Rocksdb 通过posix_advise 让内核减少在page_cache的预读
文章目录
- 1. 问题排查
- 确认I/O完全/大多数来自于rocksdb
- 确认此时系统只使用了rocksdb的Get来读
- 确认每次系统调用下发读的请求大小
- 确认是否在内核发生了预读
- 2. 问题原因
- 内核预读机制
- page_cache_sync_readahead
- ondemand_readahead
- 3. 优化
事情起源于 组内的分布式kv 系统使用rocksdb过程中发现磁盘有超过预期3-4x的读I/O问题,因为禁止了block-cache,也就是每一次Get会对应一次磁盘I/O,刚好上层Get的qps和下层磁盘的r/s 基本吻合,也就是一次读,读了超过3个page。但是实际写入的value也就 128B,按照nvme的block size 4K的配置,读上来3个page则远超过了我们的预期。
本文涉及的代码 rocksdb版本是 6.4.6,linux 内核版本是 3.10.1
1. 问题排查
看到了严重的读放大现象之后,接下来一探问题的原因。
确认I/O完全/大多数来自于rocksdb
当我们不知道kv系统内部如何使用rocksdb的情况下需要确认这一些IO的来源。
抓I/O 线程栈
sudo iotop能直接看到系统中的磁盘i/o来源的线程如果此时能够看到具体的线程名称,确认是在读rocksdb,OK,跳过这一步
sudo pstack tid抓取一个线程栈pstack的逻辑是通过gdb attach进去 执行bt,多抓几次就能够知道I/O线程大多数的时间在干嘛
这里发现确实是在rocksdb的
Get调用栈上Thread 1 (process 1201132): #0 0x00007fa59de53f73 in pread64 () from /lib64/libpthread.so.0 #1 0x00000000009020c3 in pread (__offset=56899894, __nbytes=3428, __buf=0x7fa4a83bb670, __fd=<optimized out>) at /usr/include/bits/unistd.h:83 #2 rocksdb::PosixRandomAccessFile::Read(unsigned long, unsigned long, rocksdb::IOOptions const&, rocksdb::Slice*, char*, rocksdb::IODebugContext*) const () at thirdpartty/rocksdb/env/io_posix.cc:453 #3 0x0000000000a074f7 in rocksdb::RandomAccessFileReader::Read(unsigned long, unsigned long, rocksdb::Slice*, char*, bool) const () at thirdpartty/rocksdb/monitoring/statistics.h:127 #4 0x000000000097b8e9 in rocksdb::BlockFetcher::ReadBlockContents() () at thirdpartty/rocksdb/table/format.h:45 #5 0x000000000095bd87 in rocksdb::BlockBasedTable::MaybeReadBlockAndLoadToCache<rocksdb::Block> (this=0xf2083e80, prefetch_buffer=0x0, ro=..., handle=..., uncompression_dict=..., block_entry=0x7fa4a83bcc10, block_type=rocksdb::kData, get_context=0x7fa4a83bd630, lookup_context=0x7fa4a83bcf50, contents=0x0) at thirdpartty/rocksdb/include/rocksdb/cache.h:272 #6 0x000000000095c1d1 in rocksdb::BlockBasedTable::RetrieveBlock<rocksdb::Block> (this=this@entry=0xf2083e80, prefetch_buffer=prefetch_buffer@entry=0x0, ro=..., handle=..., uncompression_dict=..., block_entry=0x7fa4a83bcc10, block_type=rocksdb::kData, get_context=0x7fa4a83bd630, lookup_context=0x7fa4a83bcf50, for_compaction=false, use_cache=true) at thirdpartty/rocksdb/table/block_based/block_based_table_reader.h:585 #7 0x000000000095ef3a in rocksdb::BlockBasedTable::NewDataBlockIterator<rocksdb::DataBlockIter> (this=this@entry=0xf2083e80, ro=..., handle=..., input_iter=input_iter@entry=0x7fa4a83bd190, block_type=block_type@entry=rocksdb::kData, get_context=get_context@entry=0x7fa4a83bd630, lookup_context=0x7fa4a83bcf50, s=..., prefetch_buffer=0x0, for_compaction=false) at thirdpartty/rocksdb/monitoring/perf_step_timer.h:41 #8 0x000000000096a4a1 in rocksdb::BlockBasedTable::Get(rocksdb::ReadOptions const&, rocksdb::Slice const&, rocksdb::GetContext*, rocksdb::SliceTransform const*, bool) () at thirdpartty/rocksdb/table/block_based/block_based_table_reader.cc:3288 #9 0x00000000008a1c0c in rocksdb::TableCache::Get(rocksdb::ReadOptions const&, rocksdb::InternalKeyComparator const&, rocksdb::FileMetaData const&, rocksdb::Slice const&, rocksdb::GetContext*, rocksdb::SliceTransform const*, rocksdb::HistogramImpl*, bool, int) () at thirdpartty/rocksdb/db/table_cache.cc:406
抓取进程都在操作哪一些文件,和上面的进程栈信息double check一下
这里需要系统支持eBPF,使用了一个bcc工具集中的一个opensnoop命令。opensnoop -p pid能够看到当前进程按顺序操作的文件,都会打印出来# opensnoop -p 1200034|grep sst 1200034 rocksdb:low3 6929 0 ../db/13/064388.sst 1200034 rocksdb:low3 14988 0 ../db/13/064389.sst 1200034 rocksdb:low3 18074 0 ../db/13/064390.sst 1200034 rocksdb:low12 3158 0 ../db/11/064350.sst 1200034 rocksdb:low0 9030 0 ../db/31/064494.sst 1200034 rocksdb:low1 10111 0 ../db/19/064495.sst 1200034 rocksdb:low2 1691 0 ../db/0/064570.sst 1200034 test_process/w4- 2879 0 00000000001494113842.sst 1200034 rocksdb:low10 1974 0 ../db/7/064437.sst 1200034 rocksdb:low4 3696 0 ../db/14/064445.sst 1200034 rocksdb:low12 3158 0 ../db/11/064351.sst 1200034 rocksdb:low11 3017 0 ../db/21/064524.sst可以看到除了rocksdb的sst文件之外,还有一个其他的文件,但是我们主体的读取都是sst,所以基本能够确认磁盘的读i/o都是来源于rocksdb.
