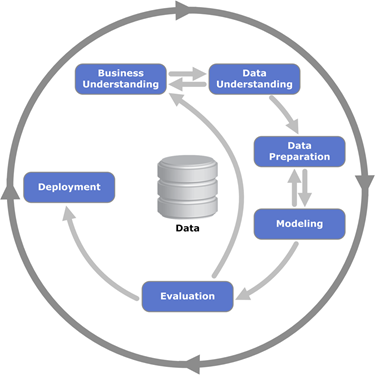
AutoML很火,过度吹捧的结果?
- 数据科学项目
AutoML
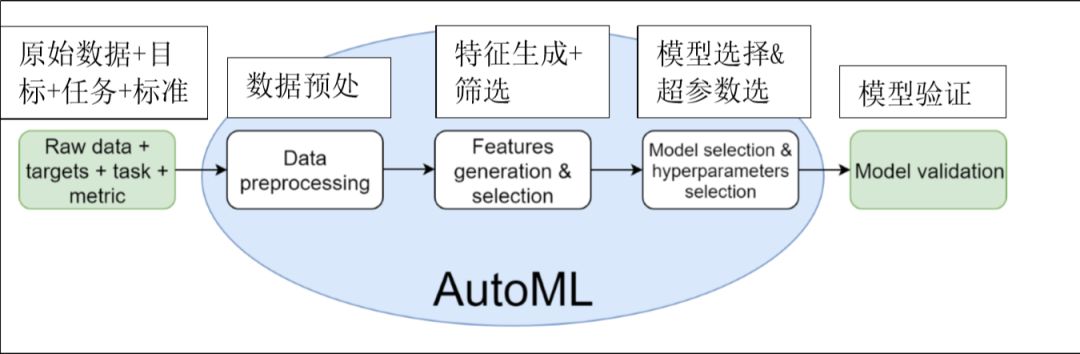
AutoML将填补数据科学市场中“供应”与“需求”之间的空缺
- AutoML可帮助数据科学小组节省时间
简单来说:
如果(从模型中的收益 > 数据科学小组花费的时间)= 不需要节省时间
如果(从模型中的收益 <= 数据科学小组花费的时间)= 你真的解决了问题吗?
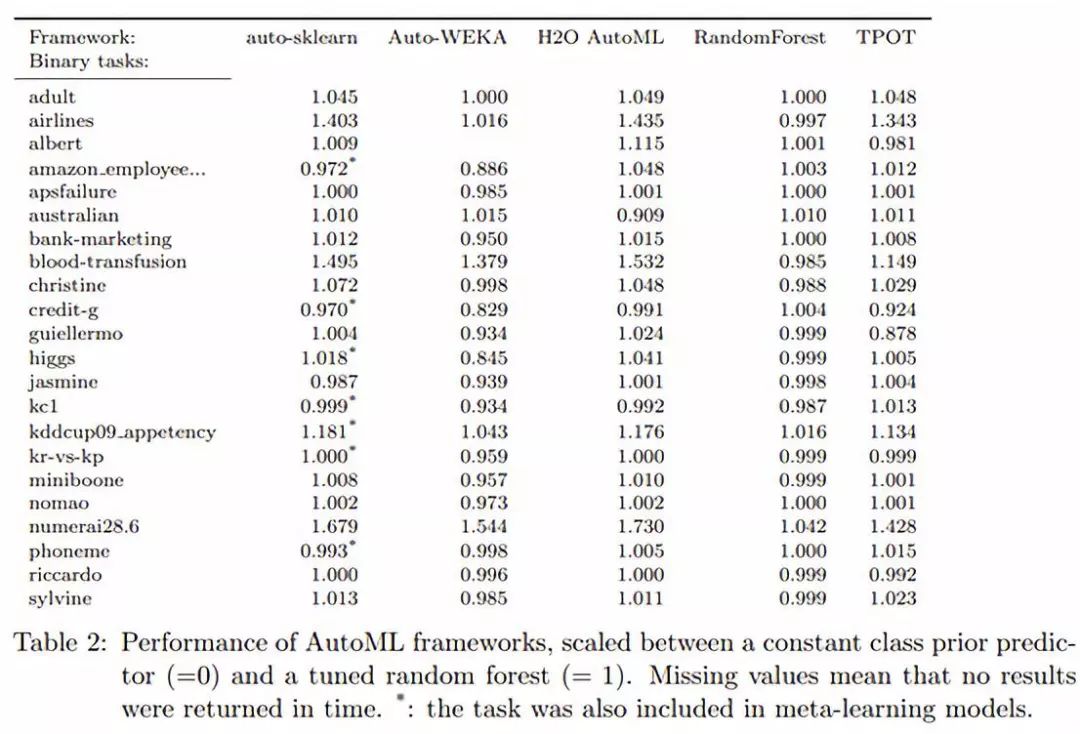
Score = (ROC AUC / ROC AUC of my baseline) * 100%
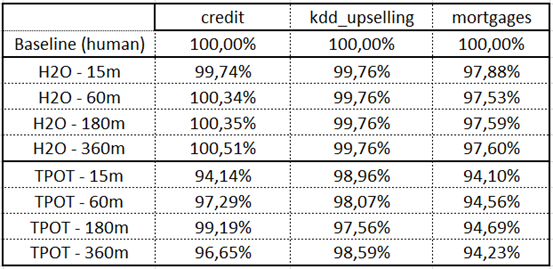
PS:引擎不是车
原文链接:https://towardsdatascience.com/automl-is-overhyped-1b5511ded65f
◆
精彩推荐
◆

