损失函数之Cross-Entropy介绍及C++实现
在深度学习中,损失函数用来评估模型的预测值与真实值之间的差异程度,是模型对数据拟合程度的反映,拟合的越差,损失函数的值越大;反之,损失函数越小,说明模型的预测值就越接近真实值,模型的准确性也就越好。深度学习的模型训练的目标就是使损失函数的值尽可能小。因此损失函数又被称为目标函数。深度学习的模型训练的过程就是不断地最小化损失函数。选择适合的损失函数不仅影响最终预测的准确性,而且影响训练的效率。
常用的损失函数包括:最小均方差损失函数、L1范数损失函数、L2范数损失函数、交叉熵损失函数等。
1948年,香农提出了信息熵的概念,并且发展为一门独立的学科,即信息论。香农将平均自信息量定义为信息熵,简称为熵。在信息论中,信息熵是为了消除不确定性所需的度量,为了验证概率低的事件,需要大量的信息,此时的信息熵很大;相反,为了验证概率高的事件,则需要少量的信息,此时的信息熵很小。
交叉熵用于度量分布之间的信息差异。交叉熵是信息论中的重要概念,熵是对不确定问题的度量准则,而交叉熵是信息论领域的一种度量,建立在熵的基础上,通常是用来度量两个概率分布之间信息的差异。
最小化交叉熵的过程也就是极大似然估计,深度学习训练的目的,就是最小化交叉熵,使预测的数据分布与真实的数据分布尽量相同。
交叉熵损失函数(Cross-Entropy Loss Function)通常被用来解决深度学习中的分类问题。
对于多分类,每个样本都有一个已知的类标签(class label),概率为1.0,所有其它标签的概率为0.0。模型(model)可以估计样本属于每个类别标签的概率。然后可以使用交叉熵来计算两个概率分布之间的差异。
如果一个分类问题具有三个类别,并且一个样本具有第一类的标签,则概率分布将为[1,0,0];如果一个样本具有第二类的标签,则它概率分布为[0,1,0]。
PyTorch中的交叉熵损失函数的计算还包含了Softmax。Softmax能将原网络输出转变为概率形式。
Softmax交叉熵损失函数是最常用的分类损失函数。若要将样本分为C个类别,在使用Softmax交叉熵损失时,需要将神经网络的最后一层输出设置为C,得到C个分数后输入Softmax交叉熵损失函数。
Softmax交叉损失函数实际上分为两步:求Softmax和求交叉熵损失,其中第一步操作可以得到当前样本属于某类别的概率,然后将这些概率与实际值One-Hot向量求交叉熵,因为实际值是仅在第y个位置为1,其它部分为0,所以最终只保留了第y个位置的交叉熵。
在深度学习样本训练的过程中,采用One-Hot形式进行标签编码,再计算交叉熵损失。在使用交叉熵损失函数的网络训练之前,需要将样本的实际值也转化为概率值形式。为达到这个目的,常用的方法为独热编码即One-Hot编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
Softmax的介绍参考:https://blog.csdn.net/fengbingchun/article/details/75220591
交叉熵损失函数公式如下:来自于:https://programmathically.com/an-introduction-to-neural-network-loss-functions/
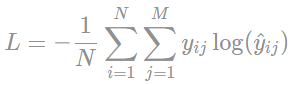
N:样本数;M:类别数;y:预期结果;y hat:模型产生的结果
交叉熵损失函数的C++实现如下:
template<typename _Tp> // y实际值; t预测值; m类别数
_Tp loss_function_cross_entropy(const _Tp* y, const _Tp* t, int m)