确认此时系统只使用了rocksdb的Get来读
到这里,我们能够确认I/O是由rocksdb产生的,可能会想是不是kv系统中使用rocksdb的方式有问题,他们可能不仅仅是用了Get,在某一个他们也不清楚的线程里用了迭代器扫描,才产生这么多的I/O,我们想要确认这个问题。这个时候之前使用的pstack调用栈就不够用了,因为它只是一个线程,而我们要用它抓更多的线程比较麻烦,简单且直观的办法就是火焰图。
现在有大量的I/O,而且rocksdb的操作基本都是on-cpu的,所以直接看on-cpu的火焰图就非常容易得看到IO调用栈的来源了。
通过如下脚本立即抓取
#!/bin/sh
DIR=./git clone https://github.com/brendangregg/FlameGraph # clone 火焰图目录
if [ $? -ne 0 ]; thenecho "clone FlameGraph failed"exit -1
ficd FlameGraph
sudo perf record -F 99 -p $1 -g -o $DIR/"$1".data -- sleep $2
sudo perf script -i $DIR/"$1".data > $DIR/"$1".perf
stackcollapse-perf.pl $DIR/"$1".perf > $DIR/"$1".folded
flamegraph.pl $DIR/"$1".folded > $DIR/"$1".svgcp $DIR/cpu1.svg ../
会在当前目录下生成一个$pid.svg的文件,使用浏览器打开即可看到完整的on-cpu调用栈
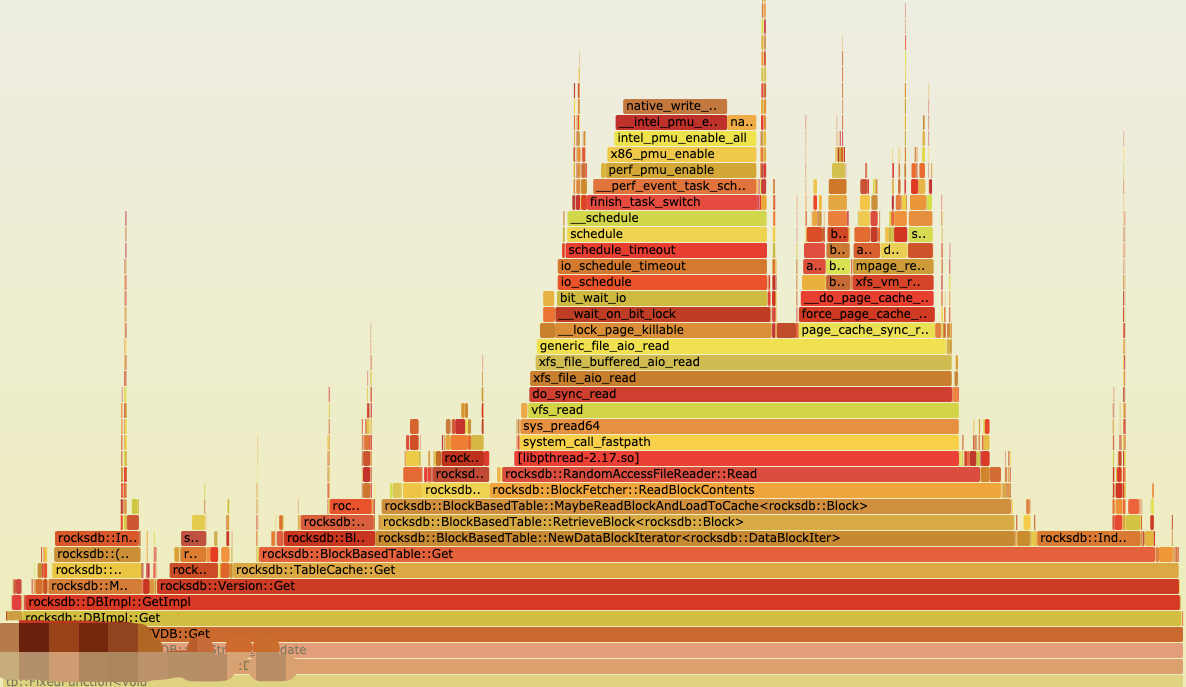
看起来确实是大多数的cpu都消耗在了rocksdb的Get调用栈上了,好吧。。。问题躲不开了。
确认每次系统调用下发读的请求大小
按照我们对磁盘读取的正常逻辑理解,如果读取的数据块大小小于正常的磁盘块4k大小的话 从磁盘文件系统下发的读取请求会填充成一个4k的cache页面,读取一个磁盘的block。
所以为什么它这里会读取这么多的block,估算上层的总磁盘带宽/总qps 可以得到每个请求大概读了3-4个block,而实际的value大小也就128B,读取sst的时候会把这个value所在的datablock整个读上来,默认一个datablock是4k,这就很奇怪了。
为了确认rocksdb侧的pread64系统调用确实读的内容比较少,我们要获取系统调用每次读的请求大小,看是不是rocksdb 拼接的请求有问题。
执行命令:sudo strace -ttt -T -F -p 1200034 -e trace=pread64 -o strace.txt 追踪pread64系统调用,并打印每个系统调用的时间,最后的结果保存在strace.txt中。
1200069 1619615339.683332 pread64(3686, <unfinished ...>
1200067 1619615339.683750 pread64(23901, <unfinished ...>
1200064 1619615339.683761 pread64(6470, <unfinished ...>
1200060 1619615339.683776 pread64(17541, <unfinished ...>
1200058 1619615339.683784 pread64(15210, <unfinished ...>
1200069 1619615339.686670 <... pread64 resumed> "\0\34\232\1abcdefghij2376553061\1\202\326\216X\0\0\0"..., 3941, 26362727) = 3941 <0.002925>
1200067 1619615339.686696 <... pread64 resumed> "\320\0\0\0\0\0\0\0\341\307\326\315\246I\0\0\6\24\0\0\0abcdefghij3"..., 3950, 30242502) = 3950 <0.002944>
1200064 1619615339.686711 <... pread64 resumed> "`\30\260\200\237\356\354\264\22\21\220\23\336%\0\0\0\0m-\323Y\0\0\0\0\320\0\0\0\0\0"..., 3422, 18387244) = 3422 <0.002949>
1200060 1619615339.686726 <... pread64 resumed> "\311\4\323\32\0\32\6abcdefghij46297319\21\377\377\377\377\377\377"..., 3941, 31861449) = 3941 <0.002948>
1200058 1619615339.686734 <... pread64 resumed> "7,<Qz p&~dHZ!i5kvVUU^Jgc%vA/F;uL"..., 3977, 15684275) = 3977 <0.002949>
...如果想要确认这个pread64读的文件句柄是rocksdb的sst文件,可以通过 sudo ls -l /proc/1200034/fd/15210 来看这个进程打开的文件句柄确实是连结到了sst文件。
