情感识别难?图神经网络创新方法大幅提高性能

作者 | Kevin Shen
译者 | Monanfei
出品 | AI科技大本营(ID: rgznai100)
【导读】最近,深度学习在自然语言处理领域(NLP)取得了很大的进步。随着诸如 Attention 和 Transformers 之类新发明的出现,BERT 和 XLNet 一次次取得进步,使得文本情感识别之类的等任务变得更加容易。本文将介绍一种新的方法,该方法使用图模型在对话中进行情感识别。
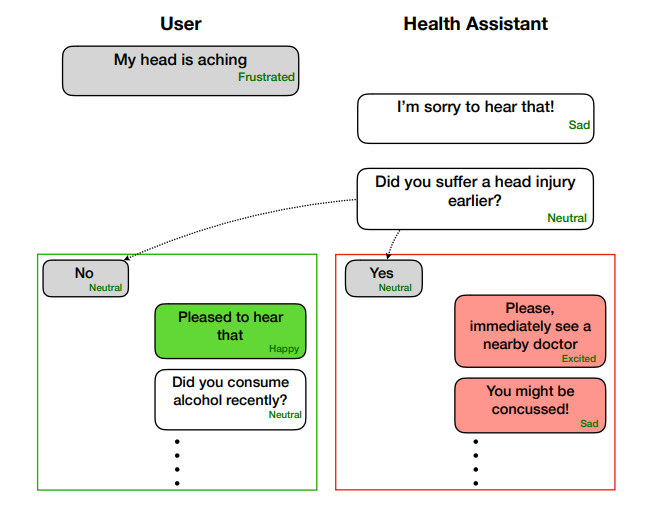
