一、常用的内置方法
- 1、
__new__ 和 __init__:__new__构造方法 、__init__初始化函数
1、__new__方法是真正的类构造方法,用于产生实例化对象(空属性)。重写__new__方法可以控制对象的产 生过程。也就是说会通过继承object的new方法返回一个内存空间(self),给后面的init使用。
2、__init__方法是初始化方法,负责对实例化对象进行属性值初始化,此方法必须返回None,__new__方法 必须返回一个对象。
3、重写__init__方法可以控制对象的初始化过程。相当于在给object之前,添加了我们重写的内容
class Foo:
def __new__(cls, *args, **kwargs):
print('in new') # 先执行
obj = object.__new__(cls) # 使用object返回一个内存空间self,这里可以吧cls理解为指针也就是Foo里的指针
print(obj) #<__main__.Foo object at 0x02FF6D90>
return obj
def __init__(self):
print('init',self) # 后执行 init <__main__.Foo object at 0x02FF6D90>
Foo()
#单例模式 :类无论实例化多少次,对象只能是一个class Student:
__instance = None
def __new__(cls, *args, **kwargs): # 这里的cls是表示来自Student,此时还没有生成self
if not cls.__instance:
cls.__instance = object.__new__(cls)
return cls.__instance
def sleep(self):
print('sleeping...')
stu1 = Student()
stu2 = Student()
print(id(stu1), id(stu2)) # 两者输出相同
print(stu1 is stu2) # True
2、
__str__和__repr__两者的目的都是为了显式的显示对象的一些必要信息,方便查看和调试。
__str__被print默认调用,__repr__被控制台输出时默认调用。即,使用__str__控制用户展示,使用__repr__控制调试展示。#默认所有类继承object类,object类应该有一个默认的str和repr方法,打印的是对象的来源以及对应的内存地址class Student:
def __init__(self, name, age):
self.name = name
self.age = age
stu = Student('zlw', 26)
print(stu) # <__main__.Student object at 0x0000016ED4BABA90>
# 自定义str来控制print的显示内容,str函数必须return一个字符串对象
#__str__class Course:
def __init__(self,name,price,period):
self.name = name
self.price = price
self.period = period
def __str__(self):
'''1、打印这个对象的时候 自动触发__str__''''''2、使用%s进行字符串的拼接的时候 自动触发__str__'''return '%s,%s,%s'%(self.name,self.price,self.period)
python = Course('python',25000,'6 months')
print(python) # python,25000,6 months
print('course %s'%python) # course python,25000,6 months
print(f'course {python}') # course python,25000,6 months
# 如果 不实现str方法,那么对象打印出来只是一串地址,因为object中有str,给你兜着.l = [1,2,3]
# l是对象,打印的时候直接显示的是元素print(l) #打印列表,因为它是列表的对像,所以有自己的父类的str
#reprclass Course:
def __init__(self,name,price,period):
self.name = name
self.price = price
self.period = period
def __repr__(self): # 备胎
return '%s,%s,%s'%(self.name,self.price,self.period)
def __str__(self):
return self.name
# __repr__ = __str__ # 效果和上面定义__repr__一样
python = Course('python',25000,'6 months')
print(python) # python
print('course %s'%python) #course python
print(f'course {python}') #course python
print(repr(python)) # python,25000,6 months,使用的__repr__的打印,显然此时要打印的对像str不行
print('course %r'%python) #course python,25000,6 months
#总结:# 如果str存在,repr也存在# 那么print(obj)和使用字符串格式化format,%s这两种方式 调用的都是__str__# 而repr(obj)和%r格式化字符串,都会调用__repr__# 如果str不存在,repr存在# 那么print(obj),字符串格式化format,%s,%r 和repr(obj)都调用__repr__# 如果str存在,repr不存在# 那么print(obj)和使用字符串格式化format,%s这两种方式 调用的都是__str__# repr(obj)和%r格式化字符串 都会打印出内存地址,入最上例# 打印对象 先走自己的str,如果没有,走父类的,如果除了object之外的所有父类都没有str# 再回来,找自己的repr,如果自己没有,再找父类的,理论上来说,最好还是使用repr
3、
__call__:对象() 自动触发__call__中的内容__call__方法提供给对象可以被执行的能力,就像函数那样拥有
__call__方法的对象,使用callable可以得到True的结果,可以使用()执行,执行时,可以传入参数,也可以返回值。所以我们可以使用__call__方法来实现实例化对象作为装饰器# 检查一个函数的输入参数个数, 如果调用此函数时提供的参数个数不符合预定义,则无法调用。
# 单纯函数版本装饰器def args_num_require(require_num):
def outer(func):
def inner(*args, **kw):
if len(args) != require_num:
print('函数参数个数不符合预定义,无法执行函数')
return None
return func(*args, **kw)
return inner
return outer
(2)
def show(*args):
print('show函数成功执行!')
