机器学习数据拆分_解释了关键的机器学习概念-数据集拆分和随机森林
机器学习数据拆分
数据集分割 (Dataset Splitting)
Splitting up into Training, Cross Validation, and Test sets are common best practices. This allows you to tune various parameters of the algorithm without making judgements that specifically conform to training data.
分为培训,交叉验证和测试集是常见的最佳实践。 这使您可以调整算法的各种参数,而无需做出专门符合训练数据的判断。
动机 (Motivation)
Dataset Splitting emerges as a necessity to eliminate bias to training data in ML algorithms. Modifying parameters of a ML algorithm to best fit the training data commonly results in an overfit algorithm that performs poorly on actual test data. For this reason, we split the dataset into multiple, discrete subsets on which we train different parameters.
数据集拆分是消除ML算法中训练数据偏差的必要条件。 修改ML算法的参数以最适合训练数据通常会导致过拟合算法,该算法在实际测试数据上的表现不佳。 因此,我们将数据集分为多个离散子集,在这些子集上训练不同的参数。
训练集 (The Training Set)
The Training set is used to compute the actual model your algorithm will use when exposed to new data. This dataset is typically 60%-80% of your entire available data (depending on whether or not you use a Cross Validation set).
训练集用于计算算法在暴露给新数据时将使用的实际模型。 该数据集通常占整个可用数据的60%-80%(取决于您是否使用交叉验证集)。
交叉验证集 (The Cross Validation Set)
Cross Validation sets are for model selection (typically ~20% of your data). Use this dataset to try different parameters for the algorithm as trained on the Training set. For example, you can evaluate different model parameters (polynomial degree or lambda, the regularization parameter) on the Cross Validation set to see which may be most accurate.
交叉验证集用于模型选择(通常约占数据的20%)。 使用此数据集尝试对训练集上训练的算法使用不同的参数。 例如,您可以在“交叉验证”集上评估不同的模型参数(多项式或lambda,正则化参数),以查看哪个模型参数最准确。
测试集 (The Test Set)
The Test set is the final dataset you touch (typically ~20% of your data). It is the source of truth. Your accuracy in predicting the test set is the accuracy of your ML algorithm.
测试集是您接触的最终数据集(通常是数据的约20%)。 这是真理的源头。 预测测试集的准确性就是ML算法的准确性。
随机森林 (Random Forest)
A Random Forest is a group of decision trees that make better decisions as a whole than individually.
随机森林是一组决策树,它们总体上比单独决策更好。
问题 (Problem)
Decision trees by themselves are prone to overfitting. This means that the tree becomes so used to the training data that it has difficulty making decisions for data it has never seen before.
决策树本身很容易过度拟合 。 这意味着树变得非常习惯于训练数据,以至于难以为从未见过的数据做出决策。
随机森林的解决方案 (Solution with Random Forests)
Random Forests belong in the category of ensemble learning algorithms. This class of algorithms use many estimators to yield better results. This makes Random Forests usually more accurate than plain decision trees. In Random Forests, a bunch of decision trees are created. Each tree is trained on a random subset of the data and a random subset of the features of that data. This way the possibility of the estimators getting used to the data (overfitting) is greatly reduced, because each of them work on the different data and features than the others. This method of creating a bunch of estimators and training them on random subsets of data is a technique in ensemble learning called bagging or Bootstrap AGGregatING. To get the prediction, the each of the decision trees vote on the correct prediction (classification) or they get the mean of their results (regression).
