Caffe源码中blob文件分析
Caffe源码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/blob.hpp文件的内容:
1. Include文件:
(1)、<caffe/common.hpp>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/54955236
(2)、<caffe/proto/caffe.pb.h>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/55267162
(3)、<caffe/syncedmem.hpp>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/56665919
(4)、<caffe/util/math_functinons.hpp>:此文件的介绍可以参考:http://blog.csdn.net/fengbingchun/article/details/56280708
2. 全局常量kMaxBlobAxes:
由const声明的全局常量kMaxBlobAxes表示Blob可以支持的最高维数,目前设置的支持的最高维数为32。
3. 类Blob:
Blob是Caffe中处理和传递实际数据的数据封装包,并且在CPU与GPU之间具有数据同步处理能力。从数学意义上说,blob是按C风格连续存储的N维数组,即在内部所存储的数据是一块连续的内存。
Blob是用来存储图像数据、网络参数(包括权值、偏置以及它们的梯度)、模型参数、学习到的参数、网络传输过程中产生的数据、网络中间的处理结果、优化过程的偏导数等各种数据。
Blob可以动态改变数组的尺寸,当拓展数组导致原有内存空间不足以存放下数据时(count_>capacity_),就会通过Reshape函数实现重新确定空间大小。
Blob数据可以通过Protobuf来做相应的序列化操作,ToProto和FromProto两个函数完成相应的序列化、反序列化(数据解析)操作。
Caffe基于blobs存储和交换数据。网络各层之间的数据都是通过Blob来传递的。为了便于优化,blobs提供统一的内存接口来存储某种类型的数据,例如批量图像数据、模型参数以及用来进行优化的导数。
blobs可根据CPU主机与GPU设备的同步需要,屏蔽CPU/GPU混合运算在计算上的开销。主机和设备上的内存按需分配,以提高内存的使用效率。
对于批量图像数据来说,blob常规的维数为图像数量N*通道数K*图像高度H*图像宽度W。blob按行为主(row-major)进行存储,所以一个4维blob中,坐标为(n,k,h,w)的值的物理位置为((n*K+k)*H+h)*W+w,这也使得最后面/最右边的维度更新最快,其中:
(1)、Number/N是每个批次处理的数据量。批量处理信息有利于提供设备处理和交换的数据的吞吐率。在ImageNet上每个训练批量为256张图像,则N=256;
(2)、Channel/K是特征维度,例如对RGB图像来说,可以理解为通道数量,K=3;如果是网络中间结果,就是feature map的数量;
(3)、H、W:如果是图像数据,可以理解为图像的高度和宽度;如果是参数数据,可以理解为滤波核的高度和宽度。
虽然Caffe的图像应用例子中很多blobs都是4维坐标,但是对于非图像应用任务,blobs也完全可以照常使用。
参数Blob的维度是根据层的类型和配置而变化的。
对于blob中的数据,我们关心的是values(值)和gradients(梯度),所以一个blob单元存储了两块数据------data_和diff_。前者是我们在网络中传送的普通数据,后者是通过网络计算得到的梯度。而且,由于数据既可存储在CPU上,又可存储在GPU上,因而有两种数据访问方式,如在CPU上的data_:静态方式,不改变数值(const Dtype* cpu_data() const;);动态方式,改变数值(Dtype*mutable_cpu_data();)。GPU和diff_的操作与在CPU上的data_类似。
之所以这么设计是因为blob使用了一个SyncedMemory类来同步CPU和GPU上的数据,以隐藏同步的细节和最小化传送数据。一个经验准则是,如果不想改变数据,就一直使用常量调用,而且决不要在自定义类中存储指针。每次操作blob时,调用相应的函数来获取它的指针,因为SyncedMemory需要用这种方式来确定何时需要复制数据。
实际上,使用GPU时,Caffe中CPU代码先从磁盘中加载数据到blob,同时请求分配一个GPU设备核(devicekernel)以使用GPU进行计算,再将计算好的blob数据送入下一层,这样既实现了高效运算,又忽略了底层细节。只要所有layers均有GPU实现,这种情况下所有的中间数据和梯度都会保留在GPU 上。
注:以上关于Blob内容的介绍主要摘自由CaffeCN社区翻译的《Caffe官方教程中译本》。
<caffe/blob.hpp>文件的详细介绍如下:
#ifndef CAFFE_BLOB_HPP_
#define CAFFE_BLOB_HPP_#include <algorithm>
#include <string>
#include <vector>#include "caffe/common.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/syncedmem.hpp"
#include "caffe/util/math_functions.hpp"// 全局常量,用来表示Blob可以支持的最高维数
const int kMaxBlobAxes = 32;namespace caffe {/*** @brief A wrapper around SyncedMemory holders serving as the basic* computational unit through which Layer%s, Net%s, and Solver%s* interact.** TODO(dox): more thorough description.*/
template <typename Dtype>
class Blob {public:
// 默认不带参数的构造函数,初始化count_=0,capacity_=0Blob() : data_(), diff_(), count_(0), capacity_(0) {}/// @brief Deprecated; use <code>Blob(const vector<int>& shape)</code>.
