MIT 6.824 Lab2A (raft) -- Leader Election
文章目录
- 实验要求
- Leader Election流程 及详细实现介绍
- 基本角色
- 关键超时变量
- 关键的两个RPC实现
- RequestVote RPC
- AppendEntries RPC
- Go并发编程实现leader election调度
本节记录的是完成MIT6.824 raft lab的leader Election部分实验。
代码: https://github.com/BaronStack/MIT-6.824-lab, clone之后git checkout lab2-2A
实验要求
这里是raft lab2 的2A部分,也是这个lab的一个基础部分。主要完成的raft功能是 leader election 和 heartbeat 心跳。即 集群选举从初始化状态选举出一个leader,且在集群没有异常的情况下这个leader会通过heartbeat心跳一直保持自己的leader状态。
详细的功能可以 通过test_test.go的两个测试看看2A这里主要的功能是什么?
func TestInitialElection2A(t *testing.T) {servers := 3 //初始化三个peercfg := make_config(t, servers, false) // 完成初使选举defer cfg.cleanup()cfg.begin("Test (2A): initial election")// is a leader elected?cfg.checkOneLeader() // 检查leader是否选举出来且只有一个// sleep a bit to avoid racing with followers learning of the// election, then check that all peers agree on the term.time.Sleep(50 * time.Millisecond)// 完成leader选举之后,当前leader任期内的term 大于等于初始化的term// 且后续没有网络异常的情况下这个term不会发生变化term1 := cfg.checkTerms()if term1 < 1 {t.Fatalf("term is %v, but should be at least 1", term1)}// does the leader+term stay the same if there is no network failure?time.Sleep(2 * RaftElectionTimeout)// 过了一段时间,确保term不会发生变化term2 := cfg.checkTerms()if term1 != term2 {fmt.Printf("warning: term changed even though there were no failures")}// there should still be a leader.// 仍然只有一个leadercfg.checkOneLeader()cfg.end()
}
后面的一个测试是针对leader election过程中的其他异常情况进行的,详细代码可以看看test_test.go 的 TestReElection2A函数的测试内容:
- 三个peer选举出一个leader
- 一个peer异常,leader能够正常选出来
- 两个peer异常,leader选举不出来,因为已经超过大多数异常了
- 恢复了一个peer之后有两个peer,能够选举出来一个leader
- 再加入一个peer之后不影响之前正常的leader
整体来看就是一个完整的leader election的实现。
Leader Election流程 及详细实现介绍
基本角色
这里的角色在实际raft相关的应用中是以服务进程的形式存在的。

follower,所有角色开始时的状态,等待接受leader心跳RPCs,如果收不到则会变成CandidateCandidate,候选人。是变成Leader的上一个角色,候选人会向其他所有节点发送RequestVote RPCs,如果收到集群大多数的回复,则会将自己角色变更为Leader,并发送AppendEntries RPCs。Leader,集群的皇帝/主人…,raft能够保证每一个集群仅有一个leader。负责和客户端进行通信,并将客户端请求转发给集群其他成员。
代码中定义了三种常量表示peer不同的state:
const (STATE_FOLLOWER = iota // 0STATE_CANDIDATESTATE_LEADERHBINTERVAL = 50 * time.Millisecond // 50ms 心跳间隔
)
关键超时变量
Election Timeout选举超时时间。即Cadidate 向集群其他节点发送vote请求时,如果在Election Timeout时间内没有收到大多数的回复,则会重新发送vote rpc。以上将实际
RequestVote简写为vote ,就是请求投票的rpc一般这个超时时间是在