通过上面抓到的pread64系统调用信息,可以很明显的发现系统调用下发的是小于4K的请求大小。。。我擦嘞。
立即通过btrace再抓一下磁盘I/O:
$ sudo btrace -a read /dev/nvme0n1
259,0 32 1 0.000000000 1201042 Q RA 5033391024 + 32 [test_process]
259,0 32 2 0.000001625 1201042 G RA 5033391024 + 32 [test_process]
259,0 32 3 0.000001926 1201042 P N [test_process]
259,0 32 4 0.000002279 1201042 U N [test_process] 1
259,0 32 5 0.000003219 1201042 D RA 5033391024 + 32 [test_process]
259,0 33 1 0.000010787 1201046 Q RA 3397669536 + 24 [test_process]
259,0 33 2 0.000012535 1201046 G RA 3397669536 + 32 [test_process]
259,0 33 3 0.000012992 1201046 P N [test_process]
259,0 33 4 0.000013308 1201046 U N [test_process] 1
259,0 33 5 0.000014375 1201046 D RA 3397669536 + 32 [test_process]
259,0 3 1 0.000024160 1201030 Q RA 32733208 + 32 [test_process]
259,0 3 2 0.000025016 1201030 G RA 32733208 + 24 [test_process]
259,0 3 3 0.000025320 1201030 P N [test_process]
259,0 3 4 0.000025660 1201030 U N [test_process] 1
259,0 3 5 0.000026382 1201030 D RA 32733208 + 32 [test_process]
259,0 3 6 0.000032077 843424 C RA 5618458520 + 32 [0]
259,0 32 6 0.000067811 1201120 Q RA 4936712824 + 32 [test_process]
259,0 32 7 0.000068510 1201120 G RA 4936712824 + 32 [test_process]
...
可以看到确实,从磁盘上读到了很多超过2个4k的block,也就是系统调用pread64下发了小于一个block的请求,而落到磁盘的I/O达到了4个block。。。interesting。
确认是否在内核发生了预读
只能进入内核逻辑了,看起来像是操作系统的预读逻辑。
顺着火焰图的调用栈来看,我们的pread系统调用的调用栈如下:
sys_pread64vfs_readdo_sync_readxfs_file_aio_readxfs_file_buffered_aio_readgeneric_file_aio_readdo_generic_file_readpage_cache_sync_readahead
实际由page-cache下发读取的页面个数是在page_cache_sync_readahead 的参数中。
这里我们抛开内核函数的逻辑,想要单纯确认一下do_generic_file_read下发的请求数目,可以通过stap来抓取一下这个函数的变量
void page_cache_sync_readahead(struct address_space *mapping,struct file_ra_state *ra, struct file *filp,pgoff_t offset, unsigned long req_size);#!/bin/stapprobe kernel.function("page_cache_sync_readahead").call {printf("req_size : %lu\n", $req_size);
}
可以发现page_cache_sync_readahead这个函数的时候仅仅才1个页面。
继续向下,看到page_cache_sync_readahead 内部实现有两个分支:
void page_cache_sync_readahead(struct address_space *mapping,struct file_ra_state *ra, struct file *filp,pgoff_t offset, unsigned long req_size)
{/* no read-ahead */if (!ra->ra_pages)return;/* be dumb */if (filp && (filp->f_mode & FMODE_RANDOM)) {force_page_cache_readahead(mapping, filp, offset, req_size);return;}/* do read-ahead */ondemand_readahead(mapping, ra, filp, false, offset, req_size);
}
这里后续会说明这里的两个分支到底作用为何?
