MyBatis-Plus 实战教程四 idea插件
插件功能
MybatisPlus提供了很多的插件功能,进一步拓展其功能。目前已有的插件有:
- PaginationInnerInterceptor:自动分页
- TenantLineInnerInterceptor:多租户
- DynamicTableNameInnerInterceptor:动态表名
- OptimisticLockerInnerInterceptor:乐观锁
- IllegalSQLInnerInterceptor:sql 性能规范
- BlockAttackInnerInterceptor:防止全表更新与删除
分页插件
在未引入分页插件的情况下,MybatisPlus是不支持分页功能的,IService和BaseMapper中的分页方法都无法正常起效。
所以,我们必须配置分页插件。
配置分页插件
在项目中新建一个配置类:
其代码如下:
package com.onenewcode.mpdemo.config;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
// 初始化核心插件
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 添加分页插件
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
分页API
编写一个分页查询的测试:
@Test
void testPageQuery() {
// 1.分页查询,new Page()的两个参数分别是:页码、每页大小
Page<User> p = userService.page(new Page<>(2, 2));
// 2.总条数
System.out.println("total = " + p.getTotal());
// 3.总页数
System.out.println("pages = " + p.getPages());
// 4.数据
List<User> records = p.getRecords();
records.forEach(System.out::println);
}
运行的SQL如下:
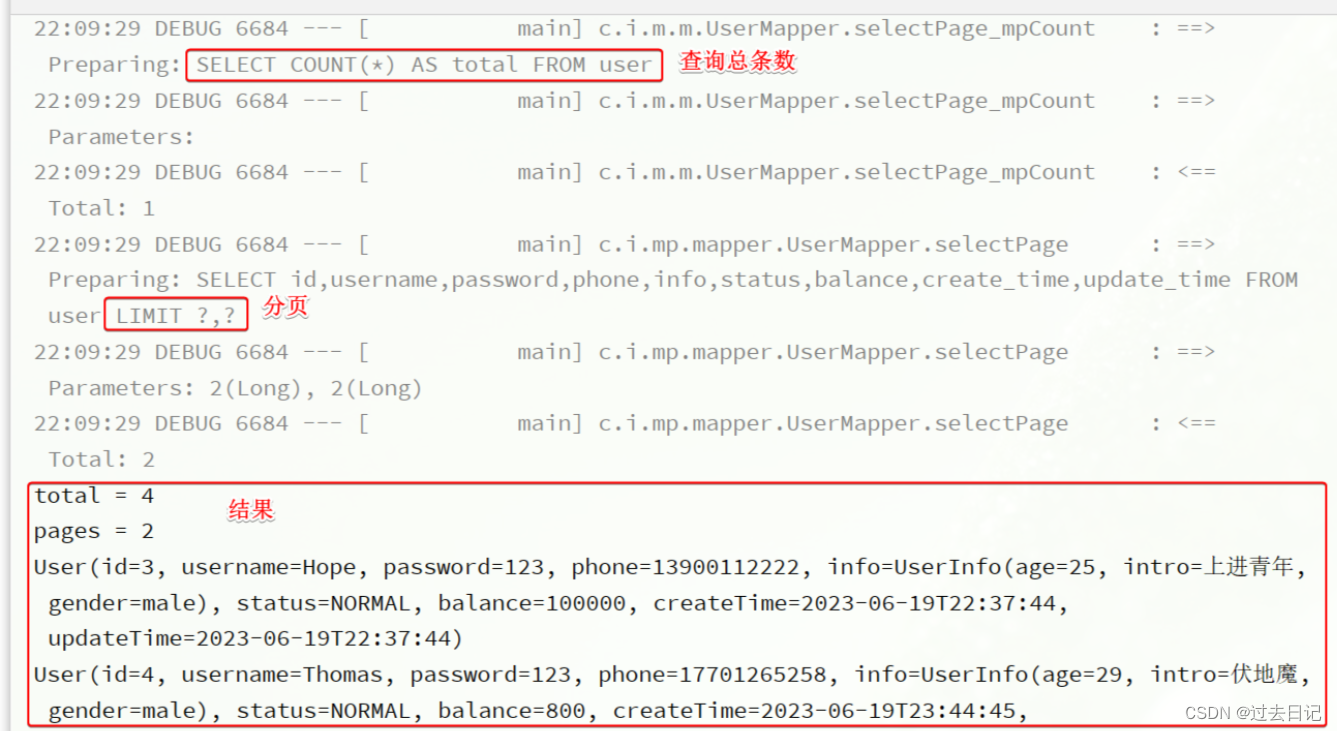
这里用到了分页参数,Page,即可以支持分页参数,也可以支持排序参数。常见的API如下:
int pageNo = 1, pageSize = 5;
// 分页参数
Page<User> page = Page.of(pageNo, pageSize);
// 排序参数, 通过OrderItem来指定
page.addOrder(new OrderItem("balance", false));
userService.page(page);
通用分页实体
现在要实现一个用户分页查询的接口,接口规范如下:
| 参数 | 说明 |
|---|---|
| 请求方式 | GET |
| 请求路径 | /users/page |
| 请求参数 | { “pageNo”: 1, “pageSize”: 5, “sortBy”: “balance”, “isAsc”: false, “name”: “o”, “status”: 1 } |
| 返回值 | { “total”: 100006, “pages”: 50003, “list”: [ { “id”: 1685100878975279298, “username”: “user_9****”, “info”: { “age”: 24, “intro”: “英文老师”, “gender”: “female” }, “status”: “正常”, “balance”: 2000 } ] } |
| 特殊说明 | - 如果排序字段为空,默认按照更新时间排序 - 排序字段不为空,则按照排序字段排序 |
这里需要定义3个实体:
- UserQuery:分页查询条件的实体,包含分页、排序参数、过滤条件
- PageDTO:分页结果实体,包含总条数、总页数、当前页数据
- UserVO:用户页面视图实体
实体
由于UserQuery之前已经定义过了,并且其中已经包含了过滤条件,具体代码如下:
package com.onenewcode.mpdemo.domain.query;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
@Data
@ApiModel(description = "用户查询条件实体")
public class UserQuery {
@ApiModelProperty("用户名关键字")
private String name;
@ApiModelProperty("用户状态:1-正常,2-冻结")
private Integer status;
@ApiModelProperty("余额最小值")
private Integer minBalance;
@ApiModelProperty("余额最大值")
private Integer maxBalance;
}
其中缺少的仅仅是分页条件,而分页条件不仅仅用户分页查询需要,以后其它业务也都有分页查询的需求。因此建议将分页查询条件单独定义为一个PageQuery实体.
