提高C++性能的编程技术笔记:总结
《提高C++性能的编程技术》这本书是2011年出版的,书中有些内容的介绍可能已经过时,已不再适用于现在的C++编程中,但大部分内容还是很有参考意义的。
这里是基于之前所有笔记的简单总结,笔记列表如下:
跟踪实例:https://blog.csdn.net/fengbingchun/article/details/83449625
构造函数和析构函数:https://blog.csdn.net/fengbingchun/article/details/83960568
虚函数、返回值优化:https://blog.csdn.net/fengbingchun/article/details/84185474
临时对象:https://blog.csdn.net/fengbingchun/article/details/84192535
单线程内存池:https://blog.csdn.net/fengbingchun/article/details/84497625
多线程内存池:https://blog.csdn.net/fengbingchun/article/details/84592548
内联:https://blog.csdn.net/fengbingchun/article/details/85030305
标准模板库:https://blog.csdn.net/fengbingchun/article/details/85470197
引用计数:https://blog.csdn.net/fengbingchun/article/details/85861776
编码优化:https://blog.csdn.net/fengbingchun/article/details/85934251
设计优化、可扩展性、系统体系结构相关:https://blog.csdn.net/fengbingchun/article/details/86549506
跟踪实例:最理想的跟踪性能优化的方法应该能够完全消除性能开销,即把跟踪调用嵌入在#ifdef块内。使用这种方法的不足在于必须重新编译程序来打开或关闭跟踪。
影响C++性能的因素:I/O的开销是高昂的;函数调用的开销是要考虑的一个因素,因此我们应该将短小的、频繁调用的函数内联;复制对象的开销是高昂的,最好选择传递引用,而不是传递值。
内联对大块头函数的影响是无足轻重的。只有在针对那些调用和返回开销占全部开销的绝大部分的小型函数时,内联对性能的改善才有较大的影响。内联消除了常被使用的小函数调用所产生的函数开销。
对象定义会触发隐形地执行构造函数和析构函数。我们称其为”隐性执行”而不是”隐性开销”是因为对象的构造和销毁并不总是意味产生开销。如果构造函数和析构函数所执行的计算是必须的,那么就要考虑使用高效的代码(内联会减少函数调用和返回的开销)。
通过引用传递对象还是不能保证良好的性能,所以避免对象的复制的确有利于提高性能,但是如果我们不必一开始就创建和销毁该对象的话,这种处理方式将更有利于性能的提升。
被打算创造设计灵活性的世界纪录。你的设计只需要在当前问题范围之内足够灵活就可以了。在完成同样的简单工作时,char指针有时可以比string对象更有效率。
内联消除了常被使用的小函数调用所产生的函数开销。
构造函数和析构函数:对象的创建和销毁往往会造成性能的损失。在继承层次中,对象的创建将引起其先辈的创建。对象的销毁也是如此。
构造函数和析构函数可以像手工编写的C代码一样有效。然而在实践中,它们经常包含冗余计算。
性能优化经常需要牺牲一些其它软件目标,诸如灵活性、可维护性、成本和重用之类的重要目标经常必须为性能让步。
对象的创建(或销毁)触发对父对象和成员对象的递归创建(或销毁)。要当心复杂层次中对象的复合使用。它们使得创建和销毁的开销更为高昂。
