70行Go代码打败C
【12月公开课预告】,入群直接获取报名地址
12月11日晚8点直播主题:人工智能消化道病理辅助诊断平台——从方法到落地
12月12日晚8点直播:利用容器技术打造AI公司技术中台
12月17日晚8点直播主题:可重构计算:能效比、通用性,一个都不能少
作者 | Ajeet D'Souza
译者 | 苏本如,编辑 | maozz
来源 | CSDN(ID:CSDNnews)
Chris Penner最近发表的这篇文章——用80行Haskell代码击败C(https://chrispenner.ca/posts/wc),在互联网上引起了相当大的争议,从那以后,尝试用各种不同的编程语言来挑战历史悠久的C语言版wc命令(译者注:用于统计一个文件中的行数、字数、字节数或字符数的程序命令)就变成了一种大家趋之若鹜的游戏,可以用来挑战的编程语言列表如下:
Ada
C
Common Lisp
Dyalog APL
Futhark
Haskell
Rust
今天,我们将用Go语言来进行这个wc命令的挑战。作为一种具有优秀并发原语的编译语言,要获得与C语言相当的性能应该很容易。
虽然wc命令被设计为可以从标准输入设备(stdin)读取、处理非ASCII文本编码和解析命令行标志(wc命令的帮助可以参考这里),但我们在这里不会这样做。相反,像上面提到的文章一样,我们将集中精力使我们的实现尽可能简单。
如果你想看这篇文章用到的源代码,可以参考这里(https://github.com/ajeetdsouza/blog-wc-go)。
比较基准
我们将使用GNU的time工具包,针对两种语言编写的wc命令,从运行耗费时间和最大常驻内存大小两个方面来进行比较。
$ /usr/bin/time -f "%es %MKB" wc test.txt
用来比较的C语言版的wc命令和在Chris Penner的原始文章里用到的版本相同,使用gcc 9.2.1和-O3编译。对于我们自己的实现,我们将使用go 1.13.4(我也尝试过gccgo,但结果不是很好)来编译。并且,我们将使用以下系统配置作为运行的基准:
英特尔酷睿i5-6200U@2.30GHz 处理器(2个物理核,4个线程)
4+4 GB内存@2133 MHz
240 GB M.2固态硬盘
Fedora 31 Linux发行版
为了确保公平的比较,所有实现都将使用16 KB的缓冲区来读取输入。输入将是两个大小分别为100 MB和1GB,使用us-ascii编码的文本文件。
原始实现(wc-naïve)
解析参数很容易,因为我们只需要文件路径,代码如下:
if len(os.Args) < 2 {
panic("no file path specified")
}
filePath := os.Args[1]
file, err := os.Open(filePath)
if err != nil {
panic(err)
}
defer file.Close()
我们将按字节遍历文本和跟踪状态。幸运的是,在这种情况下,我们只需要知道两种状态:
前一个字节是空白;
前一个字节不是空白。
当从空白字符变为非空白字符时,我们给字计数器(word counter)加一。这种方法允许我们直接从字节流中读取,从而保持很低的内存消耗。
const bufferSize = 16 * 1024
reader := bufio.NewReaderSize(file, bufferSize)
lineCount := 0
wordCount := 0
byteCount := 0
prevByteIsSpace := true
for {
b, err := reader.ReadByte()
if err != nil {
if err == io.EOF {
break
} else {
panic(err)
}
}
byteCount++
switch b {
case '\n':
lineCount++
prevByteIsSpace = true
case ' ', '\t', '\r', '\v', '\f':
prevByteIsSpace = true
default:
if prevByteIsSpace {
wordCount++
prevByteIsSpace = false
}
}
}
要显示结果,我们将使用本机println()函数。在我的测试中,导入fmt库(注:Go语言的格式化库)会导致可执行文件的大小增加大约400 KB!
println(lineCount, wordCount, byteCount, file.Name())
让我们运行这个程序,然后看看它与C语言版wc的运行结果比较(见下表):
好消息是,我们的第一次尝试已经使我们在性能上接近C语言的版本。实际上,我们在内存使用方面做得比C更好!
