如何快速搭建智能人脸识别系统

作者 | 小白
来源 | 小白学视觉
网络安全是现代社会最关心的问题之一,确保只有特定的人才能访问设备变得极其重要,这是我们的智能手机设有两级安全系统的主要原因之一。这是为了确保我们的隐私得到维护,只有真正的所有者才能访问他们的设备。基于人脸识别的智能人脸识别技术就是这样一种安全措施,本文我们将研究如何利用VGG-16的深度学习和迁移学习,构建我们自己的人脸识别系统。
简介
本项目构建的人脸识别模型将能够检测到授权所有者的人脸并拒绝任何其他人脸,如果面部被授予访问权限或访问被拒绝,模型将提供语音响应。用户将有 3 次尝试验证相同,在第三次尝试失败时,整个系统将关闭,从而保持安全。如果识别出正确的面部,则授予访问权限并且用户可以继续控制设备。完整代码将在文章末尾提供Github下载链接。
搭建方法
首先,我们将研究如何收集所有者的人脸图像。然后,如果我们想添加更多可以访问我们系统的人,我们将创建一个额外的文件夹。我们的下一步是将图像大小调整为 (224, 224, 3) 形状,以便我们可以将其通过 VGG-16 架构。请注意,VGG-16 架构是在具有上述形状的图像净权重上进行预训练的。然后我们将通过对数据集执行图像数据增强来创建图像的变化。在此之后,我们可以通过排除顶层来自由地在 VGG-16 架构之上创建我们的自定义模型。接下来是编译、训练和相应地使用基本回调拟合模型。