不过抓这个函数的stap发现只能读到1个page的请求,也就是do_generic_file_read只下发了1个page。
通过注释能够看到如果要预读的话应该会在ondemand_readahead函数中,结合火焰图,这个函数预读的话最终会走到ra_submit --> __do_page_cache_readahead 逻辑,同样的stap抓一下这个函数的nr_to_read的参数,发现确实预读到了3-4个page。
定位到了函数:ondemand_readahead ,预读的多个页面就是在这里填充的,而ra_submit只是很薄的一层调用:
unsigned long ra_submit(struct file_ra_state *ra,struct address_space *mapping, struct file *filp)
{int actual;actual = __do_page_cache_readahead(mapping, filp,ra->start, ra->size, ra->async_size);return actual;
}
到此我们结合火焰图的调用栈知道了具体的哪个内核函数发生了预读,但是为什么还不清楚。
2. 问题原因
内核预读机制
内核的预读机制起源是我们还处于大多数存储场景都是HDD介质,磁盘的转动和磁头的寻道消耗太多的时间,而我们想要在HDD的基础上提升读性能,可以减少磁头移动的次数,连续读取多个扇区的数据内容就可以。实际的操作系统中,用户读取一个文件,一般会从头读到尾,这一些文件在磁盘上的存储都是连续的扇区,也就是可以利用预读来一次读取多个扇区,减少磁头频繁移动寻道。
当然,这个预读机制在我们的NVME上同样有效,现在大多数的nvme底层存储介质还是nand ,使用的是浮栅晶体管做存储单元,通过两极加正反电压来控制浮栅层内电子的移动情况。详细的底层nand存储介质原理介绍感兴趣的同学可以参考从NMOS 和 PCM 底层存储单元 来看NAND和3D XPoint的本质区别。回到要说的预读问题,有了预读,可以减少一次或者多次针对nvme的IO,也就能节省几十us-几个ms 的时间,极大得提升了系统的响应时间。
预读(read-ahead) 算法预测即将访问的页面,并提前将他们读入到page-cache中,后续的读取就不需要产生io了。
主要任务:
- 批量:把小I/O 聚集为大I/O,改善磁盘利用率,提升系统吞吐
- 提前:对应用程序隐藏磁盘的延迟,加快系统响应时间
- 预测:属于预读算法的核心任务。前两个功能都依赖准确的预测能力。包括linux , freeBSD, solaris 等主流操作系统都遵循一个原则:预读仅针对顺序读模式。这个模式比较简单且普遍,提升效果也更明显,但是随机读模式对于内核来说也是难以预测的。
触发预读 的条件:
内核处理用户进程读请求时调用:
page_cache_sync_readahead或page_cache_async_readahead内核为文件内存映射分配一个页面时,即调用
mmap用户进程执行系统调用
readahead用户进程在打开文件之后执行
posix_fadvise系统调用用户进程执行
madvise()系统调用,使用MADV_WILLNEEDflag 通知内核文件内存映射的指定区域将来会被访问
预读的过程 是:
预读算法的实现是通过维护两个窗口:当前窗口(current window) 和 前进窗口(ahead window)
用户进程当前访问的page 都会在current window中,当内核判读用户进程是顺序访问 且 初始访问页面是在当前窗口时就检查前进窗口是否建立,如果未建立,则建立一个新的前进窗口,并为对应的文件页面触发读操作。如果用户进程的读命中了前进窗口的页面,则将前进窗口切换为当前窗口。
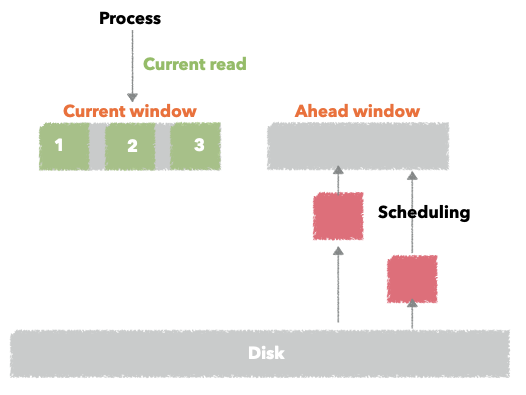
如上图,用户访问当前窗口的时候会构建前进窗口,理想情况下当前窗口的页面都是已经被cache住的,而前进窗口则还在调度页面到cache;当然也会有正在访问的当前窗口的页面正在调度的情况。
如果用户进程访问的页面命中了前进窗口,则前进窗口会切换为当前窗口,实际的前进窗口的大小会根据命中情况动态调整,命中到前进窗口的page越多,下次创建的前进窗口的大小则会更大一些,否则就会缩小。
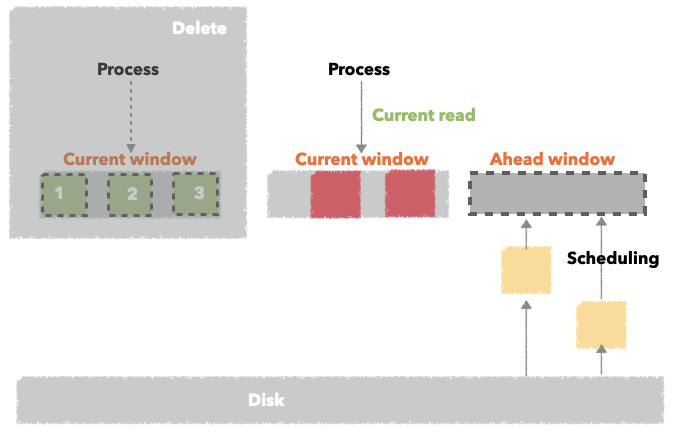
page_cache_sync_readahead
通过前面的问题分析过程,我们知道了在page_cache_sync_readahead的内部调用中发生了预读,用户下发的是一个页面,在它内部却读了超过3个页面。
看一下这个函数的逻辑,参数含义如下:
- mapping: 文件拥有者的address_space对象
- ra: 包含此页面的文件
file_ra_state描述符,持有是否进行预读的标记 - filp: 文件对象
- offset: 页面在文件中的起始偏移量
- req_size: 完成当前读操作需要的页面数
这个函数一般会在cache-miss的时候被调用,即它的调用者发现文件page不在cache中,触发这个函数去读对应的page,当然也包括了预读,因为前面我们通过systemtap抓这个函数的时候也只是下发了一个page,最后它内部的经过ondemand_readahead的处理返回了3个page。
void page_cache_sync_readahead(struct address_space *mapping,struct file_ra_state *ra, struct file *filp,pgoff_t offset, unsigned long req_size)
{/* no read-ahead */// 如果前面填充的readahead-pages是空的话直接返回if (!ra->ra_pages)return;/* be dumb */// 这里 FMODE_RANDOM 是由posix_advise指定的随机读标记,不需要预读if (filp && (filp->f_mode & FMODE_RANDOM)) {force_page_cache_readahead(mapping, filp, offset, req_size);return;}/* do read-ahead */// 真正执行预读的逻辑。ondemand_readahead(mapping, ra, filp, false, offset, req_size);
}
可以看到,第二个分支中 会判断文件mode是否为FMODE_RANDOM ,如果是的话就不执行预读了,仅仅读当前用户进程需要读的page。这个标记可以由用户进程打开文件的时候通过posix_advise来指定。
指定的逻辑在posix_advise系统调用的实现中:
SYSCALL_DEFINE4(fadvise64_64, int, fd, loff_t, offset, loff_t, len, int, advice) {...case POSIX_FADV_RANDOM:spin_lock(&f.file->f_lock);f.file->f_mode |= FMODE_RANDOM;spin_unlock(&f.file->f_lock);break;...