拆分输入(wc-chunks)
虽然缓冲I/O读取对于提高性能至关重要,但调用ReadByte()并检查循环中的错误会带来很多不必要的开销。我们可以通过手动缓冲读取调用而不是依赖bufio.Reader来避免这种情况。
为此,我们将把输入分成可以单独处理的缓冲块(chunk)。幸运的是,要处理一个chunk,我们只需要知道前一个chunk的最后一个字符是否是空白。
让我们编写几个工具函数:
type Chunk struct {
PrevCharIsSpace bool
Buffer []byte
}
type Count struct {
LineCount int
WordCount int
}
func GetCount(chunk Chunk) Count {
count := Count{}
prevCharIsSpace := chunk.PrevCharIsSpace
for _, b := range chunk.Buffer {
switch b {
case '\n':
count.LineCount++
prevCharIsSpace = true
case ' ', '\t', '\r', '\v', '\f':
prevCharIsSpace = true
default:
if prevCharIsSpace {
prevCharIsSpace = false
count.WordCount++
}
}
}
return count
}
func IsSpace(b byte) bool {
return b == ' ' || b == '\t' || b == '\n' || b == '\r' || b == '\v' || b == '\f'
}
现在,我们可以将输入分成几个chunk(块),并将它们传送给GetCount函数。
totalCount := Count{}
lastCharIsSpace := true
const bufferSize = 16 * 1024
buffer := make([]byte, bufferSize)
for {
bytes, err := file.Read(buffer)
if err != nil {
if err == io.EOF {
break
} else {
panic(err)
}
}
count := GetCount(Chunk{lastCharIsSpace, buffer[:bytes]})
lastCharIsSpace = IsSpace(buffer[bytes-1])
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
要获取字节数,我们可以进行一次系统调用来查询文件大小:
fileStat, err := file.Stat()
if err != nil {
panic(err)
}
byteCount := fileStat.Size()
现在我们已经完成了,让我们看看它与C语言版wc的运行结果比较(见下表):
从上表结果看,我们在这两个方面都超过了C语言版wc命令,而且我们甚至还没有开始并行化我们的程序。tokei报告显示这个程序只有70行代码!
使用channel并行化(wc-channel)
不可否认,将wc这样的命令改成并行化运行有点过分了,但是让我们看看我们到底能走多远。Chris Penner的原始文章里的测试采用了并行化来读取输入文件,虽然这样做改进了运行时,但文章的作者也承认,并行化读取带来的性能提高可能仅限于某些类型的存储,而在其他类型的存储则有害无益。
对于我们的实现,我们希望我们的代码能够在所有设备上执行,所以我们不会这样做。我们将建立两个channel – chunks和counts。每个worker线程将从chunks中读取和处理数据,直到channel关闭,然后将结果写入counts中。
func ChunkCounter(chunks <-chan Chunk, counts chan<- Count) {
totalCount := Count{}
for {
chunk, ok := <-chunks
if !ok {
break
}
count := GetCount(chunk)
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
counts <- totalCount
}
我们将为每个逻辑CPU核心生成一个worker线程:
numWorkers := runtime.NumCPU()
chunks := make(chan Chunk)
counts := make(chan Count)
for i := 0; i < numWorkers; i++ {
go ChunkCounter(chunks, counts)
}
现在,我们循环运行,从磁盘读取并将作业分配给每个worker:
const bufferSize = 16 * 1024
lastCharIsSpace := true
for {
buffer := make([]byte, bufferSize)