采集图像
在这一步中,我们将编写一个简单的 Python 代码,通过单击空格键按钮来收集图像,我们可以单击“q”按钮退出图形窗口。图像的收集是一个重要的步骤,本步骤将授予设备人脸信息收集的访问权限。执行以下代码将完成本步骤:
import cv2
import oscapture = cv2.VideoCapture(0)
directory = "Bharath/"
path = os.listdir(directory)
count = 0我们将“打开”我们的默认网络摄像头,然后继续捕获数据集所需的面部图像。这是由 VideoCapture 命令完成的。然后我们将创建一个指向我们特定目录的路径并将计数初始化为 0。这个计数变量将用于标记我们的图像,从 0 到我们单击的照片总数。执行整个图像采集过程所需的代码:
while True:ret, frame = capture.read()cv2.imshow('Frame', frame)key = cv2.waitKey(1)if key%256 == 32:img_path = directory + str(count) + ".jpeg"cv2.imwrite(img_path, frame)count += 1elif key%256 == 113:
breakcapture.release()
cv2.destroyAllWindows()我们确保代码仅在网络摄像头被捕获和激活时运行,然后将捕获视频并返回帧。然后我们将分配变量“key”以获取按下按钮的命令。这个按键给了我们两个选择:
当我们按键盘上的空格键时单击图片。
按下“q”时退出程序。
退出程序后,我们将从网络摄像头中释放视频捕获并销毁 cv2 图形窗口。
调整图像大小
在下一个代码块中,我们将相应地调整图像大小。我们希望将我们收集的图像重塑为适合通过 VGG-16 架构的大小,该架构是对 imagenet 权重进行预训练的。
import cv2
import osdirectory = "Bharath/"
path = os.listdir(directory)for i in path:
img_path = directory + i
image = cv2.imread(img_path)
image = cv2.resize(image, (224, 224))
cv2.imwrite(img_path, image)我们将所有从默认帧大小捕获的图像重新缩放到 (224, 224) 像素,因为我们想尝试像 VGG-16 这样的迁移学习模型,同时已经以 RGB 格式捕获了图像。因此我们已经有 3 个通道,我们不需要指定。VGG-16 所需的通道数为 3,架构的理想形状为 (224, 224, 3)。调整大小步骤完成后,我们可以将所有者的目录转移到图像文件夹中。
图像数据的增强
我们收集并创建了我们的图像,下一步是对数据集执行图像数据增强以复制副本并增加数据集的大小。可以使用以下代码块来做到这一点:
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=30,
shear_range=0.3,
zoom_range=0.3,
width_shift_range=0.4,
height_shift_range=0.4,
horizontal_flip=True,
fill_mode='nearest')train_generator = train_datagen.flow_from_directory(directory,
target_size=(Img_Height, Img_width),
batch_size=batch_size,
class_mode='categorical',
shuffle=True)重新缩放图像并更新所有参数以适合我们的模型,参数如下:
1,重新调整=重标度由1/255归一化每个像素值的
2 rotation_range =指定旋转随机范围
3. shear_range =指定在逆时针方向范围内的每个角度的强度
4. zoom_range = 指定缩放范围
5. width_shift_range = 指定扩展的宽度
6. height_shift_range = 指定扩展的高度
7. horizontal_flip =水平翻转图像
8. fill_mode= 根据最近的边界填充
train_datagen.flow_from_directory 获取目录的路径并生成批量增强数据。可调用的属性如下:
1. train dir = 指定我们存储图像数据的目录
2. color_mode = 图像灰度或RGB 格式,默认为 RGB
3. target_size = 图像的尺寸
4.batch_size =操作数据批次的数目
5. class_mode = 确定返回的标签数组的类型
6.shuffle= shuffle:是否对数据进行混洗(默认:True)
构建模型
在下一个代码块中,我们将在变量 VGG16_MODEL 中导入 VGG-16 模型,并确保我们输入的模型没有顶层。使用没有顶层的 VGG-16 架构,我们现在可以添加我们的自定义层。为了避免训练 VGG-16 层,我们给出以下命令:
layers.trainable = False。我们还将打印出这些层并确保它们的训练设置为 False。
VGG16_MODEL = VGG16(input_shape=(Img_width, Img_Height, 3), include_top=False, weights='imagenet')for layers in VGG16_MODEL.layers: layers.trainable=Falsefor layers in VGG16_MODEL.layers:print(layers.trainable)在 VGG-16 架构之上构建我们的自定义模型:
# Input layer
input_layer = VGG16_MODEL.output# Convolutional Layer
Conv1 = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='valid',
data_format='channels_last', activation='relu',
kernel_initializer=keras.initializers.he_normal(seed=0),
name='Conv1')(input_layer)# MaxPool Layer
Pool1 = MaxPool2D(pool_size=(2,2),strides=(2,2),padding='valid',
data_format='channels_last',name='Pool1')(Conv1)# Flatten
flatten = Flatten(data_format='channels_last',name='Flatten')(Pool1)# Fully Connected layer-1
FC1 = Dense(units=30, activation='relu',
kernel_initializer=keras.initializers.glorot_normal(seed=32),
name='FC1')(flatten)# Fully Connected layer-2
FC2 = Dense(units=30, activation='relu',
kernel_initializer=keras.initializers.glorot_normal(seed=33),
name='FC2')(FC1)# Output layer
Out = Dense(units=num_classes, activation='softmax',
kernel_initializer=keras.initializers.glorot_normal(seed=3),
name='Output')(FC2)model1 = Model(inputs=VGG16_MODEL.input,outputs=Out)人脸识别模型将使用迁移学习进行训练,我们将使用没有顶层的 VGG-16 模型。将在 VGG-16 模型的顶层添加自定义层,然后我们将使用此迁移学习模型来预测它是否是授权所有者的脸。自定义层由输入层组成,它基本上是 VGG-16 模型的输出。我们添加了一个带有 32 个过滤器的卷积层,kernel_size 为 (3,3),默认步幅为 (1,1),我们使用激活作为 relu,he_normal 作为初始化器。我们将使用池化层对卷积层中的层进行下采样。2 个完全连接的层与激活一起用作 relu,即在样本通过展平层后的密集架构。输出层有一个 num_classes 为 2 的 softmax 激活,它预测num_classes的概率,即授权所有者或额外的参与者或被拒绝的人脸。最终模型将输入作为 VGG-16 模型的开始,输出作为最终输出层。
回调函数
在下一个代码块中,我们将查看面部识别任务所需的回调。
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.callbacks import ReduceLROnPlateau
from tensorflow.keras.callbacks import TensorBoardcheckpoint = ModelCheckpoint("face_rec.h5", monitor='accuracy', verbose=1,save_best_only=True, mode='auto', period=1)reduce = ReduceLROnPlateau(monitor='accuracy', factor=0.2, patience=3, min_lr=0.00001, verbose = 1)logdir='logsface'
tensorboard_Visualization = TensorBoard(log_dir=logdir, histogram_freq=True)我们将导入 3 个必需的回调来训练我们的模型:ModelCheckpoint、ReduceLROnPlateau 和 Tensorboard。
ModelCheckpoint — 此回调用于存储训练后模型的权重。我们通过指定 save_best_only=True 只保存模型的最佳权重。
ReduceLROnPlateau — 此回调用于在指定的epoch数后降低优化器的学习率。在这里,我们将耐心指定为 10。如果在 10 个 epoch 后准确率没有提高,那么我们的学习率就会相应地降低 0.2 倍。
Tensorboard — tensorboard 回调用于绘制图形的可视化,即精度和损失的图形。
编译并拟合模型
model1.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.001),
metrics=['accuracy'])epochs = 20model1.fit(train_generator,
epochs = epochs,
callbacks = [checkpoint, reduce, tensorboard_Visualization])编译和拟合我们的模型。将训练模型并将最佳权重保存到 face_rec.h5,这样就不必反复重新训练模型,并且可以在需要时使用我们保存的模型。本文使用的损失是 categorical_crossentropy,它计算标签和预测之间的交叉熵损失。我们将使用的优化器是 Adam,其学习率为 0.001,我们将根据度量精度编译我们的模型。我们将在增强的训练图像上拟合数据。在拟合步骤之后,这些是我们能够在训练损失和准确性方面取得的结果:

图表
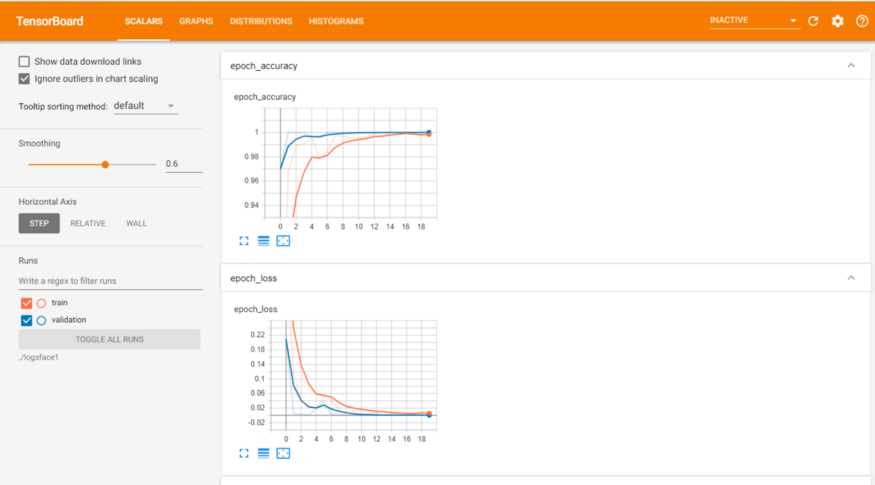
训练数据表:
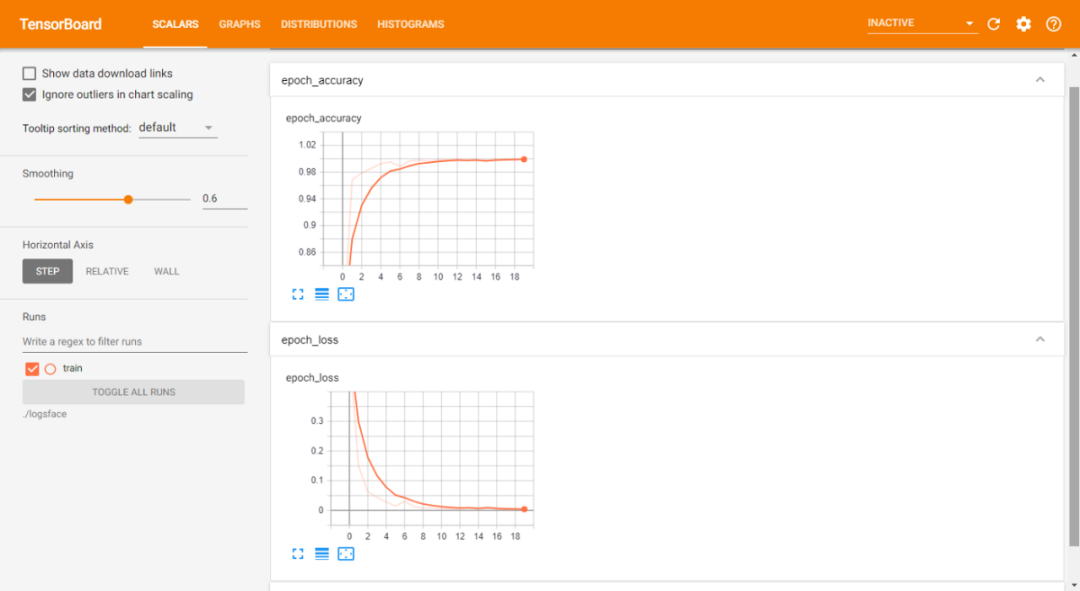
训练和验证数据表:
本文GITHUB代码链接:
https://github.com/Bharath-K3/Smart-Face-Lock-System


