TitanDB GC详细实现原理 及其 引入的问题
文章目录
- 1. 为什么要有GC
- 2. GC的触发条件
- 3. GC的核心逻辑
- 1. blob file形态
- 2. GC Prepare
- 3. GC pick file
- 4. GC run
- 4. GC 引入的问题
- 5. Titan的测试代码
通过本篇,能够从TitanDB的源代码中看到 key/value 分离之后引入的一些复杂性,这个复杂性很难避免。
主要从如下几点展开描述:
- GC 触发条件
- GC 的 核心逻辑
- GC 引入的问题
希望通过对Titan源代码的分析能够加深各位对key-value分离策略优劣的理解,为今后自己的业务选型提供参考。
1. 为什么要有GC
Titan 从 Wisckey 中借鉴的key-value分离思想来降低LSM-tree的写放大 以及LSM-tree的 Compaction 中I/O带宽的占用。这对于引擎层很薄且大value场景 来说 还是比较适用的,比较薄的引擎层能够让应用的性能尽可能能接近引擎,而大value场景中传统的LSM-tree会携带着value进行compaction,这对于传统的NVME-ssd / SATA-ssd 来说简直是灾难,sst的读写I/O队列是共享的,而带着大value compaction 场景下的I/O很容易达到带宽瓶颈,从而让应用的读长尾不忍直视。。。
跑偏了,以上是titan或者说key-value分离出现的缘由。而引入了key-value分离,也就是仅仅让较小数据量的key存放在LSM-tree中,并参与LSM-tree的compaction调度,而大value则单独存放在另一个地方,所以需要对大value的存放文件进行GC,保正compaction对key的清理 能够同步到大value中,清理对应的过期value,这是titan正确性保障的基本功能,也是基于lsm-tree的key-value分离系统必须要实现的。
接下来我们详细看看Titan的实践过程。
2. GC的触发条件
前面提到了GC 的作用是清理因为compaction而过期的key的value,所以GC的触发肯定和compaction同步或者先后顺序的;而且compaction 的过程才能知道具体的sst文件的变动情况。
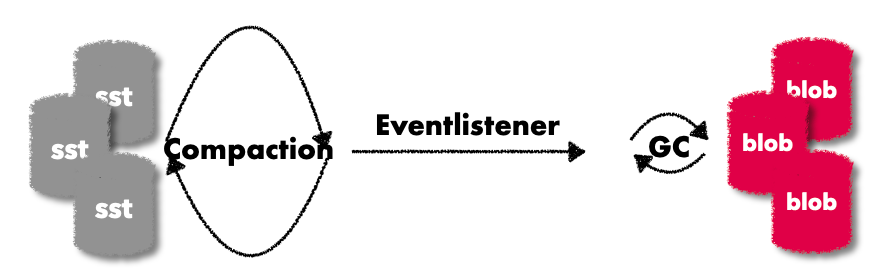
所以titan 的GC通过rocksdb的EventListener 来触发的。
这里又要说一下Rocksdb的灵活扩展性,为用户提供了多种多样能够操作引擎内部核心逻辑的接口,来让熟悉的用户更好得使用引擎。
就像titan GC这里用到的EventListener中,titan只需要在OnCompactionCompleted实现触发GC的逻辑,就能在compaction完成之后尝试调度GC,这个时候能够看到comapction的一些内部信息,非常之方便。
rocksdb compaction中调度EventListener 逻辑如下:
Status DBImpl::BackgroundCompaction(bool* made_progress,JobContext* job_context,LogBuffer* log_buffer,PrepickedCompaction* prepicked_compaction,Env::Priority thread_pri) {...if (c != nullptr) {c->ReleaseCompactionFiles(status);*made_progress = true;#ifndef ROCKSDB_LITE// Need to make sure SstFileManager does its bookkeepingauto sfm = static_cast<SstFileManagerImpl*>(immutable_db_options_.sst_file_manager.get());if (sfm && sfm_reserved_compact_space) {sfm->OnCompactionCompletion(c.get());}
#endif // ROCKSDB_LITE// 调度用户态实现的 OnCompactionCompletedNotifyOnCompactionCompleted(c->column_family_data(), c.get(), status,compaction_job_stats, job_context->job_id);}...
}
其中NotifyOnCompactionCompleted会执行具体的OnCompactionCompleted的逻辑
void DBImpl::NotifyOnCompactionCompleted(ColumnFamilyData* cfd, Compaction* c, const Status& st,const CompactionJobStats& compaction_job_stats, const int job_id) {...TEST_SYNC_POINT("DBImpl::NotifyOnCompactionCompleted::UnlockMutex");{CompactionJobInfo info{};BuildCompactionJobInfo(cfd, c, st, compaction_job_stats, job_id, current,&info);//执行for (auto listener : immutable_db_options_.listeners) {listener->OnCompactionCompleted(this, info);}}...
