深度学习中的优化算法之BGD
之前在https://blog.csdn.net/fengbingchun/article/details/75351323 介绍过梯度下降,常见的梯度下降有三种形式:BGD、SGD、MBGD,它们的不同之处在于我们使用多少数据来计算目标函数的梯度。
大多数深度学习算法都涉及某种形式的优化。优化指的是改变x以最小化或最大化某个函数f(x)的任务。我们通常以最小化f(x)指代大多数最优化问题。我们把要最小化或最大化的函数称为目标函数(objective function)或准则(criterion)。当我们对其进行最小化时,我们也把它称为成本函数(cost function)、损失函数(loss function)或误差函数(error function)。
梯度下降是深度学习中一种常用的优化技术。梯度是函数的斜率。它衡量一个变量响应另一个变量的变化而变化的程度。在数学上,梯度下降是一个凸函数,其输出是输入的一组参数的偏导数。梯度越大,坡度越陡(the greater the gradient, the steeper the slope)。从初始值开始,迭代运行梯度下降以找到参数的最佳值,以找到给定成本函数的最小可能值。
梯度下降是一种优化算法,通常用于寻找深度学习算法中的权值及系数(weights or coefficients),如逻辑回归。它的工作原理是让模型对训练数据进行预测,并使用预测中的error来更新模型从而减少error(It works by having the model make predictions on training data and using the error on the predictions to update the model in such a way as to reduce the error)。
该算法的目标是找到使模型在训练数据集上的误差最小化的模型参数(e.g. coefficients or weights)。它通过对模型进行更改,使其沿着误差的梯度或斜率向下移动到最小误差值来实现这一点。这使该算法获得了"梯度下降"的名称。
梯度下降是深度学习中非常流行的优化算法。它的目标是搜索目标函数或成本函数(objective function or cost function)的全局最小值。这只有在目标函数是凸函数时才有可能,这间接意味着该函数将是碗形的。在非凸函数的情况下,梯度下降会找到最近的最小值,这个函数的最小值称为局部最小值。
梯度下降是一种一阶优化算法。这意味着在更新参数时它只考虑函数的一阶导数。我们的主要目标是在每次迭代中使梯度沿最陡斜率的方向行进,我们在与目标函数的梯度相反的方向上更新参数。
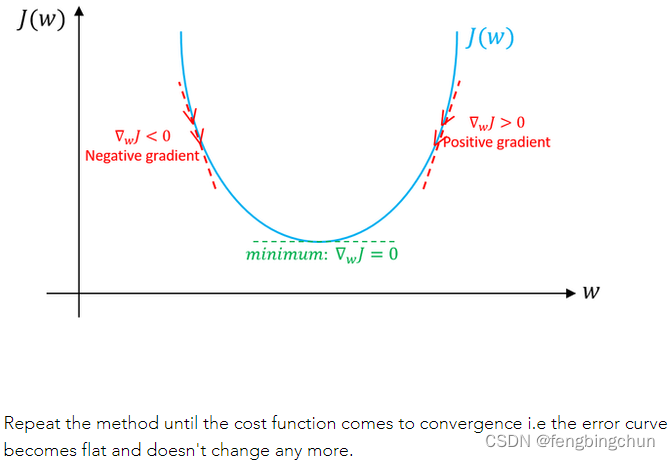
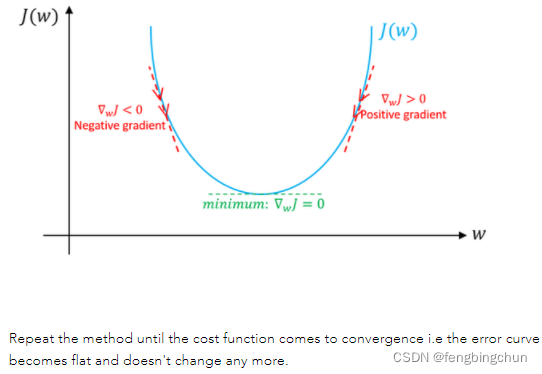
图解说明:假设只有weight没有bias。如果weight(w)的特定值的斜率>0,则表示我们在最优w*的右侧,在这种情况下,更新将是负数,并且w将开始接近最优w*。但是,如果weight(w)的特定值的斜率<0,则更新将为正值,并将当前值增加到w以收敛到w*的最佳值。以下截图来自于https://www.machinelearningman.com:重复该方法,直到成本函数收敛。
在https://blog.csdn.net/fengbingchun/article/details/79370310 中有梯度下降应用于二分类的公式推导。
BGD(Batch Gradient Descent):批量梯度下降,是梯度下降法最原始的形式,它计算训练数据集中每个样本的误差(error),使用所有的样本来进行参数更新。整个训练数据集的一个周期(one cycle)称为一个训练epoch。BGD是在每个训练epoch结束时才进行模型更新。
梯度下降是一种最小化目标函数的方法:θ为模型的参数,J(θ)为目标函数,以下截图来自https://arxiv.org/pdf/1609.04747.pdf

批量梯度下降可以使用固定的学习率。同时处理整个训练集,只有处理完整个训练集才更新一次权值和偏置。
优点:
(1).对模型的更新较小意味着这种形式的梯度下降比随机梯度下降的计算效率更高。
(2).降低的(decreased)的更新频率会产生更稳定的误差梯度(error gradient),在某些问题上可能产生更稳定的收敛。
(3).预测误差(prediction error)的计算和模型更新的分离使算法适用于基于并行处理的实现。
缺点:
(1).更稳定的误差梯度可能会导致模型过早收敛到一组不太理想的参数。
(2).训练结束时的更新需要在所有训练样本中累积预测误差的额外复杂性(additional complexity)。
(3).通常需要将整个训练数据集加载到内存中以供算法使用。
(4).对于大型数据集,模型更新以及训练速度可能会变得非常慢。
以上内容主要参考:
1. https://arxiv.org/pdf/1609.04747.pdf
2. https://machinelearningmastery.com/
3. https://www.machinelearningman.com
以下的测试代码以https://blog.csdn.net/fengbingchun/article/details/79346691 中逻辑回归实现的基础上进行调整:
logistic_regression2.hpp:
#ifndef FBC_SRC_NN_LOGISTIC_REGRESSION2_HPP_
#define FBC_SRC_NN_LOGISTIC_REGRESSION2_HPP_#include <vector>