往
期
回
顾
资讯
AI被当做炒作工具?
技术
谷歌新深度学习系统促进放射科
资讯
机器学习可以忘记吗?是个好问题
资讯
AI不可以作为专利认证发明人

分享

点收藏

点点赞

点在看
相关文章:

全局唯一ID生成方案
2019独角兽企业重金招聘Python工程师标准>>> 全局唯一ID生成方案对比 - http://cenalulu.github.io/mysql/guid-generate/ 转载于:https://my.oschina.net/meilihao/blog/386264

大型互联网 b2b b2c o2o 电子商务云平台
技术解决方案 开发语言: java、j2ee 数据库:mysql JDK支持版本: JDK1.6、JDK1.7、JDK1.8版本 核心技术:分布式、云服务、微服务、服务编排等。 核心架构: 使用Spring Cloud分布式微服务云架构进行服务化开发࿰…
Linux下redis安装部署
1、下载源代码 http://code.google.com/p/redis/downloads/list 下载redis-1.2.6.tar.gz 将下载包拷贝到/usr/local/webserver/redis-1.2.6/下 2、安装 tar -zxvf redis-1.2.6.tar.gzce redis-1.2.6make 3、调整内存 如果内存情况比较紧张的话,需要设定内核参数&am…

阿里无人车配送快递突破 100 万单,小蛮驴牵引的自动驾驶战略布局
作者 | 张昊 出品 | AI科技大本营(ID:rgznai100) 从物流的“最后”三公里中,我们看到了自动驾驶技术的“最前”沿 在9月27日举办的达摩院媒体沟通会上,阿里巴巴集团副总裁、达摩院自动驾驶实验室负责人王刚宣布,达摩院…
[Python] 中文路径和中文文本文件乱码问题
情景: Python首先读取名为log.txt的文本文件, 其中包含有文件名相对路径信息filename. 随后Python调用shutil.copy2(src, dst)对该filename文件进行复制操作. 由于filename为相对路径信息, 所以我们需要硬编码写入父目录, 假设为"C:\\源目录\\", 同时还有目标目录信息…

kubernetes Helm
Helm产生原因利用Kubernetes部署一个应用,需要Kubernetes原生资源文件如deployment、replicationcontroller、service或pod 等。而对于一个复杂的应用,会有很多类似上面的资源描述文件,如果有更新或回滚应用的需求,可能要修改和维…

