Rocksdb 通过ingestfile 来支持高效的离线数据导入
文章目录
- 前言
- 使用方式
- 实现原理
- 总结
前言
很多时候,我们使用数据库时会有离线向数据库导入数据的需求。比如大量用户在本地的一些离线数据,想要将这一些数据导入到已有的数据库中;或者说NewSQL场景中部分机器离线,重新上线之后的数据增量/全量同步 等场景。这个时候 我们并不想要让这一些数据占用过多的系统资源,更不希望他们对正常的线上业务有影响,所以尽可能高效得完成这一些数据的同步就需要深入设计一番。
而如果底层引擎使用的是rocksdb,那就非常省事了,只需要组织好你们的数据调用接口就完事了,剩下的导入过程由引擎完成。 tikv便是通过 rocksdb的这个功能完成集群异常恢复之后 region之间的全量增量同步的。回到今天我们要讨论的主题,便是rocksdb的这个数据导入过程是如何尽可能快、尽可能高效得完成的。
使用方式
讲解实现原理之前我们先看看如何使用这个功能,功能的易用性也很重要,用户还是希望尽可能得少写代码来完成这个工作。使用上主要是两部分:创建SST文件 和 导入SST文件。
创建sst文件:这一步主要是通过一个sst_filter_writer,将需要导入的 k/v 数据转换成sst文件
需要注意的是:
- 用户k/v 数据需要按照options.comparator 严格有序,默认是按照key的字典序
- 这里的options 建议和db写入的options用一套(压缩选项,sst文件相关选项等)
Options options;SstFileWriter sst_file_writer(EnvOptions(), options); // 指定形成的sst文件的路径 std::string file_path = "/home/usr/file1.sst";// open file_path Status s = sst_file_writer.Open(file_path); for (...) {// 写入sst,用户保证k/v 的顺序s = sst_file_writer.Put(key, value);if (!s.ok()) {printf("Error while adding Key: %s, Error: %s\n", key.c_str(),s.ToString().c_str());return 1;} }// 完成写入 s = sst_file_writer.Finish();导入sst文件:这个步骤就是将创建好的一个或者多个sst文件导入到db中,也允许向多个cf中导入
IngestExternalFileOptions ifo;
// Ingest the 2 passed SST files into the DB
// 导入数据
Status s = db_->IngestExternalFile({"/home/usr/file1.sst", "/home/usr/file2.sst"}, ifo);
使用还是比较简单的,整体的使用过程如下:
#include <iostream>
#include <vector>#include <gflags/gflags.h>#include <rocksdb/db.h>
#include <rocksdb/env.h>
#include <rocksdb/sst_file_writer.h>#define DATA_SIZE 10
#define VALUE_SIZE 1024using namespace std;// 比较函数
bool cmp(pair<string, string> str1,pair<string, string> str2) {if(str1.first < str2.first) {return true;} else if (str1.first == str2.first && str1.second < str2.second) {return true;} else {return false;}
}// 随机字符串
static string rand_data(long data_range) {char buff[30];unsigned long long num = 1;for (int i = 0;i < 4; ++i) {num *= (unsigned long long )rand();}sprintf(buff, "%llu", num % (unsigned long long)data_range );string data(buff);return data;
}// 构造有序数据
void construct_data(vector<pair<string,string>> &input) {int i;string key;string value;for (i = 0;i < DATA_SIZE; i++) {if(key == "0") {continue;}key = rand_data(VALUE_SIZE);value = rand_data(VALUE_SIZE);input.push_back(make_pair(key, value));}