PageQuery是前端提交的查询参数,一般包含四个属性:
- pageNo:页码
- pageSize:每页数据条数
- sortBy:排序字段
- isAsc:是否升序
@Data
@ApiModel(description = "分页查询实体")
public class PageQuery {
@ApiModelProperty("页码")
private Integer pageNo;
@ApiModelProperty("页码")
private Integer pageSize;
@ApiModelProperty("排序字段")
private String sortBy;
@ApiModelProperty("是否升序")
private Boolean isAsc;
}
然后,让我们的UserQuery继承这个实体:
package com.onenewcode.mpdemo.domain.query;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import lombok.EqualsAndHashCode;
@EqualsAndHashCode(callSuper = true)
@Data
@ApiModel(description = "用户查询条件实体")
public class UserQuery extends PageQuery {
@ApiModelProperty("用户名关键字")
private String name;
@ApiModelProperty("用户状态:1-正常,2-冻结")
private Integer status;
@ApiModelProperty("余额最小值")
private Integer minBalance;
@ApiModelProperty("余额最大值")
private Integer maxBalance;
}
返回值的用户实体沿用之前定一个UserVO实体:
最后,则是分页实体PageDTO:
代码如下:
package com.onenewcode.mpdemo.domain.dto;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.util.List;
@Data
@ApiModel(description = "分页结果")
public class PageDTO<T> {
@ApiModelProperty("总条数")
private Long total;
@ApiModelProperty("总页数")
private Long pages;
@ApiModelProperty("集合")
private List<T> list;
}
开发接口
我们在UserController中定义分页查询用户的接口:
package com.onenewcode.mpdemo.controller;
import com.onenewcode.mpdemo.domain.dto.PageDTO;
import com.onenewcode.mpdemo.domain.query.PageQuery;
import com.onenewcode.mpdemo.domain.vo.UserVO;
import com.onenewcode.mpdemo.service.UserService;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("users")
@RequiredArgsConstructor
public class UserController {
private final UserService userService;
@GetMapping("/page")
