Eigen向量化内存对齐/Eigen的SSE兼容,内存分配/EIGEN_MAKE_ALIGNED_OPERATOR_NEW
1.总结
对于基本数据类型和自定义类型,我们需要用预编译指令来保证栈内存的对齐,用重写operator new的方式保证堆内存对齐。对于嵌套的自定义类型,申请栈内存时会自动保证其内部数据类型的对齐,而申请堆内存时仍然需要重写operator new。
有一种特殊情况本文并未提到,如果使用std::vector ,需要传入自定义内存申请器,即std::vector<Vector4d, AlignedAllocator>,其中AlignedAllocator是我们自定义的内存申请器。这是因为,std::vector中使用了动态申请的空间保存数据,因此默认的operator new是无法让其内存对齐的。在无法重写std::vector类的operator new的情况下,标准库提供了自定义内存申请器的机制,让用户可以以自己的方式申请内存。具体做法本文就不再展开了,理解了前面的内容,这个问题应该很容易解决。
2. EIGEN_MAKE_ALIGNED_OPERATOR_NEW
SSE支持128bit的多指令并行,但是有个要求是处理的对象必须要在内存地址以16byte整数倍的地方开始。不过这些细节Eigen在做并行化的时候会自己处理。
但是,如果把一些Eigen的结构放到std的容器里面,比如vector,map。这些容器会把一个一个的Eigen结构在内存里面连续排放。
可以想象,如果这些Eigen的结构本身不是16byte大小,一连续排放后,自然有很多对象就不是在16byte整数倍的地方开始了。
Eigen提供了两种方法来解决:
使用特别的内存分配对象
std::map<int, Eigen::Vector4f, std::less<int>, Eigen::aligned_allocator<std::pair<const int, Eigen::Vector4f> > >
std::vector<Eigen::Vector4f,Eigen::aligned_allocator<Eigen::Vector4f> >
针对vector的时候,还需要额外添加头文件#include<Eigen/StdVector>
在对象定义的时候,使用特殊的宏
EIGEN_DEFINE_STL_VECTOR_SPECIALIZATION(Matrix2d)
注意必须在所有Eigen对象出现前使用这个宏
有这个问题的Eigen结构包括:
Eigen::Vector2d
Eigen::Vector4d
Eigen::Vector4f
Eigen::Matrix2d
Eigen::Matrix2f
Eigen::Matrix4d
Eigen::Matrix4f
Eigen::Affine3d
Eigen::Affine3f
Eigen::Quaterniond
Eigen::Quaternionf
另外如果上面提到的这些结构作为一个对象的成员,比如:
class Foo
{...Eigen::Vector2d v;...
};
...
Foo *foo = new Foo;
这个时候需要在类定义里面使用另外一个宏:
class Foo
{...Eigen::Vector2d v;...
public:EIGEN_MAKE_ALIGNED_OPERATOR_NEW
};
...
Foo *foo = new Foo;
原因分析:对象内部的内存分配是相对与对象的地址的。如果对象的地址不是16byte对齐的,里面的成员并不会知道这个信息,所以没有办法分配16byte对其的地址。解决办法就是强制让分配对象的时候,就给一个16byte对齐的地址。
EIGEN_MAKE_ALIGNED_OPERATOR_NEW会重载new函数。
3. problem solver record
用valgrind检查内存问题,发现种种线索都指向g2o。g2o是一个SLAM后端优化库,里面封装了大量SLAM相关的优化算法,内部使用了Eigen进行矩阵运算。
关闭-march=native这个编译选项后就能正常运行,而这个编译选项其实是告诉编译器当前的处理器支持哪些SIMD指令集,Eigen中又恰好使用了SSE、AVX等指令集进行向量化加速。此时,机智的我发现Eigen文档中有一章叫做Alignment issues,里面提到了某些情况下Eigen对象可能没有内存对齐,从而导致程序崩溃。
现在,证据到齐,基本可以确定我遇到的真实问题了:编译安装g2o时,默认没有使用-march=native,因此里面的Eigen代码没有使用向量化加速,所以它们并没有内存对齐。而在我的程序中,启用了向量化加速,所有的Eigen对象都是内存对齐的。两个程序链接起来之后,g2o中未对齐的Eigen对象一旦传递到我的代码中,向量化运算的指令就会触发异常。解决方案很简单,要么都用-march=native,要么都不用。
4. 这就来谈谈向量化和内存对齐里面的门道。
什么是向量化运算?
