拿来就能用!如何用 AI 算法提高安全运维效率?
作者 | 黄龙
责编 | 伍杏玲
来源 | CSDN(ID:CSDNnews)
在整个安全工作中,安全运维是不可或缺的一环,其目的是保证各项安全工作持续有效地运作。除了对外的沟通和业务对接相关工作,大部分安全运维的日常工作相对固定,如漏洞审核、安全产品运维、日志审计和应急响应等工作。
安全工程师除了需要具备一些基础的安全技能,通常还需要具备发现问题的能力和举一反三的能力,比如在漏洞审核是发现一个反射型XSS漏洞,需要思考这个问题是否是通用的问题,通过哪些途径(搜索引擎、业务日志、扫描器脚本等)能发现和挖掘出同类问题,以达到通过问题发现本质。
这些要求和能力所需要的技术,往往也在不断地发展。
技术发展
随着互联网、物联网、大数据和云计算的快速发展,整个IT行业的技术栈都在快速发展,这里我们来简单看一下安全工程师对日志进行安全分析的技术发展史。
早期的业务量不多,技术栈简单,业务复杂度不高,通常日志的量级还不算太大,往往通过简单的命令(awk/sort/cat/find等)或者简单的shell/Python/perl脚本,再加上工程师人肉分析来进行处理。比如入侵排查和响应,分析结果和效率往往特别依赖于安全工程师的日志分析能力、经验和Linux操作的熟练度以及脚本的编写使用。
随着互联网的发展,业务量快速增加和技术栈的高速发展,日志越来越多,需要进行日志分析的平台也快速提升,HDFS和ELK(Elasticsearch + Logstash,Kibana)就应运而生。HDFS作为离线分析,安全工程师可以通过简单的Hive SQL完成一些分析和统计工作;ELK一般作为集中日志分析系统,在搜集、展示和查询方面非常灵活,更加简单易用。所以这个时候的日志分析和问题排查,基本上只依赖于安全工程师的日志分析能力和安全经验,而一些hive sql或者es查询语法,学习成本是非常低的。
随着日志量越来越大,一方面日志量越来越大,日志分析的效率需要提高;另一方面很多安全分析的需求也不简单的是一些特征关键字和统计能完成的,可能有些需要依赖于前面的行为等,这时候安全工程师就需要新的工具来进行支撑。
面临的问题
当下,安全运维工作有两个重要指标:效果和效率。
前面我们提到安全运维工程师需要进行安全分析,随着现在业务的快速发展和技术栈复杂度的提升,工程师每天面对的是海量的数据,很多时候的工作可能都是大海捞针,工程师面对海量的日志数据,如何快速地定位问题,以及如何挖掘出更多的安全风险都是急需解决的问题。
安全工程师在运维安全产品的时候,需要通过自身的能力来提升一些安全产品的效果,如降低WAF的漏报情况,安全运维人员或多或少都做过以下一些工作:
比较简单的做法可能就是不停的搜集各种攻击的Payload,进行攻击测试;
除了搜集Payload外,深入一点的做法一般是通过梳理关键字/特征从ES或者HDFS提取疑似攻击日志,进行人工分析;
随着大数据平台和威胁情报的发展,再进一步的方式会考虑将已经发现攻击的IP和威胁情报的扫描IP的对应的请求进行梳理,进行二次分析;
比较理想的做法是对全量日志进行分析,提取攻击行为日志,根据日志提取特征。