public PageDTO<UserVO> queryUsersPage(UserQuery query){
return userService.queryUsersPage(query);
}
// 。。。 略
}
然后在IUserService中创建queryUsersPage方法:
PageDTO<UserVO> queryUsersPage(PageQuery query);
接下来,在UserServiceImpl中实现该方法:
@Override
public PageDTO<UserVO> queryUsersPage(PageQuery query) {
// 1.构建条件
// 1.1.分页条件
Page<User> page = Page.of(query.getPageNo(), query.getPageSize());
// 1.2.排序条件
if (query.getSortBy() != null) {
page.addOrder(new OrderItem(query.getSortBy(), query.getIsAsc()));
}else{
// 默认按照更新时间排序
page.addOrder(new OrderItem("update_time", false));
}
// 2.查询
page(page);
// 3.数据非空校验
List<User> records = page.getRecords();
if (records == null || records.size() <= 0) {
// 无数据,返回空结果
return new PageDTO<>(page.getTotal(), page.getPages(), Collections.emptyList());
}
// 4.有数据,转换
List<UserVO> list = BeanUtil.copyToList(records, UserVO.class);
// 5.封装返回
return new PageDTO<UserVO>(page.getTotal(), page.getPages(), list);
}
改造PageQuery实体
在刚才的代码中,从PageQuery到MybatisPlus的Page之间转换的过程还是比较麻烦的。
我们完全可以在PageQuery这个实体中定义一个工具方法,简化开发。
像这样:
package com.onenewcode.mpdemo.domain.query;
import com.baomidou.mybatisplus.core.metadata.OrderItem;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import lombok.Data;
@Data
public class PageQuery {
private Integer pageNo;
private Integer pageSize;
private String sortBy;
private Boolean isAsc;
public <T> Page<T> toMpPage(OrderItem ... orders){
// 1.分页条件
Page<T> p = Page.of(pageNo, pageSize);
// 2.排序条件
// 2.1.先看前端有没有传排序字段
if (sortBy != null) {
p.addOrder(new OrderItem(sortBy, isAsc));
return p;
}
// 2.2.再看有没有手动指定排序字段
if(orders != null){
p.addOrder(orders);
}
return p;
}
public <T> Page<T> toMpPage(String defaultSortBy, boolean isAsc){
