | 知乎
1. 训练误差和泛化误差
对于机器学习模型在训练数据集和测试数据集上的表现。如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不⼀定更准确。这是为什么呢?
因为存在着训练误差和泛化误差:
训练误差:模型在训练数据集上表现出的误差。
泛化误差:模型在任意⼀个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。
训练误差的期望小于或等于泛化误差。也就是说,⼀般情况下,由训练数据集学到的模型参数会使模型在训练数据集上的表现优于或等于在测试数据集上的表现。由于⽆法从训练误差估计泛化误差,⼀味地降低训练误差并不意味着泛化误差⼀定会降低。
机器学习模型应关注降低泛化误差。
2. 该如何选择模型
在机器学习中,通常需要评估若⼲候选模型的表现并从中选择模型。这⼀过程称为模型选择(model selection)。可供选择的候选模型可以是有着不同超参数的同类模型。以多层感知机为例,我们可以选择隐藏层的个数,以及每个隐藏层中隐藏单元个数和激活函数。为了得到有效的模型,我们通常要在模型选择上下⼀番功夫。
2.1 验证数据集
从严格意义上讲,测试集只能在所有超参数和模型参数选定后使⽤⼀次。不可以使⽤测试数据选择模型,如调参。由于⽆法从训练误差估计泛化误差,因此也不应只依赖训练数据选择模型。鉴于此,我们可以预留⼀部分在训练数据集和测试数据集以外的数据来进⾏模型选择。这部分数据被称为验证数据集,简称验证集(validation set)。例如,我们可以从给定的训练集中随机选取⼀小部分作为验证集,而将剩余部分作为真正的训练集。
可以通过预留这样的验证集来进行模型选择,判断验证集在模型中的表现能力。
2.2 K 折交叉验证
由于验证数据集不参与模型训练,当训练数据不够⽤时,预留⼤量的验证数据显得太奢侈。⼀种改善的⽅法是K折交叉验证(K-fold cross-validation)。在K折交叉验证中,我们把原始训练数据集分割成K个不重合的⼦数据集,然后我们做K次模型训练和验证。每⼀次,我们使⽤⼀个⼦数据集验证模型,并使⽤其他K − 1个⼦数据集来训练模型。在这K次训练和验证中,每次⽤来验证模型的⼦数据集都不同。最后,我们对这K次训练误差和验证误差分别求平均。
3. ⽋拟合和过拟合
欠拟合:模型⽆法得到较低的训练误差。
过拟合:是模型的训练误差远小于它在测试数据集上的误差。
给定训练数据集,
如果模型的复杂度过低,很容易出现⽋拟合;
如果模型复杂度过⾼,很容易出现过拟合。
应对⽋拟合和过拟合的⼀个办法是针对数据集选择合适复杂度的模型。
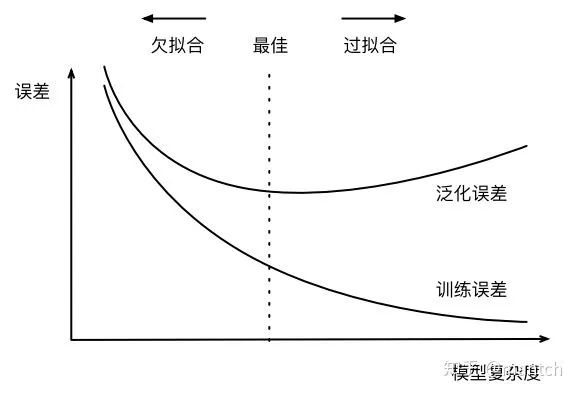
训练数据集⼤⼩
影响⽋拟合和过拟合的另⼀个重要因素是训练数据集的⼤小。⼀般来说,如果训练数据集中样本数过少,特别是⽐模型参数数量(按元素计)更少时,过拟合更容易发⽣。此外,泛化误差不会随训练数据集⾥样本数量增加而增⼤。因此,在计算资源允许的范围之内,我们通常希望训练数据集⼤⼀些,特别是在模型复杂度较⾼时,例如层数较多的深度学习模型。
正则化
应对过拟合问题的常⽤⽅法:权重衰减(weight decay),权重衰减等价于L2范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常⽤⼿段。
4. 丢弃法(Dropout)
除了上面提到的权重衰减以外,深度学习模型常常使⽤丢弃法(dropout)来应对过拟合问题。丢弃法有⼀些不同的变体。本节中提到的丢弃法特指倒置丢弃法(inverted dropout)。