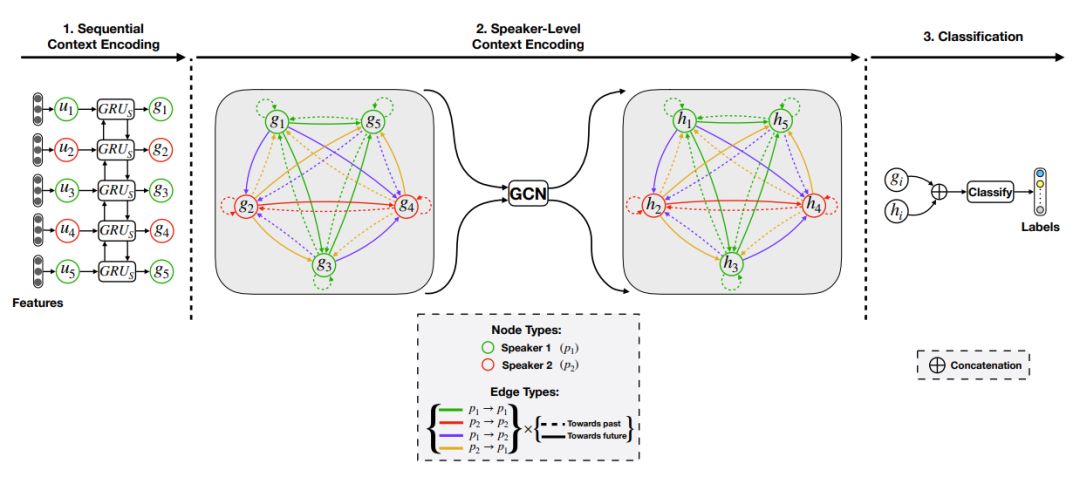
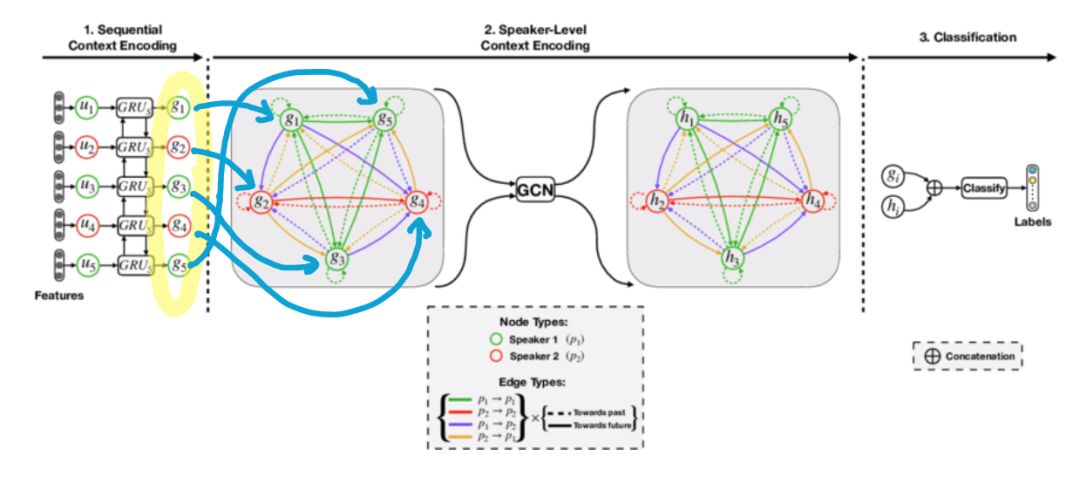
- 序列的上下文:序列中句子的含义。该上下文处理过去的单词如何影响未来的单词、单词的关系以及语义/句法特征。RNN 模型考虑了序列的上下文。
- 说话者级别的上下文:说话者相互以及自身的依赖性。这种情况涉及说话者之间的关系以及自我依赖性:自己的个性会改变并影响你在谈话过程中的说话方式。
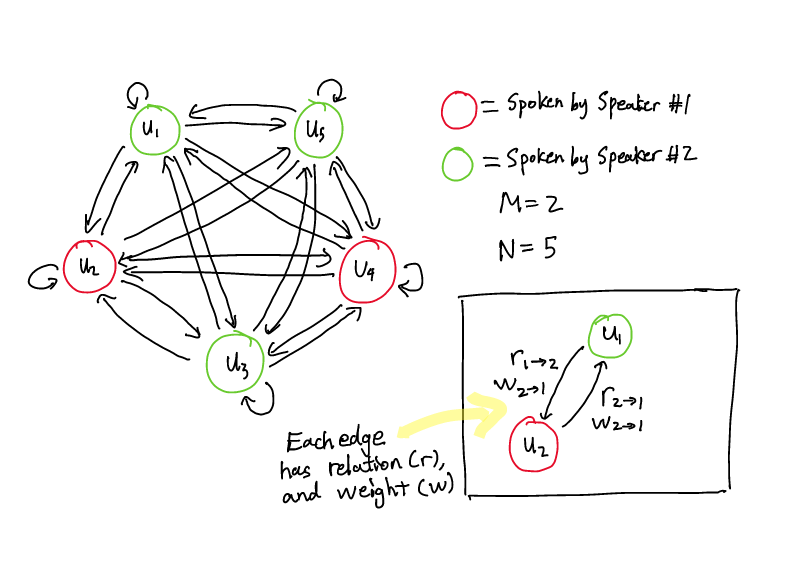
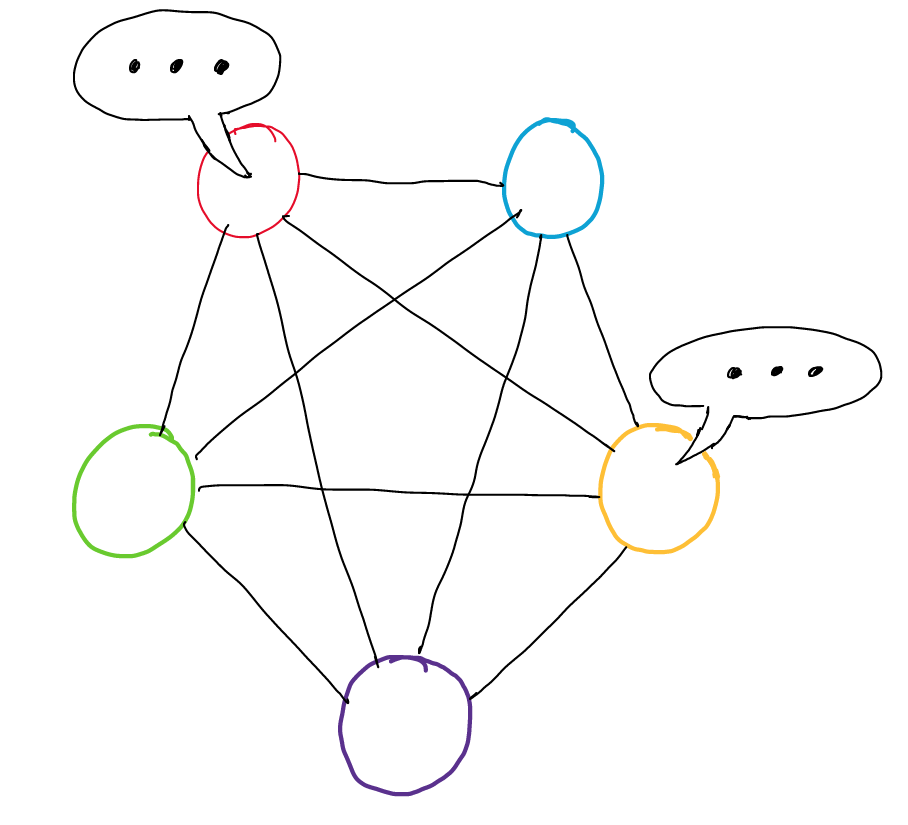