150-300ms的随机时间,为了防止集群出现频繁的 split vote 影响leader选举效率的情况,将这个超时时间取在155-300ms范围内的随机时间。当然,这个数值也是经过测试的,超时时间设置在150-300ms 之间能够保证raft集群 leader的稳定性,也可以将超时时间设置的比较低(12-24ms),但是存在的网络延迟则会导致一些不必要的leader选举。随机超时时间的设定实现如下,因为看到有很多完成6.824的伙伴有说这里超市时间是个坑,测试数百上千次可能无法保证每次都能在超市时间内选举出leader,目前还没有遇到:
time.After(time.Duration(rand.Int63() % 333 + 550) * time.Millisecond) //这里设置的是550-880ms之间关于splite vote的情况可以看如下图,图片来自raft可视化官网:
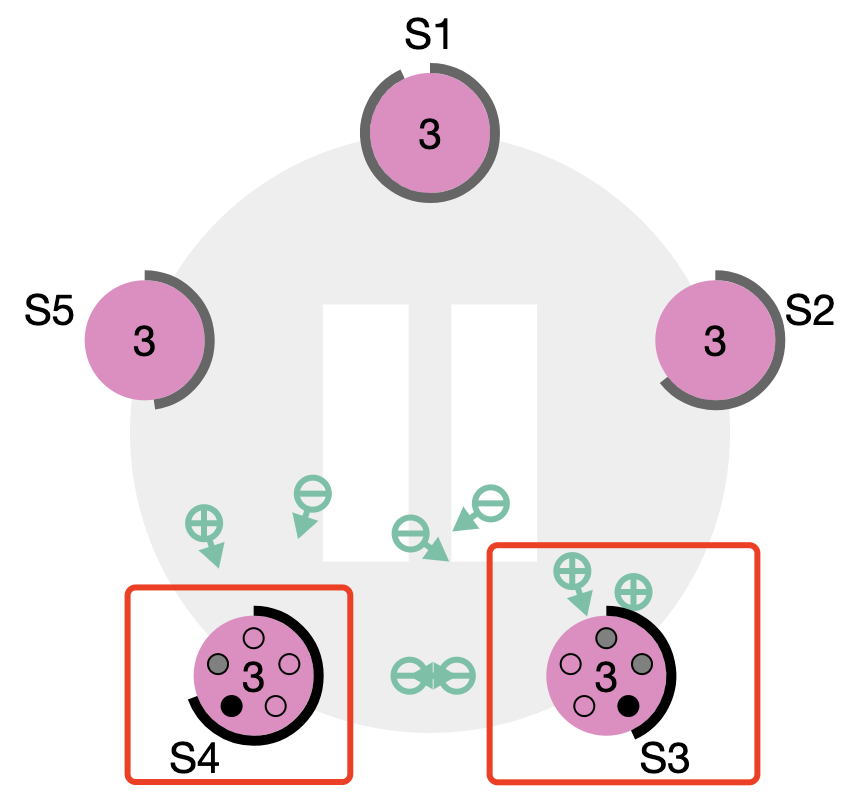
两个节点收到对方的vote请求之前变成了candidate,发送了各自的request vote。Heartbeats Timeout心跳超时时间。follower接受来自leader的心跳,如果在heartbeats timeout这个时间段内follower没有收到来自leader的AppendEntries RPCs,则follower会重新触发选举。收到了,则重置follower 本地的 heartbeats timeout。TermLeader选举过程中除了之前提到的基本变量,还会有一个Term 的概念。
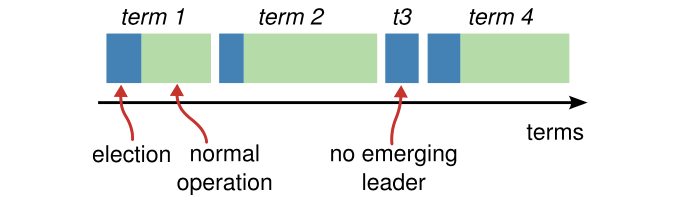 ,
,每一个term的变更不一定表示Leader一定会被选举出来了。
上图中的 term3 则完全没有选出leader,这种情况的出现就是上文中描述的splite vote的情况,这个时候Term也会增加,当时并没有leader 被选出来,在ceph/zookeeper中 其实就类比于Epoch。
关键的两个RPC实现
在讲实际的RequestVoterpc和SendRequestVote实现之前我们先来看看什么是RPC(remote procedure call)远程进程调用。
我们知道raft维护的是一个集群多台机器之间的共识状态,那需要这个集群内的机器之间频繁得进行数据传输。而我们希望实际发送过去得不仅仅是数据流,还有可以执行产生数据流的函数,这样能够高效得完成一些逻辑上的数据处理。比如,raft中我们将RequestVote封装成一个函数,将本地的peer状态作为参数和整个函数一起发送到远端的机器,远端的机器能够根据发送过来的peer状态通过RequestVote内部逻辑来决定自己本地的行为。这个过程如果纯粹得通过网络发送数据包,显然需要大量的数据传输,所以RPC也就应运而生了。
实现RPC的话 不像我们本地服务器进程之间通信或者进程内部的函数调用这么简单方便,因为是跨服务器的,之间的信息交流只能通过网络。我们想要让本地的函数在远端也能够执行,需要实现如下几个机制:
- Call ID映射。保证本地和远端服务器都能够通过这个映射找到唯一的函数指针执行
- 序列化和反序列化。需要将函数参数进行序列化成字节流 通过网络传输到远端,远端服务器再进行反序列化解析得到参数。
- 网络传输。需要通过网络协议将Call ID、序列化和反序列化数据 发送到远端。这里的协议并不会有太多的限制,TCP/UDP/HTTP等都可以。
轻量级得RPC的实现感兴趣的同学可以看看labrpc.go,对于RPC过程中需要处理的网络异常或者流量控制这样的需求 学习gRPC或者bRPC等C++实现也是很经典的。
RequestVote RPC
这个RPC存在的目的是为了选举leader,即集群中有peer变成了candidate状态时就会发送RequestVote rpc。
RequestVote RPCs以上两个超时过程也说了,投票是通过rpc请求实现的,且当有RequestVote 出现时,说明发送的peer本省的state已经是处于Candidate了实际的RPC-args和reply结构体如下:
type RequestVoteArgs struct {// Your data here (2A, 2B).Term int // current candidate's termCandidateId int // candidate's id requesting voteLastLogIndex int // index of current candidate's last log entryLastLogTerm int // term of current candidate's last log entry }// // example RequestVote RPC reply structure. // field names must start with capital letters! // type RequestVoteReply struct {// Your data here (2A).Term int // current term, for candidate to update itselfVoteGranted bool // true means candidate received vote }我们的raft中
RequestVote的实现中,如果想要接收这个rpc的peer为发送的rpc即RequestVoteArgs投票,则需要满足以下几个条件:Receive-peer 的 term > send-peer 的term,则receiver-peer保留自己本身的状态,毕竟Term都比请求投票的peer term新
