三十之惑–面霸的八月(第二部分)
书接上回,今天叙述小米的面试经历。
这里可能有一些技术理解和技术方案,欢迎讨论。另昨天共计收入7笔共95元,够我喝几杯咖啡了,谢谢所有捐钱的朋友。
如果你心疼我码字辛苦,有钱朋友钱场,没钱的请拉朋友来捧个钱场,捧场链接:https://me.alipay.com/chunshengster ,多少不限
小米:
- 运维部
在小米是聊了两个部门的,首先是运维部门,在 @wilbur井源 的热情招待下,吃了顿大餐,抱歉的是我没有带足现金,所以付款时我无法“客气”,改天补请。
wilbur井源同两位同事与我四人边吃边聊,我简单介绍当前的网站的服务结构以及部分业务的技术设计,比如网站架构的分布情况,分布式文件系统fastDFS的使用状况、Redis和MySQL的一些部署结构和技术,其中尤其对监控这件事情我做了详细一些的说明(详见服务可用性监控的一些思考以及实践),中间提到了关于主动监控(主动监控是指通过运维和业务部门指定监控的系统资源、接口、页面、日志等,主动发现问题,警报级别较高)、被控监控的概念(指通过JSlib或客户端lib对于所有的操作尤其是网络接口的请求进行监控,对异常进行汇报,通过收集日志的方式进行可用性问题的发现)。当然,还有必不可少的是对haproxy的运行和优化状况(参见Haproxy配置),MySQL的架构及优化方式(见MySQL架构及运维),Redis常见的性能问题(参见redis架构及运维问题),fastDFS同其他分布式存储MogileFS、TFS、lusterfs的在功能、运维成本上的横向比较,多IDC图片cache的部署以及性能优化(参见多idc图片Cache部署),Linux内核参数(参见Linux内核配置)和让我特别自豪的是关于网卡smp affinity/RPF/RFS的优化效果(参考3/4/5)的一些优化等。当然,这是正经的运维部门,我阐述了我对“运维”工作的理解:60%的分析整理工作加上40%的技能,分析整理能力是做好运维的基础。
井源也询问了几个安全问题,我粗浅的理解是:从SA的经历来讲,做好IT系统规划,合理区分服务器角色,通过iptables是能够阻止大多数接入层非法请求的;对于web业务的安全来讲,SQL注入、CRSF等攻击是因为对输入输入内容的过滤不严格导致的,在开发的过程中合理使用一些优秀框架或lib,也能够避免大多数漏洞的产生;有个比较有意思的话题是关于溢出的,现在我已经不会计算溢出地址了,在我当script boy的时候研究过一点,忘光光了,惭愧……
井源这边的效率很好,边吃边聊的气氛很放松,不过很多问题都停留在一些思路和效果数据上,没有勾勾画画的太多深入的探讨。
- 电商部
大约8点半左右到的电商部门,常规面试的第一轮都是技术,包括细节。面试官是位张姓的team leader。
在这轮面试的过程中,因为是在会议室,有笔有板,所以我边讲边写。大体上介绍了我对web服务架构的理解,我认为,web服务架构大体上离不开这样几个层面:接入层(负载均衡)、业务服务层、数据层,一般还会有不少的后台辅助程序进行同步、异步的处理各种不适合在业务层融合的服务单元。数据层可以包括DB、Cache、File等,数据层还可能会有很多中间件或代理服务器用来做数据层的负载均衡或是HA,以及Sharding等。同面试官详细介绍了当前服务的公司在每一层所采用的技术,分别是:haproxy、nginx+php、twemproxy+redis、MySQL+RedisCache、Varnish+Squid+nginx+fastDFS。
haproxy的服务器配置是按照100w并发的目标进行配置和优化的,计划100w客户端连接,考虑每个客户端连接可能产生1个内部连接,按照每个连接消耗4k内存来算,大约8G内存,实际上往往比这个数字要大。目前达到的最大连接数目测到过16w,在接入层的系统优化上分别有:网卡中断优化(参考3/4/5),linux 内核参数优化(见linux sysctl.conf配置)。
值得一提的是,我们的haproxy服务器都是64G内存,实际上远远永不到这么多,图片服务的最外层cache,即Varnish,我们也是部署在haproxy服务器上的。