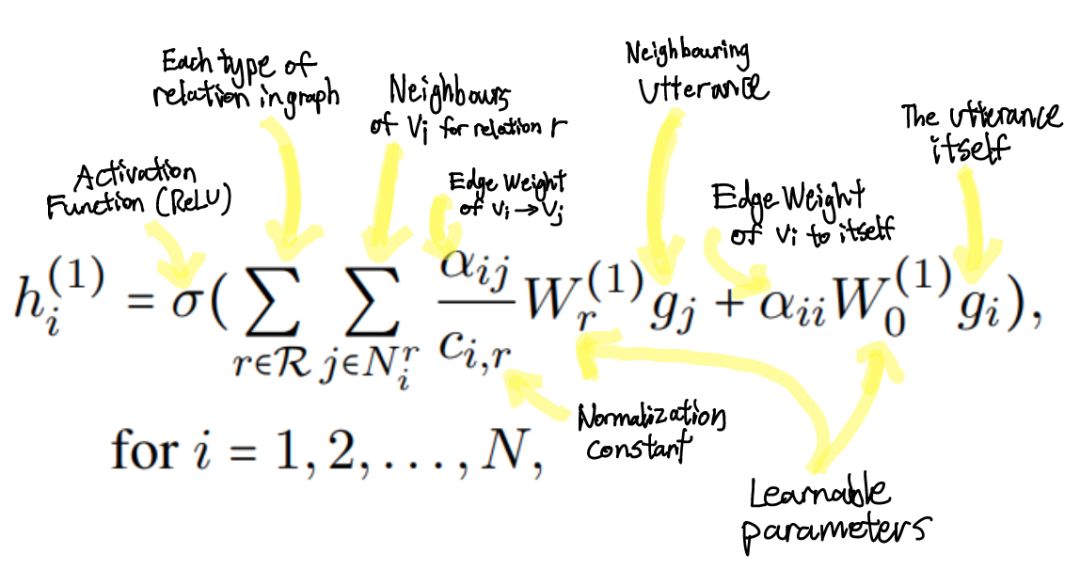
- 语段作为节点(V)。边(E)是节点之间的路径/连接。关系(R)是边的不同类型/标签。边权值(W)代表边的重要性。
- 两个节点 v[i] 和 v[j] 之间的每个边都有两个属性:关系(r)和权重(w)。
- 该图是有向的。因此,所有边都是独特的路径。从v[i] 到 v[j] 的边不同于从 v[j] 到 v[i] 的边。
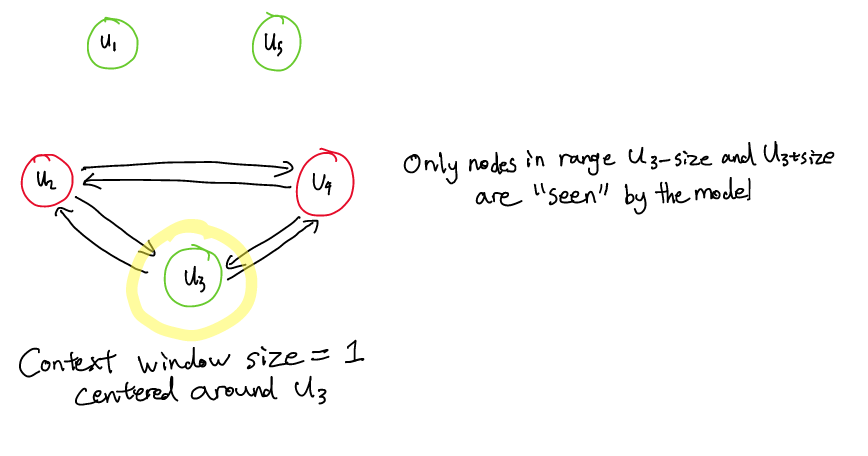
- 说话者依赖性:谁说过 u[i]?谁说 v[j]?