为了保证一致性,当send-peer的term 满足大于等于receive-peer的term的时候需要比较上一个term是否比receive-peer的上一个term新,如果是相等,还需要确认上一个log index是否更新。这一些都满足之后才能更新receive-peer的状态为follower 以及 投票的id。即receive-peer认可了send-peer是leader。
除了最开始的term的比较之外,后续的last-term以及last-log-index 都是为了保证选举出来的leader能够拥有最更新的日志。
代码实现如下:
func (rf *Raft) RequestVote(args RequestVoteArgs,reply *RequestVoteReply) {// Your code here (2A, 2B).rf.mu.Lock()defer rf.mu.Unlock()reply.VoteGranted = falseif args.Term < rf.currentTerm { // 判断term,rf.currentTerm是receiver-peer的term// send-peer的term没有receiver-peer的term新,直接返回reply.Term = rf.currentTermreturn}// send-peer的term更新,则更新receive-peer的state和本地term// 如果两者相等, 则需要继续后续的last-term和last-index的判断if args.Term > rf.currentTerm { rf.currentTerm = args.Termrf.state = STATE_FOLLOWERrf.voteFor = -1}reply.Term = rf.currentTermlast_term := rf.GetLastTerm()last_index := rf.GetLastIndex()update := false// only the leader have the newer term and log-index than current peer// then we could vote for the peerif args.LastLogTerm > last_term {update = true}if args.LastLogTerm == last_term && args.LastLogIndex >= last_index {update = true}// 都满足send-peer拥有更全的日志,receive-peer才会选择去更新本地相关状态和跟进termif (rf.voteFor == -1 || rf.voteFor == args.CandidateId) && update {rf.chanGrantVote <- truerf.state = STATE_FOLLOWERreply.VoteGranted = truerf.voteFor = args.CandidateId // 投票给send-peer的peer id} }sendAppendEntries的实现 大体是在send-peer端在发送完rpc接收到reply之后的处理逻辑
- 在收到
RequestVote之后,检查发现当前state的状态已经发生变化了,则保持这个状态直接返回(在此期间可能收到了AppendEntries RPC ,则会直接变更为follower) - term 发生了变化,则认为当前peer在收到自己发送的rpc回复之前收到别人的rpc且为别人投了票,也就是状态也发生了变化
- 自己还是保持的发送之前的state和term,只是收到回复的term比自己的term大,那将自己状态变更为follower
- 收到的回复中发现别人投给自己一票,那就准备将自己变更为leader
func (rf *Raft) sendRequestVote(server int, args RequestVoteArgs, reply *RequestVoteReply) bool {ok := rf.peers[server].Call("Raft.RequestVote", args, reply)rf.mu.Lock()defer rf.mu.Unlock()if ok {// find that the current peer's state changed , return okif rf.state != STATE_CANDIDATE {return ok}// keep the current peer's state, our state have been changedterm := rf.currentTermif args.Term != term {return ok}if reply.Term > term {rf.currentTerm = reply.Termrf.state = STATE_FOLLOWERrf.voteFor = -1}// 别人的回复认可了自己,投了自己一票if reply.VoteGranted {rf.voteCount ++// 确认自己的投票总数超过半数,则通过channel 标记自己成为leaderif rf.state == STATE_CANDIDATE && rf.voteCount > len(rf.peers)/2 {rf.state = STATE_FOLLOWERrf.chanLeader <- true}}}return ok