bytes, err := file.Read(buffer)
if err != nil {
if err == io.EOF {
break
} else {
panic(err)
}
}
chunks <- Chunk{lastCharIsSpace, buffer[:bytes]}
lastCharIsSpace = IsSpace(buffer[bytes-1])
}
close(chunks)
一旦完成,我们可以简单地将每个worker得到的计数(count)汇总来得到总的word count:
totalCount := Count{}
for i := 0; i < numWorkers; i++ {
count := <-counts
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
close(counts)
让我们运行它,并且看看它与C语言版wc的运行结果比较(见下表):
从上表可以看出,我们的wc现在快了很多,但在内存使用方面出现了相当大的倒退。特别要注意我们的输入循环如何在每次迭代中分配内存的!channel是共享内存的一个很好的抽象,但是对于某些用例来说,简单地不使用channel通道可以极大地提高性能。
使用Mutex并行化(wc-mutex)
在本节中,我们将允许每个worker读取文件,并使用sync.Mutex互斥锁确保读取不会同时发生。我们可以创建一个新的struct来处理这个问题:
type FileReader struct {
File *os.File
LastCharIsSpace bool
mutex sync.Mutex
}
func (fileReader *FileReader) ReadChunk(buffer []byte) (Chunk, error) {
fileReader.mutex.Lock()
defer fileReader.mutex.Unlock()
bytes, err := fileReader.File.Read(buffer)
if err != nil {
return Chunk{}, err
}
chunk := Chunk{fileReader.LastCharIsSpace, buffer[:bytes]}
fileReader.LastCharIsSpace = IsSpace(buffer[bytes-1])
return chunk, nil
}
然后,我们重写worker函数,让它直接从文件中读取:
func FileReaderCounter(fileReader *FileReader, counts chan Count) {
const bufferSize = 16 * 1024
buffer := make([]byte, bufferSize)
totalCount := Count{}
for {
chunk, err := fileReader.ReadChunk(buffer)
if err != nil {
if err == io.EOF {
break
} else {
panic(err)
}
}
count := GetCount(chunk)
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
counts <- totalCount
}
与前面一样,我们现在可以为每个CPU核心生成一个worker线程:
fileReader := &FileReader{
File: file,
LastCharIsSpace: true,
}
counts := make(chan Count)
for i := 0; i < numWorkers; i++ {
go FileReaderCounter(fileReader, counts)
}
totalCount := Count{}
for i := 0; i < numWorkers; i++ {
count := <-counts
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
close(counts)
让我们运行它,然后看看它与C语言版wc的运行结果比较(见下表):
可以看出,我们的并行实现运行速度比wc快了4.5倍以上,而且内存消耗更低!这是非常重要的,特别是如果你认为Go是一种自动垃圾收集语言的话。
结束语
虽然本文绝不暗示Go语言比C语言强,但我希望它能够证明Go语言可以作为一种系统编程语言替代C语言。
如果你有任何建议和问题,欢迎在评论区留言。
原文链接:
https://ajeetdsouza.github.io/blog/posts/beating-c-with-70-lines-of-go/
推荐阅读
我收集了12款自动生成器,无聊人士自娱自乐专用
如何用Neo4j和Scikit-Learn做机器学习任务?| 附超详细分步教程
谷歌母公司创始人双双引退,劈柴哥上位!
对话阿里云叔同:释放云价值,让容器成为“普适”技术
激辩:机器究竟能否理解常识?
Instagram个性化推荐工程中三个关键技术是什么?