show(1) # 函数参数个数不符合预定义,无法执行函数
show(1,2) # show函数成功执行!
show(1,2,3) # 函数参数个数不符合预定义,无法执行函数
# 实例对象版本装饰器class Checker:
def __init__(self, require_num):
self.require_num = require_num
def __call__(self, func):
self.func = func
def inner(*args, **kw):
if len(args) != self.require_num:
print('函数参数个数不符合预定义,无法执行函数')
return None
return self.func(*args, **kw)
return inner
(2)
def show(*args):
print('show函数成功执行!')
show(1) # 函数参数个数不符合预定义,无法执行函数
show(1,2) # show函数成功执行!
show(1,2,3) # 函数参数个数不符合预定义,无法执行函数
#补充:class A:
def call(self):
print('in call')
def __call__(self, *args, **kwargs):
print('in __call__')
A()() # in __call__
obj.call() #in call
4、
__del__析构方法,python中的清洁阿姨,周期性__del__用于当对象的引用计数为0时自动调用。__del__一般出现在两个地方:1、手工使用del减少对象引用计数至0,被垃圾回收处理时调用。2、程序结束时自动调用。__del__一般用于需要声明在对象被删除前需要处理的资源回收操作,比如文件的关闭。xxxxxxxxxx
import time
class A:
def __init__(self,name,age):
self.name = name
self.age = age
def __del__(self):
# 只和del obj语法有关系,在执行del obj之前会来执行一下__del__中的内容print('执行我啦')
a = A('alex',84)
print(a.name)
print(a.age)
# del a # 这个变量已经没了 手动删除,再打印a,报错#time.sleep(1)# 在所有的代码都执行完毕之后,所有的值都会被python解释器回收
# 手工调用del 可以将对象引用计数减一,如果减到0,将会触发垃圾回收class Student:
def __del__(self):
print('调用对象的del方法,此方法将会回收此对象内存地址')
stu = Student()
print(stu) # <__main__.Student object at 0x002FEB70>
del stu # 调用对象的__del__方法回收此对象内存地址
print(stu) # 报错
# 程序自动调用__del__函数class Student:
def __del__(self):
print('调用对象的del方法,此方法将会回收此对象内存地址')
stu = Student() # 程序直接结束,也会调用对象的__del__方法回收地址,打印里面的内容‘调用对象……’
#总结:# python解释器清理内存:# 1.我们主动删除 del obj# 2.python解释器周期性删除# 3.在程序结束之前 所有的内容都需要清空#补充:再涉及文件操作时,还是要主动关闭文件句柄。
class A:
def __init__(self,path):
self.f = open(path,'w')
def __del__(self):
'''归还一些操作系统的资源的时候使用''''''包括文件\网络\数据库连接'''self.f.close()
a = A('userinfo')
5、
__getitem__、__setitem__、__delitem__: 给列表、元组、等有序类型的索引使用重写此系列方法可以模拟对象成列表或者是字典,即可以使用
key-value的类型。xxxxxxxxxx
class StudentManager:
li = []dic = {}
def add(self, obj):
self.li.append(obj)
self.dic[obj.name] = obj
def __getitem__(self, item):
if isinstance(item, int):
# 通过下标得到对象return self.li[item]
elif isinstance(item, slice):
# 通过切片得到一串对象start = item.start
stop = item.stop
return [student for student in self.li[start:stop]]
elif isinstance(item, str):
# 通过名字得到对象return self.dic.get(item, None)
else:# 给定的key类型错误raise TypeError('你输入的key类型错误!')