}
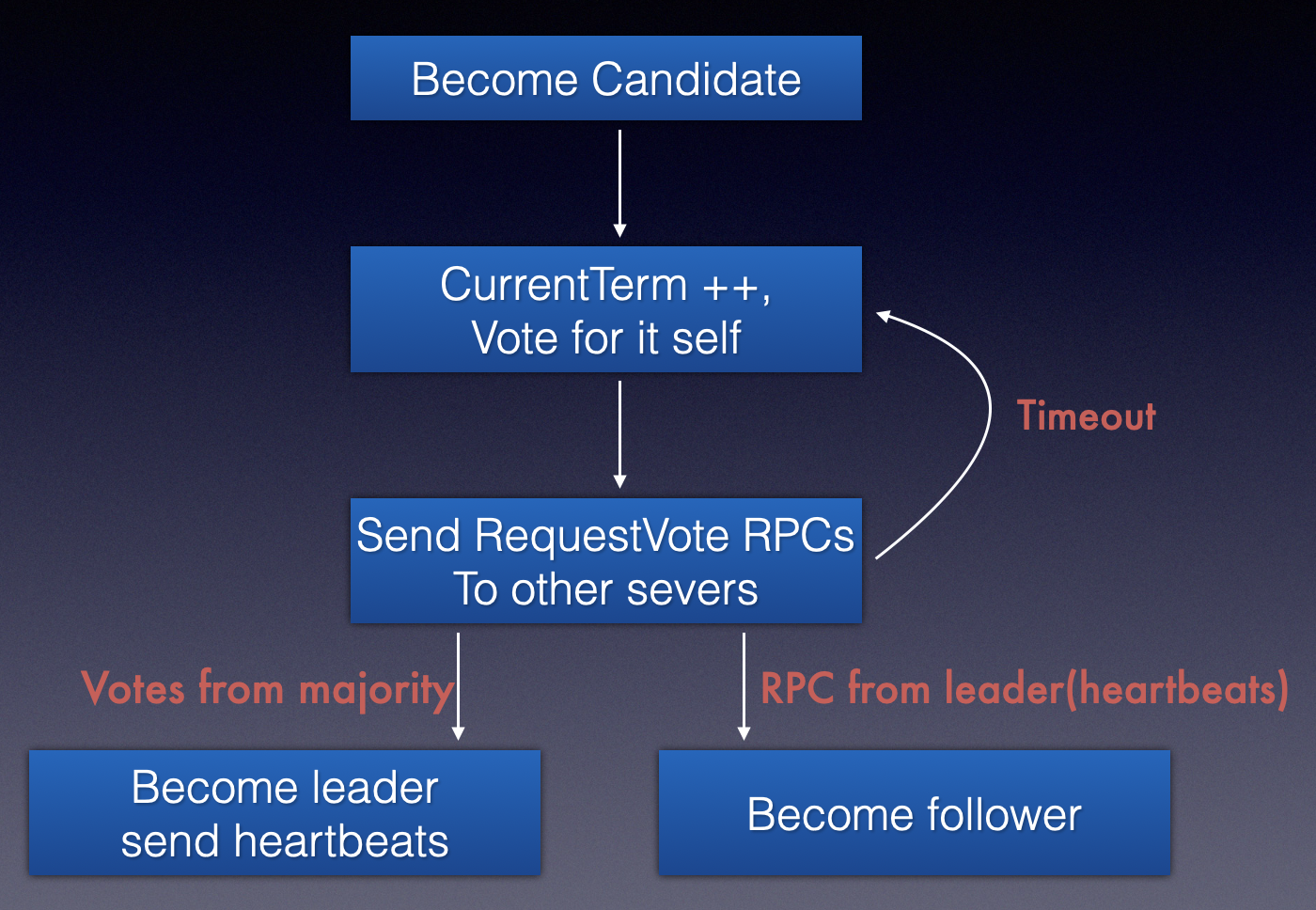
关于Term在candidate 投票过程中发生的变化 如下图。
AppendEntries RPC
这个rpc是leader维护自己状态的,每隔一段时间像其他的follower发送AppendEntries,这段时间的集群term不会发生变化。并且AppendEntries也会携带着log-entry 更新log index。
AppendEntries RPCsleader 同步数据时的rpc请求。其发送和接收回复的结构体形态如下:
// AppendEntries RPC args type AppendEntriesArgs struct {Term int // leader 的termLeaderId int // leader 所在peer的idPrevLogIndex int // leader上一个log indexPrevLogTerm int // leader 上一个log的termEntries []LogEntry // leader 存放的logLeaderCommit int // leader 已经commit的index }// AppendEntries RPC reply type AppendEntriesReply struct {Term int // 当前peer回复给leader的term,leader用来判断是否需要变更自身的状态Success bool // 当前peer是否仍然认可leaderNextIndex int // 下一个log entry的index内容 }AppendEntries 中主要做的事情如下(L表示leader,P表示收到RPC的peer):
- 发现L-term < P-term,这个时候认为集群发生了异常,返回success为false表示当前peer不认可leader的任期了
- 检查L-prevLogIndex和P-LogIndex是否匹配,如过发现L-prevLogIndex更 新,则认为follower的log不全,需要从leader补充,那需要找到和P-LogIndex 匹配的index,将找到的index+1返回给leader。这个过程其实就是leader补全和follower之间的日志差异,需要向前找到leader和follower所处的同一个term的同一个index才能返回。
当然,第二点其实是lab 2B要做的事情,这个无关于leader election。
看一下实现
func (rf *Raft) AppendEntries(args AppendEntriesArgs,reply *AppendEntriesReply) {rf.mu.Lock()defer rf.mu.Unlock()// 发现L-term < P-term,认为集群发生了异常,将当前peer的term返回回去reply.Success = falseif args.Term < rf.currentTerm {reply.Term = rf.currentTermreply.NextIndex = rf.GetLastIndex() + 1return}// 如果是Term正常的,那就直接填充channel,告诉leader当前peer仍然是followerrf.chanHeartbeat <- trueif args.Term > rf.currentTerm {rf.currentTerm = args.Termrf.state = STATE_FOLLOWERrf.voteFor = -1}reply.Term = args.Termif args.PrevLogIndex > rf.GetLastIndex() {reply.NextIndex = rf.GetLastIndex() + 1return}baseIndex := rf.log[0].LogIndex// 对PrevLogIndex的检查,确保follower的entry是和leader的log entry同步的if args.PrevLogIndex > baseIndex {term := rf.log[args.PrevLogIndex-baseIndex].LogTermif args.PrevLogTerm != term {for i := args.PrevLogIndex - 1 ; i >= baseIndex; i-- {if rf.log[i-baseIndex].LogTerm != term {reply.NextIndex = i + 1break}}return}}if args.PrevLogIndex < baseIndex {} else {rf.log = rf.log[: args.PrevLogIndex+1-baseIndex]rf.log = append(rf.log, args.Entries...)reply.Success = truereply.NextIndex = rf.GetLastIndex() + 1}return }sendAppendEntries是leader 发送完AppendEntriesRPC之后的一些处理逻辑func (rf *Raft) sendAppendEntries(server int, args AppendEntriesArgs, reply *AppendEntriesReply) bool {ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)rf.mu.Lock()defer rf.mu.Unlock()if ok {// 发送RPC之后发现当前leader的状态和term发生了变化,直接返回吧// 可能在此期间收到其他peer的rpc拥有更高的term,也会让自身的状态和term发生变化if rf.state != STATE_LEADER {return ok}if args.Term != rf.currentTerm {return ok}// 如果leader自身没有变化,但是发现收到回复的term比自己的term新// 只能认为自己的follower了if reply.Term > rf.currentTerm {rf.currentTerm = reply.Termrf.state = STATE_FOLLOWERrf.voteFor = -1return ok}// 更新logindexif reply.Success {if len(args.Entries) > 0 {rf.nextIndex[server] = args.Entries[len(args.Entries) - 1].LogIndex + 1rf.matchInex[server] = rf.nextIndex[server] - 1}} else {rf.nextIndex[server] = reply.NextIndex}}return ok }
从上面的AppendEntries和RequestVote两种RPC我们大体清楚了在leader Election过程中的节点状态变化的情况。
总体来说就是当Follower长时间没有收到心跳的时候就会变成 Candidate,Candidate通过RequestVote逻辑对一些term新旧的判断或者logIndex新旧的判断进行投票从而选择term最新且log最全的peer作为leader,不认为自己能够当选leader 的peer同时也会将自己的状态变更为follower;leader会不断得向follower发送AppendEntries 来维持自己的leader状态。当集群发生异常(宕机的旧leader重新启动,收到了新Leader的状态信息)则会将自己标记为Follower。
如下图:

Go并发编程实现leader election调度
我们在RPC中已经将大多数的核心实现已经描述清楚了, 接下来就是在外部构造集群需要的多个peer ,每个peer通过接收发送RPC来维护自己的外部状态机的行为,从而更好得在三种状态之间变迁。
根据Lab 2A的要求,会检查集群从最开始没有leader的状态进行选举,完成leader选举;到集群正常运行时模拟节点网络异常进行leader选举。
这里面需要用到GO并发的一些知识 多路选择 + 超时控制 + CSP(communicating sequential processes),能够体会到GO语言在并发编程下的强大。
调度这里我们要做的事情就是:
初始化几个peer
每一个peer维护一个状态机,每一个状态下去调度各自状态的逻辑。
Follower
a. 对candidate和leader的rpc进行回复
b. 如果超市时间内没有收到AppendEntries rpc 或者 收到candidate的投票,会讲自己的状态转为candidateCandidates
投票过程中会做的事情:
a. 增加当前peer的term
b. 为自己投票
c. 重置选举超市时间
d. 发送RequestVote RPC 发送给其他peer如果发送的rpc收到的回复大多数都认可自己,那就变成leader
如果收到了AppendEntries RPC, 那就变成follower,说明有其他人在选举
如果超时时间过期了,那就开启一个新的termLeader
选举过程中的leader主要是发送AppendEntries RPC来维护自己的term
看看具体的实现(仅仅是leader选举的部分,并没有处理持久化的log信息):
这个Make的调用会在测试代码通过make_config --> Start1 --> Make初始化三个peer
