最新的B站弹幕和评论爬虫,你们要的冰冰来啦!
作者 | 周萝卜
来源 | 萝卜大杂烩
最近想爬下B站的弹幕和评论,发现网上找到的教程基本都失效了,毕竟爬虫和反爬是属于魔高一尺、道高一丈的双方,程序员小哥哥们在网络的两端斗智斗勇,也是精彩纷呈。
当然了,对于爬虫这一方,爬取网站数据,一般目的都是比较明确的,比如我这里就是为了冰冰,废话不多说,开干!

获取弹幕数据
这里先声明一点,虽然网络上的整体教程都失效了,但是有一些步骤还是可以参考的,比如我们可以知道,对于弹幕数据,我们是可以通过如下的一个接口来获取的
https://comment.bilibili.com/xxxx.xml
在浏览器打开可以看到如下:
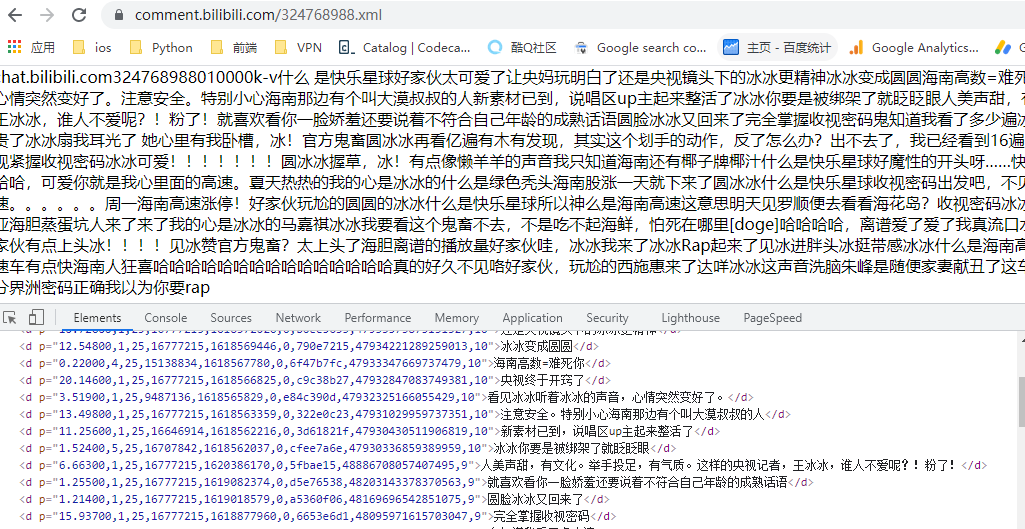
数据还是非常干净的,那么下一步就是看如何获取这个 xml 的 url 地址了,也就是如何获取 324768988 ID
接下来我们搜索整个网页的源码,可以发现如下情况

也就是说,我们需要的 ID 是可以在 script 当中获取的,下面就来编写一个提取 script 内容的函数
def getHTML_content(self):# 获取该视频网页的内容response = requests.get(self.BVurl, headers = self.headers)html_str = response.content.decode()html=etree.HTML(html_str)result=etree.tostring(html)return resultdef get_script_list(self,str):html = etree.HTML(str)script_list = html.xpath("//script/text()")return script_list拿到所有的 script 内容之后,我们再来解析我们需要的数据
script_list = self.get_script_list(html_content)
# 解析script数据,获取cid信息
for script in script_list:if '[{"cid":' in script:find_script_text = script
final_text = find_script_text.split('[{"cid":')[1].split(',"page":')[0]最后,我们再把整体代码封装成一个类,就完成了弹幕抓取的数据收集工作了
spider = BiliSpider("BV16p4y187hc")
spider.run()结果如下:

获取评论数据
对于评论数据,可能要复杂一些,需要分为主(main)评论和回复主评论的 reply 评论
我们通过浏览器工具抓取网页上的所有请求,然后搜索 reply,可以得到如下结果
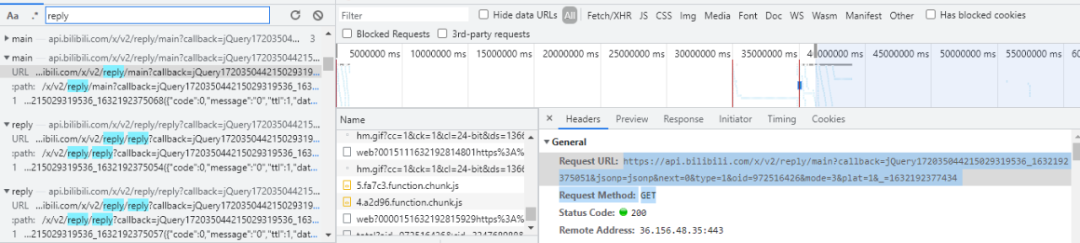
我们先来看看 main 请求,整理后通过浏览器访问如下
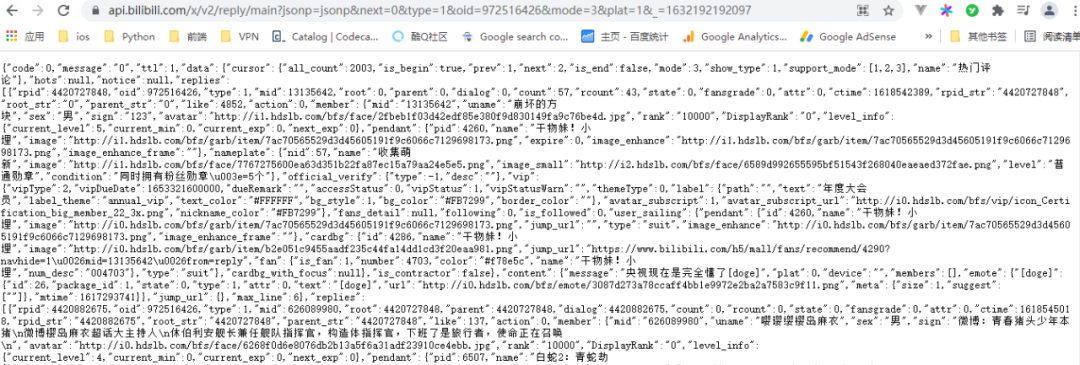
也可以直接通过 requests 请求
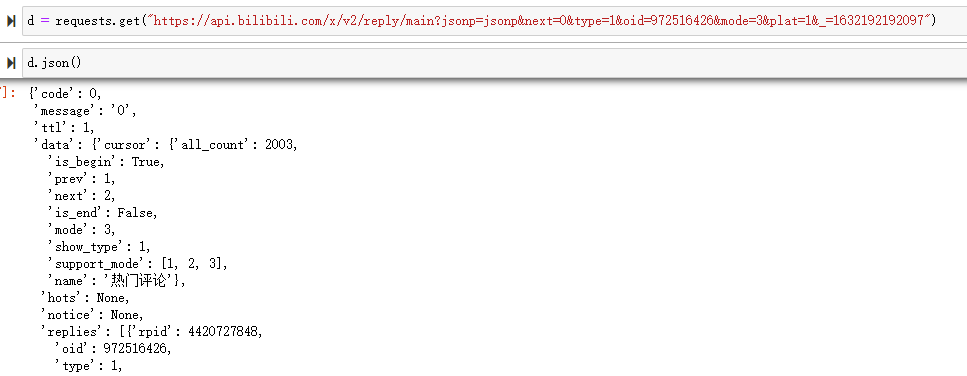
通过观察可以得知,响应消息里的 replies 就是主评论内容,同时我们还可以改变 url 当中的 next 参数来翻页,进而请求不同的数据
这里我们再关注下 rpid 参数,这个会用于 reply 评论中
再来看看 reply 评论,同样可以使用 requests 直接访问,同时 url 当中的 root 参数就是我们上面提到的 rpid 参数
我们厘清了上面的关系之后,我们就可以编写代码了
def get_data(data):data_list = []comment_data_list = data["data"]["replies"]for i in comment_data_list:data_list.append([i['rpid'], i['like'], i['member']['uname'], i['member']['level_info']['current_level'], i['content']['message']])return data_listdef save_data(data_type, data):if not os.path.exists(data_type + r'_data.csv'):with open(data_type + r"_data.csv", "a+", encoding='utf-8') as f:f.write("rpid,点赞数量,用户,等级,评论内容\n")for i in data:rpid = i[0]like_count = i[1]user = i[2].replace(',', ',')level = i[3]content = i[4].replace(',', ',')row = '{},{},{},{},{}'.format(rpid,like_count,user,level,content)f.write(row)f.write('\n')else:with open(data_type + r"_data.csv", "a+", encoding='utf-8') as f:for i in data:rpid = i[0]like_count = i[1]user = i[2].replace(',', ',')level = i[3]content = i[4].replace(',', ',')row = '{},{},{},{},{}'.format(rpid,like_count,user,level,content)f.write(row)f.write('\n')for i in range(1000):url = "https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next={}&type=1&oid=972516426&mode=3&plat=1&_=1632192192097".format(str(i))print(url)d = requests.get(url)data = d.json()if not data['data']['replies']:breakm_data = get_data(data)save_data("main", m_data)for j in m_data:reply_url = "https://api.bilibili.com/x/v2/reply/reply?jsonp=jsonp&pn=1&type=1&oid=972516426&ps=10&root={}&_=1632192668665".format(str(j[0]))print(reply_url)r = requests.get(reply_url)r_data = r.json()if not r_data['data']['replies']:breakreply_data = get_data(r_data)save_data("reply", reply_data)time.sleep(5)time.sleep(5)爬取过程中:

这样,针对一个冰冰视频,我们就完成了上千评论的抓取
可视化
下面我们简单做一些可视化动作
先来看下我们爬取的数据整体的样子
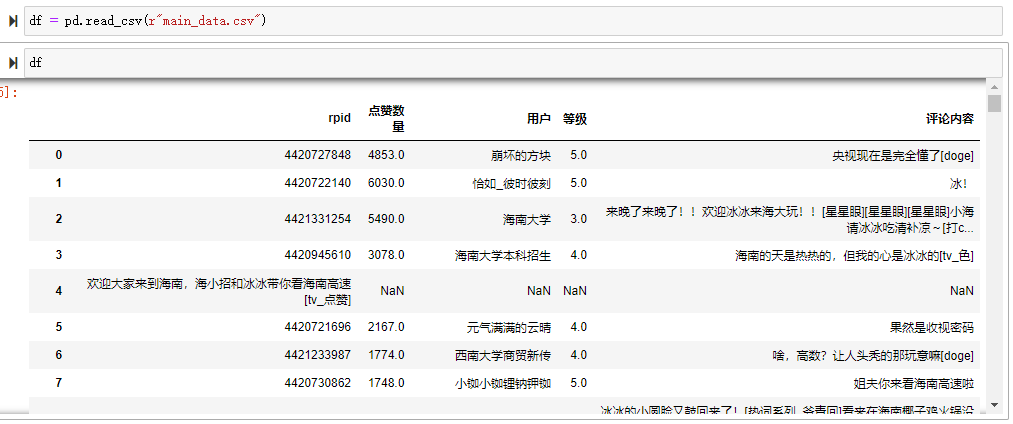
因为数据中有一些空值,我们来处理下
df_new = df.dropna(axis=0,subset = ["用户"]) 下面就可以作图了,GO!
使用 pyecharts 还是我们的首选,毕竟编写容易
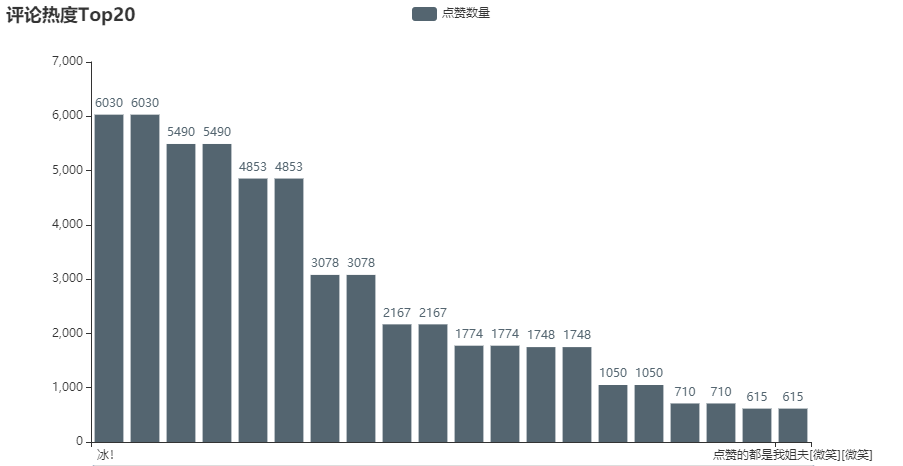
评论热度
df1 = df.sort_values(by="点赞数量",ascending=False).head(20)c1 = (Bar().add_xaxis(df1["评论内容"].to_list()).add_yaxis("点赞数量", df1["点赞数量"].to_list(), color=Faker.rand_color()).set_global_opts(title_opts=opts.TitleOpts(title="评论热度Top20"),datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_="inside")],).render_notebook()
)
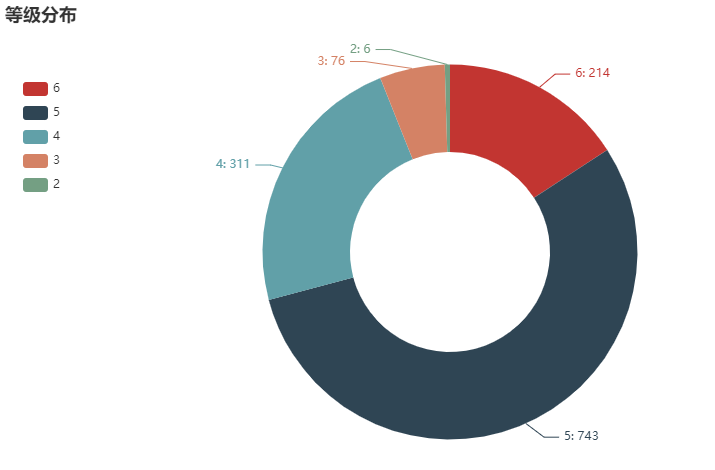
等级分布
pie_data = df_new.等级.value_counts().sort_index(ascending=False)
pie_data.tolist()
c2 = (Pie().add("",[list(z) for z in zip([str(i) for i in range(6, 1, -1)], pie_data.tolist())],radius=["40%", "75%"],).set_global_opts(title_opts=opts.TitleOpts(title="等级分布"),legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")).render_notebook()
)
评论词云
def wordcloud(data, name, pic=None):comment = jieba.cut(str(data), cut_all=False)words = ' '.join(comment)img = Image.open(pic)img_array = np.array(img)wc = WordCloud(width=2000, height=1800, background_color='white', font_path=font, mask=img_array,stopwords=STOPWORDS, contour_width=3, contour_color='steelblue')wc.generate(words)wc.to_file(name + '.png')wordcloud(df_new["评论内容"], "冰冰", '1.PNG')
相关文章:

K:java中的序列化与反序列化
Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java序列化与反序列化?以下内容将围绕这些问题进行展开讨论。 Java序列化与反序列化 简单来说Java序列化是指把Java对象转换为字节序列的过程;而Java反序列化是指…
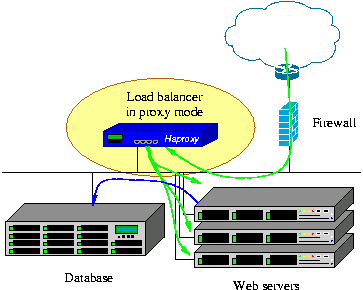
千万级并发HAproxy均衡负载系统介绍
Haproxy介绍及其定位 HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。根据官方数据,其最高极限支持10G的并发。 HAProxy特别适用于那些负载特大的web站点, 这些…
中国的“Databricks”们:打造AI基础架构,我们是认真的
AI落地最大的驱动因素是基础架构的升级。 近年来,大数据分析、AI等领域一直备受关注,常有引人关注的融资事件发生。美国数据科学公司Databricks刚刚在今年8月底完成了16亿美元H轮融资,其最新估值高达380亿美元,相比7个月前G轮融资…
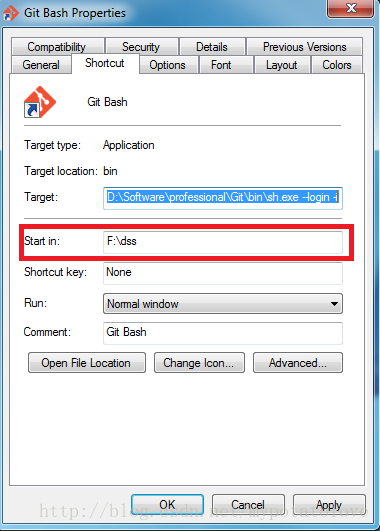
更改git bash默认的路径
在打开git bash时,每次都是在C:\Uer路径下,每次都需要先用cd命令转换到自己需要工作的路径(cd /f/dss)。修改打开git bash 时的默认的路径就可以不用每次都使用cd命令转换到需要管理的目录。 修改默认路径方法:右击Gi…
Gradle入门系列(4):创建二进制发布版本
本文由 伯乐在线 - JustinWu 翻译。未经许可,禁止转载! 英文出处:petrikainulainen。欢迎加入翻译组。 在创建了一个实用的应用程序之后,我们可能想将其与他人分享。其中一种方式就是创建一个可以从网站上下载的二进制文件。 这篇…
什么是A记录、MX记录、CNAME记录
什么是A记录? A (Address) 记录是用来指定主机名(或域名)对应的IP地址记录。用户可以将该域名下的网站服务器指向到自己的web server上。同时也可以设置域名的子域名。通俗来说A记录就是服务器的IP,域名绑定A记录就是告诉DNS,当你输入域名的…