return this.toMpPage(new OrderItem(defaultSortBy, isAsc));
}
public <T> Page<T> toMpPageDefaultSortByCreateTimeDesc() {
return toMpPage("create_time", false);
}
public <T> Page<T> toMpPageDefaultSortByUpdateTimeDesc() {
return toMpPage("update_time", false);
}
}
这样我们在开发也时就可以省去对从PageQuery到Page的的转换:
// 1.构建条件
Page<User> page = query.toMpPageDefaultSortByCreateTimeDesc();
改造PageDTO实体
在查询出分页结果后,数据的非空校验,数据的vo转换都是模板代码,编写起来很麻烦。
我们完全可以将其封装到PageDTO的工具方法中,简化整个过程:
package com.onenewcode.mpdemo.domain.dto;
import cn.hutool.core.bean.BeanUtil;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Collections;
import java.util.List;
import java.util.function.Function;
import java.util.stream.Collectors;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageDTO<V> {
private Long total;
private Long pages;
private List<V> list;
/**
* 返回空分页结果
* @param p MybatisPlus的分页结果
* @param <V> 目标VO类型
* @param <P> 原始PO类型
* @return VO的分页对象
*/
public static <V, P> PageDTO<V> empty(Page<P> p){
return new PageDTO<>(p.getTotal(), p.getPages(), Collections.emptyList());
}
/**
* 将MybatisPlus分页结果转为 VO分页结果
* @param p MybatisPlus的分页结果
* @param voClass 目标VO类型的字节码
* @param <V> 目标VO类型
* @param <P> 原始PO类型
* @return VO的分页对象
*/
public static <V, P> PageDTO<V> of(Page<P> p, Class<V> voClass) {
// 1.非空校验
List<P> records = p.getRecords();
if (records == null || records.size() <= 0) {
// 无数据,返回空结果
return empty(p);
}
// 2.数据转换
List<V> vos = BeanUtil.copyToList(records, voClass);
// 3.封装返回
return new PageDTO<>(p.getTotal(), p.getPages(), vos);
}
/**
* 将MybatisPlus分页结果转为 VO分页结果,允许用户自定义PO到VO的转换方式
* @param p MybatisPlus的分页结果
* @param convertor PO到VO的转换函数