#include <string>namespace ANN {enum class ActivationFunction {Sigmoid // logistic sigmoid function
};enum class LossFunction {MSE // Mean Square Error
};enum class Optimzation {BGD, // Batch_Gradient_DescentSGD, // Stochastic Gradient DescentMBGD // Mini-batch Gradient Descent
};template<typename T>
class LogisticRegression2 { // two categories
public:LogisticRegression2() = default;int init(const T* data, const T* labels, int train_num, int feature_length, T learning_rate = 0.00001, int epochs = 300);int train(const std::string& model);int load_model(const std::string& model);T predict(const T* data, int feature_length) const; // y = 1/(1+exp(-(wx+b)))private:int store_model(const std::string& model) const;T calculate_z(const std::vector<T>& feature) const; // z(i)=w^T*x(i)+bT calculate_cost_function() const;T calculate_activation_function(T value) const;T calculate_loss_function() const;T calculate_loss_function_derivative() const;T calculate_loss_function_derivative(unsigned int index) const;void calculate_gradient_descent();std::vector<std::vector<T>> x_; // training setstd::vector<T> y_; // ground truth labelsstd::vector<T> o_; // predict valueint epochs_ = 100; // epochsint m_ = 0; // train samples numint feature_length_ = 0; // weights lengthT alpha_ = (T)0.00001; // learning ratestd::vector<T> w_; // weightsT b_ = (T)0.; // thresholdActivationFunction activation_func_ = ActivationFunction::Sigmoid;LossFunction loss_func_ = LossFunction::MSE;Optimzation optim_ = Optimzation::BGD;
}; // class LogisticRegression2} // namespace ANN#endif // FBC_SRC_NN_LOGISTIC_REGRESSION2_HPP_logistic_regression2.cpp:
#include "logistic_regression2.hpp"
#include <fstream>
#include <algorithm>
#include <random>
#include <cmath>
#include "common.hpp"namespace ANN {template<typename T>
int LogisticRegression2<T>::init(const T* data, const T* labels, int train_num, int feature_length, T learning_rate, int epochs)
{if (train_num < 2) {fprintf(stderr, "logistic regression train samples num is too little: %d\n", train_num);return -1;}if (learning_rate <= 0) {fprintf(stderr, "learning rate must be greater 0: %f\n", learning_rate);return -1;}if (epochs <= 0) {fprintf(stderr, "number of epochs cannot be zero or a negative number: %d\n", epochs);return -1;}alpha_ = learning_rate;epochs_ = epochs;m_ = train_num;feature_length_ = feature_length;x_.resize(m_);y_.resize(m_);o_.resize(m_);for (int i = 0; i < m_; ++i) {const T* p = data + i * feature_length_;x_[i].resize(feature_length_);for (int j = 0; j < feature_length_; ++j) {x_[i][j] = p[j];}y_[i] = labels[i];}return 0;