}void traverse_data(vector<pair<string,string>> input) {int i;for(auto data : input) {cout << data.first << " " << data.second << endl;}
}// 创建sst文件
int create_sst(string file_path) {vector<pair<string,string>> input;vector<pair<string,string>>::iterator input_itr;rocksdb::Options option;/* open statistics and disable compression */option.create_if_missing = true;option.compression = rocksdb::CompressionType::kNoCompression;rocksdb::SstFileWriter sst_file_writer(rocksdb::EnvOptions(), option);rocksdb::Status s = sst_file_writer.Open(file_path);if (!s.ok()) {printf("Error while opening file %s, Error: %s\n", file_path.c_str(),s.ToString().c_str());return 1;}// 需要保证数据有序后再写入construct_data(input);sort(input.begin(), input.end(), cmp);traverse_data(input);// Insert rows into the SST file, note that inserted keys must be // strictly increasing (based on options.comparator)for (input_itr = input.begin(); input_itr != input.end();input_itr ++) {rocksdb::Slice key(input_itr->first);rocksdb::Slice value(input_itr->second);s = sst_file_writer.Put(key, value);if (!s.ok()) {printf("Error while adding Key: %s, Error: %s\n",key.ToString().c_str(),s.ToString().c_str());return 1;}}// Close the files = sst_file_writer.Finish();if (!s.ok()) {printf("Error while finishing file %s, Error: %s\n", file_path.c_str(),s.ToString().c_str());return 1;}return 0;
}static rocksdb::DB *db;void create_db() {rocksdb::Options option;/* open statistics and disable compression */option.create_if_missing = true;option.compression = rocksdb::CompressionType::kNoCompression;rocksdb::Status s = rocksdb::DB::Open( option,"./db", &db);if (!s.ok()) {printf("Open db failed : %s\n", s.ToString().c_str());return;}
}void db_write(int num_keys) {rocksdb::WriteOptions write_option;write_option.sync = true;rocksdb::Slice key;rocksdb::Slice value;rocksdb::Status s;int i;printf("begin write \n");for (i = 0;i < num_keys; i++) {key = rand_data(VALUE_SIZE);value = rand_data(VALUE_SIZE);s = db->Put(write_option, key, value);if (!s.ok()) {printf("Put db failed : %s\n", s.ToString().c_str());return;}}db->Flush(rocksdb::FlushOptions());printf("finish write \n");