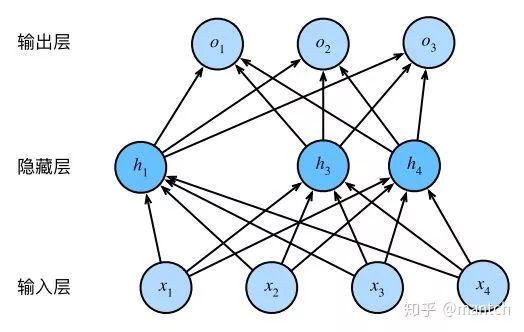
回忆⼀下,“多层感知机”描述了⼀个单隐藏层的多层感知机。其中输⼊个数为4,隐藏单元个数为5,且隐藏单元hi(i = 1, . . . , 5)的计算表达式为:
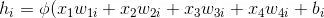
这⾥ϕ是激活函数,x1, . . . , x4是输⼊,隐藏单元i的权重参数为w1i, . . . , w4i,偏差参数为bi。当对该隐藏层使⽤丢弃法时,该层的隐藏单元将有⼀定概率被丢弃掉。设丢弃概率为p,那么有p的概率hi会被清零,有1 − p的概率hi会除以1 − p做拉伸。丢弃概率是丢弃法的超参数。具体来说,设随机变量ξi为0和1的概率分别为p和1 − p。使⽤丢弃法时我们计算新的隐藏单元
![]()
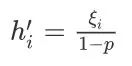
由于E(ξi) = 1 − p,因此:
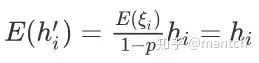
即丢弃法不改变其输⼊的期望值。让我们对隐藏层使⽤丢弃法,⼀种可能的结果如下图所⽰,其中h2和h5被清零。这时输出值的计算不再依赖h2和h5,在反向传播时,与这两个隐藏单元相关的权重的梯度均为0。由于在训练中隐藏层神经元的丢弃是随机的,即h1, . . . , h5都有可能被清零,输出层的计算⽆法过度依赖h1, . . . , h5中的任⼀个,从而在训练模型时起到正则化的作⽤,并可以⽤来应对过拟合。在测试模型时,我们为了拿到更加确定性的结果,⼀般不使⽤丢弃法。
5. 梯度消失/梯度爆炸(Vanishing / Exploding gradients)
训练神经网络,尤其是深度神经所面临的一个问题就是梯度消失或梯度爆炸,也就是你训练神经网络的时候,导数或坡度有时会变得非常大,或者非常小,甚至于以指数方式变小,这加大了训练的难度。
本质上,梯度消失和爆炸是一种情况。在深层网络中,由于网络过深,如果初始得到的梯度过小,或者传播途中在某一层上过小,则在之后的层上得到的梯度会越来越小,即产生了梯度消失。梯度爆炸也是同样的。一般地,不合理的初始化以及激活函数,如sigmoid等,都会导致梯度过大或者过小,从而引起消失/爆炸。
解决方案
1、预训练加微调
其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)。
此方法有一定的好处,但是目前应用的不是很多了。
2、梯度剪切、正则
梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。
另外一种解决梯度爆炸的手段是采用权重正则化(weithts regularization)比较常见的是L1和L2正则。
3、ReLu、leakReLu等激活函数
ReLu:其函数的导数在正数部分是恒等于1,这样在深层网络中,在激活函数部分就不存在导致梯度过大或者过小的问题,缓解了梯度消失或者爆炸。同时也方便计算。当然,其也存在存在一些缺点,例如过滤到了负数部分,导致部分信息的丢失,输出的数据分布不在以0为中心,改变了数据分布。
leakrelu:就是为了解决relu的0区间带来的影响,其数学表达为:leakrelu=max(k*x,0)其中k是leak系数,一般选择0.01或者0.02,或者通过学习而来。
4、Batch Normalization