* @param <V> 目标VO类型
* @param <P> 原始PO类型
* @return VO的分页对象
*/
public static <V, P> PageDTO<V> of(Page<P> p, Function<P, V> convertor) {
// 1.非空校验
List<P> records = p.getRecords();
if (records == null || records.size() <= 0) {
// 无数据,返回空结果
return empty(p);
}
// 2.数据转换
List<V> vos = records.stream().map(convertor).collect(Collectors.toList());
// 3.封装返回
return new PageDTO<>(p.getTotal(), p.getPages(), vos);
}
}
最终,业务层的代码可以简化为:
@Override
public PageDTO<UserVO> queryUserByPage(PageQuery query) {
// 1.构建条件
Page<User> page = query.toMpPageDefaultSortByCreateTimeDesc();
// 2.查询
page(page);
// 3.封装返回
return PageDTO.of(page, UserVO.class);
}
如果是希望自定义PO到VO的转换过程,可以这样做:
@Override
public PageDTO<UserVO> queryUserByPage(PageQuery query) {
// 1.构建条件
Page<User> page = query.toMpPageDefaultSortByCreateTimeDesc();
// 2.查询
page(page);
// 3.封装返回
return PageDTO.of(page, user -> {
// 拷贝属性到VO
UserVO vo = BeanUtil.copyProperties(user, UserVO.class);
// 用户名脱敏
String username = vo.getUsername();
vo.setUsername(username.substring(0, username.length() - 2) + "**");
return vo;
});
}
仓库地址
https://github.com/onenewcode/mp-demo.git
相关文章:
spring.factories文件的作用
即spring.factories文件是帮助spring-boot项目包以外的bean(即在pom文件中添加依赖中的bean)注册到spring-boot项目的spring容器中。在Spring Boot启动时,它会扫描classpath下所有的spring.factories文件,加载其中的自动配置类,并将它们注入到Spring ApplicationContext中,使得项目能够自动运行。spring.factories文件是Spring Boot自动配置的核心文件之一,它的作用是。

7min到40s:SpringBoot 启动优化实践
然后重点排查这些阶段的代码。先看下。

SpringBoot系列教程之Bean之指定初始化顺序的若干姿势
之前介绍了@Order注解的常见错误理解,它并不能指定 bean 的加载顺序,那么问题来了,如果我需要指定 bean 的加载顺序,那应该怎么办呢?本文将介绍几种可行的方式来控制 bean 之间的加载顺序。

SpringBoot接口防抖(防重复提交)的一些实现方案