向量化运算就是用SSE、AVX等SIMD(Single Instruction Multiple Data)指令集,实现一条指令对多个操作数的运算,从而提高代码的吞吐量,实现加速效果。SSE是一个系列,包括从最初的SSE到最新的SSE4.2,支持同时操作16 bytes的数据,即4个float或者2个double。AVX也是一个系列,它是SSE的升级版,支持同时操作32 bytes的数据,即8个float或者4个double。
但向量化运算是有前提的,那就是内存对齐。SSE的操作数,必须16 bytes对齐,而AVX的操作数,必须32 bytes对齐。也就是说,如果我们有4个float数,必须把它们放在连续的且首地址为16的倍数的内存空间中,才能调用SSE的指令进行运算。
A Simple Example
为了给没接触过向量化编程的同学一些直观的感受,我写了一个简单的示例程序:
#include <immintrin.h>
#include <iostream>int main() {double input1[4] = {1, 1, 1, 1};double input2[4] = {1, 2, 3, 4};double result[4];std::cout << "address of input1: " << input1 << std::endl;std::cout << "address of input2: " << input2 << std::endl;__m256d a = _mm256_load_pd(input1);__m256d b = _mm256_load_pd(input2);__m256d c = _mm256_add_pd(a, b);_mm256_store_pd(result, c);std::cout << result[0] << " " << result[1] << " " << result[2] << " " << result[3] << std::endl;return 0;
}
这段代码使用AVX中的向量化加法指令,同时计算4对double的和。这4对数保存在input1和input2中。 _mm256_load_pd指令用来加载操作数,_mm256_add_pd指令进行向量化运算,最后, _mm256_store_pd指令读取运算结果到result中。可惜的是,程序运行到第一个_mm256_load_pd处就崩溃了。崩溃的原因正是因为输入变量没有内存对齐。我特意打印出了两个输入变量的地址,结果如下
address of input1: 0x7ffeef431ef0
address of input2: 0x7ffeef431f10
上一节提到了AVX要求32字节对齐,我们可以把这两个输入变量的地址除以32,看是否能够整除。结果发现0x7ffeef431ef0和 0x7ffeef431f10都不能整除。当然,其实直接看倒数第二位是否是偶数即可,是偶数就可以被32整除,是奇数则不能被32整除。
如何让输入变量内存对齐呢?我们知道,对于局部变量来说,它们的内存地址是在编译期确定的,也就是由编译器决定。所以我们只需要告诉编译器,给input1和input2申请空间时请让首地址32字节对齐,这需要通过预编译指令来实现。不同编译器的预编译指令是不一样的,比如gcc的语法为__attribute__((aligned(32))),MSVC的语法为 __declspec(align(32)) 。以gcc语法为例,做少量修改,就可以得到正确的代码
#include <immintrin.h>
#include <iostream>int main() {__attribute__ ((aligned (32))) double input1[4] = {1, 1, 1, 1};__attribute__ ((aligned (32))) double input2[4] = {1, 2, 3, 4};__attribute__ ((aligned (32))) double result[4];std::cout << "address of input1: " << input1 << std::endl;std::cout << "address of input2: " << input2 << std::endl;__m256d a = _mm256_load_pd(input1);__m256d b = _mm256_load_pd(input2);__m256d c = _mm256_add_pd(a, b);_mm256_store_pd(result, c);std::cout << result[0] << " " << result[1] << " " << result[2] << " " << result[3] << std::endl;return 0;