}template<typename T>
int LogisticRegression2<T>::train(const std::string& model)
{CHECK(x_.size() == y_.size());w_.resize(feature_length_, (T)0.);generator_real_random_number(w_.data(), feature_length_, (T)-0.01f, (T)0.01f, true);generator_real_random_number(&b_, 1, (T)-0.01f, (T)0.01f);for (int iter = 0; iter < epochs_; ++iter) {calculate_gradient_descent();fprintf(stdout, "echoch: %d, cost function: %f\n", iter, calculate_cost_function());}CHECK(store_model(model) == 0);return 0;
}template<typename T>
int LogisticRegression2<T>::load_model(const std::string& model)
{std::ifstream file;file.open(model.c_str(), std::ios::binary);if (!file.is_open()) {fprintf(stderr, "open file fail: %s\n", model.c_str());return -1;}int length{ 0 };file.read((char*)&length, sizeof(length));w_.resize(length);feature_length_ = length;file.read((char*)w_.data(), sizeof(T)*w_.size());file.read((char*)&b_, sizeof(T));file.close();return 0;
}template<typename T>
T LogisticRegression2<T>::predict(const T* data, int feature_length) const
{CHECK(feature_length == feature_length_);T value{ (T)0. };for (int t = 0; t < feature_length_; ++t) {value += data[t] * w_[t];}value += b_;return (calculate_activation_function(value));
}template<typename T>
int LogisticRegression2<T>::store_model(const std::string& model) const
{std::ofstream file;file.open(model.c_str(), std::ios::binary);if (!file.is_open()) {fprintf(stderr, "open file fail: %s\n", model.c_str());return -1;}int length = w_.size();file.write((char*)&length, sizeof(length));file.write((char*)w_.data(), sizeof(T) * w_.size());file.write((char*)&b_, sizeof(T));file.close();return 0;
}template<typename T>
T LogisticRegression2<T>::calculate_z(const std::vector<T>& feature) const
{T z{ 0. };for (int i = 0; i < feature_length_; ++i) {z += w_[i] * feature[i];}z += b_;return z;
}template<typename T>
T LogisticRegression2<T>::calculate_cost_function() const
{/*// J+=-1/m([y(i)*loga(i)+(1-y(i))*log(1-a(i))])// Note: log0 is not definedT J{0.};for (int i = 0; i < m_; ++i)J += -(y_[i] * std::log(o_[i]) + (1 - y_[i]) * std::log(1 - o_[i]) );return J/m_;*/T J{0.};for (int i = 0; i < m_; ++i)J += 1./2*std::pow(y_[i] - o_[i], 2);return J/m_;
}template<typename T>
T LogisticRegression2<T>::calculate_activation_function(T value) const
{switch (activation_func_) {case ActivationFunction::Sigmoid:default: // Sigmoidreturn ((T)1 / ((T)1 + std::exp(-value))); // y = 1/(1+exp(-value))}