}int main() {// 先写入一批数据create_db();db_write(100000);// 创建sst文件if (create_sst("./test.sst") == 0) {printf("creates sst success !\n");} else {printf("creates sst failed !\n");}// 导入数据rocksdb::IngestExternalFileOptions ifo;// Ingest the 2 passed SST files into the DBprintf("Ingest sst !\n");rocksdb::Status s = db->IngestExternalFile({"test.sst"}, ifo);if (!s.ok()) {printf("Error while adding file test.sst , Error %s\n",s.ToString().c_str());return 1;}return 0;
}
运行输出如下:
begin write
finish write
# consturct data,需按照字典序,如果没有按照字典序构造的话会报错
1008 232
240 880
288 63
410 768
506 56
534 256
640 180
72 248
800 672
944 217
creates sst success !
通过db日志可以看到我们创建的sst文件test.sst被成功导入到db,形成了./db/000020.sst,且在db目录中。
╰─$ cat db/LOG |grep ingested
[AddFile] External SST file test.sst was ingested in L0 with path ./db/000020.sst (global_seqno=200012)╰─$ ls db
000017.log 000020.sst IDENTITY LOG LOG.old.1618643738564935 OPTIONS-000008
000019.sst CURRENT LOCK LOG.old.1618123487361092 MANIFEST-000013 OPTIONS-000016
实现原理
从如何使用这个功能上我们能够感觉到这一些数据并不是通过rocksdb正常的I/O流程写入的。如果使用正常的接口,那我们用户不需要排序,而是直接通过db->Put接口将k/v写入,凡事都有但是,但是这样来导入离线数据在rocksdb内部后续的flush/compaction 都会消耗大量的系统资源,而这并不是我们想要的高效。所以,rocksdb提供的ingest接口肯定不会让这一些要导入的数据消耗过多的资源,接下来我们一起看看底层的详细实现。
为了更形象得告诉大家在rocksdb作为存储引擎的场景,如果通过传统的put接口导入数据会多出哪一些I/O,如下图
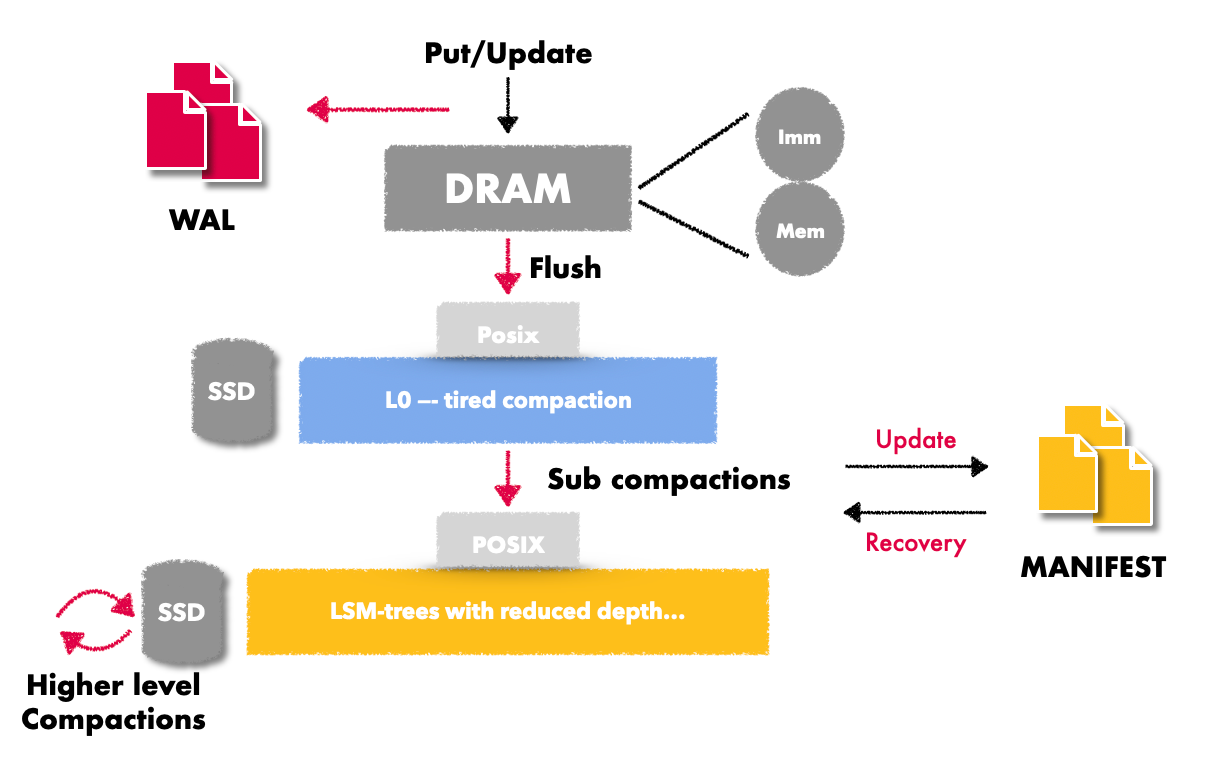
其中红色的尖头 是ingest file 相比于传统的put接口 少的I/O部分,可以说ingest方式导入数据极大得节约了整个系统资源的开销(包括但不限于I/O , CPU 资源的开销)。
下面主要介绍的是有了sst文件,接下来如何导入到db中的过程。关于通过sst_file_writer创建具体的sst文件的过程就不多说了,也就是按照sst文件的格式(datablock,index block…footer)等将有序的数据一个个添加进去而已。
主要有如下几步:
- 为待插入的sst文件创建file link到db目录,或者直接拷贝进去
- 停止写入,需要保证即将导入的sst文件在db中拥有一个安全合理的seqno,如果持续写入,那这个seqno可能不会全局递增了。
- 检查导入的sst文件是否和memtable中的key-range有重叠,有的话需要flush memtable
- 为这个sst文件 按照其key-range挑选一个合适的level放进去
- 为这个问天添加一个全局的seqno
- 恢复db的写入
其中停止写入到恢复写入这段时间对于用户来说越小越好,所以ingest的性能很重要。
接下来看看详细的源代码实现:
导入数据的函数入口是DBImpl::IngestExternalFiles
导入的sst文件最后都需要形成一个db内部的sst文件,因为这个时候已经停止写入了,所以会从最新的sst文件编号之后取一个文件编号,后续的其他要导入的sst文件会不断追加。
Status DBImpl::IngestExternalFiles(const std::vector<IngestExternalFileArg>& args) {...// 构造文件编号到next_file_number中Status status = ReserveFileNumbersBeforeIngestion(static_cast<ColumnFamilyHandleImpl*>(args[0].column_family)->cfd(), total,pending_output_elem, &next_file_number);if (!status.ok()) {InstrumentedMutexLock l(&mutex_);ReleaseFileNumberFromPendingOutputs(pending_output_elem);return status;}...
