关于 线程模型中经常使用的 __sync_fetch_and_add 原子操作的性能
最近从 kvell 这篇论文中看到一些单机存储引擎的优秀设计,底层存储硬件性能在不远的未来可能不再是主要的性能瓶颈,反而高并发下的CPU可能是软件性能的主要限制。像BPS/AEP/Optane-SSD 等Intel 推出的硬件存储栈已经能够在延时上接近DRAM的量级,吞吐在较低的队列深度下更是能够超越当前主流NVMe-ssd 数倍甚至一个量级;同时结合 SPDK/io_uring/ZNS 等新型底层软件栈,更是能够在操作系统层级完全发挥硬件性能。
这个时候,我们的软件设计模型需要适配硬件的发展。这里KVell 提出的单机引擎软件栈就是 shard-nothing。 即引擎层调度I/O的时候是单线程的,每个调度线程绑定一个 CPU-core 来完整调度整个IO的处理,这个调度方式的优劣会在后面介绍KVell 的时候详细描述(NUMA架构下对cpu的访存非常友好)。总之,多线程独立处理请求的模型 也是 ceph 最新的 crimson osd 正在进行重构的主体架构。
本文主要讨论的是在 KVell 的实现中看到 一个线程间同步数据的调度函数的使用__sync_fetch_and_add,它是GCC 提供的针对一个变量的原子操作。
有点好奇为什么KVell 会使用这个函数原子操作这个变量,按照我们的编程习惯,我们为了防止多线程对同一个变量的修改不是原子的,可能会考虑使用排他锁或者内核的 atomic_* 系列操作,但是它这里使用了这个函数,那这个选择肯定是有原因的(当然可能C语言没有atomic 库,所以没法直接用)。
所以就简单做了一个性能测试:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <mutex>
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
#include <sys/time.h>int g_iFlagAtom = 1;
#define WORK_SIZE 5000000
#define WORKER_COUNT 10
std::vector<std::thread> g_tWorkerID;
std::mutex mu;
#ifdef ATOMIC
std::atomic<int> g_iSum;
#else
int g_iSum = 0;
#endifuint64_t NowMicros() {struct timeval tv;gettimeofday(&tv, nullptr);return static_cast<uint64_t>(tv.tv_sec) * 1000000 + tv.tv_usec;
}void * thr_worker(int tid) {printf ("WORKER THREAD %d STARTUP\n", tid);int i=0;for (i=0; i<WORK_SIZE; ++i) {if (g_iFlagAtom) {
#ifdef ATOMIC
#else__sync_fetch_and_add(&g_iSum, 1);
#endif} else {
#ifdef ATOMICg_iSum ++;
#elsemu.lock();g_iSum ++;mu.unlock();
#endif}}return NULL;
}int main(int argc, char* argv[]) {if (argc < 2) {printf("args < 2");return -1;}g_iFlagAtom = atoi(argv[1]);int i;for (i=0;i<WORKER_COUNT;++i) {g_tWorkerID.push_back(std::thread(thr_worker, i));}uint64_t start = NowMicros();for (i=0;i<g_tWorkerID.size();++i) {g_tWorkerID[i].join();}printf ("CREATED %d WORKER THREADS\n", i);std::cout << "THE SUM :" << g_iSum << " TIME:" << NowMicros() - start<< "us" << std::endl;return 0;
}
- 对比
__sync_fetch_and_add和普通排他锁之间的性能差异:g++ -std=c++11 test_atomic.cc -o test_atomic# 普通锁 性能$ ./test_atomic 0 WORKER THREAD 1 STARTUP WORKER THREAD 0 STARTUP WORKER THREAD 2 STARTUP WORKER THREAD 3 STARTUP WORKER THREAD 5 STARTUP WORKER THREAD 4 STARTUP WORKER THREAD 7 STARTUP WORKER THREAD 6 STARTUP WORKER THREAD 8 STARTUP WORKER THREAD 9 STARTUP CREATED 10 WORKER THREADS THE SUM :50000000 TIME:2870679us # __sync_fetch_and_add 性能$ ./test_atomic 1 WORKER THREAD 0 STARTUP WORKER THREAD 1 STARTUP WORKER THREAD 3 STARTUP WORKER THREAD 4 STARTUP WORKER THREAD 2 STARTUP WORKER