数据结构与算法:19 排序
19 排序
知识结构:
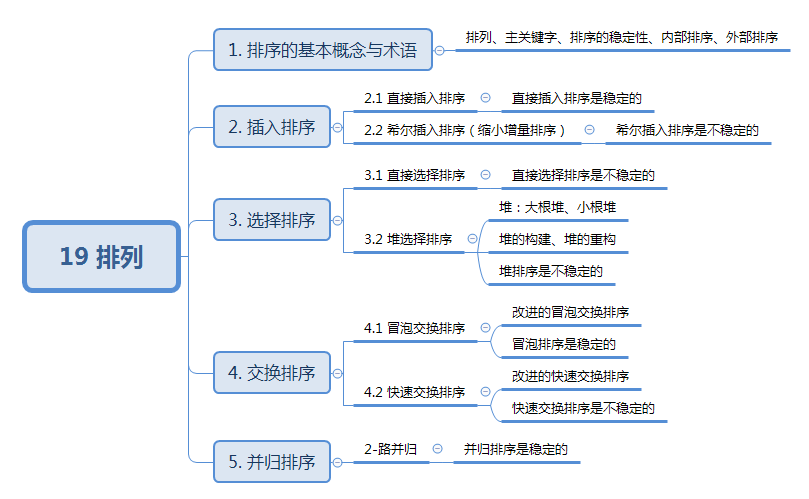
1. 排序的基本概念与术语
假设含有nnn个记录的序列为{r1,r2,⋯,rn}\lbrace r_1,r_2,\cdots,r_n \rbrace{r1,r2,⋯,rn},其相应的关键字分别为{k1,k2,⋯,kn}\lbrace k_1,k_2,\cdots,k_n \rbrace{k1,k2,⋯,kn},需确定 的一种排列1,2,⋯,n1,2,\cdots,n1,2,⋯,n,使其相应的关键字满足kp1≤kp2≤⋯≤kpnk_{p_1}\leq k_{p_2}\leq\cdots\leq k_{p_n}kp1≤kp2≤⋯≤kpn的关系,即使得序列成为一个按关键字有序的序列 ,这个样的操作就称为 排列。
能唯一标识某一记录的关键字称为 主关键字。
假设ki=kj(1≤i≤n,1≤j≤n,i≠j)k_i = k_j(1\leq i \leq n, 1\leq j\leq n,i\neq j)ki=kj(1≤i≤n,1≤j≤n,i=j),且在排序前的序列中rir_iri领先于rjr_jrj(即i<ji<ji<j )。如果排序后rir_iri仍领先于rjr_jrj,则称所用的排序方法是稳定的;反之,若可能使得排序后的序列中rjr_jrj领先于rir_iri,则称所用的排序方法是不稳定的。
例如:
- 待排序序列:20,30,20‾20,30,\overline{20}20,30,20
- 稳定的排序结果:20,20‾,3020,\overline{20},3020,20,30
- 不稳定的排序结果:20‾,20,30\overline{20},20,3020,20,30
内部排序:排序过程都在内存中进行的排序。
外部排序:排序过程需要在内存和外存之间不断交换数据的排序。
根据排序过程中借助的主要操作,我们把内排序分为:插入排序、选择排序、交换排序和并归排序。可以说,这些都是比较成熟的排序技术,已经被广泛地应用于许许多多的程序语言或数据库当中,甚至它们都已经封装了关于排序算法的实现代码。因此,我们学习这些排序算法的目的不是为了去现实排序算法,而是通过学习来提高我们编写算法的能力,以便于去解决更多复杂和灵活的应用性问题。
2. 插入排序
2.1 直接插入排序
将一个记录插入到已经排好序的有序表中,从而得到一个新的记录增1的有序表。
即:先将序列的第1个记录看成是一个有序的子序列,然后从第2个记录逐个进行插入,直至整个序列有序为止。
如:int[] Key = new int[]{45,34,78,12,34,32,29,64};
排序过程:
init0→[45],34‾,78,12,34,32,29,64init0\rightarrow [45],\overline{34},78,12,34,32,29,64init0→[45],34,78,12,34,32,29,64
step1→[34‾,45],78,12,34,32,29,64step1\rightarrow [\overline{34},45],78,12,34,32,29,64step1→[34,45],78,12,34,32,29,64
step2→[34‾,45,78],12,34,32,29,64step2\rightarrow [\overline{34},45,78],12,34,32,29,64step2→[34,45,78],12,34,32,29,64
step3→[12,34‾,45,78],34,32,29,64step3\rightarrow [12,\overline{34},45,78],34,32,29,64step3→[12,34,45,78],34,32,29,64
step4→[12,34‾,34,45,78],32,29,64step4\rightarrow [12,\overline{34},34,45,78],32,29,64step4→[12,34,34,45,78],32,29,64
step5→[12,32,34‾,34,45,78],29,64step5\rightarrow [12,32,\overline{34},34,45,78],29,64step5→[12,32,34,34,45,78],29,64
step6→[12,29,32,34‾,34,45,78],64step6\rightarrow [12,29,32,\overline{34},34,45,78],64step6→[12,29,32,34,34,45,78],64
result→[12,29,32,34‾,34,45,64,78]result\rightarrow [12,29,32,\overline{34},34,45,64,78]result→[12,29,32,34,34,45,64,78]
程序代码:
/// <summary>
/// 直接插入排序
/// </summary>
/// <typeparam name="T">需要排序记录的类型</typeparam>
/// <param name="array">需要排序的记录集合</param>
public static void StraightInsertSort<T>(T[] array) where T : IComparable<T>
{for (int i = 1; i < array.Length; i++){int j = i - 1;T current = array[i];while (j >= 0 && array[j].CompareTo(current) > 0){array[j + 1] = array[j];j--;}array[j + 1] = current;}
}
如果碰见一个和插入元素相等的,那么插入元素把想插入的元素放在相等元素的后面,所以,相等元素的前后顺序没有改变,从原无序序列出去的顺序就是排好序后的顺序,所以直接插入排序是稳定的。
2.2 希尔插入排序
希尔排序是1959年由D.L.Shell提出来的,相对直接插入排序有较大的改进。希尔插入排序又叫做缩小增量排序。
直接插入排序的效率在某些时候是很高的,比如我们的记录本身就是基本有序的,我们只需要少量的插入操作,就可以完成整个记录集的排序工作,此时直接插入排序很高效。还有就是记录数比较少时,直接插入的优势也比较明显。可问题在于,两个条件本身就过于苛刻,现实中记录少或者基本有序都属于特殊情况。
不过别着急,有条件当然是好,条件不存在,我们创造条件也是可以去做的。于是科学家希尔研究出了一种排序方法,对直接插入排序改进后可以增加效率。