}
到现在基本就已经进入了GC的逻辑了,也就是titan实现的void TitanDBImpl::OnCompactionCompleted
3. GC的核心逻辑
讲解详细的GC逻辑之前先整体看看titan的blobfile形态。
1. blob file形态
看看基本的blobfile的内部存储结构
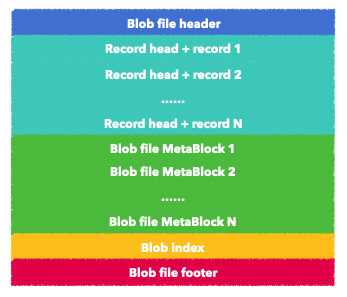
相关的所有block信息都在blob_format.h中
大体结构和我们rocksdb的sst文件结构类似的,只不过value的存储上使用的是record,一个record是一个key-value的记录,而sst中则是一个data-block。
blob file header: 整个blob file的header 字段,用来标识当前file的version信息和魔数, 实现了两个版本,用来兼容rocksdb的blobdb
// Format of blob file header for version 1 (8 bytes): // // +--------------+---------+ // | magic number | version | // +--------------+---------+ // | Fixed32 | Fixed32 | // +--------------+---------+ // // For version 2, there are another 4 bytes for flags: // // +--------------+---------+---------+ // | magic number | version | flags | // +--------------+---------+---------+ // | Fixed32 | Fixed32 | Fixed32 | // +--------------+---------+---------+blob record: 整个blob file存放 key-value的区域
主要包括两部分:record head 和 record其中 record head 主要保存的是当前 record 内key+value的总大小,还有一个字节标识当前record是否开启了压缩
// Format of blob head (9 bytes): // // +---------+---------+-------------+ // | crc | size | compression | // +---------+---------+-------------+ // | Fixed32 | Fixed32 | char | // +---------+---------+-------------+ //这个record head 字段的添加是在 encode recod 的时候写入的
void BlobEncoder::EncodeRecord(const BlobRecord& record) {record_buffer_.clear();compressed_buffer_.clear();// encode recordCompressionType compression;record.EncodeTo(&record_buffer_);record_ = Compress(compression_info_, record_buffer_, &compressed_buffer_,&compression);// encode record headassert(record_.size() < std::numeric_limits<uint32_t>::max());EncodeFixed32(header_ + 4, static_cast<uint32_t>(record_.size()));header_[8] = compression;// 生成src,并ecode 到头部字段uint32_t crc = crc32c::Value(header_ + 4, sizeof(header_) - 4);crc = crc32c::Extend(crc, record_.data(), record_.size());EncodeFixed32(header_, crc); }第二部分的record 是主体,存放key-value,是的,没错,这里会存放一个key的备份,来所以value。也就是titan相比于rocksdb这里会多存放一份key。
struct BlobRecord {Slice key;Slice value;void EncodeTo(std::string* dst) const;Status DecodeFrom(Slice* src);size_t size() const { return key.size() + value.size(); }friend bool operator==(const BlobRecord& lhs, const BlobRecord& rhs); };blob file meta 这里存放当前blobfile的一些元信息,类似于sst的 properties block(存放当前sst的大小,datablock个数,每个datablock大小,处于哪个层 ,最大最小key等)/filter block(bloom filter)/ compress block/range del block 。blob file这里也是为了方便扩展,也允许加入很多meta block。
// Format of blob file meta (not fixed size): // // +-------------+-----------+--------------+------------+ // | file number | file size | file entries | file level | // +-------------+-----------+--------------+------------+ // | Varint64 | Varint64 | Varint64 | Varint32 | // +-------------+-----------+--------------+------------+ // +--------------------+--------------------+ // | smallest key | largest key | // +--------------------+--------------------+ // | Varint32 + key_len | Varint32 + key_len | // +--------------------+--------------------+ // // The blob file meta is stored in Titan's manifest for quick constructing of // meta infomations of all the blob files in memory. // // Legacy format: // // +-------------+-----------+ // | file number | file size | // +-------------+-----------+ // | Varint64 | Varint64 | // +-------------+-----------+Blob index block,报错record所处当前blobfile的offset和整个record的size,用来在seek的过程中快速找到对应的blob record
// Format of blob index (not fixed size): // // +------+-------------+------------------------------------+ // | type | file number | blob handle | // +------+-------------+------------------------------------+ // | char | Varint64 | Varint64(offsest) + Varint64(size) | // +------+-------------+------------------------------------+ // // It is stored in LSM-Tree as the value of key, then Titan can use this blob // index to locate actual value from blob file.Blob file footer 这是最后一个block,目前只是保存了一个空的index handle 以及
kEncodedLength{kBlobFooterSize}size。
读blobfile的时候减去kEncodedLength{kBlobFooterSize};之后的偏移地址就是index record的部分。因为现在的实现是没有meta block的,这里应该是为了预留meta block的index的,所以实际encode到footer的
meta_index_handle内容是空的。
这里说的有点啰嗦了,总之知道底层文件的组织形态,那上层的读写细节就很容易把控了。
接下来看看底层的核心设计细节。
2. GC Prepare