随机森林属于集成学习算法的类别。 这类算法使用许多估计器来产生更好的结果。 这使得随机森林通常比普通决策树更准确 。 在随机森林中,创建了一堆决策树。 每棵树都在数据的随机子集和数据特征的随机子集上训练 。 这样,估计器习惯于数据(过度拟合)的可能性就大大降低了,因为它们每个都处理不同的数据和特征 。 创造了一堆估计和训练他们对数据的随机子集的这种方法是在集成学习称为装袋或引导聚集的技术。 为了获得预测,每个决策树都对正确的预测(分类)进行投票,或者获取结果的均值(回归)。
在Python中提升的示例 (Example of Boosting in Python)
In this competition, we are given a list of collision events and their properties. We will then predict whether a τ → 3μ decay happened in this collision. This τ → 3μ is currently assumed by scientists not to happen, and the goal of this competition was to discover τ → 3μ happening more frequently than scientists currently can understand. The challenge here was to design a machine learning problem for something no one has ever observed before. Scientists at CERN developed the following designs to achieve the goal. https://www.kaggle.com/c/flavours-of-physics/data
在这次比赛中,我们给出了碰撞事件及其属性的列表。 然后,我们将预测在此碰撞中是否发生了τ→3μ衰减。 科学家目前认为τ→3μ不会发生,并且该竞赛的目的是发现τ→3μ的发生比科学家目前所能理解的更为频繁。 这里的挑战是设计一种机器学习问题,以解决以前从未见过的问题。 欧洲核子研究中心的科学家开发了以下设计来实现这一目标。 https://www.kaggle.com/c/flavours-of-physics/data
#Data Cleaning
import pandas as pd
data_test = pd.read_csv("test.csv")
data_train = pd.read_csv("training.csv")
data_train = data_train.drop('min_ANNmuon',1)
data_train = data_train.drop('production',1)
data_train = data_train.drop('mass',1)#Cleaned data
Y = data_train['signal']
X = data_train.drop('signal',1)#adaboost
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
seed = 9001 #this ones over 9000!!!
boosted_tree = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1), algorithm="SAMME", n_estimators=50, random_state = seed)
model = boosted_tree.fit(X, Y)predictions = model.predict(data_test)
print(predictions)
#Note we can't really validate this data since we don't have an array of "right answers"#stochastic gradient boosting
from sklearn.ensemble import GradientBoostingClassifier