}
有了在db内部的合法文件编号,我们就可以进行文件迁移了,将待导入的sst文件迁移到db内部已经构造好的sst文件编号之中。
会为每一个cf构造一个ingest_job, 将待导入文件拷贝/移动到 db内部的sst文件中,这个过程是在接下来的Prepare函数中。
uint64_t start_file_number = next_file_number;for (size_t i = 1; i != num_cfs; ++i) {start_file_number += args[i - 1].external_files.size();auto* cfd =static_cast<ColumnFamilyHandleImpl*>(args[i].column_family)->cfd();SuperVersion* super_version = cfd->GetReferencedSuperVersion(this);// prepare 函数exec_results[i].second = ingestion_jobs[i].Prepare(args[i].external_files, start_file_number, super_version);exec_results[i].first = true;CleanupSuperVersion(super_version);}
看看Prepare的函数实现:
- 拿着输入的多个sst文件,如果有多个,则需要检查这一些文件之间是否有重叠key,有的话就不支持了(rocksdb除了l0,其他层不允许有重叠key)。
- 根据用户指定的ingest option: move_files 是否为true,来将待导入文件move到db中, 如果move失败了就拷贝文件。
Status ExternalSstFileIngestionJob::Prepare(const std::vector<std::string>& external_files_paths,uint64_t next_file_number, SuperVersion* sv) {// 解析文件信息for (const std::string& file_path : external_files_paths) {IngestedFileInfo file_to_ingest;status = GetIngestedFileInfo(file_path, &file_to_ingest, sv);if (!status.ok()) {return status;}files_to_ingest_.push_back(file_to_ingest);}// 确保导入的多个sst文件之间没有重叠......} else if (num_files > 1) {// Verify that passed files dont have overlapping rangesautovector<const IngestedFileInfo*> sorted_files;for (size_t i = 0; i < num_files; i++) {sorted_files.push_back(&files_to_ingest_[i]);}std::sort(sorted_files.begin(), sorted_files.end(),[&ucmp](const IngestedFileInfo* info1, const IngestedFileInfo* info2) {return sstableKeyCompare(ucmp, info1->smallest_internal_key,info2->smallest_internal_key) < 0;});// 如果有重叠的话,ingest也无法支持,因为在db中大于level0的更高层level内部的// sst文件之间是不允许有重叠的,加速更高层的二分查找。for (size_t i = 0; i < num_files - 1; i++) {if (sstableKeyCompare(ucmp, sorted_files[i]->largest_internal_key,sorted_files[i + 1]->smallest_internal_key) >= 0) {files_overlap_ = true;break;}}}......// 根据用户参数move文件if (ingestion_options_.move_files) {status = env_->LinkFile(path_outside_db, path_inside_db);...} else { // 否则就拷贝文件f.copy_file = true;}if (f.copy_file) {TEST_SYNC_POINT_CALLBACK("ExternalSstFileIngestionJob::Prepare:CopyFile",nullptr);// CopyFile also sync the new file.status = CopyFile(env_, path_outside_db, path_inside_db, 0,db_options_.use_fsync);}...