推荐阅读
网红“AI大佬”被爆论文剽窃,Jeff Dean都看不下去了
AI大佬“互怼”:Bengio和Gary Marcus隔空对谈深度学习发展现状
有了这套模板,再不担心刷不动LeetCode了
Google图嵌入工业界最新大招,高效解决训练大规模深度图卷积神经网络问题
太鸡冻了!我用Python偷偷查到暗恋女生的名字
苹果 5G 芯片“难产”
【角度刁钻】如果把线程当作一个人来对待,秒懂
C 语言这么厉害,它自身是用什么语言写的?
一文了解超级账本DLT、库、开发工具有哪些, Hyperledger家族成员你认识几个?

你点的每个“在看”,我都认真当成了AI
相关文章:

tomcat6 配置web管理端访问权限
配置tomcat 管理端登陆 /apache-tomcat-6.0.35/conf/tomcat-users.xml 配置文件,使用时需要把注释去掉<!-- <!-- <role rolename"tomcat"/> <role rolename"role1"/> <user username"tomcat" password"…

@程序员:Python 3.8正式发布,重要新功能都在这里
整理 | Jane、夕颜出品 | AI科技大本营(ID:rgznai100)【导读】最新版本的Python发布了!今年夏天,Python 3.8发布beta版本,但在2019年10月14日,第一个正式版本已准备就绪。现在,我们都…
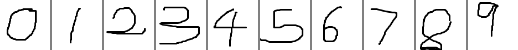
TensorRT Samples: MNIST(serialize TensorRT model)
关于TensorRT的介绍可以参考: http://blog.csdn.net/fengbingchun/article/details/78469551 这里实现在构建阶段将TensorRT model序列化存到本地文件,然后在部署阶段直接load TensorRT model序列化的文件进行推理,mnist_infer.cpp文件内容…
【mysql错误】用as别名 做where条件,报未知的列 1054 - Unknown column 'name111' in 'field list'...
需求:SELECT a AS b WHRER b1; //这样使用会报错,说b不存在。 因为mysql底层跑SQL语句时:where 后的筛选条件在先, as B的别名在后。所以机器看到where 后的别名是不认的,所以会报说B不存在。 这个b只是字段a查询结…
C++2年经验
网络 sql 基础算法 最多到图和树 常用的几种设计模式,5以内即可转载于:https://www.cnblogs.com/liujin2012/p/3766106.html
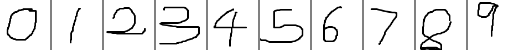
在Caffe中调用TensorRT提供的MNIST model
在TensorRT 2.1.2中提供了MNIST的model,这里拿来用Caffe的代码调用实现,原始的mnist_mean.binaryproto文件调整为了纯二进制文件mnist_tensorrt_mean.binary,测试结果与使用TensorRT调用(http://blog.csdn.net/fengbingchun/article/details/…

142页ICML会议强化学习笔记整理,值得细读
作者 | David Abel编辑 | DeepRL来源 | 深度强化学习实验室(ID: Deep-RL)ICML 是 International Conference on Machine Learning的缩写,即国际机器学习大会。ICML如今已发展为由国际机器学习学会(IMLS)主办的年度机器…

CF1148F - Foo Fighters
CF1148F - Foo Fighters 题意:你有n个物品,每个都有val和mask。 你要选择一个数s,如果一个物品的mask & s含有奇数个1,就把val变成-val。 求一个s使得val总和变号。 解:分步来做。发现那个奇数个1可以变成&#x…
html传參中?和amp;
<a href"MealServlet?typefindbyid&mid<%m1.getMealId()%> 在这句传參中?之后的代表要传递的參数当中有两个參数第一个为type第二个为mid假设是一个參数就不用加&假设是多个參数须要加上&来传递
实战:手把手教你实现用语音智能控制电脑 | 附完整代码
作者 | 叶圣出品 | AI科技大本营(ID:rgznai100)导语:本篇文章将基于百度API实现对电脑的语音智能控制,不需要任何硬件上的支持,仅仅依靠一台电脑即可以实现。作者经过测试,效果不错,同时可以依据…
C++/C++11中左值、左值引用、右值、右值引用的使用
C的表达式要不然是右值(rvalue),要不然就是左值(lvalue)。这两个名词是从C语言继承过来的,原本是为了帮助记忆:左值可以位于赋值语句的左侧,右值则不能。 在C语言中,二者的区别就没那么简单了。一个左值表达式的求值结…