作为一名老码农,在开发后端Java业务系统,包括各种管理后台和小程序等。在这些项目中,我设计过单/多租户体系系统,对接过许多开放平台,也搞过消息中心这类较为复杂的应用,但幸运的是,我至今还没有遇到过线上系统由于代码崩溃导致资损的情况。这其中的原因有三点:一是业务系统本身并不复杂;二是我一直遵循某大厂代码规约,在开发过程中尽可能按规约编写代码;三是经过多年的开发经验积累,我成为了一名熟练工,掌握了一些实用的技巧。啥是防抖所谓防抖,一是防用户手抖,二是防网络抖动。
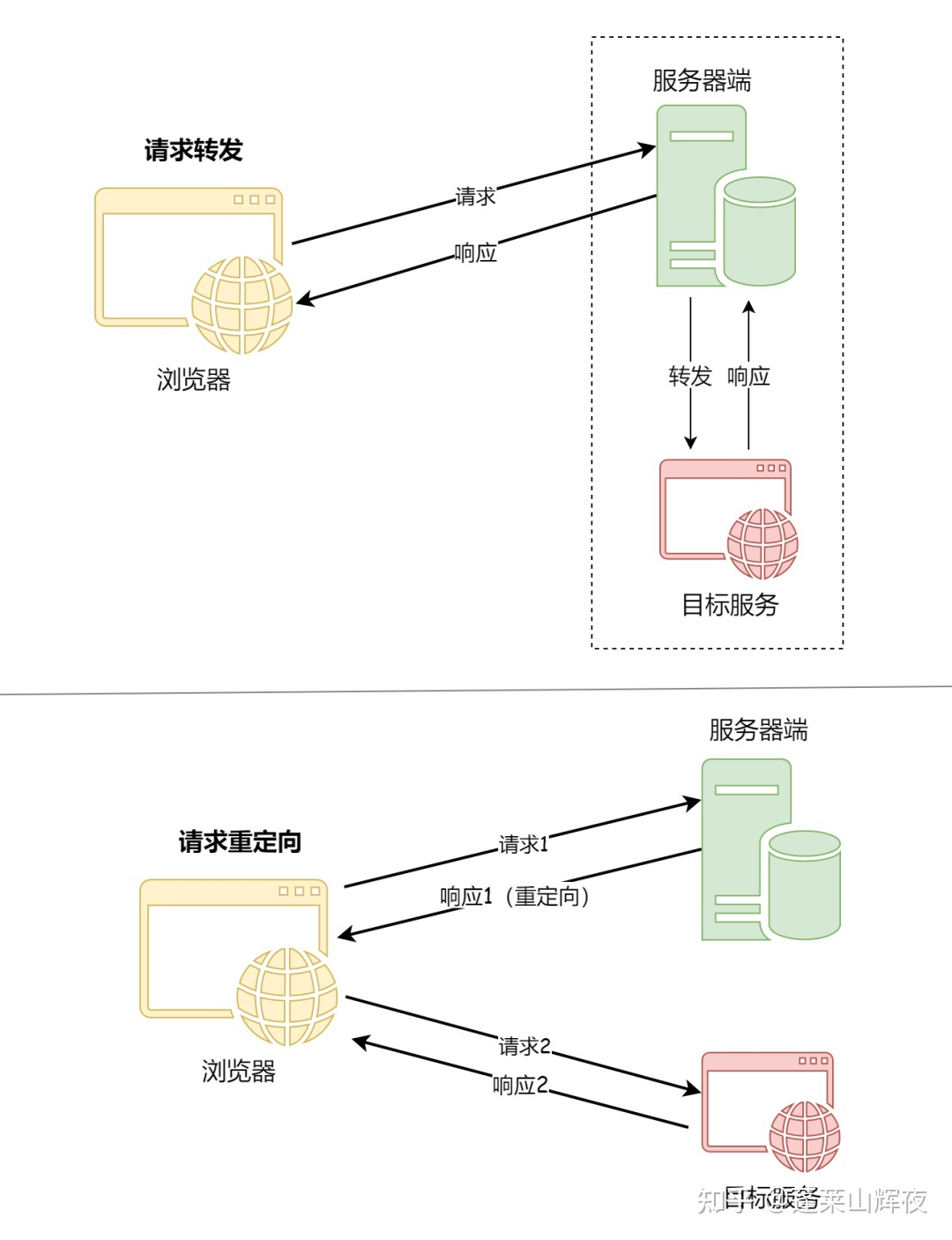
SpringBoot请求转发与重定向
但是可能由于B网址相对于A网址过于复杂,这样搜索引擎就会觉得网址A对用户更加友好,因而在重定向之后任然显示旧的网址A,但是显示网址B的内容。在平常使用手机的过程当中,有时候会发现网页上会有浮动的窗口,或者访问的页面不是正常的页面,这就可能是运营商通过某种方式篡改了用户正常访问的页面。重定向,是指在Nginx中,重定向是指通过修改URL地址,将客户端的请求重定向到另一个URL地址的过程,Nginx中实现重定向的方式有多种,比如使用rewrite模块、return指令等。使用场景:在返回视图的前面加上。

SpringBoot 中实现订单30分钟自动取消的策略
在电商和其他涉及到在线支付的应用中,通常需要实现一个功能:如果用户在生成订单后的一定时间内未完成支付,系统将自动取消该订单。本文将详细介绍基于Spring Boot框架实现订单30分钟内未支付自动取消的几种方案,并提供实例代码。
SpringBoot 优雅实现超大文件上传,通用方案
通俗的说,你把要上传的东西上传,服务器会先做MD5校验,如果服务器上有一样的东西,它就直接给你个新地址,其实你下载的都是服务器上的同一个文件,想要不秒传,其实只要让MD5改变,就是对文件本身做一下修改(改名字不行),例如一个文本文件,你多加几个字,MD5就变了,就不会秒传了。分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件。
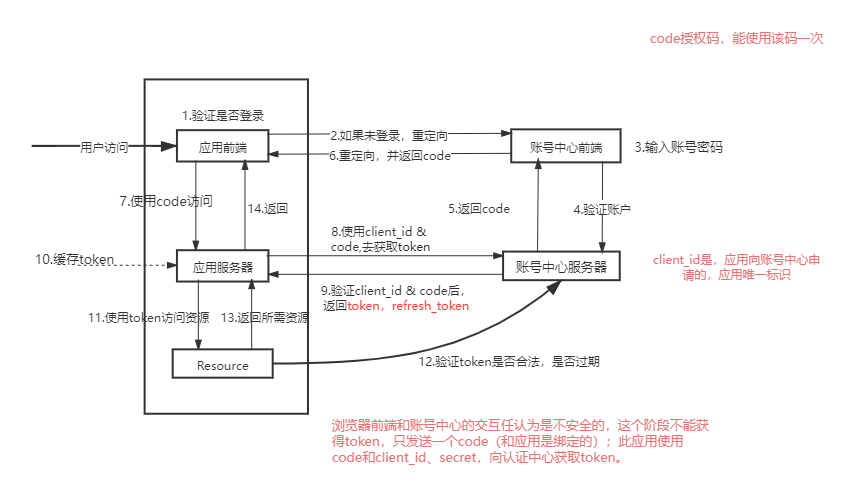
Springboot + oauth2 单点登录 - 原理篇
OAuth 协议为用户资源的授权提供了一个安全的、开放而又简易的标准,允许用户授权第三方移动应用访问他们存储在另外的服务提供者上的信息,而不需要将用户名和密码提供给第三方移动应用或分享他们数据的所有内容,OAuth2.0是OAuth协议的延续版本,但不向后兼容OAuth 1.0即完全废止了OAuth1.0。授权码模式(authorization code)密码模式(resource owner password credentials)客户端模式(client credentials) 不常用。
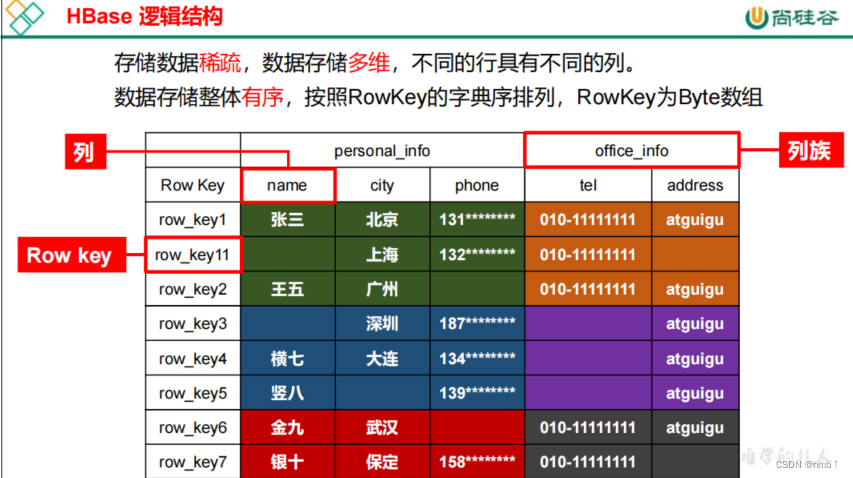
Springboot整合HBase——大数据技术之HBase2.x
Apache HBase 是以hdfs为数据存储的,一种分布式、可扩展的noSql数据库。是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase使用与BigTable(BigTable是一个稀疏的、分布式的、持久化的多维排序map)非常相似的数据模型。用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。

Docker部署SpringBoot项目详细部署过程
Docker可比喻成一个装应用的容器,将应用及其依赖文件、数据等打包在容器内,直接运行容器即可把应用运行起来,而无需关心环境配置问题。 本文记录个人学习Docker的总结内容,安装、配置和部署等内容,在过程中,应注意命令不要写错,加上Docker插件等问题,若出现理解不到位的地方,请多指出。