THREAD 5 STARTUP WORKER THREAD 6 STARTUP WORKER THREAD 7 STARTUP WORKER THREAD 8 STARTUP WORKER THREAD 9 STARTUP CREATED 10 WORKER THREADS THE SUM :50000000 TIME:1138828us - 对比
atomic原子变量的性能:g++ -std=c++11 test_atomic.cc -o test_atomic -DATOMIC$ ./test_atomic 0 WORKER THREAD 0 STARTUP WORKER THREAD 5 STARTUP WORKER THREAD 6 STARTUP WORKER THREAD 3 STARTUP WORKER THREAD 4 STARTUP WORKER THREAD 9 STARTUP WORKER THREAD 2 STARTUP WORKER THREAD 1 STARTUP WORKER THREAD 7 STARTUP WORKER THREAD 8 STARTUP CREATED 10 WORKER THREADS THE SUM :50000000 TIME:1180191us
从上面的测试数据可以整体看到__sync_fetch_and_add 的性能是比互斥锁性能好数倍,而和atomic的性能差不多。
为什么__sync_fetch_and_add 性能比互斥锁好呢?
我们来看一下如下代码的汇编实现。
#include <iostream>
int main() {int a;__sync_fetch_and_add(&a, 1);return 0;
}
编译: g++ -S test_sync_fetch_and_add.cc -o t.s
.section __TEXT,__text,regular,pure_instructions.build_version macos, 11, 0 sdk_version 11, 1.globl _main ## -- Begin function main.p2align 4, 0x90
_main: ## @main.cfi_startproc
## %bb.0:pushq %rbp.cfi_def_cfa_offset 16.cfi_offset %rbp, -16movq %rsp, %rbp.cfi_def_cfa_register %rbpxorl %eax, %eaxmovl $0, -4(%rbp)movl $1, -8(%rbp)movl $1, %ecx# lock前缀,这里是这个函数性能的关键。lock xaddl %ecx, -8(%rbp)movl %ecx, -12(%rbp)popq %rbpretq.cfi_endproc## -- End function
.subsections_via_symbols
其中汇编代码中有一个lock 前缀, 这个lock 前缀后面跟的是一个xaddl的指令。
这里万分感谢一位同事对lock前缀实现上的指正,现如今博客上的内容很多都是几年前甚至十几年前的技术,如今随着硬件的高速发展,这一些信息如果不能及时跟进最新的技术动态,往往会误导后续学习的同学,在最新技术迭代方面,以后一定会持续求证,保证总结的信息是准确的,并且后续持续更新之前的一些技术博客,以防误导他人。
关于lock前缀的实现,在 Intel486 和 Pentium processors 以及之前的处理器上面确实会在指令执行期间对内存总线进行加锁。
但是在 intel P6 和 更新的处理器上面,锁前缀已经不再是对内存总线进行加锁了,而是通过缓存一致性原理加锁当前处理器的cache,即当前的cpu-cache 所访问的内存,防止其他的cpu访问或者修改当前的cpu-cache中对应内存的内容,这样的加锁粒度更小,也更高效。更细节的内容可以参考intel 官方文档 中的8.1.4部分。
下面是原回答:
在x86 平台上, CPU 提供了指令执行期间加锁内存总线的手段。也就是通过这个
lock前缀,标识后续的一个指令的执行之前会加锁内存总线,而同处于当前内存总线的其他CPU的指令在此期间无法修改内存,等到lock 后面的一个指令执行完毕才会释放内存总线的锁。用这个指令前缀能够实现 CAS 以及 spinlock。
以下是__sync_fetch_and_add 函数的简单实现:
inline unsigned int __sync_fetch_and_sub(volatile unsigned int* p,unsigned int decr)
{unsigned int result;__asm__ __volatile__ ("lock; xadd %0, %1":"=r"(result), "=m"(*p):"0"(-decr), "m"(*p):"memory");return result;
}
同样的,我们在C++的 标准库的 atomic 代码的汇编中 中也能看到带有lock 前缀的指令。那这种 lock 前缀加锁内存总线相比于我们的排他锁的实现的性能差异体现在哪呢?
mu.lock() 或者 pthread_mutex_lock() 底层都是会调用操作系统的futex 系统调用,这个是操作系统层级调度线程的原子操作时的调度方式。它的粒度是操作系统级别的,让其他想要访问当前内存地址的线程挂起,等待增在访问内存的线程执行完毕再调度其他的线程。这样的调度粒度往往是线程的大量上下文信息在CPU cache中的load 和 overload。相比于__sync_fetch_and_sub 函数中的lock 前缀 锁内存总线来说效率高多了。
相关文章:

R 语言爬虫 之 cnblog博文爬取
Cnbolg Crawl a). 加载用到的R包 ##library packages needed in this case library(proto) library(gsubfn) ## Warning in doTryCatch(return(expr), name, parentenv, handler): 无法载入共享目标对象‘/Library/Frameworks/R.framework/Resources/modules//R_X11.so’&#…
Java项目:宿舍管理系统(java+jsp+SSM+Spring+mysql)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能:包括学生管理,班级管理,宿舍管理,人员信息维 护。维修登记,卫生管理,访客管理等等。 二、项目运行 环境配置&am…

项目管理5大过程组,42个过程一句话讲解
2019独角兽企业重金招聘Python工程师标准>>> 启动过程组:(1)制定项目章程:诞生项目,并为项目经理“正名”;(2)识别干系人:搞清楚谁与项目相关;规划…
Android Q 变更和新特性
安全和隐私变更 隐私保护是Android Q重要的主题之一,Android Q带来了一系列增强用户隐私保护的变更。 1 应用文件存储空间限制 应用访问限制是Android Q影响最大变更之一。在Android Q系统中,应用只可以通过路径读取自己应用沙箱内的文件,如果…

KVell 单机k/v引擎:用最少的CPU 来调度Nvme的极致性能
文章目录前言KVell背景业界引擎使用Nvme的问题CPU 会是 LSM-kv 存储的瓶颈CPU 也会是 Btree-kv 存储的瓶颈KVell 设计亮点 及 总体架构实现KVell 设计亮点1. Share nothing2. Do not sorted on disk, but keep indexes in memory3. Aim for fewer syscalls , not for sequentia…
android录像增加时间记录(源码里修改)
需要做一个功能,录像和播放时都显示录时的时间,参考文章链接找不到了,不好意思,这里记录一下,防止下次找不到了。另一篇关于源码录像的流程请参考 http://www.verydemo.com/demo_c131_i79000.html 在源码CameraSource.…
Java项目:在线旅游系统(java+jsp+SSM+Spring+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能:用户的登录注册,旅游景点的展示,旅游预订,收藏,购买,以及酒店住宿留言等等,后台管理员,订单…
混合式APP开发中中间件方案Rexsee
发现Rexsee时,他已经一年多没有更新过了,最后版本是2012年的。 他的实现思路是通过Android自带的Java - Javascript 桥机制,在WebView中的JavaScript同Java进行通信,而这样的话即Javascript可以直接创建原生UI界面,以获…
vue 前端框架 (三)
VUE 生命周期 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><script type"text/javascript" src"js/vue.js"></script><link rel"stylesheet" type"te…
Rocksdb 的 MergeOperator 简单使用记录
本篇仅仅是一个记录 MergeOperator 的使用方式。 Rocksdb 使用MergeOperator 来代替Update 场景中的读改写操作,即用户的一个Update 操作需要调用rocksdb的 Get Put 接口才能完成。 而这种情况下会引入一些额外的读写放大,对于支持SQL这种update 频繁的…
Java项目:考试系统Java基础Gui(java+Gui)
源码获取:博客首页 "资源" 里下载! 功能简介: 所属课程、题目内容、题目选项、题目答案、题目等级、学生管理、试卷管理、题目管理、时间控制 服务页面: public class ServerClient extends javax.swing.JFrame {/** …

软件工程需求设计说明书
Java即时通聊天程序 设计需求说明书 专业班级: 计本班1202班 项目组成员: 杨宗坤 刘瑞 满亚洲 指导教师: 张利峰 开始日期: 完成日期: 编写目的: 本说明书是在充分理解系统需求分析…
Nagios 安装文档
安装前的装备工作(1)解决安装Nagios的依赖关系:Nagios基本组件的运行依赖于httpd、gcc和gd。可以通过以下命令来检查nagios所依赖的rpm包是否已经安装完成:#yum -y install httpd gcc glibc glibc-common *gd* php php-mysql mysql mysql-server --skip-…

Comprehensive Guide to build a Recommendation Engine from scratch (in Python) / 从0开始搭建推荐系统...
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-recommendation-engine-python/, 一篇详细的入门级的推荐系统的文章,这篇文章内容详实,格式漂亮,推荐给大家. 下面是翻译,翻译关注的是意思&#x…