class Student:
manager = StudentManager()
def __init__(self, name):
self.name = name
self.manager.add(self) # 将自己的名字传入
# def __str__(self):# return f'学生: {self.name}'
# __repr__ = __str__ #没有这个会在切片时 打印两个地址def __repr__(self): # 备胎上 ,如果没有上面的话就用这个 替补,或则直接使用这个
return f'学生: {self.name}'
stu1 = Student('小明')
stu2 = Student('大白')
stu3 = Student('小红')
stu4 = Student('胖虎')
# 当做列表使用print(Student.manager[0]) # 学生: 小明
print(Student.manager[-1]) # 学生: 胖虎
print(Student.manager[1:3]) # [学生: 大白, 学生: 小红]
# 当做字典使用print(Student.manager['胖虎']) # 学生: 胖虎
6、
with:的上下文处理__enter__、__exit__这两个方法的重写可以让我们对一个对象使用with方法来处理工作前的准备,以及工作之后的清扫行为。用好了可以提升我们的代码质量xxxxxxxxxx
#1、运用在数据库中class MySQL:
def connect(self):
print('启动数据库连接,申请系统资源')
def execute(self):
print('执行sql命令,操作数据')
def finish(self):
print('数据库连接关闭,清理系统资源')
def __enter__(self): # with的时候触发,并赋给as变量,必须要有enter
self.connect()
return self # 将实例化的空间返回,给as后面的变量
def __exit__(self, exc_type, exc_val, exc_tb): # 离开with语句块时触发
self.finish()
with MySQL() as mysql: # 首先实例化Mysql,mysql接受作为对象
mysql.execute()
# 结果:# 启动数据库连接,申请系统资源# 执行sql命令,操作数据# 数据库连接关闭,清理系统资源
#2、最简单的class File:
def __enter__(self):
print('start')
def __exit__(self, exc_type, exc_val, exc_tb):
print('exit')
with File():
print('wahaha')
#执行顺序:start wahaha exit
#3、手写一个文件操作类:import pickle
class myopen:
def __init__(self,path,mode='r'):
self.path = path
self.mode = mode
def __enter__(self):
print('start')
self.f = open(self.path,mode=self.mode) #打开一个文件句柄
return self.f
def __exit__(self, exc_type, exc_val, exc_tb):
self.f.close()
print('exit')
with myopen('userinfo','a') as f: #初始化myopen,返回的实例化结果给f
f.write('hello,world')
#4、添加功能class MypickleDump:
def __init__(self,path,mode = 'ab'):
self.path = path
self.mode = mode
def __enter__(self):
self.f = open(self.path,self.mode)
return self
def dump(self,obj):