{_Tp loss = 0.;for (auto i = 0; i < m; ++i)loss += -y[i] * std::log(t[i]);return loss;
}测试代码如下:
int test_loss_function()
{
{ // only one sampleconst int classes_number = 5;std::vector<float> sample = { 0.0418, 0.0801, -1.3888, -1.9604, 1.0712 };std::vector<float> target = { 0, 0, 1, 0, 0 }; // One-Hotstd::vector<float> input(classes_number);assert(sample.size() == classes_number && target.size() == classes_number && input.size() == classes_number);fbc::activation_function_softmax(sample.data(), input.data(), classes_number);float output = fbc::loss_function_cross_entropy(target.data(), input.data(), classes_number);fprintf(stdout, "output: %.4f\n", output);
}{ // five samplesconst int classes_number = 5, samples_number = 5;std::vector<std::vector<float>> samples = {{0.0418, 0.0801, -1.3888, -1.9604, 1.0712 },{0.3519, -0.6115, -0.0325, 0.4484, -0.1736},{0.1530, 0.0670, -0.3894, -1.0830, -0.4757},{-1.3519, 0.2115, 1.2325, -1.4484, 0.9736},{1.1230, -0.5670, 1.0894, 1.9890, 0.03567}};std::vector<std::vector<float>> targets = {{0, 0, 0, 0, 1},{0, 0, 0, 1, 0},{0, 0, 1, 0, 0},{0, 1, 0, 0, 0},{1, 0, 0, 0, 0}};std::vector<std::vector<float>> inputs(samples_number);assert(samples[0].size() == classes_number && targets[0].size() == classes_number && inputs.size() == samples_number);float output = 0.;for (int i = 0; i < samples_number; ++i) {inputs[i].resize(classes_number);fbc::activation_function_softmax(samples[i].data(), inputs[i].data(), classes_number);output += fbc::loss_function_cross_entropy(targets[i].data(), inputs[i].data(), classes_number);}output /= samples_number;fprintf(stdout, "output: %.4f\n", output);