前面说了,compaction结束之后会通过OnCompactionCompleted 来触发。
这个时候正常的GC逻辑中是 要知道 接下来清理哪一些blob,以及清理blob中多少的数据。如果这个时候inplace update,那还需要大量的随机读,并且是随机写入,后续文件的清理也比较麻烦,哪怕只有一条record也不能清理;所以整体GC的核心读写都是和compaction的思想类似的,从文件中读取record、丢掉过期的record,只保留新写入到新的blobfile中。势必消耗较少的cpu,还能保证GC的效率。
这里看一下GC pick file的逻辑,选择需要参与GC的 blob file。
在Titan中key 从用户下发,到形成sst/blob file的过程如下:
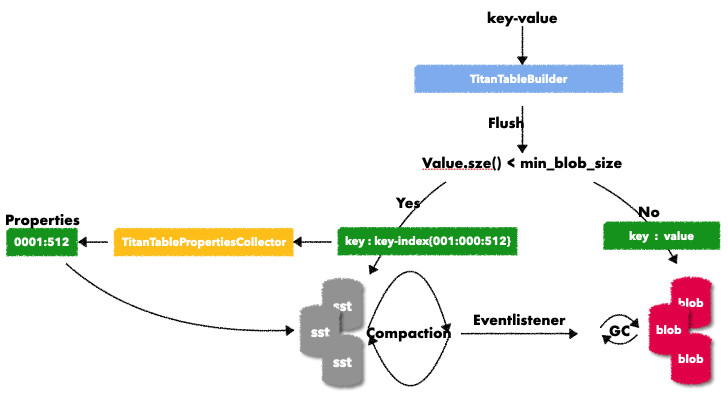
Flush的过程会根据min_blob_size来区分value的存储,如果会存放在blobfile中,则它会生成一个上图中的key-key-index 准备写入sst文件,这个key-index 包括三列
- 第一列:这个key的value所属blobfile的filenumber
- 第二列:这个key在blobfile中的record的偏移地址
- 第三列:这个key所在blobfile的record的大小
也就是通过key-index,能够索引到这个key在blobfile中的record,当这个key-index要被写入到sst中时 titan为了收集GC需要的信息,会实现一个Rocksdb的TablePropertiesCollector,在flush/compaction形成sst时,将当前sst中key的index信息做一个汇总写入到table properties block中。这里的汇总信息包括上图中最左侧的部分,当然实际上当前sst中对应多少个blobfile就会有多少条(一个map数据结构,以blob file number为key,对应的record size为value)。
有了properties的信息之后,就能够知道compaction完成之后输入的sst文件的properties和输出的sst文件的blob file中key的变动情况(blob record也存储了对应的key-value),这样就能决策哪一些blobfile是否达到GC的触发条件(关于GC的触发条件后面会说)。
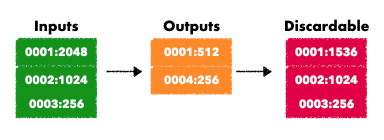
大体就是输入的sst文件总的properties信息 和 输出的propertis的blobfile信息做差值,就知道最后每个blobfile会被丢弃多少的数据。
这个数据会存放在 blob_file_size_diff变量中, 对应的处理代码如下:
void TitanDBImpl::OnCompactionCompleted(const CompactionJobInfo& compaction_job_info) {...// lamda 表达式,处理inputs 时 to_add为false,ExtractGCStatsFromTableProperty 仅仅是累积// 处理outputs时,会将to_add置为true,则会和之前的做diff,这样就知道每个blobfile丢弃的record大小情况auto update_diff = [&](const std::vector<std::string>& files, bool to_add) {for (const auto& file_name : files) {auto prop_iter = prop_collection.find(file_name);if (prop_iter == prop_collection.end()) {ROCKS_LOG_WARN(db_options_.info_log,"OnCompactionCompleted[%d]: No table properties for file %s.",compaction_job_info.job_id, file_name.c_str());continue;}Status gc_stats_status = ExtractGCStatsFromTableProperty(prop_iter->second, to_add, &blob_file_size_diff);if (!gc_stats_status.ok()) {// TODO: Should treat it as background error and make DB read-only.ROCKS_LOG_ERROR(db_options_.info_log,"OnCompactionCompleted[%d]: failed to extract GC stats from table ""property: compaction file: %s, error: %s",compaction_job_info.job_id, file_name.c_str(),gc_stats_status.ToString().c_str());assert(false);}}};update_diff(compaction_job_info.input_files, false /*to_add*/);update_diff(compaction_job_info.output_files, true /*to_add*/);...
}
有了每次compaction前后 每个 blobfile中过期数据量的情况,接下来titan会为上面blob_file_size_diff map中的每一个blob file 维护一个state,用来标识这个文件中的“垃圾”数据的比例,计算方式很简单 ,大体就是1 - live_data_size / file_size:
double GetDiscardableRatio() const {if (file_size_ == 0) {return 0;}// TODO: Exclude meta blocks from file sizereturn 1 - (static_cast<double>(live_data_size_) /(file_size_ - kBlobMaxHeaderSize - kBlobFooterSize));
}
而这个数据则会被当作当前blobfile 是否会被选择参与GC的score 标准。
计算每个blobfile的gc score 逻辑如下:
需要注意的是如果一个blobfile 过小(默认小于8M),会为其设置0.5的core,从而加快小文件的回收。
gc_score_ 会从大到小排个序,后续的GC过程中的blobfile文件挑选会优先挑选gc_score较高的。
void BlobStorage::ComputeGCScore() {// TODO: no need to recompute all everytimeMutexLock l(&mutex_);gc_score_.clear();for (auto& file : files_) {if (file.second->is_obsolete()) {continue;}gc_score_.push_back({});auto& gcs = gc_score_.back();gcs.file_number = file.first;if (file.second->file_size() < cf_options_.merge_small_file_threshold) {// for the small file or file with gc mark (usually the file that just// recovered) we want gc these file but more hope to gc other file with// more invalid datagcs.score = cf_options_.blob_file_discardable_ratio;} else {gcs.score = file.second->GetDiscardableRatio();}}// gc_score会从大到小排序std::sort(gc_score_.begin(), gc_score_.end(),[](const GCScore& first, const GCScore& second) {return first.score > second.score;});
}
接下来有了每个文件的gc_sore信息就可以正式调度一个gc job 了,默认只能调度一个GCjob。
设置一个的目的并不是说有数据冲突/一致性问题,而是GC的I/O代价太高,需要限制I/O,保证应用的延时
void TitanDBImpl::MaybeScheduleGC() {mutex_.AssertHeld();if (db_options_.disable_background_gc) return;if (shuting_down_.load(std::memory_order_acquire)) return;while (unscheduled_gc_ > 0 &&bg_gc_scheduled_ < db_options_.max_background_gc) {unscheduled_gc_--;bg_gc_scheduled_++;// 调度gc job 开始异步GCthread_pool_->SubmitJob(std::bind(&TitanDBImpl::BGWorkGC, this));}
