MXNet中依赖库介绍及简单使用
MXNet是一种开源的深度学习框架,核心代码是由C++实现,在编译源码的过程中,它需要依赖其它几种开源库,这里对MXNet依赖的开源库进行简单的说明:
1. OpenBLAS:全称为Open Basic Linear Algebra Subprograms,是开源的基本线性代数子程序库,是一个优化的高性能多核BLAS库,主要包括矩阵与矩阵、矩阵与向量、向量与向量等操作。它的License是BSD-3-Clause,可以商用,目前最新的发布版本是0.3.3。它的源码放在GitHub上,由张先轶老师等持续维护。
OpenBLAS是由中科院软件所并行软件与计算科学实验室发起的基于GotoBLAS2 1.13 BSD版的开源BLAS库高性能实现。
BLAS是一个应用程序接口(API)标准,用以规范发布基础线性代数操作的数值库(如矢量或矩阵乘法)。该程序集最初发布于1979年,并用于建立更大的数值程序包(如LAPACK)。在高性能计算领域,BLAS被广泛使用。
测试代码如下(openblas_test.cpp):
#include "openblas_test.hpp"
#include <iostream>
#include <cblas.h>int test_openblas_1()
{int th_model = openblas_get_parallel();switch (th_model) {case OPENBLAS_SEQUENTIAL:printf("OpenBLAS is compiled sequentially.\n");break;case OPENBLAS_THREAD:printf("OpenBLAS is compiled using the normal threading model\n");break;case OPENBLAS_OPENMP:printf("OpenBLAS is compiled using OpenMP\n");break;}int n = 2;double* x = (double*)malloc(n*sizeof(double));double* upperTriangleResult = (double*)malloc(n*(n + 1)*sizeof(double) / 2);for (int j = 0; j<n*(n + 1) / 2; j++)upperTriangleResult[j] = 0;x[0] = 1; x[1] = 3;cblas_dspr(CblasRowMajor, CblasUpper, n, 1, x, 1, upperTriangleResult);double*& A = upperTriangleResult;std::cout << A[0] << "\t" << A[1] << std::endl << "*\t" << A[2] << std::endl;free(upperTriangleResult);free(x);return 0;
}
执行结果如下:

2. DLPack:仅有一个头文件dlpack.h。DLPack是一种开放的内存张量(tensor)结构,用于在不同框架之间共享张量,如Tensorflow, PyTorch, NXNet,不发生任何数据复制或拷贝。
dlpack.h文件中包括两个枚举类型,四个结构体:
枚举类型DLDeviceType:支持的设备类型包括CPU、CUDA GPU、OpenCL、Apple GPU、AMD GPU等。
枚举类型DLDataTypeCode:支持的数据类型包括有符号int、无符号int、float。
结构体DLContext:A Device context for Tensor and operator,数据成员包括设备类型和设备id。
结构体DLDataType:tensor支持的数据类型,数据成员包括code基本类型,值必须为DLDataTypeCode支持的;位数(bits)可以是8,16,32;类型的lanes数。
结构体DLTensor:tensor对象,不管理内存。数据成员包括数据指针(void*)、DLContext、维数、DLDataType、tensor的shape、tensor的stride、数据开始指针的字节偏移量。
结构体DLManagedTensor:管理DLTensor内存。
3. MShadow:全称Matrix Shadow,用C++/CUDA实现的轻量级的CPU/GPU矩阵和tensor模板库。它的文件全部为.h或.cuh,使用时直接include即可。注意:如果在工程属性预处理器定义中没有加入MSHADOW_STAND_ALONE,则需要包括额外的CBLAS或MKL或CUDA的支持。如果不依赖其它库,定义MSHADOW_STAND_ALONE,则会导致有些函数没有实现,如dot_engine-inl.h中,函数体中会包括语句:LOG(FATAL) << “Not implemented!”;
这里为了测试不开启MSHADOW_STAND_ALONE宏,仅开启MSHADOW_USE_CBLAS宏。
测试代码如下(mshadow_test.cpp):
#include "mshadow_test.hpp"
#include <iostream>
#include <cmath>
#include "mshadow/tensor.h"// reference: mshadow source code: mshadow/guideint test_mshadow_1()
{// intialize tensor engine before using tensor operationmshadow::InitTensorEngine<mshadow::cpu>();// assume we have a float spacefloat data[20];// create a 2 x 5 x 2 tensor, from existing spacemshadow::Tensor<mshadow::cpu, 3> ts(data, mshadow::Shape3(2, 5, 2));// take first subscript of the tensormshadow::Tensor<mshadow::cpu, 2> mat = ts[0];// Tensor object is only a handle, assignment means they have same data content// we can specify content type of a Tensor, if not specified, it is float bydefaultmshadow::Tensor<mshadow::cpu, 2, float> mat2 = mat;mat = mshadow::Tensor<mshadow::cpu, 1>(data, mshadow::Shape1(10)).FlatTo2D();// shaape of matrix, note size order is same as numpyfprintf(stdout, "%u X %u matrix\n", mat.size(0), mat.size(1));// initialize all element to zeromat = 0.0f;// assign some valuesmat[0][1] = 1.0f; mat[1][0] = 2.0f;// elementwise operationsmat += (mat + 10.0f) / 10.0f + 2.0f;// print out matrix, note: mat2 and mat1 are handles(pointers)for (mshadow::index_t i = 0; i < mat.size(0); ++i) {for (mshadow::index_t j = 0; j < mat.size(1); ++j) {fprintf(stdout, "%.2f ", mat2[i][j]);}fprintf(stdout, "\n");}mshadow::TensorContainer<mshadow::cpu, 2> lhs(mshadow::Shape2(2, 3)), rhs(mshadow::Shape2(2, 3)), ret(mshadow::Shape2(2, 2));lhs = 1.0;rhs = 1.0;ret = mshadow::expr::implicit_dot(lhs, rhs.T());mshadow::VectorDot(ret[0].Slice(0, 1), lhs[0], rhs[0]);fprintf(stdout, "vdot=%f\n", ret[0][0]);int cnt = 0;for (mshadow::index_t i = 0; i < ret.size(0); ++i) {for (mshadow::index_t j = 0; j < ret.size(1); ++j) {fprintf(stdout, "%.2f ", ret[i][j]);}fprintf(stdout, "\n");}fprintf(stdout, "\n");for (mshadow::index_t i = 0; i < lhs.size(0); ++i) {for (mshadow::index_t j = 0; j < lhs.size(1); ++j) {lhs[i][j] = cnt++;fprintf(stdout, "%.2f ", lhs[i][j]);}fprintf(stdout, "\n");}fprintf(stdout, "\n");mshadow::TensorContainer<mshadow::cpu, 1> index(mshadow::Shape1(2)), choosed(mshadow::Shape1(2));index[0] = 1; index[1] = 2;choosed = mshadow::expr::mat_choose_row_element(lhs, index);for (mshadow::index_t i = 0; i < choosed.size(0); ++i) {fprintf(stdout, "%.2f ", choosed[i]);}fprintf(stdout, "\n");mshadow::TensorContainer<mshadow::cpu, 2> recover_lhs(mshadow::Shape2(2, 3)), small_mat(mshadow::Shape2(2, 3));small_mat = -100.0f;recover_lhs = mshadow::expr::mat_fill_row_element(small_mat, choosed, index);for (mshadow::index_t i = 0; i < recover_lhs.size(0); ++i) {for (mshadow::index_t j = 0; j < recover_lhs.size(1); ++j) {fprintf(stdout, "%.2f ", recover_lhs[i][j] - lhs[i][j]);}}fprintf(stdout, "\n");rhs = mshadow::expr::one_hot_encode(index, 3);for (mshadow::index_t i = 0; i < lhs.size(0); ++i) {for (mshadow::index_t j = 0; j < lhs.size(1); ++j) {fprintf(stdout, "%.2f ", rhs[i][j]);}fprintf(stdout, "\n");}fprintf(stdout, "\n");mshadow::TensorContainer<mshadow::cpu, 1> idx(mshadow::Shape1(3));idx[0] = 8;idx[1] = 0;idx[2] = 1;mshadow::TensorContainer<mshadow::cpu, 2> weight(mshadow::Shape2(10, 5));mshadow::TensorContainer<mshadow::cpu, 2> embed(mshadow::Shape2(3, 5));for (mshadow::index_t i = 0; i < weight.size(0); ++i) {for (mshadow::index_t j = 0; j < weight.size(1); ++j) {weight[i][j] = i;}}embed = mshadow::expr::take(idx, weight);for (mshadow::index_t i = 0; i < embed.size(0); ++i) {for (mshadow::index_t j = 0; j < embed.size(1); ++j) {fprintf(stdout, "%.2f ", embed[i][j]);}fprintf(stdout, "\n");}fprintf(stdout, "\n\n");weight = mshadow::expr::take_grad(idx, embed, 10);for (mshadow::index_t i = 0; i < weight.size(0); ++i) {for (mshadow::index_t j = 0; j < weight.size(1); ++j) {fprintf(stdout, "%.2f ", weight[i][j]);}fprintf(stdout, "\n");}fprintf(stdout, "upsampling\n");#ifdef small
#undef small
#endifmshadow::TensorContainer<mshadow::cpu, 2> small(mshadow::Shape2(2, 2));small[0][0] = 1.0f;small[0][1] = 2.0f;small[1][0] = 3.0f;small[1][1] = 4.0f;mshadow::TensorContainer<mshadow::cpu, 2> large(mshadow::Shape2(6, 6));large = mshadow::expr::upsampling_nearest(small, 3);for (mshadow::index_t i = 0; i < large.size(0); ++i) {for (mshadow::index_t j = 0; j < large.size(1); ++j) {fprintf(stdout, "%.2f ", large[i][j]);}fprintf(stdout, "\n");}small = mshadow::expr::pool<mshadow::red::sum>(large, small.shape_, 3, 3, 3, 3);// shutdown tensor enigne after usagefor (mshadow::index_t i = 0; i < small.size(0); ++i) {for (mshadow::index_t j = 0; j < small.size(1); ++j) {fprintf(stdout, "%.2f ", small[i][j]);}fprintf(stdout, "\n");}fprintf(stdout, "mask\n");mshadow::TensorContainer<mshadow::cpu, 2> mask_data(mshadow::Shape2(6, 