关于std::string 在 并发场景下 __grow_by_and_replace free was not allocated 的异常问题
使用string时发现了一些坑。 我们知道stl 容器并不是线程安全的,所以在使用它们的过程中往往需要一些同步机制来保证并发场景下的同步更新。 应该踩的坑还是一个不拉的踩了进去,所以还是记录一下吧。 string作为一个容器,随着我们的append 或…

Java项目:银行管理系统+文档Java基础Gui(java+Gui)
源码获取:博客首页 "资源" 里下载! 功能介绍: 登录、打印、取款、改密、转账、查询、挂失、存款、退卡 服务模块: public class atmFrame extends JFrame {private JPanel contentPane;private user user; // private…

ie旋转滤镜Matrix
旋转一个元素算是一个比较常见的需求了吧,在支持CSS3的浏览器中可以使用transform很容易地实现,这里有介绍:http://www.css88.com/archives/2168,这里有演示http://www.css88.com/tool/css3Preview/Transform.html,就不…
音频(3):iPod Library Access Programming Guide:Introduction
NextIntroduction介绍iPod库访问(iPod Library Access)让应用程序可以播放用户的歌曲、有声书、和播客。这个API设计使得基本播放变得非常简单,同时也支持高级的搜索和播放控制功能。iPod library access 通过打开iOS允许的音乐相关的广阔范围…
【2019/4/30】周进度报告
冲刺可以推迟了,但这不妨碍知识储备(另外这周看了看梦断代码,感觉还是很有意思的一本书)。 第七周所花时间约9个小时代码量700多行,主要是阅读代码为主(框架内代码)博客量1篇了解到的知识点 1.y…

关于 智能指针 的线程安全问题
先说结论,智能指针都是非线程安全的。 多线程调度智能指针 这里案例使用的是shared_ptr,其他的unique_ptr或者weak_ptr的结果都是类似的,如下多线程调度代码: #include <memory> #include <thread> #include <v…

Java项目:无库版商品管理系统(java+Gui+文档)
源码获取:博客首页 "资源" 里下载! 功能介绍: 添加商品、修改商品、删除商品、进货出货、查看流水、注册 登录业务处理: public class LoginView extends JFrame implements ComponentListener{private JPanel center…
LTE QCI分类 QoS
http://blog.163.com/gzf_lte/blog/static/20840310620130140057204/ http://blog.163.com/gzf_lte/blog/static/208403106201301403652527/ http://blog.sina.com.cn/u/1731932381 lte2010 QCI (QoS Class Identifier)同时应用于GBR和Non-GBR承载。一个QCI是一个值࿰…
CSS 单行溢出文本只显示部分内容
.cc-item div { width:175px; text-overflow:clip; //该属性适用于IE6,IE7 max-width:175px; //该属性适用于IE8,FF,谷歌}
Audio声音
转载于:https://www.cnblogs.com/kubll/p/10799187.html

Rocksdb Ribbon Filter : 结合 XOR-filter 以及 高斯消元算法 实现的 高效filter
文章目录前言XOR-filter 实现原理xor filter 的构造原理xor filter 构造总结XOR-filter 和 ADD-filter对比XOR-filter 在计算上的优化Ribbon filter高斯消元法总结参考前言 还是起源于前几天的Rocksdb meetup,其中Peter C. Dillinger 这位大佬分享了自己为rocksdb实…

Java项目:无库版银行管理系统(java+Gui+文档)
源码获取:博客首页 "资源" 里下载! 功能介绍: 注册用户、编辑用户、删除用户、存取款、查看流水 存入业务处理: public class depositFrame extends JFrame {private JPanel contentPane;private JTextField inputFiel…
iptables-save和iptables-restore
iptables-save用来把当前的规则存入一个文件里以备iptables-restore使用。它的使用很简单,只有两个参数:iptables-save [-c] [-t table]参数-c的作用是保存包和字节计数器的值。这可以使我们在重启防火墙后不丢失对包和字节的统计。带-c参数的iptables-s…