从YARN迁移到k8s,滴滴机器学习平台二次开发是这样做的
丁磊向左,刘强东向右
华裔候选人Andrew Yang加密政策公布,如果当选美国总统这些法规将会实施
你点的每个“在看”,我都认真当成了AI
相关文章:
Android开源框架ImageLoader的完美例子
要使用ImageLoader就要到这里下载jar包: https://github.com/nostra13/Android-Universal-Image-Loader 然后导入项目中去就行了 项目文档结构图: 从界面说起,界面本身是没什么好说的,就是如何在xml当中进行定义罢了 有以下这么多…
“掘金”金融AI落地,英特尔趟出一套通关攻略
有人说,金融业是最大的AI应用场景,但不管怎样,不可否认的事实是金融业已经从数字化走向AI化。某种程度上,AI与金融业有着天然的契合性:其一,金融业本身就是以数据为基本元素的行业,它为AI的模型…
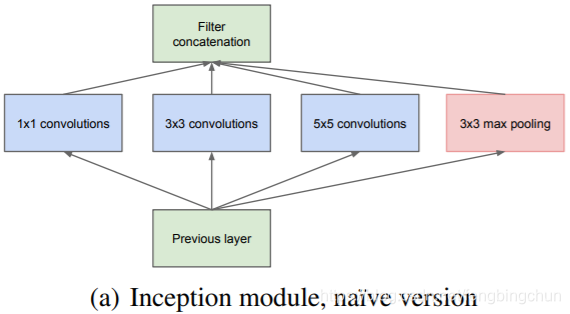
深度神经网络中的Inception模块介绍
深度神经网络(Deep Neural Networks, DNN)或深度卷积网络中的Inception模块是由Google的Christian Szegedy等人提出,包括Inception-v1、Inception-v2、Inception-v3、Inception-v4及Inception-ResNet系列。每个版本均是对其前一个版本的迭代改进。另外,依…

iOS隐藏导航栏的方法
- (void)viewWillAppear:(BOOL)animated { [super viewWillAppear:animated]; [self.navigationController setNavigationBarHidden:YES animated:animated]; }
NEW关键字的三种用法
声明:本文最初是本人从他出转载到51CTO上的一篇文章,但现在记不清最初从出处了,原文作者看到还请原来,现在发表在这里只为学习,本人在51CTO的该文章的地址为:http://kestrelsaga.blog.51cto.com/3015222/75…
论文解读 | 微信看一看实时Look-alike推荐算法
作者丨gongyouliu编辑丨lily来源 | 授权转载自大数据与人工智能(ID:ai-big-data)微信看一看的精选文章推荐(见下面图1)大家应该都用过,微信团队在今年发表了一篇文章来专门介绍精选推荐的算法实现细节(Real-time Attention based Look-alike Model,简称R…
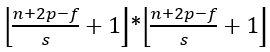
经典网络GoogLeNet介绍
经典网络GoogLeNet由Christian Szegedy等于2014年提出,论文名为《Going deeper with convolutions》,论文见:https://arxiv.org/pdf/1409.4842v1.pdf GoogLeNet网络用到了Inception-v1模块,关于Inception模块的介绍可以参考&…
iOS webview 点击按钮返回上一页面或者返回首页
- (void)floatBtn:(UIButton *)sender { NSLog("点击"); if ([self.webView canGoBack]) { [self.webView goBack]; } else{ [self.view resignFirstResponder]; [self.navigationController popViewControllerAnimate…

centos6.6 Kickstart无人值守安装(一):原理篇
为什么80%的码农都做不了架构师?>>> #为什么要自动化无人值守安装? 偷懒……nb……zb……geekno no no 瞬间完成大规模机器部署,提高生产力,节省时间精力,为公司谋取更多利益,实现社会和谐!#怎…
拿来就能用!如何用 AI 算法提高安全运维效率?