gradient_boosted_tree = GradientBoostingClassifier(n_estimators=50, random_state=seed)
model2 = gradient_boosted_tree.fit(X,Y)predictions2 = model2.predict(data_test)
print(predictions2)翻译自: https://www.freecodecamp.org/news/key-machine-learning-concepts-explained-dataset-splitting-and-random-forest/
机器学习数据拆分
相关文章:
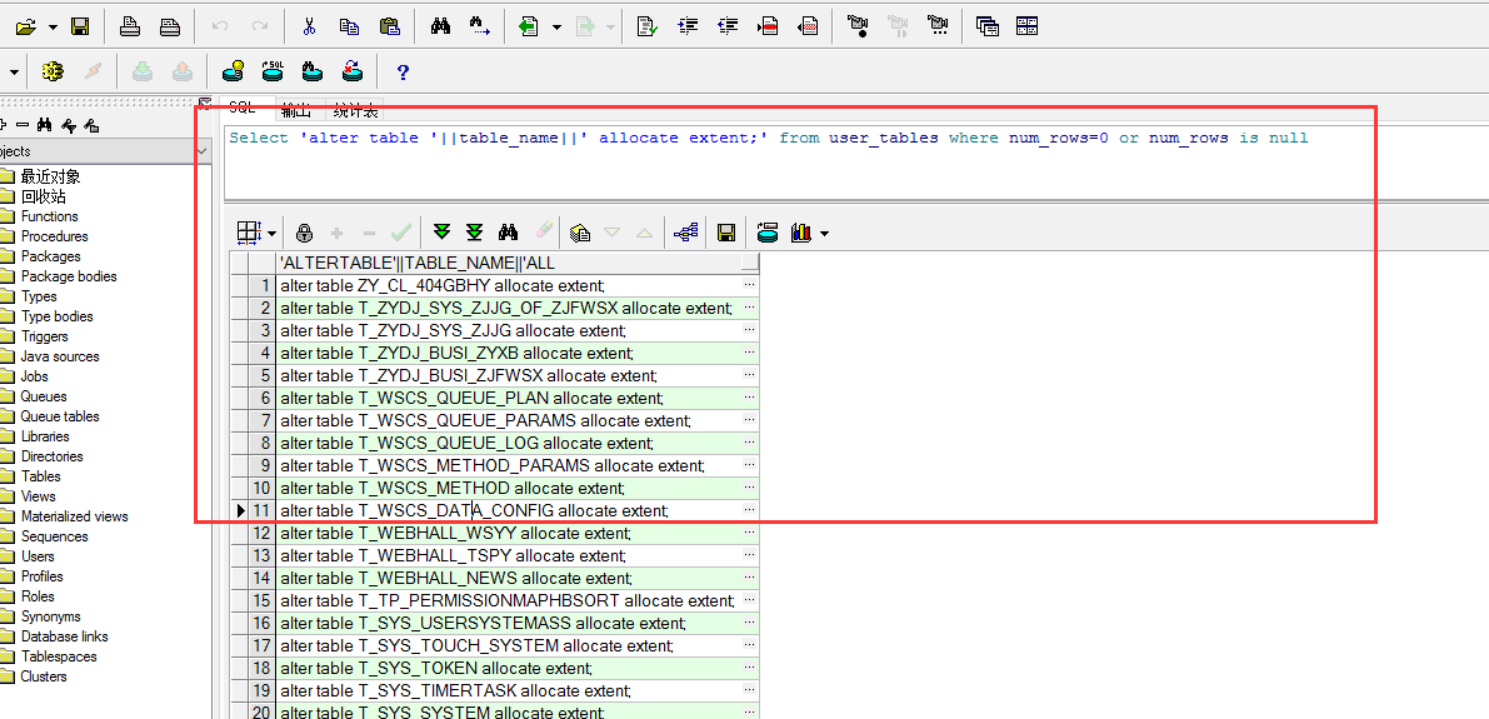
Oracle 导表异常处理方案 (解决空表导出出错问题)
Select alter table ||table_name|| allocate extent; from user_tables where num_rows0 or num_rows is null 然后执行查询语句 再导出数据 一个语句搞定: declare stmt varchar2(200); begin for tb in (select table_name from user_tables where seg…

10个你必须知道的ios框架
你好,iOS 开发者们!我的名字叫 Pawe?,我是一个独立 iOS 开发者,并且是 Enter Universe 的作者。 接近两年前我发布了iOS开源库,让你的开发坐上火箭吧。这是我在这里最棒的文章了(根据 Medium 用户的反馈来…

生成N个不相等的随机数
近期项目中须要生成N个不相等的随机数。实现的时候。赶工期,又有项目中N非常小(0-100)直接谢了一个最直观的方法: public static List<Integer> randomSet(int num,int threshold){Random random new Random();if(num > threshold) return null;Set<In…
kafka streams_如何使用Kafka Streams实施更改数据捕获
kafka streamsChange Data Capture (CDC) involves observing the changes happening in a database and making them available in a form that can be exploited by other systems. 更改数据捕获 (CDC)涉及观察数据库中发生的更改,并将其以可被其他系统利用的形式…
iOS超全开源框架、项目和学习资料汇总(1)UI篇
上下拉刷新控件**1. ** MJRefresh --仅需一行代码就可以为UITableView或者CollectionView加上下拉刷新或者上拉刷新功能。可以自定义上下拉刷新的文字说明。(推荐)**2. ** SVPullToRefresh --下拉刷新控件4500star,值得信赖**3. ** CBStoreHo…

day16 递归函数
一、递归 函数 为什么要有函数,提高代码的可读性,避免重复的代码,提高代码的复用性 在函数中能用return的不要print 1、递归的最大深度997 def foo(n):print(n)n1foo(n) foo(1) 递归的最大深度2、修改递归的最大深度 由此我们可以看出&#x…
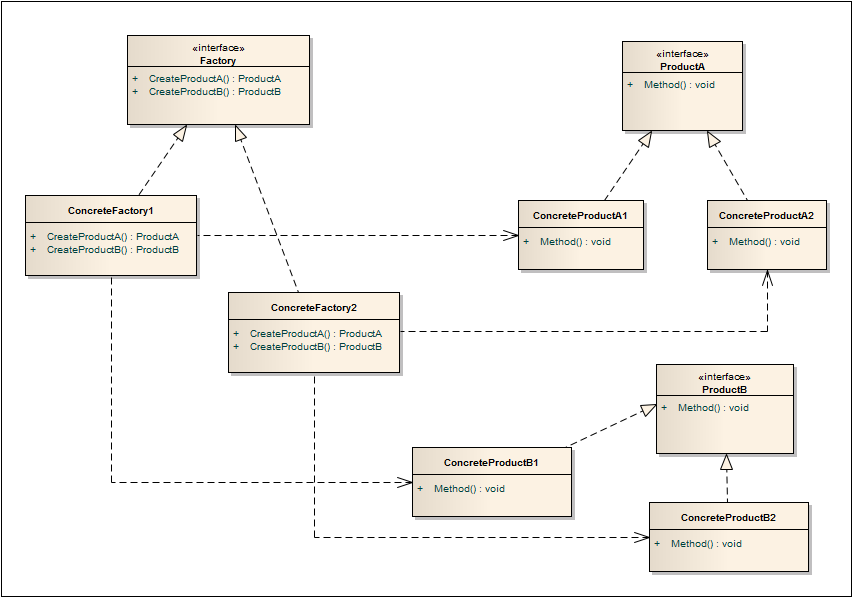
设计模式之笔记--抽象工厂模式(Abstract Factory)
抽象工厂模式(Abstract Factory) 定义 抽象工厂模式(Abstract Factory),提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。 类图 描述 多个抽象产品类,每个抽象产品类可以派…
用户体验改善案例_如何检测用户的设备,以便改善他们的用户体验
用户体验改善案例A few months ago I watched a great talk from the Chrome Dev Summit about performance in slow devices.几个月前,我观看了Chrome开发者峰会上有关慢速设备性能的精彩演讲。 It blew my mind all the work done by Facebook in identifying de…