// 带参数的显示构造函数,推荐使用带vector<int>参数的构造函数
// 这两个构造函数内部会均会调用Reshape(const vector<int>)函数
// 注:执行这两个构造函数后,并不会真正分配内存空间,只是用来设置当前blob的shape_、count_和capacity_大小explicit Blob(const int num, const int channels, const int height, const int width);explicit Blob(const vector<int>& shape);/// @brief Deprecated; use <code>Reshape(const vector<int>& shape)</code>.
// Reshape系列函数通过输入参数用来设置或重新设置当前blob的shape_、count_和capacity_大小
// 推荐使用带vector<int>参数的Reshape函数
// 内部会调用SyncedMemory的构造函数,但不会真正分配内存空间
// 通过num/channes/height/width参数设置shape_、count_和capacity_大小void Reshape(const int num, const int channels, const int height, const int width);/*** @brief Change the dimensions of the blob, allocating new memory if* necessary.** This function can be called both to create an initial allocation* of memory, and to adjust the dimensions of a top blob during Layer::Reshape* or Layer::Forward. When changing the size of blob, memory will only be* reallocated if sufficient memory does not already exist, and excess memory* will never be freed.** Note that reshaping an input blob and immediately calling Net::Backward is* an error; either Net::Forward or Net::Reshape need to be called to* propagate the new input shape to higher layers.*/
// 通过vector<int>参数设置shape_、count_和capacity_大小void Reshape(const vector<int>& shape);
// 通过类BlobShape参数设置shape_、count_和capacity_大小
// BlobShape是定义在caffe.proto中的一个message,其字段有dimvoid Reshape(const BlobShape& shape);
// 通过外部的blob参数来设置shape_、count_和capacity_大小void ReshapeLike(const Blob& other);// 以string类型获得当前blob的shape_和count_值inline string shape_string() const {ostringstream stream;for (int i = 0; i < shape_.size(); ++i) {stream << shape_[i] << " ";}stream << "(" << count_ << ")";return stream.str();}// 获得当前Blob的所有维度值inline const vector<int>& shape() const { return shape_; }/*** @brief Returns the dimension of the index-th axis (or the negative index-th* axis from the end, if index is negative).** @param index the axis index, which may be negative as it will be* "canonicalized" using CanonicalAxisIndex.* Dies on out of range index.*/
// 获得当前Blob指定索引的维度值inline int shape(int index) const {return shape_[CanonicalAxisIndex(index)];}// 获得当前Blob的维数inline int num_axes() const { return shape_.size(); }// 获得当前Blob的元素个数inline int count() const { return count_; }/*** @brief Compute the volume of a slice; i.e., the product of dimensions* among a range of axes.** @param start_axis The first axis to include in the slice.** @param end_axis The first axis to exclude from the slice.*/
// 根据指定的start axis和end axis(部分blob)计算blob元素个数inline int count(int start_axis, int end_axis) const {CHECK_LE(start_axis, end_axis);CHECK_GE(start_axis, 0);CHECK_GE(end_axis, 0);CHECK_LE(start_axis, num_axes());CHECK_LE(end_axis, num_axes());int count = 1;for (int i = start_axis; i < end_axis; ++i) {count *= shape(i);}return count;}/*** @brief Compute the volume of a slice spanning from a particular first* axis to the final axis.** @param start_axis The first axis to include in the slice.*/
// 根据指定的start axis(部分blob)计算blob元素个数inline int count(int start_axis) const {return count(start_axis, num_axes());}/*** @brief Returns the 'canonical' version of a (usually) user-specified axis,* allowing for negative indexing (e.g., -1 for the last axis).** @param index the axis index.* If 0 <= index < num_axes(), return index.* If -num_axes <= index <= -1, return (num_axes() - (-index)),* e.g., the last axis index (num_axes() - 1) if index == -1,* the second to last if index == -2, etc.* Dies on out of range index.*/
// Blob的index可以是负值,对参数axis_index进行判断,结果返回一个正的索引值
// 如果axis_index是负值,则要求axis_index>=-shape_.size(),则返回axis_index+shape_.size()
// 如果axis_index是正值,则要求axis_index<shape_.size(),则直接返回axis_indexinline int CanonicalAxisIndex(int axis_index) const {CHECK_GE(axis_index, -num_axes())<< "axis " << axis_index << " out of range for " << num_axes()<< "-D Blob with shape " << shape_string();CHECK_LT(axis_index, num_axes())<< "axis " << axis_index << " out of range for " << num_axes()<< "-D Blob with shape " << shape_string();if (axis_index < 0) {return axis_index + num_axes();}return axis_index;}/// @brief Deprecated legacy shape accessor num: use shape(0) instead.
// 获得当前blob的num,推荐调用shape(0)函数inline int num() const { return LegacyShape(0); }/// @brief Deprecated legacy shape accessor channels: use shape(1) instead.