这里我们会发现,随着日志量的越来越大,依赖人肉分析大量数据是不现实的。虽然抽样分析和正则或规则匹配也是一种折中方案,但是会存在一定的遗漏风险。这个时候,我们需要通过一些更优的方案和工具,能够快速高效地从海量数据中发现更多未知的问题,而机器学习很可能就是我们的答案。
AI赋能安全运维工作初探
安全与机器学习
目前在安全领域已经有很多方向尝试借助机器学习来解决问题,如恶意软件检测、违规图片识别,垃圾邮件识别,UEBA等。
机器学习在垃圾邮件、风控系统和违禁图片识别方向是效果比较显著的,比如对违禁图片进行打标,通过机器学习进行自动分类:
现阶段,大部分机器学习仅仅是融入到各种安全产品中,而在基础安全领域并没有得到很好的利用。一方面是机器学习本身有一定的成本,在日常运维中使用有一定的门槛;另一方面在基础安全领域的机器学习的效果受制于样本的限制,比如在Webshell的检测中,我们发现现有的Webshell样本是远远不够的,有些时候我们会在实践过程中发现,算法的准确性还不如一些简单的规则。
实际上,并不是所有的场景都适合现阶段的机器学习落地,这里我们先来关注一些适合机器学习的场景,比如大量日志数据的处理和分析。
前面的分析我们已经知道,面对大量日志的分析和处理,我们之前使用的初级工具(shell命令、Python脚本等)和中级工具(ES搜索、HiveSQL等)等都已经满足不了我们的需求了,这时候我们就需要使用机器学习这个高级工具了。
通过日志分析发现异常用户
背景介绍
日志分析和审计在安全运维工作中经常遇到,这里我们考虑一个很简单的日志审计需求:有一个业务,提供了敏感接口的访问日志,需要安全工程师发现哪些人有问题。
针对这类问题,目前比较常见的分析方式主要是基于统计方式,最常见的就是频次统计,比如每个员工的访问阈值是100次/天,当超过了100次我们就报警。这类的分析统计实现是比较简单的,通过时间窗口来实现。
这里,为了展示方便,我选取了一个访问量小的业务,用其中一个功能的访问日志做说明。
简单分析
日志记录的主要信息是:谁在什么时间,在什么地点,对谁做了什么事情?
这里面,每一个维度可以单独分析,同时也可以联合分析,很多时候结果完全依赖于运营人员的经验或者是系统的规则。
通常情况下,我们分析的维度包括:
频率:单个用户在一段时间范围内的行为超过了某个阈值;
时域:在特定的时间做这件事情,如在凌晨3点,下载了3份文件;
地点:通常情况是IP,这里可以和威胁情报做Join,也可以根据业务做分析,比如是员工通过一台美国的服务器访问了xx系统;
这些条件还可以组合,综合一些规则条件来处理。当然,再复杂一点就是一个简单的日志行为分析系统了。
我们考虑一些场景,如果是一些应急的分析需求,日志量有不小,我们怎么来快速进行分析呢?或者是已经有很多日志数据了,因为数据量太大而没有利用起来,我们是否能挖掘其中的价值呢?
这里我们尝试使用机器学习的算法来进行一些分析。
具体实例——发现异常用户
很多时候,我们的需求是发现异常用户行为,所以需要有工具帮助我们快速提取异常的用户行为。有过日志分析经验的同学应该会有这样的经验:通常情况下,大部分的用户基本都是正常请求;有部分用户的请求是异常;但是异常的情况之间往往有很大的差异。简单来说就是正常的人都差不多,奇葩的人可能有各种奇葩。那么,我们怎么去提取这些“奇葩”呢?