Batch Normalization是深度学习发展以来提出的最重要的成果之一了,目前已经被广泛的应用到了各大网络中,具有加速网络收敛速度,提升训练稳定性的效果,Batch Normalization本质上是解决反向传播过程中的梯度问题。Batch Normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化到均值为0,方差为1保证网络的稳定性。
有一些从 0 到 1 而不是从 1 到 1000 的特征值,通过归一化所有的输入特征值?,以获得类似范围的值,可以加速学习。所以 Batch 归一化起的作用的原因,直观的一点就是,它在做类似的工作,但不仅仅对于这里的输入值,还有隐藏单元的值。
它可以使权重比你的网络更滞后或更深层,比如,第 10 层的权重更能经受得住变化。
残差结构
残差的方式,能使得深层的网络梯度通过跳级连接路径直接返回到浅层部分,使得网络无论多深都能将梯度进行有效的回传。
LSTM
LSTM全称是长短期记忆网络(long-short term memory networks),是不那么容易发生梯度消失的,主要原因在于LSTM内部复杂的“门”(gates)。在计算时,将过程中的梯度进行了抵消。
6. 随机梯度下降法(SGD)
6.1 mini-batch梯度下降
你可以把训练集分割为小一点的子集训练,这些子集被取名为 mini-batch,假设每一个子集中只有 1000 个样本,那么把其中的? (1)到? (1000)取出来,将其称为第一个子训练集,也叫做 mini-batch,然后你再取出接下来的 1000 个样本,从? (1001)到? (2000),然后再取 1000个样本,以此类推。
在训练集上运行 mini-batch 梯度下降法,你运行 for t=1……5000,因为我们有5000个各有 1000 个样本的组,在 for 循环里你要做得基本就是对? {?}和? {?}执行一步梯度下降法。
batch_size=1,就是SGD。
batch_size=n,就是mini-batch
batch_size=m,就是batch
其中1<n<m,m表示整个训练集大小。
优缺点:
batch:相对噪声低些,幅度也大一些,你可以继续找最小值。
SGD:大部分时候你向着全局最小值靠近,有时候你会远离最小值,因为那个样本恰好给你指的方向不对,因此随机梯度下降法是有很多噪声的,平均来看,它最终会靠近最小值,不过有时候也会方向错误,因为随机梯度下降法永远不会收敛,而是会一直在最小值附近波动。一次性只处理了一个训练样本,这样效率过于低下。
mini-batch:实践中最好选择不大不小的 mini-batch,得到了大量向量化,效率高,收敛快。
首先,如果训练集较小,直接使用 batch 梯度下降法,这里的少是说小于 2000 个样本。一般的 mini-batch 大小为 64 到 512,考虑到电脑内存设置和使用的方式,如果 mini-batch 大小是 2 的?次方,代码会运行地快一些。
6.2 调节 Batch_Size 对训练效果影响到底如何?
Batch_Size 太小,模型表现效果极其糟糕(error飙升)。
随着 Batch_Size 增大,处理相同数据量的速度越快。
随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
7. 优化算法
7.1 动量法
在每次迭代中,梯度下降根据⾃变量当前位置,沿着当前位置的梯度更新⾃变量。然而,如果⾃变量的 迭代⽅向仅仅取决于⾃变量当前位置,这可能会带来⼀些问题。
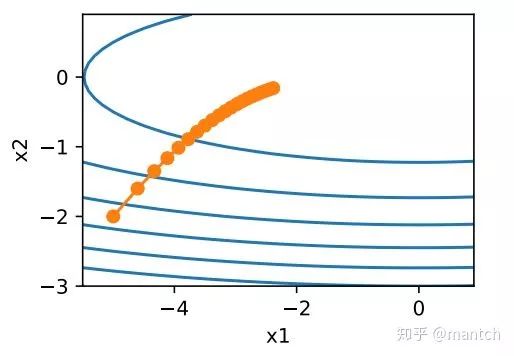
让我们考虑⼀个输⼊和输出分别为⼆维向量x = [x1, x2]⊤和标量的⽬标函数
