如何利用 Python 爬取 LOL 高清精美壁纸?
作者 | 阿拉斯加
来源 | 杰哥的IT之旅
一、背景介绍
随着移动端的普及出现了很多的移动 APP,应用软件也随之流行起来。最近看到英雄联盟的手游上线了,感觉还行,PC 端英雄联盟可谓是爆火的游戏,不知道移动端的英雄联盟前途如何,那今天我们使用到多线程的方式爬取 LOL 官网英雄高清壁纸。
二、页面分析
目标网站:
https://lol.qq.com/data/info-heros.shtml#Navi
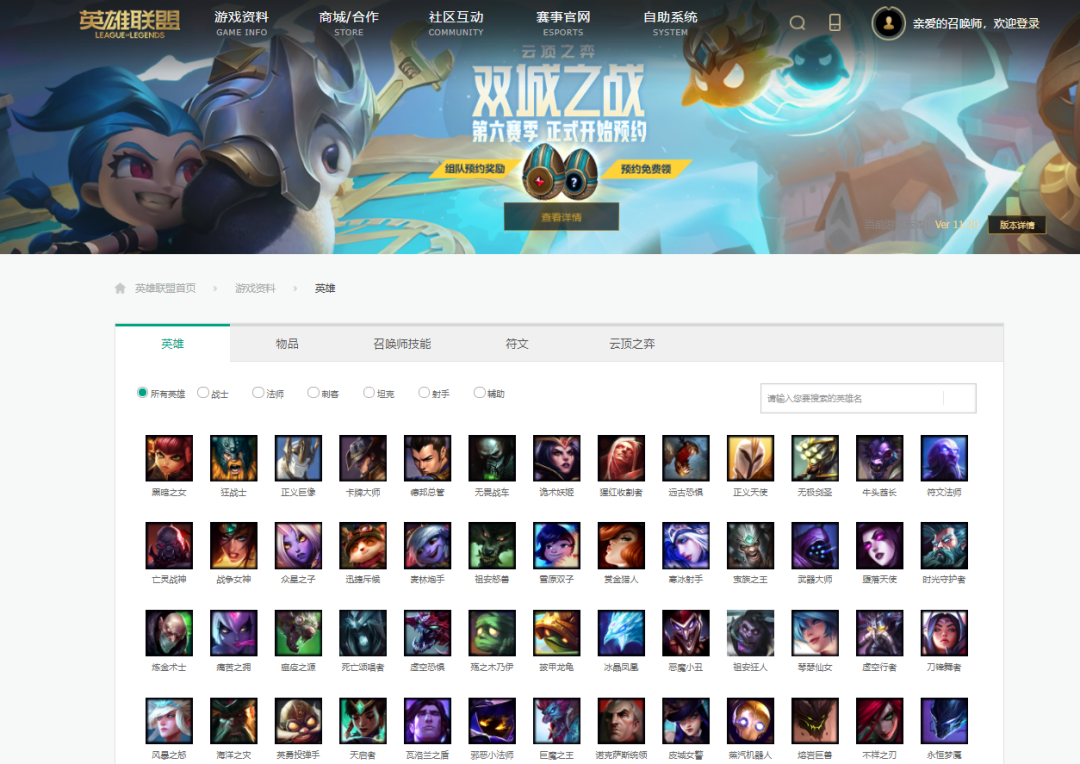
官网界面如图所示,显而易见,一个小图表示一个英雄,我们的目的是爬取每一个英雄的所有皮肤图片,全部下载下来并保存到本地。
次级页面
上面的页面我们称为主页面,次级页面也就是每一个英雄对应的页面,就以黑暗之女为例,它的次级页面如下所示:
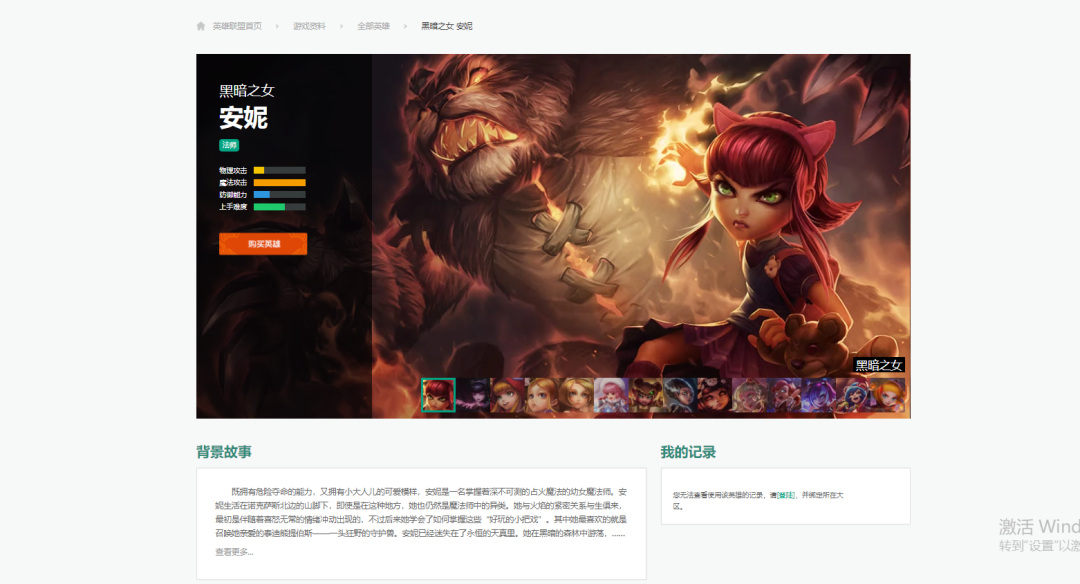
我们可以看到有很多的小图,每一张小图对应一个皮肤,通过 network 查看皮肤数据接口,如下图所示:
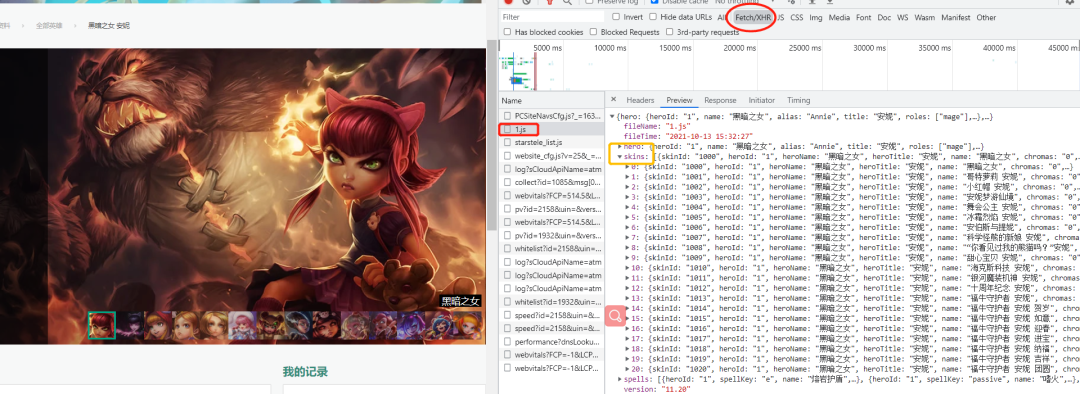
我们知道了皮肤信息是一个 json 格式的字符串进行传输的,那么我们只要找到每个英雄对应的 id,找到对应的 json 文件,提取需要的数据就能得到高清皮肤壁纸。
然后这里黑暗之女的 json 的文件地址是:
hero_one = 'https://game.gtimg.cn/images/lol/act/img/js/hero/1.js'这里其实规律也非常简单,每个英雄的皮肤数据的地址是这样的:
url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(id)那么问题来了 id 的规律是怎么样的呢?这里英雄的 id 需要在首页查看,如下所示:
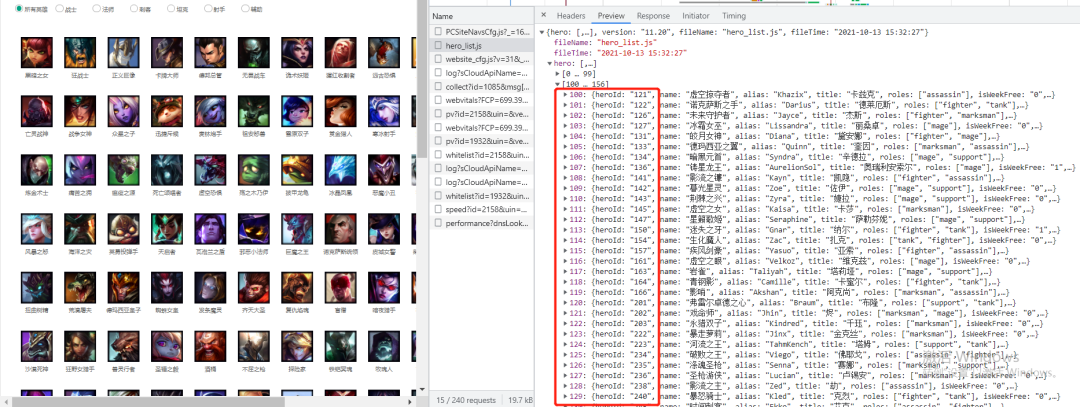
我们可以看到两个列表[0,99],[100,156],即 156 个英雄,但是 heroId 却一直到了 240….,由此可见,它是有一定的变化规律的,并不是依次加一,所以要爬取全部英雄皮肤图片,需要先拿到全部的heroId。
三、抓取思路
为什么使用多线程,这里解释一下,我们在爬取图片,视频这种数据的时候,因为需要保存到本地,所以会使用大量的文件的读取和写入操作,也就是 IO 操作,试想一下如果我们进行同步请求操作;
那么在第一次请求完成一直到文件保存到本地,才会进行第二次请求,那么这样效率非常低下,如果使用多线程进行异步操作,效率会大大提升。
所以必然要使用多线程或者是多进程,然后把这么多的数据队列丢给线程池或者进程池去处理;
在 Python 中,multiprocessing Pool 进程池,multiprocessing.dummy 非常好用。
multiprocessing.dummy模块:dummy模块是多线程;multiprocessing模块:multiprocessing是多进程;
multiprocessing.dummy模块与multiprocessing模块两者的 api 都是通用的,代码的切换使用上比较灵活;