思想:按待排序列下标的一定增量分组(如:增量序列t1,t2,⋯,tkt_1,t_2,\cdots,t_kt1,t2,⋯,tk,其中ti>tjt_i>t_jti>tj,tk=1t_k=1tk=1),将整个待排序列分割成若干子序列,分别进行直接插入排序,随着增量逐渐减少,所分组包含的记录越来越多,到增量值减至1时,整个记录集被分成一组(这时待排序列“基本有序”),再对全体记录进行直接插入排序,算法终止(对待排序列进行了kkk趟直接插入排序)。
我所理解Shell Insertion Sort最牛的地方是,让排序算法能够并行化。
希尔插入排序增量的取法:
delta1=[n2]=[102]=5delta1=\left[\frac{n}{2}\right] =\left[\frac{10}{2}\right]=5delta1=[2n]=[210]=5
delta2=[delta12]=[52]=2delta2=\left[\frac{delta1}{2}\right]=\left[\frac{5}{2}\right]=2delta2=[2delta1]=[25]=2
delta3=[delta22]=[22]=1delta3=\left[\frac{delta2}{2}\right]=\left[\frac{2}{2}\right]=1delta3=[2delta2]=[22]=1
即:先将要排序的一组记录按某个增量deltadeltadelta([n2]\left[\frac{n}{2}\right][2n] ,nnn为要排序数的个数)分成若干组子序列,每组中记录的下标相差deltadeltadelta。对每组中全部元素进行直接插入排序,然后在用一个较小的增量([delta2]\left[\frac{delta}{2}\right][2delta] )对它进行分组,在每组中再进行直接插入排序。继续不断缩小增量直至为1,最后使用直接插入排序完成排序。
如:int[] Key = new int[]{45,34,78,12,34,32,29,64};
排序过程:
d=4→45,34‾,78,12,34,32,29,64d=4\rightarrow 45,\overline{34},78,12,34,32,29,64d=4→45,34,78,12,34,32,29,64
d=2→34,32,29,12,45,34‾,78,64d=2\rightarrow 34,32,29,12,45,\overline{34},78,64d=2→34,32,29,12,45,34,78,64
d=1→29,12,34,32,45,34‾,78,64d=1\rightarrow 29,12,34,32,45,\overline{34},78,64d=1→29,12,34,32,45,34,78,64
result→12,29,32,34,34‾,45,64,78result\rightarrow 12,29,32,34,\overline{34},45,64,78result→12,29,32,34,34,45,64,78
程序代码:
private static void Shell<T>(int delta, T[] array) where T : IComparable<T>
{//带增量的直接插入排序for (int i = delta; i < array.Length; i++){int j = i - delta;T current = array[i];while (j >= 0 && array[j].CompareTo(current) > 0){array[j + delta] = array[j];j = j - delta;}array[j + delta] = current;}
}/// <summary>
/// 希尔插入排序
/// </summary>
/// <typeparam name="T">需要排序记录的类型</typeparam>
/// <param name="array">需要排序的记录集合</param>
public static void ShellInsertSort<T>(T[] array) where T : IComparable<T>
{for (int delta = array.Length/2; delta > 0; delta = delta/2){Shell(delta, array);}
}
希尔插入排序时效分析很难,关键码的比较次数与记录移动次数依赖于增量因子序列deltadeltadelta的选取。目前还没有人给出选取最好的增量因子序列的方法。希尔插入排序方法是一个不稳定的排序方法。
3. 选择排序
3.1 直接选择排序
思想:每一趟在n−i(i=0,1,⋯,n−1)n-i(i=0,1,\cdots,n-1)n−i(i=0,1,⋯,n−1)个记录中选取关键字最小的记录作为有序序列中第iii个记录。(在要排列的一组数中,选出最小的一个数与第1个位置的数交换;然后在剩下的数当中再找最小的与第2个位置的数交换,依次类推,直到第n−1n-1n−1个元素和第nnn个元素比较为止。)
如:int[] Key = new int[]{45,34,78,12,34,32,29,64};
排序过程:
i=0→12,34‾,78,45,34,32,29,64i=0\rightarrow 12,\overline{34},78,45,34,32,29,64i=0→12,34,78,45,34,32,29,64
i=1→12,29,78,45,34,32,34‾,64i=1\rightarrow 12,29,78,45,34,32,\overline{34},64i=1→12,29,78,45,34,32,34,64
i=2→12,29,32,45,34,78,34‾,64i=2\rightarrow 12,29,32,45,34,78,\overline{34},64i=2→12,29,32,45,34,78,34,64
i=3→12,29,32,34,45,78,34‾,64i=3\rightarrow 12,29,32,34,45,78,\overline{34},64i=3→12,29,32,34,45,78,34,64
i=4→12,29,32,34,34‾,78,45,64i=4\rightarrow 12,29,32,34,\overline{34},78,45,64i=4→12,29,32,34,34,78,45,64
i=5→12,29,32,34,34‾,45,78,64i=5\rightarrow 12,29,32,34,\overline{34},45,78,64i=5→12,29,32,34,34,45,78,64
i=6→12,29,32,34,34‾,45,64,78i=6\rightarrow 12,29,32,34,\overline{34},45,64,78i=6→12,29,32,34,34,45,64,78
程序代码:
/// <summary>
/// 直接选择排序
/// </summary>
