一文搞定深度学习建模预测全流程(Python)

作者 | 泳鱼
来源 | 算法进阶
本文详细地梳理及实现了深度学习模型构建及预测的全流程,代码示例基于python及神经网络库keras,通过设计一个深度神经网络模型做波士顿房价预测。主要依赖的Python库有:keras、scikit-learn、pandas、tensorflow(建议可以安装下anaconda包,自带有常用的python库)
一、基础介绍
机器学习
机器学习的核心是通过模型从数据中学习并利用经验去决策。进一步的,机器学习一般可以概括为:从数据出发,选择某种模型,通过优化算法更新模型的参数值,使任务的指标表现变好(学习目标),最终学习到“好”的模型,并运用模型对数据做预测以完成任务。由此可见,机器学习方法有四个要素:数据、模型、学习目标、优化算法。
深度学习
深度学习是机器学习的一个分支,它是使用多个隐藏层神经网络模型,通过大量的向量计算,学习到数据内在规律的高阶表示特征,并利用这些特征决策的过程。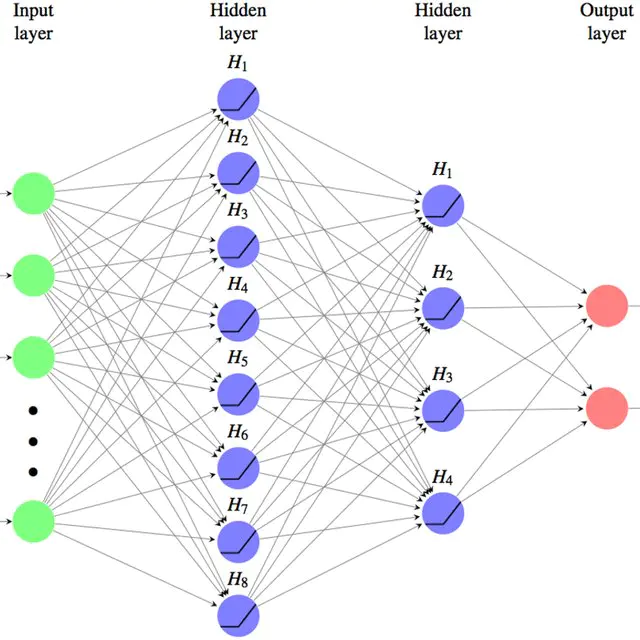
keras简介
本文基于keras搭建神经网络模型去预测,keras是python上常用的神经网络库。相比于tensorflow、Pytorch等库,它对初学者很友好,开发周期较快。下图为keras要点知识的速查表:
二、建模流程
深度学习的建模预测流程,与传统机器学习整体是相同的,主要区别在于深度学习是端对端学习,可以自动提取高层次特征,大大减少了传统机器学习依赖的特征工程。如下详细梳理流程的各个节点并附相应代码: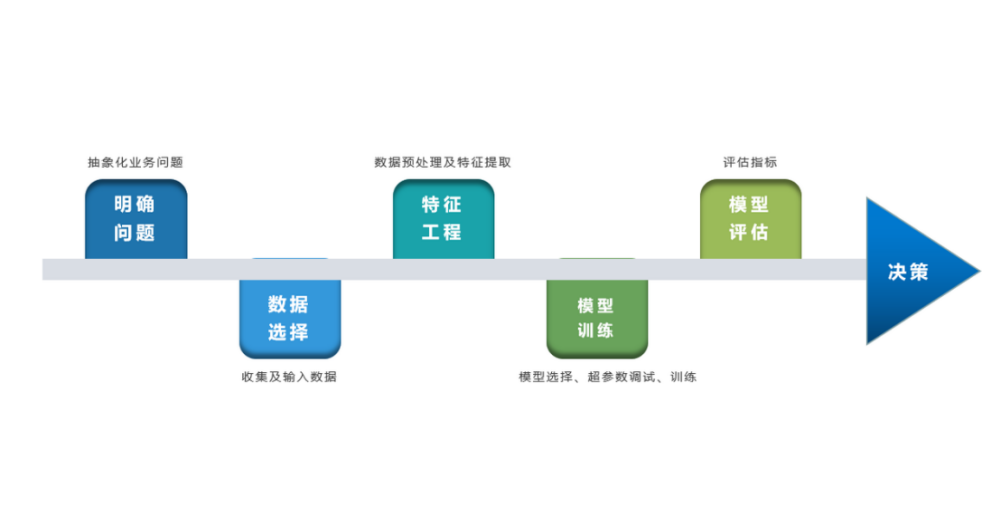
2.1 明确问题及数据选择
2.1.1 明确问题
深度学习的建模预测,首先需要明确问题,即抽象为机器 / 深度学习的预测问题:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。
以预测房价为例,我们需要输入:和房价有关的数据信息为特征x,对应的房价为y作为监督信息。再通过神经网络模型学习特征x到房价y内在的映射关系。通过学习好的模型输入需要预测数据的特征x,输出模型预测Y。对于一个良好的模型,它预测房价Y应该和实际y很接近。
2.1.2 数据选择
深度学习是端对端学习,学习过程中会提取到高层次抽象的特征,大大弱化特征工程的依赖,正因为如此,数据选择也显得格外重要,其决定了模型效果的上限。如果数据质量差,预测的结果自然也是很差的——业界一句名言“garbage in garbage out”。
数据选择是准备机器 / 深度学习原料的关键,需要关注的是:
①数据样本规模:对于深度学习等复杂模型,通常样本量越多越好。如《Revisiting Unreasonable Effectiveness of Data in Deep Learning Era 》等研究,一定规模下,深度学习性能会随着数据量的增加而增加。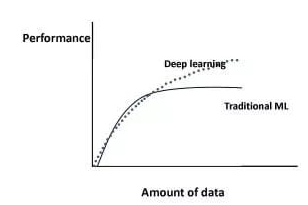 然而工程实践中,受限于硬件支持、标注标签成本等原因,样本的数据量通常是比较有限的,这也是机器学习的重难点。对于模型所需最少的样本量,其实没有固定准则,需要要结合实际样本特征、任务复杂度等具体情况(经验上,对于分类任务,每个类别要上千的样本数)。
然而工程实践中,受限于硬件支持、标注标签成本等原因,样本的数据量通常是比较有限的,这也是机器学习的重难点。对于模型所需最少的样本量,其实没有固定准则,需要要结合实际样本特征、任务复杂度等具体情况(经验上,对于分类任务,每个类别要上千的样本数)。
② 数据的代表性:数据质量差、无代表性,会导致模型拟合效果差。需要明确与任务相关的数据表范围,避免缺失代表性数据或引入大量无关数据作为噪音。
③ 数据时间范围:对于监督学习的特征变量x及标签y,如与时间先后有关,则需要划定好数据时间窗口,否则可能会导致常见的数据泄漏问题,即存在了特征与标签因果颠倒的情况。
以预测房价任务为例,对数据选择进行说明:
收集房价相关的数据信息(特征维度)和对应房价(标签),以及尽量多的样本数。数据信息如该区域的繁华程度、教育资源、治安等情况就和预测的房价比较相关,有代表性。而诸如该区域“人均养的兔子数”类数据信息,对房价的预测就没那么相关,对于无代表性的数据特征的加入,主要会增加人工处理的成本、计算复杂度,还有可能引入了模型学习的噪音。
划定好数据时间窗口。比如我们可以学习该区域历史2010~2020年的房价,预测未来2021的房价(这是一个经典的时间序列预测问题,常用RNN模型)。但却不能学习了2021年或者更后面的未来房价、人口数等相关信息,反过来去预测2021年房价,这就是一个数据泄露的问题(模型都学习了与标签相关等未知的信息,还预测个啥?)。