func Make(peers []*labrpc.ClientEnd, me int,persister *Persister, applyCh chan ApplyMsg) *Raft {rf := &Raft{}rf.peers = peersrf.persister = persisterrf.me = me// Your initialization code here (2A, 2B, 2C).// 初始化当前peerrf.state = STATE_FOLLOWERrf.voteFor = -1rf.voteCount = 0rf.log = append(rf.log, LogEntry{LogTerm: 0})// 这里维护了几个channel,在后续变更peer状态的时候会从channel中取数据// heartbeat和requestVote 的两个计时器也都是依赖channel来实现的// channel填充的话则是在我们前面实现的RPC之中rf.chanLeader = make(chan bool, 100) // 变更为leaderrf.chanHeartbeat = make(chan bool, 100) // 接收到heartbeat心跳rf.chanGrantVote = make(chan bool, 100) // 投票完成rf.chanApply = applyCh// 启动一个go routine,来维护当前peer的状态机go func() {for {switch rf.state {case STATE_FOLLOWER:select {// 有一段时间接受不到心跳,或者收到Candidate的投票// 则将当前follower状态变更为candidate,准备进行leader electioncase <- rf.chanHeartbeat:case <- rf.chanGrantVote:case <-time.After(time.Duration(rand.Int63() % 333 + 550) * time.Millisecond): // 计时器rf.state = STATE_CANDIDATE} case STATE_LEADER:rf.broadCastAppendEntries() //leader 广播AppendEntries,有log的话会携带着log-indextime.Sleep(HBINTERVAL)case STATE_CANDIDATE:rf.mu.Lock()rf.currentTerm ++ // 增加当前term,表示开启了一个新一轮的leader任期rf.voteFor = rf.me // 每个candidate先为自己投票 rf.voteCount = 1 // 投票计数自增,后续通过这个计数判断是否能够成为leaderrf.mu.Unlock()go rf.broadCastReqeustVote() // candidate 向除自己之外的其他peer广播RequestVoteselect {case <-time.After(time.Duration(rand.Int63() % 333 + 550) * time.Millisecond):case <-rf.chanHeartbeat: // chanHeartbeat为真,收到了AppendEntries,则变更为follower(已经有leader了)rf.state = STATE_FOLLOWERcase <-rf.chanLeader: // 在处理RequestVote返回的逻辑中发现自己能够成为leader,变更为leaderrf.mu.Lock()rf.state = STATE_LEADER// 调整后续要发送的rf.nextIndex = make([]int,len(rf.peers))rf.matchInex = make([]int,len(rf.peers))for i := range rf.peers {rf.nextIndex[i] = rf.GetLastIndex() + 1rf.matchInex[i] = 0}rf.mu.Unlock()}}}}()
}
需要注意的是go的channel机制如果不初始化buffer,则会是阻塞的,一个channel 会一直阻塞在这段超时时间内 直到拿到了值。
ch := make(chan bool, 10) //设置大小为10的buffer,如果不设置buffer大小,则后续取值的时候会阻塞ch <- true // 向ch中填值
ret := <- ch // 从ch取值
所以在raft的go实现中 针对channel变量的设置 都会有 buffer,从而防止其他routine获取channel 值时阻塞。
相关文章:
Java项目:在线考试系统(java+springboot+vue+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 本系统主要实现的功能有: 学生以及老师的注册登录,在线考试,错题查询,学生管理,问题管理,错题管理,错题查询…

写给自己的web开发资源
web开发给我的感觉就是乱七八糟,而且要学习感觉总是会有东西要学习,很乱很杂我也没空搞,(其实学习这个的方法就是去用它,什么你直接用?学过js么学过jquery么?哈哈,我没有系统的看完过…

虚拟机VMWare“提示:软件虚拟化与此平台上的长模式不兼容”的解决方法
虚拟机VMWare“提示:软件虚拟化与此平台上的长模式不兼容”不少童鞋反映,在使用Windows7 64位操作系统时,无法运行VMWare或MS Virtual server等软件虚拟操作系统。提示为“提示:软件虚拟化与此平台上的长模式不兼容. 禁用长模式. …

如何在Vue项目中使用vw实现移动端适配(转)
有关于移动端的适配布局一直以来都是众说纷纭,对应的解决方案也是有很多种。在《使用Flexible实现手淘H5页面的终端适配》提出了Flexible的布局方案,随着viewport单位越来越受到众多浏览器的支持,因此在《再聊移动端页面的适配》一文中提出了…
Jsoncpp 在C++开发中的一些使用记录