}
到此,文件就已经进入到了rocksdb 之中,ingest_job的prepare流程就结束了。
接下来 就到了我们前面介绍总步骤的第二步,停止用户对当前db的写入:
DBImpl::IngestExternalFilesWriteThread::EnterUnbatched
其中WriteThread::EnterUnbatched函数会让当前db的写入线程都处于wait状态。
接下来就是检查当前要导入的文件是否和memtable中的key-range有重叠,函数调用如下:
DBImpl::IngestExternalFilesExternalSstFileIngestionJob::NeedsFlushColumnFamilyData::RangesOverlapWithMemtables
这个函数ColumnFamilyData::RangesOverlapWithMemtables会拿着从ingest files中构造好的key-range和memtable中的 key-range 进行对比,如果有重叠key,则会将memtable flush置为true
Status ColumnFamilyData::RangesOverlapWithMemtables(const autovector<Range>& ranges, SuperVersion* super_version,bool* overlap) {...Status status;// 拿着ingest files的range中的每一个key,看是否能够从memtable中找到for (size_t i = 0; i < ranges.size() && status.ok() && !*overlap; ++i) {auto* vstorage = super_version->current->storage_info();auto* ucmp = vstorage->InternalComparator()->user_comparator();InternalKey range_start(ranges[i].start, kMaxSequenceNumber,kValueTypeForSeek);// 从memtable中找memtable_iter->Seek(range_start.Encode());status = memtable_iter->status();ParsedInternalKey seek_result;if (status.ok()) {if (memtable_iter->Valid() &&!ParseInternalKey(memtable_iter->key(), &seek_result)) {status = Status::Corruption("DB have corrupted keys");}}// 找到了,则置overlap为trueif (status.ok()) {if (memtable_iter->Valid() &&ucmp->Compare(seek_result.user_key, ranges[i].limit) <= 0) {*overlap = true;} else if (range_del_agg.IsRangeOverlapped(ranges[i].start,ranges[i].limit)) {*overlap = true;}}}...
}
在后续的DBImpl::FlushMemTable函数中会flush memtable,不同的cf是分开进行的
DBImpl::IngestExternalFilesDBImpl::FlushMemTable
接下来就开始了第四步和第五步的处理逻辑,需要为每一个落到db中的sst文件挑选合适的level以及分配全局seqno,处理逻辑在Run函数中:
DBImpl::IngestExternalFilesExternalSstFileIngestionJob::Run
主要处理逻辑如下:
一个一个ingest file进行处理
选择一个合适的level,将ingest file插入进去
如果user配置了allow_ingest_behind=true,即允许导入的数据直接插入到最后一层的文件位置,且ingest的时候配置的ingest option中ingest_behind=true,则会先尝试插入到bottomest level,如果最后一层的文件和待插入的文件有重叠,则插入失败。处理逻辑在CheckLevelForIngestedBehindFile函数之中。否则逐层遍历,找到第一个和这一些key-range有重叠的level即可。函数
AssignLevelAndSeqnoForIngestedFile找到了合适的level的同时会记录一个
assigned_seqno,是在当前last_sequence的基础上+1得到的。函数AssignLevelAndSeqnoForIngestedFile之中。为当前ingest_file 写入一个global seq no, 并执行fsync/sync。函数
AssignGlobalSeqnoForIngestedFile之中。最后就是将当完成更新的ingest file的元信息更新到
VersionEdit之中。
接下来就进入尾声了:
- 将更新的
VersionEdit写入到MANIFEST文件之中 - 更新每个ingest file对应的cf信息,并且调度compaction/flush, 因为之前ingest file时找的是有重叠key的一层。
- 恢复db的写入
// 将`VersionEdit`写入到MANIFEST文件之中status =versions_->LogAndApply(cfds_to_commit, mutable_cf_options_list,edit_lists, &mutex_, directories_.GetDbDir());}if (status.ok()) {for (size_t i = 0; i != num_cfs; ++i) {auto* cfd =static_cast<ColumnFamilyHandleImpl*>(args[i].column_family)->cfd();if (!cfd->IsDropped()) {//更新每个ingest file对应的cf信息,并且调度compaction/flush, 因为之前ingest file时找的是有重叠key的一层InstallSuperVersionAndScheduleWork(cfd, &sv_ctxs[i],*cfd->GetLatestMutableCFOptions());...}}}// 恢复db的写入,唤醒db的其他所有的writerwrite_thread_.ExitUnbatched(&w);
到此,整个ingest就算是结束了。
总结
通过ingest的实现,我们能够看到rocksdb通过ingest的方式支持离线数据导入确实能够极大得降低系统资源的开销。不需要一个key在LSM中被反复的写入、读取。
相关文章:
Java项目:企业人事管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能介绍:员工管理,用户管理,部门管理,文档管理, 职位管理等等。 二、项目运行 环境配置: Jdk1.8 Tomcat8.5 mysql Eclispe (I…

XCODE 6.1.1 配置GLFW
最近在学习opengl的相关知识。第一件事就是配环境(好烦躁)。了解了一下os x下的OpenGL开源库,主要有几个:GLUT,freeglut,GLFW等。关于其详细的介绍可以参考opengl网站(https://www.opengl.org/wiki/Related_toolkits_and_APIs)。由…
SpringCloud远程调用为啥要采用HTTP,而不是RPC?