最理想的情况就是通过机器学习的算法,直接区分出正常和异常的用户。正如我们前面提到的,异常的情况可能是多种多样,所以这里我们不能简单的进行二分类,而是考虑使用聚类算法,先进行分类,再针对各类的用户进行针对性的分析,这里我们尝试使用K-Means算法。
上图就是通过K-Means算法分簇效果展示,通过图表相信大家比较容易理解。
很多时候一开始分析日志时,我们并不清楚正常访问和异常访问具体的特征和区别,所以这里使用 K-Means算法,K-Means本身是无监督学习算法,所以我们在使用时并不需要花费大量的时间来搜集样本,并进行模型训练(终于不用像识别图片验证码那样整理一大堆的样本文件了)。
另外一个很重要的原因就是K-Means算法非常容易实现,上手也比较容易,简单的来说就是先根据请求的特性进行分类,然后我们去掉正常的请求(通常情况下数量最多的一簇),针对其他簇(异常)进行深入分析。
K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
有关“簇”和“质心”参考下图:
这里具体的原理我们暂时不做解释,感兴趣的同学可以通过搜索引擎自行了解。
算法实践
为了大家方便了解,我们提取了部分数据做一个简单的分析演示。
这是某个系统,敏感接口的访问日志(IP地址和页面信息已经做了脱敏处理),我们现在简单的从用户的访问频次来进行分析。
我们现在主要目的是区分正常用户和异常用户,这里我们并没有之前的用户数据参考,所以选择非监督学习的K-Means算法。
提取特征
首先是提取特征,为了方便演示,我们这里仅使用单个维度特征(用户每天的访问次数):
我们可以先直接通过折线图看一下各个用户的访问情况:
通过访问情况图表,我们只能比较直观的观察到一些比较明显的数量较多的情况。
因为这个特征本身是数字特征,所以可以直接作为算法的特征,又是单一维度,也省掉了特征转换的一个过程。
提取完特征,我们借助K-Means算法来进行分类,算法会根据业务情况将数据分为几类,到底分为几类需要用户指定,那到底几类比较合理呢?我们可以通过一些方法帮我们决定。
比较直观和常用的方法时肘部法则(Elbow Method),我们来看一下运行的结果:
我们可以看到,通过画K与cost function的关系曲线图,如左图所示,肘部的值(cost function开始时下降很快,在肘部开始平缓)做为K值,K=4。
PS:并不是所有的问题都可以通过画肘部图来解决,这里使用肘部图是为了方便让大家观察。
这里,我们直接调用sklearn中的KMeans算法:
分类完成,发现异常情况
通过K-Means分类,我们可以发现这四类的情况:
0簇的用户最多,139个,根据我们的经验判断这139个用户是正常的。所以我们的重点可以放在后面3个簇中,即关注用户25,28,49,52的行为。
这里我们观察一下这4个异常用户的访问情况,我们可以看到这几个异常用户确实是可疑用户,和我们之前通过阈值分析结果匹配,并且还有些行为特定,如突然某一天的访问量都突然增多。
说明:
K-Means很多时候只能帮助我们进行分簇,并不能直接解决问题,分类之后的工作还是需要安全工程师人工进行分析。
如果面对海量的用户访问数据,通常情况下正常用户的访问占大部分(特别是内部系统),所以使用算法能够帮助我们排除大量正常的数据,让安全工程师更专注于异常的数据分析,可以大大的提高我们的分析效率。
小结
在一些UBA/UEBA的产品中,也是使用了K-Means算法或者其他的聚类算法。当然,在实际情况中远远不止这些工作,从特征提取到模型训练,交叉对比等机器学习有一套完整的工程化流程。
同时,我们也需要注意,并非所有的异常都是有安全问题的,这里就需要安全运营通过对业务的敏感性,以及和业务对接的方式去分析和排查。
WAF漏报问题优化
背景介绍
前段时间在护网行动发现, WAF(Web Application Firewall)基本已经成为各个公司的标配了。我们都知道WAF确实能帮助我们拦截很多Web应用攻击,作为运维人员,都会面对一个触及灵魂的问题:如何评估WAF的拦截效果?漏报率怎么样,误报率怎么样?