本节代码
如下加载数据的代码,使用的是keras自带的波士顿房价数据集。一些常用的机器学习开源数据集可以到kaggle.com/datasets、archive.ics.uci.edu等网站下载。
from keras.datasets import boston_housing #导入波士顿房价数据集(train_x, train_y), (test_x, test_y) = boston_housing.load_data()波士顿房价数据集是统计20世纪70年代中期波士顿郊区房价等情况,有当时城镇的犯罪率、房产税等共计13个指标(特征)以及对应的房价中位数(标签)。
2.2 特征工程
特征工程就是对原始数据分析处理,转化为模型可用的特征。这些特征可以更好地向预测模型描述潜在规律,从而提高模型对未见数据的准确性。对于深度学习模型,特征生成等加工不多,主要是一些数据的分析、预处理,然后就可以灌入神经网络模型了。
2.2.1 探索性数据分析
选择好数据后,可以先做探索性数据分析(EDA)去理解数据本身的内部结构及规律。如果你对数据情况不了解,也没有相关的业务背景知识,不做相关的分析及预处理,直接将数据喂给模型往往效果不太好。通过探索性数据分析,可以了解数据分布、缺失、异常及相关性等情况。
本节代码
我们可以通过EDA数据分析库如pandas profiling,自动生成分析报告,可以看到这份现成的数据集是比较"干净的":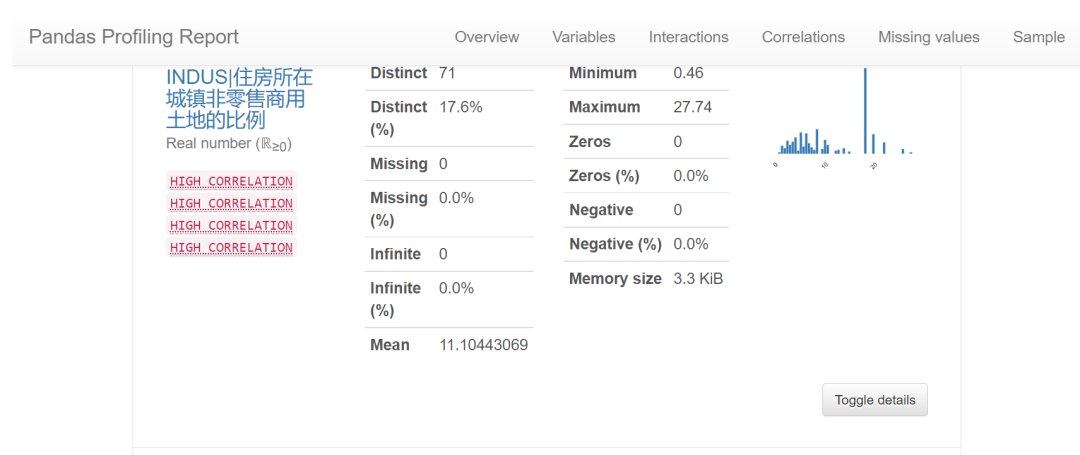
import pandas as pd
import pandas_profiling# 特征名称
feature_name = ['CRIM|住房所在城镇的人均犯罪率','ZN|住房用地超过 25000 平方尺的比例','INDUS|住房所在城镇非零售商用土地的比例','CHAS|有关查理斯河的虚拟变量(如果住房位于河边则为1,否则为0 )','NOX|一氧化氮浓度','RM|每处住房的平均房间数','AGE|建于 1940 年之前的业主自住房比例','DIS|住房距离波士顿五大中心区域的加权距离','RAD|距离住房最近的公路入口编号','TAX 每 10000 美元的全额财产税金额','PTRATIO|住房所在城镇的师生比例','B|1000(Bk|0.63)^2,其中 Bk 指代城镇中黑人的比例','LSTAT|弱势群体人口所占比例']train_df = pd.DataFrame(train_x, columns=feature_name) # 转为df格式pandas_profiling.ProfileReport(train_df)2.2.2 特征表示
像图像、文本字符类的数据,需要转换为计算机能够处理的数值形式。图像数据(pixel image)实际上是由一个像素组成的矩阵所构成的,而每一个像素点又是由RGB颜色通道中分别代表R、G、B的一个三维向量表示,所以图像实际上可以用RGB三维矩阵(3-channel matrix)的表示(第一个维度:高度,第二个维度:宽度,第三个维度:RGB通道),最终再重塑为一列向量(reshaped image vector)方便输入模型。
文本类(类别型)的数据可以用多维数组表示,包括:① ONEHOT(独热编码)表示:它是用单独一个位置的0或1来表示每个变量值,这样就可以将每个不同的字符取值用唯一的多维数组来表示,将文字转化为数值。如字符类的性别信息就可以转换为“是否为男”、“是否为女”、“未知”等特征。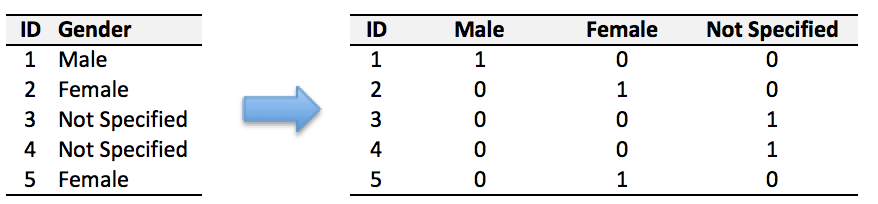
②word2vetor分布式表示:它基本的思想是通过神经网络模型学习每个单词与邻近词的关系,从而将单词表示成低维稠密向量。通过这样的分布式表示可以学习到单词的语义信息,直观来看语义相似的单词其对应的向量距离相近。
本节代码
数据集已是数值类数据,本节不做处理。
2.2.2 特征清洗
异常值处理 收集的数据由于人为或者自然因素可能引入了异常值(噪音),这会对模型学习进行干扰。通常需要处理人为引起的异常值,通过业务及技术手段(如数据分布、3σ准则)判定异常值,再结合实际业务含义删除或者替换掉异常值。
缺失值处理 神经网络模型缺失值的处理是必要的,数据缺失值可以通过结合业务进行填充数值或者删除。① 缺失率较高,结合业务可以直接删除该特征变量。经验上可以新增一个bool类型的变量特征记录该字段的缺失情况,缺失记为1,非缺失记为0;② 缺失率较低,可使用一些缺失值填充手段,如结合业务fillna为0或-9999或平均值,或者训练回归模型预测缺失值并填充。