jsoncpp 是一个C 语言实现的json库,非常方便得支持C得各种数据类型到json 以及 json到各种数据类型的转化。 一个json 类型的数据如下: {"code" : 10.01,"files" : "","msg" : "","uploadid&q…

Java项目:图书管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括(管理员和学生角色): 管理员和学生登录,图书管理,图书添加删除修改,图书 借阅,图书归还,图书查看,学…

使用 Flash Builder 的 Apple iOS 开发过程
使用 Flash Builder 的 Apple iOS 开发过程 iOS 开发和部署过程概述 构建、调试或部署 iOS 应用程序前的准备工作 在测试、调试或安装 iOS 应用程序时选择的文件 将应用程序部署到 Apple App Store 时选择的文件 在使用 Flash Builder 开发 iOS 应用程序之前,必须…

grep之字符串搜索算法Boyer-Moore由浅入深(比KMP快3-5倍)
2019独角兽企业重金招聘Python工程师标准>>> 1. 简单介绍 在用于查找子字符串的算法当中,BM(Boyer-Moore)算法是目前被认为最高效的字符串搜索算法,它由Bob Boyer和J Strother Moore设计于1977年。 一般情况下…

多线程threading
threading用于提供线程相关的操作,线程是应用程序中工作的最小单元。python当前版本的多线程库没有实现优先级、线程组,线程也不能被停止、暂停、恢复、中断。 1. threading模块提供的类: Thread, Lock, Rlock, Condition, [Bounded]Sem…
一个简单的程序来使用WiredTiger 存储引擎
前言 WiredTiger 自 mongodb3.0 集成进来之后为mongodb拉回了大量的口碑,从而在mongodb-3.2 版本直接代替了in-memory存储引擎,作为了mongodb的默认存储引擎。其 通过支持Append-only btree lsm-tree 以及 针对磁盘/内存数据结构上的多核和无锁优化&am…
Java项目:网上商城系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述功能 javaweb 网上商城系统,前台+后台管理,用户注册,登录,上哦展示,分组展示,搜索,收货地址管理&…

Linux 启动详解之init
1.init初探 init是Linux系统操作中不可缺少的程序之一。init进程,它是一个由内核启动的用户级进程,然后由它来启动后面的任务,包括多用户环境,网络等。 内核会在过去曾使用过init的几个地方查找它,它的正确位置&#x…
mysql 相关命令
mysqladmin versionmysqladmin statusmysqlshow -u帐号 -p密码 mysqlshow -u帐号 -p密码 库名mysql -u帐号 -p密码 -e SELECT Host,Db,User From db mysqlmysqldump --quick mysql | gzip > /root/mysql.gzmysqladmin create dbtestgunzip < /root/mysql.gz | mysql…
maven 添加数据库驱动
1.电脑上需要安装 apache maven2.下载oracle的jar包 例如我下载的是ojdbc7-12.jar3.cmd执行命令 mvn install:install-file -DgroupIdcom.oracle -DartifactIdojdbc7 -Dversion12 -Dpackagingjar -Dfiled:\jar\ojdbc7-12.jar-Dfile jar包所存放的位置4.pom文件添加࿱…
Rocksdb 的 BlobDB key-value 分离存储插件
前言 还是回到传统的 LSM-tree 中,我们key-value 写入时以append形态存放到一个data-block中,多个data-blockmetablock 之类的数据组织成一个sst。当我们读数据以及compaction的时候读到key 之后则很方便得读取到对应的value,一次I/O能够将k…
Java项目:(前端vue后台java微服务)在线考试系统(java+vue+springboot+mysql+maven)
源码获取:博客首页 "资源" 里下载! 考试流程: 用户前台注册成为学生 管理员后台添加老师,系统将该用户角色上升为老师 老师登录,添加考试,添加题目,发布考试 考生登录前台参加考试,…
C++实现stack【栈】
要求: //****file: stack.h/*对stack进行初始化检查stack为空,或已满将整数压入到stack中从stack里弹出整数 不移除任何袁术,讲过stack的内容输出到标准输出Stack类的私有成员如下:一个用于打印错误信息的私有哦成员函数三个私有数…
c#操作Excel整理总结
大家好,这是我在工作中总结的关于C#操作Excel的帮助类,欢迎大家批评指正! using System; using System.Collections.Generic; using System.Data; using System.Data.OleDb; using System.IO; using Aspose.Cells;namespace MusicgrabTool {p…