}
输出结果为
address of input1: 0x7ffc5ca2e640
address of input2: 0x7ffc5ca2e660
2 3 4 5
可以看到,这次的两个地址都是32的倍数,而且最终的运算结果也完全正确。
虽然上面的代码正确实现了向量化运算,但实现方式未免过于粗糙。每个变量声明前面都加上一长串预编译指令看起来就不舒服。我们尝试重构一下这段代码。
5. 重构
首先,最容易想到的是,把内存对齐的double数组声明成一种自定义数据类型,如下所示
using aligned_double4 = __attribute__ ((aligned (32))) double[4];aligned_double4 input1 = {1, 1, 1, 1};aligned_double4 input2 = {1, 2, 3, 4};aligned_double4 result;
这样看起来清爽多了。更进一步,如果4个double是一种经常使用的数据类型的话,我们就可以把它封装为一个Vector4d类,这样,用户就完全看不到内存对齐的具体实现了,像下面这样。
#include <immintrin.h>
#include <iostream>class Vector4d {using aligned_double4 = __attribute__ ((aligned (32))) double[4];
public:Vector4d() {}Vector4d(double d1, double d2, double d3, double d4) {data[0] = d1;data[1] = d2;data[2] = d3;data[3] = d4;}aligned_double4 data;
};Vector4d operator+ (const Vector4d& v1, const Vector4d& v2) {__m256d data1 = _mm256_load_pd(v1.data);__m256d data2 = _mm256_load_pd(v2.data);__m256d data3 = _mm256_add_pd(data1, data2);Vector4d result;_mm256_store_pd(result.data, data3);return result;
}std::ostream& operator<< (std::ostream& o, const Vector4d& v) {o << "(" << v.data[0] << ", " << v.data[1] << ", " << v.data[2] << ", " << v.data[3] << ")";return o;
}int main() {Vector4d input1 = {1, 1, 1, 1};Vector4d input2 = {1, 2, 3, 4};Vector4d result = input1 + input2;std::cout << result << std::endl;return 0;
}
这段代码实现了Vector4d类,并把向量化运算放在了operator+中,主函数变得非常简单。
但不要高兴得太早,这个Vector4d其实有着严重的漏洞,如果我们动态创建对象,程序仍然会崩溃,比如这段代码
int main() {Vector4d* input1 = new Vector4d{1, 1, 1, 1};Vector4d* input2 = new Vector4d{1, 2, 3, 4};std::cout << "address of input1: " << input1->data << std::endl;std::cout << "address of input2: " << input2->data << std::endl;Vector4d result = *input1 + *input2;std::cout << result << std::endl;delete input1;delete input2;return 0;
}
崩溃前的输出为
address of input1: 0x1ceae70
address of input2: 0x1ceaea0
很诡异吧,似乎刚才我们设置的内存对齐都失效了,这两个输入变量的内存首地址又不是32的倍数了。
6.Heap vs Stack
问题的根源在于不同的对象创建方式。直接声明的对象是存储在栈上的,其内存地址由编译器在编译时确定,因此预编译指令会生效。但用new动态创建的对象则存储在堆中,其地址在运行时确定。C++的运行时库并不会关心预编译指令声明的对齐方式,我们需要更强有力的手段来确保内存对齐。