本节代码
从数据分析报告可见,波士顿房价数据集无异常、缺失值情况,本节不做处理。
2.2.3 特征生成
特征生成作用在于弥补基础特征对样本信息的表达有限,增加特征的非线性表达能力,提升模型效果。它是根据基础特征的含义进行某种处理(聚合 / 转换之类),常用方法如人工设计、自动化特征衍生(如featuretools工具):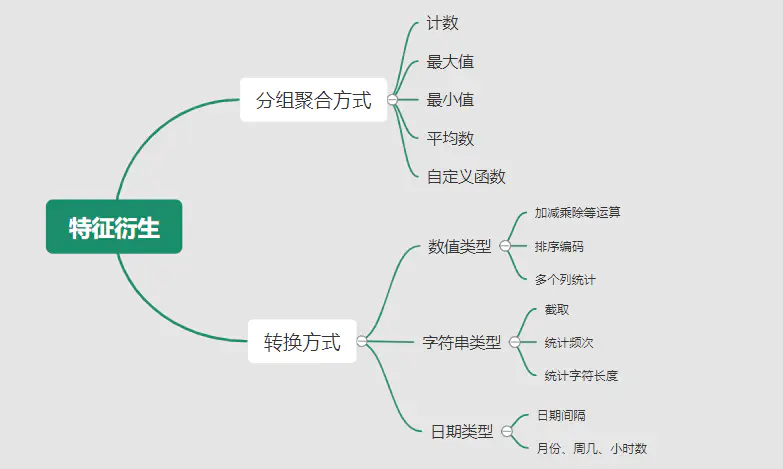 深度神经网络会自动学习到高层次特征,常见的深度学习的任务,图像类、文本类任务通常很少再做特征生成。而对于数值类的任务,加工出显著特征对加速模型的学习是有帮助的,可以做尝试。
深度神经网络会自动学习到高层次特征,常见的深度学习的任务,图像类、文本类任务通常很少再做特征生成。而对于数值类的任务,加工出显著特征对加速模型的学习是有帮助的,可以做尝试。
本节代码
特征已经比较全面,本节不再做处理,可自行验证特征生成的效果。
2.2.4 特征选择
特征选择用于筛选出显著特征、摒弃非显著特征。这样做主要可以减少特征(避免维度灾难),提高训练速度,降低运算开销;减少干扰噪声,降低过拟合风险,提升模型效果。常用的特征选择方法有:过滤法(如特征缺失率、单值率、相关系数)、包装法(如RFE递归特征消除、双向搜索)、嵌入法(如带L1正则项的模型、树模型自带特征选择)。
本节代码
模型使用L1正则项方法,本节不再做处理,可自行验证其他方法。
2.3 模型训练
神经网络模型的训练主要有3个步骤:
构建模型结构(主要有神经网络结构设计、激活函数的选择、模型权重如何初始化、网络层是否批标准化、正则化策略的设定)
模型编译(主要有学习目标、优化算法的设定)
模型训练及超参数调试(主要有划分数据集,超参数调节及训练)
2.3.1 模型结构
常见的神经网络模型结构有全连接神经网络(FCN)、RNN(常用于文本 / 时间系列任务)、CNN(常用于图像任务)等等。
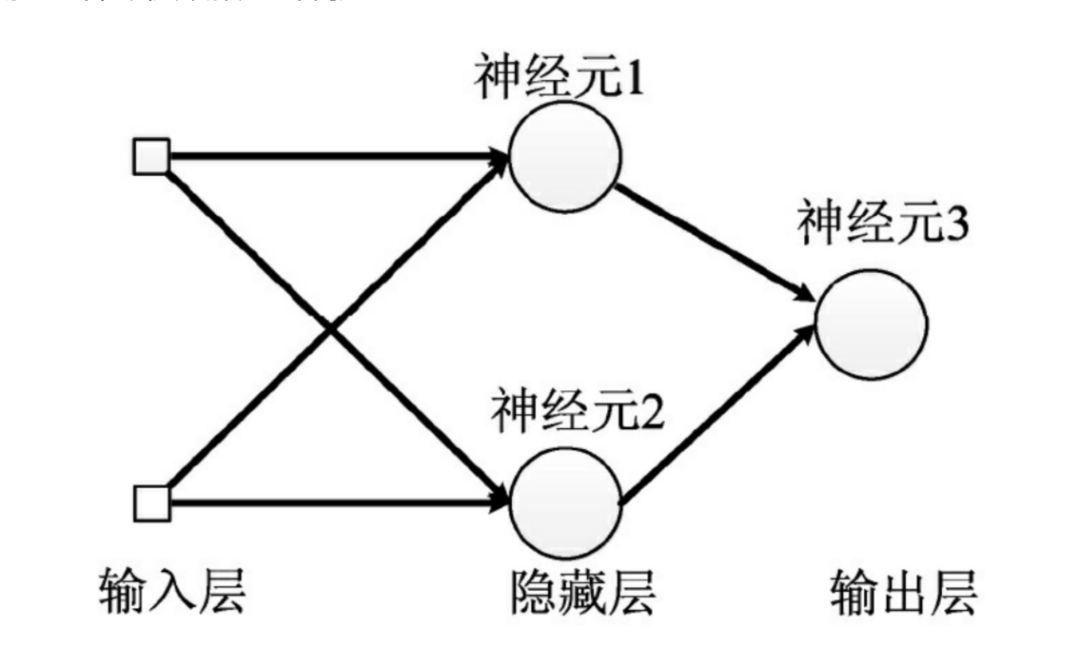
神经网络由输入层、隐藏层与输出层构成。不同的层数、神经元(计算单元)数目的模型性能也会有差异。
输入层:为数据特征输入层,输入数据特征维数就对应着网络的神经元数。(注:输入层不计入模型层数)
隐藏层:即网络的中间层(可以很多层),其作用接受前一层网络输出作为当前的输入值,并计算输出当前结果到下一层。隐藏层的层数及神经元个数直接影响模型的拟合能力。
输出层:为最终结果输出的网络层。输出层的神经元个数代表了分类类别的个数(注:在做二分类时情况特殊一点,如果输出层的激活函数采用sigmoid,输出层的神经元个数为1个;如果采用softmax,输出层神经元个数为2个是与分类类别个数对应的;)
对于模型结构的神经元个数 ,输入层、输出层的神经元个数通常是确定的,主要需要考虑的是隐藏层的深度及宽度,在忽略网络退化问题的前提下,通常隐藏层的神经元的越多,模型有更多的容量(capcity)去达到更好的拟合效果(也更容易过拟合)。搜索合适的网络深度及宽度,常用有人工经验调参、随机 / 网格搜索、贝叶斯优化等方法。经验上的做法,可以参照下同类任务效果良好的神经网络模型的结构,结合实际的任务,再做些微调。
2.3.2 激活函数
根据万能近似原理,简单来说,神经网络有“够深的网络层”以及“至少一层带激活函数的隐藏层”,既可以拟合任意的函数。可见激活函数的重要性,它起着特征空间的非线性转换。对于激活函数选择的经验性做法:
对于输出层,二分类的输出层的激活函数常选择sigmoid函数,多分类选择softmax;回归任务根据输出值范围来确定使不使用激活函数。
对于隐藏层的激活函数通常会选择使用ReLU函数,保证学习效率。
2.3.3 权重初始化
权重参数初始化可以加速模型收敛速度,影响模型结果。常用的初始化方法有:
uniform均匀分布初始化
normal高斯分布初始化 需要注意的是,权重不能初始化为0,这会导致多个隐藏神经元的作用等同于1个神经元,无法收敛。
2.3.4 批标准化
batch normalization(BN)批标准化,是神经网络模型常用的一种优化方法。它的原理很简单,即是对原来的数值进行标准化处理: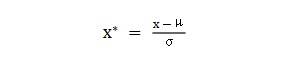 batch normalization在保留输入信息的同时,消除了层与层间的分布差异,具有加快收敛,同时有类似引入噪声正则化的效果。它可应用于网络的输入层或隐藏层,当用于输入层,就是线性模型常用的特征标准化处理。
batch normalization在保留输入信息的同时,消除了层与层间的分布差异,具有加快收敛,同时有类似引入噪声正则化的效果。它可应用于网络的输入层或隐藏层,当用于输入层,就是线性模型常用的特征标准化处理。