}return 0;
}执行结果如下:

调用PyTorch接口测试代码如下:
import torch
import torch.nn as nnloss = nn.CrossEntropyLoss()input = torch.tensor([[0.0418, 0.0801, -1.3888, -1.9604, 1.0712]])
target = torch.tensor([2]).long() # target为2,one-hot表示为[0,0,1,0,0]
output = loss(input, target)
print("output:", output)data1 = [[ 0.0418, 0.0801, -1.3888, -1.9604, 1.0712],[ 0.3519, -0.6115, -0.0325, 0.4484, -0.1736],[ 0.1530, 0.0670, -0.3894, -1.0830, -0.4757],[ -1.3519, 0.2115, 1.2325, -1.4484, 0.9736],[ 1.1230, -0.5670, 1.0894, 1.9890, 0.03567]]
data2 = [4, 3, 2, 1, 0]input = torch.tensor(data1)
target = torch.tensor(data2)
output = loss(input, target)
print("output:", output)执行结果如下:可见C++实现的代码与调用PyTorch接口两边产生的结果完全一致

GitHub:
https://github.com/fengbingchun/NN_Test
https://github.com/fengbingchun/PyTorch_Test
相关文章:

C语言应用于LR中-如何得到数组长度
C语言没有提供获取数组长度的函数,最起码我不知道,所以编写了一个函数取数组的长度,调试成功,大家可以试试。另外也可以用sizeof(a)/4来取得整型数组的长度,因为整型占4个字节。效果相同。#include "web_api.h&qu…
6个你必须知道的机器学习的革命性的教训
加入「公开课」交流群,获取更多学习资料、课程及热招岗位等信息作者 | James Warner编译 | ronghuaiyang来源 | 转载自AI公园(ID:AI_Paradise)【导读】机器学习是未来,因为它将广泛应用于计算机和其他领域。尽管如此,开发有效的机…
vim ctags使用方法
一、用好系统自带软件ctags大部分的unix系统都有ctags软件,它能跟vim很好地合作。用途:生成c语言的标签文件,实现相关c文件之间的跳转。用法:1.生成标签文件在当前目录下(运行$提示符后面的命令): $ctags -R .-R表示recursive,递归,为当前目录…
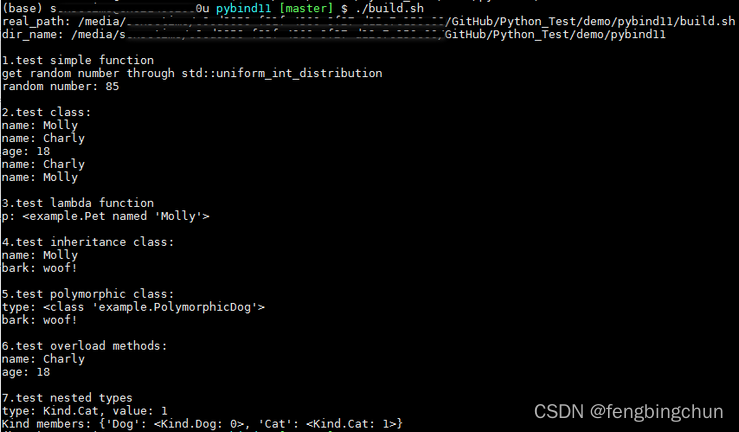
pybind11介绍
pybind11是一个轻量级的仅头文件库,主要用于创建现有C代码的Python绑定,它的源码在https://github.com/pybind/pybind11,license为BSD,最新发布版本为2.9.1。 可将pybind11库视为Boost.Python的一个小型自包含版本(Think of this …
改善AI性别偏见的4种方法 | CSDN博文精选
