python 速度矢量_最近邻搜索4D空间python快速-矢量化
For each observation in X (there are 20) I want to get the k(3) nearest neighbors.
How to make this fast to support up to 3 to 4 million rows?
Is it possible to speed up the loop iterating over the elements? Maybe via numpy, numba or some kind of vectorization?
A naive loop in python:
import numpy as np
from sklearn.neighbors import KDTree
n_points = 20
d_dimensions = 4
k_neighbours = 3
rng = np.random.RandomState(0)
X = rng.random_sample((n_points, d_dimensions))
print(X)
tree = KDTree(X, leaf_size=2, metric='euclidean')
for element in X:
print('********')
print(element)
# when simply using the first row
#element = X[:1]
#print(element)
# potential optimization: query_radius https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KDTree.html#sklearn.neighbors.KDTree.query_radius
dist, ind = tree.query([element], k=k_neighbours, return_distance=True, dualtree=False, breadth_first=False, sort_results=True)
# indices of 3 closest neighbors
print(ind)
#[[0 9 1]] !! includes self (element that was searched for)
print(dist) # distances to 3 closest neighbors
#[[0. 0.38559188 0.40997835]] !! includes self (element that was searched for)
# actual returned elements for index:
print(X[ind])
## after removing self
print(X[ind][0][1:])
Optimally the output is a pandas.DataFrame of the following structure:
lat_1,long_1,lat_2,long_2,neighbours_list
0.5488135,0.71518937,0.60276338,0.54488318, [[0.61209572 0.616934 0.94374808 0.6818203 ][0.4236548 0.64589411 0.43758721 0.891773]
edit
For now, I have a pandas-based implementation:
df = df.dropna() # there are sometimes only parts of the tuple (either left or right) defined
X = df[['lat1', 'long1', 'lat2', 'long2']]
tree = KDTree(X, leaf_size=4, metric='euclidean')
k_neighbours = 3
def neighbors_as_list(row, index, complete_list):
dist, ind = index.query([[row['lat1'], row['long1'], row['lat2'], row['long2']]], k=k_neighbours, return_distance=True, dualtree=False, breadth_first=False, sort_results=True)
return complete_list.values[ind][0][1:]
df['neighbors'] = df.apply(neighbors_as_list, index=tree, complete_list=X, axis=1)
df.head()
But this is very slow.
edit 2
Sure, here is a pandas version:
import numpy as np
import pandas as pd
from sklearn.neighbors import KDTree
from scipy.spatial import cKDTree
rng = np.random.RandomState(0)
#n_points = 4_000_000
n_points = 20
d_dimensions = 4
k_neighbours = 3
X = rng.random_sample((n_points, d_dimensions))
X
df = pd.DataFrame(X)
df = df.reset_index(drop=False)
df.columns = ['id_str', 'lat_1', 'long_1', 'lat_2', 'long_2']
df.id_str = df.id_str.astype(object)
display(df.head())
tree = cKDTree(df[['lat_1', 'long_1', 'lat_2', 'long_2']])
dist,ind=tree.query(X, k=k_neighbours,n_jobs=-1)
display(dist)
print(df[['lat_1', 'long_1', 'lat_2', 'long_2']].shape)
print(X[ind_out].shape)
X[ind_out]
# fails with
# AssertionError: Shape of new values must be compatible with manager shape
df['neighbors'] = X[ind_out]
df
But it fails as I cannot re-assign the result.
解决方案
You could use scipy's cKdtree.
Example
rng = np.random.RandomState(0)
n_points = 4_000_000
d_dimensions = 4
k_neighbours = 3
X = rng.random_sample((n_points, d_dimensions))
tree = cKDTree(X)
#%timeit tree = cKDTree(X)
#3.74 s ± 29.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
#%%timeit
_,ind=tree.query(X, k=k_neighbours,n_jobs=-1)
#shape=(4000000, 2)
ind_out=ind[:,1:]
#shape=(4000000, 2, 4)
coords_out=X[ind_out].shape
#7.13 s ± 87.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
About 11s for a problem of this size is quite good.
相关文章:

使用ajax不刷新页面获取、操作数据
在使用jsp或html时,利用ajax达到不刷新页面就可以获取、操作数据。 首先上代码 (htmljs) 在此处需要引入jquery插件 <!-- 这是页面部分 html--> <body><div style"width:100%;height:30px; float:left"><in…

C/C++面试题分享
1、指针和引用的区别? 答:引用是在C中引入的。它们之间的区别有: (1) 非空区别:指针可以为空,而引用不能为空 (2) 可修改区别:如果指针不是常指针…

js增加属性_前端js基础2
JavaScriptECMAScript(ES):规定了js的一些基础的核心知识(变量、数据类型、语法规范、操作语句等) 3/56/7 说出ES5和ES6的区别? DOM:document object model 文档对象模型,里面提供了一些属性和方法,可以让我们操作页面中的元素 BO…
附加的操作系统服务
select :等待I/O实现threading:高层次的线程接口thread:多线程调度dummy_threading:提供threading模块的副本接口dummy——thread:提供thread模块的副本接口mutiprocessing:在全局调度锁下使用子进程mmap:内…
使用myeclipse的第一步
使用myeclipse的第一步 将以下代码copy放在一个包中运行,然后在控制台输入任意字符,回车,然后控制台打印一串密匙,这里你输入的就是账号,控制台返回的就是注册码,点击MyEclipse->Subscription *** 输入…
一道题弄明白二维数组的指针
#include<stdio.h> int main(int args,char ** argv) {int map[3][3]{{1,2,3},{4,5,6},{7,8,9}};int **pMap(int **)map;printf("%d\n",map);//数组的首地址printf("%d\n",*(map1));//数组第二行首地址printf("%d\n",*map1);//数组首行的第…