- 时间依赖性:u[i] 是在 u[j] 之前发出的,还是之后?
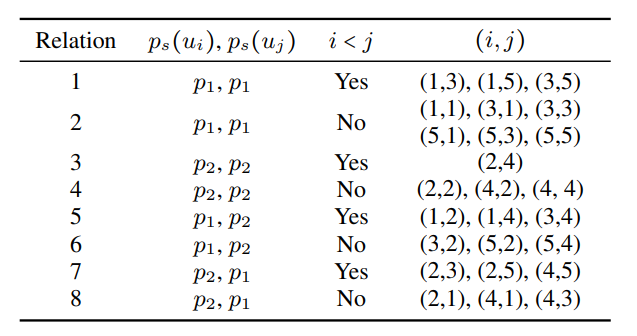 例子中所有可能的关系列表
例子中所有可能的关系列表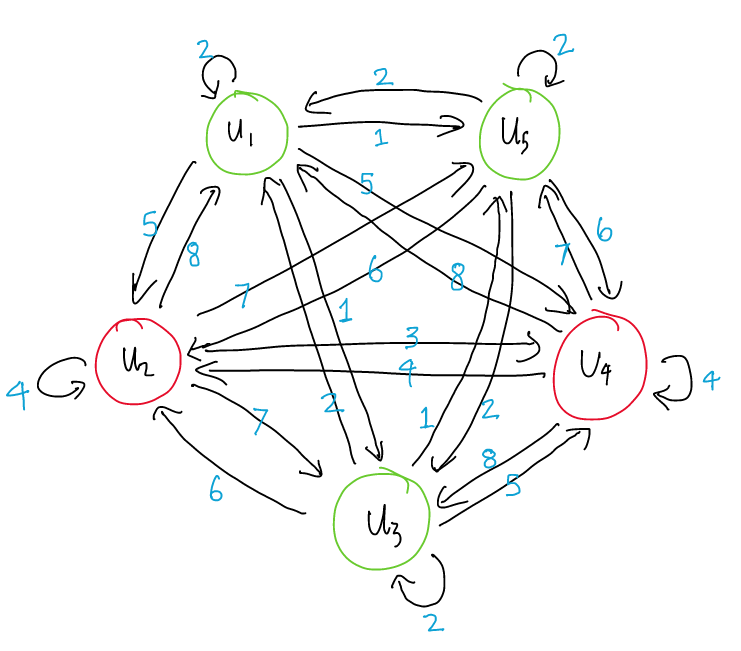
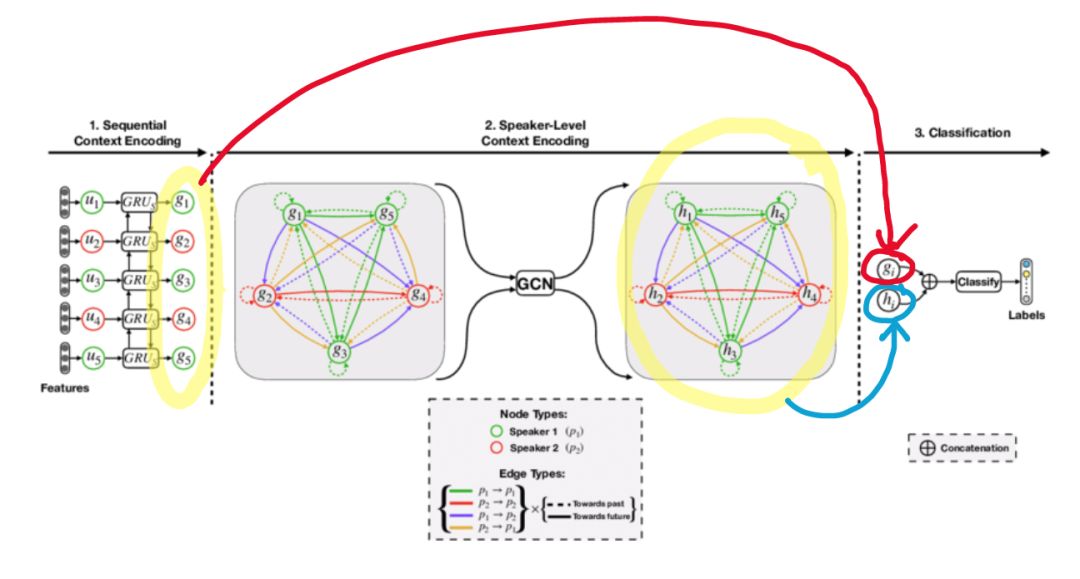
- IEMOCAP:视频形式的十位独立发言人的双向对话。语段中带有快乐、悲伤、中立、愤怒、激动或沮丧的标签。
- AVEC:人类与人工智能之间的对话。语段具有四个标签:价值([-1,1])、唤醒([-1,1])、期望([-1,1])和能力([0,∞])。
- MELD:包含电视连续剧《老友记》中的 1400 个对话和 13000 个语段。MELD 还包含互补的声音和视觉信息。语段被标记为愤怒、厌恶、悲伤、喜悦、惊奇、恐惧或中立。
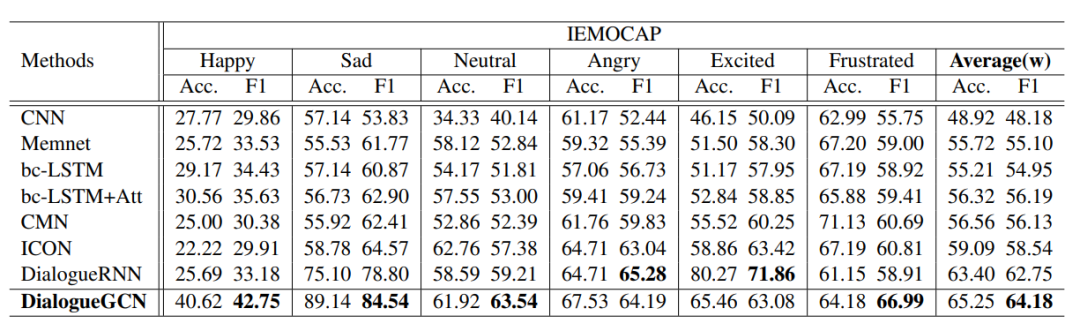 DialogueGCN与其他模型在IEMOCAP数据集上的表现(表摘自[1])
DialogueGCN与其他模型在IEMOCAP数据集上的表现(表摘自[1])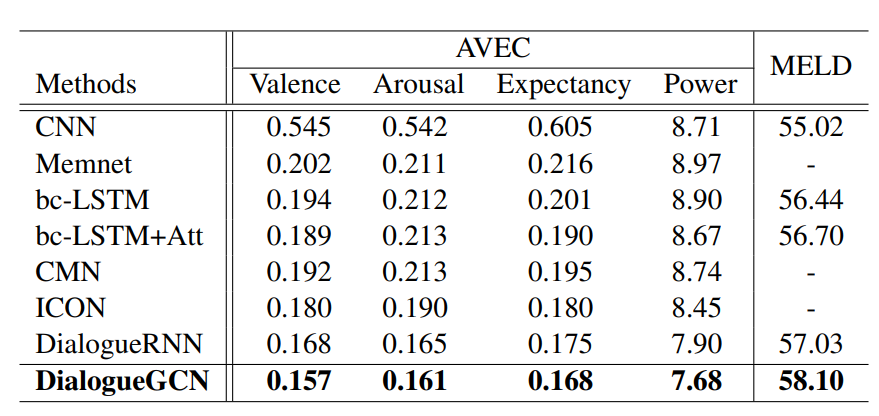 DialogueGCN与其他模型在AVEC和MELD数据集上的表现(表摘自[1])
DialogueGCN与其他模型在AVEC和MELD数据集上的表现(表摘自[1])- 类似的情绪类别,例如“沮丧”和“生气”,或“激动”和“快乐”。
- 简短的话语,例如“好”或“是”。
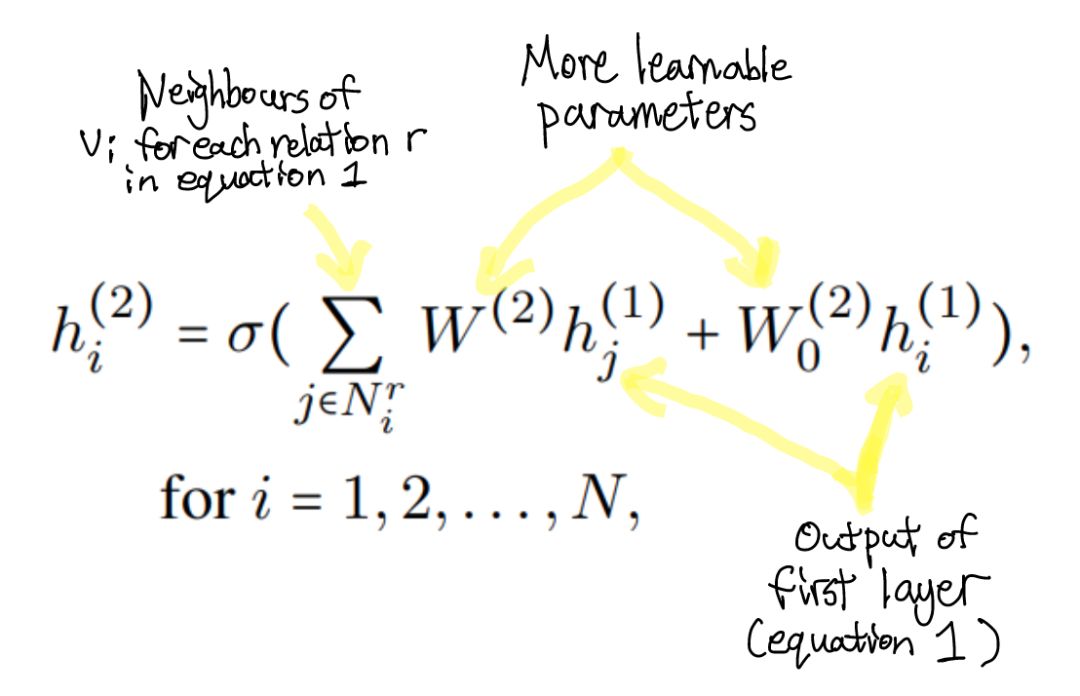
- 上下文很重要。一个好的模型不仅要考虑对话的顺序上下文(句子的顺序,单词彼此之间的关联),还要考虑说话者级别的上下文(说话者说什么,当他们说话时,它们如何受到其他说话者和自己的影响)。与传统的序列模型和基于注意力的模型相比,集成说话者级别的上下文是一大进步。
- 序列并不是代表对话的唯一方式。数据的结构可以帮助捕获更多的上下文。在这种情况下,说话者级别的上下文更容易以图形格式编码。
- 图神经网络是 NLP 研究的宝库。聚合邻居信息的关键概念虽然看上去简单,但在捕获数据中的关系方面具有惊人的功能。