2.3.5 正则化
正则化是在以(可能)增加经验损失为代价,以降低泛化误差为目的,抑制过拟合,提高模型泛化能力的方法。经验上,对于复杂任务,深度学习模型偏好带有正则化的较复杂模型,以达到较好的学习效果。常见的正则化策略有:dropout,L1、L2、earlystop方法。
2.3.6 选择学习目标
机器 / 深度学习通过学习到“好”的模型去决策,“好”即是机器 / 深度学习的学习目标,通常也就是预测值与目标值之间的误差尽可能的低。衡量这种误差的函数称为代价函数 (Cost Function)或者损失函数(Loss Function),更具体地说,机器 / 深度学习的目标是极大化降低损失函数。
对于不同的任务,往往也需要用不同损失函数衡量,经典的损失函数包括回归任务的均方误差损失函数及二分类任务的交叉熵损失函数等。
均方误差损失函数
衡量模型回归预测的误差情况,一个简单思路是用各个样本i的预测值f(x;w)减去实际值y求平方后的平均值,这也就是经典的均方误差(Mean Squared Error)损失函数。通过极小化降低均方误差损失函数,可以使得模型预测值与实际值数值差异尽量小。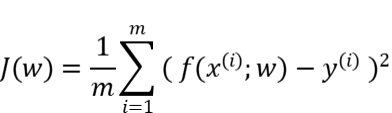
交叉熵损失函数
衡量二分类预测模型的误差情况,常用交叉熵损失函数,使得模型预测分布尽可能与实际数据经验分布一致(最大似然估计)。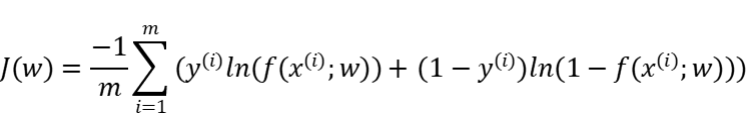 另外,还有一些针对优化难点而设计的损失函数,如Huber Loss主要用于解决回归问题中,存在奇点数据带偏模型训练的问题。Focal Loss主要解决分类问题中类别不均衡导致的模型训偏问题。
另外,还有一些针对优化难点而设计的损失函数,如Huber Loss主要用于解决回归问题中,存在奇点数据带偏模型训练的问题。Focal Loss主要解决分类问题中类别不均衡导致的模型训偏问题。
2.3.7 选择优化算法
当我们机器 / 深度学习的学习目标是极大化降低(某个)损失函数,那么如何实现这个目标呢?通常机器学习模型的损失函数较复杂,很难直接求损失函数最小的公式解。幸运的是,我们可以通过优化算法(如梯度下降、随机梯度下降、Adam等)有限次迭代优化模型参数,以尽可能降低损失函数的值,得到较优的参数值。
对于大多数任务而言,通常可以直接先试下Adam、SGD,然后可以继续在具体任务上验证不同优化器效果。
2.3.8 模型训练及超参数调试
划分数据集
训练模型前,常用的HoldOut验证法(此外还有留一法、k折交叉验证等方法),把数据集分为训练集和测试集,并可再对训练集进一步细分为训练集和验证集,以方便评估模型的性能。① 训练集(training set):用于运行学习算法,训练模型。② 开发验证集(development set)用于调整模型超参数、EarlyStopping、选择特征等,以选择出合适模型。③ 测试集(test set)只用于评估已选择模型的性能,但不会据此改变学习算法或参数。
超参数调试
神经网络模型的超参数是比较多的:数据方面超参数 如验证集比例、batch size等;模型方面 如单层神经元数、网络深度、选择激活函数类型、dropout率等;学习目标方面 如选择损失函数类型,正则项惩罚系数等;优化算法方面 如选择梯度算法类型、初始学习率等。
常用的超参调试有人工经验调节、网格搜索(grid search或for循环实现)、随机搜索(random search)、贝叶斯优化(bayesian optimization)等方法。
另外,有像Keras Tuner分布式超参数调试框架(文档见:keras.io/keras_tuner),集成了常用调参方法,还比较实用的。
本节代码
创建模型结构
结合当前房价预测任务是一个经典简单表格数据的回归预测任务。我们采用基础的全连接神经网络,隐藏层的深度一两层也就差不多。通过keras.Sequential方法来创建一个神经网络模型,并在依次添加带有批标准化的输入层,一层带有relu激活函数的k个神经元的隐藏层,并对这层隐藏层添加dropout、L1、L2正则的功能。由于回归预测数值实际范围(5~50+)直接用线性输出层,不需要加激活函数。
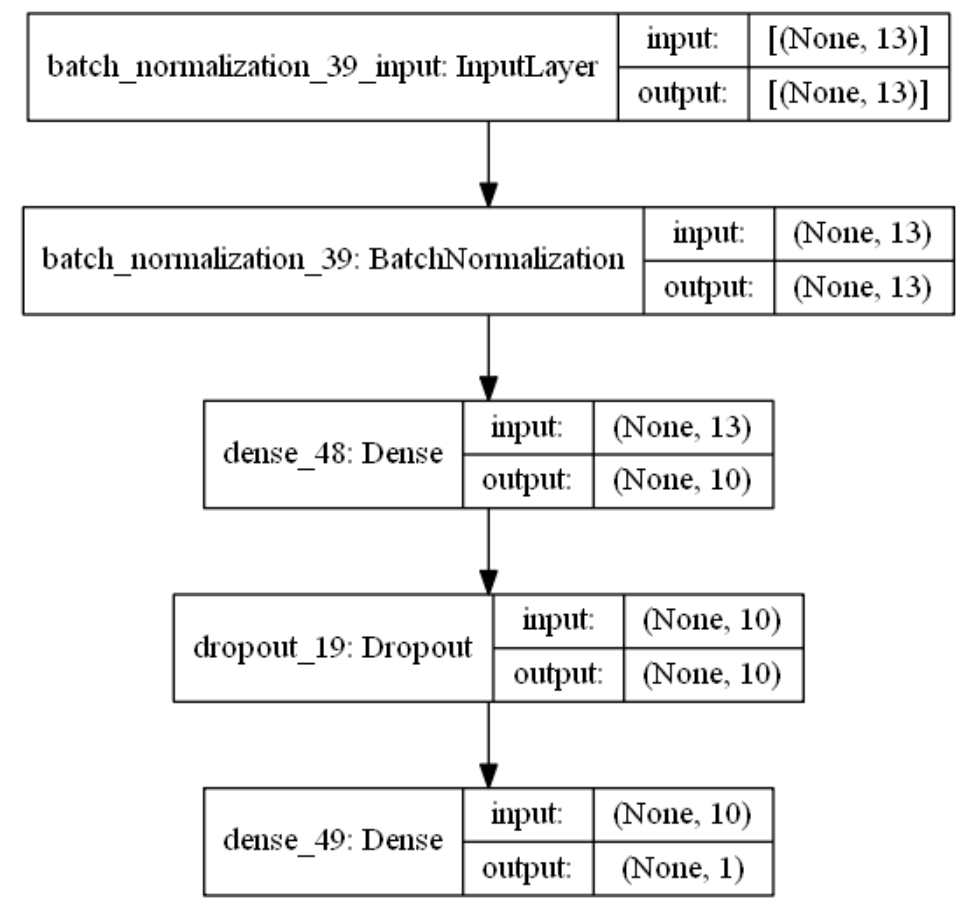
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from tensorflow import random
from keras import regularizers