}
回到我们要讨论的预读逻辑中,接下来看一下真正执行预读的函数ondemand_readahead
ondemand_readahead
这个函数主要是根据传入的file_ra_state描述符执行一些动作,函数参数还是刚才page_cache_sync_readahead函数传入进来的。
主体逻辑是
- 首先判断读取是否从文件开头开始,如果是,则初始化预读信息。默认设置的是4个page
- 如果不是文件头,则判断是否是顺序访问(连续读),如果是,则扩大预读数量,一般是上次预读数量x2
- 如果不是顺序访问, 则认为是随机读,不适合预读,只会读取sys_read请求的page数量。
- 最后调用
ra_submit提交读请求
static unsigned long
ondemand_readahead(struct address_space *mapping,struct file_ra_state *ra, struct file *filp,bool hit_readahead_marker, pgoff_t offset,unsigned long req_size)
{unsigned long max = max_sane_readahead(ra->ra_pages);/** start of file*/// 判断是否是从文件开头读取,offset=0// 如果是,则会调用get_init_ra_size 初始化预读页面if (!offset)goto initial_readahead;/** It's the expected callback offset, assume sequential access.* Ramp up sizes, and push forward the readahead window.*/// 如果不是从文件开始预读,且是顺序读(发现当前的偏移地址是上次读的起始地址+size)// 通过get_next_ra_size 扩大预读窗口if ((offset == (ra->start + ra->size - ra->async_size) ||offset == (ra->start + ra->size))) {ra->start += ra->size;ra->size = get_next_ra_size(ra, max);ra->async_size = ra->size;goto readit; // 进入ra_submit执行实际的预读}/** Hit a marked page without valid readahead state.* E.g. interleaved reads.* Query the pagecache for async_size, which normally equals to* readahead size. Ramp it up and use it as the new readahead size.*/// 发现当前文件被打上了一个预读失效的标记,这里默认传入的是falseif (hit_readahead_marker) {pgoff_t start;rcu_read_lock();start = radix_tree_next_hole(&mapping->page_tree, offset+1,max);rcu_read_unlock();if (!start || start - offset > max)return 0;ra->start = start;ra->size = start - offset; /* old async_size */ra->size += req_size;ra->size = get_next_ra_size(ra, max);ra->async_size = ra->size;goto readit;}/** oversize read*/// 大块预读,即sys_read请求的页面大小超过了最大的预读设置// 重新初始化预读窗口,预读更多的页面if (req_size > max)goto initial_readahead;/** sequential cache miss*/// 内核重新发现当前读是顺序读,创建新的当前窗口if (offset - (ra->prev_pos >> PAGE_CACHE_SHIFT) <= 1UL)goto initial_readahead;/** Query the page cache and look for the traces(cached history pages)* that a sequential stream would leave behind.*/// 这个函数里面发现不是顺序读,会返回0,直接不进行预读了// 后续的__do_page_cache_readahead 函数readahead size被设置为0 了if (try_context_readahead(mapping, ra, offset, req_size, max))goto readit;/** standalone, small random read* Read as is, and do not pollute the readahead state.*/return __do_page_cache_readahead(mapping, filp, offset, req_size, 0);// 初始化当前预读窗口
initial_readahead:ra->start = offset;ra->size = get_init_ra_size(req_size, max);ra->async_size = ra->size > req_size ? ra->size - req_size : ra->size;readit:/** Will this read hit the readahead marker made by itself?* If so, trigger the readahead marker hit now, and merge* the resulted next readahead window into the current one.*/if (offset == ra->start && ra->size == ra->async_size) {ra->async_size = get_next_ra_size(ra, max);ra->size += ra->async_size;}// 实际进行预读指定page个数的调用return ra_submit(ra, mapping, filp);
}
3. 优化
到这里我们就知道了操作系统的预读优化主要是针对顺序读场景,且会动态调整预读窗口的大小。那回到我们rocksdb这里,业务下发的是随机读,但部分读请求显然是发生了预读。因为测试的场景是用极少blockcache的,也就是这一些想要预读到page-cache的datablock 大多数都不会被cache住。