(*本文为AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆

推荐阅读
相关文章:

Java的学习之路(1)
学过C语言之后,尝试接触Java. 借博文来记录自己学习的过程. Test01:利用循环,输出整数1-999之和 1 //2 //循环计算1到999的整数之和并输出3 //4 package demo;5 6 public class Main {7 8 public static void main(String[] args) {9 int su…

Swift - 使用addSubview()方法将StoryBoard中的视图加载进来
使用 Storyboard 我们可以很方便地搭建好各种复杂的页面,同时通过 segue 连接可以轻松实现页面的跳转。但除了segue,我们还可以使用纯代码的方式实现Storyboard界面的跳转。 比如:使用 presentViewController() 方法将当前页面视图切换成新视…

这项技术厉害了!让旅行者 2 号从星际空间发首批数据!
立即购票:https://dwz.cn/z1jHouwE物联网作为信息系统向物理世界的延伸,极大地拓展了人类认知和控制物理世界的能力,被称为继计算机和互联网之后的世界信息产业的第三次浪潮,正在深刻地改变着人类的生存环境和生活方式。据最新报道…
Ubuntu 14.04上使用CMake编译MXNet源码操作步骤(Python)
MXNet源码版本号为1.3.0,其它依赖库的版本号可参考:https://blog.csdn.net/fengbingchun/article/details/84997490 。 为了通过编译源码支持python接口,这里在 https://blog.csdn.net/fengbingchun/article/details/85162936 的基础上对bui…
近段时间学习html和CSS的一些细碎总结
1、边框圆角属性:border-radius,取值能够是 百分比 / 自己定义长度,不能够取负值。假设是圆,将高度和宽度设置相等,而且将border-radius设置为100% 2、IE6,IE7,IE8,opera,…