我想想大部分运维人员都会有自己的测试工具,包含搜集的一些特定的攻击测试样例,定期做一些评估测试,如:
通常情况下,有基础的测试用例和持续的运营,误报我们比较容易发现和及时处理。但是漏报的问题大家很难评估,尽管我们已经梳理了各种攻击和漏洞利用的场景。
但是在复杂的互联网环境和云环境,如果我们仔细分析日志,还是会发现有不少漏过的情况。
正如我们前面提到的,除了Payload搜集和简单关键字提取外,常见的做法就是可疑请求打标。简单来讲就是将所有已经拦截过的请求的IP,在一定时间需求内的请求都打上可疑的标签,当然IP维度还可以包含一些威胁情报的扫描IP,或者是全量日志直接分析。
这里,我们的目的就是从这些可疑或者全量日志中,提取出特定的攻击日志,以降低我们的人工分析量。
具体实例——XSS攻击日志挖掘
很多时候我们想提升我们WAF的拦截效果,降低漏报,就需要对日志进行分析和攻击行为提取,并转换为拦截规则。
前面我们已经讲了使用K-Means可以帮助我们进行分类的方法,这里我们换一个思路,我们针对XSS这个类型的漏报日志进行提取。
算法实践
1、样本搜集
在WAF的运维期间,已经搜集了很多XSS攻击的Payload和日志,这里我们再整理一些正常的请求日志。
这样我们就已经有了正样本和负样本,可以尝试通过监督度学习,从请求日志中挖掘我们的漏网之鱼。
2、特征提取
因为需要发现XSS攻击,所以我们首先需要简单地梳理一下XSS Payload的特征,XSS攻击通常如下:
很可能包含一些HTML标签或者事件属性,比如html标签<script>, <img>, <style>等,比如事件属性 onerror, onload等所有on事件, src, href等;
通常情况下,需要闭合,比如 ‘, “, </script>, </textarea>等;
可能包含一些探测关键字/函数,比如 xss, alert(1), document.cookie等;
通常情况下,如果黑客进行利用需要引入三方js,需要注意短链接等;
通常情况下,在js中需要连接字符,比如注释后面//, 比如连接可执行js代码 ;, -,+, /,*, ^, &等;
去掉闭合支付之后,是一些可解析执行的js语句或者HTML语句。
……
从安全工程师的角度去分析,我们能发现很多特征,但是这里我们需要学习如何把这些特征转换为机器能够识别的特征。
作为文本特征的提取,首先是分词,然后对分词的特征进行处理。再想办法把这些特征进行处理,让他们变成机器能识别的特征向量。比较简单的特征提取方式就是直接针对敏感字符/关键字的个数进行统计和分析,这个更符合统计学的思路,感兴趣的朋友可以参考《Web安全之机器学习入门》。
这里我们尝试另一种思路,选择嵌入式词向量(Word embedding),嵌入式词向量就是通过学习文本来用词向量表征词的语义信息,通过将词嵌入空间使得语义相似的词在空间内的距离接近。
因为XSS攻击通常执行的是HTML/JavaScript脚本,是具有一些语义的关联。这里我们可以使用嵌入式词向量模型,建立一个XSS的语义模型,让机器能够理解< script>、alert()这样的语言,这样看起来更符合人类分析的模式。
首先我们进行分词:
然后取正样例中出现次数最多的300个词,构成词汇表(其他词统一用特定的字符如“NSRC”替代),使用gensim模块的word2vec类处理。
我们可以看看XSS Payload的部分分词情况:
分类完成,挖掘XSS攻击
同样的,我们把正常样本也进行类似的处理,然后这里我们使用支持向量机(Support Vector Machines, SVM)算法进行识别。SVM比较适合二分类问题,即我们所说的好/坏的情况。
SVM是一种监督学习算法,在学习复杂的非线性方程时,能够提供一种更为清晰和更加强大的方式。之前很多有使用SVM进行图片验证码识别,识别的效果也是挺不错的。
