深入研究ConcurrentHashMap 源码从7到8的变迁
ConcurrentHashMap是线程安全且高效的HashMap
1 为什么要使用ConcurrentHashMap
- 线程不安全的HashMap
HashMap是Java中最常用的一个Map类,性能好、速度快,但不能保证线程安全,它可用null作为key/value
HashMap的线程不安全主要体现在resize时的死循环及使用迭代器时的fast-fail
在多线程环境下,使用HashMap进行put会引起死循环,所以在并发情况下不能使用HashMap.例如,执行以下代码会引起死循环.
final HashMap<String, String> map = new HashMap<>(2);Thread t = new Thread(() -> {for (int i = 0; i < 10000; i++) {new Thread(() -> map.put(UUID.randomUUID().toString(), ""), "ftf" + i).start();}}, "ftf");t.start();t.join();
HashMap在并发执行put会引起死循环,是因为多线程会导致HashMap的Entry链表成环,一旦成环,Entry的next节点永远不为空,产生死循环
而
- 效率低下的HashTable
线程安全的Map类,其public方法均用synchronize修饰
这表示在多线程操作时,每个线程在操作之前都会锁住整个map,待操作完成后才释放
如线程1使用put进行元素添加,线程2不但不能使用put方法进行添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低,这必然导致多线程时性能不佳.另外,Hashtable不能使用null作为key/value - 锁分段技术可有效提升并发访问率
我们可以回想一下,Hashtable(或者替代方案 Collections.synchronizedMap)的可伸缩性的主要障碍是它使用了一个 map 范围的锁,为了保证插入、删除或者检索操作的完整性必须保持这样一个锁,而且有时候甚至还要为了保证迭代遍历操作的完整性保持这样一个锁。这样一来,只要锁被保持,就从根本上阻止了其他线程访问 Map,即使处理器有空闲也不能访问,这样大大地限制了并发性。
ConcurrentHashMap 摒弃了单一的 map 范围的锁,取而代之的是由 32 个锁组成的集合,其中每个锁负责保护 hash bucket 的一个子集。锁主要由变化性操作(put() 和 remove())使用。具有 32 个独立的锁意味着最多可以有 32 个线程可以同时修改 map。这并不一定是说在并发地对 map 进行写操作的线程数少于 32 时,另外的写操作不会被阻塞――32 对于写线程来说是理论上的并发限制数目,但是实际上可能达不到这个值。但是,32 依然比 1 要好得多,而且对于运行于目前这一代的计算机系统上的大多数应用程序来说已经足够了- 首先将数据分成一段一段地存储
- 然后给每一段数据配一把锁
- 当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问
2 ConcurrentHashMap的结构
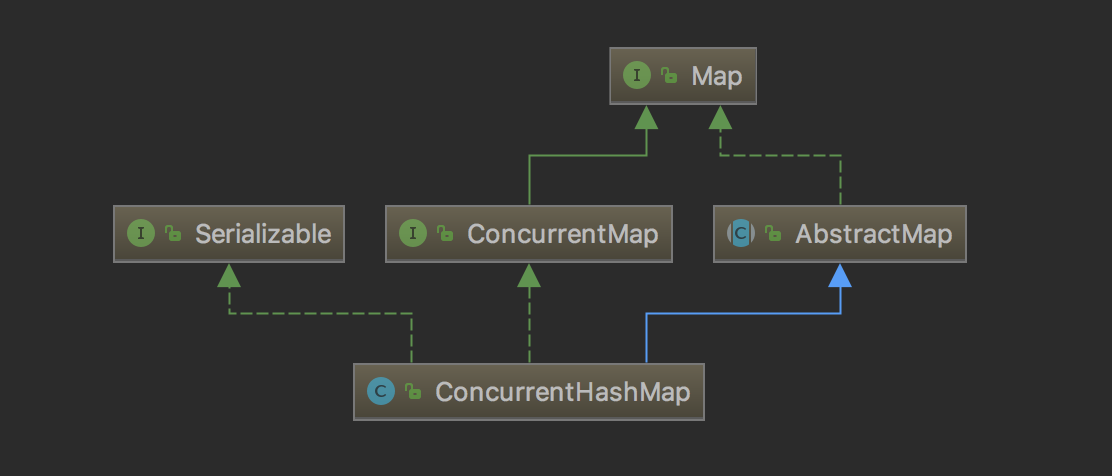
通过ConcurrentHashMap的类图来分析ConcurrentHashMap的结构
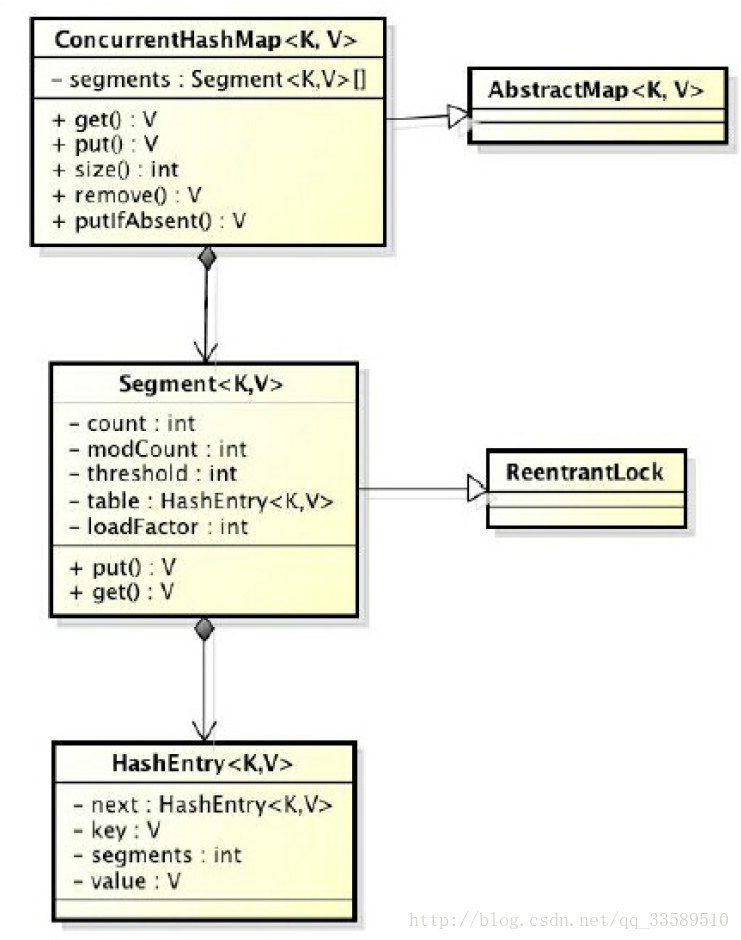
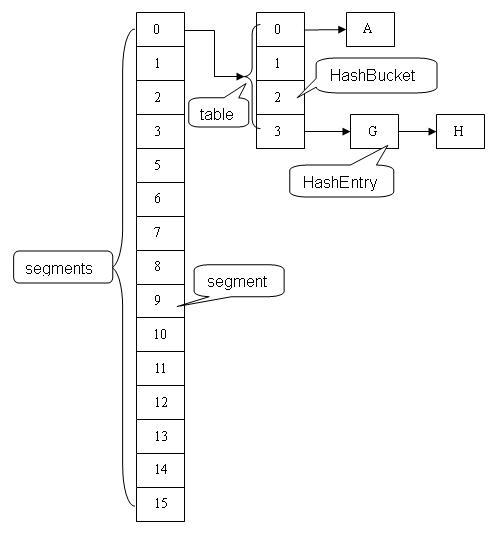
ConcurrentHashMap是由Segment数组和HashEntry数组组成
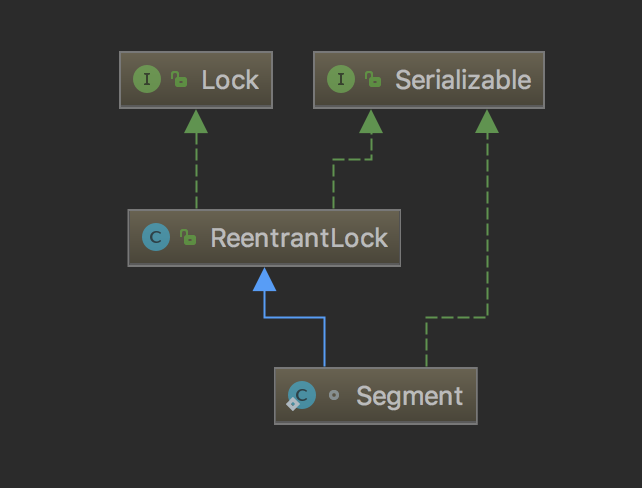
2.1 Segment是一种可重入锁
static final class Segment<K,V> extends ReentrantLock implements Serializable { /** * 在本 segment 范围内,包含的 HashEntry 元素的个数* 该变量被声明为 volatile 型*/ transient volatile int count; /** * table 被更新的次数*/ transient int modCount; /** * 当 table 中包含的 HashEntry 元素的个数超过本变量值时,触发 table 的再散列*/ transient int threshold; /** * table 是由 HashEntry 对象组成的数组* 如果散列时发生碰撞,碰撞的 HashEntry 对象就以链表的形式链接成一个链表* table 数组的数组成员代表散列映射表的一个桶* 每个 table 守护整个 ConcurrentHashMap 包含桶总数的一部分* 如果并发级别为 16,table 则守护 ConcurrentHashMap 包含的桶总数的 1/16 */ transient volatile HashEntry<K,V>[] table; /** * 装载因子*/ final float loadFactor; Segment(int initialCapacity, float lf) { loadFactor = lf; setTable(HashEntry.<K,V>newArray(initialCapacity)); } /** * 设置 table 引用到这个新生成的 HashEntry 数组* 只能在持有锁或构造函数中调用本方法*/ void setTable(HashEntry<K,V>[] newTable) { // 计算临界阀值为新数组的长度与装载因子的乘积threshold = (int)(newTable.length * loadFactor); table = newTable; } /** * 根据 key 的散列值,找到 table 中对应的那个桶(table 数组的某个数组成员)*/ HashEntry<K,V> getFirst(int hash) { HashEntry<K,V>[] tab = table; // 把散列值与 table 数组长度减 1 的值相“与”,
// 得到散列值对应的 table 数组的下标// 然后返回 table 数组中此下标对应的 HashEntry 元素return tab[hash & (tab.length - 1)]; }
}
Segment 类继承于 ReentrantLock ,从而使得 Segment 对象能充当锁的角色
Segment 对象用来守护其(成员对象 table 中)包含的若干个桶
table 是一个由 HashEntry 对象组成的数组。table 数组的每一个数组成员就是散列映射表的一个桶。
count 变量是一个计数器,它表示每个 Segment 对象管理的 table 数组(若干个 HashEntry 组成的链表)包含的 HashEntry 对象的个数。每一个 Segment 对象都有一个 count 对象来表示本 Segment 中包含的 HashEntry 对象的总数。注意,之所以在每个 Segment 对象中包含一个计数器,而不是在 ConcurrentHashMap 中使用全局的计数器,是为了避免出现“热点域”而影响 ConcurrentHashMap 的并发性。
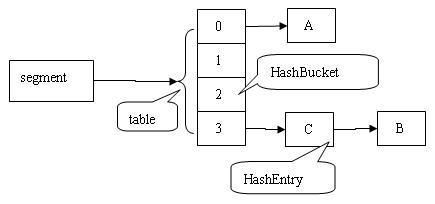
依次插入 ABC 三个 HashEntry 节点后,Segment 的结构示意图。
2.2 HashEntry则用于存储键值对数据
static final class HashEntry<K,V> { final K key; // 声明 key 为 final 型final int hash; // 声明 hash 值为 final 型 volatile V value; // 声明 value 为 volatile 型final HashEntry<K,V> next; // 声明 next 为 final 型 HashEntry(K key, int hash, HashEntry<K,V> next, V value) { this.key = key; this.hash = hash; this.next = next; this.value = value; }
}
一个ConcurrentHashMap里包含一个Segment数组
Segment的结构和HashMap类似,是一种数组和链表结构.
一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,
必须首先获得与它对应的Segment锁.如图
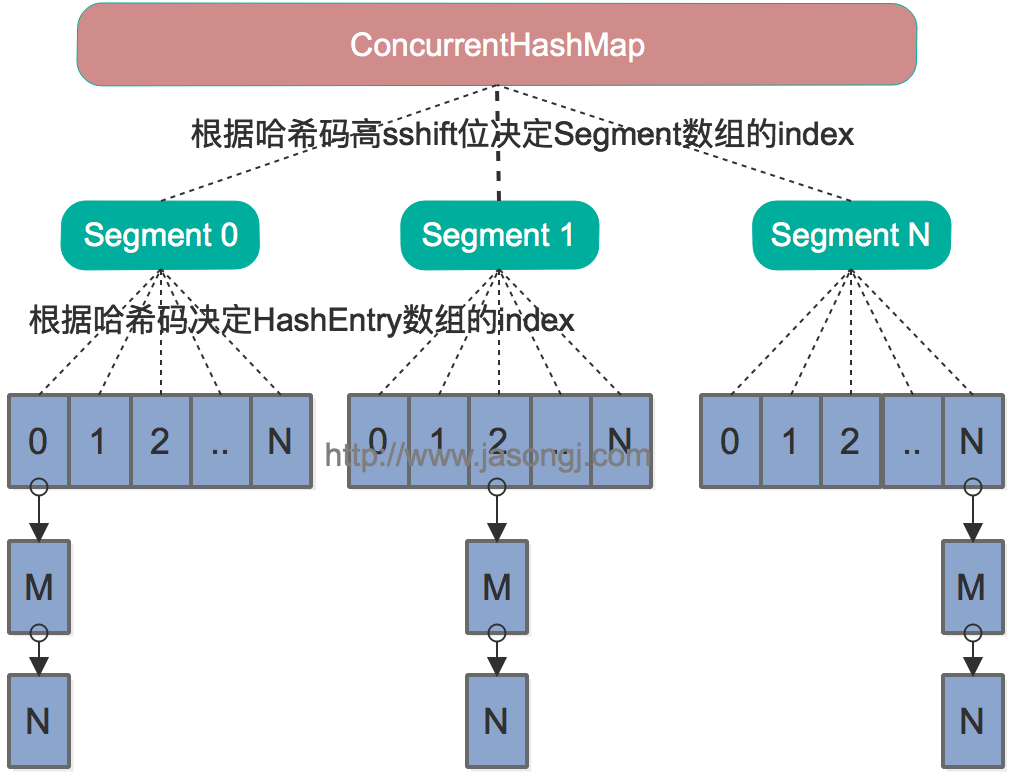
在 ConcurrentHashMap 中,在散列时如果产生“碰撞”,将采用“分离链接法”来处理“碰撞”:把“碰撞”的 HashEntry 对象链接成一个链表
由于 HashEntry 的 next 域为 final 型,所以新节点只能在链表的表头处插入。 下图是在一个空桶中依次插入 A,B,C 三个 HashEntry 对象后的结构图:

注意:由于只能在表头插入,所以链表中节点的顺序和插入的顺序相反。
3 ConcurrentHashMap的初始化
3.1 Segment详解
3.1.1 Segment的索引与读取
ConcurrentHashMap类中包含三个与Segment相关的成员变量:
/*** Mask value for indexing into segments. The upper bits of a* key's hash code are used to choose the segment.*/ final int segmentMask;/*** Shift value for indexing within segments.*/ final int segmentShift;/*** The segments, each of which is a specialized hash table.*/ final Segment<K,V>[] segments;
其中segments是Segment的原生数组,此数组的长度可以在ConcurrentHashMap的构造函数中使用并发度参数指定,其默认值为DEFAULT_CONCURRENCY_LEVEL=16
- segmentShift是用来计算segments数组索引的位移量
- segmentMask则是用来计算索引的掩码值
例如并发度为16时(即segments数组长度为16),segmentShift为32-4=28(因为2的4次幂为16),而segmentMask则为1111(二进制),索引的计算式如下:
int j = (hash >>> segmentShift) & segmentMask;
寻址方式
在读写某个Key时,先取该Key的哈希值。并将哈希值的高N位对Segment个数取模从而得到该Key应该属于哪个Segment,接着如同操作HashMap一样操作这个Segment
为了保证不同的值均匀分布到不同的Segment,需要通过如下方法计算哈希值。
private int hash(Object k) {int h = hashSeed;if ((0 != h) && (k instanceof String)) {return sun.misc.Hashing.stringHash32((String) k);}h ^= k.hashCode();h += (h << 15) ^ 0xffffcd7d;h ^= (h >>> 10);h += (h << 3);h ^= (h >>> 6);h += (h << 2) + (h << 14);return h ^ (h >>> 16);
}
同样为了提高取模运算效率,通过如下计算
- ssize即为大于concurrencyLevel的最小的2的N次方
- segmentMask为2^N-1
对于某一个Key的哈希值,只需要向右移segmentShift位以取高sshift位,再与segmentMask取与操作即可得到它在Segment数组上的索引
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {++sshift;ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
在多线程并发访问一个共享变量时,为了保证逻辑的正确,可以采用以下方法:
- 加锁,性能最低,能保证原子性、可见性,防止指令重排
- volatile修饰,性能中等,能保证可见性,防止指令重排
- 使用getObjectVolatile,性能最好,可防止指令重排
因此ConcurrentHashMap选择了使用Unsafe的getObjectVolatile来读取segments中的元素