Swift:闭包
[objc] view plaincopy print?/* 闭包(Closures) * 闭包是自包含的功能代码块,可以在代码中使用或者用来作为参数传值。 * 在Swift中的闭包与C、OC中的blocks和其它编程语言(如Python)中的lambdas类似。 * 闭包…
Ubuntu下使用CMake编译OpenSSL源码操作步骤(C语言)
OpenSSL的版本为1.0.1g,在ubuntu下通过CMake仅编译c代码不包括汇编代码,脚本内容如下: build.sh内容: #! /bin/bashreal_path$(realpath $0) dir_namedirname "${real_path}" echo "real_path: ${real_path}, di…
从词袋到Transfomer,NLP十年突破史
作者 | Zelros AI译者 | 夕颜出品 | AI科技大本营(ID:rgznai100)【导读】通过 Kaggle 竞赛视角,观察 NLP 十年发展简史。根据上下文(这里指句子的最后一个词),“它”可以指“动物”或“街道”。图源 | Goog…

《千只鹤》--[日]川端康成
《千只鹤》,作者是川端康成 故事梗概: 三谷菊治的父亲是个著名的茶道师匠,他生前与一位叫栗本近子的女人有染,后来又 钟情于太田夫人,而且由于后者而疏远了前者,但前者仍出入于三谷家。在三谷先生去 世四年…
所有接口添加plist文件的写法 swift
第一步 建立plist文件 interface JMTConfigUtils : NSObject /** * 获取配置文件中友盟key * * return NSString */ - (NSString *)umengKey; /** * 微信AppId * * return NSString */ - (NSString *)wxAppId; /** * 微信appSecret * * return NSString */ - (NSString…
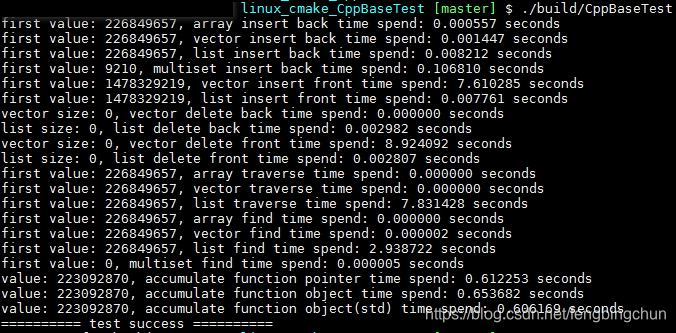
提高C++性能的编程技术笔记:标准模板库+测试代码