在最外层服务器上,我们每天大约5亿+(1-1.5亿+的动态请求、3-4亿+的图片请求)的请求量,共计使用7台64G的Dell R410,目前看负载还很低,从系统的各种资源上看,请求量翻倍应该是没有问题的。
在最外层的服务器配置上,有一个问题值得注意,即sysctl.conf的配置中,timestamp必须为0,这个在tcp协议的扩展标准中有提到,否有nat环境的客户端连接有可能产生异常,异常的状况可以在netstat -s 的输出中看到。还需要注意的是timestamp=0的情况下,tw_reuse是不生效的。
要保证服务器能够接收大并发的连接请求是件不难的事情,但需要考虑一个细节,每接收一个请求,haproxy就需要至少分配一个系统的tcp端口请求后面的业务服务器、cache服务器,系统一个ip地址可用的端口数最多为65535,一般还需要减去1024。值得考虑的是减小 tw_bucket 的容量,让系统在tw_bucket满的状况下,对tw状态的连接进行丢弃,以达到快速回收的目的,tw的默认回收时间的2倍的MSL。还有一个方式就是多配置几个ip。
还有一个问题,接入层的服务器往往会开启iptables,内核中nf的相关配置也是需要优化的,比如 nf_conntrack_max、nf_conntrack_tcp_timeout_established等。
在业务层的优化有nginx+php(fastcgi连接方式、php-fpm.conf配置中的优化),我的一个经验是,如果nginx同phpcgi运行在同一台服务器,采用unix socket的方式进行fastcgi协议的交互是效果最快的,比127.0.0.1的回环地址要快太多。我在08年优化过一台服务器(Dell 2960,16G内存),通过两个步骤,将一台服务器从900qps,优化到6000qps以上,其一是将fastcgi协议运行在unix socket上,其二是合理配置spawn-fcgi的进程数量。现在基本上phpcgi都是运行在php-fpm中的了,其进程池逻辑是我最赞赏的功能之一。
如果nginx和php-fpm不在同一台服务器上,可以考虑使用fastcgi_keepalive的配置,实现nginx同fastcgi服务器持久连接,以提高效率。
nginx+php-fpm提供的运行状态非常有意义,nginx的status模块和php-fpm的status输出可以告诉我们nginx进程的请求处理状况,php-fpm的status输出可以告诉我们php-fpm的进程池设置是否合理。我们目前对这两个数据通过nagios定期采集,并绘制成图表,很有“观赏价值”。
php-fpm.conf的配置中还有几个参数对优化比较重要,其一是进程自动重启的条件pm.max_requests,其二是php-slow log的配置,slow log 是优化php代码的非常重要的信息。在我目前的环境中,php的慢执行日志是通过rsyslog进行传输并集中分析的,以此反向推进开发对php代码的优化。
php的服务器在高并发的情况下,有可能因为服务器本身可提供的端口数量的限制,无法同redis服务器建立大量的连接,这时候可以在sysctl.conf中配合timestamps=1 加上tw_reuse/tw_recycle的方式,进行端口快速回收,以便更好的向数据层建立连接,接入层的haproxy是不可以这样的。
这一层还涉及到一个安全问题,就是php代码被修改并挂马的状况,我的解决方案是,将php-fpm的运行用户同php代码的属主设置成不同的用户,并且保证php-fpm的运行用户不能对php代码具有写的权限。
数据层的情况里,MySQL主从结构以及MHA+keepalived的高可用配置,这个基本上是看文档应该就能够理解的。如果是5.6的新版MySQL,其高可用监控可能可以做的更简单,MySQL官方提供对应的工具,只是我还没有测试。对MHA的监控功能,我觉得亮点是MHA对切换过程中MySQL binlog的获取和执行,在最大程度上避免了数据丢失。但是其缺点也是有的,比如:监控进程在触发切换后就停止了,一旦触发,必须重新启动进程再继续监控。06年时我在sina做过一个叫Trust DMM的项目,通过 DNS、MON加上自己写的插件,监控MySQL主从集群的可用性,可以实现,主库、主备自动切换(缺乏binlog处理的环节);从库是一组服务器,如果从库发生问题,可以自动下线。只是这套系统部署起来比较麻烦。这个项目曾经获得过sina的创新一等奖。