造车新势力“围猎”秋招,应届生如何拿下高薪 offer ?
作者 | 易璜珵 出品 | 《新程序员》近年来,互联网大厂的秋招开启得越来越早,只为先人一步将优秀的毕业生纳入麾下。所谓“金九银十”,九月即将结束,许多大厂的秋招正式批也逐渐进入笔试和面试环节。在新能源汽车领域…
云评测、云监测、云加速,性能魔方mmTrix全球速度最快
在移动互联网高速发展的今天,互联网企业如果要实现业务增长,在激烈的市场竞争中站稳脚跟,必须要尽可能的提高用户体验和产品影响力。而要达实现这个目标,产品应用性能质量的好坏往往起到重要作用,APM服务受到了越来越多…
水平切分与垂直切分
数据库优化无非水平切分与垂直切分! 1.水平.就是按记录分. 一个数据库有3000W用户记录.处理速度比较慢.这时可以把3000W.分成三份.每份都是1000W.分别放在不同的机器上. 2.垂直分割就是按字段分. 一个数据库有3000W用户记录.包括字段id,user,password,first_name,l…
iOS 设计模式浅析 1 - 策略
本篇文章主要讲三个点: 1. 什么是策略模式.2. 策略模式的优缺点.3. demo .1. 策略模式定义一系列算法, 并且将每个算法封装起来, 算法之间可以互相替换. 使用前提: 输入已知, 好比你渴了, 可以喝可乐, 可以喝牛奶, 也可以喝水. 在我们项目中比较常见的使用情况: 1. 切换主题, 要…
何崚谈阿里巴巴前端性能优化最佳实践
转载:http://www.infoq.com/cn/interviews/hl-alibaba-front-end-performance-optimization 大家好,我现在在阿里巴巴园区采访阿里巴巴中文站架构师,兼B2B网站优化领域的负责人何崚。何崚你好,请简单介绍一下你自己。 我叫何崚&am…
java基础_04
2019独角兽企业重金招聘Python工程师标准>>> 1、java语言的程序结构。Java语言支持3种程序结构:顺序结构、选择结构(分支结构)、循环结构2、顺序结构是最简单、最普遍的一种。java程序如果没有意外都是按照从前到后、从左到右的顺…

会唱歌、会弹琴,清华大学 AI 学生华智冰火了
整理 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 清华大学计算机系知识工程实验室,开发的中国首个原创虚拟学生——华智冰,与近日亮相。她的声音、肢体动作全部由人工智能完成。 今年6月,清华大学计算机系录取了一位…
22. Node.Js Buffer类(缓冲区)-(二)
转自:https://blog.csdn.net/u011127019/article/details/52512242转载于:https://www.cnblogs.com/sharpest/p/8046463.html
linux安装sphinx
从sphnix网站下载sphinx源码包,当前最新版本是: http://sphinxsearch.com/files/sphinx-0.9.9.tar.gz。当然,还需要保证你的系统已经安装了mysql。其次,就是依照官方的安装指导进行安装了,基本步骤如下:解压…

机器人越像人越好?被机器人盯着会变『蠢』
编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 摘要:人形机器人的凝视会影响人们对社会决策任务的反应方式。 资料来源:IIT 你是否遇到过这种问题,跟别人对是不超过三秒?当你直视别人眼睛的时候&#x…
SQL Server 储存过程的output 参数
要做的参数的回传一方面要做到有储存过程的配合,再一方面也要有调用方法的配合,也就是说错误的调用方法是没有办法把值回传的。 下面是例子 --1、储存过程方面的配合 create procedure dbo.usp_C i as int output ---**注意这里要用output 关键字**--…
JavaScript基础笔记集合(转)
JavaScript基础笔记集合 JavaScript基础笔记集合js简介 js是脚本语言。浏览器是逐行的读取代码,而传统编程会在执行前进行编译 js存放的位置 html脚本必须放在<script>、</script>之内。 <script>可放置在<head>、<body>里 和css一…
Xapian安装
Xapian是一个用C编写的全文检索程序,他的作用类似于Java的lucene。Xapian除了提供原生的C编程接口之外,还提供了Perl,PHP,Python和Ruby编程接口和相应的类库,所以你可以直接从自己喜欢的脚本编程语言当中使用Xapian进行…
IOS开发中多线程的使用
一、创建多线程的五种方式1.开启线程的方法一 NSThread * thread[[NSThread alloc] initWithTarget:self selector:selector(_update) object:nil]; 2.开启线程的方法二 [NSThread detachNewThreadSelector:selector(_update) toTarget:self withObject:nil]; 3.开启线程的方法…