标准模板库(Standard Template Library, STL)是容器和通用算法的强效组合。 渐近复杂度:算法的渐近复杂度是对算法性能的近似估计。它是算法集到特定性能标准集的映射。如果需要对包含N个整数的向量的所有元素求和,那么每个整数必须且仅需检查一次&…

「创式纪」人工智能应用创新大赛启动,首次结合商业计划和机器学习
谈到人工智能,技术和应用场景成为了大家广泛关注的话题。技术的演进,是推动人工智能发展的核心,而广泛的场景应用,则是人工智能真正价值所在。现阶段,精准营销、信贷风控、人脸比对等为人熟知的AI,已经经过…
linux chattr命令
chattr 设置linux文件的属性 (参照man手册进行翻译,常用的属性都翻译过来,个人觉得很少用到的属性就没有翻译) 用法:chattr [ -RVf ] -[acdeijstuADST] files选项:-R 对目录进行递归处理-V 显示详细的输出-F 忽略…
swift 中高德地图随时读取坐标地点的写法
自己写的方法 不比比 自己能看懂就行 只用作自己学习swift的总结 import UIKit typealias block (String,String) ->() class MoveCarViewController: UIViewController,MAMapViewDelegate,AMapLocationManagerDelegate,AMapSearchDelegate,UITextFieldDelegate,UIAler…
万字干货 | Python后台开发的高并发场景优化解决方案
嘉宾 | 黄思涵 来源 | AI科技大本营在线公开课互联网发展到今天,规模变得越来越大,也对所有的后端服务提出了更高的要求。在平时的工作中,我们或多或少都遇到过服务器压力过大问题。针对该问题,本次公开课邀请到了金山办公AI平台研…

提高C++性能的编程技术笔记:引用计数+测试代码
引用计数(reference counting):基本思想是将销毁对象的职责从客户端代码转移到对象本身。对象跟踪记录自身当前被引用的数目,在引用计数达到零时自行销毁。换句话说,对象不再被使用时自行销毁。 引用计数和执行速度之间的关系是与上下文紧密…
如何提升 CSS 选择器的性能?