我还提到了我认为的DBA日常的工作至少应该包括:审查并执行上线SQL;定期检查MySQL慢日志并分析,将分析结果反馈到开发部门进行调整;定期审查数据库中索引的效率以及可用性,进行优化我反馈。现在做一个一般水平的DBA已经相当容易了,对percona的工具了解透彻,已经能够解决非常多的数据库问题了。
MySQL还有一个难缠的问题,numa架构下,大内存服务器内存使用效率的问题,numactl对策略进行调整,如果使用percona的MySQL版本,可以通过 memlock配置对MySQL的Innodb引擎进行限制,禁止其使用swap。
MySQL常见的架构里,还有一种主从存储引擎不一致的方式,即主库采用Innodb引擎,提高并发写入的能力,从库采用Myisam引擎,这种方式目前我们也在采用。这样做一是为了获取更好的读性能,另外是,Myisam引擎的是可以节省内存的。Myisam在索引数据内存读取,数据内容磁盘读取的状态下,已经可以比较高效的运行了,myisam_use_mmap的配置项,会让MySQL将myisam的data文件也mmap到内存中,这样做既高效,又可以使用mysiam引擎的特性。
数据库主库要避免一件事情发生,就是无条件删除和无条件修改,如“delete from table”以及”update table set xxx=yyyy”等无where条件语句,原则来讲是应该禁止执行的,这样的权限不应该开放给开发的同学,甚至DBA都不能无限制的操作。目前我的解决方案是 sql_safe_updates=1,但这配置是不能够写my.cnf中的,只能启动mysql后进入console进行配置。
当前我们还使用了Redis作为DB,基于主从架构,跨IDC。目前的问题是,复制连接断开后,Redis快照重传的问题,从库会在快照替换期间有短暂的性能抖动。 Redis2.8新版本psync的特性应该可以改善这个问题。我们还使用twemproxy,目前部署在每一台php服务器上,并监听unix socket,php使用phpredis的模块进行连接。有效减少三次握手的时间。temwproxy还有很多其他的优秀特性,通过一致性hash做cache集群,可以有效的避免cache迁移问题。通过其对后端redis的健康监控,可以自动下线有故障的redis。
还有针对多IDC的图片存储和Cache部署情况。目前我们自建的图片CDN承载网站每天约4亿的请求,带宽最高峰值约1.5G左右,其结构大体上是中心IDC存储图片原图+SQUID disk cache存储图片缩略图,在外地IDC使用两级缓存,分别为一层SQUID disk cache(两台,做HA),另一层为Varnish cache(最多四台),实际上,如果仅考虑work around的状态,squid cache层基本上也可以不要的。但是,目前这样的结构可以减少varnish回中心节点的请求,减少中心机房带宽的压力。这个结构还算简单,varnish在高并发请求下,有一些资源配置是需要注意的,比如NFILES / VARNISH_MAX_THREADS / nuke_limit 等。
沟通的技术问题还是非常多的,包括在井源那里提到监控框架的事情,也尤其提到了我对rsyslog的优化,优化后的rsyslog在可靠性方面是非常值得称赞的(优化思路见参考6)
我有一些将电商三面的运维运维同学的问题综合到这里了,有些话重复的就不再描述。
值得一提的是二面是另一位开发负责人,一看就是个很有独立思考能力的同学,他问了我一个很有意思的问题,大体的意思是,在系统架构方面,有这样的几个层次,从下往上:使用开源、精通开源,优化并修改开源软件,创造开源软件。问我自己评价我是在哪一个层次的。我认真的思考了一下,我应该是在第二个层次,有些精通的,有些修改过的。
电商四面是时间最长的,至少有两个小时以上,结束的时候已经是夜里一点四十了,我觉得电商的老大是应该在支付宝里面给我捐一些钱才好的 ,不知道有没有小米的同学能够转告哈 ![]() 。我们应该是谈到了非常多的事情,包括秒杀的解决方案,包括对持续集成和自动化测试的理解、对后台数据业务类型的开发中数据计算错误的理解,时不时能够得到“我们想的很一致”这样的评价。