from keras.layers import Dense,Dropout,BatchNormalization
from keras.models import Sequential, Model
from keras.callbacks import EarlyStopping
from sklearn.metrics import mean_squared_errornp.random.seed(1) # 固定随机种子,使每次运行结果固定
random.set_seed(1)# 创建模型结构:输入层的特征维数为13;1层k个神经元的relu隐藏层;线性的输出层;for k in [5,20,50]: # 网格搜索超参数:神经元数kmodel = Sequential()model.add(BatchNormalization(input_dim=13)) # 输入层 批标准化 model.add(Dense(k, kernel_initializer='random_uniform', # 均匀初始化activation='relu', # relu激活函数kernel_regularizer=regularizers.l1_l2(l1=0.01, l2=0.01), # L1及L2 正则项use_bias=True)) # 隐藏层model.add(Dropout(0.1)) # dropout法model.add(Dense(1,use_bias=True)) # 输出层模型编译
设定学习目标为(最小化)回归预测损失mse,优化算法为adam
model.compile(optimizer='adam', loss='mse')模型训练
我们通过传入训练集x,训练集标签y,使用fit(拟合)方法来训练模型,其中epochs为迭代次数,并通过EarlyStopping及时停止在合适的epoch,减少过拟合;batch_size为每次epoch随机采样的训练样本数目。
# 训练模型history = model.fit(train_x, train_y, epochs=500, # 训练迭代次数batch_size=50, # 每epoch采样的batch大小validation_split=0.1, # 从训练集再拆分验证集,作为早停的衡量指标callbacks=[EarlyStopping(monitor='val_loss', patience=20)], #早停法verbose=False) # 不输出过程 print("验证集最优结果:",min(history.history['val_loss']))model.summary() #打印模型概述信息# 模型评估:拟合效果plt.plot(history.history['loss'],c='blue') # 蓝色线训练集损失plt.plot(history.history['val_loss'],c='red') # 红色线验证集损失plt.show()最后,这里简单采用for循环,实现类似网格搜索调整超参数,验证了隐藏层的不同神经元数目(超参数k)的效果。由验证结果来看,神经元数目为50时,损失可以达到10的较优效果(可以继续尝试模型增加深度、宽度,达到过拟合的边界应该有更好的效果)。
注:本节使用的优化方法较多(炫技ing),单纯是为展示一遍各种深度学习的优化tricks。模型并不是优化方法越多越好,效果还是要实际问题具体验证。
2.4 模型评估及优化
机器学习学习的目标是极大化降低损失函数,但这不仅仅是学习过程中对训练数据有良好的预测能力(极低的训练损失),根本上还在于要对新数据(测试集)能有很好的预测能力(泛化能力)。
评估模型误差的指标
评估模型的预测误差常用损失函数的大小来判断,如回归预测的均方损失。但除此之外,对于一些任务,用损失函数作为评估指标并不直观,所以像分类任务的评估还常用f1-score,可以直接展现各种类别正确分类情况。
查准率P:是指分类器预测为Positive的正确样本(TP)的个数占所有预测为Positive样本个数(TP+FP)的比例;查全率R:是指分类器预测为Positive的正确样本(TP)的个数占所有的实际为Positive样本个数(TP+FN)的比例。F1-score是查准率P、查全率R的调和平均:
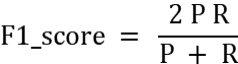
注:如分类任务的f1-score等指标只能用于评估模型最终效果,因为作为学习目标时它们无法被高效地优化,训练优化时常用交叉熵作为其替代的分类损失函数 (surrogate loss function)。
评估拟合效果
评估模型拟合(学习)效果,常用欠拟合、拟合良好、过拟合来表述,通常,拟合良好的模型有更好泛化能力,在未知数据(测试集)有更好的效果。