那我们有没有办法完全不让操作系统预读呢,减少这个场景下的预读I/O 。
回到rocksdb 读datablock 的逻辑:
rocksdb::DBImpl::Getrocksdb::DBImpl::GetImplrocksdb::Version::Getrocksdb::TableCache::Getrocksdb::BlockBasedTable::Getrocksdb::BlockBasedTable::NewDataBlockIterator<rocksdb::DataBlockIter>rocksdb::BlockBasedTable::RetrieveBlock<rocksdb::Block>rocksdb::BlockBasedTable::MaybeReadBlockAndLoadToCache<rocksdb::Block>rocksdb::BlockFetcher::ReadBlockContentsrocksdb::RandomAccessFileReader::Read
其中在rocksdb::TableCache::Get 逻辑中需要先找到点查的sst文件,获取一个文件handle
会进入到如下逻辑:
TableCache::FindTable // 如果在 block_cache 中找不到,则会进入如下逻辑中。本身我们设置的blockcache也很小,大多数的key都找不到TableCache::GetTableReader
在GetTableReader逻辑中主要是创建一个BlockBasedTable的FileReader。
Status TableCache::GetTableReader(const EnvOptions& env_options,const InternalKeyComparator& internal_comparator, const FileDescriptor& fd,bool sequential_mode, bool record_read_stats, HistogramImpl* file_read_hist,std::unique_ptr<TableReader>* table_reader,const SliceTransform* prefix_extractor, bool skip_filters, int level,bool prefetch_index_and_filter_in_cache) {std::string fname =TableFileName(ioptions_.cf_paths, fd.GetNumber(), fd.GetPathId());std::unique_ptr<RandomAccessFile> file;// 打开传入的文件Status s = ioptions_.env->NewRandomAccessFile(fname, &file, env_options);RecordTick(ioptions_.statistics, NO_FILE_OPENS);if (s.ok()) {// posix_fadvise 设置打开文件的读模式if (!sequential_mode && ioptions_.advise_random_on_open) {file->Hint(RandomAccessFile::RANDOM);}StopWatch sw(ioptions_.env, ioptions_.statistics, TABLE_OPEN_IO_MICROS);// 创建一个BlockBasedTable的table_readerstd::unique_ptr<RandomAccessFileReader> file_reader(new RandomAccessFileReader(std::move(file), fname, ioptions_.env,record_read_stats ? ioptions_.statistics : nullptr, SST_READ_MICROS,file_read_hist, ioptions_.rate_limiter, ioptions_.listeners));s = ioptions_.table_factory->NewTableReader(TableReaderOptions(ioptions_, prefix_extractor, env_options,internal_comparator, skip_filters, immortal_tables_,level, fd.largest_seqno, block_cache_tracer_),std::move(file_reader), fd.GetFileSize(), table_reader,prefetch_index_and_filter_in_cache);TEST_SYNC_POINT("TableCache::GetTableReader:0");}return s;
}
可以看到在GetTableReader的过程中会先打开文件,打开之后会根据sequential_mode和ioptions_.advise_random_on_open配置来设置文件的模式。这里默认的sequential_mode传入的时候是false,所以如果那个option是true,则会设置一个RANDOM。
其底层是通过posix_fadvise来设置文件的预读模式:
void PosixRandomAccessFile::Hint(AccessPattern pattern) {if (use_direct_io()) {return;}switch (pattern) {case NORMAL:Fadvise(fd_, 0, 0, POSIX_FADV_NORMAL);break;case RANDOM:// 对fd 下发RANDOM 标记Fadvise(fd_, 0, 0, POSIX_FADV_RANDOM);break;case SEQUENTIAL:Fadvise(fd_, 0, 0, POSIX_FADV_SEQUENTIAL);break;case WILLNEED:Fadvise(fd_, 0, 0, POSIX_FADV_WILLNEED);break;case DONTNEED:Fadvise(fd_, 0, 0, POSIX_FADV_DONTNEED);break;default:assert(false);break;}
}int Fadvise(int fd, off_t offset, size_t len, int advice) {
#ifdef OS_LINUXreturn posix_fadvise(fd, offset, len, advice);
#else(void)fd;(void)offset;(void)len;(void)advice;return 0; // simply do nothing.