// 获得当前blob的channels,推荐调用shape(1)函数inline int channels() const { return LegacyShape(1); }/// @brief Deprecated legacy shape accessor height: use shape(2) instead.
// 获得当前blob的height,推荐调用shape(2)函数inline int height() const { return LegacyShape(2); }/// @brief Deprecated legacy shape accessor width: use shape(3) instead.
// 获得当前blob的width,推荐调用shape(3)函数inline int width() const { return LegacyShape(3); }
// 获得当前blob的某一维度值inline int LegacyShape(int index) const {CHECK_LE(num_axes(), 4)<< "Cannot use legacy accessors on Blobs with > 4 axes.";CHECK_LT(index, 4);CHECK_GE(index, -4);if (index >= num_axes() || index < -num_axes()) {// Axis is out of range, but still in [0, 3] (or [-4, -1] for reverse// indexing) -- this special case simulates the one-padding used to fill// extraneous axes of legacy blobs.return 1;}return shape(index);}// 根据num、channels、height、width计算偏移量:((n*K+k)*H+h)*W+winline int offset(const int n, const int c = 0, const int h = 0, const int w = 0) const {CHECK_GE(n, 0);CHECK_LE(n, num());CHECK_GE(channels(), 0);CHECK_LE(c, channels());CHECK_GE(height(), 0);CHECK_LE(h, height());CHECK_GE(width(), 0);CHECK_LE(w, width());return ((n * channels() + c) * height() + h) * width() + w;}
// 根据vector<int> index计算偏移量:((n*K+k)*H+h)*W+winline int offset(const vector<int>& indices) const {CHECK_LE(indices.size(), num_axes());int offset = 0;for (int i = 0; i < num_axes(); ++i) {offset *= shape(i);if (indices.size() > i) {CHECK_GE(indices[i], 0);CHECK_LT(indices[i], shape(i));offset += indices[i];}}return offset;}/*** @brief Copy from a source Blob.** @param source the Blob to copy from* @param copy_diff if false, copy the data; if true, copy the diff* @param reshape if false, require this Blob to be pre-shaped to the shape* of other (and die otherwise); if true, Reshape this Blob to other's* shape if necessary*/
// 从外部blob拷贝数据到当前的blob
// 若reshape参数为true,如果两边blob的reshape不相同,则会重新reshape
// 若copy_diff为false,则拷贝data_数据;若copy_diff为true,则拷贝diff_数据void CopyFrom(const Blob<Dtype>& source, bool copy_diff = false, bool reshape = false);// 根据给定的位置访问数据
// 根据指定的偏移量获得前向传播数据data_的一个元素的值inline Dtype data_at(const int n, const int c, const int h, const int w) const {return cpu_data()[offset(n, c, h, w)];}
// 根据指定的偏移量获得反向传播梯度diff_的一个元素的值inline Dtype diff_at(const int n, const int c, const int h, const int w) const {return cpu_diff()[offset(n, c, h, w)];}
// 根据指定的偏移量获得前向传播数据data_的一个元素的值inline Dtype data_at(const vector<int>& index) const {return cpu_data()[offset(index)];}
// 根据指定的偏移量获得反向传播梯度diff_的一个元素的值inline Dtype diff_at(const vector<int>& index) const {return cpu_diff()[offset(index)];}// 获得前向传播数据data_的指针inline const shared_ptr<SyncedMemory>& data() const {CHECK(data_);return data_;}
// 获得反向传播梯度diff_的指针inline const shared_ptr<SyncedMemory>& diff() const {CHECK(diff_);return diff_;}// Blob的数据访问函数,包括CPU和GPU
// 带mutable_前缀的函数是可以对Blob数据进行改写的;其它不带的是只读的,不允许改写数据const Dtype* cpu_data() const; // 调用SyncedMemory::cpu_data()函数const Dtype* gpu_data() const; // 调用SyncedMemory::gpu_data()函数const Dtype* cpu_diff() const; // 调用SyncedMemory::cpu_data()函数const Dtype* gpu_diff() const; // 调用SyncedMemory::gpu_data()函数Dtype* mutable_cpu_data(); // 调用SyncedMemory::mutable_cpu_data()函数Dtype* mutable_gpu_data(); // 调用SyncedMemory::mutable_gpu_data()函数Dtype* mutable_cpu_diff(); // 调用SyncedMemory::mutable_cpu_data()函数Dtype* mutable_gpu_diff(); // 调用SyncedMemory::mutable_gpu_data()函数void set_cpu_data(Dtype* data); // 调用SyncedMemory::set_cpu_data(void*)函数// 它会被网络中存储参数的Blob调用,完成梯度下降过程中的参数更新
// 调用caffe_axpy函数重新计算data_(weight,bias 等减去对应的导数): data_ = -1 * diff_ + data_void Update();// Blob的数据持久化函数,通过Protobuf来做相应的序列化/反序列化操作
// BlobProto是定义在caffe.proto中的一个message,其字段有shape(BlobShape)、data、diff、num、channels、height、width
// 将BlobProto的shape/data/diff分别copy给当前blob的shape_/data_/diff_完成数据解析(反序列化)
// 若reshape参数为true,则会对当前的blob重新进行reshapevoid FromProto(const BlobProto& proto, bool reshape = true);
// 将Blob的shape_/data_/diff_(如果write_diff为true)分别copy给BlobProto的shape/data/diff完成序列化void ToProto(BlobProto* proto, bool write_diff = false) const;/// @brief Compute the sum of absolute values (L1 norm) of the data.