我们可以通过训练误差及验证集误差评估模型的拟合程度。从整体训练过程来看,欠拟合时训练误差和验证集误差均较高,随着训练时间及模型复杂度的增加而下降。在到达一个拟合最优的临界点之后,训练误差下降,验证集误差上升,这个时候模型就进入了过拟合区域。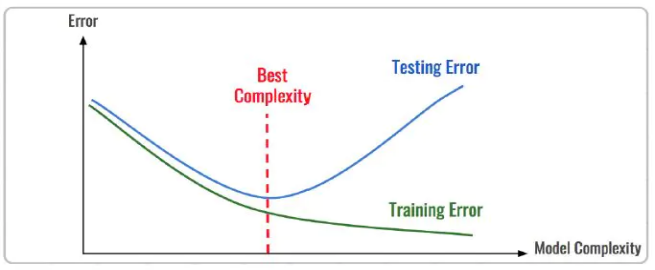
优化拟合效果的方法
实践中通常欠拟合不是问题,可以通过使用强特征及较复杂的模型提高学习的准确度。而解决过拟合,即如何减少泛化误差,提高泛化能力,通常才是优化模型效果的重点,常用的方法在于提高数据的质量、数量以及采用适当的正则化策略。
本节代码
# 模型评估:拟合效果
import matplotlib.pyplot as pltplt.plot(history.history['loss'],c='blue') # 蓝色线训练集损失
plt.plot(history.history['val_loss'],c='red') # 红色线验证集损失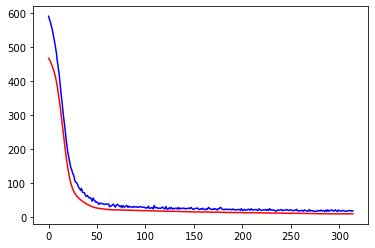 从训练集及验证集的损失来看,训练集、验证集损失都比较低,模型没有过拟合现象。
从训练集及验证集的损失来看,训练集、验证集损失都比较低,模型没有过拟合现象。
# 模型评估:测试集预测结果
pred_y = model.predict(test_x)[:,0]print("正确标签:",test_y)
print("模型预测:",pred_y )print("实际与预测值的差异:",mean_squared_error(test_y,pred_y ))#绘图表示
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 设置图形大小
plt.figure(figsize=(8, 4), dpi=80)
plt.plot(range(len(test_y)), test_y, ls='-.',lw=2,c='r',label='真实值')
plt.plot(range(len(pred_y)), pred_y, ls='-',lw=2,c='b',label='预测值')# 绘制网格
plt.grid(alpha=0.4, linestyle=':')
plt.legend()
plt.xlabel('number') #设置x轴的标签文本
plt.ylabel('房价') #设置y轴的标签文本# 展示
plt.show()评估测试集的预测结果,其mse损失为19.7,观察测试集的实际值与预测值两者的数值曲线是比较一致的!模型预测效果较好。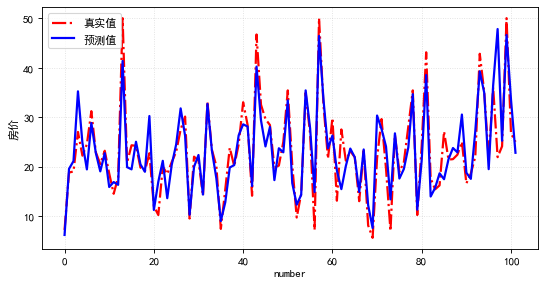
2.5 模型预测结果及解释性
决策应用是机器学习最终目的,对模型预测信息加以分析解释,并应用于实际的工作领域。
对于实际工作需要注意的是,工程上是结果导向,模型在线上运行的效果直接决定模型的成败,不仅仅包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性的综合考虑。
对于神经网络模型预测的分析解释,我们有时需要知道学习的内容,决策的过程是怎么样的(模型的可解释性)。一个可以解释的AI模型(Explainable AI, 简称XAI)意味着运作的透明,便于人类对于对AI决策的监督及接纳,以保证算法的公平性、安全性及隐私性,从而创造更加安全可靠的应用。深度学习可解释性常用方法有:LIME、LRP、SHAP等方法。
本节代码
如下通过SHAP方法,对模型预测单个样本的结果做出解释,可见在这个样本的预测中,CRIM犯罪率为0.006、RM平均房间数为6.575对于房价是负相关的。LSTAT弱势群体人口所占比例为4.98对于房价的贡献是正相关的...,在综合这些因素后模型给出最终预测值。
import shap
import tensorflow as tf # tf版本<2.0# 模型解释性
background = test_x[np.random.choice(test_x.shape[0],100, replace=False)]
explainer = shap.DeepExplainer(model,background)
shap_values = explainer.shap_values(test_x) # 传入特征矩阵X,计算SHAP值
# 可视化第一个样本预测的解释
shap.force_plot(explainer.expected_value, shap_values[0,:], test_x.iloc[0,:])