8));mshadow::TensorContainer<mshadow::cpu, 2> mask_out(mshadow::Shape2(6, 8));mshadow::TensorContainer<mshadow::cpu, 1> mask_src(mshadow::Shape1(6));mask_data = 1.0f;for (int i = 0; i < 6; ++i) {mask_src[i] = static_cast<float>(i);}mask_out = mshadow::expr::mask(mask_src, mask_data);for (mshadow::index_t i = 0; i < mask_out.size(0); ++i) {for (mshadow::index_t j = 0; j < mask_out.size(1); ++j) {fprintf(stdout, "%.2f ", mask_out[i][j]);}fprintf(stdout, "\n");}mshadow::ShutdownTensorEngine<mshadow::cpu>();return 0;
}// user defined unary operator addone
struct addone {// map can be template functiontemplate<typename DType>MSHADOW_XINLINE static DType Map(DType a) {return a + static_cast<DType>(1);}
};
// user defined binary operator max of two
struct maxoftwo {// map can also be normal functions,// however, this can only be applied to float tensorMSHADOW_XINLINE static float Map(float a, float b) {if (a > b) return a;else return b;}
};int test_mshadow_2()
{// intialize tensor engine before using tensor operation, needed for CuBLASmshadow::InitTensorEngine<mshadow::cpu>();// take first subscript of the tensormshadow::Stream<mshadow::cpu> *stream_ = mshadow::NewStream<mshadow::cpu>(0);mshadow::Tensor<mshadow::cpu, 2, float> mat = mshadow::NewTensor<mshadow::cpu>(mshadow::Shape2(2, 3), 0.0f, stream_);mshadow::Tensor<mshadow::cpu, 2, float> mat2 = mshadow::NewTensor<mshadow::cpu>(mshadow::Shape2(2, 3), 0.0f, stream_);mat[0][0] = -2.0f;mat = mshadow::expr::F<maxoftwo>(mshadow::expr::F<addone>(mat) + 0.5f, mat2);for (mshadow::index_t i = 0; i < mat.size(0); ++i) {for (mshadow::index_t j = 0; j < mat.size(1); ++j) {fprintf(stdout, "%.2f ", mat[i][j]);}fprintf(stdout, "\n");}mshadow::FreeSpace(&mat); mshadow::FreeSpace(&mat2);mshadow::DeleteStream(stream_);// shutdown tensor enigne after usagemshadow::ShutdownTensorEngine<mshadow::cpu>();return 0;
}
其中test_mshadow_2的执行结果如下:
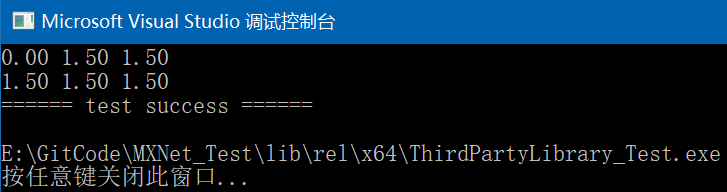
4. DMLC-Core:全称Distributed Machine Learning Common Codebase,它是支持所有DMLC项目的基础模块,用于构建高效且可扩展的分布式机器学习通用库。
测试代码如下(dmlc_test.cpp):
#include "dmlc_test.hpp"
#include <iostream>
#include <cstdio>
#include <functional>
#include <dmlc/parameter.h>
#include <dmlc/registry.h>// reference: dmlc-core/example and dmlc-core/teststruct MyParam : public dmlc::Parameter<MyParam> {float learning_rate;int num_hidden;int activation;std::string name;// declare parameters in header fileDMLC_DECLARE_PARAMETER(MyParam) {DMLC_DECLARE_FIELD(num_hidden).set_range(0, 1000).describe("Number of hidden unit in the fully connected layer.");DMLC_DECLARE_FIELD(learning_rate).set_default(0.01f).describe("Learning rate of SGD optimization.");DMLC_DECLARE_FIELD(activation).add_enum("relu", 1).add_enum("sigmoid", 2).describe("Activation function type.");DMLC_DECLARE_FIELD(name).set_default("mnet").describe("Name of the net.");// user can also set nhidden besides num_hiddenDMLC_DECLARE_ALIAS(num_hidden, nhidden);DMLC_DECLARE_ALIAS(activation, act);}