}template<typename T>
T LogisticRegression2<T>::calculate_loss_function() const
{switch (loss_func_) {case LossFunction::MSE:default: // MSET value = 0.;for (int i = 0; i < m_; ++i) {value += 1/2.*std::pow(y_[i] - o_[i], 2);}return value/m_;}
}template<typename T>
T LogisticRegression2<T>::calculate_loss_function_derivative() const
{switch (loss_func_) {case LossFunction::MSE:default: // MSET value = 0.;for (int i = 0; i < m_; ++i) {value += o_[i] - y_[i];}return value/m_;}
}template<typename T>
T LogisticRegression2<T>::calculate_loss_function_derivative(unsigned int index) const
{switch (loss_func_) {case LossFunction::MSE:default: // MSEreturn (o_[index] - y_[index]);}
}template<typename T>
void LogisticRegression2<T>::calculate_gradient_descent()
{switch (optim_) {case Optimzation::BGD:default: // BGDT db = (T)0.;std::vector<T> dw(feature_length_, (T)0.), z(m_, (T)0), dz(m_, (T)0);for (int i = 0; i < m_; ++i) {z[i] = calculate_z(x_[i]);o_[i] = calculate_activation_function(z[i]);dz[i] = calculate_loss_function_derivative(i);for (int j = 0; j < feature_length_; ++j) {dw[j] += x_[i][j] * dz[i]; // dw(i)+=x(i)(j)*dz(i)}db += dz[i]; // db+=dz(i)}for (int j = 0; j < feature_length_; ++j) {dw[j] /= m_;w_[j] -= alpha_ * dw[j];}b_ -= alpha_*(db/m_);}
}template class LogisticRegression2<float>;
template class LogisticRegression2<double>;} // namespace ANNtest.cpp:
int test_logistic_regression2_train()
{
#ifdef _MSC_VERconst std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
#elseconst std::string image_path{ "data/images/digit/handwriting_0_and_1/" };
#endifcv::Mat data, labels;for (int i = 1; i < 11; ++i) {const std::vector<std::string> label{ "0_", "1_" };for (const auto& value : label) {std::string name = std::to_string(i);name = image_path + value + name + ".jpg";cv::Mat image = cv::imread(name, 0);if (image.empty()) {fprintf(stderr, "read image fail: %s\n", name.c_str());return -1;}data.push_back(image.reshape(0, 1));}}data.convertTo(data, CV_32F);std::unique_ptr<float[]> tmp(new float[20]);for (int i = 0; i < 20; ++i) {if (i % 2 == 0) tmp[i] = 0.f;else tmp[i] = 1.f;}labels = cv::Mat(20, 1, CV_32FC1, tmp.get());ANN::LogisticRegression2<float> lr;const float learning_rate{ 0.00001f };const int iterations{ 1000 };int ret = lr.init((float*)data.data, (float*)labels.data, data.rows, data.cols);if (ret != 0) {fprintf(stderr, "logistic regression init fail: %d\n", ret);return -1;}#ifdef _MSC_VERconst std::string model{ "E:/GitCode/NN_Test/data/logistic_regression2.model" };