。我们应该是谈到了非常多的事情,包括秒杀的解决方案,包括对持续集成和自动化测试的理解、对后台数据业务类型的开发中数据计算错误的理解,时不时能够得到“我们想的很一致”这样的评价。
那时已近半夜,记忆进入低效态,一些太琐碎的事情记不得了,重复的技术方案也不再赘述。下面简单描述一下我对秒杀的解决方案的理解:10w的数据,从0到10w,不能多卖。目前的问题是,每次到秒杀时分可能同时进入100w的请求/连接。如何破?
我的方案是:排除user、session等外部依赖服务的前提下,两台ha外面抗并发连接(后来想这个无所谓的,不如做成php的服务器),三台PHP服务器(不要使用任何框架,最朴素的纯粹PHP代码),两台Redis(最初说了一台)。具体优化状况如下:
- haproxy优化能够支持百万并发连接,这个很容易了
- nginx优化worker connections,优化nginx的并发支持能力和请求队列的接收能力
- php-fpm优化listen.backlog,优化fastcgi请求队列的接收能力。
- Redis 假如在秒杀的1分钟内,服务器不出现故障,优化redis的最大连接数
- 优化所有服务器的网卡、sysctl参数
php的逻辑可以简单的理解为对redis的某一个key进行incr原子操作,如果返回的当前数值小于等于10w(两台redis的情况下应小于等于5w),则认为中签。
从我以前看到的数据来讲,redis的最好状态在8w qps。nginx+php在08年时已经优化到6000 qps,目前的服务器设备(双核16cpu+64G内存)达到2、3wQps应该也是不难的事情(这个的最新数据我不知道)。上述配置至少应该能够在5s内完成10w次redis的incr操作。加上系统各系统对请求队列的支持,可以几乎做到不报错,短暂延迟。
如果考虑1台redis请求量会很高,可以考虑分片,每台分5w。
当然,这是在仅仅思考不到1分钟内给出的方案,从现在来看,haproxy是可以不要,nginx扛并发连接的能力也不错。所有的细节还需要通过压力测试进行验证。而实际情况加上对其他服务的依赖(我不知到还有哪些,抽丝剥茧去除干扰),方案也会更加复杂一些。据电商老大讲,实际情况是,秒杀的服务用了十几台服务器,秒杀的时候偶尔出现一些故障,小米做秒杀的同学,压力很大哦。
如果你提到要记录中签的用户的uid和中签号码,还是redis吧。
(突然wps的linux版崩溃了,只能恢复到这里,后面的部分内容是重写的,可能有点混乱)
针对刚才的问题,我在白板上画了个简单的架构图:haproxy+nginx/php+redis,haproxy和nginx/php都是可线性扩展的,redis可以通过sharding来实现扩展。理论上讲,一个可扩展的架构是可以满足任何性能要求的,更何况如此简单的逻辑,单机性能已经可以做到非常高了。
电商王姓负责人在问我方案时问这个需求会有哪些难点?我看着白板笑笑:目前看,应该不存在难点。如果有问题,应该看日志和服务状态以及服务器状态。
第四面聊得很头机,对方几次想结束时都突然冒出来一个问题,每一个都会讨论比较久,比如后台的一些计算操作是否换成java更合适,因为java可以更严谨。我说这可能不是语言的问题,而是程序员习惯和素质的问题,如果想换,其实我倒是更愿意尝鲜,比如用go,还可能可以同时满足性能的问题。
还有突然聊到持续集成,我坦言,我对持续集成的理解停留在用工具实现自动测试和发布这样的层面上,没有实操经验。但我个人的一个粗浅的认知是:持续集成的前提是自动化测试,自动化测试的两个难点:1,自动化测试用例的设计;2,程序员对自动化测试的理解和心理反抗程度。我在目前单位有过短暂的尝试:专业的传统测试人员对测试用例进行设计,程序员接收到的需求应该包括正向逻辑的产品需求和测试用例的需求。开发工作完成的标记是:自己写的测试用例在自己的代码上完全通过,代表自己一项开发工作的完成。
说到这里,对方不禁双手伸出拇指!(哈哈哈哈)
或多或少也还有一些别的话题,我自认为那晚像演讲一样很精彩,只不过时间已过午夜,其他的一些细节不太记得了,如果想起或小米参加面试的同学有提起,我再补充了。