加入「公开课」交流群,获取更多学习资料、课程及热招岗位等信息作者 | Josh Feast翻译 | 王子龙校对 | 王琦本文阐述导致AI偏见的原因并提出应用的解决方案。任何对AI偏见的审查都需要意识到一个事实:这些偏见主要源于人类固有的偏见。我们创建、训练的模…
C#程序调用外部程序
/**编程语言:VisualStudio.NetC#(Beta2)*作者:迪泊威*功能:通过C#程序调用Windows记事本程序编辑一个*名为test.txt的文本文件。**在整个程序中System.Diagnostics.Process.Start(Info)*为主要语句。*如果只是单独执行一个外部程序࿰…
svn 同步脚本
REPOS"$1"REV"$2"export LANGen_US.UTF-8/usr/bin/svn update /home/wwwroot/yswifi --username yangxc --password yangxc >>/tmp/svn_hook_log.txtecho who am i,$REPOS,$REV >> /tmp_hook_var.txt转载于:https://www.cnblogs.com/xkcp008/p…
DevOps火爆,招人却太难了!
DevOps一词最近两年人们谈的比较多,很多人简单地理解为“Dev”“Ops”,是否将开发人员和运营人员放在一个部门就完事了呢?其实DevOps是一组过程、方法与系统的统称,用于促进开发、技术运营和质量保障部门之间的沟通、协作与整合。…
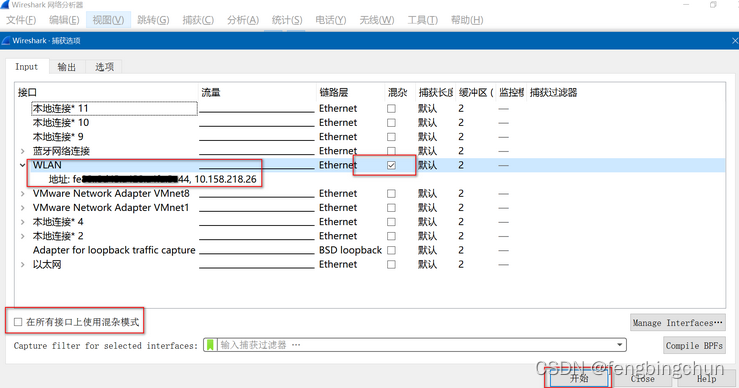
网络数据包分析软件Wireshark简介
Wireshark是被广泛使用的免费开源的网络协议分析软件(network protocol analyzer)或网络数据包分析软件,它可以让你在微观层面上查看网络上发生的事情,它的功能是截取网络数据包,并尽可能显示出最为详细的网络数据包信息。它的源码在https://…

SEO研究:网站结构
在衡量所有权重之间,网站结构大概占到30%,这也是很多网站排名不好,或者有站长根本不用优化就能获得很好排名的原因。说到结构必须明白两个概念,一个是物理概念,就是文件存放的路径,另一个是逻辑结构。比较好的情况是逻…
form实现登陆操作
这几天想写个保存cookies的网页,先写了个登陆界面,奈何点击登陆后总是无法正常跳转。经查阅资料和询问高手,总算得以解决。 原错误代码如下: <html> <title>SaveCookies</title> <head> <script>fu…
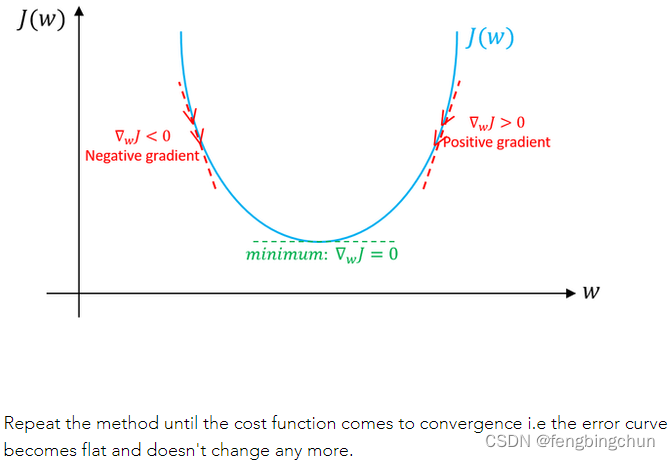
深度学习中的优化算法之BGD
之前在https://blog.csdn.net/fengbingchun/article/details/75351323 介绍过梯度下降,常见的梯度下降有三种形式:BGD、SGD、MBGD,它们的不同之处在于我们使用多少数据来计算目标函数的梯度。 大多数深度学习算法都涉及某种形式的优化。优化指…
死宅福音:乐高不怕多,智能分拣机帮你归类
作者 | 神经小兮来源 | HyperAI超神经(ID:HyperAI)【导读】乐高现在几乎已经是优质玩具的代名词,该品牌旗下最为知名的,莫过于乐高积木。其丰富的形状与多样的玩法,无论大人小孩都喜欢。但是,这…
优化eclipse启动速度
< DOCTYPE html PUBLIC -WCDTD XHTML StrictEN httpwwwworgTRxhtmlDTDxhtml-strictdtd> 最近发现eclipse越来越慢,影响了开发使用速度。经过处理,快了一些,希望给大家一些提示。 1,取消系统的自动折叠 操作方法:…

一个基于J2EE的web应用程序运行起来需要什么?