在C++中,不自觉地在程序开始处预先定义所有对象的做法是一种浪费。因为这样可能会创建一些直到最后都没有用到的对象。在C++中,把变量的创建延迟到第一次使用前。
要确保所编写的代码实际使用了所有创建的对象和这些对象所执行的计算。有的应用程序注重可维护性和灵活性,而另一些应用程序则可能把对性能的考虑放在最为重要的位置。作为程序员,应当清楚自己到底更看重哪个方面。
对象的生命周期不是无偿的。至少对象的创建和销毁会消耗CPU周期。不要随意创建一个对象,除非你打算使用它。通常情况下,要等到需要使用对象的地方再创建它。
编译器必须初始化被包含的成员对象之后再执行构造函数体。你必须在初始化阶段完成成员对象的创建。这可以降低随后在构造函数部分调用赋值操作符的开销。在某些情况下,这样也可以避免临时对象的产生。
虚函数:在以下几个方面,虚函数可能会造成性能损失:构造函数必须初始化vptr(虚函数表);虚函数是通过指针间接调用的,所以必须先得到指向虚函数表的指针,然后再获得正确的函数偏移量;内联是在编译时决定的,编译器不可能把运行时才解析的虚函数设置为内联。
某些情况下,在编译期间解析虚函数的调用是可能的,但这是例外情况。由于在编译期间不能确定所调用的函数所属的对象类型,所以大多数虚函数调用都是在运行期间解析的。编译期间无法解析对内联造成了负面影响。由于内联是在编译期间确定的,所以它需要具体函数的信息,但如果在编译期间不能确定将调用哪个函数,就无法使用内联。
评估虚函数的性能损失就是评估无法内联该函数所造成的损失。这种损失的代价并不固定,它取决于函数的复杂程度和调用频率。一种极端情况是频繁调用的简单函数,它们是内联的最大受益者,若无法内联则会造成重大性能损失。另一极端情况是很少调用的复杂函数。
虚函数的代价在于无法内联函数调用,因为这些调用是在运行时动态绑定的。唯一潜在的效率问题是从内联获得的速度(如果可以内联的话)。但对于那些代价并非取决于调用和返回开销的函数来说,内联效率不是问题。
模板比继承提供更好的性能。它把对类型的解析提前到编译期间,我们认为这是没有成本的。
函数返回值:通过转换源代码和消除对象的创建来加快源代码的执行速度,这种优化称为返回值优化(Return Value Optimization, RVO)。
如果必须按值返回对象,通过RVO可以省去创建和销毁局部对象的步骤,从而改善性能。
RVO的应用要遵照编译器的实现而定。这需要参考编译器文档或通过实验来判断是否使用RVO以及何时使用。
通过编写计算性构造函数可以更好地使用RVO。
临时对象:临时对象会以构造函数和析构函数的形式降低一半的性能。
将构造函数声明为explicit,可以阻止编译器在幕后使用类型转换。
编译器常常创建临时对象来解决类型不匹配问题。通过函数重载可以避免这种情况。
如果可能,应尽量避免使用对象拷贝。按引用传递和返回对象。
在<op>可能是”+、-、*”或者”/”的地方,使用<op>=运算符可以消除临时对象。
单线程内存池:频繁地分配和回收内存会严重地降低程序的性能。性能降低的原因在于默认的内存管理是通用的。应用程序可能会以某种特定的方式使用内存,并且为不需要的功能付出性能上的代价。通过开发专用的内存管理器可以解决这个问题。对专用内存管理器的设计可以从多个角度考虑。我们至少可以想到两个方面:大小和并发。
从大小的角度分为以下两种:
(1)、固定大小:分配固定大小内存块的内存管理器。
(2)、可变大小:分配任意大小内存块的内存管理器。所请求分配的大小事先是未知的。
类似的,从并发的角度也分为以下两种:
(1)、单线程:内存管理器局限在一个线程内。内存被一个线程使用,并且不越出该线程的界限。这种内存管理器不涉及相互访问的多线程。
(2)、多线程:内存管理器被多个线程并发地使用。这种实现需要包含互斥执行的代码段。无论什么时候,只能有一个线程在执行一个代码段。
灵活性以速度的降低为代价.随着内存管理的功能和灵活性的增强,执行速度将降低.