/// <typeparam name="T">需要排序记录的类型</typeparam>
/// <param name="array">需要排序的记录集合</param>
public static void StraightSelectSort<T>(T[] array) where T : IComparable<T>
{for (int i = 0; i < array.Length - 1; i++){int minIndex = i;T min = array[i];for (int j = i + 1; j < array.Length; j++){if (array[j].CompareTo(min) < 0){min = array[j];minIndex = j;}}if (minIndex != i){array[minIndex] = array[i];array[i] = min;}}
}
直接选择排序是不稳定的。
3.2 堆选择排序
直接选择排序并没有把每一趟的比较结果保存下来,在后一趟的比较中,许多比较在前一趟已经做过了,但由于前一趟排序时未保存这些比较结果,所以后一趟排序时又重复执行了这些比较操作,因而执行的比较次数较多。
如果可以做到每次在选择到最小记录的同时,并根据比较结果对其他记录做出相应的调整,那样排序的总体效率就会非常高了。而堆选择排序是一种树形选择排序,是对直接选择排序的有效改进。堆选择排序算法是Floyd和Williams在1964年共同发明的,同时,他们也发明了“堆”这样的数据结构。
堆的概念:具有nnn个元素的序列K={k1,k2,⋯,kn}K=\lbrace k_1,k_2,⋯,k_n \rbraceK={k1,k2,⋯,kn}当且仅当满足
{ki≤k2iki≤k2i+1,{ki≥k2iki≥k2i+1,i=1,2,⋯,[n2]\begin{cases} k_i\leq k_{2i}\\ k_i\leq k_{2i+1} \end{cases}, \begin{cases} k_i\geq k_{2i}\\ k_i\geq k_{2i+1} \end{cases}, i=1,2,\cdots,\left[\frac{n}{2}\right] {ki≤k2iki≤k2i+1,{ki≥k2iki≥k2i+1,i=1,2,⋯,[2n]
时称之为堆。
若关键码的集合K={k1,k2,⋯,kn}K=\lbrace k_1,k_2,⋯,k_n \rbraceK={k1,k2,⋯,kn},把它们按照完全二叉树的顺序存放在一维数组中。
- 若满足ki≤k2ik_i\leq k_{2i}ki≤k2i且ki≤k2i+1k_i\leq k_{2i+1}ki≤k2i+1则称作小根堆。
- 若满足ki≥k2ik_i\geq k_{2i}ki≥k2i且ki≥k2i+1k_i \geq k_{2i+1}ki≥k2i+1则称作大根堆。
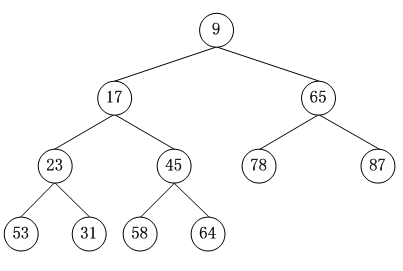
小根堆:int[] Key = new int[]{9,17,65,23,45,78,87,53,31,58,64};
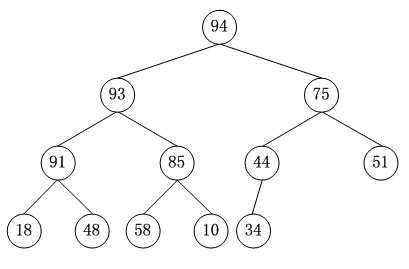
大根堆:int[] Key = new int[]{94,93,75,91,85,44,51,18,48,58,10,34};
思想(以大根堆为例):
构建大根堆之后,输出堆顶记录,对剩余的n−1n-1n−1个记录接着构建大根堆,便可得到nnn个记录的次大值,如此反复执行,就能得到一个有序序列,这个过程称为堆选择排序。
堆选择排序需解决的两个问题:
问题1:如何建堆,对初始序列建堆的过程,就是一个反复进行筛选的过程。
- (1)对一棵具有nnn个结点的完全二叉树来说最后一个结点是第[n2][\frac{n}{2}][2n]个结点的子树。
- (2)筛选从第[n2][\frac{n}{2}][2n]个结点为根的子树开始,该子树成为堆。
- (3)之后向前依次对各结点为根的子树进行筛选,使之成为堆,直到根结点。
即把序号为[n2],[n2]−1,⋯,1[\frac{n}{2}],[\frac{n}{2}]-1,\cdots,1[2n],[2n]−1,⋯,1,的记录作为根的子树都调整为堆。
问题2:输出堆顶元素后,如何调整新堆。
- (1)设有nnn个元素的堆,输出堆顶元素后,剩下n−1n-1n−1个元素。将堆底元素送入堆顶(最后一个元素与堆顶进行交换),堆被破坏,其原因仅是根结点不满足堆的性质。
- (2)将根结点与左,右子树中较大元素进行交换。
- (3)若与左子树交换:如果左子树堆被破坏,即左子树的根结点不满足堆的性质,则重复第二步。
- (4)若与右子树交换:如果右子树堆被破坏,即右子树的根结点不满足堆的性质,则重复第二步。
- (5)继续对不满足堆性质的子树进行上述操作,直到叶子结点,堆被重建成。
即:输出堆顶元素,将最后一个叶子结点放在堆顶,重新构建大根堆。
如:int[] Key = new int[]{45,34,78,12,34,32,29,64};
排序过程:
初始时:Key1→−1,45,34‾,78,12,34,32,29,64Key1 \rightarrow -1,45,\overline{34},78,12,34,32,29,64Key1→−1,45,34,78,12,34,32,29,64
建堆后:Key1→−1,78,64,45,34‾,34,32,29,12Key1 \rightarrow -1,78,64,45,\overline{34},34,32,29,12Key1→−1,78,64,45,34,34,32,29,12
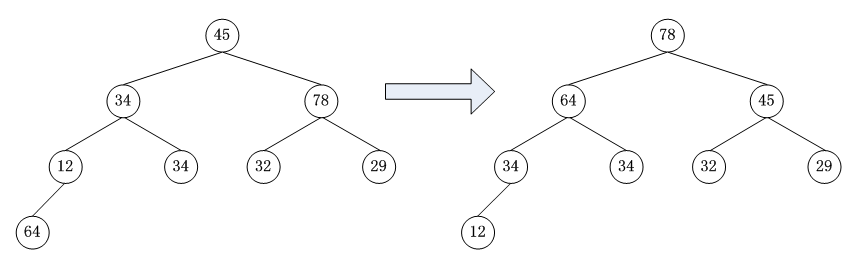
堆重建后:
Key1→−1,64,34‾,45,12,34,32,29,[78]Key1 \rightarrow -1,64,\overline{34},45,12,34,32,29,[78]Key1→−1,64,34,45,12,34,32,29,[78]
Key1→−1,45,34‾,32,12,34,29,[64,78]Key1 \rightarrow -1,45,\overline{34},32,12,34,29,[64,78]Key1→−1,45,34,32,12,34,29,[64,78]
Key1→−1,34‾,34,32,12,29,[45,64,78]Key1 \rightarrow -1,\overline{34},34,32,12,29,[45,64,78]Key1→−1,34,34,32,12,29,[45,64,78]
Key1→−1,34,29,32,12,[34‾,45,64,78]Key1 \rightarrow -1,34,29,32,12,[\overline{34},45,64,78]Key1→−1,34,29,32,12,[34,45,64,78]