整场小米的面试两个部门加起来共计约7个小时,这是我经历过的最长时间的面试了……小米的面试很辛苦,今天码字也很辛苦,现在已经是凌晨1点半了,如果你觉得上面的经过对你有所帮助或是有意思,就捧个钱场或人场吧: http://me.alipay.com/chunshengster
参考:
- Profiling: From single systems to data centershttp://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/ko//pubs/archive/36575.pdf
- X-Trace: A Pervasive Network Tracing Framework
https://www.usenix.org/conference/nsdi-07/x-trace-pervasive-network-tracing-framework - http://blog.chunshengster.me/2013/05/smp_irq_affinity.html
- http://weibo.com/1412805292/zvNrDsqtT
- http://weibo.com/2173311714/zw40tv3D2
- http://blog.chunshengster.me/2013/07/high_performance_rsyslogd.html
- http://www.wandoujia.com/blog/from-qa-to-ep
相关文章:

Curator Cache
1.Curator Cache 与原生ZooKeeper Wacher区别 原生的ZooKeeper Wacher是一次性的:一个Wacher一旦触发就会被移出,如果你想要反复使用Wacher,就要在Wacher被移除后重新注册,使用起来很麻烦。使用Curator Cache 可以反复使用Wacher了…

程序可以在硬件之间发送吗_你知道硬件、软件工程师之间,还有一个固件工程师吗?...
软件跟硬件之间的界限已经越来越模糊了,那么处于这个灰色地带的,就是固件了。这就分成三类工作者。1、软件工程师一般指做图形界面的程序员,工作内容就是写C、JAVA、Web等。2、硬件工程师当然是指玩电路板的,工作内容就是画原理图…
悲催的跨平台文献管理能力
1.古老的TCP交互 邮箱、FTP、硬盘 2.用现成软件Zotero 免费、跨平台、导入后在Win福昕注释可实时同步mac看看 人生苦短,我用Zotero。。

Mastering Algorithms with C中文版附带源码说明
Mastering Algorithm with C是一本非常经典和独具个性的算法书,主要是从程序员的角度,对算法领域的基本内容,通过C语言进行源码实现,其附带的源码非常详细,对初接触这个领域的程序员很有参考价值.我特地将该书源码的使用方法做了笔记,放在这样,以便日后参考. 下面是该书的封面…
仿qq左滑删除listview_Java基于Swing和Netty仿QQ界面聊天小项目
点击上方 好好学java ,选择 星标 公众号重磅资讯、干货,第一时间送达今日推荐:硬刚一周,3W字总结,一年的经验告诉你如何准备校招!个人原创100W访问量博客:点击前往,查看更多来源&…

[BZOJ1602] [Usaco2008 Oct] 牧场行走 (LCA)
Description N头牛(2<n<1000)别人被标记为1到n,在同样被标记1到n的n块土地上吃草,第i头牛在第i块牧场吃草。 这n块土地被n-1条边连接。 奶牛可以在边上行走,第i条边连接第Ai,Bi块牧场,第i…
大数据中用到的新的数据类型bigint、decimal、smallint、tinyint
在对比oracle数据库和大数据库的时候,发现了几个用以存放数字的新的类型bigint、decimal、smallint、tinyint,为了对比之间的不同,我进行了统计 bigint 可以精确的表示从-263到263-1(即从-9,223,372,036,854,775,808到 9,223,372,036,854,77…
[综合面试] 计算机面试书籍与求职网站推荐
一、推荐书籍 计算机的好书挺多的,我买了也有四五十本,也花了不少钱,但是这些投资都是值的,好好看一下这些书,让自己找工作时的薪水涨个几千是没问题的。当然,也有些书是电子版的。我是c方向的,…