}
3. GC pick file
接下来顺着代码,会进入到GC 入口函数 TitanDBImpl::BackgroundGC,首先会挑选当前需要参与GC 的blob file。
- 首先根据上面prepare过程中维护的 gc_socre 来确认当前文件是否符合gc的基本条件。即要求每一个core都大于等于
cf_options_.blob_file_discardable_ratio,默认是0.5 - 满足的话 找到这个文件的标识,并添加到GC文件 数组
blob_files中 - 如果累积的gc file总文件大小超过 gc batch size:
cf_options_.max_gc_batch_size(默认1G) 或者 有效总数据超过cf_options_.blob_file_target_size(默认256M) ,则认为当前job文件挑选够了
std::unique_ptr<BlobGC> BasicBlobGCPicker::PickBlobGC(BlobStorage* blob_storage) {Status s;std::vector<std::shared_ptr<BlobFileMeta>> blob_files;...for (auto& gc_score : blob_storage->gc_score()) {// score 是否满足GC 最低score的要求if (gc_score.score < cf_options_.blob_file_discardable_ratio) {break;}// 确认这个文件存在auto blob_file = blob_storage->FindFile(gc_score.file_number).lock();if (!CheckBlobFile(blob_file.get())) {// Skip this file id this file is being GCed// or this file had been GCedROCKS_LOG_INFO(db_options_.info_log, "Blob file %" PRIu64 " no need gc",blob_file->file_number());continue;}// 继续挑选当前job参与GC的文件if (!stop_picking) {blob_files.emplace_back(blob_file);batch_size += blob_file->file_size();estimate_output_size += blob_file->live_data_size();// 是否达到了GC的batch大小以及 有效数据量大小阈值的要求,满足则停止挑选文件if (batch_size >= cf_options_.max_gc_batch_size ||estimate_output_size >= cf_options_.blob_file_target_size) {// Stop pick file for this gc, but still check file for whether need// trigger gc after thisstop_picking = true;}} else { // 完成挑选,将剩下的文件放在下一个job中。next_gc_size += blob_file->file_size();if (next_gc_size > cf_options_.min_gc_batch_size) {maybe_continue_next_time = true;RecordTick(statistics(stats_), TITAN_GC_REMAIN, 1);ROCKS_LOG_INFO(db_options_.info_log,"remain more than %" PRIu64" bytes to be gc and trigger after this gc",next_gc_size);break;}}}...return std::unique_ptr<BlobGC>(new BlobGC(std::move(blob_files), std::move(cf_options_), maybe_continue_next_time));
}
4. GC run
实际函数主体的入口是DoRunGC(), 这一部分就是类似于comapction的调度逻辑了。
构造一个最小堆 迭代器,并为参与GC的所有文件也都维护一个迭代器, 每次迭代器的移动(next)都会从 多个blobfile中取一个record,将key 按照compartor放在最小堆里。
从迭代器直接取key(最小堆里的堆顶,读上来的最小的key),去sst中反查key是否存在
- 存在则认为是不可丢弃的,会写入到新的blob文件中。
- 否则就会被丢弃,迭代器直接跳过这个key的处理。
一边通过迭代器读取,一边将从最小堆中取出的key 确认不会被丢弃就写入到新的blobfile中
通过write callback ,将写入到新的blobfile的key再回写到lsm-tree中。因为 value已经放到了新的blobfile中了,但是lsm-tree中的key并不知道这一点。所以还需要重写一次。
其中迭代器处理构造一个最小堆的过程如下:
void BlobFileMergeIterator::SeekToFirst() {for (auto& iter : blob_file_iterators_) {iter->SeekToFirst();// 将每一个blobfile问的迭代器添加到最小堆中if (iter->status().ok() && iter->Valid()) min_heap_.push(iter.get());}if (!min_heap_.empty()) {current_ = min_heap_.top();min_heap_.pop();} else {status_ = Status::Aborted("No iterator is valid");}
}
判断一个key是否能够被丢弃,逻辑如下:
Status BlobGCJob::DiscardEntry(const Slice& key, const BlobIndex& blob_index,bool* discardable) {TitanStopWatch sw(env_, metrics_.gc_read_lsm_micros);assert(discardable != nullptr);PinnableSlice index_entry;bool is_blob_index = false;// 从SST文件先读一次,确认是否存在Status s = base_db_impl_->GetImpl(ReadOptions(), blob_gc_->column_family_handle(), key, &index_entry,nullptr /*value_found*/, nullptr /*read_callback*/, &is_blob_index);if (!s.ok() && !s.IsNotFound()) {return s;}// count read bytes for checking LSM entrymetrics_.gc_bytes_read += key.size() + index_entry.size();// 找不到,则确认可以丢弃,更新丢弃标记。if (s.IsNotFound() || !is_blob_index) {// Either the key is deleted or updated with a newer version which is// inlined in LSM.*discardable = true;return Status::OK();}......return Status::OK();
}
写入到新的blobfile逻辑如下:
void BlobFileBuilder::Add(const BlobRecord& record, BlobHandle* handle) {if (!ok()) return;encoder_.EncodeRecord(record);handle->offset = file_->GetFileSize();handle->size = encoder_.GetEncodedSize();live_data_size_ += handle->size;// 追加写入,先写每个record的head// 每个record的内容前面已经描述过了。status_ = file_->Append(encoder_.GetHeader());if (ok()) {// 再写recordstatus_ = file_->Append(encoder_.GetRecord());num_entries_++;// The keys added into blob files are in order.if (smallest_key_.empty()) {smallest_key_.assign(record.key.data(), record.key.size());}assert(cf_options_.comparator->Compare(record.key, Slice(smallest_key_)) >=0);assert(cf_options_.comparator->Compare(record.key, Slice(largest_key_)) >=0);largest_key_.assign(record.key.data(), record.key.size());}