作者 | 黄龙责编 | 伍杏玲来源 | CSDN(ID:CSDNnews) 在整个安全工作中,安全运维是不可或缺的一环,其目的是保证各项安全工作持续有效地运作。除了对外的沟通和业务对接相关工作,大部分安全运维的日常工作相…
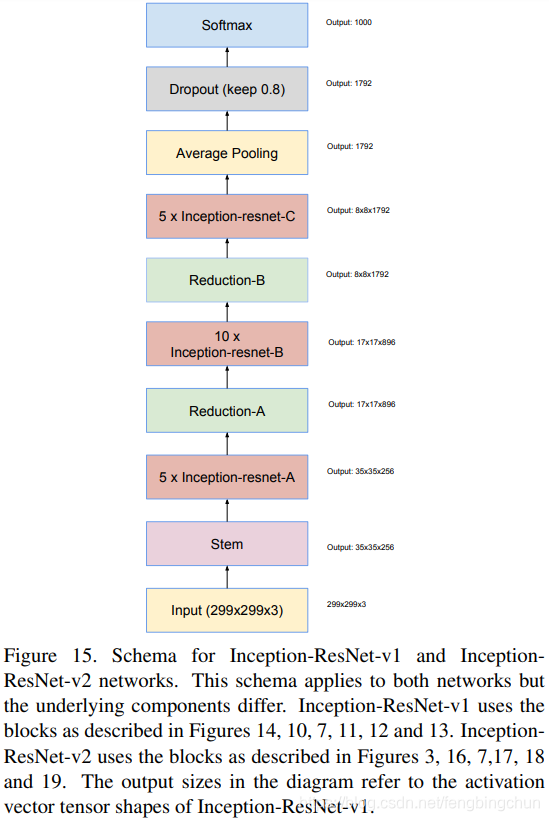
深度神经网络中Inception-ResNet模块介绍
之前在https://blog.csdn.net/fengbingchun/article/details/113482036 介绍了Inception,在https://blog.csdn.net/fengbingchun/article/details/114167581 介绍了ResNet,这里介绍下深度神经网络中的Inception-ResNet模块。 介绍Inception-ResNet的论文…
iOS 让UIView的左上角和右上角为圆角
-(UIView *)platFormBGV{ if (!_platFormBGV) { _platFormBGV [[UIView alloc] init]; _platFormBGV.backgroundColor [UIColor whiteColor]; _platFormBGV.frame CGRectMake(0, self.view.frame.size.height, APP_WIDTH, 220); // 左上和右上为圆角 UIBezierPath *cornerRa…
HttpUnit学习笔记
HttpUnit 能模拟浏览器的动作,如提交表单、JavaScript执行、基本HTTP认证、cookies建立以及自己主动页面重定向,通过编写代码能够处理取回来的文本、XML DOM或表单、表、链接。当与Junit等框架结合时,就能很easy地进行一个站点的功能測试了。…
C++11中头文件type_traits介绍
C11中的头文件type_traits定义了一系列模板类,在编译期获得某一参数、某一变量、某一个类等等类型信息,主要做静态检查。 此头文件包含三部分: (1).Helper类:帮助创建编译时常量的标准模板类。介绍见以下测试代码: …
反季大清仓,最低仅需34.9元
不知不觉已经12月份了还有一个月就要过年啦很多地方已经进入了寒冬的季节有的地方已经开启了下雪模式纷纷开始买冬天的商品棉衣、羽绒服、取暖器......但是.......今天我是来搞反季清仓的快来看看今天的反季清仓有啥商品~●反季清仓商品—程序员专属定制T ●专属定制T_shirt&am…
iOS 预览word pdf 文件
此类用于改变QLPreviewController 导航栏title #import <QuickLook/QuickLook.h> NS_ASSUME_NONNULL_BEGIN interface QLPreviewController (title) property (nonatomic, strong) NSString *qlpTitle; end NS_ASSUME_NONNULL_END #import "QLPreviewControllertitl…
Java过滤器模式
//创建一个类,在该类上应用标准 public class Person { private String name; private String gender; private String maritalStatus; public Person(String name, String gender, String maritalStatus) { this.name name; …
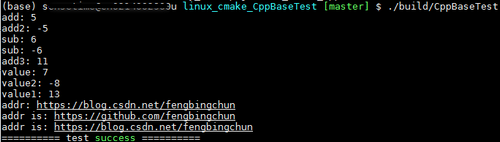
C++中指向类成员指针的用法
C中,指向类的成员指针包含两种: (1).指向类的成员函数的指针: 类型 (类名::* 函数成员指针名)(参数表); 函数成员指针名 &类名::函数成员名; 也可将以上两条语句调整为一条语句: 类型 (类名::* 函数成员指针名)(参数表) &…
多模态人物识别技术及其在爱奇艺视频场景中的应用 | 公开课笔记