全局内存管理器(由new()和delete()执行)是通用的,因此代价高。
专用内存管理器比全局内存管理器快一个数量级以上。
如果主要分配固定大小的内存块,专用的固定大小内存管理器将明显地提升性能。
如果主要分配限于单线程的内存块,那么内存管理器也会有类似的性能提高。由于省去了全局函数new()和delete()必须处理的并发问题,单线程内存管理器的性能有所提高。
多线程内存池:全局内存管理器(通过new()和delete()实现)是通用的,因此它的开销也非常大。
因为单线程内存管理器要比多线程内存管理器快的多,所以如果要分配的大多数内存块限于单线程中使用,那么可以显著提升性能。
如果开发了一套有效的单线程分配器,那么通过模板可以方便地将它们扩展到多线程环境中。
内联基础:内联类似于宏,在调用方法内部展开被调用方法,以此来代替方法的调用。一般来说表达内联意图的方式有两种:一种是在定义方法时添加内联保留字的前缀;另一种是在类的头部声明中定义方法。
从逻辑上说,编译器将方法内联化的步骤如下:首先将待内联方法的连续代码块复制到调用方法中的调用点处。然后在块中为所有内联方法的局部变量分配内存。之后将内联方法的输入参数和返回值映射到调用方法的局部变量空间内。最后,如果内联方法有多个返回点,将其转变为内联代码块末尾的分支。经过这样的处理即可消除所有与调用相关的痕迹以及性能损失。避免方法调用仅仅是内联可提升的性能空间的一半。调用间(cross-call)优化是内联可提升的性能空间的另外一半。优秀的、经过优化的编译器可以使内联方法的边界痕迹难以区分。方法中大量的甚至是所有的代码经过优化后都将不复存在,因为编译器可能会对方法中大部分代码进行重新排列。因此,尽管在逻辑上可以将方法内联化看作是对一定内聚度的维持,不过编译器并未强制执行这种优化措施,这也是内联的优点之一。
如果方法有返回值,特别当其返回值是一个对象时,被调用方法将对象复制到调用方法为返回值预留的存储空间中也是一笔开销。对于较大的对象而言,这笔额外开销将更加客观,尤其是使用复杂的拷贝构造函数执行该任务时(这种会产生两份调用/返回开销:一份开销是因为对方法的显示调用,另一份则是拷贝构造函数返回一个对象时产生的开销)。
内联是一种由编译器/配置器/优化器执行的、基于编译和配置的优化操作。
保留字”inline”仅表示对编译器的一种建议。它告诉编译器,将方法代码内联展开而不是调用可以获得更佳性能。但是编译器没有义务答应内联请求。因此编译器可以根据自己的意愿或者能力来选择是否进行内联。这就意味着即使没有被明确告知需要内联(对低价值方法编译器会自动内联,这常常是优化的副作用)编译器也会这样去做,或者即便被明确告知需要内联却不进行内联。
内联还会引起一些值得注意的副作用:从逻辑上来说,虽然经常被存放于单独的.inl文件中,但其实内联方法的定义应为类头文件的一部分。头文件及其逻辑上包含的.inl文件随后被用到它们的.c或.cpp文件包含。源文件被编译为目标文件后,就不需要在目标文件做任何标示以说明目标文件包含哪些内联方法了。也就是说,通常情况下,目标文件已完全解析了内联方法且不需要再对其存在性进行保存(不存在链接需求)。因此,尽管C++语言明文禁止,但是源文件仍然可以和内联方法的定义一起编译,而另一源文件也可以和另一版本不同但方法相同的文件一起编译。
如果编译器足够完善,许多对虚方法的调用是可以内联化的。因此,如果配置文件指出某些虚方法需要占用程序过多的运行时间,则可通过将部分方法调用内联化来挽回一些开销。这也说明如果编译器有能力并且选择了将虚方法内联化,那么几乎可以保证一定会有一些针对同一方法的内联调用实例以及虚方法调用实例。
内联就是用方法的代码来替换对方法的调用。
内联通过消除调用开销来提升性能,并且允许进行调用间优化。
内联的主要作用是对运行时间进行优化,当然它也可以使可执行映像变得更小。
内联----站在性能的角度:调用间(cross-call)优化:面向某一方法的调用过程,基于对上下文场景更加全面的理解,使得编译器在源代码层面及机器代码层面对方法进行优化。这种优化的一般形式为:在编译期间进行一部分预处理,从而避免在运行时重复类似的过程。内联的这类优化应是编译器的职责,而不是程序员的。