}
重写回写key到lsm-tree中的逻辑如下:
new_blob_index.EncodeToBase(&index_entry);
// Store WriteBatch for rewriting new Key-Index pairs to LSM
// 通过writecallback来回写
GarbageCollectionWriteCallback callback(cfh, blob_record.key.ToString(),std::move(blob_index));
callback.value = index_entry;
rewrite_batches_.emplace_back(std::make_pair(WriteBatch(), std::move(callback)));
auto& wb = rewrite_batches_.back().first;
s = WriteBatchInternal::PutBlobIndex(&wb, cfh->GetID(), blob_record.key,index_entry);
4. GC 引入的问题
从上面的GC核心处理逻辑中,我们能够看到GC的实现相比于compaction还是很简单的,可能是因为blobfile的各种meta block功能没有上全,所以gc过程并不会特别复杂。
需要注意的是GC 的处理细节:
- 从blobfile中取到的record,还需要拿着key再去lsm-tree中读一下。因为不确定这个key是存在还是不存在,需要额外的一次读。
- 写完blobfile之后还需要对lsm-tree中的key进行一次更新,因为lsm-tree中的key不知道它的value已经写入到了新的blobfile中。又需要一次额外的写。
- 更严重的是GC会带着大value读写,这对于当下 共享读写队列 的硬件来说,是一个长尾灾难。写入延时的增大会造成读的长尾。
这有钱的可以用intel optane ssd p5800,据说读写队列分离,互不影响;没钱的加限速呗。。。。
假如我们仅仅是使用titan,并不想改动/优化 一下titan的话,那很简单,让value-size : key-size 差异足够大,这个时候GC的这两个额外读和额外写相比于GC本身的value读写,都降低很多了。lsm-tree中key的密度大了,文件个数相对较少。
假如我们key-size:10B ,value size: 64KB,有一块6T的SSD,不考虑写放大的情况,整个盘都写满,key+key-index形成的sst所占用的空间也还不到2G,LSM-tree也就2层。。。。即使考虑上写放大, 也就最多到第三层。且写放大完全可以通过level_compaction_dynamic_level_bytes降低到最小。这样的LSM-tree中的查找基本不会消耗太多的I/O,很快的。
而如果想要改进Titan,让它的性能进一步提升,需要对源代码有足够深入的了解和思考。
欢迎一起讨论!!!
5. Titan的测试代码
使用如下代码可以测试使用titan和不使用titan的一些性能对比,使用titan的话-use_titan=true即可
#include <unistd.h>
#include <atomic>
#include <iostream>
#include <random>
#include <string>
#include <thread>#include <sys/time.h>#include "rocksdb/db.h"
#include "rocksdb/table.h"
#include "rocksdb/cache.h"
#include "rocksdb/slice_transform.h"
#include "rocksdb/filter_policy.h"
#include "rocksdb/write_batch.h"
#include "rocksdb/rate_limiter.h"
#include "rocksdb/perf_context.h"
#include "rocksdb/iostats_context.h"
#include "gflags/gflags.h"#include "titan/db.h"
#include "titan/options.h"using namespace google;DEFINE_int64(read_ratio,0,"read threads' num");
DEFINE_int64(time,1200,"read threads' ratio");
DEFINE_int64(thread_num,64,"total threads ");
DEFINE_bool(rate_limiter,false,"use rocksdb ratelimiter");
DEFINE_bool(use_dynamic,false,"use dynamic level size");
DEFINE_int64(limit_size, 512, "rate limiter size");
DEFINE_string(db_dir,"./rocksdb_data","rocksdb data's directory");
DEFINE_int64(multidb_nums,1,"the number of multidb");
DEFINE_int64(value_len, 1024, "value size");
DEFINE_bool(use_titan, false, "use titandb");
DEFINE_bool(disable_wal, false, "disable wal");std::atomic<long> g_op_W;
std::atomic<long> g_op_R;// 这里测试过程中为了区分两种db,声明了两个
// 实际的话可以只用一种std::vector<rocksdb::DB*> src_db;
// 实例化完成一个titandb之后 可以将该titandb 赋值给src_db,
// 即 src_db[0] = titan_db;
std::vector<rocksdb::DB*> src_db;
std::vector<rocksdb::titandb::TitanDB*> titan_db;
rocksdb::Options options;
rocksdb::titandb::TitanOptions titan_options;
std::mt19937 generator_; // 生成伪随机数static double now()
{struct timeval t;gettimeofday(&t, NULL);return t.tv_sec + t.tv_usec / 1e6;
}void SetOptions() {options.create_if_missing = true;options.compression = rocksdb::kNoCompression;options.statistics = rocksdb::CreateDBStatistics();options.stats_persist_period_sec = 10;options.stats_dump_period_sec = 10;std::shared_ptr<rocksdb::Cache> cache = rocksdb::NewLRUCache(10737418240);rocksdb::BlockBasedTableOptions bbto;bbto.whole_key_filtering = true;bbto.cache_index_and_filter_blocks = true;bbto.filter_policy.reset(rocksdb::NewBloomFilterPolicy(16,false));bbto.block_cache = cache;options.table_factory.reset(rocksdb::NewBlockBasedTableFactory(bbto));options.max_background_compactions = 32;if(FLAGS_rate_limiter) {options.strict_bytes_per_sync = true;options.bytes_per_sync = 1024*1024;options.rate_limiter.reset(rocksdb::NewGenericRateLimiter(FLAGS_limit_size*1024*1024,100*1000,10,rocksdb::RateLimiter::Mode::kWritesOnly,true));}if(FLAGS_use_titan) {titan_options = options;}
}