![]() =0.1x_1^2+2x_2^2)。这⾥将
=0.1x_1^2+2x_2^2)。这⾥将![]() 系数从1减小到了0.1。下⾯实现基于这个⽬标函数的梯度下降,并演⽰使⽤学习率为0.4时⾃变量的迭代轨迹。
系数从1减小到了0.1。下⾯实现基于这个⽬标函数的梯度下降,并演⽰使⽤学习率为0.4时⾃变量的迭代轨迹。
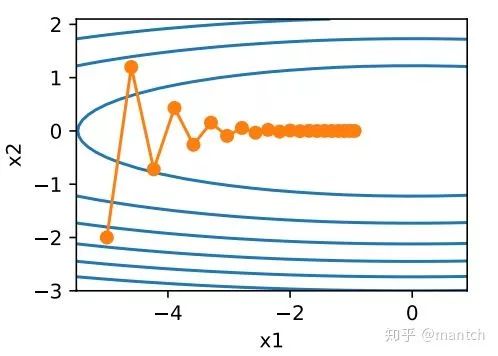
可以看到,同⼀位置上,⽬标函数在竖直⽅向(x2轴⽅向)⽐在⽔平⽅向(x1轴⽅向)的斜率的绝对值更⼤。因此,给定学习率,梯度下降迭代⾃变量时会使⾃变量在竖直⽅向⽐在⽔平⽅向移动幅度更⼤。那么,我们需要⼀个较小的学习率从而避免⾃变量在竖直⽅向上越过⽬标函数最优解。然而,这会造成⾃变量在⽔平⽅向上朝最优解移动变慢。
动量法的提出是为了解决梯度下降的上述问题。由于小批量随机梯度下降⽐梯度下降更为⼴义,本章后续讨论将沿⽤“小批量随机梯度下降”⼀节中时间步t的小批量随机梯度gt的定义。设时间步t的⾃变量为xt,学习率为ηt。在时间步0,动量法创建速度变量v0,并将其元素初始化成0。在时间步t > 0,动量法对每次迭代的步骤做如下修改:
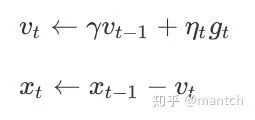
其中,动量超参数γ满⾜0 ≤ γ < 1。当γ = 0时,动量法等价于小批量随机梯度下降。在梯度下降时候使用动量法后的迭代轨迹:
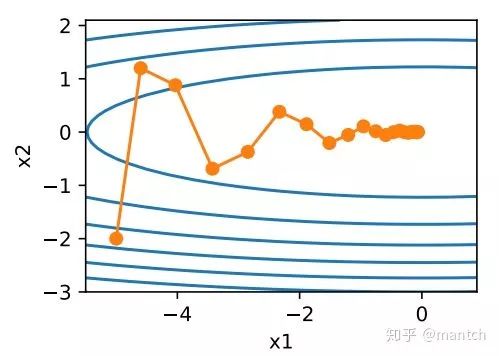
可以看到使⽤较小的学习率η = 0.4和动量超参数γ = 0.5时,动量法在竖直⽅向上的移动更加平滑,且在⽔平⽅向上更快逼近最优解。
所以,在动量法中,⾃变量在各个⽅向上的移动幅度不仅取决当前梯度,还取决于过去的各个梯度在各个⽅向上是否⼀致。在本节之前⽰例的优化问题中,所有梯度在⽔平⽅向上为正(向右),而在竖直⽅向上时正(向上)时负(向下)。这样,我们就可以使⽤较⼤的学习率,从而使⾃变量向最优解更快移动。
7.2 AdaGrad算法
优化算法中,⽬标函数⾃变量的每⼀个元素在相同时间步都使⽤同⼀个学习率来⾃我迭代。在“动量法”⾥我们看到当x1和x2的梯度值有较⼤差别时,需要选择⾜够小的学习率使得⾃变量在梯度值较⼤的维度上不发散。但这样会导致⾃变量在梯度值较小的维度上迭代过慢。动量法依赖指数加权移动平均使得⾃变量的更新⽅向更加⼀致,从而降低发散的可能。本节我们介绍AdaGrad算法,它根据⾃变量在每个维度的梯度值的⼤小来调整各个维度上的学习率,从而避免统⼀的学习率难以适应所有维度的问题。
AdaGrad算法会使⽤⼀个小批量随机梯度gt按元素平⽅的累加变量st。在时间步0,AdaGrad将s0中每个元素初始化为0。在时间步t,⾸先将小批量随机梯度gt按元素平⽅后累加到变量st:
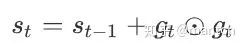
其中⊙是按元素相乘。接着,我们将⽬标函数⾃变量中每个元素的学习率通过按元素运算重新调整⼀下:
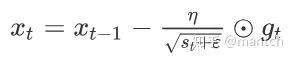
其中η是学习率,ϵ是为了维持数值稳定性而添加的常数,如10的-6次方。这⾥开⽅、除法和乘法的运算都是按元素运算的。这些按元素运算使得⽬标函数⾃变量中每个元素都分别拥有⾃⼰的学习率。
需要强调的是,小批量随机梯度按元素平⽅的累加变量st出现在学习率的分⺟项中。因此,
如果⽬标函数有关⾃变量中某个元素的偏导数⼀直都较⼤,那么该元素的学习率将下降较快;
反之,如果⽬标函数有关⾃变量中某个元素的偏导数⼀直都较小,那么该元素的学习率将下降较慢。