Linux网络编程--进程间通信(一)
进程间通信简介(摘自《Linux网络编程》p85) AT&T 在 UNIX System V 中引入了几种新的进程通讯方式,即消息队列( MessageQueues),信号量( semaphores)和共享内存( sha…

mysql 行号_PQ获取TABLE的单一值作为条件查询MySQL返回数据
下午,我正爽歪歪地喝着咖啡,看着Power BI每秒钟刷新一次,静静等待某个分公司完成本月绩效任务,自动调用Python在钉钉群中发送喜报:紧接着再次调用Python将Power BI云端报告中的各分公司最新完成率数据和柱状图截图发在…
UUID的使用及其原理
今天敲项目要用UUID,想起之前老师告诉UUID的使用,但没说具体的生成逻辑,于是我进行了百度 首先,UUID的使用: //生成随机的UUID String uuid UUID.randomUUID().toString().replaceAll("-", "")…
链表类型题目需要用到的头文件list.h
下面是后面链表相关题目中需要用到的链表结点的定义和相关操作函数,参见下面的list.h文件: 注意链表结点的定义采用cpp的定义方式,它会被cpp的文件调用。比如后面删除链表重复结点的文件del_repeated_list.cpp中的编译方式: g -…

led计数电路实验报告_「正点原子FPGA连载」第八章 按键控制LED灯实验
1)实验平台:正点原子开拓者FPGA开发板2)本实例源码下载:请移步正点原子官网第八章 按键控制LED灯实验按键是常用的一种控制器件。生活中我们可以见到各种形式的按键,由于其结构简单,成本低廉等特点,在家电、数码产品、…
svn官方备份hot-backup.py强烈推荐
Author:牛班图 Date:2016/05/18 Address:suzhou --- centos 6.7默认安装的python是2.6.6,大家可以先查看一下自己操作系统的python版本,python -v; hot-backup.py是基于python2写的,python3的语法有些地方不一样,所以在…
用js方法做提交表单的校验
基础知识: 原始提交如下: <form action"<%basePath %>puser/register" method"post"><input placeholder"Name" name"realname"> <input type"email" placeholder"Email…
tree类型题目需要用到的头文件tree.h
下面是树类型题目需要用到的头文件tree.h,请包含在cpp文件中编译,而不是放在c文件中编译,比如查找树中两个节点的最低公共父结点的题common_parent_in_tree.cpp,编译它的方法是: g -g common_parent_in_tree.cpp -o common_parent_in_tree 下面是tree.h的内容: #include <…
用easyui动态创建一个对话框
function randomString(len) { len len || 32; var $chars ABCDEFGHJKMNPQRSTWXYZabcdefhijkmnprstwxyz2345678; /****默认去掉了容易混淆的字符oOLl,9gq,Vv,Uu,I1****/ var maxPos $chars.length; var pwd ; for (i 0; i < len; i) { pwd $…

网站收录工具(php导航自动收录源码)_网站如何快速收录,网站不收录怎么办?...
经常有朋友说怎么快速收录,网站不收录怎么收录??其实,网站不包括一般的新网站数量,没有SEO基础,SEO了解合作伙伴经常会遇到问题,甚至很多人会告诉你,不包括网站引流,导致…

JS Uncaught SyntaxError:Unexpected identifier异常报错原因及其解决方法
最近在写ajax的时候,调用js方法,遇到了Uncaught SyntaxError:Unexpected identifier异常报错,开始搞不清原因,很苦恼。 以为是js方法参数个数和长度的问题,后来发现原来是这样~ 以下是 浏览器窗口的报错 以及 按钮处…