void OpenDB() {SetOptions();for (int i = 1;i <= FLAGS_multidb_nums; i ++) {if (FLAGS_use_titan) {rocksdb::titandb::TitanDB* tmp_db;auto s = rocksdb::titandb::TitanDB::Open(titan_options, FLAGS_db_dir+std::to_string(i), &tmp_db);if (!s.ok()) {std::cout << "open failed :" << s.ToString() << std::endl;}titan_db.push_back(tmp_db);} else {rocksdb::DB* tmp_db;auto s = rocksdb::DB::Open(options, FLAGS_db_dir+std::to_string(i), &tmp_db);if (!s.ok()) {std::cout << "open failed :" << s.ToString() << std::endl;}src_db.push_back(tmp_db);}}
}void DBWrite(int num) {double ts = now();int db_num = num % FLAGS_multidb_nums;while (true) {std::string key = std::to_string(generator_());std::string value(FLAGS_value_len, 'x');if(num == 0) {rocksdb::SetPerfLevel(rocksdb::PerfLevel::kEnableTimeExceptForMutex);rocksdb::get_perf_context()->Reset();rocksdb::get_iostats_context()->Reset();}rocksdb::WriteOptions wo;wo.disableWAL = FLAGS_disable_wal;if(FLAGS_use_titan) {titan_db[db_num]->Put(wo, "test_graph_"+key, value);} else {src_db[db_num]->Put(wo, "test_graph_"+key, value);}++g_op_W;if(num == 0 && now() - ts >= 1) { // 每隔一秒,打印一次0号线程的延时数据rocksdb::SetPerfLevel(rocksdb::PerfLevel::kDisable);std::cout<< "\nwrite_wal_time "<< rocksdb::get_perf_context()->write_wal_time<< "\nwrite_memtable_time "<< rocksdb::get_perf_context()->write_memtable_time<< "\nwrite_delay_time "<< rocksdb::get_perf_context()->write_delay_time<< std::endl;ts = now();}}
}void DBRead(int num) {std::string value;double ts = now();int db_num = num % FLAGS_multidb_nums;while (true) {std::string key = std::to_string(generator_());if(num == 0) { // 为0号线程开启 perfrocksdb::SetPerfLevel(rocksdb::PerfLevel::kEnableTimeExceptForMutex);rocksdb::get_perf_context()->Reset();rocksdb::get_iostats_context()->Reset();}if(FLAGS_use_titan) {titan_db[db_num]->Get(rocksdb::ReadOptions(), key, &value);} else {src_db[db_num]->Get(rocksdb::ReadOptions(), key, &value);}++g_op_R;if(num == 0 && now() - ts >= 1) {rocksdb::SetPerfLevel(rocksdb::PerfLevel::kDisable);std::cout<< "\nget_from_memtable_time: " << rocksdb::get_perf_context()->get_from_memtable_time<< "\nget_from_output_files_time: " << rocksdb::get_perf_context()->get_from_output_files_time<< "\nread_nanos "<< rocksdb::get_iostats_context()-> read_nanos<< std::endl;ts = now();}}
}int main(int argc, char** argv) {ParseCommandLineFlags(&argc,&argv, true);OpenDB();if (FLAGS_multidb_nums > FLAGS_thread_num) {std::cout << "multidb nums bigger than thread num, invalid" << std::endl;return -1;}int write_threads = (int)(FLAGS_thread_num - (double)FLAGS_read_ratio / 100.0 * FLAGS_thread_num);for (int i = 0;i < FLAGS_thread_num - write_threads ; i++) {new std::thread(DBRead, i);}for(int i = 0;i < write_threads; ++i) {new std::thread(DBWrite, i);}long last_opn_R = 0;long last_opn_W = 0;int count = FLAGS_time;while(count > 0) {sleep(1);long nopn_R = g_op_R;long nopn_W = g_op_W;std::cout << "read_speed : " << nopn_R - last_opn_R << std::endl;std::cout << "write_speed : " << nopn_W - last_opn_W << std::endl;last_opn_R = nopn_R;last_opn_W = nopn_W;count --;std::string out;// src_db[0]->GetProperty("rocksdb.stats", &out); // 每一层的延时信息// fprintf(stdout, "rocksdb.stats: %s\n", out.c_str());}return 0;
}
相关文章:
Java项目:医院住院管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 住院病人管理,住院病房管理,医生管理,药品管理,仪 器管理等等。 二、项目运行 环境配置: Jdk1.8 Tomcat8.…

1m网速是什么意思,1m带宽是什么意思
1M网速下载速度应是多少?我怎么才50多KB?? 建议: 一般来说是90到100算正常。最高能达到120 带究竟该有多快 揭开ADSL真正速度之谜 常常使用ADSL的用户,你知道ADSL的真正速度吗?带着这个疑问我们将问题一步一步展开。…
泛型实体类List绑定到repeater
泛型实体类List<>绑定到repeater 后台代码: private void bindnewslist(){long num 100L;List<Model.news> news _news.GetList(out num);this.newslist.DataSource news;this.newslist.DataBind();} 说明:Model.news是实体类,…

Qt4.8.5移植
这两天搞了Qt移植 因为不小心 耽误了挺多时间 但是也比较好的掌握了 现在记录一下 准备工具: tslib-1.16 qt-everywhere-opensource-src-4.8.5.tar 下载路径: tslib-1.16下载: https://github.com/kergoth/tslib/releases/download/1.16/t…
Rocksdb 通过ingestfile 来支持高效的离线数据导入
文章目录前言使用方式实现原理总结前言 很多时候,我们使用数据库时会有离线向数据库导入数据的需求。比如大量用户在本地的一些离线数据,想要将这一些数据导入到已有的数据库中;或者说NewSQL场景中部分机器离线,重新上线之后的数…
Java项目:企业人事管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能介绍:员工管理,用户管理,部门管理,文档管理, 职位管理等等。 二、项目运行 环境配置: Jdk1.8 Tomcat8.5 mysql Eclispe (I…

XCODE 6.1.1 配置GLFW
最近在学习opengl的相关知识。第一件事就是配环境(好烦躁)。了解了一下os x下的OpenGL开源库,主要有几个:GLUT,freeglut,GLFW等。关于其详细的介绍可以参考opengl网站(https://www.opengl.org/wiki/Related_toolkits_and_APIs)。由…
SpringCloud远程调用为啥要采用HTTP,而不是RPC?