// Unsafe mechanics private static final sun.misc.Unsafe UNSAFE;
private static final long SBASE;
private static final int SSHIFT;
private static final long TBASE;
private static final int TSHIFT;
private static final long HASHSEED_OFFSET;
private static final long SEGSHIFT_OFFSET;
private static final long SEGMASK_OFFSET;
private static final long SEGMENTS_OFFSET;static {int ss, ts;try {UNSAFE = sun.misc.Unsafe.getUnsafe();Class tc = HashEntry[].class;Class sc = Segment[].class;TBASE = UNSAFE.arrayBaseOffset(tc);SBASE = UNSAFE.arrayBaseOffset(sc);ts = UNSAFE.arrayIndexScale(tc);ss = UNSAFE.arrayIndexScale(sc);HASHSEED_OFFSET = UNSAFE.objectFieldOffset(ConcurrentHashMap.class.getDeclaredField("hashSeed"));SEGSHIFT_OFFSET = UNSAFE.objectFieldOffset(ConcurrentHashMap.class.getDeclaredField("segmentShift"));SEGMASK_OFFSET = UNSAFE.objectFieldOffset(ConcurrentHashMap.class.getDeclaredField("segmentMask"));SEGMENTS_OFFSET = UNSAFE.objectFieldOffset(ConcurrentHashMap.class.getDeclaredField("segments"));} catch (Exception e) {throw new Error(e);}if ((ss & (ss-1)) != 0 || (ts & (ts-1)) != 0)throw new Error("data type scale not a power of two");SSHIFT = 31 - Integer.numberOfLeadingZeros(ss);TSHIFT = 31 - Integer.numberOfLeadingZeros(ts);
}private Segment<K,V> segmentForHash(int h) {long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;return (Segment<K,V>) UNSAFE.getObjectVolatile(segments, u);
}
观察segmentForHash(int h)方法可知
- 首先使用(h >>> segmentShift) & segmentMask
计算出该h对应的segments索引值(假设为x) - 然后使用索引值(x<<SSHIFT) + SBASE计算出segments中相应Segment的地址
- 最后使用UNSAFE.getObjectVolatile(segments,u)取出相应的Segment,并保持volatile读的效果
Segment的锁
Segment继承了ReentrantLock,因此它实际上是一把锁。在进行put、remove、replace、clear等需要改动内部内容的操作时,都要进行加锁操作,其代码一般是这样的:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {HashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value);V oldValue;try {
//实际代码……}} finally {unlock();}return oldValue;
}
首先调用tryLock,如果加锁失败,则进入scanAndLockForPut(key, hash, value)
该方法实际上是先自旋等待其他线程解锁,直至指定的次数MAX_SCAN_RETRIES
若自旋过程中,其他线程释放了锁,导致本线程直接获得了锁,就避免了本线程进入等待锁的场景,提高了效率
若自旋一定次数后,仍未获取锁,则调用lock方法进入等待锁的场景
采用这种自旋锁和独占锁结合的方法,在很多场景下能够提高Segment并发操作数据的效率。
初始化方法是通过initialCapacity、loadFactor和concurrencyLevel等几个
参数来初始化segment数组、段偏移量segmentShift、段掩码segmentMask和每个segment里的HashEntry数组来实现的.
- 初始化segments数组
if (concurrencyLevel > MAX_SEGMENTS)concurrencyLevel = MAX_SEGMENTS;int sshift = 0;int ssize = 1;while (ssize < concurrencyLevel) {++sshift;ssize <<= 1;}segmentShift = 32 - sshift;segmentMask = ssize - 1;this.segments = Segment.newArray(ssize);
segments数组的长度ssize是通过concurrencyLevel计算得出的
为了能通过按位与的散列算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方,所以必须计算出一个大于或等于concurrencyLevel的最小的2的N次方值来作为segments数组的长度
concurrencyLevel的最大值是65535,这意味着segments数组的长度最大为65536,对应的二进制是16位
- 初始化segmentShift和segmentMask
这两个全局变量需要在定位segment时的散列算法里使用
sshift等于ssize从1向左移位的次数,默认concurrencyLevel等于16,1需要向左移位移动4次,所以sshift为4.- segmentShift用于定位参与散列运算的位数,segmentShift等于32减sshift,所以等于28,这里之所以用32是因为ConcurrentHashMap里的hash()方法输出的最大数是32位,后面的测试中我们可以看到这点
- segmentMask是散列运算的掩码,等于ssize减1,即15,掩码的二进制各个位的值都是1.因为ssize的最大长度是65536,所以segmentShift最大值是16,segmentMask最大值是65535,对应的二进制是16位,每个位都是1
- 初始化每个segment
输入参数initialCapacity是ConcurrentHashMap的初始化容量,loadfactor是每个segment的负载因子,在构造方法里需要通过这两个参数来初始化数组中的每个segment.
if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;int c = initialCapacity / ssize;if (c * ssize < initialCapacity)++c;int cap = 1;while (cap < c)cap <<= 1;for (int i = 0; i < this.segments.length; ++i)this.segments[i] = new Segment<K, V>(cap, loadFactor);
上面代码中的变量cap就是segment里HashEntry数组的长度,它等于initialCapacity除以ssize的倍数c,如果c大于1,就会取大于等于c的2的N次方值,所以cap不是1,就是2的N次方.
segment的容量threshold=(int)cap*loadFactor,默认initialCapacity等于16,loadfactor等于0.75,通过运算cap等于1,threshold等于零.
- 定位Segment
ConcurrentHashMap使用分段锁Segment来保护不同段的数据,在插入和获取元素时,先通过散列算法定位到Segment
private static int hash(int h) {h += (h << 15) ^ 0xffffcd7d;h ^= (h >>> 10);h += (h << 3);h ^= (h >>> 6);h += (h << 2) + (h << 14);return h ^ (h >>> 16);}
进行再散列,是为了减少散列冲突,使元素能够均匀地分布在不同的Segment上,从而提高容器的存取效率.
假如散列的质量差到极点,那么所有的元素都在一个Segment中,不仅存取元素缓慢,分段锁也会失去意义.
ConcurrentHashMap通过以下散列算法定位segment
final Segment<K,V> segmentFor(int hash) {return segments[(hash >>> segmentShift) & segmentMask];
}
默认情况下segmentShift为28,segmentMask为15,再散列后的数最大是32位二进制数据,向右无符号移动28位,即让高4位参与到散列运算中,(hash>>>segmentShift)&segmentMask的运算结果分别是4、15、7和8,可以看到散列值没有发生冲突.
HashEntry
如果说ConcurrentHashMap中的segments数组是第一层hash表,则每个Segment中的HashEntry数组(transient volatile
HashEntry<K,V>[] table)是第二层hash表。每个HashEntry有一个next属性,因此它们能够组成一个单向链表。HashEntry相关代码如下:
static final class HashEntry<K,V> {final int hash;final K key;volatile V value;volatile HashEntry<K,V> next;HashEntry(int hash, K key, V value, HashEntry<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}/*** Sets next field with volatile write semantics. (See above* about use of putOrderedObject.)*/ final void setNext(HashEntry<K,V> n) {UNSAFE.putOrderedObject(this, nextOffset, n);}// Unsafe mechanics static final sun.misc.Unsafe UNSAFE;static final long nextOffset;static {try {UNSAFE = sun.misc.Unsafe.getUnsafe();Class k = HashEntry.class;nextOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("next"));} catch (Exception e) {throw new Error(e);}}
}/*** Gets the ith element of given table (if nonnull) with volatile* read semantics. Note: This is manually integrated into a few* performance-sensitive methods to reduce call overhead.*/ @SuppressWarnings("unchecked")
static final <K,V> HashEntry<K,V> entryAt(HashEntry<K,V>[] tab, int i) {return (tab == null) ? null :(HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)i << TSHIFT) + TBASE);
}/*** Sets the ith element of given table, with volatile write* semantics. (See above about use of putOrderedObject.)*/ static final <K,V> void setEntryAt(HashEntry<K,V>[] tab, int i,HashEntry<K,V> e) {UNSAFE.putOrderedObject(tab, ((long)i << TSHIFT) + TBASE, e);
}
与Segment类似,HashEntry使用UNSAFE.putOrderedObject来设置它的next成员变量,这样既可以提高性能,又能保持并发可见性。同时,entryAt方法和setEntryAt方法也使用了UNSAFE.getObjectVolatile和UNSAFE.putOrderedObject来读取和写入指定索引的HashEntry。
总之,Segment数组和HashEntry数组的读取写入一般都是使用UNSAFE。
用 HashEntery 对象的不变性来降低读操作对加锁的需求
在HashEntry 类的定义中我们可以看到,HashEntry 中的 key,hash,next 都声明为final型。
这意味着,不能把节点添加到链接的中间和尾部,也不能在链接的中间和尾部删除节点。这个特性可以保证:在访问某个节点时,这个节点之后的链接不会被改变。这个特性可以大大降低处理链表时的复杂性
同时,HashEntry 类的 value 域被声明为 Volatile ,JMM可以保证:某个写线程对 value 域的写入马上可以被后续的某个读线程“看”到
在 ConcurrentHashMap 中,不允许用 null 作为键/值,当读线程读到某个 HashEntry 的 value 域的值为 null 时,便知道产生了冲突——发生了重排序现象,需要加锁后重新读入这个 value 值
这些特性互相配合,使得读线程即使在不加锁状态下,也能正确访问 ConcurrentHashMap
下面我们分别来分析线程写入的两种情形:对散列表做非结构性修改的操作和对散列表做结构性修改的操作。
- 非结构性修改操作
只是更改某个 HashEntry 的 value 域的值。由于对 Volatile 变量的写入操作将与随后对这个变量的读操作进行同步。当一个写线程修改了某个 HashEntry 的 value 域后,另一个读线程读这个值域,JMM能够保证读线程读取的一定是更新后的值。所以,写线程对链表的非结构性修改能够被后续不加锁的读线程“看到” - 结构性修改
实质上是对某个桶指向的链表做结构性修改。如果能够确保:在读线程遍历一个链表期间,写线程对这个链表所做的结构性修改不影响读线程继续正常遍历这个链表。那么读 / 写线程之间就可以安全并发访问这个 ConcurrentHashMap
结构性修改操作包括 put,remove,clear。下面我们分别分析这三个操作
- clear 操作只是把 ConcurrentHashMap 中所有的桶“置空”,每个桶之前引用的链表依然存在,只是桶不再引用到这些链表(所有链表的结构并没有被修改)。正在遍历某个链表的读线程依然可以正常执行对该链表的遍历。
- 从下面的代码put 操作中,我们可以看出:put 操作如果需要插入一个新节点到链表中时 , 会在链表头部插入这个新节点。此时,链表中的原有节点的连接并没有被修改。也就是说:插入新键 / 值对到链表中的操作不会影响读线程正常遍历这个链表。
下面来分析 remove 操作,先让我们来看看 remove 操作的源代码实现。
remove
V remove(Object key, int hash, Object value) { lock(); // 加锁try{ int c = count - 1; HashEntry<K,V>[] tab = table; // 根据散列码找到 table 的下标值int index = hash & (tab.length - 1); // 找到散列码对应的那个桶HashEntry<K,V> first = tab[index]; HashEntry<K,V> e = first; while(e != null&& (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue = null; if(e != null) { V v = e.value; if(value == null|| value.equals(v)) { // 找到要删除的节点oldValue = v; ++modCount; // 所有处于待删除节点之后的节点原样保留在链表中// 所有处于待删除节点之前的节点被克隆到新链表中HashEntry<K,V> newFirst = e.next;// 待删节点的后继结点for(HashEntry<K,V> p = first; p != e; p = p.next) newFirst = new HashEntry<K,V>(p.key, p.hash, newFirst, p.value); // 把桶链接到新的头结点// 新的头结点是原链表中,删除节点之前的那个节点tab[index] = newFirst; count = c; // 写 count 变量} } return oldValue; } finally{ unlock(); // 解锁} }
和get一样,先根据散列码找到具体的链表;然后遍历这个链表找到要删除的节点;最后把待删除节点之后的所有节点原样保留在新链表中,把待删除节点之前的每个节点克隆到新链表中
下面通过图例来说明 remove 操作。假设写线程执行 remove 操作,要删除链表的 C 节点,另一个读线程同时正在遍历这个链表。