// 计算data_的L1范式:向量中各个元素绝对值之和Dtype asum_data() const;/// @brief Compute the sum of absolute values (L1 norm) of the diff.
// 计算diff_的L1范式:向量中各个元素绝对值之和Dtype asum_diff() const;/// @brief Compute the sum of squares (L2 norm squared) of the data.
// 计算data_的L2范式平方:向量中各元素的平方和Dtype sumsq_data() const;/// @brief Compute the sum of squares (L2 norm squared) of the diff.
// // 计算diff_的L2范式平方:向量中各元素的平方和Dtype sumsq_diff() const;/// @brief Scale the blob data by a constant factor.
// 将data_数据乘以一个因子:X = alpha*Xvoid scale_data(Dtype scale_factor);/// @brief Scale the blob diff by a constant factor.
// 将diff_数据乘以一个因子:X = alpha*Xvoid scale_diff(Dtype scale_factor);/*** @brief Set the data_ shared_ptr to point to the SyncedMemory holding the* data_ of Blob other -- useful in Layer%s which simply perform a copy* in their Forward pass.** This deallocates the SyncedMemory holding this Blob's data_, as* shared_ptr calls its destructor when reset with the "=" operator.*/
// 将外部指定的blob的data_指针指向给当前blob的data_,以实现共享data_void ShareData(const Blob& other);/*** @brief Set the diff_ shared_ptr to point to the SyncedMemory holding the* diff_ of Blob other -- useful in Layer%s which simply perform a copy* in their Forward pass.** This deallocates the SyncedMemory holding this Blob's diff_, as* shared_ptr calls its destructor when reset with the "=" operator.*/
// 将外部指定的blob的diff_指针指向给当前blob的diff_,以实现共享diff_void ShareDiff(const Blob& other);
// 比较两个blob的shape是否相同
// BlobProto是定义在caffe.proto中的一个message,其字段有shape(BlobShape)、data、diff、num、channels、height、widthbool ShapeEquals(const BlobProto& other);protected:
// Caffe中类的成员变量名都带有后缀"_",这样就容易区分临时变量和类成员变量shared_ptr<SyncedMemory> data_; // 存储前向传播的数据shared_ptr<SyncedMemory> diff_; // 存储反向传播的导数、梯度、偏差vector<int> shape_; // Blob的维度值,通过Reshape函数的shape参数获得相应值,若为4维,则依次为num、channels、height、widthint count_; // 表示Blob中的元素个数,shape_所有元素的乘积int capacity_; // 表示当前Blob的元素个数(控制动态分配),因为Blob可能会reshape// 禁止使用Blob类的拷贝和赋值操作DISABLE_COPY_AND_ASSIGN(Blob);
}; // class Blob} // namespace caffe#endif // CAFFE_BLOB_HPP_// 可选package声明符,用来防止不同的消息类型有命名冲突
package caffe; // 以下所有生成的信息将会在命名空间caffe内: namespace caffe { ... }// 说明:带"deprecated"关键字的信息可以不用看,过时的,后面有可能是被废弃的// 以下三个是关于blob的三个类:BlobShape、BlobProto、BlobProtoVector
// Specifies the shape (dimensions) of a Blob.
message BlobShape { // 数据块形状(Blob的维度),若为4维,则为num、channel、height、widthrepeated int64 dim = 1 [packed = true]; // blob shape数组
}message BlobProto { // blob属性类optional BlobShape shape = 7; // BlobShappe类对象repeated float data = 5 [packed = true]; // float类型的data,前向repeated float diff = 6 [packed = true]; // float类型的diff,后向repeated double double_data = 8 [packed = true]; // double类型的data,前向repeated double double_diff = 9 [packed = true]; // double类型的diff,后向// 4D dimensions -- deprecated. Use "shape" instead.// 已使用BlobShape shape替代optional int32 num = 1 [default = 0];optional int32 channels = 2 [default = 0];optional int32 height = 3 [default = 0];optional int32 width = 4 [default = 0];
}// The BlobProtoVector is simply a way to pass multiple blobproto instances
// around.