spring和springboot、springMVC有什么区别?
今天来聊一下,刚在面试中被问到的一个经典问题Spring 提供了广泛的功能用于企业级应用开发Spring Boot 简化了 Spring 应用的开发和部署Spring MVC 则是专注于构建 Web 应用的 MVC 框架在使用时,你可以根据项目需求选择合适的组件或组合使用它们。在很多现代的 Spring 应用中,特别是微服务架构中,Spring Boot 和 Spring MVC 经常一起使用。好了,以上就是本文的全部内容,如有问题欢迎留言讨论。
Spring Boot整合日期转换器(Converter)和拦截器(HandlerInterceptor)
配置文件形式针对框架进行个性化定制,例如:拦截器,类型转化器等等。WebMvcConfigurer配置类其实是。内部的一种配置方式,采用。
SpringBoot 使用过滤器、拦截器、切面(AOP),及其之间的区别和执行顺序
Servlet(Server Applet),全称是Java Servlet,是提供基于协议请求/响应服务的Java类。在JavaEE中是Servlet规范,即是指Java语言实现的一个接口,广义的Servlet是指任何实现了这个Servlet接口的Java类,一般人们理解是后者。是什么。
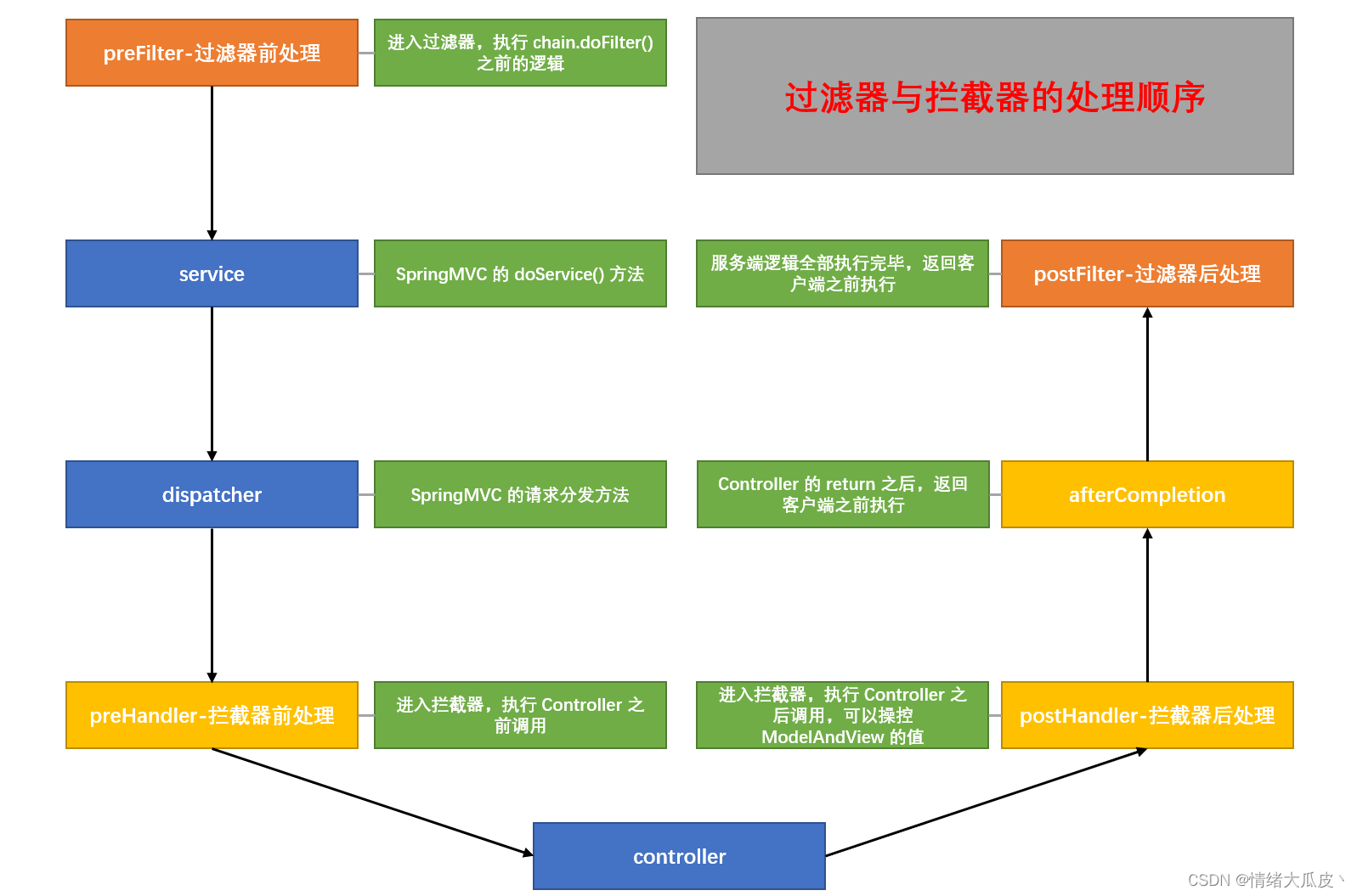
【总结】SpringBoot 中过滤器、拦截器、监听器的基本使用
拦截器是在面向切面编程中应用的,就是在你的service或者一个方法前调用一个方法,或者在方法后调用一个方法。是基于JAVA的反射机制。1)预处理preHandle()方法用户发送请求时,先执行preHandle()方法。会先按照顺序执行所有拦截器的preHandle方法,一直遇到return false为止,比如第二个preHandle方法是return false,则第三个以及以后所有拦截器都不会执行。若都是return true,则执行用户请求的url方法。2)后处理postHandle()方法。
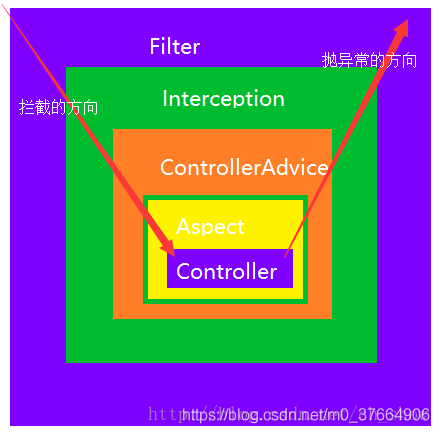
SpringBoot--过滤器/拦截器/AOP--区别/使用/顺序
本文介绍SpringMVC(SpringBoot)中的过滤器、拦截器、AOP的区别及其用法。 如果监听器、过滤器、 拦截器、 AOP都存在,则它们的执行顺序为:监听器 => 过滤器=> 拦截器=> AOP。
Spring boot 3 集成rocketmq-spring-boot-starter解决版本不一致问题
根据上篇文章使用Docker安装RocketMQ并启动之后,有个隐患详情见下文。如何解决rocketmq 和spring boot 3.x集成问题
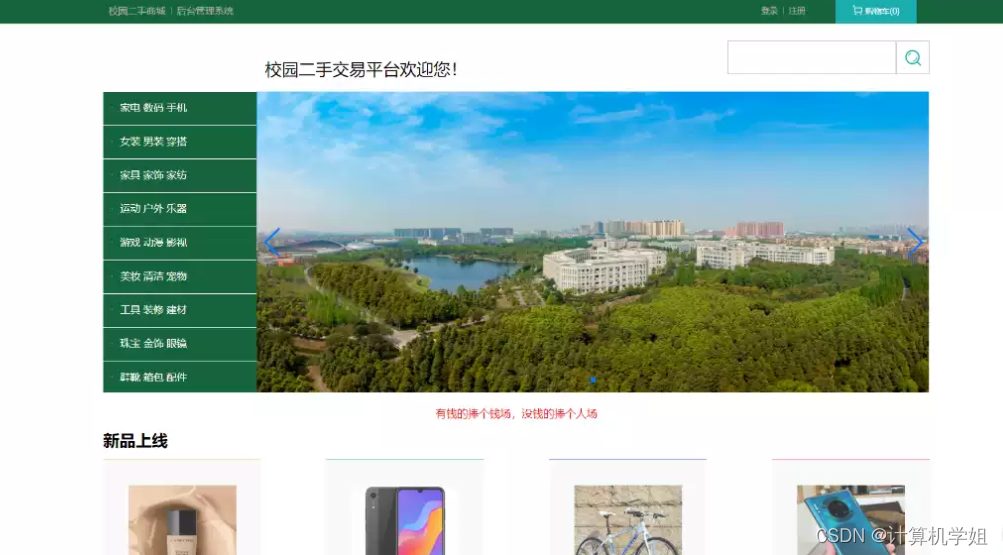
基于SpringBoot的校园二手闲置交易平台
基于SpringBoot的校园二手闲置交易平台的设计与实现~
SpringBoot 中获取 Request 的四种方法
Controller中获取request对象后,如果要在其他方法中(如service方法、工具类方法等)使用request对象,需要在调用这些方法时将request对象作为参数传入。如果其他方法(如工具类中static方法)需要使用request对象,则需要在调用这些方法时将request参数传递进去。下面介绍的方法4,则可以直接在诸如工具类中的static方法中使用request对象(当然在各种Bean中也可以使用)。该方法实现的原理是,在Controller方法开始处理请求时,对象是方法参数,相当于。
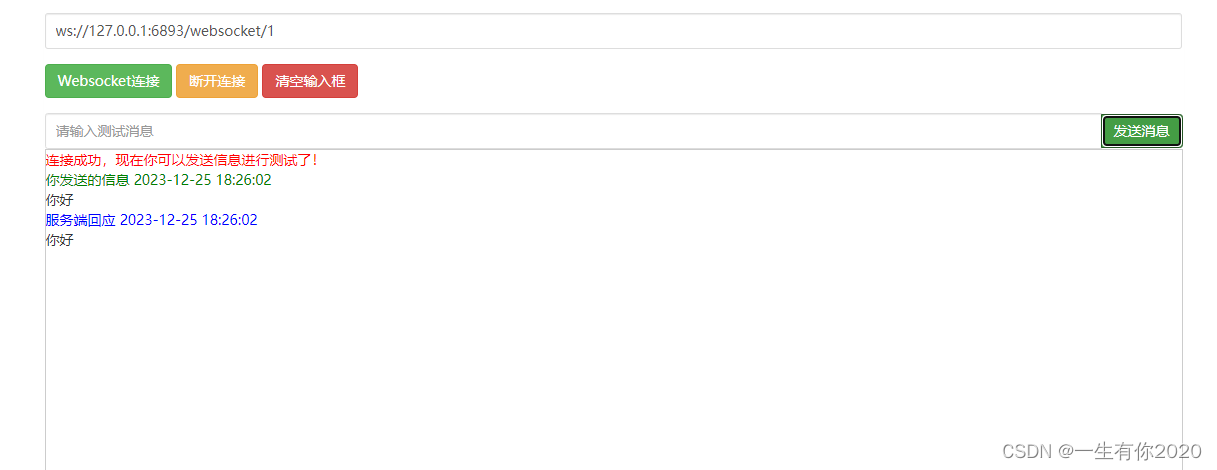
springboot对接WebSocket实现消息推送