Could not create the view: An unexpected exception was thrown. Myeclipse空间报错
转载于:https://blog.51cto.com/82654993/1424339
Banknote Dataset(钞票数据集)介绍
Banknote Dataset(钞票数据集):这是从纸币鉴别过程中的图像里提取的数据,用来预测钞票的真伪的数据集。该数据集中含有1372个样本,每个样本由5个数值型变量构成,4个输入变量和1个输出变量。小波变换工具用于从图像中提取特征。这是…
快速适应性很重要,但不是元学习的全部目标
作者 | Khurram Javed, Hengshuai Yao, Martha White译者 | Monanfei出品 | AI科技大本营(ID:rgznai100)实践证明,基于梯度的元学习在学习模型初始化、表示形式和更新规则方面非常有效,该模型允许从少量样本中进行快速适应。这些方…
面试题-自旋锁,以及jvm对synchronized的优化
背景 想要弄清楚这些问题,需要弄清楚其他的很多问题。 比如,对象,而对象本身又可以延伸出很多其他的问题。 我们平时不过只是在使用对象而已,怎么使用?就是new 对象。这只是语法层面的使用,相当于会了一门编…
DNS解析故障
在实际应用过程中可能会遇到DNS解析错误的问题,就是说当我们访问一个域名时无法完成将其解析到IP地址的工作,而直接输入网站IP却可以正常访问,这就是因为DNS解析出现故障造成的。这个现象发生的机率比较大,所以本文将从零起步教给…
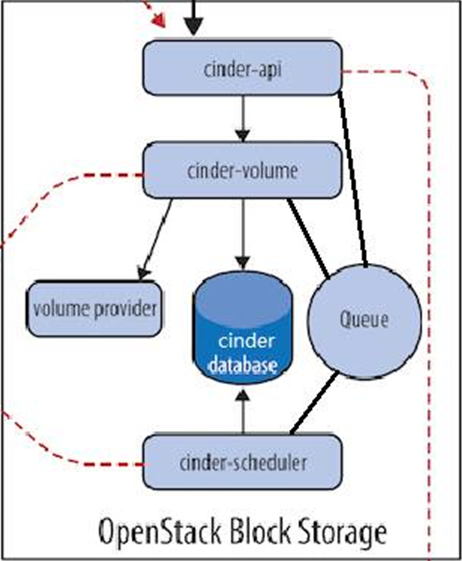
cinder存储服务
一、cinder 介绍: 理解 Block Storage 操作系统获得存储空间的方式一般有两种: 1、通过某种协议(SAS,SCSI,SAN,iSCSI 等)挂接裸硬盘,然后分区、格式化、创建文件系统;或者直接使用裸硬盘存储数据࿰…
Ubuntu 14.04 64位机上配置Android Studio操作步骤
Android Studio是一个为Android平台开发程序的集成开发环境。2013年5月16日在Google I/O上发布,可供开发者免费使用。Android Studio基于JetBrains IntelliJ IDEA,为Android开发特殊定制,并在Windows、OS X和Linux平台上均可运行。1. 从 htt…
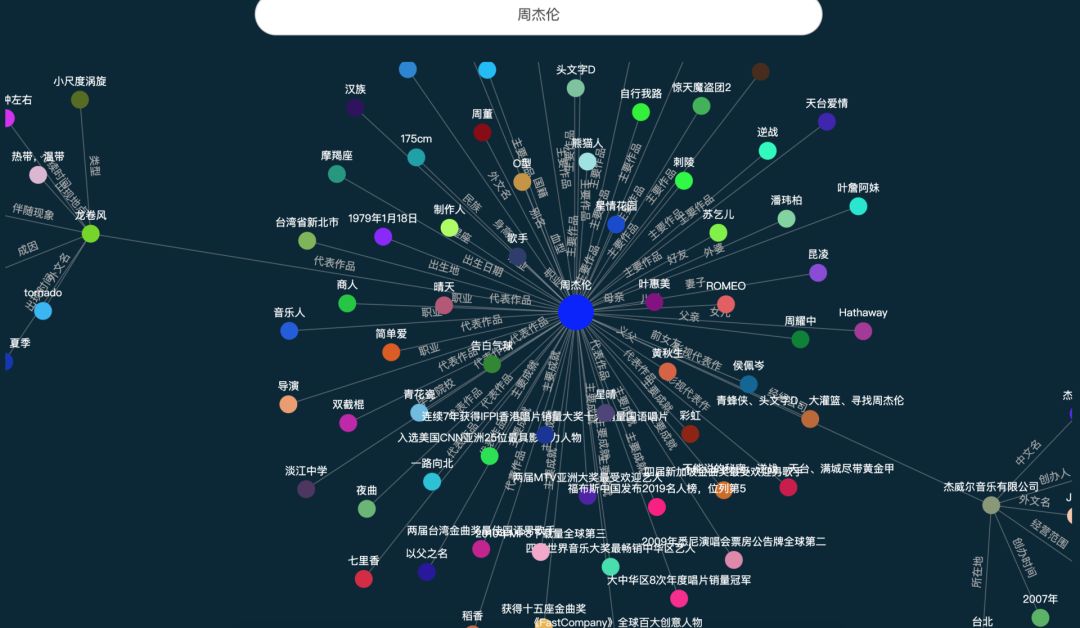
大规模1.4亿中文知识图谱数据,我把它开源了
作者 | Just出品 | AI科技大本营(ID:rgznai100)人工智能从感知阶段逐步进入认知智能的过程中,知识图谱技术将为机器提供认知思维能力和关联分析能力,可以应用于机器人问答系统、内容推荐等系统中。不过要降低知识图谱技术应用的门…