我们首先在一个测试的 demo.py 文件抓取英雄 id,这里的代码我已经写好了,得到一个储存英雄 id 的列表,直接在主文件里使用即可;
demo.py
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
res = requests.get(url,headers=headers)
res = res.content.decode('utf-8')
res_dict = json.loads(res)
heros = res_dict["hero"] # 156个hero信息
idList = []
for hero in heros:hero_id = hero["heroId"]idList.append(hero_id)
print(idList)得到 idList 如下所示:
idlist = [1,2,3,….,875,876,877] # 中间的英雄 id 这里不做展示
构建的 url:
page = 'http://www.bizhi88.com/s/470/{}.html'.format(i)
这里的 i 表示 id,进行 url 的动态构建;
那么我们定制两个函数一个用于爬取并且解析页面(spider),一个用于下载数据 (download),开启线程池,使用 for 循环构建存储英雄皮肤 json 数据的 url,储存在列表中,作为 url 队列,使用 pool.map() 方法执行 spider (爬虫)函数;
def map(self, fn, *iterables, timeout=None, chunksize=1):"""Returns an iterator equivalent to map(fn, iter)”“”
# 这里我们的使用是:pool.map(spider,page) # spider:爬虫函数;page:url队列作用:将列表中的每个元素提取出来当作函数的参数,创建一个个进程,放进进程池中;
参数1:要执行的函数;
参数2:迭代器,将迭代器中的数字作为参数依次传入函数中;
json数据解析
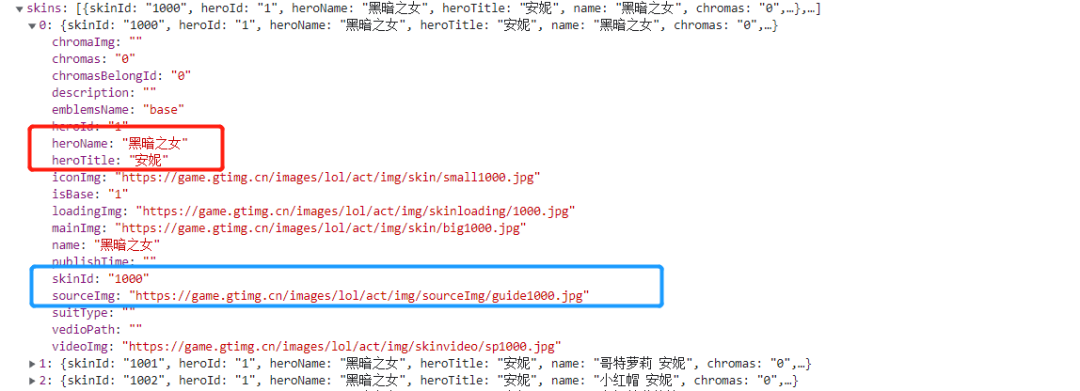
这里我们就以黑暗之女的皮肤的 json 文件做展示进行解析,我们需要获取的内容有 1.name,2.skin_name,3.mainImg,因为我们发现 heroName 是一样的,所以把英雄名作为该英雄的皮肤文件夹名,这样便于查看保存;
item = {}
item['name'] = hero["heroName"]
item['skin_name'] = hero["name"]
if hero["mainImg"] == '':continue
item['imgLink'] = hero["mainImg"]有一个注意点:
有的 mainImg 标签是空的,所以我们需要跳过,否则如果是空的链接,请求时会报错;
四、数据采集
导入相关第三方库
import requests # 请求
from multiprocessing.dummy import Pool as ThreadPool # 并发