C++提供的new关键字是个好东西,它避免了C语言中丑陋的malloc操作,但同时也隐藏了实现细节。如果我们翻看C++官方文档,可以发现new Vector4d实际上做了两件事情,第一步申请sizeof(Vector4d)大小的空间,第二步调用Vector4d的构造函数。要想实现内存对齐,我们必须修改第一步申请空间的方式才行。好在第一步其实调用了operator new这个函数,我们只需要重写这个函数,就可以实现自定义的内存申请,下面是添加了该函数后的Vector4d类。
class Vector4d {using aligned_double4 = __attribute__ ((aligned (32))) double[4];
public:Vector4d() {}Vector4d(double d1, double d2, double d3, double d4) {data[0] = d1;data[1] = d2;data[2] = d3;data[3] = d4;}void* operator new (std::size_t count) {void* original = ::operator new(count + 32);void* aligned = reinterpret_cast<void*>((reinterpret_cast<size_t>(original) & ~size_t(32 - 1)) + 32);*(reinterpret_cast<void**>(aligned) - 1) = original;return aligned;}void operator delete (void* ptr) {::operator delete(*(reinterpret_cast<void**>(ptr) - 1));}aligned_double4 data;
};
operator new的实现还是有些技巧的,我们来详细解释一下。 首先,根据C++标准的规定,operator new的参数count是要开辟的空间的大小。 为了保证一定可以得到count大小且32字节对齐的内存空间,我们把实际申请的内存空间扩大到count + 32。可以想象,在这count + 32字节空间中, 一定存在首地址为32的倍数的连续count字节的空间。 所以,第二行代码,我们通过对申请到的原始地址original做一些位运算,先找到比original小且是32的倍数的地址,然后加上32,就得到了我们想要的对齐后的地址,记作aligned。 接下来,第三行代码很关键,它把原始地址的值保存在了aligned地址的前一个位置中,之所以要这样做,是因为我们还需要自定义释放内存的函数operator delete。毕竟aligned地址并非真实申请到的地址,所以在该地址上调用默认的delete 是会出错的。可以看到,我们在代码中也定义了一个operator delete,传入的参数正是前面operator new返回的对齐的地址。这时候,保存在aligned前一个位置的原始地址就非常有用了,我们只需要把它取出来,然后用标准的delete释放该内存即可。
为了方便大家理解这段代码,有几个细节需要特地强调一下。::operator new中的::代表全局命名空间,因此可以调用到标准的operator new。第三行需要先把aligned强制转换为void类型,这是因为我们希望在aligned的前一个位置保存一个void*类型的地址,既然保存的元素是地址,那么该位置对应的地址就是地址的地址,也就是void。
这是一个不大不小的trick,C++的很多内存管理方面的处理经常会有这样的操作。但不知道细心的你是否发现了这里的一个问题:reinterpret_cast<void**>(aligned) - 1这个地址是否一定在我们申请的空间中呢?换句话说, 它是否一定大于original呢? 之所以存在这个质疑,是因为这里的-1其实是对指针减一。要知道,在64位计算机中,指针的长度是8字节,所以这里得到的地址其实是reinterpret_cast<size_t>(aligned) - 8。看出这里的区别了吧,对指针减1相当于对地址的值减8。所以仔细想想,如果original到aligned的距离小于8字节的话,这段代码就会对申请的空间以外的内存赋值,可怕吧。
其实没什么可怕的,为什么我敢这样讲,因为Eigen就是这样实现的。这样做依赖于现代编译器的一个共识:所有的内存分配都默认16字节对齐。这个事实可以解释很多问题,首先,永远不用担心original到aligned的距离会不会小于8了,它会稳定在16,这足够保存一个指针。其次,为什么我们用AVX指令集举例,而不是SSE?因为SSE要求16字节对齐,而现代编译器已经默认16字节对齐了,那这篇文章就没办法展开了。 最后,为什么我的代码在NVIDIA TX2上运行正常而在服务器上挂掉了?因为TX2中是ARM处理器,里面的向量化指令集NEON也只要求16字节对齐。
噩梦又现!