#elseconst std::string model{ "data/logistic_regression2.model" };
#endifret = lr.train(model);if (ret != 0) {fprintf(stderr, "logistic regression train fail: %d\n", ret);return -1;}return 0;
}int test_logistic_regression2_predict()
{
#ifdef _MSC_VERconst std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
#elseconst std::string image_path{ "data/images/digit/handwriting_0_and_1/" };
#endifcv::Mat data, labels, result;for (int i = 11; i < 21; ++i) {const std::vector<std::string> label{ "0_", "1_" };for (const auto& value : label) {std::string name = std::to_string(i);name = image_path + value + name + ".jpg";cv::Mat image = cv::imread(name, 0);if (image.empty()) {fprintf(stderr, "read image fail: %s\n", name.c_str());return -1;}data.push_back(image.reshape(0, 1));}}data.convertTo(data, CV_32F);std::unique_ptr<int[]> tmp(new int[20]);for (int i = 0; i < 20; ++i) {if (i % 2 == 0) tmp[i] = 0;else tmp[i] = 1;}labels = cv::Mat(20, 1, CV_32SC1, tmp.get());CHECK(data.rows == labels.rows);#ifdef _MSC_VERconst std::string model{ "E:/GitCode/NN_Test/data/logistic_regression2.model" };
#elseconst std::string model{ "data/logistic_regression2.model" };
#endifANN::LogisticRegression2<float> lr;int ret = lr.load_model(model);if (ret != 0) {fprintf(stderr, "load logistic regression model fail: %d\n", ret);return -1;}for (int i = 0; i < data.rows; ++i) {float probability = lr.predict((float*)(data.row(i).data), data.cols);fprintf(stdout, "probability: %.6f, ", probability);if (probability > 0.5) fprintf(stdout, "predict result: 1, ");else fprintf(stdout, "predict result: 0, ");fprintf(stdout, "actual result: %d\n", ((int*)(labels.row(i).data))[0]);}return 0;
}train执行结果如下:
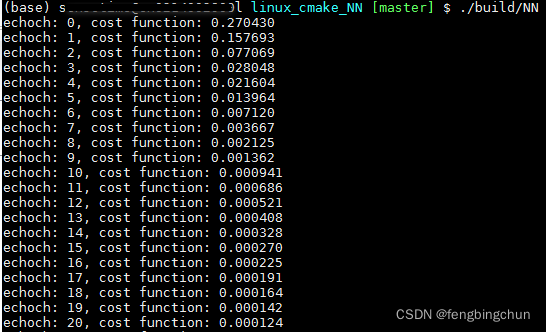
predict执行结果如下:
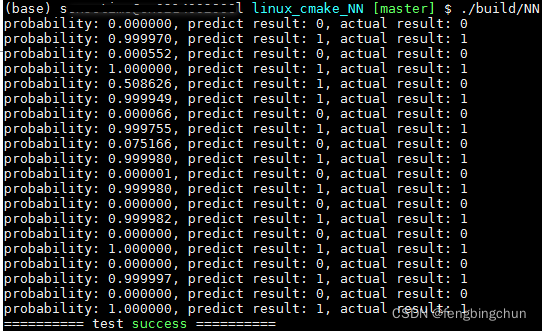
GitHub: https://github.com/fengbingchun/NN_Test
相关文章:
死宅福音:乐高不怕多,智能分拣机帮你归类
作者 | 神经小兮来源 | HyperAI超神经(ID:HyperAI)【导读】乐高现在几乎已经是优质玩具的代名词,该品牌旗下最为知名的,莫过于乐高积木。其丰富的形状与多样的玩法,无论大人小孩都喜欢。但是,这…

优化eclipse启动速度
< DOCTYPE html PUBLIC -WCDTD XHTML StrictEN httpwwwworgTRxhtmlDTDxhtml-strictdtd> 最近发现eclipse越来越慢,影响了开发使用速度。经过处理,快了一些,希望给大家一些提示。 1,取消系统的自动折叠 操作方法:…

一个基于J2EE的web应用程序运行起来需要什么?
2019独角兽企业重金招聘Python工程师标准>>> Eclipse ?IDEA?这是目前市面上最常用的开发工具啦,我的理解是这些只是开发工具,是为了方便开发的,而不是web应用程序运行起来必须的东西。 为什么会有些这方面东…
深度学习中的优化算法之MBGD
之前在https://blog.csdn.net/fengbingchun/article/details/75351323 介绍过梯度下降,常见的梯度下降有三种形式:BGD、SGD、MBGD,它们的不同之处在于我们使用多少数据来计算目标函数的梯度。 大多数深度学习算法都涉及某种形式的优化。优化指…