而在Python中,我们通过直接引入sklearn的SVM算法实现即可直接调用:
from sklearn.svm import LinearSVC通过已有的数据测试,SVM数据的准确率基本上是98%,召回率是97%。
这时候我们就开始对日志进行分析,通过SVM的训练模型进行查找,确实发现了很多我们之前没有发现的情况。
对发现的日志进行人工分析,有些场景的误报比较多,特别是参数值包含http请求的情况,这个和我们之前提取的特征有密切关系。
这里我们通过其他维度分析出的日志对比可以发现,目前我们使用Word2vec+SVM的算法还是存在一些漏报的情况:
后续
通过前面的机器学习算法,帮助我们顺利从日志中发现了更多的XSS攻击,虽然还存在一些漏报和误报的情况,但是已经比之前的一些简单的规则好了很多。
SVM算法的实现比较简单,而且性能资源消耗低,不过缺点可能是泛化能力相对较弱,发现问题有限,并不是特别的“智能”,这点通过我们分析的SVM漏报结果就可以发现。
感兴趣的朋友可以考虑一下特征优化和尝试下其他的算法。
总结
随着数据的爆发和算力性价比的提升,相信未来机器学习会越来越普及。
我们完全把算法看作一个高级工具(并没有去讲解算法本身的复杂原理),来提升安全运维工作的价值。
建议
了解机器学习,尝试通过机器学习的视角去了解和解决问题,把机器学习的各种算法当作一个解决问题的工具,就像木工使用锤子一样,先用起来,再慢慢去了解其原理。
在尝试机器学习算法时要考虑几个条件:
数据量是否较大;
样本是否足够;
安全工程师判断成本(是否直观):比如违禁图片的标签是很容易判断的,而人机识别提取的行为数据是运营很难直接判断的,所以后者的成本远比违禁图片识别高。
另外,在运维环节可以多尝试机器学习的算法和模型(离线),不建议在线上落地。线上落地需要比较专业的工程化和机器学习团队来处理,涉及到成本、效果保证、执行效率、处理结果的相关性以及回放数据对比等一些列因素;
参考:
https://www.jianshu.com/p/942d1beb7fdd
http://www.webber.tech/posts/%E4%BD%BF%E7%94%A8%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%A3%80%E6%B5%8BXSS/
《Web安全之机器学习入门》
作者简介:黄龙,网易易盾资深安全工程师,专注于互联网安全,擅长安全攻防对抗和甲方安全建设,拥有CISSP认证,同时也是网易云课堂《Web安全工程师》微专业核心制作人。
推荐阅读
远场语音识别错误率降低30%,百度提基于复数CNN网络的新技术
微软张若非:搜索引擎和广告系统,那些你所不知的AI落地技术
程序员的救星-ThinkPad T490 对比体验
C++控制台打飞机小游戏 | CSDN 博文精选
激辩:机器究竟能否理解常识?
Instagram个性化推荐工程中三个关键技术是什么?
从YARN迁移到k8s,滴滴机器学习平台二次开发是这样做的
华为将正式起诉美国联邦通信委员会;谷歌技术故障导致美国三大航空公司网站短暂宕机;英特尔拟20亿美元买以色列AI芯片公司……
2020年,区块链开发者还有哪些期待?
你点的每个“在看”,我都认真当成了AI
相关文章:
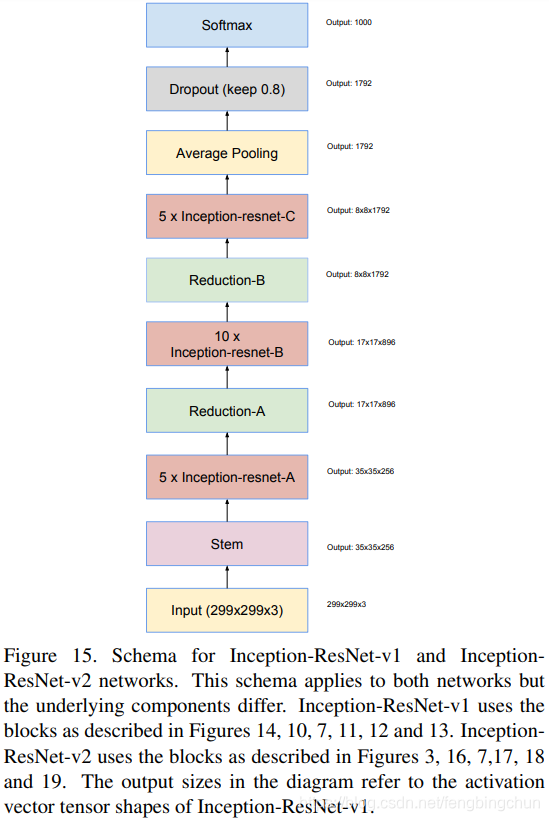
深度神经网络中Inception-ResNet模块介绍
之前在https://blog.csdn.net/fengbingchun/article/details/113482036 介绍了Inception,在https://blog.csdn.net/fengbingchun/article/details/114167581 介绍了ResNet,这里介绍下深度神经网络中的Inception-ResNet模块。 介绍Inception-ResNet的论文…

