CornerNet: 成对关键点物体检测 | CSDN博文精选

文章目录
1、论文总述
2、使用锚定框的两个缺点
3、角点检测比边界框中心或 proposals效果好的两个原因
4、corner pooling
5、用于Grouping Corners的 embedding vector的工作原理
6、正负样本的分配方式(改进的focal loss)
7、角点的offset预测
8、测试细节
9、MS COCO的使用
10、选Hourglass Network还是resnet?
11、错误分析
12、与最先进的检测器对比
参考文献
1、论文总述
本文是2018年ECCV的一篇oral,anchor free的新思路的目标检测的文章,其中2019年的几篇文章都是基于这篇paper改进的(两篇centernet cornernet_lite grid_rcnn等,后面还得看这几篇论文。。),借鉴了这个思路,即将目标检测与关键点检测(目标分割的知识)结合起来,不再采用以前流行的:先提前设定好多不同尺度和shape的anchors然后训练时候不断回归到GT。
本文思路:直接预测各个目标的左上和右下角点,然后这俩角点一组合就能框住这个目标,想法很直接,应该有很多先进的科研工作者尝试过这个想法,但为了让网络能够work,需要设计很多辅助的结构来帮助网络真的提取到各个目标的角点并分组,例如作者 为了 更好地提取角点采用沙漏网络作为backbone(论文中也有数据对比,采用resnet+fpn的话性能不如沙漏网络), 为了 更好通过物体边缘的特征来提取角点设计了corner pooling,为了 更好地将同一个目标的左上和右下角点组合到一起采用了embedding vector,为了 更好地进行难易样本的训练设计了改进版的focal loss等等吧。。
【注】:本文主要是被一篇多人姿态预测的paper启发:Associative embedding: End-to-end learning for joint detection and grouping.(后面看这篇)
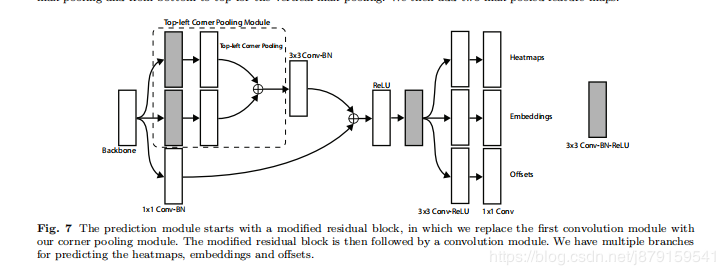
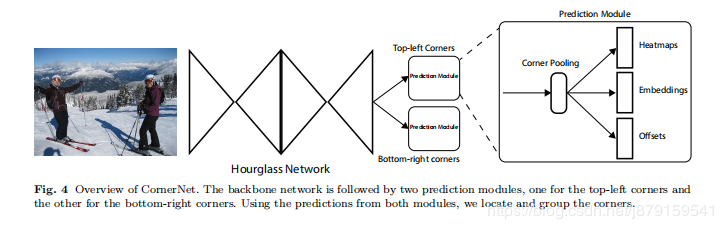
网络forward流程:根据上图,首先经过Hourglass Network backbone提取特征,通过这个backbone Feature map一般降为原图w/4 h/4,feature map尺寸一般比anchor类目标检测网络的要大,所以文中也说到,只把网络的头部加到backbone的最后一层feature map即可,并没有像ssd那样用不同级别的feature map,然后是分成两个模块(一个左上 一个右下模块)分别经过改进的残差块,这个残差块里加了 corner pooling(如上图),然后进过一系列卷积字后即分别得到两个模块的三个部分:heatmaps、embeddings和offsets。
In this paper we introduce CornerNet, a new onestage approach to object detection that does away with
anchor boxes. We detect an object as a pair of keypoints—
the top-left corner and bottom-right corner of the bounding box. We use a single convolutional network to predict a heatmap for the top-left corners of all instances
of the same object category, a heatmap for all bottomright corners, and an embedding vector for each detected corner. The embeddings serve to group a pair of
corners that belong to the same object—the network is
trained to predict similar embeddings for them.
2、使用锚定框的两个缺点
But the use of anchor boxes has two drawbacks.
First, we typically need a very large set of anchor boxes,
e.g. more than 40k in DSSD (Fu et al., 2017) and more
than 100k in RetinaNet (Lin et al., 2017). This is because the detector is trained to classify whether each
anchor box sufficiently overlaps with a ground truth
box, and a large number of anchor boxes is needed to
ensure sufficient overlap with most ground truth boxes.
As a result, only a tiny fraction of anchor boxes will
overlap with ground truth; this creates a huge imbalance between positive and negative anchor boxes and
slows down training (Lin et al., 2017).
Second, the use of anchor boxes introduces many
hyperparameters and design choices. These include how
many boxes, what sizes, and what aspect ratios. Such
choices have largely been made via ad-hoc heuristics,
and can become even more complicated when combined
with multiscale architectures where a single network
makes separate predictions at multiple resolutions, with
each scale using different features and its own set of anchor boxes (Liu et al., 2016; Fu et al., 2017; Lin et al.,
2017).
缺点1:为了覆盖各种各样的GT,需要大量的anchors,
缺点2:超参数太多,设计复杂,尤其是多尺度输入或者利用多尺度feature map时
3、角点检测比边界框中心或 proposals效果好的两个原因
First, the center of a box can be harder to localize because it depends on all 4 sides of the object,
whereas locating a corner depends on 2 sides and is thus
easier, and even more so with corner pooling, which encodes some explicit prior knowledge about the definition of corners.
Second, corners provide a more efficient way of densely discretizing the space of boxes: we just need O(wh) corners to represent O(w2h2) possible anchor boxes.
这点就比较有意思了,首先说一下作者的原话,为什么检测角点比检测中心点更好:一是角点利用两条边就能得到,中心点需要4条边得到;二是角点两个点(左上 右下)就可以编码一个框,编码效率高,而中心点需要四个数,例如densebox的相对于左上右下角点的偏移( x1 y1 x2 y2),或者Objects as Points里的相对于中心点的偏移 和 w h,即( x y w h)。
然而在2019年的工作中,发现作者的这两条假设是错的!!,就是因为角点检测利用到的目标特征比较少,只利用边缘特征就可以检测到角点,而中心点需要利用目标内部的特征,所以就导致角点检测误检率很高(这点在本论文中也有实验验证,作者发现角点检测的效果还需要很大提升),而中心点的检测反而效果比较好。
4、corner pooling
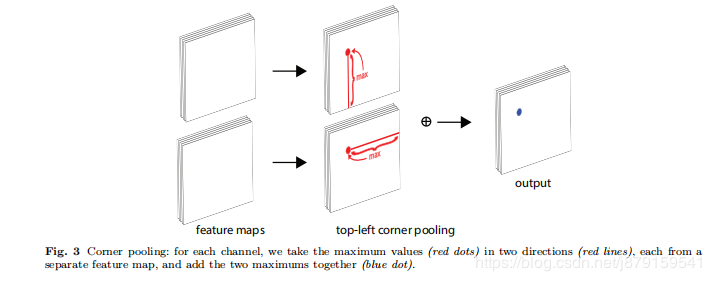
Another novel component of CornerNet is corner pooling,
a new type of pooling layer that helps a convolutional network better localize corners of bounding boxes.
A corner of a bounding box is often outside the
object—consider the case of a circle as well as the examples in Fig. 2. In such cases a corner cannot be localized based on local evidence. Instead, to determine
whether there is a top-left corner at a pixel location, we
need to look horizontally towards the right for the
topmost boundary of the object, and look vertically towards the bottom for the leftmost boundary. (以下为具体操作)
This motivates our corner pooling layer: it takes in two feature
maps; at each pixel location it max-pools all feature
vectors to the right from the first feature map, maxpools all feature vectors directly below from the second
feature map, and then adds the two pooled results together. An example is shown in Fig. 3
例子:找左上角点,该点向右看找最大值找到的是‘上’ 该点向下看找到的最大值是‘左’ 这样左上这个角点即找到了,右下这个角点同理。下图为具体例子:
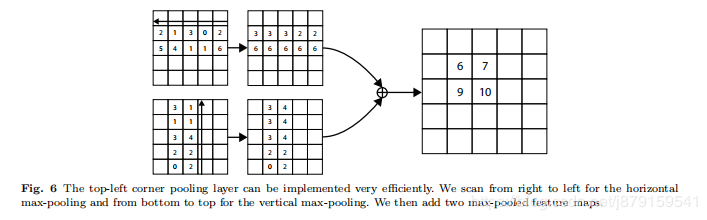
corner pooling对性能的提升:

5、用于Grouping Corners的 embedding vector的工作原理
这篇paper中对左上和右下角点的检测是分开的,就是在两个feature map上分分别检测左上和右下角点,即这张feature map上都是同类别的目标的左上角点,而另一个模块的某张feature map上都是同类别的目标的右下角点,那想组成框的话需要把同一个目标的左上和右下角点组合在一起,这就是embedding vector的作用,至于作者为什么没有在一张feature map上同时进行左上和右下角点的检测,这个不清楚,可能是参考的那篇人体姿态的论文的关系,毕竟检测人体关键点的时候,只有人一个类别,然后heatmap的channel个数为k,这个k是指人体关键点。
接下来说一下自己对embedding vector工作原理的理解:
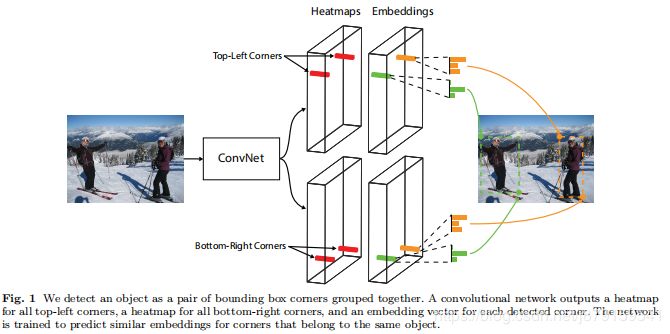
如上图所示:embeddings是根据heatmap上每个点及其周围的特征产生的一个n维向量,即每个角点都会产生一个n维的向量,这个向量编码了这个角点对应目标的信息,如果某左上角点和右下角点是同一个目标的,那对应的这两个embedding vector应该很相似,也就是这个两个向量之间的距离很小,因为他们编码的是同一个目标的信息,然后根据这种理论,不断训练网络,让embedding vector确实可以学到每对角点对应的embedding vector,而且他们之间距离很近,但不同目标的角点之间距离很大,要让网络学成这样才能效果好,
但 我自己对这个总觉得有点不靠谱,感觉让网络学成这样有点难,不同类别的embedding vector之间距离很大,这个可能还好说,但同一个类别之间的物体很相似,让他们之间的embedding vector距离很大感觉有点困难,这可能就是cornernet会误检多的原因,具体的还得去看参考的那篇人体姿态的论文,因为embedding vector出自那篇论文,这个只是我的一点猜想。
embedding vector训练时的损失函数如下:

【注】:heatmaps是C个channel,C为目标类别,同一个channel的heatmap是同一个类别的所有目标的左上角点。
6、正负样本的分配方式(改进的focal loss)
基于anchor的目标检测网络一般都是根绝anchor和GT之间的iou来定正负样本:IOU大于多少为正样本,小于多少为负样本,但由于这个网络只用检测角点,所以正样本就是各个目标GT的左上和右下角点对应的那个位置,值为1,其他位置为负样本,但这样的话,正样本太少,负样本很多,所以作者提出了一种 减小挨正样本挨得近负样本的损失,挨得越近它的值越大,但不超过1,离正样本越远(但在某个半径之内,这个半径实验中根据具体目标大小而定,而且让这对角点产生的框与GT的IOU大于某个阈值)值越小,衰减速度是用的高斯核函数,正负样本的损失函数为:

关于半径如何确定的实验验证:

7、角点的offset预测
Hence, a location (x, y) in the image is mapped to the location

in the heatmaps, where n is the downsampling factor. When we remap the locations from the
heatmaps to the input image, some precision may be
lost, which can greatly affect the IoU of small bounding
boxes with their ground truths. To address this issue we
predict location offsets to slightly adjust the corner locations before remapping them to the input resolution
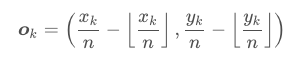
where ok is the offset, xk and yk are the x and y coordinate for corner k. In particular, we predict one set of
offsets shared by the top-left corners of all categories,
and another set shared by the bottom-right corners. For
training, we apply the smooth L1 Loss (Girshick, 2015)
at ground-truth corner locations:
注意:这个预测的角点的偏移是由于下采样导致的与原图不对应,而且对每个点只预测两个偏移,一个x的,一个y的,不分类别,应该是只有2个channel,而不是2C个channel。
损失函数为:

至此网络的总损失函数为:
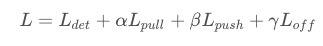
8、测试细节
During testing, we use a simple post-processing algorithm to generate bounding boxes from the heatmaps, embeddings and offsets. We first apply non-maximal
suppression (NMS) by using a 3×3 max pooling layer on
the corner heatmaps. Then we pick the top 100 top-left
and top 100 bottom-right corners from the heatmaps.
The corner locations are adjusted by the corresponding offsets. We calculate the L1 distances between the
embeddings of the top-left and bottom-right corners.
Pairs that have distances greater than 0.5 or contain
corners from different categories are rejected. The average scores of the top-left and bottom-right corners are
used as the detection scores.
Instead of resizing an image to a fixed size, we maintain the original resolution of the image and pad it with zeros before feeding it to CornerNet. Both the original
and flipped images are used for testing. We combine the
detections from the original and flipped images, and apply soft-nms (Bodla et al., 2017) to suppress redundant
detections. Only the top 100 detections are reported.
The average inference time is 244ms per image on a
Titan X (PASCAL) GPU.
测试时候流程:先分别挑出100个左上角点 和100个右下角点,然后用预测出的offset进行调整,最后根据计算 embbeding 之间的距离对角点进行分组。
9、MS COCO的使用
We evaluate CornerNet on the very challenging MS
COCO dataset (Lin et al., 2014). MS COCO contains
80k images for training, 40k for validation and 20k for
testing. All images in the training set and 35k images in
the validation set are used for training. The remaining
5k images in validation set are used for hyper-parameter
searching and ablation study.
10、选Hourglass Network还是resnet?
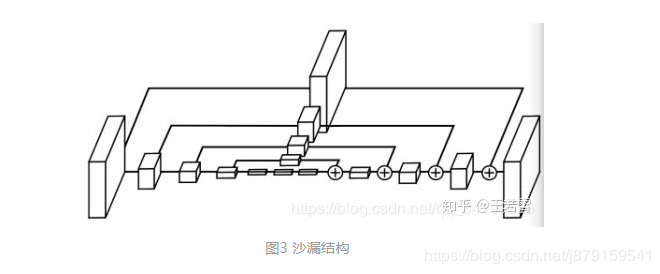

在检测关键点方面,还是沙漏网络更胜一筹。
11、错误分析
角点检测有待提升。
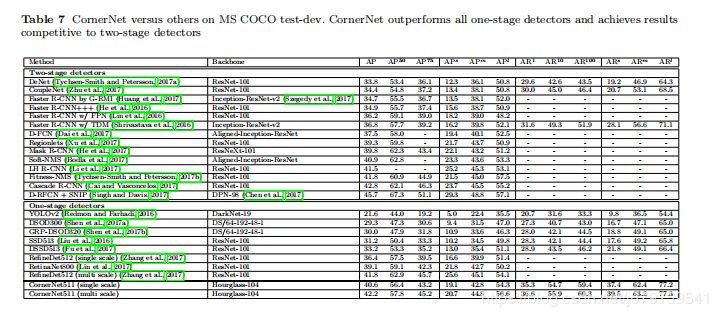
12、与最先进的检测器对比
参考文献
1、CornerNet算法解读(https://zhuanlan.zhihu.com/p/53407590)
2、CornerNet 算法笔记(https://blog.csdn.net/u014380165/article/details/83032273)
3、CornerNet:目标检测算法新思路(https://zhuanlan.zhihu.com/p/41825737)
原文链接:https://blog.csdn.net/j879159541/article/details/102522606
(*本文为 AI科技大本营转载文章,转载请联系作者)
◆
精彩推荐
◆
推荐阅读

你点的每个“在看”,我都认真当成了AI
相关文章:

PHP创建日志记录(已封装)
1 <?php2 3 class Logs{4 private $_filepath; //文件路径5 private $_filename; //文件名6 private $_filehandle; //文件引擎7 8 9 public function Logs($dir null,$filename null){ 10 11 $this->_filepath empty($dir) ? : $d…

如何用Swift实现一个好玩的弹性动画
本文由CocoaChina译者浅夏旧时光翻译自Raywenderlich 原文:How To Create an Elastic Animation with Swift 每个像样的iOS应用程序一定会有自定义元素、自定义UI以及自定义动画等等很多自定义的东西。 假如你想让你的应用脱颖而出,你必须花费一些时间为…

深入探讨Python的import机制:实现远程导入模块 | CSDN博文精选
来源 | Python编程时光(ID:Python-Time)所谓的模块导入,是指在一个模块中使用另一个模块的代码的操作,它有利于代码的复用。也许你看到这个标题,会说我怎么会发这么基础的文章?与此相反。恰恰我觉得这篇文章…