import time # 效率
import os # 文件操作
import json # 解析页面数据解析
def spider(url):res = requests.get(url, headers=headers)result = res.content.decode('utf-8')res_dict = json.loads(result)skins = res_dict["skins"] # 15个hero信息print(len(skins))for index,hero in enumerate(skins): # 这里使用到enumerate获取下标,以便文件图片命名;item = {} # 字典对象item['name'] = hero["heroName"]item['skin_name'] = hero["name"]if hero["mainImg"] == '':continueitem['imgLink'] = hero["mainImg"]print(item)download(index+1,item)download 下载图片
def download(index,contdict):name = contdict['name']path = "皮肤/" + nameif not os.path.exists(path):os.makedirs(path)content = requests.get(contdict['imgLink'], headers=headers).contentwith open('./皮肤/' + name + '/' + contdict['skin_name'] + str(index) + '.jpg', 'wb') as f:f.write(content)这里我们使用 OS 模块创建文件夹,前面我们有说到,每个英雄的 heroName 的值是一样的,借此创建文件夹并命名,方便皮肤的保存(归类),然后就是这里图片文件的路径需要仔细,少一个斜杠就会报错。
main() 主函数
def main(): pool = ThreadPool(6)page = []for i in range(1,21):newpage = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(i)print(newpage)page.append(newpage)result = pool.map(spider, page)pool.close()pool.join()end = time.time()说明:
在主函数里我们首选创建了六个线程池;
通过 for 循环动态构建 20 条 url,我们小试牛刀一下,20 个英雄皮肤,如果爬取全部可以对之前的 idList 遍历,再动态构建 url;
使用 map() 函数对线程池中的 url 进行数据解析存储操作;
当线程池 close 的时候并未关闭线程池,只是会把状态改为不可再插入元素的状态;
五、程序运行
if __name__ == '__main__':main()结果如下:

当然了这里只是截取了部分图像,总共爬取了 200+ 张图片,总体来说还是可以。
六、总结
本次我们使用了多线程爬取了英雄联盟官网英雄皮肤高清壁纸,因为图片涉及到 IO 操作,我们使用并发方式进行,大大提高了程序的执行效率。
当然爬虫浅尝辄止,此次小试牛刀,爬取了 20 个英雄的皮肤图片,感兴趣的小伙伴可以把皮肤全部爬取下来,只需要改变遍历的元素为之前的 idlist 即可。
相关文章:

生产环境主从数据同步不了?
生产环境主从数据同步不了?经历过程: 一般我们常常在做主从复制的时候,可能是很少遇到到错误,那都是因为,你做主从基本用的是,本地虚拟机做,或者一些测试环境做。但是当我们把主从复制部署…

用 YOLOv5模型识别出表情!
作者 | 闫永强来源 | Datawhale本文利用YOLOV5对手势进行训练识别,并识别显示出对应的emoji,如同下图:本文整体思路如下。提示:本文含完整实践代码,代码较长,建议先看文字部分的实践思路,代码先…
Linux操作系统中内存buffer和cache的区别
我们一开始,先从Free命令说起。 free 命令相对于top 提供了更简洁的查看系统内存使用情况: $ freetotal used free shared buffers cachedMem: 255268 238332 16936 0 85540 126384-/ buffers/cache: 26408 228860Swap: 265000 …
sort cut 命令的常用用法
sort命令介绍:sort是在Linux里非常常用的一个命令,管排序的,集中精力,五分钟搞定sort,现在开始!1 sort的工作原理sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后&…