如果你以为到这里就圆满结束了,那可是大错特错。还有个天坑没展示给大家,下面的代码中,我的自定义类Point包含了一个Vector4d的成员,这时候…
class Point {
public:Point(Vector4d position) : position(position) {}Vector4d position;
};int main() {Vector4d* input1 = new Vector4d{1, 1, 1, 1};Vector4d* input2 = new Vector4d{1, 2, 3, 4};Point* point1 = new Point{*input1};Point* point2 = new Point{*input2};std::cout << "address of point1: " << point1->position.data << std::endl;std::cout << "address of point2: " << point2->position.data << std::endl;Vector4d result = point1->position + point2->position;std::cout << result << std::endl;delete input1;delete input2;delete point1;delete point2;return 0;
}
输出的地址又不再是32的倍数了,程序戛然而止。我们分析一下为什么会这样。在主函数中,new Point动态创建了一个Point对象。前面提到过,这个过程分为两步,第一步申请Point对象所需的空间,即sizeof(Point)大小的空间,第二步调用Point的构造函数。我们寄希望于第一步申请到的空间恰好让内部的position对象对齐,这是不现实的。因为整个过程中并不会调用Vector4d的operator new,调用的只有Point的operator new,而这个函数我们并没有重写。
可惜的是,此处并没有足够优雅的解决方案,唯一的方案是在Point类中也添加自定义operator new,这就需要用户的协助,类库的作者已经无能为力了。 不过类库的作者能做的,是尽量让用户更方便地添加operator new,比如封装为一个宏定义,用户只需要在Point类中添加一句宏即可。最后,完整的代码如下。
#include <immintrin.h>
#include <iostream>#define ALIGNED_OPERATOR_NEW void* operator new (std::size_t count) { void* original = ::operator new(count + 32); void* aligned = reinterpret_cast<void*>((reinterpret_cast<size_t>(original) & ~size_t(32 - 1)) + 32); *(reinterpret_cast<void**>(aligned) - 1) = original; return aligned;} void operator delete (void* ptr) { ::operator delete(*(reinterpret_cast<void**>(ptr) - 1)); }class Vector4d {using aligned_double4 = __attribute__ ((aligned (32))) double[4];
public:Vector4d() {}Vector4d(double d1, double d2, double d3, double d4) {data[0] = d1;data[1] = d2;data[2] = d3;data[3] = d4;}ALIGNED_OPERATOR_NEWaligned_double4 data;
};Vector4d operator+ (const Vector4d& v1, const Vector4d& v2) {__m256d data1 = _mm256_load_pd(v1.data);__m256d data2 = _mm256_load_pd(v2.data);__m256d data3 = _mm256_add_pd(data1, data2);Vector4d result;_mm256_store_pd(result.data, data3);return result;
}std::ostream& operator<< (std::ostream& o, const Vector4d& v) {o << "(" << v.data[0] << ", " << v.data[1] << ", " << v.data[2] << ", " << v.data[3] << ")";return o;