【12月公开课预告】,入群直接获取报名地址12月11日晚8点直播主题:人工智能消化道病理辅助诊断平台——从方法到落地12月12日晚8点直播:利用容器技术打造AI公司技术中台12月17日晚8点直播主题:可重构计算:能效比、通用性…
JsonObject json字符串转换成JSonObject对象
字符串:{"code":"1004","msg":"请先添加系统靠勤人员信息!","userRegistInfo":{"acc":"小谷","id":0,"phoneMac":"","phoneNum":"…
基于人脸关键点修复人脸,腾讯等提出优于SOTA的LaFIn生成网络
作者 | Yang Yang、Xiaojie Guo、Jiayi Ma、Lin Ma、Haibin Ling译者 | 刘畅编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导语】现实场景中,人脸的变化是很大的,例如不同的姿势、表情和遮挡等,因此在现…

在Ubuntu上编译opencv 2.4.13源码支持android平台操作步骤
之前在https://blog.csdn.net/fengbingchun/article/details/96430706中编译过opencv源码用于海思平台,这里通过修改脚本编译opencv 2.4.13.6源码,使其支持android平台。 1. 从https://github.com/opencv/opencv/releases下载opencv 2.4.13.6源码&#…
Java组合模式
组合模式:适用于把一组相似的对象当作一个单一的对象,组合迷失一句树形结构来组合对象,用来表示部分以及整体层次。这种类的设计模式属于结构型模式,他创建了对象组的树形结构 这种模式创建了一个包含自己对象组的的类。给类提供了…

SQL故障转移集群操作方法
SQL故障转移集群操作方法1 给SQL服务器配置IP地址,每台服务器需要两个IP,一个通讯用,一个作为心跳线,修改计算机的名称,关闭服务器的防火墙,开启远程桌面.2心跳网卡配置去掉ipv6,并去掉下列几项进行验证3域控制器服务器管理器 添加角色 AD域服务启动AD域服务加入到域中打开DNS服…
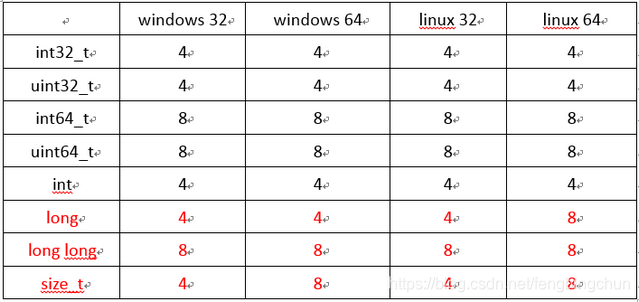
Windows/Linux上使用fopen相关函数读取大文件
在介绍读取大文件之前,先了解下<cstdint>文件,标准头文件,存放固定宽度整数类型,如int32_t, uint32_t,不管在32位上还是64位上,长度都为4个字节;int64_t, uint64_t,不管在32位…
蚂蚁金服提新概率图模型GLN,正确率提升8.2%,具备可解释性 | NeurIPS 2019
作者 | 蚂蚁金服编辑 | Jane出品 | AI科技大本营(ID;rgznai100)【导读】一年一度的国际顶级学术会议NeurIPS 2019将于12月8日至14日在加拿大温哥华举行。作为人工智能和机器学习领域最顶级的盛会之一,每年都会吸引来自全世界的AI大…
Java外观模式
外观模式:隐藏系统的复杂性,并向客户提供了一个客户端可以访问系统的接口,这种类型的设计模式属于结构型模式,他向现有的系统添加一个接口,来隐藏系统的复杂性 这种模式设计到一个单一的类,该类提供了客户请…
【spring框架】spring整合hibernate初步
spring与hibernate做整合的时候,首先我们要获得sessionFactory。我们一般只需要操作一个sessionFactory,也就是一个"单例",这一点很适合交给spring来管理。下面的代码演示如何创建一个JDBC DataSource 和Hibernate SessionFactory:…
PyTorch简介
PyTorch是一个针对深度学习,并且使用GPU和CPU来优化的tensor library(张量库)。最新发布的稳定版本为1.9,源码在https://github.com/pytorch/pytorch 。它支持在Linux、Mac和Windows上编译和运行。调用Python接口可以通过Anaconda或Pip的方式安装&#x…
Java 责任链模式
顾名思义,责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。 在这种模式中,通常每个接收者…