然而,由于st⼀直在累加按元素平⽅的梯度,⾃变量中每个元素的学习率在迭代过程中⼀直在降低(或不变)。所以,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到⼀个有⽤的解。
7.3 RMSProp算法
当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到⼀个有⽤的解。为了解决这⼀问题,RMSProp算法对AdaGrad算法做了⼀点小小的修改。
不同于AdaGrad算法⾥状态变量st是截⾄时间步t所有小批量随机梯度gt按元素平⽅和,RMSProp算法将这些梯度按元素平⽅做指数加权移动平均。具体来说,给定超参数0 ≤ γ < 1,RMSProp算法在时间步t > 0计算:
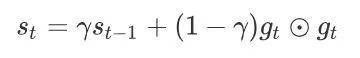
和AdaGrad算法⼀样,RMSProp算法将⽬标函数⾃变量中每个元素的学习率通过按元素运算重新调整,然后更新⾃变量:
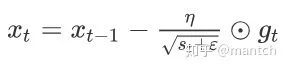
其中η是学习率,ϵ是为了维持数值稳定性而添加的常数,如10的-6次方。因为RMSProp算法的状态变量st是对平⽅项gt ⊙ gt的指数加权移动平均,所以可以看作是最近1/(1 − γ)个时间步的小批量随机梯度平⽅项的加权平均。如此⼀来,⾃变量每个元素的学习率在迭代过程中就不再⼀直降低(或不变)。
7.4 AdaDelta算法
除了RMSProp算法以外,另⼀个常⽤优化算法AdaDelta算法也针对AdaGrad算法在迭代后期可能较难找到有⽤解的问题做了改进。有意思的是,AdaDelta算法没有学习率这⼀超参数。
AdaDelta算法也像RMSProp算法⼀样,使⽤了小批量随机梯度gt按元素平⽅的指数加权移动平均变量st。在时间步0,它的所有元素被初始化为0。给定超参数0 ≤ ρ < 1(对应RMSProp算法中的γ),在时间步t > 0,同RMSProp算法⼀样计算:
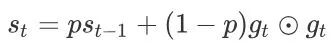
与RMSProp算法不同的是,AdaDelta算法还维护⼀个额外的状态变量∆xt,其元素同样在时间步0时被初始化为0。我们使⽤∆xt−1来计算⾃变量的变化量:
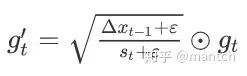
最后,我们使⽤∆xt来记录⾃变量变化量![]()
按元素平⽅的指数加权移动平均:
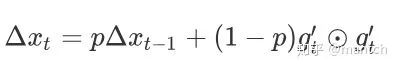
可以看到,如不考虑ϵ的影响,AdaDelta算法与RMSProp算法的不同之处在于使⽤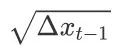 来替代超参数η。
来替代超参数η。
7.5 Adam算法
Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均。
Adam算法使⽤了动量变量vt和RMSProp算法中小批量随机梯度按元素平⽅的指数加权移动平均变量st,并在时间步0将它们中每个元素初始化为0。给定超参数0 ≤ β1 < 1(算法作者建议设为0.9),时间步t的动量变量vt即小批量随机梯度gt的指数加权移动平均:
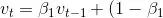
和RMSProp算法中⼀样,给定超参数0 ≤ β2 < 1(算法作者建议设为0.999),将小批量随机梯度按元素平⽅后的项gt ⊙ gt做指数加权移动平均得到st:

由于我们将 v0 和 s0 中的元素都初始化为 0,在时间步 t 我们得到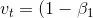
\sum_{i=1}^t\beta_1^{t-i}g_i)。将过去各时间步小批量随机梯度的权值相加,得到 \sum_{i=1}^t\beta_1^{t-i}=1-\beta_1^t)。需要注意的是,当 t 较小时,过去各时间步小批量随机梯度权值之和会较小。例如,当β1 = 0.9时,v1 = 0.1g1。为了消除这样的影响,对于任意时间步 t,我们可以将 vt 再除以
\sum_{i=1}^t\beta_1^{t-i}=1-\beta_1^t)。需要注意的是,当 t 较小时,过去各时间步小批量随机梯度权值之和会较小。例如,当β1 = 0.9时,v1 = 0.1g1。为了消除这样的影响,对于任意时间步 t,我们可以将 vt 再除以![]() ,从而使过去各时间步小批量随机梯度权值之和为1。这也叫作偏差修正。在Adam算法中,我们对变量 vt 和 st 均作偏差修正:
,从而使过去各时间步小批量随机梯度权值之和为1。这也叫作偏差修正。在Adam算法中,我们对变量 vt 和 st 均作偏差修正:
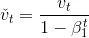
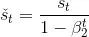
接下来,Adam算法使⽤以上偏差修正后的变量vˆt和sˆt,将模型参数中每个元素的学习率通过按元素运算重新调整:
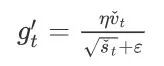
其中η是学习率,ϵ是为了维持数值稳定性而添加的常数,如10的-8次方。和AdaGrad算法、RMSProp算法以及AdaDelta算法⼀样,⽬标函数⾃变量中每个元素都分别拥有⾃⼰的学习率。最后,使⽤![]() 迭代⾃变量:
迭代⾃变量:
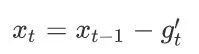
7.6 局部最优--鞍点问题
一个具有高维度空间的函数,如果梯度为 0,那么在每个方向,它可能是凸函数,也可能是凹函数。如果你在 2 万维空间中,那么想要得到局部最优,所有的 2 万个方向都需要是这样,但发生的机率也许很小,也许是2的-20000次方,你更有可能遇到有些方向的曲线会这样向上弯曲,另一些方向曲线向下弯,而不是所有的都向上弯曲,因此在高维度空间,你更可能碰到鞍点。
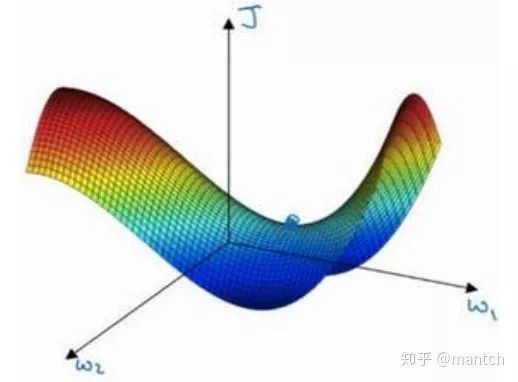
而不会碰到局部最优。至于为什么会把一个曲面叫做鞍点,你想象一下,就像是放在马背上的马鞍一样,如果这是马,这是马的头,这就是马的眼睛,画得不好请多包涵,然后你就是骑马的人,要坐在马鞍上,因此这里的这个点,导数为 0 的点,这个点叫做鞍点。我想那确实是你坐在马鞍上的那个点,而这里导数为 0。
鞍点中的平稳段是一个问题,这样使得学习十分缓慢,这也是像 Momentum 或是RMSprop,Adam 这样的算法,能够加速学习算法的地方。在这些情况下,更成熟的优化算法,如 Adam 算法,能够加快速度,让你尽早往下走出平稳段。
8. 如何解决训练样本少的问题
利用预训练模型进行迁移微调(fine-tuning),预训练模型通常在特征上拥有很好的语义表达。此时,只需将模型在小数据集上进行微调就能取得不错的效果。CV有ImageNet,NLP有BERT等。
数据集进行下采样操作,使得符合数据同分布。
数据集增强、正则或者半监督学习等方式来解决小样本数据集的训练问题。
9. 如何提升模型的稳定性?
正则化(L2, L1, dropout):模型方差大,很可能来自于过拟合。正则化能有效的降低模型的复杂度,增加对更多分布的适应性。
前停止训练:提前停止是指模型在验证集上取得不错的性能时停止训练。这种方式本质和正则化是一个道理,能减少方差的同时增加的偏差。目的为了平衡训练集和未知数据之间在模型的表现差异。
扩充训练集:正则化通过控制模型复杂度,来增加更多样本的适应性。
特征选择:过高的特征维度会使模型过拟合,减少特征维度和正则一样可能会处理好方差问题,但是同时会增大偏差。
10. 有哪些改善模型的思路
1、数据角度
增强数据集。无论是有监督还是无监督学习,数据永远是最重要的驱动力。更多的类型数据对良好的模型能带来更好的稳定性和对未知数据的可预见性。对模型来说,“看到过的总比没看到的更具有判别的信心”。
2、模型角度
模型的容限能力决定着模型可优化的空间。在数据量充足的前提下,对同类型的模型,增大模型规模来提升容限无疑是最直接和有效的手段。
3、调参优化角度
如果你知道模型的性能为什么不再提高了,那已经向提升性能跨出了一大步。超参数调整本身是一个比较大的问题。一般可以包含模型初始化的配置,优化算法的选取、学习率的策略以及如何配置正则和损失函数等等。
4、训练角度
在越大规模的数据集或者模型上,诚然一个好的优化算法总能加速收敛。但你在未探索到模型的上限之前,永远不知道训练多久算训练完成。所以在改善模型上充分训练永远是最必要的过程。充分训练的含义不仅仅只是增大训练轮数。有效的学习率衰减和正则同样是充分训练中非常必要的手段。
11. 如何提高深度学习系统的性能
提高模型的结构。
改进模型的初始化方式,保证早期梯度具有某些有益的性质,或者具备大量的稀疏性,或者利用线性代数原理的优势。
选择更强大的学习算法。
参考文献
动手学--深度学习
吴恩达--深度学习笔记
GitHub
百面机器学习
链接:https://zhuanlan.zhihu.com/p/78854514
(*本文为 AI科技大本营转载文章,转载请联系作者)
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!