iOS 让UIView的左上角和右上角为圆角
-(UIView *)platFormBGV{ if (!_platFormBGV) { _platFormBGV [[UIView alloc] init]; _platFormBGV.backgroundColor [UIColor whiteColor]; _platFormBGV.frame CGRectMake(0, self.view.frame.size.height, APP_WIDTH, 220); // 左上和右上为圆角 UIBezierPath *cornerRa…
HttpUnit学习笔记
HttpUnit 能模拟浏览器的动作,如提交表单、JavaScript执行、基本HTTP认证、cookies建立以及自己主动页面重定向,通过编写代码能够处理取回来的文本、XML DOM或表单、表、链接。当与Junit等框架结合时,就能很easy地进行一个站点的功能測试了。…
C++11中头文件type_traits介绍
C11中的头文件type_traits定义了一系列模板类,在编译期获得某一参数、某一变量、某一个类等等类型信息,主要做静态检查。 此头文件包含三部分: (1).Helper类:帮助创建编译时常量的标准模板类。介绍见以下测试代码: …
反季大清仓,最低仅需34.9元
不知不觉已经12月份了还有一个月就要过年啦很多地方已经进入了寒冬的季节有的地方已经开启了下雪模式纷纷开始买冬天的商品棉衣、羽绒服、取暖器......但是.......今天我是来搞反季清仓的快来看看今天的反季清仓有啥商品~●反季清仓商品—程序员专属定制T ●专属定制T_shirt&am…
iOS 预览word pdf 文件
此类用于改变QLPreviewController 导航栏title #import <QuickLook/QuickLook.h> NS_ASSUME_NONNULL_BEGIN interface QLPreviewController (title) property (nonatomic, strong) NSString *qlpTitle; end NS_ASSUME_NONNULL_END #import "QLPreviewControllertitl…
Java过滤器模式
//创建一个类,在该类上应用标准 public class Person { private String name; private String gender; private String maritalStatus; public Person(String name, String gender, String maritalStatus) { this.name name; …
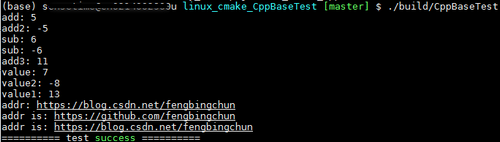
C++中指向类成员指针的用法
C中,指向类的成员指针包含两种: (1).指向类的成员函数的指针: 类型 (类名::* 函数成员指针名)(参数表); 函数成员指针名 &类名::函数成员名; 也可将以上两条语句调整为一条语句: 类型 (类名::* 函数成员指针名)(参数表) &…
多模态人物识别技术及其在爱奇艺视频场景中的应用 | 公开课笔记
【12月公开课预告】,入群直接获取报名地址12月11日晚8点直播主题:人工智能消化道病理辅助诊断平台——从方法到落地12月12日晚8点直播:利用容器技术打造AI公司技术中台12月17日晚8点直播主题:可重构计算:能效比、通用性…
JsonObject json字符串转换成JSonObject对象
字符串:{"code":"1004","msg":"请先添加系统靠勤人员信息!","userRegistInfo":{"acc":"小谷","id":0,"phoneMac":"","phoneNum":"…