Graph + AI 2021中国峰会:TigerGraph与行业共探图与AI应用前景
由企业级可扩展图分析平台TigerGraph主办的第二届“Graph AI中国峰会”将于10月20日线上举办,本届主题为“图创未来无界精彩”。作为全球唯一一个专注于图技术的行业峰会,“Graph AI峰会”自开办以来,受到数据行业专家及应用领域伙伴的持续…
rrdtool数据备份与迁移
rrdtool 显示错误ERROR: This RRD was created on another architecture rrdtool数据备份与迁移1.在原服务器生成xml文件 …
Format specifies type 'id' but the argument has type 'NSError *__autoreleasing *
我想打印error,但是出现了标题中的错误,代码如下: -(id)yobee_responseObjectForResponse:(NSURLResponse *)response data:(NSData *)data error:(NSError *__autoreleasing *)error { if (error) { NSLog("url ----> %\n error %&…
域名解析和cdn 原理
用户访问未使用CDN缓存网站的过程为: 1)、用户向浏览器提供要访问的域名; 2)、浏览器调用域名解析函数库对域名进行解析,以得到此域名对应的IP地址; 3)、浏览器使用所得到的IP地址,域名的服务主机发出数据访问请求; 4)…

首批 iPhone 13 用户直呼太“坑”:拍照有马赛克、不能用高刷、还与 Apple Watch “失联”?...
整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)iPhone 13 到底香不香,早在 9 月 15 号的苹果秋季发布会上给了我们答案。对此,自然是仁者见仁智者见智:有人认为 iPhone 13 “加量不加价”挺划算,有人则…

《javascript语言精粹》读书笔记(一)
为什么80%的码农都做不了架构师?>>> 第一章 精华 任何语言都有其精华的部分和鸡肋的部分,javascript也不例外,而且鸡肋的部分还很多。但javascript的流行却不受他的质量影响。javascript为何如此流行?因为他是web浏览…
WPF 与Surface 2.0 SDK 亲密接触–LibraryContainer 篇
最近比较懒惰一直都没写东西,再不写笔里的墨水就快干了。看过前面关于LibraryStack 和LibraryBar 的介绍后,大家可能已经对Library 控件系列有了进一步了解,本篇将继续介绍LibraryContainer,它其实就是LibraryStack、LibrayBar 的…

Transformer 代码完全解读!
作者 | 安晟&闫永强来源 | Datawhale本篇正文部分约10000字,分模块解读并实践了Transformer,建议收藏阅读。2017年谷歌在一篇名为《Attention Is All You Need》的论文中,提出了一个基于attention(自注意力机制)结构来处理序列相关的问题的模型&am…
php后台开发(二)Laravel框架
php后台开发(二)Laravel框架 为了提高后台的开发效率,往往需要选择一套适合自己的开发框架,因此,选择了功能比较完善的Laravel框架,仔细学来,感觉和Python语言的框架Django非常类似。 Laravel框…
Redis的介绍
Redis的介绍数据库主要类型有对象数据库,关系数据库,键值数据库等等,对象数据库太超前了,现阶段不提也罢;关系数据库就是平常说的MySQL,PostgreSQL这些熟的不能再熟的东西,至于键值数据库则是本…
从源代码编译里程碑的 ICS ROM
从源代码编译里程碑的 ICS ROM 操作系统选择 Ubuntu 10.04, 可以用虚拟机;安装 Android SDK , 并更新;打开命令行窗口, 输入下面的命令, 准备编译环境: sudo apt-get install git-core gnupg f…

Varnish purges 缓存清除
Varnish的缓存清除非常复杂。无论是Varnish的清除方式还是清除时候使用的语法规则等,都是比较复杂。为了理解他,我花费了不少时间,现在我很高兴我知道怎么来解释给大家听了。 1、Varnish有两种方式来清除缓存,其中一种方式是通过命…