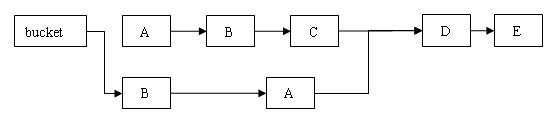
删除节点 C 之后的所有节点原样保留到新链表中
删除节点 C 之前的每个节点被克隆到新链表中
注意:它们在新链表中的链接顺序被反转了。
在执行 remove 操作时,原始链表并没有被修改,也就是说:读线程不会受同时执行 remove 操作的并发写线程的干扰
综合上面的分析我们可以看出,写线程对某个链表的结构性修改不会影响其他的并发读线程对这个链表的遍历访问
5 ConcurrentHashMap的操作
主要研究ConcurrentHashMap的3种操作——get操作、put操作和size操作.
5.1 get操作
Segment的get操作实现非常简单和高效.
- 先经过一次再散列
- 然后使用这个散列值通过散列运算定位到Segment
- 再通过散列算法定位到元素.
public V get(Object key) {Segment<K,V> s; HashEntry<K,V>[] tab;int h = hash(key);
//找到segment的地址 long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
//取出segment,并找到其hashtable if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&(tab = s.table) != null) {
//遍历此链表,直到找到对应的值 for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);e != null; e = e.next) {K k;if ((k = e.key) == key || (e.hash == h && key.equals(k)))return e.value;}}return null;
}
整个get方法不需要加锁,只需要计算两次hash值,然后遍历一个单向链表(此链表长度平均小于2),因此get性能很高。
高效之处在于整个过程不需要加锁,除非读到的值是空才会加锁重读.
HashTable容器的get方法是需要加锁的,那ConcurrentHashMap的get操作是如何做到不加锁的呢?
原因是它的get方法将要使用的共享变量都定义成了volatile类型,
如用于统计当前Segement大小的count字段和用于存储值的HashEntry的value.定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖于原值),
在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁.
之所以不会读到过期的值,是因为根据Java内存模型的happen before原则,对volatile字段的写操作先于读操作,即使两个线程同时修改和获取
volatile变量,get操作也能拿到最新的值,
这是用volatile替换锁的经典应用场景.
transient volatile int count;
volatile V value;
在定位元素的代码里可以发现,定位HashEntry和定位Segment的散列算法虽然一样,都与数组的长度减去1再相“与”,但是相“与”的值不一样
- 定位Segment使用的是元素的hashcode再散列后得到的值的高位
- 定位HashEntry直接使用再散列后的值.
其目的是避免两次散列后的值一样,虽然元素在Segment里散列开了,但是却没有在HashEntry里散列开.
hash >>> segmentShift & segmentMask // 定位Segment所使用的hash算法
int index = hash & (tab.length - 1); // 定位HashEntry所使用的hash算法
5.2 put操作
由于需要对共享变量进行写操作,所以为了线程安全,在操作共享变量时必须加锁
put方法首先定位到Segment,然后在Segment里进行插入操作
插入操作需要经历两个步骤
- 判断是否需要对Segment里的HashEntry数组进行扩容
- 定位添加元素的位置,然后将其放在HashEntry数组里
- 是否需要扩容
在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阈值,则对数组进行扩容.
值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容. - 如何扩容
在扩容的时候,首先会创建一个容量是原来两倍的数组,然后将原数组里的元素进行再散列后插入到新的数组里.
为了高效,ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment扩容.
put方法的第一步,计算segment数组的索引,并找到该segment,然后调用该segment的put方法。
public V put(K key, V value) { if (value == null) //ConcurrentHashMap 中不允许用 null 作为映射值throw new NullPointerException(); int hash = hash(key.hashCode()); // 计算键对应的散列码// 根据散列码找到对应的 Segment return segmentFor(hash).put(key, hash, value, false);
}
根据 hash 值找到对应的 Segment
/** * 使用 key 的散列码来得到 segments 数组中对应的 Segment */
final Segment<K,V> segmentFor(int hash) { // 将散列值右移 segmentShift 个位,并在高位填充 0 // 然后把得到的值与 segmentMask 相“与”
// 从而得到 hash 值对应的 segments 数组的下标值
// 最后根据下标值返回散列码对应的 Segment 对象return segments[(hash >>> segmentShift) & segmentMask];
}
put方法第二步,在Segment的put方法中进行操作。
V put(K key, int hash, V value, boolean onlyIfAbsent) { lock(); // 加锁,这里是锁定某个 Segment 对象而非整个 ConcurrentHashMap try { int c = count; if (c++ > threshold) // 如果超过再散列的阈值rehash(); // 执行再散列,table 数组的长度将扩充一倍HashEntry<K,V>[] tab = table; // 把散列码值与 table 数组的长度减 1 的值相“与”// 得到该散列码对应的 table 数组的下标值int index = hash & (tab.length - 1); // 找到散列码对应的具体的那个桶HashEntry<K,V> first = tab[index]; HashEntry<K,V> e = first; while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue; if (e != null) { // 如果键 / 值对以经存在oldValue = e.value; if (!onlyIfAbsent) e.value = value; // 设置 value 值} else { // 键 / 值对不存在 oldValue = null; ++modCount; // 要添加新节点到链表中,所以 modCont 要加 1 // 创建新节点,并添加到链表的头部 tab[index] = new HashEntry<K,V>(key, hash, first, value); count = c; // 写 count 变量} return oldValue; } finally { unlock(); // 解锁} }
注意:这里的加锁操作是针对(键的 hash 值对应的)某个具体的 Segment,锁定的是该 Segment 而不是整个 ConcurrentHashMap
因为插入键 / 值对操作只是在这个 Segment 包含的某个桶中完成,不需要锁定整ConcurrentHashMap
此时,其他写线程对另外 15 个Segment 的加锁并不会因为当前线程对这个 Segment 的加锁而阻塞
同时,所有读线程几乎不会因本线程的加锁而阻塞(除非读线程刚好读到这个 Segment 中某个 HashEntry 的 value 域的值为 null,此时需要加锁后重新读取该值)
相比较于 HashTable 和由同步包装器包装的 HashMap每次只能有一个线程执行读或写操作,ConcurrentHashMap 在并发访问性能上有了质的提高。在理想状态下,ConcurrentHashMap 可以支持 16 个线程执行并发写操作(如果并发级别设置为 16),及任意数量线程的读操作。
5.3 size操作
要统计整个ConcurrentHashMap里元素的数量,就必须统计所有Segment里元素的数量后计总
Segment里的全局变量count是一个volatile,在并发场景下,是不是直接把所有Segment的count相加就可以得到整个ConcurrentHashMap大小了呢?不是的
虽然相加时可以获取每个Segment的count的最新值,但是可能累加前使用的count发生了变化,那么统计结果就不准了.
所以,最安全的做法是在统计size的时候把所有Segment的put、remove和clean方法全部锁住,但是这种做法显然非常低效.
因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以
ConcurrentHashMap的做法是先尝试2次通过不锁Segment的方式来统计各个Segment大小,如果统计的过程中,count发生了变化,则再采用加锁的方式来统计所有Segment的大小.
那么ConcurrentHashMap又是如何判断在统计的时候容器是否发生了变化呢?
使用modCount变量,在put、remove和clean方法里操作元素前都会将变量modCount进行加1,那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化.
6 用 Volatile 变量协调读写线程间的内存可见性
由于内存可见性问题,未正确同步的情况下,写线程写入的值可能并不为后续的读线程可见
下面以写线程 M 和读线程 N 来说明 ConcurrentHashMap 如何协调读 / 写线程间的内存可见性问题
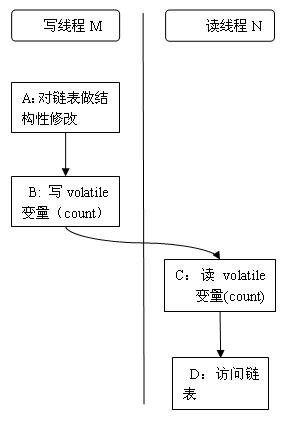
假设线程 M 在写入了 volatile 型变量 count 后,线程 N 读取了这个 volatile 型变量 count
根据 happens-before 关系法则中的程序次序法则,A appens-before 于 B,C happens-before D
根据Volatile 变量法则,B happens-before C
根据传递性,连接上面三个 happens-before 关系得到:A appens-before 于 B; B appens-before C;C happens-before D。也就是说:写线程 M 对链表做的结构性修改,在读线程 N 读取了同一个 volatile 变量后,对线程 N 也是可见的
虽然线程 N 是在未加锁的情况下访问链表。JMM可以保证:只要之前对链表做结构性修改操作的写线程 M 在退出写方法前写 volatile 型变量 count,读线程 N 在读取这个 volatile 型变量 count 后,就一定能“看到”这些修改
ConcurrentHashMap 中,每个 Segment 都有一个变量 count。它用来统计 Segment 中的 HashEntry 的个数。这个变量被声明为 volatile。
Count 变量的声明
transient volatile int count;
所有不加锁读方法,在进入读方法时,首先都会去读这个 count 变量。比如下面的 get 方法:
V get(Object key, int hash) { if(count != 0) { // 首先读 count 变量HashEntry<K,V> e = getFirst(hash); while(e != null) { if(e.hash == hash && key.equals(e.key)) { V v = e.value; if(v != null) return v; // 如果读到 value 域为 null,说明发生了重排序,加锁后重新读取return readValueUnderLock(e); } e = e.next; } } return null; }
在 ConcurrentHashMap 中,所有执行写操作的方法(put, remove, clear),在对链表做结构性修改之后,在退出写方法前都会去写这个 count 变量
所有未加锁的读操作(get, contains, containsKey)在读方法中,都会首先去读取这个 count 变量。
根据 Java 内存模型,对 同一个 volatile 变量的写 / 读操作可以确保:写线程写入的值,能够被之后未加锁的读线程“看到”。
这个特性和前面介绍的 HashEntry 对象的不变性相结合,使得在 ConcurrentHashMap 中,读线程在读取散列表时,基本不需要加锁就能成功获得需要的值。这两个特性相配合,不仅减少了请求同一个锁的频率(读操作一般不需要加锁就能够成功获得值),也减少了持有同一个锁的时间(只有读到 value 域的值为 null 时 , 读线程才需要加锁后重读)。
7 ConcurrentHashMap 实现高并发的总结
7.1 基于通常情形而优化
在实际的应用中,散列表一般的应用场景是:除了少数插入操作和删除操作外,绝大多数都是读取操作,而且读操作在大多数时候都是成功的
正是基于这个前提,ConcurrentHashMap 针对读操作做了大量的优化。通过HashEntry 对象的不变性和用 volatile 型变量协调线程间的内存可见性,使得 大多数时候,读操作不需要加锁就可以正确获得值。这个特性使得 ConcurrentHashMap 的并发性能在分离锁的基础上又有了近一步的提高
7.2 总结
ConcurrentHashMap 是一个并发散列映射表的实现,它允许完全并发的读取,并且支持给定数量的并发更新
相比于 HashTable 和用同步包装器包装的 HashMap(Collections.synchronizedMap(new HashMap())),ConcurrentHashMap 拥有更高的并发性
在 HashTable 和由同步包装器包装的 HashMap 中,使用一个全局的锁来同步不同线程间的并发访问
同一时间点,只能有一个线程持有锁,也就是说在同一时间点,只能有一个线程能访问容器。这虽然保证多线程间的安全并发访问,但同时也导致对容器的访问变成串行化的了。
在使用锁来协调多线程间并发访问的模式下,减小对锁的竞争可以有效提高并发性。有两种方式可以减小对锁的竞争:
- 减小请求同一个锁的频率
- 减少持有锁的 时间。
ConcurrentHashMap 的高并发性主要来自于三个方面:
- 1.用分离锁实现多个线程间的更深层次的共享访问,减小了请求 同一个锁的频率。
- 2.用 HashEntery 对象的不变性来降低执行读操作的线程在遍历链表期间对加锁的需求
- 3.通过对同一个 Volatile 变量的写 / 读访问,协调不同线程间读 / 写操作的内存可见性
由于散列映射表在实际应用中大多数操作都是成功的 读操作,所以 2 和 3 既可以减少请求同一个锁的频率,也可以有效减少持有锁的时间。
通过减小请求同一个锁的频率和尽量减少持有锁的时间 ,使得 ConcurrentHashMap 的并发性相对于 HashTable 和用同步包装器包装的 HashMap有了质的提高。
8 为并发而生的 ConcurrentHashMap(Java 8)
8.1 数据结构
Java 7为实现并行访问,引入了Segment这一结构,实现了分段锁,理论上最大并发度与Segment个数相等
Java 8取消了基于 Segment 的分段锁思想,改用 CAS + synchronized 控制并发操作,在某些方面提升了性能。并且追随 1.8 版本的 HashMap 底层实现,使用数组+链表+红黑树进行数据存储。
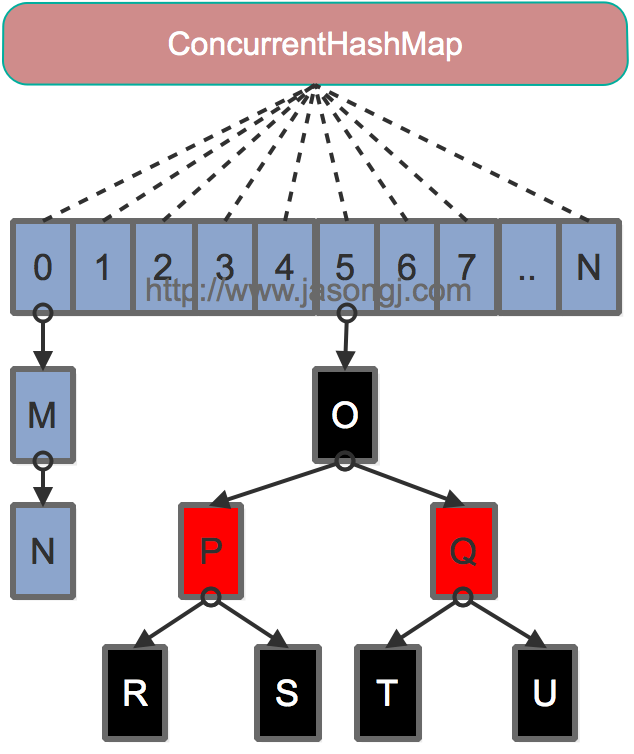
{kind=link}
和 HashMap 中的语义一样,代表整个哈希表