#endif
}
到此,我们就知道了通过这里的选项 ioptions_.advise_random_on_open = true 能够让posix_fadvise设置内核的预读建议POSIX_FADV_RANDOM,让随机读场景不进行内核的自动预读。
最后,在page_cache_sync_readahead 中会进入到不进行预读的逻辑中。
相关文章:

[leetcode] Minimum Path Sum
Minimum Path Sum Given a m x n grid filled with non-negative numbers, find a path from top left to bottom right which minimizes the sum of all numbers along its path. Note: You can only move either down or right at any point in time.分析:动态规划…
Java项目:在线小说阅读系统(读者+作者+管理员)(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 1:用户及主要操作功能 游客可以浏览网站的主页,登陆注册,小说湿度,下单购 买,订单查询,个人信息查询…
游戏中的脚本语言
本文最初发表于《游戏创造》(http://www.chinagcn.com)2007年8月刊。版权所有,侵权必究。如蒙转载,必须保留本声明,和作者署名;不得用于商业用途,必须保证全文完整。网络版首次发表于恋花蝶的博客(http://blog.csdn.ne…

mvn项目中的pom文件提示Error parsing lifecycle processing instructions解决
清空.m2/repository下的所有依赖文件,重新下载即可解决该问题。 如果本地用户下没有.m2/repository 目录,找到如下mvn 指定的repository,进去之后清空所有文件。 转载于:https://www.cnblogs.com/Hackerman/p/10736498.html
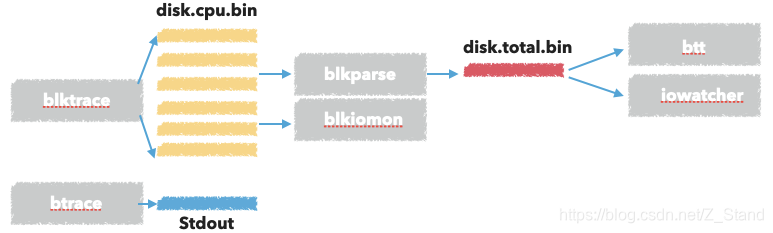
blktrace 工具集使用 及其实现原理
文章目录工具使用原理分析内核I/O栈blktrace 代码做的事情内核调用 ioctl 做的事情BLKTRACESETUPBLKTRACESTOPBLKTRACETEARDOWN内核 调用blk_register_tracepoints 之后做的事情参考最近使用blktrace 工具集来分析I/O 在磁盘上的一些瓶颈问题,特此做一个简单的记录。…

Java项目:教材管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 管理员可以增删改查教材、教材商、入库教材、用户(用 户包括学生和教师)可以对教材商、教材进行。xcel的导入 导出操作。教U阿以领取入库的教材,可以退还教材…
mysql更改数据文件目录及my.ini位置| MySQL命令详解
需求:更改mysql数据数据文件目录及my.ini位置。 步骤: 1、查找my.ini位置,可通过windows服务所对应mysql启动项,查看其对应属性->可执行文件路径,获取my.ini路径。 "D:\MySQL\MySQL Server 5.5\bin\mysqld&quo…

私有云管理-Windows Azure Pack
今天是2014年的第一天,今年的第一篇博客关于私有云,而我在2014年的主要目标也是针对私有云。随着Windows Azure在中国的落地,大家逐渐的熟悉了在Windows Azure中的云体验。而微软针对私有云、混合云推出了一个管理自助门户,Window…
面向对象(类的概念,属性,方法,属性的声明,面向对象编程思维
1 面向对象 1.1 你是如何认识新事物的? 从过往的事物中总结事物的特点(特征),并比对新事物,把新事物进行归类。 1.2 类(Class)的概念(A) 类是对一组具有相同特征和行为的对象的抽象描述。 理解: [1] 类包含了两个要素:特性和行为 > 同一类…
cannot find main module 解决办法
做6.824 实验的过程中想要跑测试,发现go test -run 2A时 出现cannot find main module问题,测试跑不起来。 原因 这个原因是从GO1.11 版本开始引入了go.mod文件来对项目中的go源码的编译相关的内容进行管理,经常使用GO的同学可能深受go get…
Java项目:网上选课系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能: 系统分为三个角色。最高权限管理员,学生,教师,包括 学生管理,教师管理,课程管理,选课,退课…

C#中类的继承 override virtual new的作用以及代码分析
继承中override virtual new的作用 virtual 父类中需要注明允许重写的方法; override 子类中必须显示声明该方法是重写的父类中的方法; new 子类中忽略父类的已存在的方法,“重写该方法“; C#中不支…

spring手动代码控制事务
为什么80%的码农都做不了架构师?>>> DataSourceTransactionManager tran new DataSourceTransactionManager(vjdbcTemplate.getDataSource());DefaultTransactionDefinition def new DefaultTransactionDefinition();//事务定义类def.setPropagationB…
tar命令-压缩,解压缩文件
tar: -c: 建立压缩档案 -x:解压 -t:查看内容 -r:向压缩归档文件末尾追加文件 -u:更新原压缩包中的文件 上面五个参数是独立的,压缩解压都要用到其中一个,可以和下面的命令连用但只能用其中一个。…

MIT 6.824 Lab2A (raft) -- Leader Election