message BlobProtoVector { // 存放多个BlobProto实例repeated BlobProto blobs = 1;
}#include "funset.hpp"
#include <string>
#include <vector>
#include "common.hpp"int test_caffe_blob()
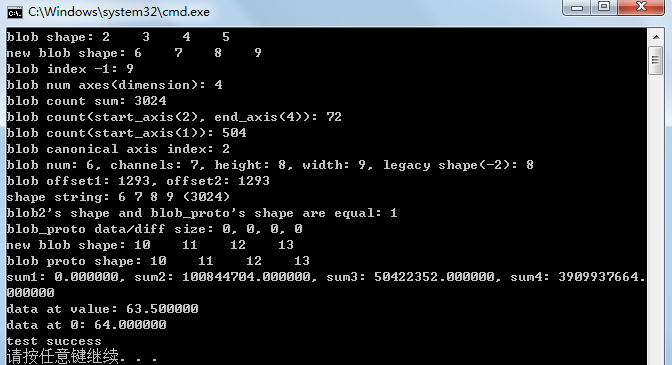
{caffe::Blob<float> blob1;std::vector<int> shape{ 2, 3, 4, 5 };caffe::Blob<float> blob2(shape);std::vector<int> blob_shape = blob2.shape();fprintf(stderr, "blob shape: ");for (auto index : blob_shape) {fprintf(stderr, "%d ", index);}std::vector<int> shape_{ 6, 7, 8, 9 };blob2.Reshape(shape_);std::vector<int> blob_shape_ = blob2.shape();fprintf(stderr, "\nnew blob shape: ");for (auto index : blob_shape_) {fprintf(stderr, "%d ", index);}fprintf(stderr, "\n");int value = blob2.shape(-1);fprintf(stdout, "blob index -1: %d\n", value);int num_axes = blob2.num_axes();fprintf(stderr, "blob num axes(dimension): %d\n", num_axes);int count = blob2.count();fprintf(stderr, "blob count sum: %d\n", count);count = blob2.count(2, 4);fprintf(stderr, "blob count(start_axis(2), end_axis(4)): %d\n", count);count = blob2.count(1);fprintf(stderr, "blob count(start_axis(1)): %d\n", count);int canonical_axis_index = blob2.CanonicalAxisIndex(-2);fprintf(stderr, "blob canonical axis index: %d\n", canonical_axis_index);int num = blob2.num();int channels = blob2.channels();int height = blob2.height();int width = blob2.width();int legacy_shape = blob2.LegacyShape(-2);fprintf(stderr, "blob num: %d, channels: %d, height: %d, width: %d, legacy shape(-2): %d\n",num, channels, height, width, legacy_shape);std::vector<int> indices{ 2, 3, 7, 6 };int offset1 = blob2.offset(indices);int offset2 = blob2.offset(indices[0], indices[1], indices[2], indices[3]);fprintf(stderr, "blob offset1: %d, offset2: %d\n", offset1, offset2);std::string shape_string = blob2.shape_string();fprintf(stderr, "shape string: %s\n", shape_string.c_str());caffe::BlobProto blob_proto;blob_proto.set_num(6);blob_proto.set_channels(7);blob_proto.set_height(8);blob_proto.set_width(9);bool flag = blob2.ShapeEquals(blob_proto);fprintf(stderr, "blob2's shape and blob_proto's shape are equal: %d\n", flag);int blob_proto_data_size_float = blob_proto.data_size();int blob_proto_data_size_double = blob_proto.double_data_size();int blob_proto_diff_size_float = blob_proto.diff_size();int blob_proto_diff_size_double = blob_proto.double_diff_size();fprintf(stderr, "blob_proto data/diff size: %d, %d, %d, %d\n", blob_proto_data_size_float,blob_proto_data_size_double, blob_proto_diff_size_float, blob_proto_diff_size_double);caffe::BlobShape blob_proto_shape;for (int i = 0; i < 4; ++i) {blob_proto_shape.add_dim(i + 10);}blob2.Reshape(blob_proto_shape);blob_shape_ = blob2.shape();fprintf(stderr, "new blob shape: ");for (auto index : blob_shape_) {fprintf(stderr, "%d ", index);}fprintf(stderr, "\n");fprintf(stderr, "blob proto shape: ");for (int i = 0; i < blob_proto_shape.dim_size(); ++i) {fprintf(stderr, "%d ", blob_proto_shape.dim(i));}fprintf(stderr, "\n");// 注:以上进行的所有操作均不会申请分配任何内存// cv::Mat -> Blobstd::string image_name = "E:/GitCode/Caffe_Test/test_data/images/a.jpg";cv::Mat mat = cv::imread(image_name, 1);if (!mat.data) {fprintf(stderr, "read image fail: %s\n", image_name.c_str());return -1;}cv::Mat mat2;mat.convertTo(mat2, CV_32FC3);std::vector<int> mat_reshape{ 1, mat2.channels(), mat2.rows, mat2.cols };blob2.Reshape(mat_reshape);float sum1 = blob2.asum_data();blob2.set_cpu_data((float*)mat2.data);float sum2 = blob2.asum_data();blob2.scale_data(0.5);float sum3 = blob2.asum_data();float sum4 = blob2.sumsq_data();fprintf(stderr, "sum1: %f, sum2: %f, sum3: %f, sum4: %f\n", sum1, sum2, sum3, sum4);float value2 = blob2.data_at(0, 2, 100, 200);fprintf(stderr, "data at value: %f\n", value2);const float* data = blob2.cpu_data();fprintf(stderr, "data at 0: %f\n", data[0]);cv::Mat mat3;mat2.convertTo(mat3, CV_8UC3);image_name = "E:/GitCode/Caffe_Test/test_data/images/a_ret.jpg";cv::imwrite(image_name, mat3);return 0;
}
GitHub:https://github.com/fengbingchun/Caffe_Test
相关文章:

jQuery之替换节点
如果要替换节点,jQuery提供了两个方法:replaceWith()和replaceAll()。 两个方法的作用相同,只是操作颠倒了。 作用:将所有匹配的元素都替换成指定的HTML或者DOM元素。(摘自《锋利的jQuery(第二版)》P72) 基…

比特大陆发布第三代AI芯片,INT8算力达17.6Tops
9月17日,福州城市大脑暨闽东北信息化战略合作发布会在数字中国会展中心隆重召开。本次发布会上,比特大陆正式推出了第三代AI芯片BM1684,同时也宣布BM1684将作为底层算力,赋能福州城市大脑,助力数字福州、数字中国的建设…

在 Azure 网站上使用 Memcached 改进 WordPress
编辑人员注释:本文章由 Windows Azure 网站团队的项目经理 Sunitha Muthukrishna 和 Windows Azure 网站开发人员体验合作伙伴共同撰写。 您是否希望改善在 Azure 网站服务上运行的 WordPress 网站的性能?如果是,那么您就需要一个可帮助加快您…

Caffe源码中io文件分析