这是一个连接表,用于哈希表扩容,扩容完成后会被重置为 null

该属性保存着整个哈希表中存储的所有的结点的个数总和,有点类似于 HashMap 的 size 属性

这是一个重要的属性,无论是初始化哈希表,还是扩容 rehash 的过程,都是需要依赖这个关键属性
有以下几种取值:
- 0:默认值
- -1:代表哈希表正在进行初始化
- 大于0:相当于 HashMap 中的 threshold,表示阈值
- 小于-1:代表有多个线程正在进行扩容
该属性的使用还是有点复杂的,在我们分析扩容源码的时候再给予更加详尽的描述

8.2 寻址方式
Java 8的ConcurrentHashMap同样是通过Key的哈希值与数组长度取模确定该Key在数组中的索引
同样为了避免不太好的Key的hashCode设计,它通过如下方法计算得到Key的最终哈希值。不同的是,Java 8的ConcurrentHashMap作者认为引入红黑树后,即使哈希冲突比较严重,寻址效率也足够高,所以作者并未在哈希值的计算上做过多设计,只是将Key的hashCode值与其高16位作异或并保证最高位为0(从而保证最终结果为正整数)

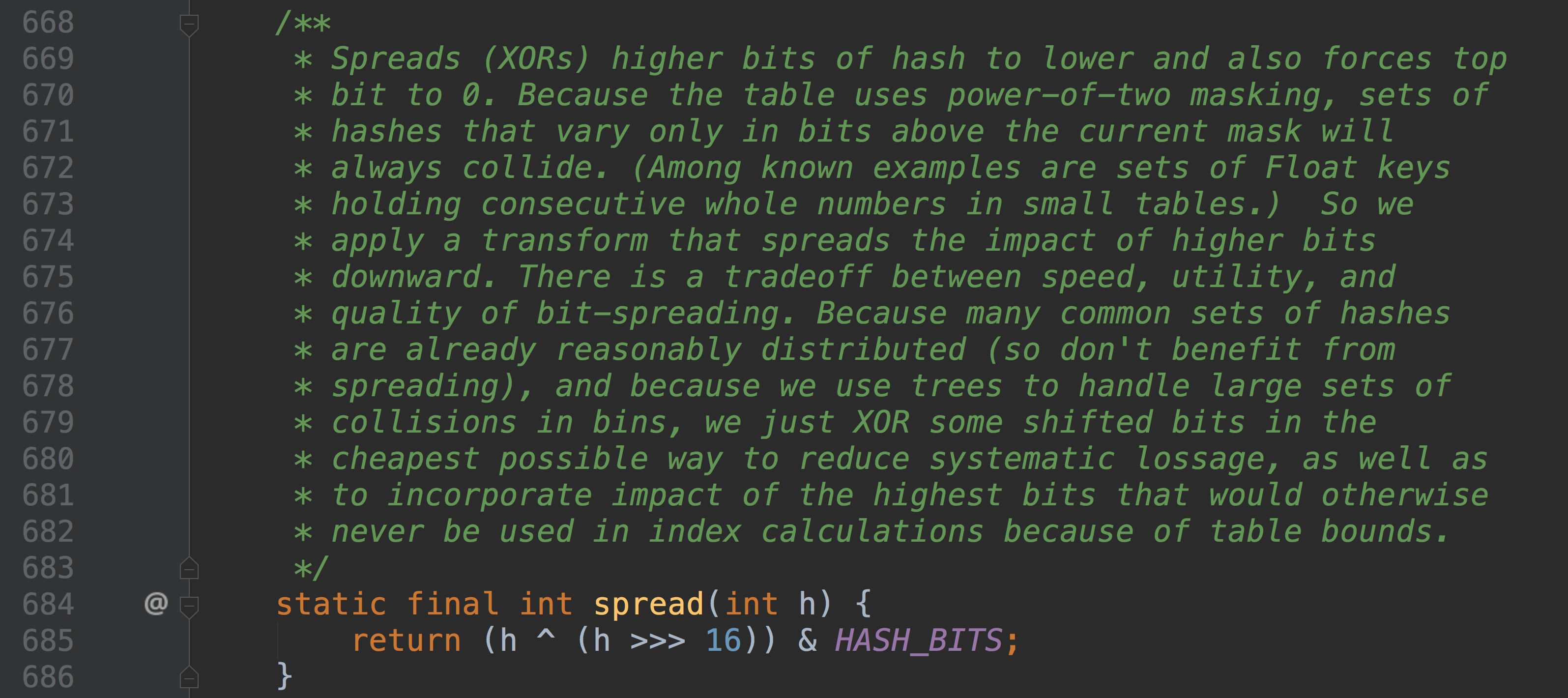
8.3 同步方式
对于put操作,如果Key对应的数组元素为null,则通过CAS操作将其设置为当前值
如果Key对应的数组元素(也即链表表头或者树的根元素)不为null,则对该元素使用synchronized关键字申请锁,然后进行操作
如果该put操作使得当前链表长度超过一定阈值,则将该链表转换为树,从而提高寻址效率。
对于读操作,由于数组被volatile关键字修饰,因此不用担心数组的可见性问题。同时每个元素是一个Node实例(Java 7中每个元素是一个HashEntry),它的Key值和hash值都由final修饰,不可变更,无须关心它们被修改后的可见性问题。而其Value及对下一个元素的引用由volatile修饰,可见性也有保障。
8.4 操作
put方法和remove方法都会通过addCount方法维护Map的size。size方法通过sumCount获取由addCount方法维护的Map的size。
其他常用的方法我们将在文末进行简单介绍,下面我们主要来分析下 ConcurrentHashMap 的一个核心方法 put,我们也会一并解决掉该方法中涉及到的扩容、辅助扩容,初始化哈希表等方法。
put
对于 HashMap 来说,多线程并发添加元素会导致数据丢失等并发问题,那么 ConcurrentHashMap 又是如何做到并发添加的呢?
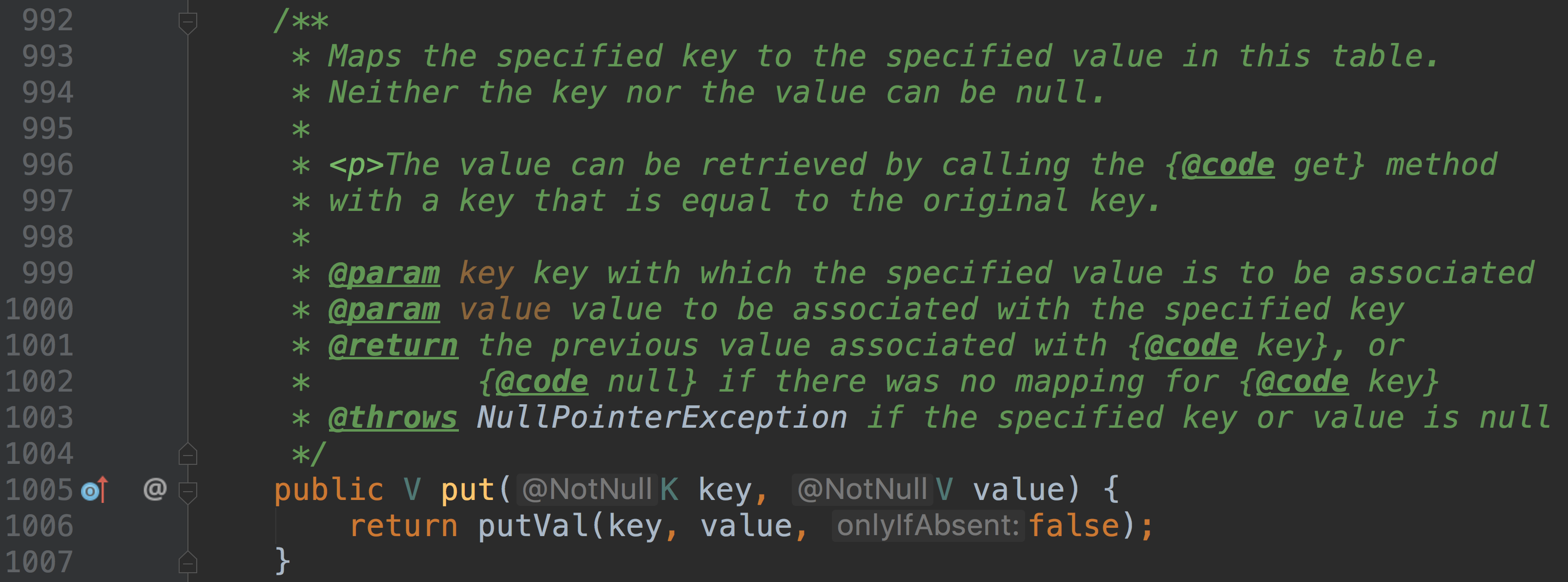
putVal 的方法比较多,我们分两个部分进行分析
第一部分
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {//对传入的参数进行合法性判断if (key == null || value == null) throw new NullPointerException();//计算键所对应的 hash 值int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;//如果哈希表还未初始化,那么初始化它if (tab == null || (n = tab.length) == 0)tab = initTable();//根据键的 hash 值找到哈希数组相应的索引位置//如果为空,那么以CAS无锁式向该位置添加一个节点else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; }
这里需要详细说明的只有initTable 方法,这是一个初始化哈希表的操作,它同时只允许一个线程进行初始化操作。
/*** Initializes table, using the size recorded in sizeCtl.*/
private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;//如果表为空才进行初始化操作while ((tab = table) == null || tab.length == 0) {//sizeCtl 小于零说明已经有线程正在进行初始化操作//当前线程应该放弃 CPU 的使用if ((sc = sizeCtl) < 0)Thread.yield(); // lost initialization race; just spin//否则说明还未有线程对表进行初始化,那么本线程就来做这个工作else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {//保险起见,再次判断下表是否为空try {if ((tab = table) == null || tab.length == 0) {//sc 大于零说明容量已经初始化了,否则使用默认容量int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")//根据容量构建数组Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = tab = nt;//计算阈值,等效于 n*0.75sc = n - (n >>> 2);}} finally {//设置阈值sizeCtl = sc;}break;}}return tab;
}
关于 initTable 方法的每一步实现都已经给出注释,该方法的核心思想就是,只允许一个线程对表进行初始化,如果不巧有其他线程进来了,那么会让其他线程交出 CPU 等待下次系统调度。这样,保证了表同时只会被一个线程初始化。
接着,我们回到 putVal 方法,这样的话,我们第一部分的 putVal 源码就分析结束了,下面我们看后一部分的源码:
//检测到桶结点是 ForwardingNode 类型,协助扩容
else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);
//桶结点是普通的结点,锁住该桶头结点并试图在该链表的尾部添加一个节点
else {V oldVal = null;synchronized (f) {if (tabAt(tab, i) == f) {//向普通的链表中添加元素,无需赘述if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}//向红黑树中添加元素,TreeBin 结点的hash值为TREEBIN(-2)else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}//binCount != 0 说明向链表或者红黑树中添加或修改一个节点成功//binCount == 0 说明 put 操作将一个新节点添加成为某个桶的首节点if (binCount != 0) {//链表深度超过 8 转换为红黑树if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);//oldVal != null 说明此次操作是修改操作//直接返回旧值即可,无需做下面的扩容边界检查if (oldVal != null)return oldVal;break;}}
}
//CAS 式更新baseCount,并判断是否需要扩容
addCount(1L, binCount);
//程序走到这一步说明此次 put 操作是一个添加操作,否则早就 return 返回了
return null;
这一部分的源码大体上已如注释所描述,至此整个 putVal 方法的大体逻辑实现相信你也已经清晰了,好好回味一下。
下面我们对这部分中的某些方法的实现细节再做一些深入学习。
首先需要介绍一下,ForwardingNode 这个节点类型
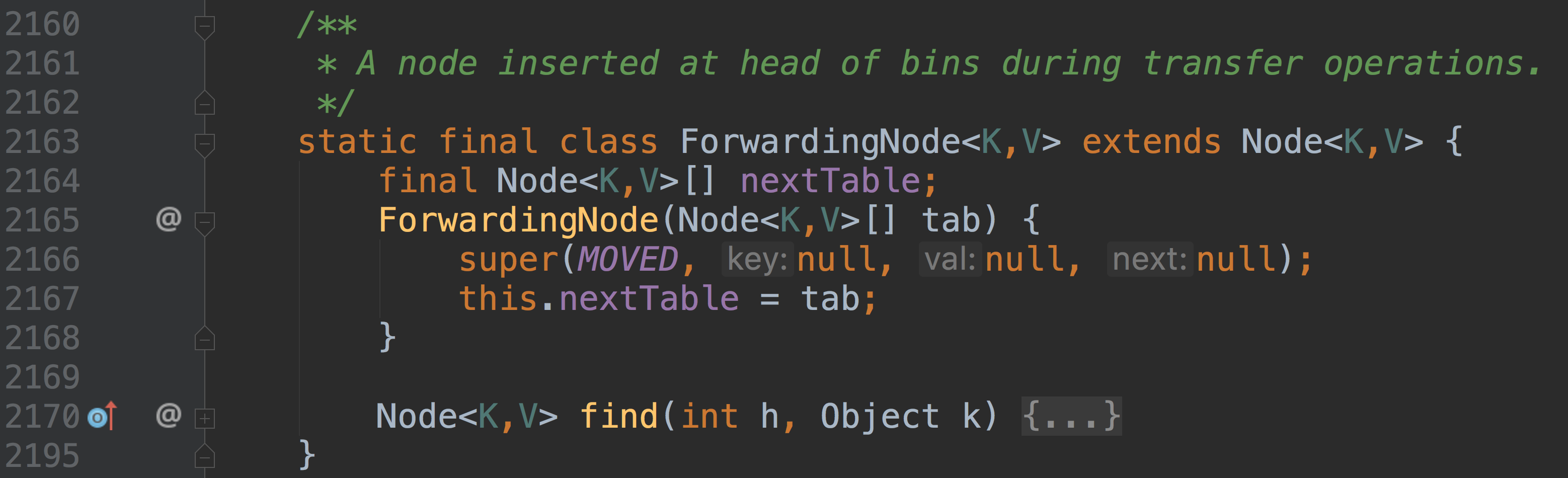
这个节点内部保存了一
nextTable 引用,它指向一张 hash 表在扩容操作中,我们需要对每个桶中的结点进行分离和转移,如果某个桶结点中所有节点都已经迁移完成了(已经被转移到新表 nextTable 中了),那么会在原 table 表的该位置挂上一个 ForwardingNode 结点,说明此桶已经完成迁移
ForwardingNode继承自 Node 结点,并且它唯一的构造函数将构建一个键/值/next 都为 null 的结点,反正它就是个标识,无需那些属性。但是 hash 值却为 MOVED
所以,我们在 putVal 方法中遍历整个 hash 表的桶结点,如果遇到 hash 值等于 MOVED,说明已经有线程正在扩容 rehash 操作,整体上还未完成,不过我们要插入的桶的位置已经完成了所有节点的迁移。
由于检测到当前哈希表正在扩容,于是让当前线程去协助扩容。
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {Node<K,V>[] nextTab; int sc;if (tab != null && (f instanceof ForwardingNode) &&(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {//返回一个 16 位长度的扩容校验标识int rs = resizeStamp(tab.length);while (nextTab == nextTable && table == tab &&(sc = sizeCtl) < 0) {//sizeCtl 如果处于扩容状态的话//前 16 位是数据校验标识,后 16 位是当前正在扩容的线程总数//这里判断校验标识是否相等,如果校验符不等或者扩容操作已经完成了,直接退出循环,不用协助它们扩容了if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || transferIndex <= 0)break;//否则调用 transfer 帮助它们进行扩容//sc + 1 标识增加了一个线程进行扩容if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {transfer(tab, nextTab);break;}}return nextTab;}return table;