CSS选择器对性能的影响源于浏览器匹配选择器和文档元素时所消耗的时间,所以优化选择器的原则是应尽量避免使用消耗更多匹配时间的选择器。而在这之前我们需要了解CSS选择器匹配的机制, 如子选择器规则: #header > a {font-weight:blod;} 我…
百度AI攻坚战:PaddlePaddle中国突围
作者 | 阿司匹林出品 | AI科技大本营(ID:rgznai100)2013年,百度开始研发深度学习框架PaddlePaddle,搜索、凤巢CTR预估上线DNN模型。2016年,在百度世界大会上,百度宣布PaddlePaddle开源ÿ…

提高C++性能的编程技术笔记:编码优化+测试代码
缓存:在现代处理器中,缓存经常与处理器中的数据缓存和指令缓存联系在一起。缓存主要用来存储使用频繁而且代价高昂的计算结果,这样就可以避免对这些结果的重复计算。如,循环内对常量表达式求值是一种常见的低性能问题。 预先计算…
Swift 中使用 SQLite——打开数据库
关于Swift中使用SQLite,接下来可能会分别从打开、增、删、改、查,几个方面来介绍SQLite的具体使用,这一篇重点介绍一下如何打开。 定义全局数据库访问句柄 /// 全局数据库访问句柄 private var db: COpaquePointer nil实现打开数据库函数 …
MVC中获取模型属性的Range和StringLength验证特性设置
MVC中的客户端及服务端模型验证信息都以ModelMetadata类型作为承载,在获得属性的ModelMetadata之后(还不知道怎么获取ModelMetadata的童鞋请自行恶补),我们可以轻松得到一些我们在模型中定义的特性,比如显示名称、是否…
以安装PyTorch为例说明Anaconda在Windows/Linux上的使用
在Windows10上配置完MXNet 1.3.0后,再配置PyTorch 1.0时,发现两者需要依赖的NumPy版本不一致,之前是通过pip安装NumPy,根据pip的版本不同,会安装不同版本的NumPy,使用起来很不方便,而且MXNet和P…
常用 SQL介绍
创建表 /*创建数据表CREATE TABLE 表名 (字段名 类型(INTEGER, REAL, TEXT, BLOB)NOT NULL 不允许为空PRIMARY KEY 主键AUTOINCREMENT 自增长,字段名2 类型,...)注意:在开发中,如果是从 Navicat 粘贴的 SQL,需要自己添加一个指令IF NO…

AttoNets,一种新型的更快、更高效边缘计算神经网络
作者 | Alexander Wong, Zhong Qiu Lin, and Brendan Chwyl 译者 | Rachel 出品 | AI科技大本营(ID:rgznai100)尽管机器学习已经在很多复杂的任务中取得了进展,但现有模型仍然面临许多边缘计算实践的困难,这些边缘计算场景包括移…
Appro DM8127 IPNC 挂载NFS遇到的问题及解决
对于Appro DM8127 IPNC,默认的启动方式是NAND is used for booting kernel and NAND is used as root filesystem 为了调试应用程序方便,通常使用挂载NFS作为 root filesystem 但是如果直接采用ti文档中所给的方法修改文件系统挂载方式(将启动…

提高C++性能的编程技术笔记:设计优化/可扩展性/系统体系结构相关+测试代码
1. 设计优化 我们可以粗略地将性能优化分为两种类型:编码优化和设计优化。编码优化定义为不需要完整理解要解决的问题或者应用程序的执行流程就能实施的优化。通过定义看出,编码优化用于局部代码,同时该过程不牵涉周围的代码。除了这些容易实…
ICLR 2020被爆半数审稿人无相关领域经验,同行评审制度在垮塌?
作者 | 若名出品 | AI科技大本营(ID:rgznai100)根据维基百科,同行评议(peer review),是指由一个或多个具有与作品生产者具有相似能力的人员(同行)对作品进行的评估活动。同行评审方法用于维持质…
Swift 中使用 SQLite——批量更新(事务处理)
本文是Swift 中使用 SQLite系列的收官之作,介绍一下在数据库中的批量更新。 事务 在准备做大规模数据操作前,首先开启一个事务,保存操作前的数据库的状态开始数据操作如果数据操作成功,提交事务,让数据库更新到数据操…

网络管理常用命令之二 - Ipconfig 命令详解(图文)
2、Ipconfig 命令...不带参数.../all 参数.../release 和 /realease6 参数.../Renew 和 /Renew6 参数.../flushdns 参数.../displaydns 参数2、Ipconfig 命令 ipconfig命令也是使用率非常高的一个命令,可用于显示系统的TCP/IP网络配置值,并刷新动态主…
Swift 中使用 SQLite——查询数据
本文主要介绍如何查询 SQLite 结果集,以及封装 SQLite 的操作方法。 准备测试代码 /// 从数据库中加载 person 数组 class func persons() -> [Person]? {// 1. 准备 SQLlet sql "SELECT id, name, age, height FROM T_Person;"// 2. 访问数据库// …