使用CSS 3创建不规则图形
2019独角兽企业重金招聘Python工程师标准>>> 前言 CSS 创建复杂图形的技术即将会被广泛支持,并且应用到实际项目中。本篇文章的目的是为大家开启它的冰山一角。我希望这篇文章能让你对不规则图形有一个初步的了解。 现在,我们已经可以使用CSS…

谷歌丰田联合成果ALBERT了解一下:新轻量版BERT,参数小18倍,性能依旧SOTA
作者 | Less Wright编译 | ronghuaiyang来源 | AI公园(ID:AI_Paradise)【导读】这是来自Google和Toyota的新NLP模型,超越Bert,参数小了18倍。你以前的NLP模型参数效率低下,而且有些过时。祝你有美好的一天。谷歌Resear…
C++中extern C的使用
C程序有时需要调用其它语言编写的函数,最常见的是调用C语言编写的函数。像所有其它名字一样,其它语言中的函数名字也必须在C中进行声明,并且该声明必须指定返回类型和形参列表。对于其它语言编写的函数来说,编译器检查…
Linux之tmpwatch命令
1、tmpwatch命令功能简介[rootvms002 /]# whatis tmpwatch tmpwatch (8) - removes files which havent been accessed for a period of... #删除一段时间内未被访问的文件tmpwatch删除最近一段时间内没有被访问的文件,时间以小时为单位,节省磁盘空间。…
你不得不知道的Visual Studio 2012(1)- 每日必用功能
2019独角兽企业重金招聘Python工程师标准>>> Visual Studio 2012已经正式发布,有很多花哨的新特性,也有很多方便使用者的新功能,当然也有负面声音。对于我们程序员,最关心的还是如何快速掌握VS2012,用于平时…
C++11中std::unique_lock的使用
std::unique_lock为锁管理模板类,是对通用mutex的封装。std::unique_lock对象以独占所有权的方式(unique owership)管理mutex对象的上锁和解锁操作,即在unique_lock对象的声明周期内,它所管理的锁对象会一直保持上锁状态;而unique…
为何Google将几十亿行源代码放在一个仓库?| CSDN博文精选
作者 | Rachel Potvin,Josh Levenberg译者 | 张建军编辑 | apddd【AI科技大本营导读】与大多数开发者的想象不同,Google只有一个代码仓库——全公司使用不同语言编写的超过10亿文件,近百TB源代码都存放在自行开发的版本管理系统Piper中&#…
小小hanoi
为什么80%的码农都做不了架构师?>>> View Code #include " iostream " using namespace std; int k 0 ; void hanoi( int m , char a , char b, char c){ if (m 1 ) { k ; printf( " %c->%c " ,a , c); return…
Unity3D心得分享
本篇文章的内容以各种tips为主,不间断更新 2019/05/10 最近更新: 使用Instantiate初始化参数去实例对象 Unity DEMO学习 Unity3D Adam Demo的学习与研究 Unity3D The Blacksmith Demo部分内容学习 Viking Village维京村落demo中的地面积水效果 Viking V…
django搭建示例-ubantu环境
python3安装--------------------------------------------------------------------------- 最新的django依赖python3,同时ubantu系统默认自带python2与python3,这里单独安装一套python3,并且不影响原来的python环境 django demo使用sqlite3,…
C++11中std::lock_guard的使用
互斥类的最重要成员函数是lock()和unlock()。在进入临界区时,执行lock()加锁操作,如果这时已经被其它线程锁住,则当前线程在此排队等待。退出临界区时,执行unlock()解锁操作。更好的办法是采用”资源分配时初始化”(RAII)方法来加…