C++ std::function<void(int)> 和 std::function<void()> 作为函数参数的注意事项
前言 std::function 作为标准库提供的函数指针,使用起来还是比较方便的,不过在使用过程中有一些需要注意的细节,这里做一个简单的记录。 基本使用 头文件: #include <functional>语法:std::function<return_type(args…
Java项目:网上电商系统(java+SSM+mysql+maven+tomcat)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能:本系统分用户前台和管理员后台。 前台展示后台管理,前台界面可实现用户登录,用户注 册,商品展示,商品明细展示,用户…
C# SQLiteHelper
1 public class SQLiteHelpers2 {3 /// <summary> 4 /// ConnectionString样例:DatasourceTest.db3;Poolingtrue;FailIfMissingfalse 5 /// </summary> 6 public static string ConnectionStri…
[Git] 拉开发分支的代码报错
Git拉开发分支的代码报错: fatal: The remote end hung up unexpectedly fatal: early EOF fatal: index-pack failed 解决办法: git config --global core.compression -1 转载于:https://www.cnblogs.com/MasterMonkInTemple/p/10754596.html
C++ 通过模版工厂实现 简单反射机制
前言 我们知道Java/Python这种语言能够很好得 支持反射。反射机制 就是一种用户输入的字符串到对应实现方法的映射,比如http接口中 用户传入了url,我们需要调用该url对应的方法/函数对象 从而做出对应的操作。 而C 并没有友好得支持这样的操作…
计算机世界的“十六进制”为什么如此重要
在计算机世界中,十六进制扮演着不可或缺的角色。它以其紧凑的表示形式、与二进制的天然对应关系以及在各个领域的广泛应用,成为了计算机科学中的一把重要工具。总体而言,计算机需要十六进制并非偶然,它是一种为了更好地满足人类理解和处理数据的需求而产生的工具,为计算机科学的发展和应用提供了便利和支持。

面试官:如何实现10亿数据判重?
以 Java 中的 int 为例,来对比观察 BitMap 的优势,在 Java 中,int 类型通常需要 32 位(4 字节*8),而 BitMap 使用 1 位就可以来标识此元素是否存在,所以可以认为 BitMap 占用的空间大小,只有 int 类型的 1/32,所以有大数据量判重时,使用 BitMap 也可以实现。所以数据库去重显然是不行的。而使用集合也是不合适的,因为数据量太大,使用集合会导致内存不够用或内存溢出和 Full GC 频繁等问题,所以此时我们的解决方案通常是采用布隆过滤器来实现判重。
Java项目:校园二手市场系统(java+SSM+mysql+maven+tomcat)
源码获取:博客首页 "资源" 里下载! 一、项目简述( IW文档) 功能:本系统分用户前台和管理员后台。 本系统用例模型有三种,分别是游客、注册用户和系统管 理员。下面分别对这三个角色的功能进行描…
php中$_REQUEST、$_POST、$_GET的区别和联系小结
php中$_REQUEST、$_POST、$_GET的区别和联系小结 作者: 字体:[增加 减小] 类型:转载php中有$_request与$_post、$_get用于接受表单数据,当时他们有何种区别,什么时候用那种最好。1. $_REQUEST php中$_REQUEST可以获取以…
uva 315 (poj 1144 求割点)
题意:给你一张无向图,求割点的个数。 思路:输入稍微处理一下接着直接套模版。 1 #include <iostream>2 #include <cstdio>3 #include <cstring>4 #include <cstdlib>5 #include <cmath>6 #include <algorit…
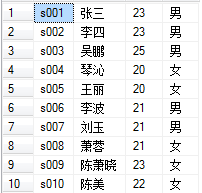
SQL学习之计算字段的用法与解析
一、计算字段 1、存储在数据库表中的数据一般不是应用程序所需要的格式。大多数情况下,数据表中的数据都需要进行二次处理。下面举几个例子。 (1)、我们需要一个字段同时显示公司名和公司地址,但这两个信息存储在不同表的列中。 (2)、省份、城市、邮政编码存储在不同…
手把手教你 用C++实现一个 可持久化 的http_server
前言 本文介绍一个有趣的 通过C实现的 持久化的http_server demo,这样我们通过http通信之后的数据可以持久化存储,即使server挂了,数据也不会丢失。我们的http_sever 也就能够真正得作为一个后端server了。 本身持久化这个能力是数据库提供…