2019独角兽企业重金招聘Python工程师标准>>> Eclipse ?IDEA?这是目前市面上最常用的开发工具啦,我的理解是这些只是开发工具,是为了方便开发的,而不是web应用程序运行起来必须的东西。 为什么会有些这方面东…
深度学习中的优化算法之MBGD
之前在https://blog.csdn.net/fengbingchun/article/details/75351323 介绍过梯度下降,常见的梯度下降有三种形式:BGD、SGD、MBGD,它们的不同之处在于我们使用多少数据来计算目标函数的梯度。 大多数深度学习算法都涉及某种形式的优化。优化指…
华科提出目标检测新方法:基于IoU-aware的定位改进,简单又有效
作者 | 周强来源 | 我爱计算机视觉(ID:aicvml)【导语】近日,华中科技大学发表了一篇新论文《IoU-aware Single-stage Object Detector for Accurate Localization》,在此论文中作者提出了一种非常简单的目标检测定位改…
js init : function ()
这个init外面应该还有一层,比如 var a { init: function () {...}, exit: function () {...} } 这样的话,可以用a.init()来调用这个函数, <script type"text/javascript">var obj{init:function(str){alert("init调用&…
Google提出移动端新SOTA模型MixNets:用混合深度卷积核提升精度
作者 | Google译者 | 刘畅编辑 | Jane出品 | AI科技大本营(ID:rgznai100) 【导语】目前,深度卷积(Depthwise convolution)在追求高性能的卷积网络中的应用变得越来越流行,但很多研究忽略了其内核…
桌面窗口的一些发现
最近因业务需要,玩了一下全屏问题。后来,对windows xp sp2的桌面窗口产生了兴趣。写了段代码,玩了一下。同时结合网上的一些知识,发现了以下一些现象。(转载请指明出处) 首先窗口名有#32769、Progman、Shel…
三说输入法[转]
如果我愿意,我会不停地说下去,直到烦死你们,谁让我用的输入法快呢。 我说了几句搜狗或股沟输入法的坏话,引来一些人的争论,大大在我预料之中,这年头,当你想说一些知名度较高的人或物的坏话时&am…

回忆之城市搜索
直接看效果点这里 HTML <!DOCTYPE html> <html> <head lang"zh-CN"><meta charset"utf-8"><title> 城市搜索 </title><link rel"stylesheet" href"ui-departure.css"> </head> <b…

ATL::CStringA和std::string之间转换的一些误区
对于刚做windows下VC的开发同学,类型转换应该是一个令其很苦恼的问题。我刚写工作的时候,也为这类问题不停的在网上搜索转换方法。最近工作中遇到一个“神奇”的bug(一般“神奇”的问题往往是低级错误导致的),最后跟踪…
Windows XP鲜为人知的70招
一、Windows XP优化恢复Windows经典界面很多人安装了Windows XP后的第一感觉就是Windows变得漂亮极了。只是可惜美丽的代价要耗掉我们本就不富裕的内存和显存。要想恢复到和经典Windows类似的界面和使用习惯,请在桌面上单击鼠标右键,选择“属性”命令即可…
Github开源趋势榜Top 1:英伟达升级发布二代StyleGAN,效果更完美
整理 | Jane出品 | AI科技大本营(ID:rgznai100)2018 年底,英伟达借鉴风格迁移的思路,提出当时最先进的无条件生成模型—— StyleGAN ,吸引了大家广泛关注。随后,代码开源,一位 Uber …
百度地图 ip查询 service
官方文档:http://developer.baidu.com/map/wiki/index.php?titlewebapi/ip-api 请求 一个例子: http://api.map.baidu.com/location/ip?ak3GFi2F04wXaVuwmGu8fN49kL1234567890&ip180.161.128.181 返回 {"address": "CN|\u6cb3\u535…
python3编写简易统计服务器
打点这个功能总是美其名曰“帮助提升用户体验”,其实说白了就是记录用户做了哪些操作。目前国内很多通用软件都做了相关功能,像360、QQ等这样的以用户体验出众的软件,其打点的面自然也很广很细。当然这种“侵犯”用户隐私的事情在业内各个公司…
作价20亿美元!英特尔收购以色列AI芯片公司Habana Labs
出品 | AI科技大本营(ID:rgznai1000)12月16日,英特尔宣布以约 20 亿美元收购以色列公司Habana Labs,这成为英特尔在以色列仅次于 Mobileye(153 亿美元) 的第二大收购案。Habana Labs 成立于 2016 年&#x…

这就是奇客文化?简直太有才了!
这就是奇客文化?简直太有才了……
java中的char类型
2019独角兽企业重金招聘Python工程师标准>>> 一:char的初始化 char是Java中的保留字,与别的语言不同的是,char在Java中是16位的,因为Java用的是Unicode。不过8位的ASCII码包含在Unicode中,是从0~127的。 Ja…