通俗的说法就是:比如说现在有两台服务器A和B,一个应用部署在A服务器上,另一个应用部署在B服务器上,如果A应用想要调用B应用提供的方法,由于他们不在一台机器下,也就是说它们不在一个JVM内存空间中,是无法直接调用的,需要通过网络进行调用,那这个调用过程就叫做RPC。建立Socket连接至少需要一对套接字,其中一个运行于客户端,称为ClientSocket ,另一个运行于服务器端,称为ServerSocket ,套接字之间的连接过程分为三个步骤:服务器监听,客户端请求,连接确认。

vs快捷键及常用设置(vs2012版)
vs快捷键: 1、ctrlf F是Find的简写,意为查找。在vs工具中按此快捷键,可以查看相关的关键词。比如查找哪些页面引用了某个类等。再配合查找范围(整个解决方案、当前项目、当前文档等),可以快速的找到问题所在…

python_day10
小甲鱼python学习笔记 爬虫之正则表达式 1.入门(要import re) 正则表达式中查找示例: >>> import re >>> re.search(rFishC,I love FishC.com) <re.Match object; span(7, 12), matchFishC> >>> #单纯的这种…
Graphics2D API:Canvas操作
在中已经介绍了Canvas基本的绘图方法,本篇介绍一些基本的画布操作.注意:1、画布操作针对的是画布,而不是画布上的图形2、画布变换、裁剪影响后续图形的绘制,对之前已经绘制过的内容没有影响。
关于Titandb Ratelimiter 失效问题的一个bugfix
本文简单讨论一下在TitanDB 中使用Ratelimiter的一个bug,也算是一个重要bug了,相关fix已经提了PR到tikv 社区了pull-210。 这个问题导致的现象是ratelimiter 在titandb Flush/GC 生成blobfiled的过程中无法生效,也就是无法限制titandb的主要…
Java项目:前台预定+后台管理酒店管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能介绍: 前台用户端:用户注册登录,房间展示,房间分类,房间 按价格区间查询,房间评论,房间预订等等 后台管…

Solr初始化源码分析-Solr初始化与启动
用solr做项目已经有一年有余,但都是使用层面,只是利用solr现有机制,修改参数,然后监控调优,从没有对solr进行源码级别的研究。但是,最近手头的一个项目,让我感觉必须把solrn内部原理和扩展机制弄…
iOS :UIPickerView reloadAllComponets not work
编辑信息页面用了很多选择栏,大部分都用 UIPickerView 来实现。在切换数据显示的时候, UIPickerView 不更新数据,不得其解。Google 无解,原因在于无法描述自己的问题,想想应该还是代码哪里写错了。 写了个测试方法&…
单相计量芯片RN8209D使用经验分享(转)
单相计量芯片RN8209D使用经验分享转载于:https://www.cnblogs.com/LittleTiger/p/10736060.html
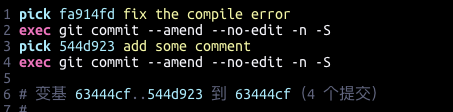
git 对之前的commit 进行重新签名 Resign
在向开源社区提交PR的时候如果之前的提交忘记添加sign (个人签名/公司签名),则社区的DCO检查会失败。 关于通过DCO检查能够确保以下几件事情生效: 你所提交的贡献是由你自己完成或者 你参与了其中,并且有权利按照开源…

【原创】linux命令bc使用详解