}
下面我们看这个稍显复杂的 transfer 方法,我们依然分几个部分来细说。
//第一部分
/*** Moves and/or copies the nodes in each bin to new table. See* above for explanation.*/
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {int n = tab.length, stride;//计算单个线程允许处理的最少table桶首节点个数,不能小于 16if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)stride = MIN_TRANSFER_STRIDE; // subdivide range 细分范围//刚开始扩容,初始化 nextTab if (nextTab == null) { // initiatingtry {@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];nextTab = nt;} catch (Throwable ex) {sizeCtl = Integer.MAX_VALUE;return;}nextTable = nextTab;//transferIndex 指向最后一个桶,方便从后向前遍历 transferIndex = n;}int nextn = nextTab.length;//定义 ForwardingNode 用于标记迁移完成的桶ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
这部分代码还是比较简单的,主要完成的是对单个线程能处理的最少桶结点个数的计算和一些属性的初始化操作。
//第二部分,并发扩容控制的核心
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
//i 指向当前桶,bound 指向当前线程需要处理的桶结点的区间下限
for (int i = 0, bound = 0;;) {Node<K,V> f; int fh;//这个 while 循环的目的就是通过 --i 遍历当前线程所分配到的桶结点//一个桶一个桶的处理while (advance) {int nextIndex, nextBound;if (--i >= bound || finishing)advance = false;//transferIndex <= 0 说明已经没有需要迁移的桶了else if ((nextIndex = transferIndex) <= 0) {i = -1;advance = false;}//更新 transferIndex//为当前线程分配任务,处理的桶结点区间为(nextBound,nextIndex)else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ? nextIndex - stride : 0))) {bound = nextBound;i = nextIndex - 1;advance = false;}}//当前线程所有任务完成if (i < 0 || i >= n || i + n >= nextn) {int sc;if (finishing) {nextTable = null;table = nextTab;sizeCtl = (n << 1) - (n >>> 1);return;}if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)return;finishing = advance = true;i = n; }}//待迁移桶为空,那么在此位置 CAS 添加 ForwardingNode 结点标识该桶已经被处理过了else if ((f = tabAt(tab, i)) == null)advance = casTabAt(tab, i, null, fwd);//如果扫描到 ForwardingNode,说明此桶已经被处理过了,跳过即可else if ((fh = f.hash) == MOVED)advance = true;
每个新参加进来扩容的线程必然先进 while 循环的最后一个判断条件中去领取自己需要迁移的桶的区间。然后 i 指向区间的最后一个位置,表示迁移操作从后往前的做。接下来的几个判断就是实际的迁移结点操作了。等我们大致介绍完成第三部分的源码再回来对各个判断条件下的迁移过程进行详细的叙述。
//第三部分
else {//synchronized (f) {if (tabAt(tab, i) == f) {Node<K,V> ln, hn;//链表的迁移操作if (fh >= 0) {int runBit = fh & n;Node<K,V> lastRun = f;//整个 for 循环为了找到整个桶中最后连续的 fh & n 不变的结点for (Node<K,V> p = f.next; p != null; p = p.next) {int b = p.hash & n;if (b != runBit) {runBit = b;lastRun = p;}}if (runBit == 0) {ln = lastRun;hn = null;}else {hn = lastRun;ln = null;}//如果fh&n不变的链表的runbit都是0,则nextTab[i]内元素ln前逆序,ln及其之后顺序//否则,nextTab[i+n]内元素全部相对原table逆序//这是通过一个节点一个节点的往nextTab添加for (Node<K,V> p = f; p != lastRun; p = p.next) {int ph = p.hash; K pk = p.key; V pv = p.val;if ((ph & n) == 0)ln = new Node<K,V>(ph, pk, pv, ln);elsehn = new Node<K,V>(ph, pk, pv, hn);}//把两条链表整体迁移到nextTab中setTabAt(nextTab, i, ln);setTabAt(nextTab, i + n, hn);//将原桶标识位已经处理setTabAt(tab, i, fwd);advance = true;}//红黑树的复制算法,不再赘述else if (f instanceof TreeBin) {TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> lo = null, loTail = null;TreeNode<K,V> hi = null, hiTail = null;int lc = 0, hc = 0;for (Node<K,V> e = t.first; e != null; e = e.next) {int h = e.hash;TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null);if ((h & n) == 0) {if ((p.prev = loTail) == null)lo = p;elseloTail.next = p;loTail = p;++lc;}else {if ((p.prev = hiTail) == null)hi = p;elsehiTail.next = p;hiTail = p;++hc;}}ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :(hc != 0) ? new TreeBin<K,V>(lo) : t;hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :(lc != 0) ? new TreeBin<K,V>(hi) : t;setTabAt(nextTab, i, ln);setTabAt(nextTab, i + n, hn);setTabAt(tab, i, fwd);advance = true;}
那么至此,有关迁移的几种情况已经介绍完成了,下面我们整体上把控一下整个扩容和迁移过程。
首先,每个线程进来会先领取自己的任务区间,然后开始 --i 来遍历自己的任务区间,对每个桶进行处理。
- 如果遇到桶的头结点是空的,那么使用 ForwardingNode 标识该桶已经被处理完成了
- 如果遇到已经处理完成的桶,直接跳过进行下一个桶的处理
- 如果是正常的桶,对桶首节点加锁,正常的迁移即可,迁移结束后依然会将原表的该位置标识位已经处理
当 i < 0,说明本线程处理速度够快的,整张表的最后一部分已经被它处理完了,现在需要看看是否还有其他线程在自己的区间段还在迁移中。这是退出的逻辑判断部分:
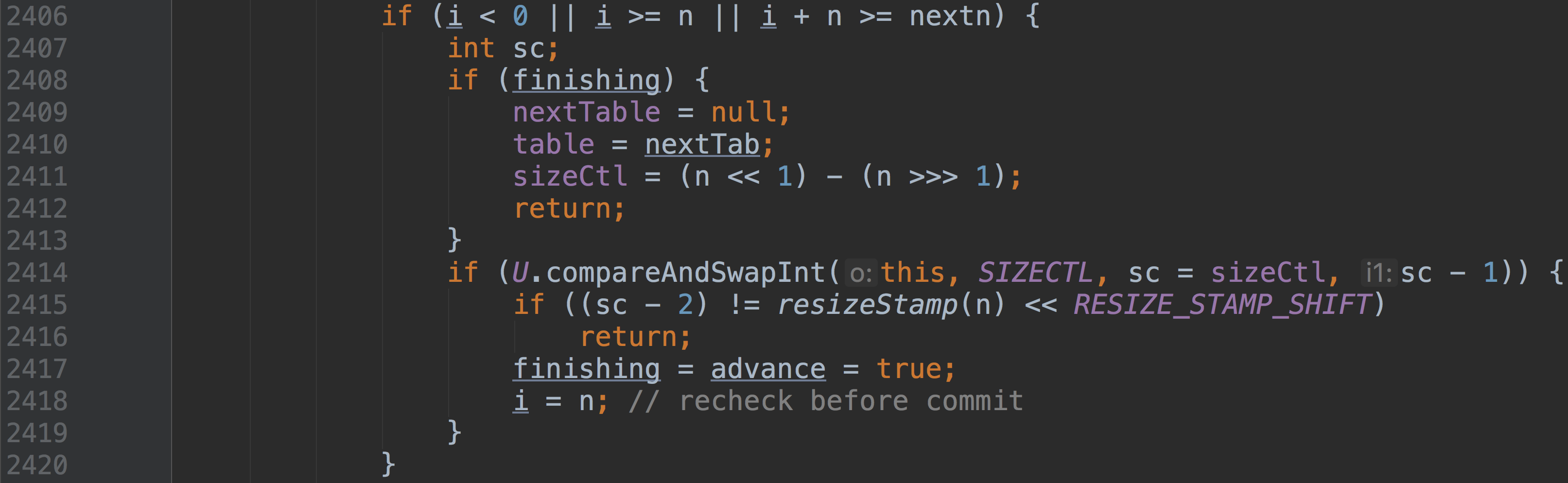
finnish 是一个标志,如果为 true 则说明整张表的迁移操作已经全部完成了,我们只需要重置 table 的引用并将 nextTable 赋为空即可。否则,CAS 式的将 sizeCtl 减一,表示当前线程已经完成了任务,退出扩容操作。
如果退出成功,那么需要进一步判断是否还有其他线程仍然在执行任务。