}class Point {
public:Point(Vector4d position) : position(position) {}ALIGNED_OPERATOR_NEWVector4d position;
};int main() {Vector4d* input1 = new Vector4d{1, 1, 1, 1};Vector4d* input2 = new Vector4d{1, 2, 3, 4};Point* point1 = new Point{*input1};Point* point2 = new Point{*input2};std::cout << "address of point1: " << point1->position.data << std::endl;std::cout << "address of point2: " << point2->position.data << std::endl;Vector4d result = point1->position + point2->position;std::cout << result << std::endl;delete input1;delete input2;delete point1;delete point2;return 0;
}
这段代码中,宏定义ALIGNED_OPERATOR_NEW 包含了operator new和operator delete,它们对所有需要内存对齐的类都适用。因此,无论是需要内存对齐的类,还是包含了这些类的类,都需要添加这个宏。
7.再谈Eigen
在Eigen官方文档中有这么一页内容
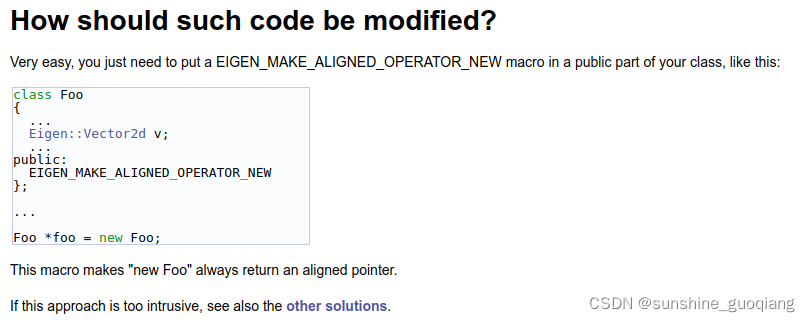
有没有觉得似曾相识?Eigen对该问题的解决方案与我们不谋而合。这当然不是巧合,事实上,本文的灵感正是来源于Eigen。但Eigen只告诉了我们应该怎么做,没有详细讲解其原理。本文则从问题的提出,到具体的解决方案,一一剖析,希望可以给大家一些更深的理解。
8.参考资料
https://blog.csdn.net/ziliwangmoe/article/details/87563498
Eigen Memory Issues ethz-asl/eigen_catkin wiki
cmake怎么编译 eigen c++_从Eigen向量化谈内存对齐
相关文章:

c/c++文件遍历
//CBrowseDir.h#pragma once#include <stdlib.h> #include <direct.h> #include <string.h> #include <io.h> #include <stdio.h> #include <iostream> using namespace std; class CBrowseDir { protected: //存放初始目录的绝对…

优化应用启动时的体验
2019独角兽企业重金招聘Python工程师标准>>> 对于应用的启动时间,只能是尽量的避免一些耗时的、非必要性的操作在主线程中,这样相对减少一部分启动的耗时,同时在等待第一帧显示的时间里,可以加入一些配置用来增加用户体…
系列四、SpringMVC响应数据和结果视图
2019独角兽企业重金招聘Python工程师标准>>> 项目结构如下 一、返回值分类 一 返回字符串 Controller方法返回字符串可以指定逻辑视图的名称,根据视图解析器为物理视图的地址,根据字符串最后跳转到对应jsp页面 第一步、导入依赖坐标文件、配置…
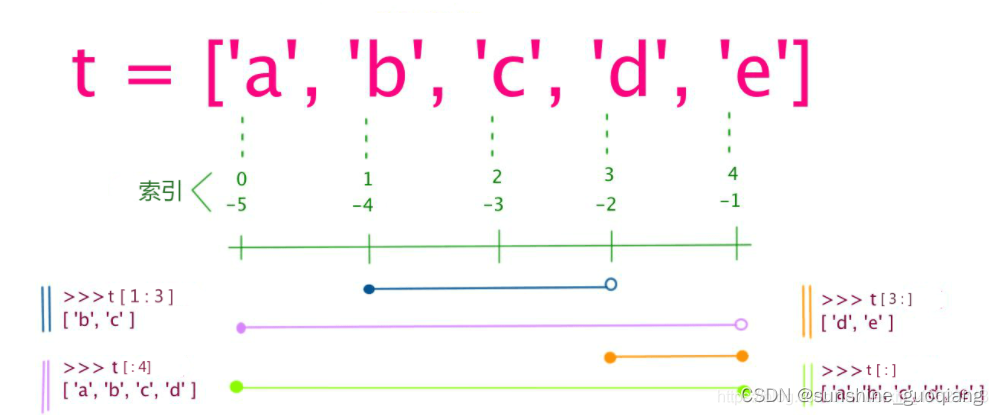
numpy数组切片:一维/二维/数组
文章目录numpy数组切片操作一维数组(冒号:)1、一个参数:a[i]2、两个参数:ba[i:j]3、三个参数:格式b a[i:j:s]4、例子二维数组(逗号,)取元素 X[n0,n1]切片 X[s0:e0,s1:e1…
行列式求值、矩阵求逆
#include <iostream> #include <string> #include <assert.h> #include <malloc.h> #include <iostream> #include <stdlib.h> #include <memory.h> #include <time.h>using namespace std;//动态分配大小位size的一维数组 te…
IP 地址子网划分
1.你所选择的子网掩码将会产生多少个子网2的x次方-2(x代表网络位借用主机的位数,即2进制为1的部分,现在的网络中,已经不需要-2,已经可以全部使用,不过需要加上相应的配置命令,例如CISCO路由器需要加上ip su…

git rebase 和 git merger