最近经常要在linux下做一些进制转换,看到了可以使用bc命令,如下: echo "obase10;ibase16;CFFF" | bc 用完以后就对bc进行了进一步的了解, man bc里面有详细的使用说明。 1.是什么,怎么用 bc - An arbitrary precision calculator language 一…
Java项目:学生信息管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 用户的登录注册,学生信息管理,教师信息管理,班级信 息管理,采用mvcx项目架构,覆盖增删改查,包括学…
MVC學習網站
http://www.cnblogs.com/haogj/archive/2011/11/23/2246032.html
数据导出Excel表格
public String exportInfoFr(String path,String name,String startdate,String enddate,SysUser user){List<Map<String, Object>> list this.esEntPermitErrDao.findListObjectBySql("select 字段值1,字段值2,字段值3,字段值4,字段值5 from 表名 where 字段…
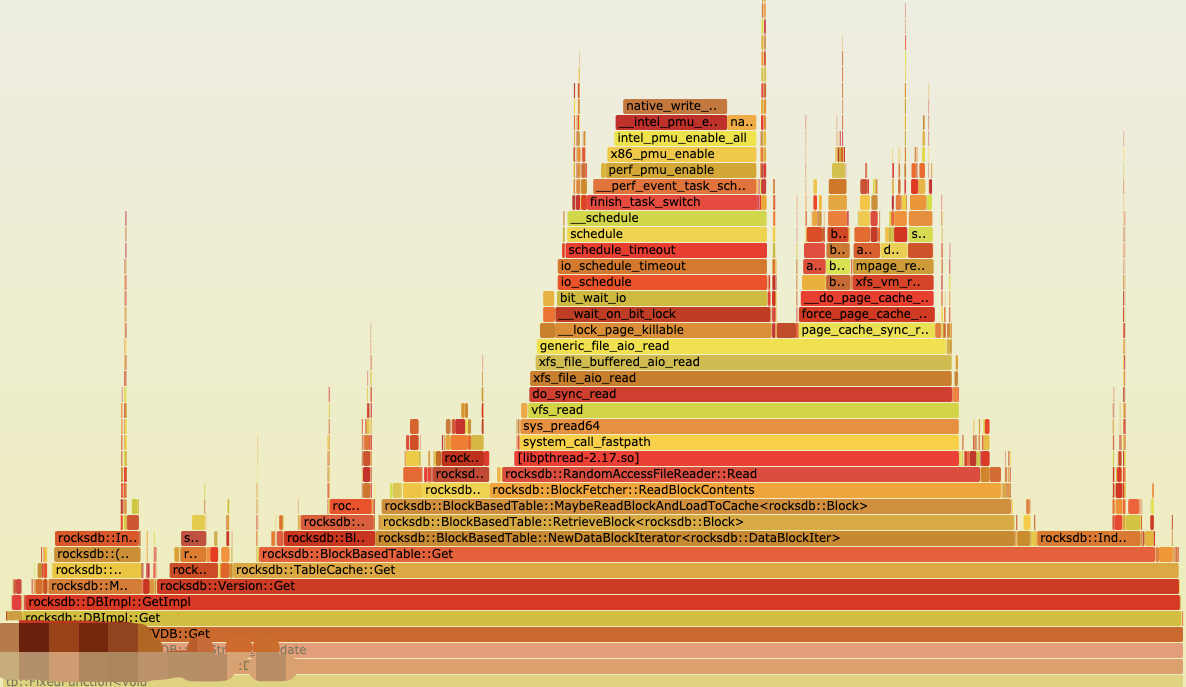
Rocksdb 通过posix_advise 让内核减少在page_cache的预读
文章目录1. 问题排查确认I/O完全/大多数来自于rocksdb确认此时系统只使用了rocksdb的Get来读确认每次系统调用下发读的请求大小确认是否在内核发生了预读2. 问题原因内核预读机制page_cache_sync_readaheadondemand_readahead3. 优化事情起源于 组内的分布式kv 系统使用rocksdb…
[leetcode] Minimum Path Sum
Minimum Path Sum Given a m x n grid filled with non-negative numbers, find a path from top left to bottom right which minimizes the sum of all numbers along its path. Note: You can only move either down or right at any point in time.分析:动态规划…
Java项目:在线小说阅读系统(读者+作者+管理员)(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 1:用户及主要操作功能 游客可以浏览网站的主页,登陆注册,小说湿度,下单购 买,订单查询,个人信息查询…
游戏中的脚本语言
本文最初发表于《游戏创造》(http://www.chinagcn.com)2007年8月刊。版权所有,侵权必究。如蒙转载,必须保留本声明,和作者署名;不得用于商业用途,必须保证全文完整。网络版首次发表于恋花蝶的博客(http://blog.csdn.ne…

mvn项目中的pom文件提示Error parsing lifecycle processing instructions解决
清空.m2/repository下的所有依赖文件,重新下载即可解决该问题。 如果本地用户下没有.m2/repository 目录,找到如下mvn 指定的repository,进去之后清空所有文件。 转载于:https://www.cnblogs.com/Hackerman/p/10736498.html