我们说过 resizeStamp(n) 返回的是对 n 的一个数据校验标识,占 16 位
而

的值为 16,那么位运算后,整个表达式必然在右边空出 16 个零。也正如我们所说的,sizeCtl 的高 16 位为数据校验标识,低 16 为表示正在进行扩容的线程数量
(resizeStamp(n) << RESIZE_STAMP_SHIFT) + 2表示当前只有一个线程正在工作,相对应的,如果
(sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT说明当前线程就是最后一个还在扩容的线程,那么会将 finishing 标识为 true,并在下一次循环中退出扩容方法。
这一块的难点在于对 sizeCtl 的各个值的理解,关于它的深入理解,这里推荐一篇文章。
着重理解位操作
看到这里,真的为 Doug Lea 精妙的设计而折服,针对于多线程访问问题,不但没有拒绝式得将他们阻塞在门外,反而邀请他们来帮忙一起工作。
好了,我们一路往回走,回到我们最初分析的 putVal 方法。接着前文的分析,当我们根据 hash 值,找到对应的桶结点,如果发现该结点为 ForwardingNode 结点,表明当前的哈希表正在扩容和 rehash,于是将本线程送进去帮忙扩容。否则如果是普通的桶结点,于是锁住该桶,分链表和红黑树的插入一个节点,具体插入过程类似 HashMap,此处不再赘述。
当我们成功的添加完成一个结点,最后是需要判断添加操作后是否会导致哈希表达到它的阈值,并针对不同情况决定是否需要进行扩容,还有 CAS 式更新哈希表实际存储的键值对数量。这些操作都封装在 addCount 这个方法中,当然 putVal 方法的最后必然会调用该方法进行处理。下面我们看看该方法的具体实现,该方法主要做两个事情。一是更新 baseCount,二是判断是否需要扩容。
//第一部分,更新 baseCount
private final void addCount(long x, int check) {CounterCell[] as; long b, s;//如果更新失败才会进入的 if 的主体代码中//s = b + x 其中 x 等于 1if ((as = counterCells) != null ||!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {CounterCell a; long v; int m;boolean uncontended = true;//高并发下 CAS 失败会执行 fullAddCount 方法if (as == null || (m = as.length - 1) < 0 || (a = as[ThreadLocalRandom.getProbe() & m]) == null ||!(uncontended =U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {fullAddCount(x, uncontended);return;}if (check <= 1)return;s = sumCount();}
这一部分主要完成的是对 baseCount 的 CAS 更新。//第二部分,判断是否需要扩容
if (check >= 0) {Node<K,V>[] tab, nt; int n, sc;while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&(n = tab.length) < MAXIMUM_CAPACITY) {int rs = resizeStamp(n);if (sc < 0) {if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||transferIndex <= 0)break;if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))transfer(tab, nt);}else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))transfer(tab, null);s = sumCount();}}
这部分代码也是比较简单的,不再赘述。
至此,对于 put 方法的源码分析已经完全结束了,很复杂但也很让人钦佩。下面我们简单看看 remove 方法的实现。
四、remove 方法实现并发删除
在我们分析完 put 方法的源码之后,相信 remove 方法对你而言就比较轻松了,无非就是先定位再删除的复合。
限于篇幅,我们这里简单的描述下 remove 方法的并发删除过程。
首先遍历整张表的桶结点,如果表还未初始化或者无法根据参数的 hash 值定位到桶结点,那么将返回 null。
如果定位到的桶结点类型是 ForwardingNode 结点,调用 helpTransfer 协助扩容。
否则就老老实实的给桶加锁,删除一个节点。
最后会调用 addCount 方法 CAS 更新 baseCount 的值。
五、其他的一些常用方法的基本介绍
最后我们在补充一些 ConcurrentHashMap 中的小而常用的方法的介绍。
1、size
size 方法的作用是为我们返回哈希表中实际存在的键值对的总数。
public int size() {long n = sumCount();return ((n < 0L) ? 0 :(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :(int)n);
}
final long sumCount() {CounterCell[] as = counterCells; CounterCell a;long sum = baseCount;if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;
}
可能你会有所疑问,ConcurrentHashMap 中的 baseCount 属性不就是记录的所有键值对的总数吗?直接返回它不就行了吗?
之所以没有这么做,是因为我们的 addCount 方法用于 CAS 更新 baseCount,但很有可能在高并发的情况下,更新失败,那么这些节点虽然已经被添加到哈希表中了,但是数量却没有被统计。
还好,addCount 方法在更新 baseCount 失败的时候,会调用 fullAddCount 将这些失败的结点包装成一个 CounterCell 对象,保存在 CounterCell 数组中。那么整张表实际的 size 其实是 baseCount 加上 CounterCell 数组中元素的个数。
2、get
get 方法可以根据指定的键,返回对应的键值对,由于是读操作,所以不涉及到并发问题。源码也是比较简单的。
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;int h = spread(key.hashCode());if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {if ((eh = e.hash) == h) {if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}else if (eh < 0)return (p = e.find(h, key)) != null ? p.val : null;while ((e = e.next) != null) {if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null;}
3、clear
clear 方法将删除整张哈希表中所有的键值对,删除操作也是一个桶一个桶的进行删除。
public void clear() {long delta = 0L; // negative number of deletionsint i = 0;Node<K,V>[] tab = table;while (tab != null && i < tab.length) {int fh;Node<K,V> f = tabAt(tab, i);if (f == null)++i;else if ((fh = f.hash) == MOVED) {tab = helpTransfer(tab, f);i = 0; // restart}else {synchronized (f) {if (tabAt(tab, i) == f) {Node<K,V> p = (fh >= 0 ? f :(f instanceof TreeBin) ?((TreeBin<K,V>)f).first : null);//循环到链表或者红黑树的尾部while (p != null) {--delta;p = p.next;}//首先删除链、树的末尾元素,避免产生大量垃圾 //利用CAS无锁置null setTabAt(tab, i++, null);}}}}if (delta != 0L)addCount(delta, -1);}
相关文章:

IANA定义的常见服务的端口号列表
最新明细:http://www.iana.org/assignments/port-numbers 几个重要常见端口: 21 FTP 22 SSH 80 HTTP 443 HTTPS 1433 MSSQLserver 3306 MySQL 11211 memcached
oracel 服务详细介绍
中的方法成功安装Oracle 11g后,共有7个服务, 这七个服务的含义分别为: 1. Oracle ORCL VSS Writer Service: Oracle卷映射拷贝写入服务,VSS(Volume Shadow Copy Service)能够让存储基础设备&…