& git merge 在上图中,每一个绿框均代表一个commit。除了c1,每一个commit都有一条有向边指向它在当前branch当中的上一个commit。 图中的项目,在c2之后就开了另外一个branch,名为experiment。在此之后,master下的修…
matplotlib绘制三维轨迹图
1. 绘制基本三维曲线 # import necessary module from mpl_toolkits.mplot3d import axes3d import matplotlib.pyplot as plt import numpy as np# load data from file # you can replace this using with open data1 np.loadtxt("./pos.txt") # print (data1) n…
求一个矩阵的最大子矩阵
#include <iostream> #include <string> #include <assert.h> #include <malloc.h> #include <iostream> #include <stdlib.h> #include <memory.h> #include <time.h> #include <limits.h>using namespace std;//动态分…
tcpdump抓包文件提取http附加资源
2019独角兽企业重金招聘Python工程师标准>>> 前面几篇文章铺垫了一大批的协议讲解,主要是为了提取pcap文件中http协议附加的资源。 1、解析pcap文件,分为文件格式头,后面就是数据包头和包数据了 2、分析每个包数据,数据…

smobiler介绍(二)
类似开发WinForm的方式,使用C#开发Android和IOS的移动应用?听起来感觉不可思议,那么Smobiler平台到底是如何实现的呢,这里给大家介绍一下。客户端Smobiler分为两种客户端,一种是开发版,一种是打包版开发版&…
Matplotlib基本用法
Matplotlib Matplotlib 是Python中类似 MATLAB 的绘图工具,熟悉 MATLAB 也可以很快的上手 Matplotlib。 1. 认识Matploblib 1.1 Figure 在任何绘图之前,我们需要一个Figure对象,可以理解成我们需要一张画板才能开始绘图。 import matplot…
HDU1201 18岁生日【日期计算】
18岁生日 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submission(s): 32851 Accepted Submission(s): 10649Problem DescriptionGardon的18岁生日就要到了,他当然很开心,可是他突然想到一个问题&am…
TypeScript 从听说到入门(上篇)
我为什么会这样念念又不忘 / 你用什么牌的箭刺穿我心脏 我也久经沙场 / 戎马生涯 / 依然 / 被一箭刺伤 ——李荣浩《念念又不忘》 接下来我会分上、下两篇文章介绍 TypeScript。 我也是 TypeScript 初学者,这两篇文章是我的学习笔记,来源于一个系列的免费…

SLAM前端中的视觉里程计和回环检测
1. 通常的惯例是把 VSLAM 分为前端和后端。前端为视觉里程计和回环检测,相当于是对图像数据进行关联;后端是对前端输出的结果进行优化,利用滤波或非线性优化理论,得到最优的位姿估计和全局一致性地图。 1 前端:图像数…

粗心导致的bug
不管是调试程序还是直接看输出i都为2,下面是运行时输出的: 用vs2010以前遇到更奇葩的事,这次用vs2013也是遇到奇葩,taskNumber值为2一定,下面两个循环体,每个循环体各执行一次,程序输出i 2真是…

gearman中任务的优先级和返回状态
gearman中任务的优先级和返回状态 一、任务的优先级 同步阻塞调用,等待返回结果 doLow:最低优先 doNomal:正常优先级 doHigh:最优先执行 异步派发任务,不等待返回结果,返回任务句柄,通过该句柄可获取任务运行状态信息 doLowBackgr…
VMware学习使用笔记
本人在学习基础上,结合实际项目实现总结的笔记。以下内容都是基于VMware vSphere 6.7的官方文档中vSAN的规划和部署而来,网址https://docs.vmware.com/cn/VMware-vSphere/index.html。 对于ESXi系统 对于内存不足512G,可以从USB或Micro SD引导…
【原】Java学习笔记020 - 面向对象
1 package cn.temptation;2 3 public class Sample01 {4 public static void main(String[] args) {5 // 成员方法的参数列表:6 // 1、参数列表中的数据类型是值类型7 // 2、参数列表中的数据类型是引用类型8 // A:…