何时避免内联:当程序中所有能够内联的方法都进行内联,代码膨胀将不可估量,这将对性能产生巨大的二次负面影响,如缓存命中问题和页面错误,而这些将令我们的工作得不偿失。另一方面,滥用的内联程序将执行较少的指令,但会耗费较多的时钟周期。内联的滥用导致的缓存错误会使性能锐减。代码膨胀所带来的副作用可能是无法承受的。
通常应避免递归方法内联。
编译器通常禁止内联复杂的方法。
直接量参数与内联结合使用,为编译器性能的大幅提升开辟了更为广阔的空间。
使用内联有时会适得其反,尤其是滥用的情况下,内联可能会使代码量变大,而代码量增多后会较原先出现更多的缓存失败和页面错误。
非精简方法的内联决策应根据样本执行的配置文件来制定,不能主观臆断。
对于那些调用频率高的方法,如果其静态尺寸较大,而动态尺寸较小,可以考虑将其重写,从而抽取其核心的动态特性,并将动态组件内联。
精简化与唯一化方法总是可以被内联。
内联技巧:内联可以改善性能。目标是找到程序的快速路径,然后内联它,尽管内联这个路径可能要费点工夫。
条件内联可以阻止内联的发生。这样就减少了编译时间,同时也简化了开发前期的调试工作。
选择性内联是一种只在某些地方内联方法的技术。在对方法进行内联时,为了抵消可能的代码尺寸膨胀的影响,选择性内联只在对性能有重大影响的路径上对方法调用进行内联。
递归内联是一种让人感觉别扭,但对于改善递归方法性能却很有效的技术。
内联的目标是消除调用开销。在使用内联之前须先弄清当前系统中真正的调用代价。
标准模板库:标准模板库(Standard Template Library, STL)是容器和通用算法的强效组合。
STL实现在以下几个方面形成了自己的优势:(1). STL实现使用最好的算法;(2). STL实现的设计者非常有可能是领域内的专家;(3). 这些领域内的专家完全地致力于提供一个灵活、强大并且高效的库。这是他们的首要任务。
STL是抽象、灵活性和效率的一种罕见的结合。对于某种特定的应用模式,一些容器比其它的更加高效,这都要随着实际应用而定。除非了解一些相关领域内STL所忽略的问题,否则你是不可能超过STL实现的。不过,在一些特定的情况下,还是有可能超越STL实现的性能的。
引用计数:基本思想是将销毁对象的职责从客户端代码转移到对象本身。对象跟踪记录自身当前被引用的数目,在引用计数达到零时自行销毁。换句话说,对象不再被使用时自行销毁。
引用计数在性能上并非无往不胜。引用计数、执行时间和资源维护会产生微妙的相互作用,如果对性能方面的考虑很重要,就必须对这几个方面仔细进行评估。引用计数是提升还是损害性能取决于其使用方式。下面的任意一种情况都可以使引用计数变得更为有效:目标对象是很大的资源消费者;资源分配和释放的代价很高;高度共享,由于使用赋值操作符和拷贝构造函数,引用计数的性能可能会很高;创建和销毁引用的代价低廉。反之,则应跳出引用计数而转为使用更加有效的简单非计数对象。
编码优化:编码优化在范围上是局部的,并且不需要对程序的整体设计有深入的理解。当你加入到一个正在进行的开发项目中,并且你对其设计还没有完全理解时,这会是一个很好的起点。
最快的代码是从不执行的代码。试着按照以下步骤去剔除那些代价高昂的计算:
(1). 你打算使用该计算结果吗?听起来有点可笑,但这种可笑的事确实会发生----有时我们执行了计算但从未使用计算的结果。
(2). 你现在需要该结果吗?请在真正需要的时候再进行计算。在一些执行流程中有些结果永远不会被使用,因此不必过早地计算。
(3). 你是否已经知道结果?如果在程序执行流程的前期已经计算出了结果,那么应该使用该结果成为可重用的。
有的时候可能无法绕开该计算,此时就必须完成它。那么现在的挑战就是加快计算速度:
(1). 该计算是否过于通用?你的实现只需要跟该领域要求的一样灵活就行,而无须奢求。可以充分利用简化的假设以降低灵活性来增加速度。
(2). 一些灵活性隐藏在函数调用中。通过实现库调用的自定义版本可以提升速度。不过,这些库调用必须是被频繁调用的,否则你的努力将得不到明显效果。熟悉你所使用的库和系统调用中隐藏的代价。