pickle.dump(obj,self.f)
def __exit__(self, exc_type, exc_val, exc_tb):
self.f.close()
with MypickleDump('pickle_file') as pickle_obj:
pickle_obj.dump({1,2,3})
pickle_obj.dump({1,2,3})
pickle_obj.dump({1,2,3})
#另写一个加载类class MypickelLoad:
def __init__(self,path,mode='rb'):
self.path = path
self.mode = mode
def __enter__(self):
self.f = open(self.path,self.mode)
return self
def loaditer(self):
while True:
try:ret = pickle.load(self.f)
yield ret #做成生成器
except EOFError:
break
def __exit__(self, exc_type, exc_val, exc_tb):
self.f.close()
with MypickelLoad('pickle_file') as mypic:
for obj in mypic.loaditer():
print(obj)
#合并两个类with MypickleDump('pickle_file') as obj:
obj.dump({1,2,3,4})
with MypickelLoad('pickle_file') as obj:
for i in obj.loaditer():
print(i)
二、了解的内置方法
1、
__doc__表述类的描述信息2、
__module__ 和 __class__前者显示当前操作对象在哪个模块xxxxxxxxxx
from lib.aa import C #这里假如有这么个模块
obj = C()
print obj.__module__ # 输出 lib.aa,即:输出模块
print obj.__class__ # 输出 lib.aa.C,即:输出类
3、
__dict__类或对象中的所有成员xxxxxxxxxx
class Province:
country = 'China'
def __init__(self, name, count):
self.name = name
self.count = count
def func(self, *args, **kwargs):
print 'func'
# 获取类的成员,即:静态字段、方法、print(Province.__dict__)
# 输出:{'country': 'China', '__module__': '__main__', 'func': <function func at 0x10be30f50>, '__init__': <function __init__ at 0x10be30ed8>, '__doc__': None}obj1 = Province('HeBei',10000)
print(obj1.__dict__)
# 获取 对象obj1 的成员# 输出:{'count': 10000, 'name': 'HeBei'}obj2 = Province('HeNan', 3888)
print(obj2.__dict__)
# 获取 对象obj1 的成员# 输出:{'count': 3888, 'name': 'HeNan'}
4、
__getslice__、__setslice__、__delslice__:给切片使用5、
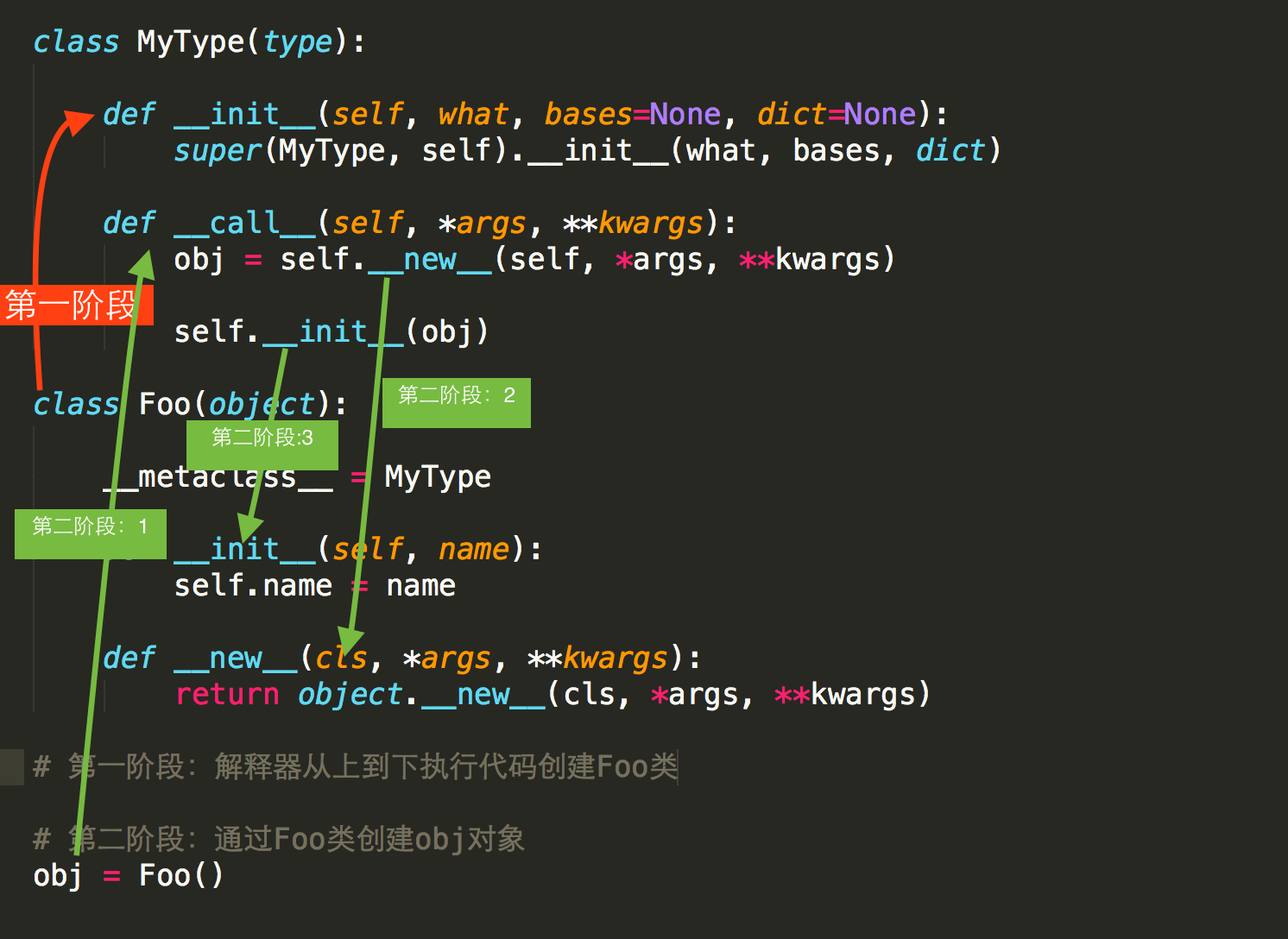
__metaclass__:其用来表示该类由 谁 来实例化创建- 类默认是由 type 类实例化产生,type类中如何实现的创建类?类又是如何创建对象?
- 类中有一个属性
__metaclass__,其用来表示该类由 谁 来实例化创建,所以,我们可以为__metaclass__设置一个type类的派生类,从而查看 类 创建的过程。也就是元类。