python在工厂中的运用_Python常见工厂函数用法示例
工厂函数:能够产生类实例的内建函数。工厂函数是指这些内建函数都是类对象, 当调用它们时,实际上是创建了一个类实例。Python中的工厂函数举例如下:1. int(),long(),float(),complex(),bool()>>> aint(9.9)>>> …
Java Random()函数生成指定范围的随机数
java中随机生成数字(指定范围) //随机获得0到(i-1)的一个数 int i ThreadLocalRandom.current().nextInt(i);
删除链表中的重复项
方法一:时间优先建立一个hash_set,key为链表中已经遍历的节点内容,开始时为空。从头开始遍历链表中的节点:- 如果节点内容已经在hash_set中存在,则删除此节点,继续向后遍历;- 如果节点内容不在h…
python提取文件名数字_在Python中从文件名提取扩展名
是否有从文件名中提取扩展名的功能?#1楼一种选择可能是与点分开:>>> filename "example.jpeg">>> filename.split(".")[-1]jpeg文件没有扩展名时没有错误:>>> "filename".split(&…
imagick API 中文说明
下面是 imagick API 中文说明 : imagick 类 imagick::adaptiveblurimage 向图像中添加 adaptive 模糊滤镜 imagick::adaptiveresizeimage 自适应调整图像数据依赖关系 imagick::adaptivesharpenimage自适应锐化图像 imagick::adaptivethresholdimage 基于范围的选择…
利用dom4j将实体类转换为对应的xml报文
利用dom4j生成xml报文 目标格式: <?xml version"1.0" encoding"GBK"?><Packet type"REQUEST" version"1.0"><Head><RequestType>C03</RequestType><UserCode>BOCIJS</UserCode…
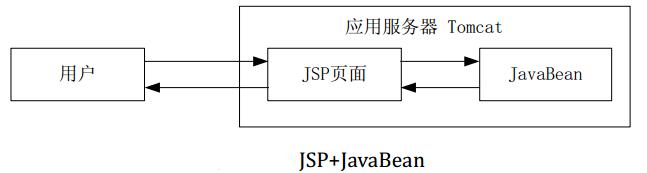
JSP--JavaBean
JSP 最强有力的一个方面就是能够使用 JavaBean 组件。 按照 Sun 公司的定义, JavaBean是一个可重复使用的软件组件。实际上 JavaBean 是一种 Java 类,通过封装属性和方法成为具有某种功能或者处理某些业务的对象,简称 Bean。 一个基本的 JSP …
python 速度矢量_最近邻搜索4D空间python快速-矢量化
For each observation in X (there are 20) I want to get the k(3) nearest neighbors.How to make this fast to support up to 3 to 4 million rows?Is it possible to speed up the loop iterating over the elements? Maybe via numpy, numba or some kind of vectoriza…
使用ajax不刷新页面获取、操作数据
在使用jsp或html时,利用ajax达到不刷新页面就可以获取、操作数据。 首先上代码 (htmljs) 在此处需要引入jquery插件 <!-- 这是页面部分 html--> <body><div style"width:100%;height:30px; float:left"><in…

C/C++面试题分享
1、指针和引用的区别? 答:引用是在C中引入的。它们之间的区别有: (1) 非空区别:指针可以为空,而引用不能为空 (2) 可修改区别:如果指针不是常指针…

js增加属性_前端js基础2
JavaScriptECMAScript(ES):规定了js的一些基础的核心知识(变量、数据类型、语法规范、操作语句等) 3/56/7 说出ES5和ES6的区别? DOM:document object model 文档对象模型,里面提供了一些属性和方法,可以让我们操作页面中的元素 BO…