通俗的说法就是:比如说现在有两台服务器A和B,一个应用部署在A服务器上,另一个应用部署在B服务器上,如果A应用想要调用B应用提供的方法,由于他们不在一台机器下,也就是说它们不在一个JVM内存空间中,是无法直接调用的,需要通过网络进行调用,那这个调用过程就叫做RPC。建立Socket连接至少需要一对套接字,其中一个运行于客户端,称为ClientSocket ,另一个运行于服务器端,称为ServerSocket ,套接字之间的连接过程分为三个步骤:服务器监听,客户端请求,连接确认。

vs快捷键及常用设置(vs2012版)
vs快捷键: 1、ctrlf F是Find的简写,意为查找。在vs工具中按此快捷键,可以查看相关的关键词。比如查找哪些页面引用了某个类等。再配合查找范围(整个解决方案、当前项目、当前文档等),可以快速的找到问题所在…

python_day10
小甲鱼python学习笔记 爬虫之正则表达式 1.入门(要import re) 正则表达式中查找示例: >>> import re >>> re.search(rFishC,I love FishC.com) <re.Match object; span(7, 12), matchFishC> >>> #单纯的这种…
Graphics2D API:Canvas操作
在中已经介绍了Canvas基本的绘图方法,本篇介绍一些基本的画布操作.注意:1、画布操作针对的是画布,而不是画布上的图形2、画布变换、裁剪影响后续图形的绘制,对之前已经绘制过的内容没有影响。
关于Titandb Ratelimiter 失效问题的一个bugfix
本文简单讨论一下在TitanDB 中使用Ratelimiter的一个bug,也算是一个重要bug了,相关fix已经提了PR到tikv 社区了pull-210。 这个问题导致的现象是ratelimiter 在titandb Flush/GC 生成blobfiled的过程中无法生效,也就是无法限制titandb的主要…
Java项目:前台预定+后台管理酒店管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能介绍: 前台用户端:用户注册登录,房间展示,房间分类,房间 按价格区间查询,房间评论,房间预订等等 后台管…
Solr初始化源码分析-Solr初始化与启动
用solr做项目已经有一年有余,但都是使用层面,只是利用solr现有机制,修改参数,然后监控调优,从没有对solr进行源码级别的研究。但是,最近手头的一个项目,让我感觉必须把solrn内部原理和扩展机制弄…
iOS :UIPickerView reloadAllComponets not work
编辑信息页面用了很多选择栏,大部分都用 UIPickerView 来实现。在切换数据显示的时候, UIPickerView 不更新数据,不得其解。Google 无解,原因在于无法描述自己的问题,想想应该还是代码哪里写错了。 写了个测试方法&…
单相计量芯片RN8209D使用经验分享(转)
单相计量芯片RN8209D使用经验分享转载于:https://www.cnblogs.com/LittleTiger/p/10736060.html
git 对之前的commit 进行重新签名 Resign
在向开源社区提交PR的时候如果之前的提交忘记添加sign (个人签名/公司签名),则社区的DCO检查会失败。 关于通过DCO检查能够确保以下几件事情生效: 你所提交的贡献是由你自己完成或者 你参与了其中,并且有权利按照开源…

【原创】linux命令bc使用详解
最近经常要在linux下做一些进制转换,看到了可以使用bc命令,如下: echo "obase10;ibase16;CFFF" | bc 用完以后就对bc进行了进一步的了解, man bc里面有详细的使用说明。 1.是什么,怎么用 bc - An arbitrary precision calculator language 一…
Java项目:学生信息管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 用户的登录注册,学生信息管理,教师信息管理,班级信 息管理,采用mvcx项目架构,覆盖增删改查,包括学…
MVC學習網站
http://www.cnblogs.com/haogj/archive/2011/11/23/2246032.html
数据导出Excel表格