(3). 尽量减少内存管理调用的数量。在绝大多数编译器中,这些调用的代价都是非常高的。
(4). 如果考虑所有可能的输入数据,则可以发现20%的数据在80%时间里出现。因此,应当以牺牲其它不经常出现的场景为代价来提高典型输入的处理速度。
(5). 缓存、RAM和磁盘访问的速度差异很明显。应该多编写缓存友好的代码。
设计优化:我们可以粗略地将性能优化分为两种类型:编码优化和设计优化。设计优化贯穿于所有代码。
在软件性能和灵活性之间存在一种基本的平衡。对于在80%时间内执行的20%的软件,性能通常损失在灵活性上。
在代码细节中可以利用缓存优化代码,在这个程序设计中也能采用这种方法。通常可以通过将先前的计算结果保存起来避免大量的计算。
对于软件的高效性而言,使用高效的算法和数据结构是必要条件,但并非充分条件。
有些计算只有在特定执行条件下才需要。这些计算应该被推迟到确实需要它们的路径上来完成。如果过早地执行计算,那么其结果可能并没有被调用。
大型软件往往会变得错综复杂,杂乱不堪。混乱软件的一大特点就是执行失效代码:那些曾经用来实现某个目标,但现在已经不需要的代码。定期清理失效和僵死代码可以增强软件性能,同时对于软件也是一种维护。
可扩展性:使用单个锁来保护多个不相关的共享资源,一般来说都不是一个好主意。这样做会扩大临界区的范围,并造成其它不相关的线程间冲突。此规则的唯一例外是在满足以下两个条件时:所有共享资源总是一起操作;任何共享资源的操作都不会消耗大量的CPU周期。缓存的原子单元以行为单位。
实现可扩展性的技巧是减少或者消除顺序化的代码。以下是可以达到这个目标的一些步骤:
任务分解:将大的任务分为小任务,使线程并发地执行这些小任务。
代码移出:临界区应该只包含关键代码,不直接操作共享资源的代码不要放在临界区内。
利用缓存:有时,通过缓存之前访问过的数据,可以消除对临界区的访问。
无共享:如果需要少量、数目固定的资源实例,可以不使用公共资源池。你可以把这些资源实例设为线程私有,并最后回收。
部分共享:有两个一样的资源池可以减少一半的竞争。
锁粒度:不要用同样的锁来保护所有资源,除非这些资源是同时更新的。
伪共享:不要在类定义里把两个使用频度都很高的锁放太靠近。你肯定不希望它们共享同一个缓存并触发缓存一致性风暴。
惊群现象:仔细分析你的锁调用的特征。当锁被释放时,是所有的等待线程都被唤醒还是只唤醒一个线程?唤醒所有线程会威胁到应用的可扩展性。
系统和类库调用:考察这些调用的实现特征。它们有可能是隐藏了顺序化的代码。
读/写锁:以读为主的共享数据会从这种锁中获益,使用这种锁,可以消除读者线程之间的竞争。
系统体系结构相关话题:存储器层级从最快(访问时间最短)到最慢(访问时间最长)其排序为:寄存器、L1(第一级)芯片内缓存、L2(第二级)芯片外缓存、主存(半导体动态随机访问内存:DRAM、SDRAM、RAMBUS、SyncLink等等)、磁盘存储器。
寄存器:存储器之王。在存储器层级上的所有实体中,寄存器延迟最短,带宽最高,开销最小。寄存器可由机器代码直接寻址。正确地使用寄存器存放变量可以使某些编译器产生的个别方法在性能上大幅提升。
最快的代码是直线型的代码:没有条件判断,没有循环,没有调用,没有返回。一般来说,程序的关键路径越像一条直线,执行速度就越快。请记住:短小而带有很多分支的代码要比长而没有分支的代码所用的执行时间长。
使用简单计算代替小分支:分支是性能的敌人。
多线程是一种相当有用的机制,而且在合适的系统中能带来巨大的性能优势,但错误地使用线程概念会导致严重的性能问题。
要使用的存储器离处理器越远,访问所需的时间就越长。离处理器最近的是寄存器,虽然容量很少,但是速度很快。对寄存器的优化对程序的性能提升而言是极其有意的。
虚拟存储器并不是无偿的,不加选择地依赖系统管理的虚拟结构可能会影响性能,而且一般都是降低性能。
上下文切换的开销巨大,需避免上下文切换。
GitHub: https://github.com/fengbingchun/Messy_Test
相关文章:

13岁小孩都跟我抢Python了,完了!