代码之美——Doom3源代码赏析2
http://www.csdn.net/article/2013-01-17/2813778-the-beauty-of-doom3-source-code/2 摘要:Dyad作者、资深C工程师Shawn McGrathz在空闲时翻看了Doom3的源代码,发出了这样的惊叹:“这是我见过的最整洁、最优美的代码!”“Doom 3的…
什么是JavaBean
按着Sun公司的定义,JavaBean是一个可重复使用的软件组件。实际上JavaBean是一种Java类,通过封装属性和方法成为具有某种功能或者处理某个业务的对象,简称bean。由于javabean是基于java语言的,因此javabean不依赖平台,具…
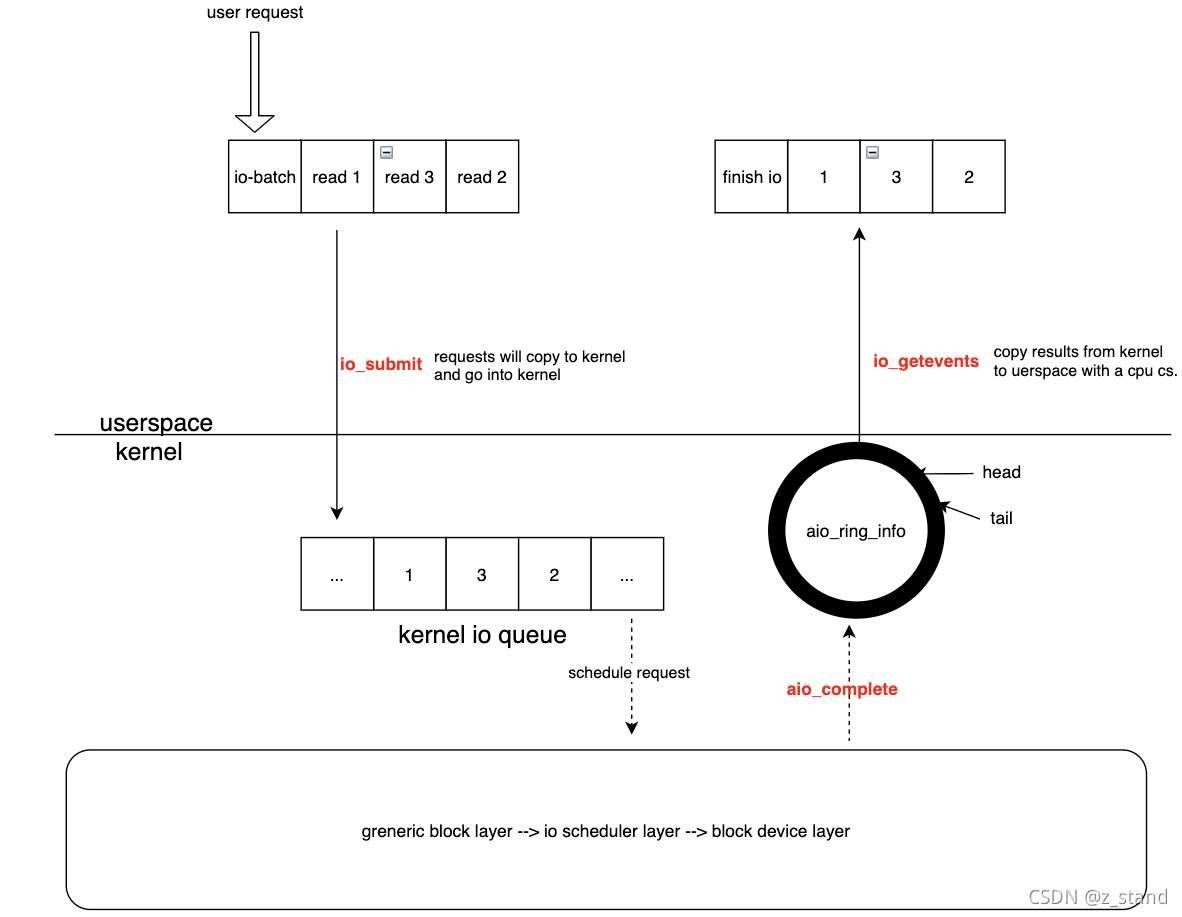
关于 linux io_uring 性能测试 及其 实现原理的一些探索
文章目录先看看性能AIO 的基本实现io_ring 使用io_uring 基本接口liburing 的使用io_uring 非poll 模式下 的实现io_uring poll模式下的实现io_uring 在 rocksdb 中的应用总结参考先看看性能 io_uring 需要内核版本在5.1 及以上才支持,liburing的编译安装 很简单&am…