使用 dockerfile 创建镜像
dockerfile 是一个文本格式的配置文件,可以使用 dockerfile 快速创建自定义的镜像。 dockerfile 一般包含4部分信息:基础镜像信息、维护者信息、镜像操作指令、容器启动时执行指令 创建镜像命令:docker build [选项] 路径,会读取指…
wireshark的使用教程--用实践的方式帮助我们理解TCP/IP中的各个协议是如何工作的
wireshark的使用教程 --用实践的方式帮助我们理解TCP/IP中的各个协议是如何工作的 wireshark是一款抓包软件,比较易用,在平常可以利用它抓包,分析协议或者监控网络,是一个比较好的工具,因为最近在研究这个,…

设计师你们还坐的住吗?2021 PS 进入人工智能 P 图时代
与每年一样,Adobe 的 Max 2021 活动顺利开展。本次活动主要是以产品展示以及其他创新产品。 这个活动最有趣的特点之一是,Adobe 不断将人工智能集成到其产品或是功能中。在过去的几年里,人工智能一直是这家公司不断探索的领域。 与许多其他公…
图像处理之噪声---椒盐,白噪声,高斯噪声三种不同噪声的区别
白噪声是指功率谱密度在整个频域内均匀分布的噪声。 所有频率具有相同能量的随机噪声称为白噪声。白噪声或白杂讯,是一种功率频谱密度为常数的随机信号或随机过程。换句话说,此信号在各个频段上的功率是一样的,由于白光是由各种频率ÿ…

发现一个“佛系记账本”
因为这是一款微信小程序,张小龙大力推崇的“用完即走”完美地适合记账应用。 不用下载、不用安装、不用注册、不用各种授权,只要从微信进入,就能记账,账本只与微信关联。 换手机、换PAD都无所谓,只要登录微信ÿ…
YSLOW法则中,为什么yahoo推荐用GET代替POST?
原文:http://www.cnxct.com/use-get-for-ajax-requests-why/ 背景:上上周五,公司前端工程师培训,提到前端优化的一些技巧,当然不能少了yahoo yslow的优化法则。其中有这么一条“Use GET for AJAX Requests”࿰…