华科提出目标检测新方法:基于IoU-aware的定位改进,简单又有效
作者 | 周强来源 | 我爱计算机视觉(ID:aicvml)【导语】近日,华中科技大学发表了一篇新论文《IoU-aware Single-stage Object Detector for Accurate Localization》,在此论文中作者提出了一种非常简单的目标检测定位改…
js init : function ()
这个init外面应该还有一层,比如 var a { init: function () {...}, exit: function () {...} } 这样的话,可以用a.init()来调用这个函数, <script type"text/javascript">var obj{init:function(str){alert("init调用&…
Google提出移动端新SOTA模型MixNets:用混合深度卷积核提升精度
作者 | Google译者 | 刘畅编辑 | Jane出品 | AI科技大本营(ID:rgznai100) 【导语】目前,深度卷积(Depthwise convolution)在追求高性能的卷积网络中的应用变得越来越流行,但很多研究忽略了其内核…
桌面窗口的一些发现
最近因业务需要,玩了一下全屏问题。后来,对windows xp sp2的桌面窗口产生了兴趣。写了段代码,玩了一下。同时结合网上的一些知识,发现了以下一些现象。(转载请指明出处) 首先窗口名有#32769、Progman、Shel…
三说输入法[转]
如果我愿意,我会不停地说下去,直到烦死你们,谁让我用的输入法快呢。 我说了几句搜狗或股沟输入法的坏话,引来一些人的争论,大大在我预料之中,这年头,当你想说一些知名度较高的人或物的坏话时&am…

回忆之城市搜索
直接看效果点这里 HTML <!DOCTYPE html> <html> <head lang"zh-CN"><meta charset"utf-8"><title> 城市搜索 </title><link rel"stylesheet" href"ui-departure.css"> </head> <b…

ATL::CStringA和std::string之间转换的一些误区
对于刚做windows下VC的开发同学,类型转换应该是一个令其很苦恼的问题。我刚写工作的时候,也为这类问题不停的在网上搜索转换方法。最近工作中遇到一个“神奇”的bug(一般“神奇”的问题往往是低级错误导致的),最后跟踪…
Windows XP鲜为人知的70招
一、Windows XP优化恢复Windows经典界面很多人安装了Windows XP后的第一感觉就是Windows变得漂亮极了。只是可惜美丽的代价要耗掉我们本就不富裕的内存和显存。要想恢复到和经典Windows类似的界面和使用习惯,请在桌面上单击鼠标右键,选择“属性”命令即可…
Github开源趋势榜Top 1:英伟达升级发布二代StyleGAN,效果更完美
整理 | Jane出品 | AI科技大本营(ID:rgznai100)2018 年底,英伟达借鉴风格迁移的思路,提出当时最先进的无条件生成模型—— StyleGAN ,吸引了大家广泛关注。随后,代码开源,一位 Uber …
百度地图 ip查询 service
官方文档:http://developer.baidu.com/map/wiki/index.php?titlewebapi/ip-api 请求 一个例子: http://api.map.baidu.com/location/ip?ak3GFi2F04wXaVuwmGu8fN49kL1234567890&ip180.161.128.181 返回 {"address": "CN|\u6cb3\u535…
python3编写简易统计服务器
打点这个功能总是美其名曰“帮助提升用户体验”,其实说白了就是记录用户做了哪些操作。目前国内很多通用软件都做了相关功能,像360、QQ等这样的以用户体验出众的软件,其打点的面自然也很广很细。当然这种“侵犯”用户隐私的事情在业内各个公司…
作价20亿美元!英特尔收购以色列AI芯片公司Habana Labs
出品 | AI科技大本营(ID:rgznai1000)12月16日,英特尔宣布以约 20 亿美元收购以色列公司Habana Labs,这成为英特尔在以色列仅次于 Mobileye(153 亿美元) 的第二大收购案。Habana Labs 成立于 2016 年&#x…

这就是奇客文化?简直太有才了!
这就是奇客文化?简直太有才了……
java中的char类型
2019独角兽企业重金招聘Python工程师标准>>> 一:char的初始化 char是Java中的保留字,与别的语言不同的是,char在Java中是16位的,因为Java用的是Unicode。不过8位的ASCII码包含在Unicode中,是从0~127的。 Ja…
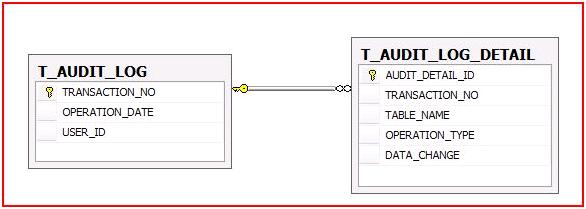
[原创] 如何追踪每一笔记录的来龙去脉:一个完整的Audit Logging解决方案—Part I...
一、提出问题 在开发一个企业级 应用的时候,尤其在一个涉及到敏感数据的应用,比如财务系统、物流系统,我们往往有这样的需求:对于数据库中每一笔数据的添加、修改和删除,都需要有一个明确的日志,以便我们可…

进程间通信:同步双工管道
因为工作需要,需要设计出一个双工的IPC。(转载请指明出处)在一番比较后,我发现管道是比较符合我们的需求的。但是我们需求要求管道的对方是可信任的,而在vista以下系统是没有GetNamedPipeClientProcessId、GetNamedPip…
就因为一个笔记本,运营和产品吵得不可开交......