使用 Python 开发一个恐龙跑跑小游戏,玩起来
作者 | 周萝卜 来源 | 萝卜大杂烩 相信很多人都玩过 chrome 浏览器上提供的恐龙跑跑游戏,在我们断网或者直接在浏览器输入地址“chrome://dino/”都可以进入游戏 今天我们就是用 Python 来制作一个类似的小游戏 素材准备 首先我们准备下游戏所需的素材,比…

了解和入门注解的应用
2019独角兽企业重金招聘Python工程师标准>>> 一、概述 jdk的java.lang包中提供的最基本的annotation 1、SuppressWarnings("deprecation") package staticimport.annotation;SuppressWarnings("deprecation") public class AnnotationTest {pub…
Linux下开发优秀链接
不得不说CSDN博客这次改版变化很大,但是友情链接功能太脆弱了。 只有自己写个帖子,不断更新吧。Linux基础 Linux内核mirrors163LVS中文站点 孙海龙 howtoforge.com 地中海东岸的蒲公英 服务器运维与网站架构 Nginx中文维基 ACME Bory.Chan Tim[后端技术]…

Q 版老黄带着硬核技术再登场,有点可爱,很有东西
编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 看到下面这个老黄是不是觉得很Q~ 11月9日,GTC 大会再次来了,英伟达创始人兼CEO黄仁勋再次从自己虚拟厨房走出来。 本次 GTC 大会都有哪些亮点呢? Q 版黄仁勋 英伟达展…

linux第七章《档案与目录管理》重点回顾
转载于:https://www.cnblogs.com/wubingshenyin/p/4514969.html

Effective java 43返回零长度的数组或者集合而不是null
转载于:https://www.cnblogs.com/limingxian537423/p/8391285.html

《Unix网络编程卷1-套接字联网API》第一个例子编译 不通过问题解决
《Unix网络编程卷1-套接字联网API》是本好书。 但是第一个例子不是很好编译。 需要如下步骤: 本人机器CentOS 5.4 1.下载源码 unpv13e解压到任意目录 然后按其readme文件操作./configure # try to figure out all implementation differencescd lib # bu…
angularJs的学习笔记-01(创建项目)
1,进入angular-phonecat目录 执行下面命令 git checkout -f step-0 然后访问 http://localhost:8000/app/ 页面出现 “Nothing here yet!” 现在就可以自己创建HTML,编写angular了 app/index.html <!doctype html> <html lang"en"…

一文搞定深度学习建模预测全流程(Python)
作者 | 泳鱼来源 | 算法进阶本文详细地梳理及实现了深度学习模型构建及预测的全流程,代码示例基于python及神经网络库keras,通过设计一个深度神经网络模型做波士顿房价预测。主要依赖的Python库有:keras、scikit-learn、pandas、tensorflow&a…
第163天:js面向对象-对象创建方式总结
面向对象-对象创建方式总结 1、 创建对象的方式,json方式 推荐使用的场合: 作为函数的参数,临时只用一次的场景。比如设置函数原型对象。 1 var obj {};2 //对象有自己的 属性 和 行为3 // 属性比如: 年龄、姓名、性别4 // 行…

一个从四秒到10毫秒,花了1年的算法问题?
原文:一个从四秒到10毫秒,花了1年的算法问题?五一后的第一周,由于搬家腰扭伤了,没注意导致压迫神经,躺在床上休息了好几天。所以没事就挂 QQ,一个网友突然问了我一个算法问题。所以有了这篇文章。感触很深&…
xinetd 说明
xinetd 是什么在linux中一些不长期使用的服务(不重要的服务?)没有被作为单独的守护进程在开机时启用,linux把这些服务监听端口全部由一个独立的进程xinetd集中监听,当收到相应的客户端请求之后,xinetd进程就…

英特尔携手中科院计算所建立中国首个 oneAPI 卓越中心
11月12日,在第三届中国超级算力大会(ChinaSC 2021)上,英特尔与中国科学院计算技术研究所共同建立中国首个 oneAPI 卓越中心,来扩大 oneAPI 对中国本土国产硬件的支持及使用oneAPI来开发全栈式开源软件。 在上个月刚结…
前端学习资源分享
2019独角兽企业重金招聘Python工程师标准>>> 推荐大神文章(文字教程) 1 综合类 前端知识体系前端知识结构Web前端开发大系概览Web前端开发大系概览-中文版智能社 - 精通JavaScript开发JavaScript中的this陷阱的最全收集--没有之一JS函数式编程指南腾讯移动Web前端知…
Nginx源码分析链接
nginx-0.8.38源码探秘:http://blog.csdn.net/ccdd14/article/details/5872312nginx源码分析: http://blog.sina.com.cn/s/blog_677be95b0100iiv7.html

基于聚类的图像分割(Python)
作者 | 小白来源 | 小白学视觉了解图像分割当我们在做一个图像分类任务时,首先我们会想从图像中捕获感兴趣的区域,然后再将其输入到模型中。让我们尝试一种称为基于聚类的图像分割技术,它会帮助我们在一定程度上提高模型性能,让我…

4月第4周全球域名商TOP15:万网第四 增势减弱
IDC评述网(idcps.com)05月21日报道:据WebHosting.info公布的最新数据显示,在4月第4周,全球十五强域名商中,域名总量成功实现净增长的有7家。其中,中法各1家,即中国万网与OVH.NET&…
PXE全自动安装操作系统--centos7.3学习笔记
PXE服务器:192.168.110.110 环境准备 安装软件 # yum -y install dhcp tftp-server tftp vsftpd lftp DHCP配置 # cd /var/dhcp # cp /usr/share/doc/dhcp-4.2.5/dhcpd.conf.example /etc/dhcp/dhcpd.conf # vim /etc/dhcp/dhcpd.conf subnet 192.168.110.0 netmask…

无事“自动驾驶”,有事“辅助驾驶”?
近日来,智能汽车事故频发,且事故原因多与所谓的“自动驾驶”功能有关,这不由得引起了人们对“自动驾驶”发展前景的担忧。实际上,大众理解的“自动驾驶”与官方的定义可能有所出入。全球公认的标准一般是由SAE International&…

九、数据库群集部署、配置 (二)
九、 数据库群集部署、配置(二)配置DTC 角色高可用在群集管理器对话框,选择"配置角色",如图2. 选择"下一步",如图3. 在选择角色对话框,选择"分布式事务协调器(DTC&a…

Linux下怎么诊断网站性能异常
网站如果突然慢了,怎么样诊断? 先用Top命令查看进程 #top选择Haporxy代理的进程 #strace -p 25054进程在干什么看的一清二楚。
[Java面试五]Spring总结以及在面试中的一些问题.
2019独角兽企业重金招聘Python工程师标准>>> 1.谈谈你对spring IOC和DI的理解,它们有什么区别? IoC Inverse of Control 反转控制的概念,就是将原本在程序中手动创建UserService对象的控制权,交由Spring框架管理&#…
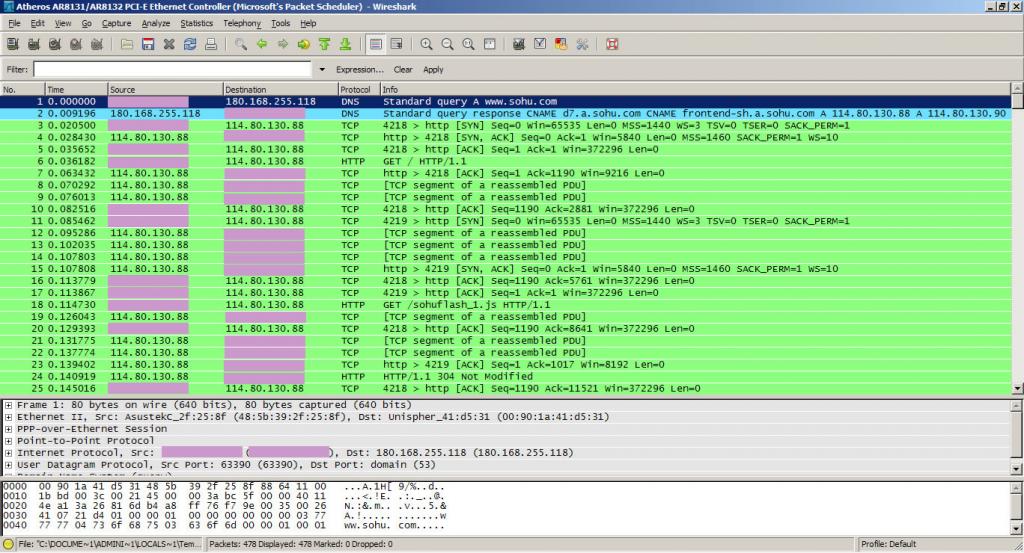
一次完整的抓包分析 Reserved TCP/IP Port List
抓包如图所示: 本机IP被粉色遮住。。。http://www.skynet.ie/~colinmac/Programming/port_listing.htmlReserved TCP/IP Port List This is an complete list of the TCP/IP ports that are IANA registered and so are not for general use in network programming…

关于Centos下Clamv反病毒软件包更新问题
最近一直在研究学习Centos下搭建Postfix实现邮件网关的内容,以便后期邮件平台网关的灾备做一些准备,今天安装Postfix到了对Clamv反病毒软件包更新的安装配置部分,遇到了个小的插曲。 具体遇到问题看着不是什么大问题,就是Clamv之前…

Meta 研发触觉手套助力元宇宙,虚拟世界也可以有触觉
编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 你不能戴着 Meta 的新型高科技虚拟现实手套抚摸狗。 但研究人员可以让它越来越接近。 Meta(前身为 Facebook)伴随着对于虚拟世界和元宇宙的领域而闻名。然而,七年…
如何判断哪个商城系统好?
现在市面上很多商城系统,如果开发者有商城系统的需求,那么可以用,可以缩短开发周期,网站更快速上线;可降低开发成本。但是正因为系统很多,怎么选择就是个问题了。因为一个商城所使用的商城系统也会产生对一…

TCP/IP中 3688端口是什么?
原文英文:http://www.corrupteddatarecovery.com/Port/3688udp-Port-Type-simple-push-s-simple-push-s.asp 翻译的不好将就看吧。 一个软件端口(通常只是被称为一个“口”)是一个虚拟的数据连接,可以通过程序用于直接交换数据&a…
文件处理命令:sed
使用:sed [-nefr] actionaction:-i直接修改读取的档案内容,而不是由屏幕输出,-r表示支持延伸型正则表达式的语法。动作说明:[n1[,n2]] function n1,n2表示要选择的行数,function包括:a-新增,c-取…