Python 多进程、协程异步抓取英雄联盟皮肤并保存在本地
作者 | 俊欣来源 | 关于数据分析与可视化就在11月7日晚间,《英雄联盟》S11赛季全球总决赛决斗,在冰岛拉开“帷幕”,同时面向全球直播。在经过了5个小时的鏖战,EDG战队最终以3:2战胜来自韩国LCK赛区的DK战队,获得俱乐部…
QT 5.4.1 for Android Ubuntu QtWebView Demo
QT 5.4.1 for Android Ubuntu QtWebView Demo 2015-5-15 目录 一、说明: 二、参考文章: 三、QtWebView Demo在哪里? 四、Qt Creator 3.4.0能打开QtWebView Demo? 五、Qt Creator如何生成AndroidManifest.xml? 一、…
硬改TP-Link WR841N v8刷breed和OpenWrt
找到了以前的路由器,想刷OpenWrt但版本是TP-Link的WR841N v8版,上网查过才知道,是专门面向国内发布的严重缩水版国际版的Flash是4M,内存RAM是32M,国内版是2M/16M,不过论坛上也有人说到手的Flash是4M的。(Op…

Facebook的实时Hadoop系统
原文地址: http://blog.solrex.org/articles/facebook-realtime-hadoop-system.html作者:杨文博Facebook 在今年六月 SIGMOD 2011 上发表了一篇名为“Apache Hadoop Goes Realtime at Facebook”的会议论文 (pdf),介绍了 Facebook 为了打造一…
Ka的回溯编程练习 Part1|整划什么的。。
1 #include<stdio.h>2 int search(int s,int t);3 void op(int k);4 int res[1001]{1},n;5 int main()6 {7 //scanf("%d",&n);8 n10;9 search(n,1); 10 return 0; 11 } 12 int search(int s,int t) //当前数的大小s,个数n 13 …

开发者关心的十个数据库技术问题
作者 | 雷海林 责编 | 田玮靖出品 | 《新程序员》如今,数据库越来越受到业界的广泛关注,许多高校毕业生及资深技术人也逐渐投身于数据库产业。《新程序员002》经过用户、专家调研,收集汇总了十个开发者关心的数据库技术问题,…
使用T-SQL语句操作数据表-更新数据
使用update语句更新表中的数据。也就是修改表中的数据。update语法格式:update <表名> set <列名更新值> [where <更新条件>] 解释:update 是更新数据名, 表明是更新数据set 是必要的, 后面可以紧随多个数据列的…

Category Archives: Linux
原文地址:http://blog.solrex.org/articles/solrex-linux-cheatsheet.html Cheatsheet:原意是考试的时候带的小抄,所以说是 cheat(作弊) sheet。在计算机科学领域里,主要是指记录一些难记命令或者操作的快查…

利用 OpenCV+ConvNets 检测几何图形
作者 | 小白 来源 | 小白学视觉 导读 人工智能领域中增长最快的子领域之一是自然语言处理(NLP),它处理计算机与人类(自然)语言之间的交互,特别是如何编程计算机以处理和理解大量自然语言数据。 自然语言处理…

《Linux实践及应用》
2019独角兽企业重金招聘Python工程师标准>>> 《Linux实践及应用》 本书以RedHat 9.0为蓝本,系统地介绍Linux的基础知识、Linux系统的安装与配置、常用命令,以及如何进行Linux系统管理和基本的网络服务设置(包括如何设置DNS服务器、…
找不到包含 OwinStartupAttribute 的程序集
2019独角兽企业重金招聘Python工程师标准>>> 尝试加载应用时出现了以下错误。 找不到包含 OwinStartupAttribute 的程序集。找不到包含 Startup 或 [AssemblyName].Startup 类的程序集。 若要禁用 OWIN 启动发现,请在 web.config 中为 appSetting owin:A…

Imagination 推新款GPU IP,首次实现桌面级光线追踪效果
游戏界被炒得最热的概念可能就是光线追踪技术了,不仅仅是PC端的游戏。光线追踪所展示出来的画面效果也确实惊艳,可以让我们感叹到图像技术达到的一个新高度。 但是实际上,光线追踪并不是一个新技术。10年前,光追就是游戏玩家茶余…
percent之集合
2019独角兽企业重金招聘Python工程师标准>>> 这个留到明天再来写吧,今天把hub剩下的坑填掉. 转载于:https://my.oschina.net/u/2011113/blog/416458