};// register it in cc file
DMLC_REGISTER_PARAMETER(MyParam);int test_dmlc_parameter()
{int argc = 4;char* argv[4] = {
#ifdef _DEBUG"E:/GitCode/MXNet_Test/lib/dbg/x64/ThirdPartyLibrary_Test.exe",
#else"E:/GitCode/MXNet_Test/lib/rel/x64/ThirdPartyLibrary_Test.exe",
#endif"num_hidden=100","name=aaa","activation=relu"};MyParam param;std::map<std::string, std::string> kwargs;for (int i = 0; i < argc; ++i) {char name[256], val[256];if (sscanf(argv[i], "%[^=]=%[^\n]", name, val) == 2) {kwargs[name] = val;}}fprintf(stdout, "Docstring\n---------\n%s", MyParam::__DOC__().c_str());fprintf(stdout, "start to set parameters ...\n");param.Init(kwargs);fprintf(stdout, "-----\n");fprintf(stdout, "param.num_hidden=%d\n", param.num_hidden);fprintf(stdout, "param.learning_rate=%f\n", param.learning_rate);fprintf(stdout, "param.name=%s\n", param.name.c_str());fprintf(stdout, "param.activation=%d\n", param.activation);return 0;
}namespace tree {struct Tree {virtual void Print() = 0;virtual ~Tree() {}};struct BinaryTree : public Tree {virtual void Print() {printf("I am binary tree\n");}};struct AVLTree : public Tree {virtual void Print() {printf("I am AVL tree\n");}};// registry to get the treesstruct TreeFactory: public dmlc::FunctionRegEntryBase<TreeFactory, std::function<Tree*()> > {};#define REGISTER_TREE(Name) \DMLC_REGISTRY_REGISTER(::tree::TreeFactory, TreeFactory, Name) \.set_body([]() { return new Name(); } )DMLC_REGISTRY_FILE_TAG(my_tree);} // namespace tree// usually this sits on a seperate file
namespace dmlc {DMLC_REGISTRY_ENABLE(tree::TreeFactory);
}namespace tree {// Register the trees, can be in seperate filesREGISTER_TREE(BinaryTree).describe("This is a binary tree.");REGISTER_TREE(AVLTree);DMLC_REGISTRY_LINK_TAG(my_tree);
}int test_dmlc_registry()
{// construct a binary treetree::Tree *binary = dmlc::Registry<tree::TreeFactory>::Find("BinaryTree")->body();binary->Print();// construct a binary treetree::Tree *avl = dmlc::Registry<tree::TreeFactory>::Find("AVLTree")->body();avl->Print();delete binary;delete avl;return 0;
}其中test_dmlc_parameter的执行结果如下:
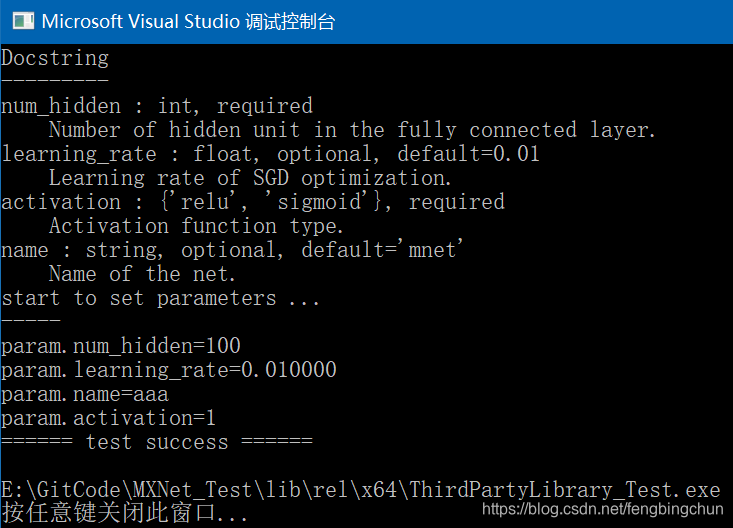
5. TVM:深度学习系统的编译器堆栈(compiler stack)。它旨在缩小深度学习框架与以性能、效率为重点的硬件后端之间的差距。它与深度学习框架协同工作,为不同的后端提供端到端的编译。TVM除了依赖dlpack、dmlc-core外,还依赖HalideIR。而且编译TVM时,一大堆C2440、C2664错误,即无法从一种类型转换为另一种类型的错误。因为在编译MXNet源码时,目前MXNet仅需要tvm源码nnvm/src下的c_api, core, pass三个目录的文件参与编译,因此后面再调试TVM库。
6. OpenCV:可选的,编译过程可参考: https://blog.csdn.net/fengbingchun/article/details/84030309
7. CUDA和cudnn:可选的,编译过程可参考:https://blog.csdn.net/fengbingchun/article/details/53892997
GitHub: https://github.com/fengbingchun/MXNet_Test
相关文章:

Python十大装腔语法
作者 | 许向武 责编 | 郭芮 来源 | CSDN 博客Python 是一种代表简单思想的语言,其语法相对简单,很容易上手。不过,如果就此小视 Python 语法的精妙和深邃,那就大错特错了。本文精心筛选了最能展现 Python 语法之精妙的十个知识点&…

MATLAB——scatter的简单应用
scatter可用于描绘散点图。 1.scatter(X,Y) X和Y是数据向量,以X中数据为横坐标,以Y中数据位纵坐标描绘散点图,点的形状默认使用圈。 样例: X [1:10]; Y X rand(size(X)); scatter(X, Y) 得到: 2.scatter(...,fill…

Windows10上使用VS2017编译MXNet源码操作步骤(C++)
MXNet是一种开源的深度学习框架,核心代码是由C实现。MXNet官网推荐使用VS2015或VS2017编译,因为源码中使用了一些C14的特性,VS2013是不支持的。这里通过VS2017编译,步骤如下: 1. 编译OpenCV,版本为3.4.2&a…

StoryBoard 视图切换和传值
一 于StoryBoard相关的类、方法和属性 1 UIStoryboard // 根据StoryBoard名字获取StoryBoard (UIStoryboard *)storyboardWithName:(NSString *)name bundle:(nullable NSBundle *)storyboardBundleOrNil;// 获取指定StoryBoard的第一个视图控制器- (nullable __kindof UIViewC…

率清华团队研发“天机芯”登《Nature》封面,他说类脑计算是发展人工通用智能的基石...
整理 | AI科技大本营(ID:rgznai100)8 月,清华大学教授、类脑计算研究中心主任施路平率队研发的关于“天机芯”的论文登上《Nature》封面,这实现了中国在芯片和人工智能两大领域登上该杂志论文零的突破,引发国内外业界一…

IntelliJ IDEA 12详细开发教程(四) 搭建Android应用开发环境与Android项目创建
今天我要给大家讲的是使用Intellij Idea开发Android应用开发。自我感觉使用Idea来进行Android开发要比在Eclipse下开发简单很多。(一)打开网站:http://developer.android.com/sdk/index.html。从网站上下载SDK下载需要的Android版本ÿ…

Git环境搭建及简单的本地、远程 两库关联
这里讲下我从拿到新的Mac后怎么一步一步搭建Git环境的。 首先让我们打开终端 在终端输入 git 如果说你卡到下面的结果说明你没有安装个git,去安装。 The program git is currently not installed. You can install it by typing: sudo apt-get install git 如果你…

提高C++性能的编程技术笔记:内联+测试代码
内联类似于宏,在调用方法内部展开被调用方法,以此来代替方法的调用。一般来说表达内联意图的方式有两种:一种是在定义方法时添加内联保留字的前缀;另一种是在类的头部声明中定义方法。 虽然内联方法的调用方式和普通方法相同&…

python学习——01循环控制
系统登录:要求输入用户名,判断用户是否存在,若存在,则输入密码,密码正确后登录系统;用户不存在则重新输入用户。密码输错三次后,用户被锁定。#!/usr/bin/env python #codingutf-8 user_dic {pe…
swift 中showAlertTitle的使用
不比比 直接上代码 import UIKit class InAndOutViewController: UIViewController,UITextFieldDelegate { let API_selectExitEntryInfo : String "/app/projectAndIdCardQuery_selectBanJianInfo" //输入框 IBOutlet weak var InputTextField: UITextField! //查…
从一张风景照中就学会的SinGAN模型,究竟是什么神操作?| ICCV 2019最佳论文
作者 | 王红成,中国海洋大学-信息科学与工程学院-计算机技术-计算机视觉方向研究生,研二在读,目前专注于生成对抗网络的研究编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导读】10 月 27 日-11 月 2 日&…
Windows10上编译MXNet源码操作步骤(Python)
1. 按照https://blog.csdn.net/fengbingchun/article/details/84997490 中操作步骤首先在Windows上通过VS2017编译MXNet源代码; 2. 从 https://mxnet.incubator.apache.org/install/windows_setup.html#install-the-mxnet-package-for-python 下载mingw64_dll.zi…
LeetCode:144_Binary Tree Preorder Traversal | 二叉树的前序遍历 | Medium
题目:Binary Tree Preorder Traversal 二叉树的前序遍历,同样使用栈来解,代码如下: 1 struct TreeNode {2 int val;3 TreeNode* left;4 TreeNode* right;5 TreeNode(int x): val(x), left(NULL)…