以下来自一位程序员母亲和工作人员的对话。程序员妈妈:您好,可以帮我推荐一本适合我家小孩看的编程书籍吗?兔子:可以的呀,《Scratch从入门到精通》,这本书适合小孩学习,您可以先看一下哦~程序员…
Windows Mobile 6.0 SDK和中文模拟器下载
【转】 Windows Mobile 6.0 SDK和中文模拟器下载 Windows Mobile 6.5 模拟器2010年12月06日 星期一 07:48转载自 zhangyanle86终于编辑 zhangyanle86Windows Mobile 6.0 SDK和中文模拟器下载 SDK 6.0下载页面:http://www.microsoft.com/downloads/details.aspx?fam…

wxPython:Python首选的GUI库 | CSDN博文精选
作者 | 天元浪子来源 | CSDN博客文章目录概述窗口程序的基本框架事件和事件驱动菜单栏/工具栏/状态栏动态布局AUI布局DC绘图定时器和线程后记概述跨平台的GUI工具库,较为有名的当属GTK、Qt 和 wxWidgets 了。GTK是C实现的,由于C语言本身不支持OOP&#x…

Swift 中使用 SQLite——修改和删除数据
本文主要介绍在SQLite中修改数据、删除数据: 更新记录 /// 将当前对象信息更新到数据库 /// /// - returns: 是否成功 func updatePerson() -> Bool {guard let name name else {print("姓名不能为空")return false}if id < 0 {print("id 不…

用python3实现指定目录下文件sha256及文件大小统计
有时会统计某个目录下有哪些文件,每个文件的sha256及文件大小等相关信息,这里用python3写了个脚本用来实现此功能,此脚本可跨平台,同时支持windows和linux,脚本(get_dir_file_info.py)内容如下: import os…
Swift 中使用 SQLite——新增数据
本文重点介绍两个方面,1、新增数据,2、获取自动增长 ID。 建立 Person.swift 数据模型 /// 个人模型 class Person: NSObject {// MARK: - 模型属性/// 代号var id: Int64 0/// 姓名var name: String?/// 年龄var age 0/// 身高var height: Double …
投稿2877篇,EMNLP 2019公布4篇最佳论文
整理 | AI科技大本营(ID:rgznai100)近日,自然语言处理领域的顶级会议之一EMNLP 2019公布了年度最佳论文。EMNLP是由国际语言学会(ACL)下属的SIGDAT小组主办的自然语言处理领域的顶级国际会议,是自然语言算法…
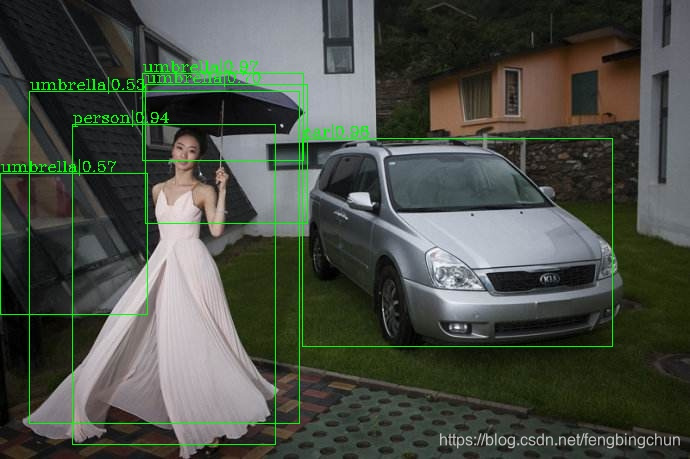
对象检测工具包mmdetection简介、安装及测试代码
mmdetection是商汤和港中文大学联合开源的基于PyTorch的对象检测工具包,属于香港中文大学多媒体实验室open-mmlab项目的一部分。该工具包提供了已公开发表的多种流行的检测组件,通过这些组件的组合可以迅速搭建出各种检测框架。 mmdetection主要特性&am…