吴恩达老师深度学习视频课笔记:人脸识别
什么是人脸识别:人脸验证和人脸识别的区别,如下图:One-shot learning:人脸识别所面临的挑战就是需要解决一次学习(one-shot learning)问题。这意味着在绝大多数人脸识别应用中你需要通过单单一张图像或者单单一个人脸图像就能去识…
用小白鼠喝毒药
题设:有N瓶水,其中有一瓶水有剧毒,如果小白鼠喝了会在24小时的时候死亡。 问:用多少只小白鼠能够检测出哪瓶水有剧毒? 要求:用的小白鼠数量少并且用时要短,并给出合理的过程与结论。 我的解题思…

怎样在swift中创建CocoaPods
本文由yake_099(博客)翻译自raywenderlich,作者:Joshua Greene 原文:How to Create CocoaPods with Swift 你可能对一些比较著名的开源的CocoaPods框架比较熟悉,比如Alamofire、MBProgressHUD。但是有时你…

吴恩达老师深度学习视频课笔记:神经风格迁移(neural style transfer)
什么是神经风格迁移(neural style transfer):如下图,Content为原始拍摄的图像,Style为一种风格图像。如果用Style来重新创造Content照片,神经风格迁移可以帮你生成Generated图像。深度卷积网络在学什么:如下图…
“Jupyter的杀手”:Netflix发布新开发工具Polynote
作者 | Michael Li 译者 | Rosie 编辑 | Jane 出品 | AI科技大本营(ID:rgznai100)【导读】10 月 29 日,Netflix 公开了他们内部开发的 Polynote。现如今,大型高科技公司公开其内部的工具或服务,然后受到业界…

System Center 2012 r2优点
System Center 2012System Center2012 是一个全面的管理平台,可帮助你轻松、高效地管理数据中心、客户端设备和混合云 IT 环境。为您提供了针对私有云、托管云和公有云基础结构和应用程序服务的通用管理工具集。可按照您的需求,为生产基础架构、可预期应…
Swift 闭包表达式
闭包是功能性自包含模块,可以在代码中被传递和使用。 Swift 中的闭包与 C 和 Objective-C 中的 blocks 以及其他一些编程语言中的 lambdas 比较相似。 闭包的形式主要有三种: 1. 全局函数是一个有名字但不会捕获任何值的闭包 2. 嵌套函数是一个有名字并可以捕获其封…
GNU AWK中BEGIN/END使用举例
以下是使用gnu awk将test.cpp文件拆分成两个文件a.cpp和b.cpp,其中b.cpp仅存放test.cpp中的数据,其它内容存放在a.cpp文件中。test.cpp内容如下: #include <stdio.h> #include <iostream> #include <string>int main() {//…
目标检测的渐进域自适应,优于最新SOTA方法
作者 | Han-Kai Hsu、Chun-Han Yao、Yi-Hsuan Tsai、Wei-Chih Hung、Hung-Yu Tseng、Maneesh Singh、Ming-Hsuan Yang译者 | 刘畅编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】目标检测的最新深度学习方法依赖于大量的边界框标注信息…
讨论下IDS的绕过
自从知道dedecms自带了80sec的内置Mysqlids后,一直以来也没有想到绕过的办法。或者是自己mysql的根底太差了吧。于是分析dedecms源码时,只找模板执行,本地包含,上传等,完全没有想到注入存在的可能性了。 可以看看某牛的…
GCC编译选项参数介绍
gcc和g分别是gnu的c和c编译器,下面是整理的常用编译选项参数: #(1). -x: 设定文件所使用的语言,使文件后缀名无效,如下,执行完后生成test.o gcc -c -x c test.jpg #(2). -c: 只编译生成目标文件即*.o,只编译不链接生成…

程序员自学到底有没有用?网友们吵翻了...
最近就有个程序员吐槽说,自己大学没怎么听老师讲课,老师讲的知识要么太旧,要么老师不会讲,自己大部分时间是在网上看视频学的。引发了以下激烈的讨论。很多网友觉得,学校老师的代码能力不行,现在技术更新又…

更新 FrameWork
这里把想要改变的东西封装到FrameWork以便实现热更新,提一下关于BundiD 一定要一致,在打包的时候一定在Edit scheme —— >Run 选择Release如图: 因为你要跑在真机上,所以这个要选择Release 另外将包含你想要放出的方法类添加…