上班最讨厌的一件事情,莫过于开会,因为每次开会感觉就要吵架,这个今天开会又吵架了,吵架竟然是因为产品小姐姐的笔记本。产品小姐姐用了一本可擦笔记本记录会议内容,运营小姐姐竟然说这个本子有什么用,不就…
Ka的递归编程练习 Part4|Hanoi汉诺塔,双色汉诺塔的也有
1 #include <stdio.h>2 void hanoi(int s,char a,char b,char c) //a是出发盘,b是中途盘,c是结束盘 3 {4 if(s0) return;5 hanoi(s-1,a,c,b); //把最底下的从a借助c移动到b6 printf("%d from %c move to %c\n",s,a,c);7 …

一种精确从文本中提取URL的思路及实现
在今年三四月份,我接受了一个需求:从文本中提取URL。这样的需求,可能算是非常小众的需求了。大概只有QQ、飞信、阿里旺旺等之类的即时通讯软件存在这样的需求。在研究这个之前,我测试了这些软件这块功能,发现它们这块的…
解读 | 2019年10篇计算机视觉精选论文(上)
作者 | 神经小兮来源 | HyperAI超神经(ID:HyperAI)2019 年转眼已经接近尾声,我们看到,这一年计算机视觉(CV)领域又诞生了大量出色的论文,提出了许多新颖的架构和方法,进一步提高了视…
不错的工具:Reflector for .NET
下载地址: http://www.aisto.com/roeder/dotnet/ 注意:下载时要输一些注册信息,输入用户名时,中间要加一个空格。
Possible MySQL server UUID duplication for server
在mysql enterprise monitor监控过程中出现这样的event事件,Topic: Possible MySQL server UUID duplication for server 事件,从该提示的描述来看貌似是存在重复的uuid,而实际上主从关系并不存在重复的uuid。主从关…
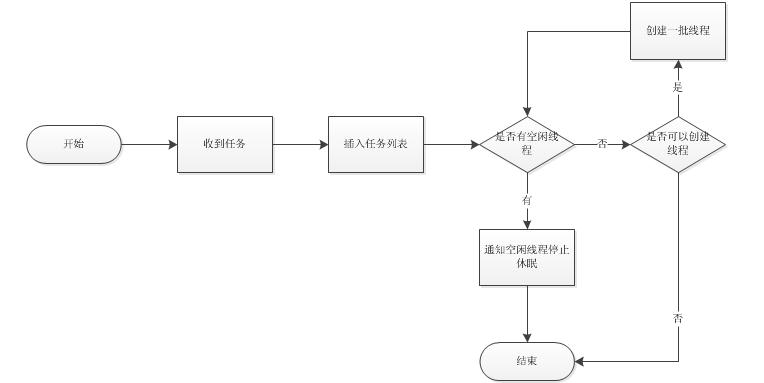
使用VC实现一个“智能”自增减线程池
工作中接手了一款产品的改造。因为该产品可能使用很多线程,所以产品中使用了线程池。(转载请指明来自BreakSoftware的CSDN博客) 线程池的一个优点是降低线程创建和销毁的频率;缺点是可能在比较闲的时候还存在一定数量的空闲线程。…
国内外财务软件科目结构的比较
科目结构是整个会计核算的基础。国内外财务软件都是任意定义科目的分段及科目编码长度,一般都能支持六段到九段。但科目结构在不同的国家有不同的规范,因而在不同的财务软件中也就有不同的控制。在科目分类上,国内外有明显的区别。国外财务软…
朋友圈装死,微博蹦迪,Python教你如何掌握女神情绪变化 | CSDN博文精选
作者 | A字头来源 | 数据札记倌很多人都是在朋友圈装死,微博上蹦迪。微信朋友圈已经不是一个可以随意发表心情的地方了,微博才是!所以你不要傻傻盯着女神的朋友圈发呆啦!本文教你如何用Python自动通知女神微博情绪变化,…
java异常笔记
Throwable是所有Java程序中错误处理的父类,有两种资类:Error和Exception。Error:表示由JVM所侦测到的无法预期的错误,由于这是属于JVM层次的严重错误,导致JVM无法继续执行,因此,这是不可捕捉到的…