Key1→−1,32,29,12,[34,34‾,45,64,78]Key1 \rightarrow -1,32,29,12,[34,\overline{34},45,64,78]Key1→−1,32,29,12,[34,34,45,64,78]
Key1→−1,29,12,[32,34,34‾,45,64,78]Key1 \rightarrow -1,29,12,[32,34,\overline{34},45,64,78]Key1→−1,29,12,[32,34,34,45,64,78]
Key1→−1,12,[29,32,34,34‾,45,64,78]Key1 \rightarrow -1,12,[29,32,34,\overline{34},45,64,78]Key1→−1,12,[29,32,34,34,45,64,78]
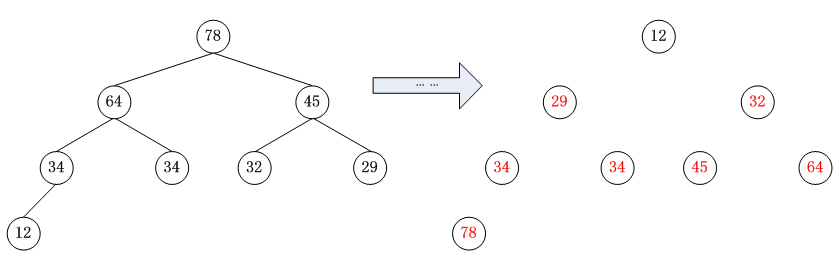
程序代码:
private static void Restore<T>(T[] array, int j, int vCount) where T : IComparable<T>
{//构建以结点j为根,一共有vCount个结点的大根堆while (j <= vCount / 2){int m = (2 * j + 1 <= vCount && array[2 * j + 1].CompareTo(array[2 * j]) > 0)? 2 * j + 1: 2 * j;if (array[m].CompareTo(array[j]) > 0){T temp = array[m];array[m] = array[j];array[j] = temp;j = m;}else{break;}}
}/// <summary>
/// 堆选择排序
/// </summary>
/// <typeparam name="T">需要排序记录的类型</typeparam>
/// <param name="array">需要排序的记录集合</param>
public static void HeapSelectSort<T>(T[] array) where T : IComparable<T>
{int vCount = array.Length;T[] tempArray = new T[vCount + 1];for (int i = 0; i < vCount; i++)tempArray[i + 1] = array[i];//初建大根堆for (int i = vCount / 2; i >= 1; i--)Restore(tempArray, i, vCount);//大根堆的重构与排序for (int i = vCount; i > 1; i--){T temp = tempArray[i];tempArray[i] = tempArray[1];tempArray[1] = temp;Restore(tempArray, 1, i - 1);}for (int i = 0; i < vCount; i++)array[i] = tempArray[i + 1];
}
4. 交换排序
4.1 冒泡交换排序
思想:通过相邻记录之间的比较和交换,使关键字较小的记录如气泡一般逐渐向上漂移直至水面。
如:int[] Key = new int[]{45,34,78,12,34,32,29,64};
i=0→[12],45,34‾,78,29,34,32,64i=0\rightarrow [12],45,\overline{34},78,29,34,32,64i=0→[12],45,34,78,29,34,32,64
i=1→[12,29],45,34‾,78,32,34,64i=1\rightarrow [12,29],45,\overline{34},78,32,34,64i=1→[12,29],45,34,78,32,34,64
i=2→[12,29,32],45,34‾,78,34,64i=2\rightarrow [12,29,32],45,\overline{34},78,34,64i=2→[12,29,32],45,34,78,34,64
i=3→[12,29,32,34‾],45,34,78,64i=3\rightarrow [12,29,32,\overline{34}],45,34,78,64i=3→[12,29,32,34],45,34,78,64
i=4→[12,29,32,34‾,34],45,64,78i=4\rightarrow [12,29,32,\overline{34},34],45,64,78i=4→[12,29,32,34,34],45,64,78
i=5→[12,29,32,34‾,34,45],64,78i=5\rightarrow [12,29,32,\overline{34},34,45],64,78i=5→[12,29,32,34,34,45],64,78
i=6→[12,29,32,34‾,34,45,64],78i=6\rightarrow [12,29,32,\overline{34},34,45,64],78i=6→[12,29,32,34,34,45,64],78
程序代码:
/// <summary>
/// 冒泡交换排序
/// </summary>
/// <typeparam name="T">需要排序记录的类型</typeparam>
/// <param name="array">需要排序的记录集合</param>
public static void BubbleExchangeSort<T>(T[] array) where T : IComparable<T>
{for (int i = 0; i < array.Length - 1; i++){for (int j = array.Length - 1; j > i; j--){if (array[j].CompareTo(array[j - 1]) < 0){T temp = array[j - 1];array[j - 1] = array[j];array[j] = temp;}}}
}
对冒泡排序常见的改进方法是加入一个标志性变量flag,用于标志某一趟排序过程是否有数据交换,如果进行某一趟排序时并没有进行数据交换,则说明数据已经按要求排列好,可立即结束排序,避免不必要的比较过程。
程序代码:
/// <summary>
/// 改进的冒泡交换排序
/// </summary>
/// <typeparam name="T">需要排序记录的类型</typeparam>
/// <param name="array">需要排序的记录集合</param>