附加的操作系统服务
select :等待I/O实现threading:高层次的线程接口thread:多线程调度dummy_threading:提供threading模块的副本接口dummy——thread:提供thread模块的副本接口mutiprocessing:在全局调度锁下使用子进程mmap:内…
使用myeclipse的第一步
使用myeclipse的第一步 将以下代码copy放在一个包中运行,然后在控制台输入任意字符,回车,然后控制台打印一串密匙,这里你输入的就是账号,控制台返回的就是注册码,点击MyEclipse->Subscription *** 输入…
一道题弄明白二维数组的指针
#include<stdio.h> int main(int args,char ** argv) {int map[3][3]{{1,2,3},{4,5,6},{7,8,9}};int **pMap(int **)map;printf("%d\n",map);//数组的首地址printf("%d\n",*(map1));//数组第二行首地址printf("%d\n",*map1);//数组首行的第…

Linux网络编程--进程间通信(一)
进程间通信简介(摘自《Linux网络编程》p85) AT&T 在 UNIX System V 中引入了几种新的进程通讯方式,即消息队列( MessageQueues),信号量( semaphores)和共享内存( sha…

mysql 行号_PQ获取TABLE的单一值作为条件查询MySQL返回数据
下午,我正爽歪歪地喝着咖啡,看着Power BI每秒钟刷新一次,静静等待某个分公司完成本月绩效任务,自动调用Python在钉钉群中发送喜报:紧接着再次调用Python将Power BI云端报告中的各分公司最新完成率数据和柱状图截图发在…
UUID的使用及其原理
今天敲项目要用UUID,想起之前老师告诉UUID的使用,但没说具体的生成逻辑,于是我进行了百度 首先,UUID的使用: //生成随机的UUID String uuid UUID.randomUUID().toString().replaceAll("-", "")…
链表类型题目需要用到的头文件list.h
下面是后面链表相关题目中需要用到的链表结点的定义和相关操作函数,参见下面的list.h文件: 注意链表结点的定义采用cpp的定义方式,它会被cpp的文件调用。比如后面删除链表重复结点的文件del_repeated_list.cpp中的编译方式: g -…

led计数电路实验报告_「正点原子FPGA连载」第八章 按键控制LED灯实验
1)实验平台:正点原子开拓者FPGA开发板2)本实例源码下载:请移步正点原子官网第八章 按键控制LED灯实验按键是常用的一种控制器件。生活中我们可以见到各种形式的按键,由于其结构简单,成本低廉等特点,在家电、数码产品、…
svn官方备份hot-backup.py强烈推荐
Author:牛班图 Date:2016/05/18 Address:suzhou --- centos 6.7默认安装的python是2.6.6,大家可以先查看一下自己操作系统的python版本,python -v; hot-backup.py是基于python2写的,python3的语法有些地方不一样,所以在…
用js方法做提交表单的校验
基础知识: 原始提交如下: <form action"<%basePath %>puser/register" method"post"><input placeholder"Name" name"realname"> <input type"email" placeholder"Email…
tree类型题目需要用到的头文件tree.h
下面是树类型题目需要用到的头文件tree.h,请包含在cpp文件中编译,而不是放在c文件中编译,比如查找树中两个节点的最低公共父结点的题common_parent_in_tree.cpp,编译它的方法是: g -g common_parent_in_tree.cpp -o common_parent_in_tree 下面是tree.h的内容: #include <…