(转)eclipse 代码自动补全
转自:http://blog.csdn.net/yushuwai2010/article/details/11856129 一般默认情况下,Eclipse的代码提示功能是比MicrosoftVisualStudio的差很多的,主要是Eclipse本身有很多选项是默认关闭的,要开发者自己去手动配置。如果开发者不…
swift 多线程GCD和延时调用
GCD 是一种非常方便的使用多线程的方式。通过使用 GCD,我们可以在确保尽量简单的语法的前提下进行灵活的多线程编程。在 “复杂必死” 的多线程编程中,保持简单就是避免错误的金科玉律。好消息是在 Swift 中是可以无缝使用 GCD 的 API 的,而且…
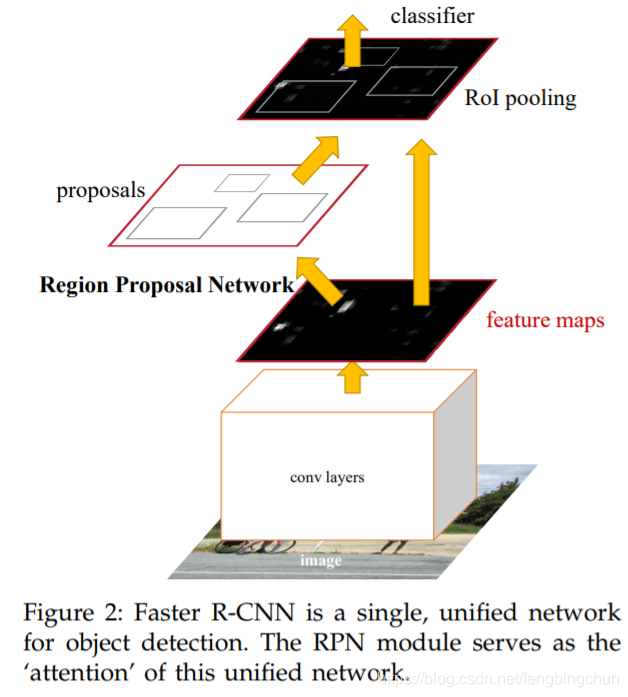
目标检测算法Faster R-CNN简介
在博文https://blog.csdn.net/fengbingchun/article/details/87091740 中对Fast R-CNN进行了简单介绍,这里在Fast R-CNN的基础上简单介绍下Faster R-CNN。 目标检测领域从R-CNN开始,通过引入卷积神经网络取得了很多突破性的进展,但是始终未能…
ICCV 2019 | 加一个任务路由让数百个任务同时跑起来,怎么做到?
作者 | Gjorgji Strezoski, Nanne van Noord, Marcel Worring 译者 | 中国海洋大学李杰 出品 | AI科技大本营(ID:rgznai100)摘要传统的多任务(MTL)学习方法依赖于架构调整和大型可训练参数集来联合优化多个任务。但是,…

DEV开发之控件NavBarControl
右键点击RunDesigner弹出如下界面鼠标先点击3或4,1,,然后点击1或2进行相应的新增或删除操作,3是分组,4是项目,4可以直接拖动到相应的分组3.属性caption:显示的名称4.NavBarControl 属性 PaintStyleName绘画风格&…
swift支持多线程操作数据库类库-CoreDataManager
类库方法 获取数据 executeFetchRequest(request:) 同步获取数据 var request: NSFetchRequest NSFetchRequest(entityName: "MonkeyEntity")var myMonkeys:NSArray? CoreDataManager.shared.executeFetchRequest(request)异步获取数据 executeFetchRequest(re…

目标检测(或分隔)算法Mask R-CNN简介
在博文https://blog.csdn.net/fengbingchun/article/details/87195597 中对Faster R-CNN进行了简单介绍,这里在Faster R-CNN的基础上简单介绍下Mask R-CNN。 Mask R-CNN是faster R-CNN的扩展形式,能够有效地检测图像中的目标,并且Mask R-CNN…

未来之城,管理者可能不是人......