public String exportInfoFr(String path,String name,String startdate,String enddate,SysUser user){List<Map<String, Object>> list this.esEntPermitErrDao.findListObjectBySql("select 字段值1,字段值2,字段值3,字段值4,字段值5 from 表名 where 字段…
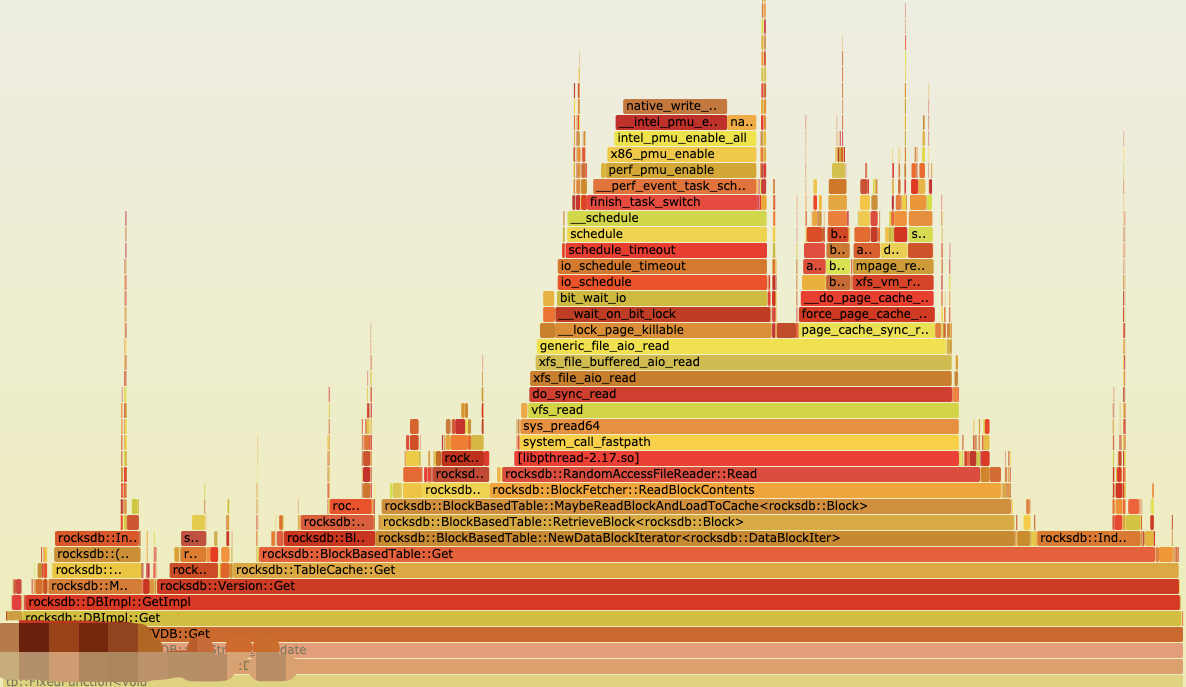
Rocksdb 通过posix_advise 让内核减少在page_cache的预读
文章目录1. 问题排查确认I/O完全/大多数来自于rocksdb确认此时系统只使用了rocksdb的Get来读确认每次系统调用下发读的请求大小确认是否在内核发生了预读2. 问题原因内核预读机制page_cache_sync_readaheadondemand_readahead3. 优化事情起源于 组内的分布式kv 系统使用rocksdb…
[leetcode] Minimum Path Sum
Minimum Path Sum Given a m x n grid filled with non-negative numbers, find a path from top left to bottom right which minimizes the sum of all numbers along its path. Note: You can only move either down or right at any point in time.分析:动态规划…
Java项目:在线小说阅读系统(读者+作者+管理员)(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 1:用户及主要操作功能 游客可以浏览网站的主页,登陆注册,小说湿度,下单购 买,订单查询,个人信息查询…
游戏中的脚本语言
本文最初发表于《游戏创造》(http://www.chinagcn.com)2007年8月刊。版权所有,侵权必究。如蒙转载,必须保留本声明,和作者署名;不得用于商业用途,必须保证全文完整。网络版首次发表于恋花蝶的博客(http://blog.csdn.ne…

mvn项目中的pom文件提示Error parsing lifecycle processing instructions解决
清空.m2/repository下的所有依赖文件,重新下载即可解决该问题。 如果本地用户下没有.m2/repository 目录,找到如下mvn 指定的repository,进去之后清空所有文件。 转载于:https://www.cnblogs.com/Hackerman/p/10736498.html
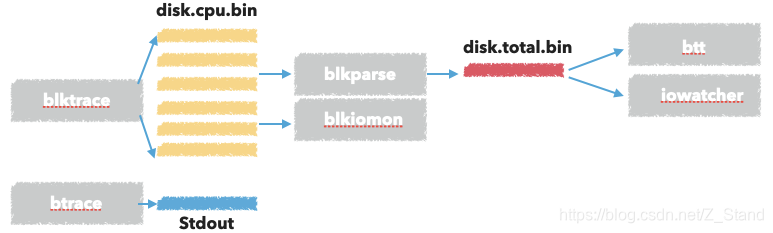
blktrace 工具集使用 及其实现原理
文章目录工具使用原理分析内核I/O栈blktrace 代码做的事情内核调用 ioctl 做的事情BLKTRACESETUPBLKTRACESTOPBLKTRACETEARDOWN内核 调用blk_register_tracepoints 之后做的事情参考最近使用blktrace 工具集来分析I/O 在磁盘上的一些瓶颈问题,特此做一个简单的记录。…

Java项目:教材管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 管理员可以增删改查教材、教材商、入库教材、用户(用 户包括学生和教师)可以对教材商、教材进行。xcel的导入 导出操作。教U阿以领取入库的教材,可以退还教材…
mysql更改数据文件目录及my.ini位置| MySQL命令详解
需求:更改mysql数据数据文件目录及my.ini位置。 步骤: 1、查找my.ini位置,可通过windows服务所对应mysql启动项,查看其对应属性->可执行文件路径,获取my.ini路径。 "D:\MySQL\MySQL Server 5.5\bin\mysqld&quo…

私有云管理-Windows Azure Pack
今天是2014年的第一天,今年的第一篇博客关于私有云,而我在2014年的主要目标也是针对私有云。随着Windows Azure在中国的落地,大家逐渐的熟悉了在Windows Azure中的云体验。而微软针对私有云、混合云推出了一个管理自助门户,Window…