基于人脸关键点修复人脸,腾讯等提出优于SOTA的LaFIn生成网络
作者 | Yang Yang、Xiaojie Guo、Jiayi Ma、Lin Ma、Haibin Ling译者 | 刘畅编辑 | Jane出品 | AI科技大本营(ID:rgznai100)【导语】现实场景中,人脸的变化是很大的,例如不同的姿势、表情和遮挡等,因此在现…

在Ubuntu上编译opencv 2.4.13源码支持android平台操作步骤
之前在https://blog.csdn.net/fengbingchun/article/details/96430706中编译过opencv源码用于海思平台,这里通过修改脚本编译opencv 2.4.13.6源码,使其支持android平台。 1. 从https://github.com/opencv/opencv/releases下载opencv 2.4.13.6源码&#…
Java组合模式
组合模式:适用于把一组相似的对象当作一个单一的对象,组合迷失一句树形结构来组合对象,用来表示部分以及整体层次。这种类的设计模式属于结构型模式,他创建了对象组的树形结构 这种模式创建了一个包含自己对象组的的类。给类提供了…

SQL故障转移集群操作方法
SQL故障转移集群操作方法1 给SQL服务器配置IP地址,每台服务器需要两个IP,一个通讯用,一个作为心跳线,修改计算机的名称,关闭服务器的防火墙,开启远程桌面.2心跳网卡配置去掉ipv6,并去掉下列几项进行验证3域控制器服务器管理器 添加角色 AD域服务启动AD域服务加入到域中打开DNS服…
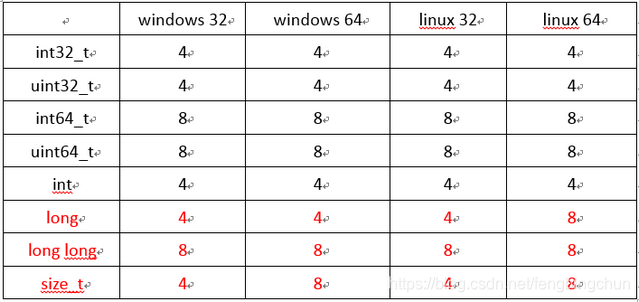
Windows/Linux上使用fopen相关函数读取大文件
在介绍读取大文件之前,先了解下<cstdint>文件,标准头文件,存放固定宽度整数类型,如int32_t, uint32_t,不管在32位上还是64位上,长度都为4个字节;int64_t, uint64_t,不管在32位…
蚂蚁金服提新概率图模型GLN,正确率提升8.2%,具备可解释性 | NeurIPS 2019
作者 | 蚂蚁金服编辑 | Jane出品 | AI科技大本营(ID;rgznai100)【导读】一年一度的国际顶级学术会议NeurIPS 2019将于12月8日至14日在加拿大温哥华举行。作为人工智能和机器学习领域最顶级的盛会之一,每年都会吸引来自全世界的AI大…
Java外观模式
外观模式:隐藏系统的复杂性,并向客户提供了一个客户端可以访问系统的接口,这种类型的设计模式属于结构型模式,他向现有的系统添加一个接口,来隐藏系统的复杂性 这种模式设计到一个单一的类,该类提供了客户请…
【spring框架】spring整合hibernate初步
spring与hibernate做整合的时候,首先我们要获得sessionFactory。我们一般只需要操作一个sessionFactory,也就是一个"单例",这一点很适合交给spring来管理。下面的代码演示如何创建一个JDBC DataSource 和Hibernate SessionFactory:…
PyTorch简介
PyTorch是一个针对深度学习,并且使用GPU和CPU来优化的tensor library(张量库)。最新发布的稳定版本为1.9,源码在https://github.com/pytorch/pytorch 。它支持在Linux、Mac和Windows上编译和运行。调用Python接口可以通过Anaconda或Pip的方式安装&#x…
Java 责任链模式
顾名思义,责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。 在这种模式中,通常每个接收者…
2019嵌入式智能国际大会圆满落幕,7大专场精彩瞬间释出!