public static void BubbleExchangeSortImproved<T>(T[] array) where T : IComparable<T>
{for (int i = 0; i < array.Length - 1; i++){bool flag = false;for (int j = array.Length - 1; j > i; j--){if (array[j].CompareTo(array[j - 1]) < 0){T temp = array[j - 1];array[j - 1] = array[j];array[j] = temp;flag = true;}}if (flag == false)break;}
}
4.2 快速交换排序
快速交换排序是由图灵奖获得者Tony Hoare(东尼.霍尔)所发展的一种排序算法,是采用分治策略的一个非常典型的应用。快速交换排序虽然高端,但其思想是来自冒泡交换排序的,冒泡交换排序是通过相邻元素的比较和交换把最小的冒泡到最顶端,而快速交换排序是比较和交换小数和大数,这样一来不仅小数冒泡到上面的同时也把大数沉到下面。
其基本思想如下:
- (1)选择一个基准元素,通常选择第一个元素或者最后一个元素。
- (2)通过一趟排序将待排序的记录分割成独立的两部分,其中一部分记录的元素值均比基准元素值小,另一部分记录的元素值比基准值大。
- (3)此时基准元素在其排好序的正确位置。
- (4)然后分别对这两部分记录用同样的方法继续进行排序,直到整个序列有序。
即:从待排记录中选一记录,将其放入正确的位置,然后以该位置为界,对左右两部分再做快速排序,直到划分的长度为1。
如:int[] Key = new int[]{45,34,78,12,34,32,29,64};
init→45,34‾,78,12,34,32,29,64init\rightarrow 45,\overline{34},78,12,34,32,29,64init→45,34,78,12,34,32,29,64
step1→[32,34‾,29,12,34],45,[78,64]step1\rightarrow [32,\overline{34},29,12,34],45,[78,64]step1→[32,34,29,12,34],45,[78,64]
step2→[[29,12],32,[34‾,34]],45,[78,64]step2\rightarrow [[29,12],32,[\overline{34},34]],45,[78,64]step2→[[29,12],32,[34,34]],45,[78,64]
step3→[[[12],29],32,[34‾,34]],45,[78,64]step3\rightarrow [[[12],29],32,[\overline{34},34]],45,[78,64]step3→[[[12],29],32,[34,34]],45,[78,64]
step4→[[[12],29],32,[[34],34‾]],45,[78,64]step4\rightarrow [[[12],29],32,[[34],\overline{34}]],45,[78,64]step4→[[[12],29],32,[[34],34]],45,[78,64]
step5→[[[12],29],32,[[34],34‾]],45,[[64],78]step5\rightarrow [[[12],29],32,[[34],\overline{34}]],45,[[64],78]step5→[[[12],29],32,[[34],34]],45,[[64],78]
程序代码:
private static void QuickSort<T>(T[] array, int left, int right) where T : IComparable<T>
{//快速排序递归函数if (left < right){T current = array[left];int i = left;int j = right;while (i < j){while (array[j].CompareTo(current) > 0 && i < j)j--;while (array[i].CompareTo(current) <= 0 && i < j)i++;if (i < j){T temp = array[i];array[i] = array[j];array[j] = temp;j--;i++;}}array[left] = array[j];array[j] = current;if (left < j - 1) QuickSort(array, left, j - 1);if (right > j + 1) QuickSort(array, j + 1, right);}
}/// <summary>
/// 快速交换排序
/// </summary>
/// <typeparam name="T">需要排序记录的类型</typeparam>
/// <param name="array">需要排序的记录集合</param>
public static void QuickExchangeSort<T>(T[] array) where T : IComparable<T>
{QuickSort(array, 0, array.Length - 1);
}
其实上面的代码还可以再优化,上面代码中基准元素已经在current中保存了,所以不需要每次交换都设置一个temp变量,在交换的时候只需要先后覆盖就可以了。这样既能较少空间的使用还能降低赋值运算的次数。
优化代码如下:
private static void QuickSortImproved<T>(T[] array, int left, int right) where T : IComparable<T>
{//快速排序递归函数if (left < right){T current = array[left];int i = left;int j = right;while (i < j){while (array[j].CompareTo(current) > 0 && i < j)j--;array[i] = array[j];while (array[i].CompareTo(current) <= 0 && i < j)i++;array[j] = array[i];}array[j] = current;if (left < j - 1) QuickSortImproved(array, left, j - 1);if (right > j + 1) QuickSortImproved(array, j + 1, right);}
}/// <summary>