往
期
回
顾
资讯
2021 PS 进入人工智能P图时代
资讯
跟人聊天 VS 跟机器聊天?
资讯
Q版老黄带着硬核技术再次登场!
图像
深度学习视频理解之图像分类

分享

点收藏

点点赞

点在看
相关文章:

第163天:js面向对象-对象创建方式总结
面向对象-对象创建方式总结 1、 创建对象的方式,json方式 推荐使用的场合: 作为函数的参数,临时只用一次的场景。比如设置函数原型对象。 1 var obj {};2 //对象有自己的 属性 和 行为3 // 属性比如: 年龄、姓名、性别4 // 行…

一个从四秒到10毫秒,花了1年的算法问题?
原文:一个从四秒到10毫秒,花了1年的算法问题?五一后的第一周,由于搬家腰扭伤了,没注意导致压迫神经,躺在床上休息了好几天。所以没事就挂 QQ,一个网友突然问了我一个算法问题。所以有了这篇文章。感触很深&…
xinetd 说明
xinetd 是什么在linux中一些不长期使用的服务(不重要的服务?)没有被作为单独的守护进程在开机时启用,linux把这些服务监听端口全部由一个独立的进程xinetd集中监听,当收到相应的客户端请求之后,xinetd进程就…

英特尔携手中科院计算所建立中国首个 oneAPI 卓越中心
11月12日,在第三届中国超级算力大会(ChinaSC 2021)上,英特尔与中国科学院计算技术研究所共同建立中国首个 oneAPI 卓越中心,来扩大 oneAPI 对中国本土国产硬件的支持及使用oneAPI来开发全栈式开源软件。 在上个月刚结…

前端学习资源分享
2019独角兽企业重金招聘Python工程师标准>>> 推荐大神文章(文字教程) 1 综合类 前端知识体系前端知识结构Web前端开发大系概览Web前端开发大系概览-中文版智能社 - 精通JavaScript开发JavaScript中的this陷阱的最全收集--没有之一JS函数式编程指南腾讯移动Web前端知…
Nginx源码分析链接
nginx-0.8.38源码探秘:http://blog.csdn.net/ccdd14/article/details/5872312nginx源码分析: http://blog.sina.com.cn/s/blog_677be95b0100iiv7.html

基于聚类的图像分割(Python)
作者 | 小白来源 | 小白学视觉了解图像分割当我们在做一个图像分类任务时,首先我们会想从图像中捕获感兴趣的区域,然后再将其输入到模型中。让我们尝试一种称为基于聚类的图像分割技术,它会帮助我们在一定程度上提高模型性能,让我…

4月第4周全球域名商TOP15:万网第四 增势减弱
IDC评述网(idcps.com)05月21日报道:据WebHosting.info公布的最新数据显示,在4月第4周,全球十五强域名商中,域名总量成功实现净增长的有7家。其中,中法各1家,即中国万网与OVH.NET&…
PXE全自动安装操作系统--centos7.3学习笔记
PXE服务器:192.168.110.110 环境准备 安装软件 # yum -y install dhcp tftp-server tftp vsftpd lftp DHCP配置 # cd /var/dhcp # cp /usr/share/doc/dhcp-4.2.5/dhcpd.conf.example /etc/dhcp/dhcpd.conf # vim /etc/dhcp/dhcpd.conf subnet 192.168.110.0 netmask…

无事“自动驾驶”,有事“辅助驾驶”?
近日来,智能汽车事故频发,且事故原因多与所谓的“自动驾驶”功能有关,这不由得引起了人们对“自动驾驶”发展前景的担忧。实际上,大众理解的“自动驾驶”与官方的定义可能有所出入。全球公认的标准一般是由SAE International&…

九、数据库群集部署、配置 (二)
九、 数据库群集部署、配置(二)配置DTC 角色高可用在群集管理器对话框,选择"配置角色",如图2. 选择"下一步",如图3. 在选择角色对话框,选择"分布式事务协调器(DTC&a…

Linux下怎么诊断网站性能异常
网站如果突然慢了,怎么样诊断? 先用Top命令查看进程 #top选择Haporxy代理的进程 #strace -p 25054进程在干什么看的一清二楚。
[Java面试五]Spring总结以及在面试中的一些问题.
2019独角兽企业重金招聘Python工程师标准>>> 1.谈谈你对spring IOC和DI的理解,它们有什么区别? IoC Inverse of Control 反转控制的概念,就是将原本在程序中手动创建UserService对象的控制权,交由Spring框架管理&#…
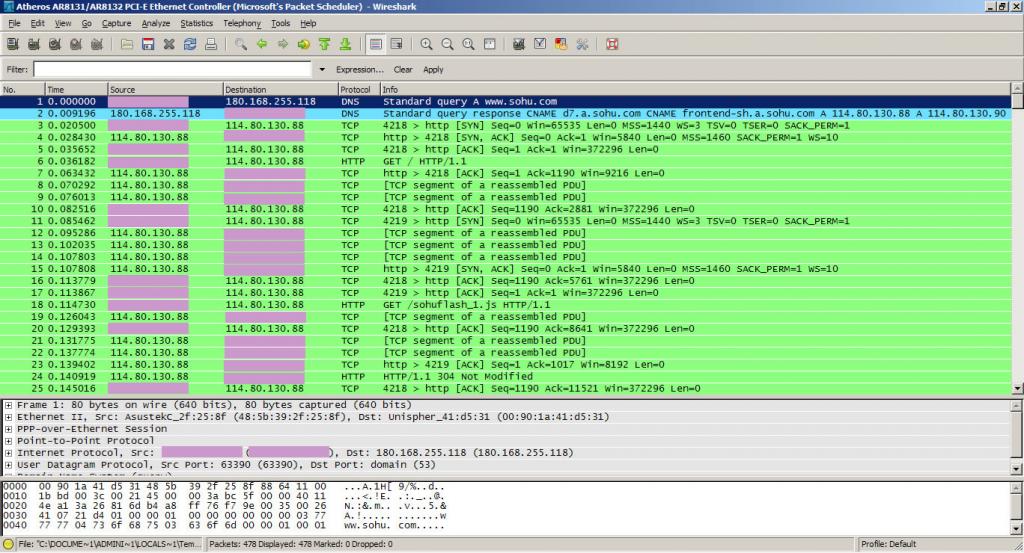
一次完整的抓包分析 Reserved TCP/IP Port List
抓包如图所示: 本机IP被粉色遮住。。。http://www.skynet.ie/~colinmac/Programming/port_listing.htmlReserved TCP/IP Port List This is an complete list of the TCP/IP ports that are IANA registered and so are not for general use in network programming…