swift (Singleton)模式
一不安全的单例实现在上一篇文章我们给出了单例的设计模式,直接给出了线程安全的实现方法。单例的实现有多种方法,如下面:?123456789101112class SwiftSingleton { class var shared: SwiftSingleton { if !Inner.instance { Inner.insta…
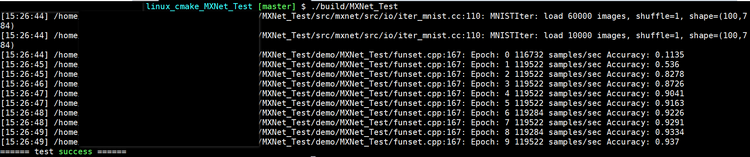
Ubuntu 14.04上使用CMake编译MXNet源码操作步骤(C++)
MXNet源码版本号为1.3.0,其它依赖库的版本号可参考:https://blog.csdn.net/fengbingchun/article/details/84997490 build.sh脚本内容为: #! /bin/bashreal_path$(realpath $0) dir_namedirname "${real_path}" echo "real_…

十年公务员转行IT,自学AI三年,他淬炼出746页机器学习入门笔记
整理 | Jane 编辑 | Just 出品 | AI科技大本营(ID:rgznai100)近期,梁劲传来该笔记重大更新的消息。《机器学习——从入门到放弃》这本笔记的更新没有停止,在基于上一版的基础上丰富了近 200 页计算机视觉领域的知识内容…

Python实现五子棋人机对战 | CSDN博文精选
作者 | 吴小鹏 来源 | 数据札记倌(ID:Data_Groom)五子棋是常见的一款小游戏,五子棋问题是人工智能中的一个经典问题。这篇文章主要介绍了Python版本五子棋的实现代码,大家可以做个参考,与我的傻儿子对弈一下。简 述虽…
HTTPS协议简介
HTTPS(HyperText Transfer Protocol Secure, 超文本传输安全协议):是一种透过计算机网络进行安全通信的传输协议。HTTPS经由HTTP进行通信,但利用SSL/TLS来加密数据包。HTTPS开发的主要目的,是提供对网站服务器的身份认证,保护交换…

闭包回调的写法
初学swift,封装了NSURLSession的get请求,在请求成功闭包回调的时候程序崩溃了 然后在图中1,2,3位置加上惊叹号“!”,再把4,5,6的惊叹号去掉就闭包回调成功了
错误 1 “System.Data.DataRow.DataRow(System.Data.DataRowBuilder)”不可访问,因为它受保护级别限制...
new DataRow 的方式: DataTable pDataTable new DataTable();DataRow pRow new DataRow(); 正确的方式: DataRow pRowpDataTable.newRow(); 转载于:https://www.cnblogs.com/wangzianan/p/4034892.html

iOS 支付 [支付宝、银联、微信]
这是开头语 前不久做了一个项目,涉及到支付宝和银联支付,支付宝和银联都是业界的老大哥,文档、SDK都是很屌,屌的找不到,屌的看不懂,屌到没朋友(吐槽而已),本文将涉及到的…
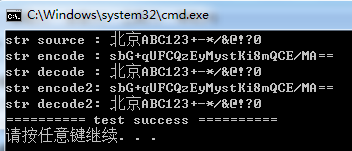
base64开源库介绍及使用
网上有一些开源的base64编解码库的实现,下面介绍几个: cppcodec是一个仅包括头文件的C11库,用于编解码RFC 4648中指定的base64, base64url, base32, base32hex等,它的License为MIT,源码在https://github.com/tplgy/cp…
情感识别难?图神经网络创新方法大幅提高性能
作者 | Kevin Shen译者 | Monanfei出品 | AI科技大本营(ID: rgznai100)【导读】最近,深度学习在自然语言处理领域(NLP)取得了很大的进步。随着诸如 Attention 和 Transformers 之类新发明的出现,BERT 和 XL…
Java的学习之路(1)
学过C语言之后,尝试接触Java. 借博文来记录自己学习的过程. Test01:利用循环,输出整数1-999之和 1 //2 //循环计算1到999的整数之和并输出3 //4 package demo;5 6 public class Main {7 8 public static void main(String[] args) {9 int su…