AI ProCon 大会优惠票限时抢购中,三人拼团,每人立减600元!识别海报二维码,即刻购票~

推荐阅读
NLP这两年:15个预训练模型对比分析与剖析
60+业内技术专家,9大核心技术专题,AI ProCon倒计时一周!
小团队如何玩转物联网开发?
一文看懂机器学习中的常用损失函数
DeepMind提图像生成的递归神经网络DRAW,158行Python代码复现
KDD 2019高维稀疏数据上的深度学习Workshop论文汇总
5G 改变社会的真相在这里!
程序员如何解决并发冲突的难题?

你点的每个“在看”,我都认真当成了喜欢
相关文章:

入行AI,你需要一本Python机器学习入门
目前机器学习红遍全球。男女老少都在学机器学习模型,分类器,神经网络和吴恩达。你也想成为一份子,但你该如何开始?今天小编推荐这本《Python机器学习》教你快速入门。01什么是机器学习?从出生的那天起,…

通过transpose和flip实现图像旋转90/180/270度
在fbc_cv库中,提供了对图像进行任意角度旋转的函数rotate,其实内部也是调用了仿射变换函数warpAffine。如果图像仅是进行90度倍数的旋转,是没有必要用warpAffine函数的。这里通过transpose和flip函数实现对图像进行顺时针90度、180度、270度的…

DIY强大的虚拟化环境-技术可行性部分
【技术可行性部分】大体的cpu支不支持呀,实际效果使用呀,截图效果截图嵌套虚拟化[esxi,xenserver,Hyper-V]嵌套虚拟化:经过各种查资料,和测试验证[只测过intel的,amd的有类似的文章请去下面的资…
C++11中rvalue references的使用
Rvalue references are a feature of C that was added with the C11 standard. The syntax of an rvalue reference is to add && after a type.为了支持移动操作,C11引入了一种新的引用类型----右值引用(rvalue reference)。所谓右值引用就是必须绑定到右…
AIの幕后人:探秘“硬核英雄”的超级武器
作者 | 云计算的阿晶 出品 | AI科技大本营(ID:rgznai100) 掐指一算八年之前,那时正是国内互联网卯足劲头起飞的一年,各行各业表现都很突出,尤其是与人们生活密切相关的手机,正大踏步地从功能机向智能手机转…
PAT乙级1003
1003 我要通过! (20 point(s))“答案正确”是自动判题系统给出的最令人欢喜的回复。本题属于 PAT 的“答案正确”大派送 —— 只要读入的字符串满足下列条件,系统就输出“答案正确”,否则输出“答案错误”。 得到“答案…
史上最简洁的UITableView Sections 展示包含NSDicionary 的NSArray
这个最典型的就是电话本,然后根据A-Z分组, 当然很多例子,不过现在发现一个很简洁易懂的: 1. 准备数据,定义一个dictionary来显示所有的内容,这个dictionary对应的value全是数组 也就是: A &…

微软麻将AI Suphx或引入“凤凰房”,与其他AI对打
作者 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】在刚刚结束的上海2019世界人工智能大会上,微软宣布了其在人工智能领域的最新研究突破——由微软亚洲研究院研发的麻将 AI 系统 Suphx 在国际知名的专业麻将平台“天凤”上荣升十段&…
C++11中std::function的使用
类模版std::function是一种通用、多态的函数封装。std::function的实例可以对任何可以调用的目标实体进行存储、复制、和调用操作,这些目标实体包括普通函数、Lambda表达式、函数指针、以及其它函数对象等。 通过std::function对C中各种可调用实体(普通函数、Lambd…
django模板的导入
模板导入 前提:多个页面有一个相同的页面版块(多个有样式标签的集合体) 如何运用:可以将多个样式标签的集合进行封装对外提供版块的名字(接口),在有该版块的页面中直接导入即可 语法:{% include 版块页面的路径 %} 四inclusion_tag自定义标签 -- 模板导入 前提:多个页面有一个相…

[UML]UML系列——包图Package
系列文章 [UML]UML系列——用例图Use Case [UML]UML系列——用例图中的各种关系(include、extend) [UML]UML系列——类图Class [UML]UML系列——类图class的关联关系(聚合、组合) [UML]UML系列——类图class的依赖关系 [UML]UML系…
2017-2018 ACM-ICPC German Collegiate Programming Contest (GCPC 2017)
A Drawing Borders 很多构造方法,下图可能是最简单的了 代码: #include<bits/stdc.h> using namespace std; const int maxn1e610; struct Point{ int x,y; }; Point a[maxn]; int numa0; Point b[maxn]; int numb0; vector<pair<double,d…
C++11中std::bind的使用
std::bind函数是用来绑定函数调用的某些参数的。std::bind它可以预先把指定可调用实体的某些参数绑定到已有的变量,产生一个新的可调用实体。它绑定的参数的个数不受限制,绑定的具体哪些参数也不受限制,由用户指定。 std::bind:(…
在图数据上做机器学习,应该从哪个点切入?
作者 | David Mack编译 | ronghuaiyang来源 | AI公园(ID:AI_Paradise)【导读】很多公司和机构都在使用图数据,想在图上做机器学习但不知从哪里开始做,希望这篇文章给大家一点启发。自从我们在伦敦互联数据中心(Connected Data Lon…
C++11中Lambda表达式的使用
Lambda表达式语法:[capture ] ( params ) mutable exception attribute -> return-type { body } 其中capture为定义外部变量是否可见(捕获),若为空,则表示不捕获所有外部变量,即所有外部变量均不可访问, 表示所有…