关于Centos下Clamv反病毒软件包更新问题
最近一直在研究学习Centos下搭建Postfix实现邮件网关的内容,以便后期邮件平台网关的灾备做一些准备,今天安装Postfix到了对Clamv反病毒软件包更新的安装配置部分,遇到了个小的插曲。 具体遇到问题看着不是什么大问题,就是Clamv之前…

Meta 研发触觉手套助力元宇宙,虚拟世界也可以有触觉
编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 你不能戴着 Meta 的新型高科技虚拟现实手套抚摸狗。 但研究人员可以让它越来越接近。 Meta(前身为 Facebook)伴随着对于虚拟世界和元宇宙的领域而闻名。然而,七年…
如何判断哪个商城系统好?
现在市面上很多商城系统,如果开发者有商城系统的需求,那么可以用,可以缩短开发周期,网站更快速上线;可降低开发成本。但是正因为系统很多,怎么选择就是个问题了。因为一个商城所使用的商城系统也会产生对一…

TCP/IP中 3688端口是什么?
原文英文:http://www.corrupteddatarecovery.com/Port/3688udp-Port-Type-simple-push-s-simple-push-s.asp 翻译的不好将就看吧。 一个软件端口(通常只是被称为一个“口”)是一个虚拟的数据连接,可以通过程序用于直接交换数据&a…
文件处理命令:sed
使用:sed [-nefr] actionaction:-i直接修改读取的档案内容,而不是由屏幕输出,-r表示支持延伸型正则表达式的语法。动作说明:[n1[,n2]] function n1,n2表示要选择的行数,function包括:a-新增,c-取…

新技能 Get,使用直方图处理进行颜色校正
作者 | 小白来源 | 小白学视觉在这篇文章中,我们将探讨如何使用直方图处理技术来校正图像中的颜色。像往常一样,我们导入库,如numpy和matplotlib。此外,我们还从skimage 和scipy.stats库中导入特定函数。import numpy as np impor…
Oracle数据库 之 删除RMAN备份
#su – oracle 切换至存放备份的目录,删除不需要的备份文件。 $export ORACLE_SIDorcl $rman RMAN>connect target / RMAN>crosscheck backup; RMAN>delete expired backup; RMAN>exit 转载于:https://www.cnblogs.com/hdtiny/p/8420770.html
Linux环境编程--fflush(stdout)有什么作用
代码: printf("hello\n");//fflush(stdout);fork(); 输出: hello代码: printf("hello\n");fflush(stdout);fork(); 输出: hellohello说明:系统函数fork()创建新的进程。 printh后打印内容在缓冲区…
sysdba不能远程登录,我们该怎么做 (转载)
sysdba不能远程登录这个也是一个很常见的问题了。 碰到这样的问题我们该如何解决呢? 我们用sysdba登录的时候,用来管理我们的数据库实例,特别是有时候,服务器不再本台机器,这个就更是有必要了。 当我们用sqlplus &qu…

TeaTalk 线上直播倒计时 | 云数据库技术创新研究与实践
随着云计算的发展,数据库上云已经成为趋势,云数据库服务相对于传统数据库在架构、性能与安全等方面都存在着新的挑战。11月23日,移动云TeaTalk线上沙龙带着满满的干货来了!本次技术沙龙邀请了移动云创新中心的技术专家及华中科技大…
再测Golang的JSON库
2019独角兽企业重金招聘Python工程师标准>>> 写项目一直需要进行序列化,听到了,也看到了很多同学老师对各个golang的json库进行测评。那本人为什么还要继续进行这一次测评呢? 因为实践过的知识最有说服力,也是属于自己…
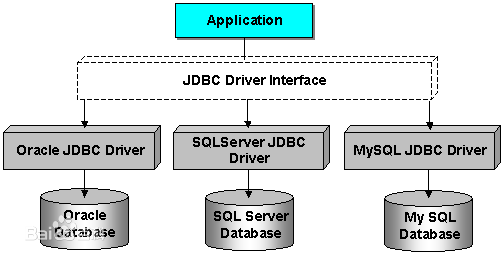
一、JAVA通过JDBC连接mysql数据库(连接)
JDBC ----JDBC(Java DataBase Connectivity)是Java与数据库的接口规范,JDBC定义了一个支持标准SQL功能的通用低层的应用程序编程接口(API),它由Java 语言编写的类和接口组成,旨在让各数据库开发商为Java程序员提供标准的数据库API。 JDBC API…

给你一个热爱阅读的机会,走到哪儿,看到哪儿的读书体验
整理 | 禾木木出品 | AI科技大本营(ID:rgznai100)不知道在自我介绍的时候是不是都有一个共同的爱好:阅读。但是喜欢阅读就代表会经常去图书馆或者是阅读室吗?不!这是一个肯定的答案。通常会因为太忙或是懒惰而选择放弃…
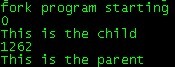
Linux环境编程--进程
查看正在运行的进程 #ps -ef #ps ax 可以看到状态查看nice值 #ps -l #ps -fsystem函数 传递命令,如同在shell中执行 char * p"ps ax"; system(p);或者 "ps ax &";//ps一启动shell就返回execl,execlp,execle函数 exec启动一个新程序…
芝麻HTTP:Scrapy-Splash的安装
2019独角兽企业重金招聘Python工程师标准>>> Scrapy-Splash是一个Scrapy中支持JavaScript渲染的工具,本节来介绍它的安装方式。 Scrapy-Splash的安装分为两部分。一个是Splash服务的安装,具体是通过Docker,安装之后,会…
用bind架设自己的智能DNS
中国的南北网络问题,是许多做网站的人的心病除了使用双通或者多通机房以外,还可以通过多台镜像服务器的方法来提高用户的访问速度 但是,如果使用的双通机房并不是单IP的,或者使用多台镜像的做法,就会面临多个不同的服务…