项目上线需要https请求,把请求地址换成wss,需要通过nginx配置转发,再443端口加上如下配置。请求地址更换成wss://域名/wss/websocket/或者播放指定的音频文件,播放音频需要浏览器设置可以发放声音。2.增加配置WebSocketConfig.java。7.增加消息推送语音播放_文本转语音。3.创建一个WebSocket实例。6.前端对接WebSocket。4.修改启动类,添加注解。8.如何修改成wss请求。5.测试一下推送消息。
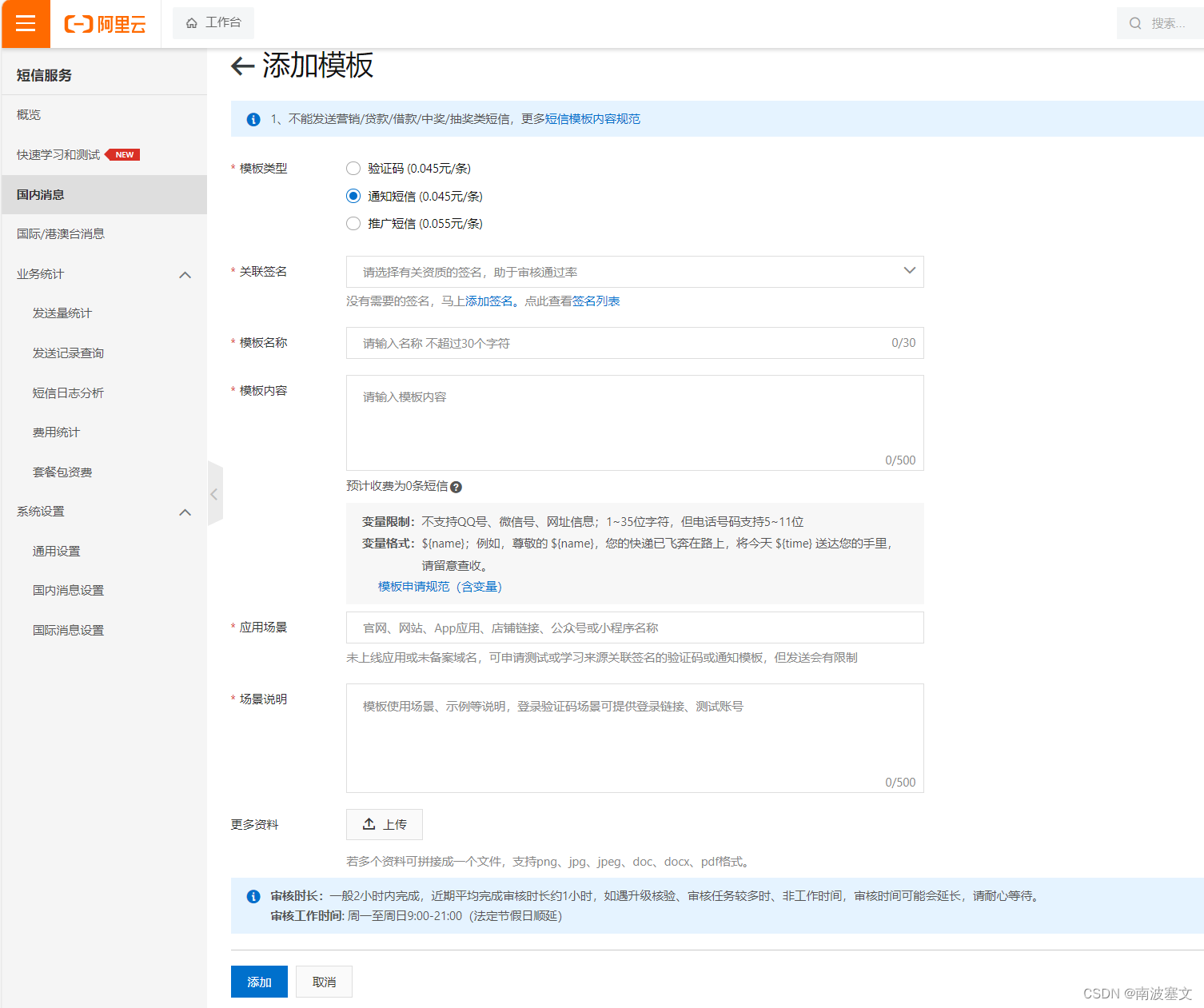
基于SpringBoot整合RocketMQ异步发送短信功能
上一篇文章记录了 RocketMQ 整体架构、安装部署、应用场景这三个内容。熟悉了 RocketMQ 相关核心概念后,本文记录基于 SpringBoot 整合 RocketMQ 异步发送短信功能,其中会引入阿里云短信服务相关内容。
利用systemd设置springboot微服务服务在linux重启后自启动
要使 Spring Boot 服务的 JAR 包在 Linux 重启后自启动,您可以使用systemd。

【Spring boot】RedisTemplate中String、Hash、List设置过期时间
putIfAbsent 指的是如果传入key对应的value已经存在,就返回存在的value,不进行替换。如果不存在,就添加key和value,返回null。如果传入key对应的value已经存在,就返回存在的value,不进行替换。如果不存在,就添加key和value,返回null。下面这两句话,可以实现向Redis插入Hash数据,并且设置整个Hash的过期时间。TimeUnit.MILLISECONDS:毫秒。TimeUnit.MILLISECONDS:微秒。TimeUnit.MINUTES:分。

SpringBoot进行自然语言处理,利用Hanlp进行文本情感分析
自然语言处理,或简称NLP,是处理和转换文本的计算机科学学科。它由几个任务组成,这些任务从标记化开始,将文本分成单独的意义单位,应用句法和语义分析来生成抽象的知识表示,然后再次将该表示转换为文本,用于翻译、问答或对话等目的。
Spring-Boot---项目创建和使用
Spring的诞生是为了简化Java程序开发的;而Spring-Boot的诞生是为了简化Spring程序开发的。快速集成框架:Spring-Boot提供了启动添加依赖的功能,用于秒级集成各种框架内置运行容器:内置了Tomcat等Web容器,无需配置可以直接运行和部署快速部署项目:更方便的把项目部署到云服务器上完全抛弃繁琐的XML:使用注解和配置的方式进行开发支持更多的监控指标:可以更好的了解项目的运行情况我们自己要创建的类要放在和启动类的同级目录下,如果不在同级运行时会报错。
微信小程序完整实现微信支付功能(SpringBoot和小程序)
然后到提供前端调用支付路由的类,WechatController类,注意我这里路由拼接的有/wechat/pay/notify,这个要和之前配置yml文件的支付回调函数一样,要不然不行。不久前给公司实现支付功能,折腾了一阵子,终于实现了,微信支付对于小白来说真的很困难,特别是没有接触过企业级别开发的大学生更不用说,因此尝试写一篇我如何从小白实现微信小程序支付功能的吧,使用的后端是SpringBoot。效果如下,这里因为我的手机不能截图支付页面,所以用的开发者工具支付的效果,都是一样的。4.前端(小程序端)

SpringBoot整合Kafka (二)
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。

SpringBoot整合Kafka (一)
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。