Caffe源码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/util/io.hpp文件的内容:1. include文件:(1)、<google/protobuf/message.h>:关于protobuf的介绍可以参考&…

DeepMind悄咪咪开源三大新框架,深度强化学习落地希望再现
作者 | Jesus Rodriguez译者 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】近几年,深度强化学习(DRL)一直是人工智能取得最大突破的核心。尽管取得了很多进展,但由于缺乏工具和库,DRL 方法仍…

seq2seq
链接: https://blog.csdn.net/wuzqchom/article/details/75792501 转载于:https://www.cnblogs.com/yttas/p/10631442.html
vip能ping通,但80不通的解决方法
最近遇到一个很奇怪的问题,在做两台服务器负载均衡的时候,vip已经添加了,而且能ping通了,但是页面访问不了,也就是说80端口一直不通,ipvsadm -lnc查看链接状态全部是SYN_RECV。网上找了好长时间,…

OpenCV中imread/imwrite与imdecode/imencode的异同
OpenCV中的cv::imdecode函数是从指定的内存缓存中读一幅图像,而cv::imencode是将一幅图像写进内存缓存中。cv::imread是从指定文件载入一幅图像,cv::imwrite是保存一幅图像到指定的文件中。cv::imread和cv::imdecode内部都是通过ImageDecoder类来进行图像…
奖金+招聘绿色通道,这一届算法大赛关注下?
大赛背景伴随着5G、物联网与大数据形成的后互联网格局的逐步形成,日益多样化的用户触点、庞杂的行为数据和沉重的业务体量也给我们的数据资产管理带来了不容忽视的挑战。为了建立更加精准的数据挖掘形式和更加智能的机器学习算法,对不断生成的用户行为事…
Linux文件属性
文件属性和权限 [rootdaf root]# ls -al total 64 drwxr-x--- 4 root root 4096 Feb 14 22:02 . drwxr-xr-x 23 root root 4096 Feb 16 13:35 .. -rw-r--r-- 1 root root 1210 Feb 10 06:03 anaconda-ks.cfg -rw------- 1…
Caffe源码中layer文件分析
Caffe源码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/layer.hpp文件的内容:1. include文件:(1)、<caffe/blob.hpp>:此文件的介绍可以参考:http://b…

全球首个软硬件推理平台 :NVDLA编译器正式开源
作者 | 神经小姐姐来源 | HyperAI超神经(ID:HyperAI)【导读】为深度学习设计新的定制硬件加速器,是目前的一个趋势,但用一种新的设计,实现最先进的性能和效率却具有挑战性。近日,英伟达开源了软硬件推理平台…
【leetcode】1018. Binary Prefix Divisible By 5
题目如下: Given an array A of 0s and 1s, consider N_i: the i-th subarray from A[0] to A[i] interpreted as a binary number (from most-significant-bit to least-significant-bit.) Return a list of booleans answer, where answer[i]is true if and only …
php中magic_quotes_gpc对unserialize的影响
昨天朋友让我帮他解决下他网站的购物车程序的问题,程序用的是PHPCMS,换空间前是好的(刚换的空间),具体问题是提示成功加入购物车后跳转到购物车页面,购物车里为空。 我看了下代码,大致的原理就是…

值得收藏!基于激光雷达数据的深度学习目标检测方法大合集(上)
作者 | 黄浴转载自知乎专栏自动驾驶的挑战和发展【导读】上周,我们在激光雷达,马斯克看不上,却又无可替代?》一文中对自动驾驶中广泛使用的激光雷达进行了简单的科普,今天,这篇文章将各大公司和机构基于激光…
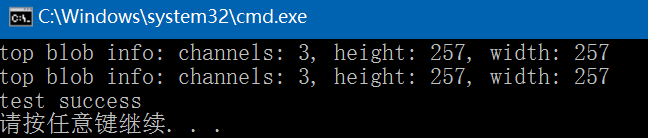
Caffe源码中Pooling Layer文件分析
Caffe源码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/vision_layers文件中PoolingLayer类,在最新版caffe中,PoolingLayer类被单独放在了include/caffe/layers/pooling_layer.hpp文件中…
手持终端以物联网的模式
近年来,物联宇手持终端以物联网的模式,开启了信息化的管理模式,迸发了新的自我提升和业务新商机。手持终端是一款智能的电子设备,它的核心功能为用户速带来业务效率的提升,如快递行业,每天的工作量需求大&a…