倒计时2天 | 专属技术人的盛会,为你而来!
5G 元年,人工智能 60 年,全球AI市场正发生着巨大的变化,顶尖科技企业和创新力量不断地进行着技术的更迭和应用的推进,专属于 AI 开发者的技术盛宴——2019 AI开发者大会(AI ProCon)将于 2 天后(…

了解大数据的特点、来源与数据呈现方式
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2639 浏览2019春节各种大数据分析报告,例如: 这世间,再无第二个国家有能力承载如此庞大的人流量。http://www.sohu.com/a/290025769_313993春节人口迁徙大数据…
Mysql使用大全 从基础到存储过程
平常习惯了phpmyadmin等其他工具的的朋友有的根本就不会命令,如果让你笔试去面试我看你怎么办,所以,学习一下还是非常有用的,也可以知道你通过GUI工具的时候工具到底做了什么。Mysql用处很广,是php最佳拍档,…
GDAL库简介以及在Windows下编译过程
GDAL(Geospatial Data Abstraction Library,地理空间数据抽象库)是一个在X/MIT许可协议下的开源栅格空间数据转换库。官网http://www.gdal.org/index.html,也可参考GitHub https://github.com/OSGeo/gdal,最新release版本为2.1.1. GDAL是一个…
Hexo博客NexT主题美化之评论系统
前言 更多效果展示,请访问我的 个人博客。 效果图: Valine 诞生于2017年8月7日,是一款基于Leancloud的快速、简洁且高效的无后端评论系统。 教程: 登录 Leancloud 官网,注册之后创建一个应用,选择【设置】-…

倒计时1天 | 专属技术人的盛会,为你而来!
5G 元年,人工智能 60 年,全球AI市场正发生着巨大的变化,顶尖科技企业和创新力量不断地进行着技术的更迭和应用的推进,专属于 AI 开发者的技术盛宴——2019 AI开发者大会(AI ProCon)将于 明天(9 …

Selenium 2 WebDriver 多线程 并发
我用的是Selenium2,至于它的背景和历史就不赘述了。Selenium2也叫WebDriver。下面讲个例子,用WebDriverjava来写个自动化测试的程序。(如果能用firefox去测试的话,我就直接用Selenium IDE录脚本了。。。)有个前提&…
GDAL2.1.1库在Ubuntu14.04下编译时遇到的问题处理方法
不用作任何调整,直接在Linux下编译GDAL2.1.1源码的步骤是:$ ./configure $ make $ make install非常简单, 这样也能正常生成gdal动态库、静态库,如果想将生成的文件放到指定的目录,则需改第一条命令为:$ ./…
刷爆了!这项技术BAT力捧!程序员:我彻底慌了...
人工智能离我们还遥远吗?近日,海底捞斥资1.5亿打造了中国首家火锅无人餐厅;阿里酝酿了两年之久的全球首家无人酒店也正式开始运营,百度无人车彻底量产。李彦宏称,这是中国第一款能够量产的无人驾驶乘用车。而阿里的这家…

redux的compose源码,中文注释
用图片会更清楚一点,注释和代码会分的清楚源码解析参考请参考https://segmentfault.com/a/11...
做好职业规划:做自己的船长
要想在职场上有所斩获,就必须做好职业规划。对于职场中人来说,职业规划是职业发展中最关键的向导。职业规划因人而异,不同的对象有不同的需求,因此制定的目标与计划也不尽相同,但个人为自己做职业规划的方法和流程是大…
GDAL中GDALDataset::RasterIO分块读取的实现
GDALDataset类中的RasterIO函数能够对图像任意指定区域、任意波段的数据按指定数据类型、指定排列方式读入内存和写入文件中,因此可以实现对大影像的分块读、写运算操作。针对特大的影像图像,有时为了减少内存消耗,对图像进行分块读取很有必要…

掌握深度学习,为什么要用PyTorch、TensorFlow框架?
作者 | Martin Heller译者 | 弯月责编 | 屠敏来源 | CSDN(ID:CSDNnews)【导读】如果你需要深度学习模型,那么 PyTorch 和 TensorFlow 都是不错的选择。并非每个回归或分类问题都需要通过深度学习来解决。甚至可以说,并…
ICANN敦促业界使用DNSSEC,应对DNS劫持攻击
HTTPS加密 可以有效帮助服务器应对DNS欺骗、DNS劫持、ARP攻击等安全威胁。DNS是什么?DNS如何被利用?HTTPS如何防止DNS欺骗? DNS如何工作? 如果您想访问www.example.com,您的浏览器需要找到该特定Web服务器的IP地址。它…

Lucene.net: the main concepts
2019独角兽企业重金招聘Python工程师标准>>> In the previous post you learnt how to get a copy of Lucene.net and where to go in order to look for more information. As you noticed the documentation is far from being complete and easy to read. So in …