把Illustrator矢量图转化为代码:Drawscript
2019独角兽企业重金招聘Python工程师标准>>> DrawScript是一款Illustrator插件,可以将Illustrator的矢量图片转换成代码,目前免费,支持转换的语言有 OBJ-CCJAVASCRIPTCREATEJS/EASELJSPROCESSINGACTIONSCRIPT 3JSONRAW BEZIER PO…

必读:ICLR 2020 的50篇推荐阅读论文
来源 | 香侬科技本文整理了ICLR2020的相关论文,此次分享的是从Openreview中选取的部分论文,共50篇,其中大部分为NLP相关。文中涉及的相关论文推荐指数与推荐理由仅为个人观点,利益无关,亦不代表香侬科技立场。希望大家…

14个Xcode中常用的快捷键操作
在Xcode 6中有许多快捷键的设定可以使得你的编程工作更为高效,对于在代码文件中快速导航、定位Bug以及新增应用特性都是极有效的。 当然,你戳进这篇文章的目的也在于想要快速的对代码文件进行操作,或者是让Xcode的各面板更为适应你小本子的屏…
C++中标准模板库std::pair的实现
以下用C实现了标准模板库中的std::pair实现,参考了 cplusplus 和 vs2013中的utility文件。关于std::pair的介绍和用法可以参考: https://blog.csdn.net/fengbingchun/article/details/52205149 实现代码pair.hpp如下: #ifndef FBC_STL_PAIR_H…
【人在职场】能力与价值
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://yunli.blog.51cto.com/831344/1547051 最近给团队(指#UC浏览器电脑版#开发团队)分享了我的《基层技术管理原则》。…
Windows与Linux之间互传文件的方法
以下方法均是以Windows为操作机:1. 通过WinSCP:WinSCP是一款开源的SFTP客户端,运行于Windows系统下,遵照GPL发布。WinSCP除了SFTP,还支持SSH、SCP(SecureCopy Protocol)。WinSCP的开发始于2000年4月,由布拉格经济大学所…
一文读懂简化的图卷积网络GCN(SGC)| ICML 2019
作者 | yyl424525来源 | CSDN博客文章目录1 相关介绍1.1 Simple Graph Convolution (SGC)提出的背景1.2 SGC效果2 Simple Graph Convolution 简化的图卷积2.1 符号定义2.2 图卷积网络GCNGCN vs MLPFeature propagation 特征传播Feature transformation and nonlinear transitio…
iOS UITableViewCell重用问题
TableView的重用机制,为了做到显示和数据分离,iOS tableView的实现并且不是为每个数据项创建一个tableCell。而是只创建屏幕可显示最大个数的cell,然后重复使用这些cell,对cell做单独的显示配置,来达到既不影响显示效果…
NLP常用工具
为什么80%的码农都做不了架构师?>>> NLP常用工具 各种工具包的有效利用可以使研究者事半功倍。 以下是NLP版版友们提供整理的NLP研究工具包。 同时欢迎大家提供更多更好用的工具包,造福国内的NLP研究。 *NLP Toolbox CLT http://compl…
Swift快速入门之getter 和 setter
属性可以用getter和setter方法的形式提供。 <code class"hljs lasso has-numbering" style"display: block; padding: 0px; background-color: transparent; color: inherit; box-sizing: border-box; font-family: Source Code Pro, monospace;font-size:u…
Linux下getopt函数的使用
getopt为解析命令行参数函数,它是Linux C库函数。使用此函数需要包含系统头文件unistd.h。 getopt函数声明如下: int getopt(int argc, char * const argv[], const char * optstring); 其中函数的argc和argv参数通常直接从main的参数直接传递而来。o…
20行Python代码说清“量子霸权”
作者 | 马超 来源 | 程序人生(ID:coder_life)近日谷歌的有关量子霸权(Quantum Supremacy)的论文登上了Nature杂志150年刊的封面位置,而再次罢占各大媒体的头条位置,其实这篇文章之前曾经短暂上过NASA的网站…

Android组件系列----BroadcastReceiver广播接收器
【声明】 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/3960623.html 【正文】 一、广播的功能和特征 广播的生命周期很短,经过调用对象-->…

Swift 代码调试-善用XCode工具(UI调试,五种断点,预览UIImage...)
原创Blog,转载请注明出处 http://blog.csdn.net/hello_hwc?viewmodelist 我的stackoverflow 工欲善其事,必先利其器,强烈建议新手同学好好研究下XCode这个工具。比如Build Settings,Build Info Rules,Build Parse…