全球第二大市场研究机构MarketsandMarkets报告称,2019年全球AIoT市场规模为51亿美元,到2024年,这一数字将增长至162亿美元。5G元年,人工智能开始更多地转向应用智能。基于此,12月6-7日,由哈尔滨工业大学&am…
ubuntu12.04 alternate win7 双系统安装
ubuntu alternate的安装比desktop复杂一点,因为alternate的安装过程有个步骤是检测cd-rom,如果你是刻盘安装,自然没问题,但是,现在的安装一般是将系统刻到U盘里,或者在硬盘中划出一个分区,将其制作成启动盘. 这里我是用U盘安装的... 安装前的准备: 1)在硬盘上分出一个空闲分区:…

C/C++包管理工具Conan简介
Conan是一个开源的、跨平台的、去中心化的C和C包管理器,它的源码在https://github.com/conan-io/conan ,License为MIT,最新发布版本为1.38.0,由Python实现。版本更新较频繁,但保持向前兼容。 Conan特点: (1…
神经架构搜索在视频理解中研究进展的综述
作者 | Michael S. Ryoo 研究员与 AJ Piergiovanni 学生研究员(Google 机器人团队)来源 | TensorFlow(ID:TensorFlow_official)视频理解一直是项颇具挑战性的难题。视频中包含时空数据,因此要提取特征表示需…
Java命令模式
命令模式(Command Pattern)是一种数据驱动的设计模式,它属于行为型模式。请求以命令的形式包裹在对象中,并传给调用对象。调用对象寻找可以处理该命令的合适的对象,并把该命令传给相应的对象,该对象执行命令…
关于本分类(codeforces-好题系列)
前前后后花了将近半个月,终于将吴神的十场cf的50题目补完了,看到了各种技巧和DP的好题,为了方便以后查阅,新增一个分类便于查找,当然本分类的题目其他分类一般都有,先去吃个饭,回来刷题解转载于…
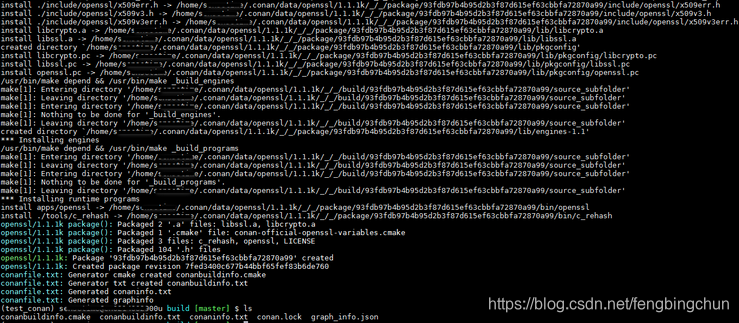
Conan客户端简单使用示例
在https://blog.csdn.net/fengbingchun/article/details/118443862 中对Conan进行了简单介绍,这里调用openssl的接口,写一个简单的test来说明Conan的使用步骤: (1).首先添加一个conanfile.txt文件,内容如下:依赖项为op…
Java解释器模式
解释器模式(Interpreter Pattern)提供了评估语言的语法或表达式的方式,它属于行为型模式。这种模式实现了一个表达式接口,该接口解释一个特定的上下文。这种模式被用在 SQL 解析、符号处理引擎等。 意图:给定一个语言&…
为什么鲜有炫富的程序员?看看中国各阶级收入统计表
网上那些口口声声随随便便就能年入百万的,听听就行。作为开发者,可以不参加双11,但是花钱最多的地方就是买电子产品和“买课”。他们的炫富就是:你根本不知道有多贵的机械键盘,为了赚钱和幸福,又买了多少大…
HQL中的Like查询需要注意的地方
public List getOrgan(String organCode, String organName) { String hsql; List list; if (organCode ! null && organCode.length() > 0) { hsql "from Ab31 where bae002 ? and aab061 like ?"; list getHibernateTemplate().find…