Swift - 使用addSubview()方法将StoryBoard中的视图加载进来
使用 Storyboard 我们可以很方便地搭建好各种复杂的页面,同时通过 segue 连接可以轻松实现页面的跳转。但除了segue,我们还可以使用纯代码的方式实现Storyboard界面的跳转。 比如:使用 presentViewController() 方法将当前页面视图切换成新视…

这项技术厉害了!让旅行者 2 号从星际空间发首批数据!
立即购票:https://dwz.cn/z1jHouwE物联网作为信息系统向物理世界的延伸,极大地拓展了人类认知和控制物理世界的能力,被称为继计算机和互联网之后的世界信息产业的第三次浪潮,正在深刻地改变着人类的生存环境和生活方式。据最新报道…
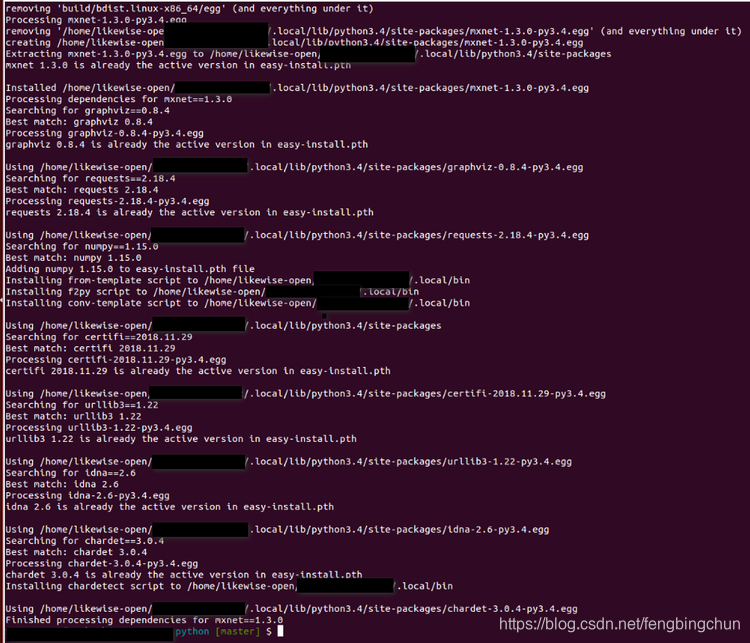
Ubuntu 14.04上使用CMake编译MXNet源码操作步骤(Python)
MXNet源码版本号为1.3.0,其它依赖库的版本号可参考:https://blog.csdn.net/fengbingchun/article/details/84997490 。 为了通过编译源码支持python接口,这里在 https://blog.csdn.net/fengbingchun/article/details/85162936 的基础上对bui…
近段时间学习html和CSS的一些细碎总结
1、边框圆角属性:border-radius,取值能够是 百分比 / 自己定义长度,不能够取负值。假设是圆,将高度和宽度设置相等,而且将border-radius设置为100% 2、IE6,IE7,IE8,opera,…

Swift:闭包
[objc] view plaincopy print?/* 闭包(Closures) * 闭包是自包含的功能代码块,可以在代码中使用或者用来作为参数传值。 * 在Swift中的闭包与C、OC中的blocks和其它编程语言(如Python)中的lambdas类似。 * 闭包…