win32 wmi编程获取系统信息
//GetSysInfo.h#pragma once#include <afxtempl.h>class GetSysInfo { public:GetSysInfo(void);~GetSysInfo(void);public: /********获取操作系统版本,Service pack版本、系统类型************/ void GetOSVersion(CString &strOSVersion,CString &…
cmake 注意事项
1. add_subdirectory()调用 CMake将在每次add_subdirectory()调用时创建一个新的变量作用域,因此这个参数最好的用法是放在cmaklists的最后使用,这样的话创建的新的变量的作用范围与内存的变化就不会影响到后面的变量的使用。 查看并打印在cmake里面定义的宏在&am…

Jmeter 使用自定义变量
有些情况下比如发起测试时URL的主机名和端口需要在采样器中出现多次,这样就有个问题,当测试的主机更改时, 我们需要修改主机名称,这时就需要修改多个地方,如果多的情况会有遗漏。如果我们在配置脚本的时候,…
Kubernetes1.5源码分析(二) apiServer之资源注册
源码版本 Kubernetes v1.5.0 简介 k8s里面有各种资源,如Pod、Service、RC、namespaces等资源,用户操作的其实也就是这一大堆资源。但这些资源并不是杂乱无章的,使用了GroupVersion的方式组织在一起。每一种资源都属于一个Group,而…
opencv3 视频稳像
OpneCV3.x中提供了专门应用于视频稳像技术的模块,该模块包含一系列用于全局运动图像估计的函数和类。结构体videostab::RansacParams实现了RANSAC算法,这个算法用来实现连续帧间的运动估计。videostab::MotionEstimatorBase是基类中所有全局运动估计方法…
perf+火焰图 = 性能分析利器
perf 1. perf安装 sudo apt install linux-tools-common检查是否安装好 perf如果出现 You may need to install the following packages for this specific kernel:推荐安装可以按照提示将推荐安装包全部安装好 sudo apt-get install linux-tools-对应版本-generic linux-c…
3- MySQL数据类型
MySQL表字段类型 MySQL数据表的表示一个二维表,由一个或多个数据列构成。 每个数据列都有它的特定类型,该类型决定了MySQL如何看待该列数据,并且约束列存放相应类型的数据。 MySQL中的列表有三种:数值类,字符串类和日期…
AddressSanitizer+cmake
1. AddressSanitizercmake(Linux) 编译指令: CXXFLAGS通常需要加上 -fsanitizeaddress -fno-omit-frame-pointer #打印函数调用路径 -fsanitize-recoveraddress #AddressSanitizer遇到错误时能够继续-fsanitizeaddress-fno-omit-frame-pointer-fsanitize-rec…
vibe前景提取改进算法
// improveVibeAlgorithm.h #ifndef IMPROVED_VIBE_ALGORITHM_H #define IMPROVED_VIBE_ALGORITHM_H#include <opencv2/opencv.hpp> using namespace std;#define WINSIZE 5 // Vibe改进算法, Barnich, Olivier & Droogenbroeck, Marc. (2009). // ViBE: A powerfu…
npm-debug.log文件出现原因
项目主目录下总是会出现这个文件,而且不止一个,原因是npm i 的时候,如果报错,就会增加一个此文件来显示报错信息,npm install的时候则不会出现。转载于:https://www.cnblogs.com/liuna/p/6558006.html

AutoFac Ioc依赖注入容器
本文原著:牛毅 原文路径 http://niuyi.github.io/blog/2012/04/06/autofac-by-unit-test/ 理解IOC容器请看下图: 没有使用IOC容器的情况下: 使用IOC容器的情况下: 去掉IOC容器的情况后: IOC容器又像一个插座,将电输送…