Mr. Process的一生-Linux内核的社会视角 (2)启动
原文地址: http://www.manio.org/cn/startup-of-linux-view-of-society.html 其实这才应该是这一系列文章的第一节,因为这篇文章讲的是盘古开天地的事。话说Mr. Process是一个现代人,但是,只要是人,总该有个祖先。人们…
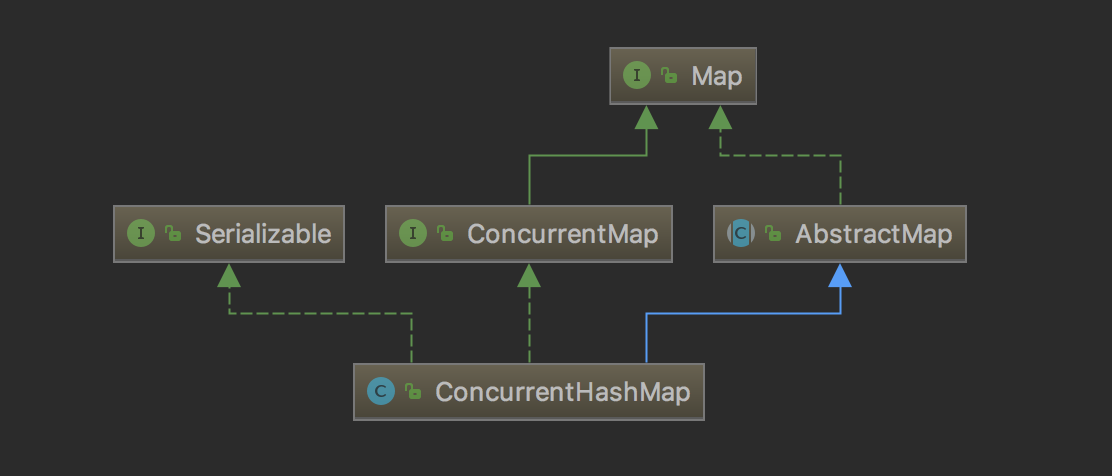
深入研究ConcurrentHashMap 源码从7到8的变迁
ConcurrentHashMap是线程安全且高效的HashMap 1 为什么要使用ConcurrentHashMap 线程不安全的HashMap HashMap是Java中最常用的一个Map类,性能好、速度快,但不能保证线程安全,它可用null作为key/value HashMap的线程不安全主要体现在resize时…
IANA定义的常见服务的端口号列表
最新明细:http://www.iana.org/assignments/port-numbers 几个重要常见端口: 21 FTP 22 SSH 80 HTTP 443 HTTPS 1433 MSSQLserver 3306 MySQL 11211 memcached
oracel 服务详细介绍
中的方法成功安装Oracle 11g后,共有7个服务, 这七个服务的含义分别为: 1. Oracle ORCL VSS Writer Service: Oracle卷映射拷贝写入服务,VSS(Volume Shadow Copy Service)能够让存储基础设备&…

使用 Python 开发一个恐龙跑跑小游戏,玩起来
作者 | 周萝卜 来源 | 萝卜大杂烩 相信很多人都玩过 chrome 浏览器上提供的恐龙跑跑游戏,在我们断网或者直接在浏览器输入地址“chrome://dino/”都可以进入游戏 今天我们就是用 Python 来制作一个类似的小游戏 素材准备 首先我们准备下游戏所需的素材,比…
了解和入门注解的应用
2019独角兽企业重金招聘Python工程师标准>>> 一、概述 jdk的java.lang包中提供的最基本的annotation 1、SuppressWarnings("deprecation") package staticimport.annotation;SuppressWarnings("deprecation") public class AnnotationTest {pub…
Linux下开发优秀链接
不得不说CSDN博客这次改版变化很大,但是友情链接功能太脆弱了。 只有自己写个帖子,不断更新吧。Linux基础 Linux内核mirrors163LVS中文站点 孙海龙 howtoforge.com 地中海东岸的蒲公英 服务器运维与网站架构 Nginx中文维基 ACME Bory.Chan Tim[后端技术]…