文章目录实验要求Leader Election流程 及详细实现介绍基本角色关键超时变量关键的两个RPC实现RequestVote RPCAppendEntries RPCGo并发编程实现leader election调度本节记录的是完成MIT6.824 raft lab的leader Election部分实验。代码: https://github.com/BaronStack/MIT-6.82…
Java项目:在线考试系统(java+springboot+vue+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统主要实现的功能有: 学生以及老师的注册登录,在线考试,错题查询,学生管理,问题管理,错题管理,错题查询…
写给自己的web开发资源
web开发给我的感觉就是乱七八糟,而且要学习感觉总是会有东西要学习,很乱很杂我也没空搞,(其实学习这个的方法就是去用它,什么你直接用?学过js么学过jquery么?哈哈,我没有系统的看完过…

虚拟机VMWare“提示:软件虚拟化与此平台上的长模式不兼容”的解决方法
虚拟机VMWare“提示:软件虚拟化与此平台上的长模式不兼容”不少童鞋反映,在使用Windows7 64位操作系统时,无法运行VMWare或MS Virtual server等软件虚拟操作系统。提示为“提示:软件虚拟化与此平台上的长模式不兼容. 禁用长模式. …

如何在Vue项目中使用vw实现移动端适配(转)
有关于移动端的适配布局一直以来都是众说纷纭,对应的解决方案也是有很多种。在《使用Flexible实现手淘H5页面的终端适配》提出了Flexible的布局方案,随着viewport单位越来越受到众多浏览器的支持,因此在《再聊移动端页面的适配》一文中提出了…
Jsoncpp 在C++开发中的一些使用记录
jsoncpp 是一个C 语言实现的json库,非常方便得支持C得各种数据类型到json 以及 json到各种数据类型的转化。 一个json 类型的数据如下: {"code" : 10.01,"files" : "","msg" : "","uploadid&q…

Java项目:图书管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括(管理员和学生角色): 管理员和学生登录,图书管理,图书添加删除修改,图书 借阅,图书归还,图书查看,学…

使用 Flash Builder 的 Apple iOS 开发过程
使用 Flash Builder 的 Apple iOS 开发过程 iOS 开发和部署过程概述 构建、调试或部署 iOS 应用程序前的准备工作 在测试、调试或安装 iOS 应用程序时选择的文件 将应用程序部署到 Apple App Store 时选择的文件 在使用 Flash Builder 开发 iOS 应用程序之前,必须…
grep之字符串搜索算法Boyer-Moore由浅入深(比KMP快3-5倍)
2019独角兽企业重金招聘Python工程师标准>>> 1. 简单介绍 在用于查找子字符串的算法当中,BM(Boyer-Moore)算法是目前被认为最高效的字符串搜索算法,它由Bob Boyer和J Strother Moore设计于1977年。 一般情况下…

多线程threading
threading用于提供线程相关的操作,线程是应用程序中工作的最小单元。python当前版本的多线程库没有实现优先级、线程组,线程也不能被停止、暂停、恢复、中断。 1. threading模块提供的类: Thread, Lock, Rlock, Condition, [Bounded]Sem…
一个简单的程序来使用WiredTiger 存储引擎
前言 WiredTiger 自 mongodb3.0 集成进来之后为mongodb拉回了大量的口碑,从而在mongodb-3.2 版本直接代替了in-memory存储引擎,作为了mongodb的默认存储引擎。其 通过支持Append-only btree lsm-tree 以及 针对磁盘/内存数据结构上的多核和无锁优化&am…
Java项目:网上商城系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述功能 javaweb 网上商城系统,前台+后台管理,用户注册,登录,上哦展示,分组展示,搜索,收货地址管理&…

Linux 启动详解之init
1.init初探 init是Linux系统操作中不可缺少的程序之一。init进程,它是一个由内核启动的用户级进程,然后由它来启动后面的任务,包括多用户环境,网络等。 内核会在过去曾使用过init的几个地方查找它,它的正确位置&#x…
mysql 相关命令
mysqladmin versionmysqladmin statusmysqlshow -u帐号 -p密码 mysqlshow -u帐号 -p密码 库名mysql -u帐号 -p密码 -e SELECT Host,Db,User From db mysqlmysqldump --quick mysql | gzip > /root/mysql.gzmysqladmin create dbtestgunzip < /root/mysql.gz | mysql…
maven 添加数据库驱动
1.电脑上需要安装 apache maven2.下载oracle的jar包 例如我下载的是ojdbc7-12.jar3.cmd执行命令 mvn install:install-file -DgroupIdcom.oracle -DartifactIdojdbc7 -Dversion12 -Dpackagingjar -Dfiled:\jar\ojdbc7-12.jar-Dfile jar包所存放的位置4.pom文件添加࿱…
Rocksdb 的 BlobDB key-value 分离存储插件
前言 还是回到传统的 LSM-tree 中,我们key-value 写入时以append形态存放到一个data-block中,多个data-blockmetablock 之类的数据组织成一个sst。当我们读数据以及compaction的时候读到key 之后则很方便得读取到对应的value,一次I/O能够将k…