【如何快速的开发一个完整的iOS直播app】(采集篇)
前言在看这篇之前,如果您还不了解直播原理,请查看这篇文章如何快速的开发一个完整的iOS直播app(原理篇)开发一款直播app,首先需要采集主播的视频和音频,然后传入流媒体服务器,本篇主要讲解如何采集主播的视频和音频&am…

easyui 报表合并单元格
前段时间工作中碰到有需求,要求数据按下图所示格式来显示,当时在园子里看到了一篇文章(时间久了,想不起是哪一篇),研究了后做出了如下的DEMO,在此当作学习笔记,简单记录一下。 首先是…
HDU2594 KMP next数组的应用
这道题就是给你两个串s1, s2让你求出s1 s2的最长相同前缀和后缀, 我们直接将s1 s2连接到一起然后处理一下next数组即可, 注意答案应该是min(len(s1), len(s2) , next[len]), 代码如下: #include <cstdio> #include <cstring> #in…
c语言中浮点数和整数转换_C中的数据类型-整数,浮点数和空隙说明
c语言中浮点数和整数转换C中的数据类型 (Data Types in C) There are several different ways to store data in C, and they are all unique from each other. The types of data that information can be stored as are called data types. C is much less forgiving about d…

【如何快速的开发一个完整的iOS直播app】(美颜篇)
前言在看这篇之前,如果您还不了解直播原理,请查看这篇文章如何快速的开发一个完整的iOS直播app(原理篇)开发一款直播app,美颜功能是很重要的,如果没有美颜功能,可能分分钟钟掉粉千万,本篇主要讲解直播中美颜…

Linux内核分析——第五章 系统调用
第五章 系统调用 5.1 与内核通信 1、系统调用在用户空间进程和硬件设备之间添加了一个中间层,该层主要作用有三个: (1)为用户空间提供了一种硬件的抽象接口 (2)系统调用保证了系统的稳定和安全 (…
BZOJ 3110
http://www.lydsy.com/JudgeOnline/problem.php?id3110 整体二分区间修改树状数组维护 #include<cstdio> #define FOR(i,s,t) for(register int is;i<t;i) inline int max(int a,int b){return a>b?a:b;} inline int min(int a,int b){return a<b?a:b;} type…
css 选择器 伪元素_CSS伪元素-解释选择器之前和之后
css 选择器 伪元素选择器之前 (Before Selector) The CSS ::before selector can be used to insert content before the content of the selected element or elements. It is used by attaching ::before to the element it is to be used on.CSS ::before选择器可用于在选定…
各种面试题啊1
技术 基础 1.为什么说Objective-C是一门动态的语言? 什么叫动态静态 静态、动态是相对的,这里动态语言指的是不需要在编译时确定所有的东西,在运行时还可以动态的添加变量、方法和类 Objective-C 可以通过Runtime 这个运行时机制,…
PEP8 Python
写在前面 对于代码而言,相比于写,它更多是读的。 pep8 一、代码编排 缩进,4个空格的缩进,编辑器都可以完成此功能;每行最大长度79,换行可以使用反斜杠,换行点要在操作符的后边。类和top-level函…
粒子滤波 应用_如何使用NativeScript开发粒子物联网应用