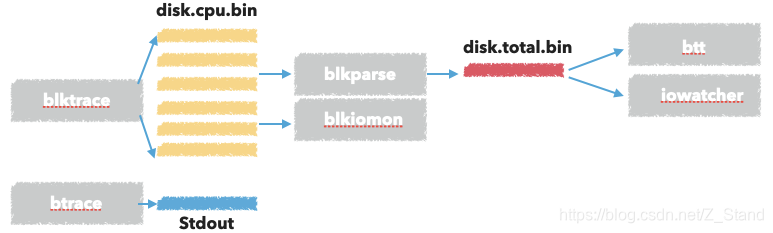
blktrace 工具集使用 及其实现原理
文章目录工具使用原理分析内核I/O栈blktrace 代码做的事情内核调用 ioctl 做的事情BLKTRACESETUPBLKTRACESTOPBLKTRACETEARDOWN内核 调用blk_register_tracepoints 之后做的事情参考最近使用blktrace 工具集来分析I/O 在磁盘上的一些瓶颈问题,特此做一个简单的记录。…

Java项目:教材管理系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能包括: 管理员可以增删改查教材、教材商、入库教材、用户(用 户包括学生和教师)可以对教材商、教材进行。xcel的导入 导出操作。教U阿以领取入库的教材,可以退还教材…
mysql更改数据文件目录及my.ini位置| MySQL命令详解
需求:更改mysql数据数据文件目录及my.ini位置。 步骤: 1、查找my.ini位置,可通过windows服务所对应mysql启动项,查看其对应属性->可执行文件路径,获取my.ini路径。 "D:\MySQL\MySQL Server 5.5\bin\mysqld&quo…

私有云管理-Windows Azure Pack
今天是2014年的第一天,今年的第一篇博客关于私有云,而我在2014年的主要目标也是针对私有云。随着Windows Azure在中国的落地,大家逐渐的熟悉了在Windows Azure中的云体验。而微软针对私有云、混合云推出了一个管理自助门户,Window…
面向对象(类的概念,属性,方法,属性的声明,面向对象编程思维
1 面向对象 1.1 你是如何认识新事物的? 从过往的事物中总结事物的特点(特征),并比对新事物,把新事物进行归类。 1.2 类(Class)的概念(A) 类是对一组具有相同特征和行为的对象的抽象描述。 理解: [1] 类包含了两个要素:特性和行为 > 同一类…
cannot find main module 解决办法
做6.824 实验的过程中想要跑测试,发现go test -run 2A时 出现cannot find main module问题,测试跑不起来。 原因 这个原因是从GO1.11 版本开始引入了go.mod文件来对项目中的go源码的编译相关的内容进行管理,经常使用GO的同学可能深受go get…
Java项目:网上选课系统(java+SSM+jsp+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能: 系统分为三个角色。最高权限管理员,学生,教师,包括 学生管理,教师管理,课程管理,选课,退课…

C#中类的继承 override virtual new的作用以及代码分析
继承中override virtual new的作用 virtual 父类中需要注明允许重写的方法; override 子类中必须显示声明该方法是重写的父类中的方法; new 子类中忽略父类的已存在的方法,“重写该方法“; C#中不支…

spring手动代码控制事务
为什么80%的码农都做不了架构师?>>> DataSourceTransactionManager tran new DataSourceTransactionManager(vjdbcTemplate.getDataSource());DefaultTransactionDefinition def new DefaultTransactionDefinition();//事务定义类def.setPropagationB…