Linux系统基础-管理之用户、权限管理
Linux用户、权限管理一、如何实现"用户管理"1.什么是用户 "User" : 是一个使用者获取系统资源的凭证,是权限的结合,为了识别界定每一个用户所能访问的资源及其服务的。只是一种凭证。会有一个表示数字,计算机会首…
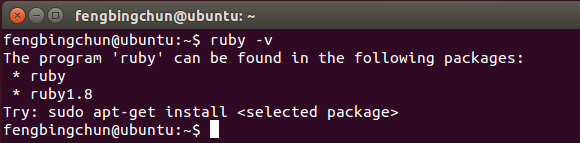
Ubuntu14.04 LTS中安装Ruby 2.4源码操作步骤
(1)、查看是否已安装ruby,执行命令,如下图,可见机子上还没有安装ruby,即使通过apt-get install命令安装也只能安装1.8版本;(2)、从 http://www.ruby-lang.org/en/downloads/ 下载最新稳定版2.4即ruby-2.4.0.tar.gz&a…

图森未来完成2.15亿美元D轮融资,将拓展无人驾驶运输服务
AI科技大本营消息,9月17日,图森未来宣布获得1.2亿美元的D2轮投资,并完成总额为2.15亿美元的D轮融资。D2轮的投资方除了此前已宣布的UPS外,还包括新的投资方鼎晖资本,以及一级供应商万都(Mando Corporation&…
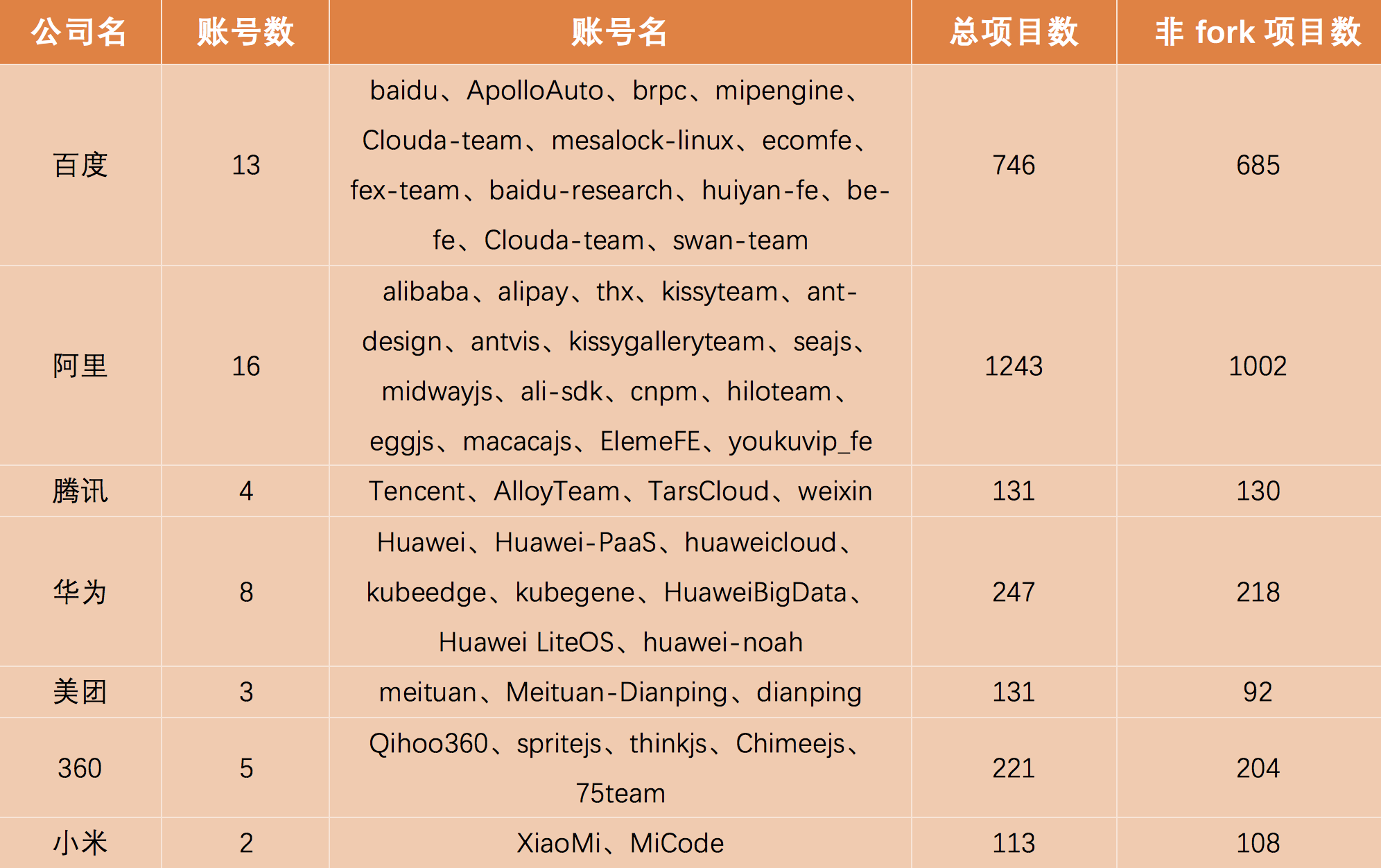
中国互联网公司开源项目调研报告
近年来,开源技术得到越来越多的重视,微软收购GitHub、IBM收购红帽,都表明了开源的价值。国内公司也越来越多的参与开源,加入开源基金会/贡献开源项目。但是,它们到底做得如何呢?为此InfoQ统计了国内在GitHu…

ReSharper 配置及用法
1:安装后,Resharper会用他自己的英文智能提示,替换掉 vs2010的智能提示,所以我们要换回到vs2010的智能提示 2:快捷键。是使用vs2010的快捷键还是使用 Resharper的快捷键呢?我是使用re的快捷键 3: Resharper安装后,会做…
Ubuntu14.04 LTS中升级gcc/g++版本到4.9.4的操作步骤
Ubuntu14.04 LTS中默认的gcc/g版本为4.8.4,如下图,在C11中增加了对正则表达式的支持,但是好像到gcc/g 4.9.2版本才会对正则表达式能很好的支持,这里介绍下Ubuntu14.04 LTS升级gcc/g版本到4.9.4的操作步骤: 1࿰…

华为全球最快AI训练集群Atlas 900诞生
作者 | 胡巍巍来源 | CSDN(ID:CSDNnews)你,和计算有什么关系?早上,你打开手机App,查看天气预报,和计算有关;中午,你打开支付宝人脸支付,买了份宫保…
rabbitmq可靠发送的自动重试机制 --转
原贴地址 https://www.jianshu.com/p/6579e48d18ae https://www.jianshu.com/p/4112d78a8753 git项目代码地址 https://github.com/littlersmall/rabbitmq-access 转载于:https://www.cnblogs.com/hmpcly/p/10641688.html

在Linux下如何安装配置SVN服务
2019独角兽企业重金招聘Python工程师标准>>> Linux下在阿里云上架一个svn centos上安装:yum install subversion 安装成功 键入命令 svnserve --version 有版本信息则进行下一步 1、新建版本库目录 mkdir -p /opt/svndata/repos 2、设置此目录为…
201671030129 周婷 《英文文本统计分析》结对项目报告
项目内容这个作业属于哪个课程软件工程这个作业的要求在哪里软件工程结对项目课程学习目标熟悉软件开发整体流程及结对编程,提升自身能力本次作业在哪个具体方面帮助我们实现目标体验组队编程,体验一个完整的工程任务一: 作业所点评博客GetHu…
C++/C++11中std::string用法汇总
C/C11中std::string是个模板类,它是一个标准库。使用string类型必须首先包含<string>头文件。作为标准库的一部分,string定义在命名空间std中。std::string是C中的字符串。字符串对象是一种特殊类型的容器,专门设计来操作字符序列。str…
你在付费听《说好不哭》,我在这里免费看直播还送书 | CSDN新书发布会
周一的时候,我拖着疲惫的身体回到家中,躺倒床上刷刷朋友圈,什么?周杰伦出新歌了?朋友圈都是在分享周杰伦的新歌《说好不哭》,作为周杰伦的粉丝,我赶紧打开手机上的QQ音乐,准备去听&a…
解决Mysql:unrecognized service错误的方法(CentOS)附:修改用户名密码
2019独角兽企业重金招聘Python工程师标准>>> service mysql start出错,mysql启动不了,解决mysql: unrecognized service错误的方法如下: [rootctohome.com ~]# service mysql startmysql: unrecognized service [rootctohome.co…