介绍如何用 Python 来绘制高清的交互式地图,建议收藏
作者 |俊欣来源 |关于数据分析与可视化今天小编来为大家介绍一个叫做Folium的模块,我们可以用它来绘制高清的交互式地图,并且标注出重要的地理位置等等,读者在看过本篇文章之后,读者大致会掌握1. 使用Folium来进行交互式地图的绘制…

Pandas Cheat Sheet
Pandas Doc: http://pandas.pydata.org/pandas-docs/stable/10min.html#min 转载于:https://www.cnblogs.com/nuswgg95528736/p/8053582.html
google ProtoBuf开发者指南
目录 1 概览 1.1 什么是protocol buffer 1.2 他们如何工作 1.3 为什么不用XML? 1.4 听起来像是为我的解决方案,如何开始? 1.5 一点历史 2 语言指导 2.1 定义一个消息类型 2.2 值类型 2.3 可选字段与缺省值 2.4 枚举 2.5 使用其他消息…
AI 生成的代码可信吗?编写的代码有 Bug 吗?
编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 即使是帮助开发人员编写软件的工具也会产生类似的bug。 目前,大部分的软件开发人员会让 AI 帮助开发者们编写代码,但是开发人员发现 AI 会像程序员的代码一样还是存有 bug。 去年…
嵌入式开发之信号采集同步---VSYNC和HSYNC的作用以及它们两者之间的关系
VSYNC和HSYNC的作用以及它们两者之间的关系 VSYNC和HSYNC的作用以及它们两者之间的关系 VSYNC和HSYNC是什么 VSYNC: vertical synchronization,指与显示器的帧数同步。 简单来说就是启用了VSYNC的渲染过程,帧数不会超过显示器的帧数,一个同步…
对ListenSocket 的研究(四)
对postmaster.c 中的 readmask,rmask,nsocket等进行分析,可以看到:它们之间有如下的关系(与细节无关的代码省略):复制代码/* * Initialise the masks for select() for the ports we are listenin…
MySQL下的NoSQL解决方案HandlerSocket
目前使用MySQL的网站,多半同时使用Memcache作为键值缓存。虽然这样的架构极其流行,有众多成功的案例,但过于依赖Memcache,无形中让Memcache成为故障的根源: Memcache数据一致性的问题:当MySQL数据变化后&a…

人群距离监测 DeepSOCIAL 最全汉化论文+源码导读
作者 |神经星星来源 |HyperAI超神经By 超神经内容一览:在疫情期间,公共场所中尽量避免人群聚集,可以有效控制疫情扩散。英国利兹大学的研究团队开源了 DeepSOCIAL 人群距离监测项目,通过 YOLOv4SORT 的方式快速实现了这一应用。关…
堆和栈的差别(转过无数次的文章)
一、预备知识—程序的内存分配 一个由C/C编译的程序占用的内存分为下面几个部分 1、栈区(stack)— 由编译器自己主动分配释放 ,存放函数的參数值,局部变量的值等。其 操作方式相似于数据结构中的栈。 2、堆区&…
ARM WFI和WFE指令【转】
本文转载至:http://www.wowotech.net/armv8a_arch/wfe_wfi.html 1. 前言 蜗蜗很早以前就知道有WFI和WFE这两个指令存在,但一直似懂非懂。最近准备研究CPU idle framework,由于WFI是让CPU进入idle状态的一种方法,就下决心把它们弄清…