/// 快速交换排序
/// </summary>
/// <typeparam name="T">需要排序记录的类型</typeparam>
/// <param name="array">需要排序的记录集合</param>
public static void QuickExchangeSortImproved<T>(T[] array) where T : IComparable<T>
{QuickSortImproved(array, 0, array.Length - 1);
}
5. 并归排序
我们首先先看两个有序序列合并的例子,如:
int[] Key1 = new int[]{1,3,5,7,9};
int[] Key2 = new int[]{2,4,6,8,10,12,14}int[] temp = new int[Key1.Length + Key2.Length];
temp→0,0,0,0,0,0,0,0,0,0,0,0temp \rightarrow 0,0,0,0,0,0,0,0,0,0,0,0temp→0,0,0,0,0,0,0,0,0,0,0,0
temp→1,2,3,4,5,6,7,8,9,0,0,0temp \rightarrow 1,2,3,4,5,6,7,8,9,0,0,0temp→1,2,3,4,5,6,7,8,9,0,0,0
temp→1,2,3,4,5,6,7,8,9,10,12,14temp \rightarrow 1,2,3,4,5,6,7,8,9,10,12,14temp→1,2,3,4,5,6,7,8,9,10,12,14
程序代码:
/// <summary>
/// 合并排序
/// </summary>
/// <typeparam name="T">需要排序记录的类型</typeparam>
/// <param name="array1">有序记录集合1</param>
/// <param name="array2">有序记录集合2</param>
/// <returns>合并后的有序记录集合</returns>
public static T[] MergeSort<T>(T[] array1,T[] array2) where T : IComparable<T>
{T[] temp = new T[array1.Length + array2.Length];int i = 0, j = 0, k = 0;while (i < array1.Length && j < array2.Length){if (array1[i].CompareTo(array2[i]) < 0){temp[k++] = array1[i++];}else{temp[k++] = array2[j++];}}while (i < array1.Length){temp[k++] = array1[i++];}while (j < array2.Length){temp[k++] = array2[j++];}return temp;
}
我们接着看一个序列的并归排序。
首先递归划分子问题,然后合并结果。把待排序列看成由两个有序的子序列构成,然后合并两个子序列,接着把子序列看成由两个有序序列组成……。倒过来看,其实就是先两两合并,然后四四合并……最终形成有序序列。该算法是采用分治策略的一个非常典型的应用,俗称 2-路并归。
如:int[] Key = new int[]{45,34,78,12,34,32,29,64};
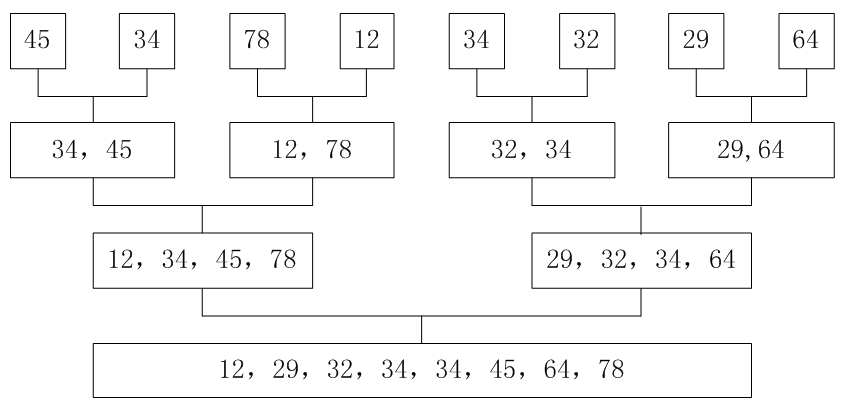
程序代码:
/// <summary>
/// 合并排序的递归合并函数
/// </summary>
/// <typeparam name="T">需要排序记录的类型</typeparam>
/// <param name="array">需要排序的记录集合</param>
/// <param name="left">起点位置</param>
/// <param name="mid">中间位置</param>
/// <param name="right">终点位置</param>
private static void Merge<T>(T[] array, int left, int mid, int right) where T : IComparable<T>
{T[] temp = new T[right - left + 1];int i = left;int j = mid + 1;int k = 0;while (i <= mid && j <= right){if (array[i].CompareTo(array[j]) < 0){temp[k++] = array[i++];}else{temp[k++] = array[j++];}}while (i <= mid){temp[k++] = array[i++];}while (j <= right){temp[k++] = array[j++];}for (int n = 0; n < temp.Length; n++){array[left + n] = temp[n];}
}/// <summary>
/// 合并排序的递归分治函数
/// </summary>
/// <typeparam name="T">需要排序记录的类型</typeparam>
/// <param name="array">需要排序的记录集合</param>
/// <param name="left">起点位置</param>
/// <param name="right">终点位置</param>
private static void MergeSort<T>(T[] array, int left, int right) where T : IComparable<T>
{if (left >= right)return;int mid = (left + right) / 2;MergeSort(array, left, mid); //递归排序左边MergeSort(array, mid + 1, right); //递归排序右边Merge(array, left, mid, right); //合并
}/// <summary>
/// 合并排序
/// </summary>
/// <typeparam name="T">需要排序记录的类型</typeparam>
/// <param name="array">需要排序的记录集合</param>
public static void MergeSort<T>(T[] array) where T : IComparable<T>
{MergeSort(array, 0, array.Length - 1);
}