粒子滤波 应用If youre developing any type of IoT product, inevitably youll need some type of mobile app. While there are easy ways, theyre not for production use.如果您要开发任何类型的物联网产品,则不可避免地需要某种类型的移动应用程序。 尽管有简单…

wkwebView基本使用方法
WKWebView有两个delegate,WKUIDelegate 和 WKNavigationDelegate。WKNavigationDelegate主要处理一些跳转、加载处理操作,WKUIDelegate主要处理JS脚本,确认框,警告框等。因此WKNavigationDelegate更加常用。 比较常用的方法: #p…
引用类型(一):Object类型
对象表示方式 1、第一种方式:使用new操作符后跟Object构造函数 var person new Object();<br/> person.name Nicholas;<br/> person.age 29; 2、对象字面量表示法 var person {name:Nicholas,age:29 } *:在age属性的值29的后面不能添加逗号…
(第四周)要开工了
忙碌的一周又过去了,这周的时间很紧,但是把时间分配的比较均匀,考研复习和各门功课都投入了一定的精力,所以不像前三周一样把大多数时间都花费在了软件工程上。也因为结对项目刚开始,我们刚刚进行任务分工以及查找资料…
统计数字,空白符,制表符_为什么您应该在HTML中使用制表符空间而不是多个非空白空间(nbsp)...
统计数字,空白符,制表符There are a number of ways to insert spaces in HTML. The easiest way is by simply adding spaces or multiple character entities before and after the target text. Of course, that isnt the DRYest method.有多种方法可以在HTML中插入空格。…
Python20-Day02
1、数据 数据为什么要分不同的类型 数据是用来表示状态的,不同的状态就应该用不同类型的数据表示; 数据类型 数字(整形,长整形,浮点型,复数),字符串,列表,元组…
Android网络框架-OkHttp3.0总结
一、概述 OkHttp是Square公司开发的一款服务于android的一个网络框架,主要包含: 一般的get请求一般的post请求基于Http的文件上传文件下载加载图片支持请求回调,直接返回对象、对象集合支持session的保持github地址:https://githu…
第一天写,希望能坚持下去。
该想的都想完了,不该想的似乎也已经尘埃落定了。有些事情,终究不是靠努力或者不努力获得的。顺其自然才是正理。 以前很多次想过要努力,学习一些东西,总是不能成,原因很多: 1.心中烦恼,不想学…
mac gource_如何使用Gource显示项目的时间表
mac gourceThe first time I heard about Gource was in 2013. At the time I watched this cool video showing Ruby on Rails source code evolution:我第一次听说Gource是在2013年 。 当时,我观看了这段很酷的视频,展示了Ruby on Rails源代码的演变&a…
insert语句让我学会的两个MySQL函数
我们要保存数据到数据库,插入数据是必须的,但是在业务中可能会出于某种业务要求,要在数据库中设计唯一索引;这时如果不小心插入一条业务上已经存在同样key的数据时,就会出现异常。 大部分的需求要求我们出现唯一键冲突…
对PInvoke函数函数调用导致堆栈不对称。原因可能是托管的 PInvoke 签名与非托管的目标签名不匹配。...
C#引入外部非托管类库时,有时候会出现“对PInvoke函数调用导致堆栈不对称。原因可能是托管的 PInvoke 签名与非托管的目标签名不匹配”的报错。 通常在DllImport标签内加入属性CallingConventionCallingConvention.Cdecl即可解决该问题。 如: [Dll…