如何快速搭建智能人脸识别系统
作者 | 小白来源 | 小白学视觉网络安全是现代社会最关心的问题之一,确保只有特定的人才能访问设备变得极其重要,这是我们的智能手机设有两级安全系统的主要原因之一。这是为了确保我们的隐私得到维护,只有真正的所有者才能访问他们的设备。基…
全局唯一ID生成方案
2019独角兽企业重金招聘Python工程师标准>>> 全局唯一ID生成方案对比 - http://cenalulu.github.io/mysql/guid-generate/ 转载于:https://my.oschina.net/meilihao/blog/386264
大型互联网 b2b b2c o2o 电子商务云平台
技术解决方案 开发语言: java、j2ee 数据库:mysql JDK支持版本: JDK1.6、JDK1.7、JDK1.8版本 核心技术:分布式、云服务、微服务、服务编排等。 核心架构: 使用Spring Cloud分布式微服务云架构进行服务化开发࿰…
Linux下redis安装部署
1、下载源代码 http://code.google.com/p/redis/downloads/list 下载redis-1.2.6.tar.gz 将下载包拷贝到/usr/local/webserver/redis-1.2.6/下 2、安装 tar -zxvf redis-1.2.6.tar.gzce redis-1.2.6make 3、调整内存 如果内存情况比较紧张的话,需要设定内核参数&am…

阿里无人车配送快递突破 100 万单,小蛮驴牵引的自动驾驶战略布局
作者 | 张昊 出品 | AI科技大本营(ID:rgznai100) 从物流的“最后”三公里中,我们看到了自动驾驶技术的“最前”沿 在9月27日举办的达摩院媒体沟通会上,阿里巴巴集团副总裁、达摩院自动驾驶实验室负责人王刚宣布,达摩院…
[Python] 中文路径和中文文本文件乱码问题
情景: Python首先读取名为log.txt的文本文件, 其中包含有文件名相对路径信息filename. 随后Python调用shutil.copy2(src, dst)对该filename文件进行复制操作. 由于filename为相对路径信息, 所以我们需要硬编码写入父目录, 假设为"C:\\源目录\\", 同时还有目标目录信息…

kubernetes Helm
Helm产生原因利用Kubernetes部署一个应用,需要Kubernetes原生资源文件如deployment、replicationcontroller、service或pod 等。而对于一个复杂的应用,会有很多类似上面的资源描述文件,如果有更新或回滚应用的需求,可能要修改和维…

造车新势力“围猎”秋招,应届生如何拿下高薪 offer ?
作者 | 易璜珵 出品 | 《新程序员》近年来,互联网大厂的秋招开启得越来越早,只为先人一步将优秀的毕业生纳入麾下。所谓“金九银十”,九月即将结束,许多大厂的秋招正式批也逐渐进入笔试和面试环节。在新能源汽车领域…
云评测、云监测、云加速,性能魔方mmTrix全球速度最快
在移动互联网高速发展的今天,互联网企业如果要实现业务增长,在激烈的市场竞争中站稳脚跟,必须要尽可能的提高用户体验和产品影响力。而要达实现这个目标,产品应用性能质量的好坏往往起到重要作用,APM服务受到了越来越多…
水平切分与垂直切分
数据库优化无非水平切分与垂直切分! 1.水平.就是按记录分. 一个数据库有3000W用户记录.处理速度比较慢.这时可以把3000W.分成三份.每份都是1000W.分别放在不同的机器上. 2.垂直分割就是按字段分. 一个数据库有3000W用户记录.包括字段id,user,password,first_name,l…
iOS 设计模式浅析 1 - 策略
本篇文章主要讲三个点: 1. 什么是策略模式.2. 策略模式的优缺点.3. demo .1. 策略模式定义一系列算法, 并且将每个算法封装起来, 算法之间可以互相替换. 使用前提: 输入已知, 好比你渴了, 可以喝可乐, 可以喝牛奶, 也可以喝水. 在我们项目中比较常见的使用情况: 1. 切换主题, 要…
何崚谈阿里巴巴前端性能优化最佳实践
转载:http://www.infoq.com/cn/interviews/hl-alibaba-front-end-performance-optimization 大家好,我现在在阿里巴巴园区采访阿里巴巴中文站架构师,兼B2B网站优化领域的负责人何崚。何崚你好,请简单介绍一下你自己。 我叫何崚&am…