相关文章:

Objective-C 什么是类
Objective-C 什么是类 转自http://www.189works.com/article-31219-1.html 之前一直做C开发,最近2个多月转 Objective-C, 入门的时候,遇到了很多的困惑。现在过节,正是解决他们的好时机。 主要参考来自http://www.sealiesoftware.…

APP之红点提醒三个阶段
下面这个页面就是我们进入APP后的主界面。客户选项的红点上数字就是显示我们没有查看的客户总数量。 当我们切换到客户这个fragment时,会显示贷款客户数量与保险客户数量。 当我们随便点击入一个选项,假如进入到保险客户的这个activity里面,L…

零基础参加java培训的系统学习路线
零基础想要学习java技术,那么最好的选择就是参加java培训,进行系统的学习,以下就是小编为大家整理的零基础参加java培训的系统学习路线,希望能够帮助到正在学习java技术的零基础同学。 零基础参加java培训的系统学习路线&#…

在ASP.NET中跟踪和恢复大文件下载
在Web应用程序中处理大文件下载的问题一直出了名的困难,因此对于大多数站点来说,如果用户的下载被中断了,它们只能说悲哀降临到用户的身上了。但是我们现在不必这样了,因为你可以使自己的ASP.NET应用程序有能力支持可恢复…

ZeroMQ实例-使用ZeroMQ进行windows与linux之间的通信
1、本文包括 1)在windows下使用ZMQ 2)在windows环境下与Linux环境下进行网络通信 2、在Linux下使用ZMQ 之前写过一篇如何在Linux环境下使用ZMQ的文章 《ZeroMQ实例-使用ZMQ(ZeroMQ)进行局域网内网络通信》,这里就不再赘述。 3、在Windows环境…

线性代数:03 向量空间 -- 基本概念
本讲义是自己上课所用幻灯片,里面没有详细的推导过程(笔者板书推导)只以大纲的方式来展示课上的内容,以方便大家下来复习。 本章主要介绍向量空间的知识,与前两章一样本章也可以通过研究解线性方程组的解把所有知识点…

如何获得PMP认证证书
pmp证书是一项由美国项目管理协会发起的项目管理专业人士认证证书,它属于国际认证类证书,含金量是非常高的,那么如何获得PMP认证证书呢?来看看下面的详细介绍。 如何获得PMP证书? PMP证书的获取是需要参加PMP考试的。我国自1999年引进PM…

UITextField的详细使用
UItextField通常用于外部数据输入,以实现人机交互。下面以一个简单的登陆界面来讲解UItextField的详细使用。//用来显示“用户名”的labelUILabel* label1 [[UILabelalloc] initWithFrame:CGRectMake(15, 65, 70, 30)];label1.backgroundCol…

06-hibernate注解-一对多单向外键关联
一对多单向外键 1,一方持有多方的集合,一个班级有多个学生(一对多)。 2,OneToMany(cascade{CascadeType.ALL}, fetchFetchType.LAZY ) //级联关系,抓取策略:懒加载。 JoinColumn(name"c…

线性代数:03 向量空间 -- 矩阵的零空间,列空间,线性方程组解的结构
本讲义是自己上课所用幻灯片,里面没有详细的推导过程(笔者板书推导)只以大纲的方式来展示课上的内容,以方便大家下来复习。 本章主要介绍向量空间的知识,与前两章一样本章也可以通过研究解线性方程组的解把所有知识点…

学Python培训有什么用
Python在近几年的发展非常迅速,在互联网行业Python的薪资也越来越高,不少人开始准备学习Python技术,那么到底学Python培训有什么用呢?来看看下面的详细介绍。 学Python培训有什么用? 学习python可以提高工作效率,使用python&…
SQL压力测试用的语句和相关计数器
将数据库中所有表的所有的内容选一遍: IF object_id(tempdb..#temp) is not null BEGIN DROP TABLE #temp END DECLARE index int DECLARE count int DECLARE schemaname varchar(50) DECLARE tablename varchar(50) set index1 set count(select count(*) from s…

线性代数:04 特征值与特征向量 -- 特征值与特征向量
本讲义是自己上课所用幻灯片,里面没有详细的推导过程(笔者板书推导)只以大纲的方式来展示课上的内容,以方便大家下来复习。 本章主要介绍特征值与特征向量的知识,前一章我们介绍了线性变换可以把一个向量映射到另一个…
使用Silverlight2的WebClient下载远程图片
在Silverlight 2之前有一个Downloader对象,开发者一般使用Downloader下载图片和文体文件,这个对象在Silverlight 2中作为了一个特性被集成到WebClient类之中,你可以直接使用WebClient的OpenReadAsync方法加载远程图片的URI,然后使…