大会官网 https://t.csdnimg.cn/KSTh2010 年,IBM 正式提出了“智慧地球”愿景。在 IBM 的设想中,智慧城市应该由六个核心系统组成:组织(人)、业务/政务、交通、通讯、水和能源。(图源 | IBM 官网࿰…
UVa 10701 - Pre, in and post
题目:已知树的前根序,中根序遍历转化成后根序遍历。 分析:递归,DS。依据定义递归求解就可以。 前根序:根,左子树,右子树; 中根序:左子树,根,右子树…

图像集存储成MNIST数据集格式实现
有时会用到将一组图像存放成MNIST中那样的数据格式,以便于用于网络的训练和测试,如MNSIT中的测试集标签t10k-labels.idx1-ubyte和测试集图像t10k-images.idx3-ubyte,各包含了10000个样本,这里以此两个测试集为例详细说明下实现过程…
ios9定位服务的app进入后台三分钟收不到经纬度,应用被挂起问题及解决方案
原来定位服务是10分钟收不到定位信息就挂起定位,现在变为最短3分钟,估计都是为了省电吧。只要你开启应用的后台定位,并且10分钟有一次定位,那么苹果就不会关闭你的线程,现在变成3分钟。若你的应用开启了后台定位&#…
程序员必知的20个Python技巧
作者 | Duomly 译者 | 弯月,编辑 | 郭芮 出品 | CSDN(ID:CSDNnews)Python是一门流行且应用广泛的通用编程语言,其应用包括数据科学、机器学习、科学计算等领域,以及后端Web开发、移动和桌面应用程序等方面。…

CSS float浮动的深入研究、详解及拓展(二)
为什么80%的码农都做不了架构师?>>> 接上回… 五、浮动的非本职工作 浮动的本职工作是让匿名inline boxes性质的文字环绕图片显示,而其他所有用浮动实现的效果都不是浮动应该做的事情,我称之为“非本职工作”。 或许我们并没有…
不需要显示地图 就获得用户当前经纬度 超简单的方法
1.遵循协议 CLLocationManagerDelegate,AMapSearchDelegate,AMapLocationManagerDelegate 2. API MAMapServices.sharedServices().apiKey APIKey AMapLocationServices.sharedServices().apiKey APIKey AMapSearchServices.sharedServices().apiKey APIKey AMapNaviService…
ELECTRA:超越BERT,2019年最佳NLP预训练模型
作者 | 李如来源 | NLPCAB(ID:rgznai100)【导读】BERT推出这一年来,除了XLNet,其他的改进都没带来太多惊喜,无非是越堆越大的模型和数据,以及动辄1024块TPU,让工程师们不知道如何落地。今天要介…
安装node和spm过程
2019独角兽企业重金招聘Python工程师标准>>> 安装nodejs 官网下载nodejs,我下的是v0.10.33版本,安装到d:\nodejs下。 1.新建目录d:\nodejs,在其中建立node_cache、node_global、node_modules三个目录。 2,将C:\Users…
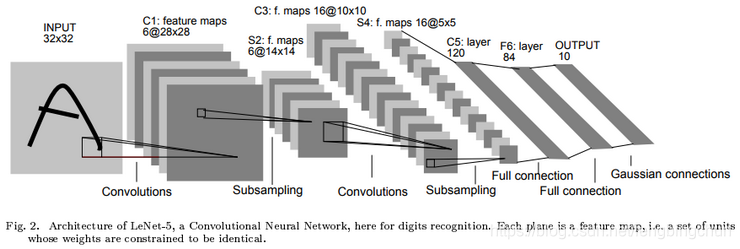
经典网络LeNet-5介绍及代码测试(Caffe, MNIST, C++)
LeNet-5:包含7个层(layer),如下图所示:输入层没有计算在内,输入图像大小为32*32*1,是针对灰度图进行训练和预测的。论文名字为” Gradient-Based Learning Applied to Document Recognition”,可以直接从ht…
根据经纬度获取用户当前位置信息
根据上篇文章获取的经纬度获取用户当前的位置信息 //获取用户所在位置信息ADDRESS func getUserAddress() { let latitude : CLLocationDegrees LATITUDES! let longitude : CLLocationDegrees LONGITUDES! print("latitude:\(latitude)") print("longitude…

刷了几千道算法题,我私藏的刷题网站都在这里了
作者 | Rocky0429 来源 | Python空间(ID: Devtogether)遥想当年,机缘巧合入了 ACM 的坑,周边巨擘林立,从此过上了"天天被虐似死狗"的生活...然而我是谁,我可是死狗中的战斗鸡,智力不够…
js实现点击li标签弹出其索引值
据说这是一道笔试题,以下是代码,没什么要文字叙述的,就是点击哪个<li>弹出哪个<li>的索引值即可: <html> <head> <style> li{width:50px;height:30px;margin:5px;float:left;text-align: center;li…
定时器开启和关闭
写程序时遇见了定时器,需要写入数据库用户的经纬 ,还要读取,写好之后发现很费电 总结原因: 1:地图定位耗电(这个根据程序要求,不能关闭,需要实时定位,很无奈ÿ…
一览群智胡健:在中国完全照搬Palantir模式,这不现实
作者 | Just出品 | AI科技大本营(ID:rgznai100)神秘的硅谷大数据挖掘公司 Palantir 是国内众多创业公司看齐的标杆,其业务是为政府和金融领域的大客户提供数据分析服务,帮助客户作出判断,甚至“预知未来”,…