python 打印皮卡丘_Python到底是什么?学姐靠它拿了5个offer
你ZAO吗?最近陌陌发布了一款很有意思的产品——ZAO,这款AI换脸的产品刷爆朋友圈!这款产品火爆到什么程度呢?正在使用ZAO的用户会发现,想要生成一段新的AI换脸视频,已经不是等待几秒、排队第几位的问题&…
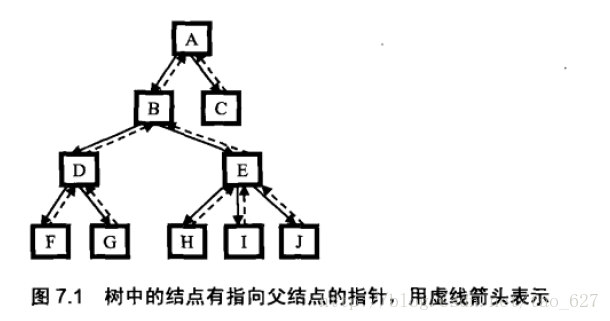
有一个1亿结点的树,已知两个结点, 求它们的最低公共祖先!
对该问题,分为如下几种情形讨论: 情形一: 假如该树为二叉树,并且是二叉搜索树, 依据二叉搜索树是排过序的, 我们只需要从树的根结点开始,逐级往下,和两个输入的结点进行比较. 如果当前结点的值比两个结点的值都大,那么最低的公共祖先一定在当前结点的左子树中,下一步遍历当前…
数据库SQL优化大总结之百万级数据库优化方案
1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t w…
js定时执行函数
方法一: //直接现定义函数 var time window.setInterval(function(){ $(’.lingdao_right’).click(); },5000); 方法二: //执行已经有的函数 var time window.setInterval(‘abc()’,5000); 清除js自动执行 clearInterval(time); //time就是定义时的名称,如上
BST(binary search tree)类型题目需要用到的头文件binary_tree.h
下面是二叉搜索树需要用到的头文件binary_tree.h #include <stdio.h>struct BinaryTreeNode{int value;BinaryTreeNode* pLeft;BinaryTreeNode* pRight; };BinaryTreeNode* CreateBinaryTreeNode(int value){BinaryTreeNode* pNode new BinaryTreeNode();pNode->valu…
终止js程序执行的方法
js终止程序执行的方法共有三种 (一)在function里面(普通js方法) (1)return; (2)return false; (二)非function方法里面(如ajax方法) alert(“发生异常”); throw SyntaxError(); ale…
将BST转换为有序的双向链表!
在二叉树中,每个结点都有两个指向子结点的指针. 在双向链表中, 每个结点也有两个指针,它们分别指向前一个结点和后一个结点.由于这两种结构的相似性, 同时二叉搜索树也是一种排过序的数据结构, 因此在理论上有可能实现二叉搜索树和排序的双向链表之间的转换. 下面的文件BST_to_…
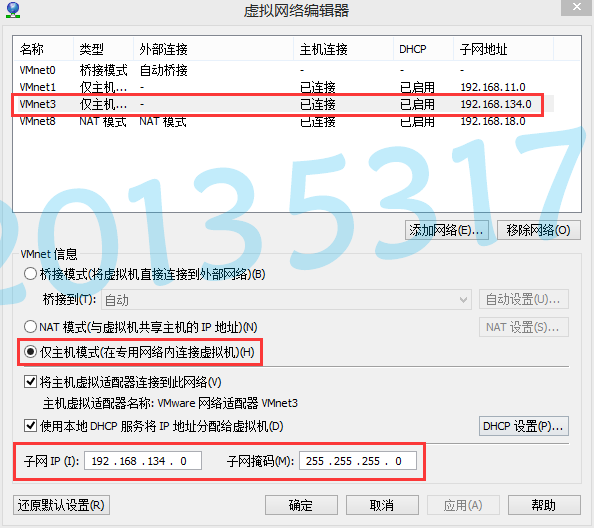
计算机病毒实践汇总五:搭建虚拟网络环境
在尝试学习分析的过程中,判断结论不一定准确,只是一些我自己的思考和探索。敬请批评指正! 涉及内容: INetSim安装及使用 ApateDNS安装及使用 1. 搭建病毒分析网络环境原因 使用虚拟机作为沙箱能把病毒与外界完全隔离开,…
form表单提交前进行ajax或js验证,校验不通过不提交
在使用form表单进行提交数据前,需要进行数据的校验->表单的校验(如:两次密码输入是否相同)后台数据的校验(如:账号是否存在),这个时候,如果哪步校验不通过,…
中体骏彩C++面试题
下面是我凭记忆想到的几个题目,有需要的同学就拿去吧,我也算做了点善事. 中体骏彩C笔试题 2013-11-18 1.指针的含义是:B A.名字 B.地址 C.名称 D.符号 2.给出下面的程序输出: #include <iostream> #include <cstdlib> #include <cstring> #include <l…
Fibonacci数列的java实现
关于Fibonacci应该都比较熟悉,0,1,1,2,3.。。。。 基本公式为f(n) f(n-1) f(n-2); f(0) 0; f(1) 1; 方法1:可以运用迭代的方法实现: public static int f1(int n){if(n<1)return n;return f1(n-1) f1(n-2); }实现方法简单。 方法2&am…
stream流对象的理解及使用
我的理解:用stream流式处理数据,将数据用一个一个方法去 . (点,即调用) 得到新的数据结果,可以一步达成。 有多种方式生成 Stream Source: 从 Collection 和数组 Collection.stream()Collecti…
永成科技C++笔试题
最后几个题有点难度,在这里说一下: 永成科技C笔试题 2013-11-19 1.将1亿以内的质数存到一个超级大的数组中,用算法如何实现? 使用"筛法"求解1亿以内的质数的程序的思路: 先动态分配1亿个bit(总计12500000字节),用字节中的每一位代表每一个整数,首先将代表奇数的那…