学习Web前端需要避免哪些错误
很多初学web前端的同学,在学习web前端的时候都会遇到一些错误,虽然有些错误与某一个具体的行为相关,但有些错误却是所有Web开发人员都需要面对的挑战。下面小编就整理一下学习Web前端需要避免哪些错误,希望能够给同学们带来帮助。…

【2012百度之星/资格赛】H:用户请求中的品牌 [后缀数组]
时间限制:1000ms内存限制:65536kB描述馅饼同学是一个在百度工作,做用户请求(query)分析的同学,他在用户请求中经常会遇到一些很奇葩的词汇。在比方说“johnsonjohnson”、“duckduck”,这些词汇虽然看起来是一些词汇的…

实战:使用Telnet排除网络故障
使用Telnet排除网络故障 如果员工告诉你,他的计算机不能访问网站。你需要断定是他的计算机系统出了问题还是IE浏览器中了恶意插件,或者是网络层面的问题。 如图2-108所示,通过Telnet 服务器的某个端口,就能断定是否访问该服务器的…

线性代数:04 特征值与特征向量 -- 矩阵的相似对角化
本讲义是自己上课所用幻灯片,里面没有详细的推导过程(笔者板书推导)只以大纲的方式来展示课上的内容,以方便大家下来复习。 本章主要介绍特征值与特征向量的知识,前一章我们介绍了线性变换可以把一个向量映射到另一个…

UI设计培训完之后可以去哪些公司工作
UI设计培训完之后可以去哪些公司工作?这是目前很多学习UI设计或者准备学习UI设计的同学比较关注的一个问题,虽然都知道UI设计的发展前景不错,但是具体学完之后该去哪里工作大家却比较迷茫,来看看下面的详细介绍吧。 UI设计培训完之后可以去哪…
Tomcat详解(下)
配置监听端口 1、编辑配置文件 1234[rootplinuxos ~]# vim /usr/local/tomcat/conf/server.xml <Connector port"80" protocol"HTTP/1.1" ##改成80端口 connectionTimeout"20000" redirectPort"8443" /> 2、重启服务 123456…

线性代数:05 实对称矩阵与二次型
本讲义是自己上课所用幻灯片,里面没有详细的推导过程(笔者板书推导)只以大纲的方式来展示课上的内容,以方便大家下来复习。 本章是特征值与特征向量知识的延续,根据谱定理可知实对称矩阵可以正交对角化,对…
HDU 2717 Catch That Cow(BFS)
题目链接 好裸,BFS。杭电多组。。2A。。 1 #include <stdio.h>2 #include <string.h>3 int p[100001],o[100001];4 int main()5 {6 int n,k,i,j,start0,end0,num0;7 while(scanf("%d%d",&n,&k)!EOF)8 {9 memset(…

参加web前端培训需要注意什么
web前端在互联网行业的就业形势是非常良好的,是很多人进入到互联网行业的一个首要选择,要想学会web前端技术,一定要参加系统的培训,那么参加web前端培训需要注意什么呢? 参加web前端培训需要注意什么? 一、选择一家靠谱的培训机…

NIO - Scatter/Gather
1.Scatter 从一个Channel读取的信息分散到N个缓冲区中(Buufer). 2.Gather 将N个Buffer里面内容按照顺序发送到一个Channel. Scatter/Gather功能是通道(Channel)提供的 并不是Buffer, Scatter/Gather相关接口 类图 ReadableByteChannel WritableByteChannel 接口提供…
android:themes.xml
按 CtrlC 复制代码按 CtrlC 复制代码本文转自 OldHawk 博客园博客,原文链接:http://www.cnblogs.com/taobataoma/p/3761520.html,如需转载请自行联系原作者

参考答案:01 线性方程组
本篇图文为《线性代数及其应用》这本教材对应习题册的参考答案。 从本章开始,我们一起来学习线性代数的有关知识,线性代数的应用之一就是求解复杂方程问题。所以,我们首先从高中时期利用高斯消元法求解线性方程组谈起,发现可以利…

Java培训都学什么
java行业的快速发展,引起了很多人的关注,越来越多的人选择报java培训机构学习java技术,那么Java培训都学什么呢?零基础的同学是否能学会呢?来看看下面的详细介绍。 Java培训都学什么?主要分为以下几个阶段: 第一阶段࿱…
网站架构之统一数据服务平台技术
一、论坛背景 新一代网站架构的使命,敏捷,开发,体验。 敏捷:业务快速增长,每天都要上线大量的小需求,应用系统日益膨胀,耦合恶化,架构越来越复杂,带来更高的开发成本。如何保持业务开发敏捷性? 开放:Faceb…
Oracle 变量绑定与变量窥视合集系列二
二 用示例演示一次硬分析(hard parse)和一次软分析(soft parse),以及一次更软的分析(softer soft parse),并对给出演示结果 我们先看一个硬解析和软解析关系测试,什么时候硬解析,什么…

参考答案:02 矩阵及其运算
本篇图文为《线性代数及其应用》这本教材对应习题册的参考答案。 本章主要介绍有关矩阵的知识,主要包括矩阵的基本运算(加法、数乘、乘法、乘幂、迹、转置),其中乘法最为重要,在计算机图形学中具有大量的应用。如果矩…