关于 linux io_uring 性能测试 及其 实现原理的一些探索
文章目录
- 先看看性能
- AIO 的基本实现
- io_ring 使用
- io_uring 基本接口
- liburing 的使用
- io_uring 非poll 模式下 的实现
- io_uring poll模式下的实现
- io_uring 在 rocksdb 中的应用
- 总结
- 参考
先看看性能
io_uring 需要内核版本在5.1 及以上才支持,liburing的编译安装 很简单,直接clone 官方的代码,sudo make && sudo make install 就好了,本文是在内核5.12版本 上测试的。
在描述io_uring 的性能之前,我们先直接看一组实测数据:
这组数据是在3D XPoint 介质的硬盘 : optane-5800上测试的,optane5800 能够提供(randread100% 150w/s , randwrite 100% 150w/s)的性能。
| Direct | Depth | Jobs | Qps | Disk Width | Latency(avg,99,995,9999 us) | |
|---|---|---|---|---|---|---|
| AIO - RandRead(4K) | 1 | 1 | 1 | 11.2w/s | 436M | 8:9:10:18 |
| AIO - RandRead(4K) | 1 | 32 | 1 | 29w/s | 1.1G | 109:112:112:115 |
| AIO - RandRead(4K) | 1 | 128 | 1 | 29w/s | 1.1G | 439:441:445:465 |
| AIO - RandRead(4K) | 1 | 256 | 1 | 29w/s | 1.1G | 881:889:898:938 |
| URING-RandRead(4K) | 1 | 1 | 1 | 11.2w/s | 437M | 8:8:9:18 |
| URING-RandRead(4K) | 1 | 32 | 1 | 30.1w/s | 1.1G | 106:108:108:110 |
| URING-RandRead(4K) | 1 | 128 | 1 | 30.1w/s | 1.1G | 426:429:429:498 |
| URING-RandRead(4K) | 1 | 256 | 1 | 30w/s | 1.1G | 854:857:857:1004 |
| URING-RandRead(4K) sq_poll | 1 | 1 | 1 | 13.5w/s | 527M | 7:7:8:18 |
| URING-RandRead(4K) sq_poll | 1 | 32 | 1 | 49.4w/s | 1.9G | 64:70:72:83 |
| URING-RandRead(4K) sq_poll | 1 | 128 | 1 | 49.4w/s | 1.9G | 259:281:281:314 |
| URING-RandRead(4K) sq_poll | 1 | 256 | 1 | 49.1w/s | 1.9G | 521:545:545:652 |
| URING-RandRead(4K) sq_poll | 0 | 1 | 1 | 9.8w/s | 383M | 8:11:12:20 |
| URING-RandRead(4K) sq_poll | 0 | 32 | 1 | 26w/s | 0.99G | 121:174:178:1158 |
| URING-RandRead(4K) sq_poll | 0 | 128 | 1 | 25.1w/s | 976M | 507:742:750:116917 |
进行测试的fio 脚本如下:
# aio
[global]
ioengine=libaio
direct=0
randrepeat=1
threads=8
runtime=15
time_based
size=1G
directory=../test-data
group_reporting
[read256B-rand]
bs=4096
rw=randread
numjobs=1
iodepth=128# io_uring
[global]
ioengine=io_uring
sqthread_poll=1 #开启io_uring sq_poll模式
direct=1
randrepeat=1
threads=8
runtime=15
time_based
size=1G
directory=../test-data
group_reporting
[read256B-rand]
bs=4096
rw=randread
numjobs=1
iodepth=128
通过上面的测试,我们能够得到如下几个结论:
- 这种高队列深度的测试下,可以看到io_uring 在开启sq_poll之后的性能 相比于aio 的高队列深度的处理能力好接近一倍;
- 在较低队列深度 以及不开启 sq_poll 模式的情况下,io_uring 整体没有太大的优势,或者说一样的性能。
- 在buffer I/O (direct=0) 下,io_uring 也不会有太大的优势,因为都得通过 os-cache 来操作。
需要注意的是,如果aio和io_uring 在高并发下(jobs 的数目不断增加),都是可以达到当前磁盘的性能瓶颈的。
AIO 的基本实现
那有这样的测试现象,我们可能会有一些疑问,就这性能?我们在nvme上做软件,希望发挥的是整个磁盘的性能,而不是比拼谁的队列深度大,谁的优势更大。。。 我用aio 做batch 也能达到磁盘的性能瓶颈,为什么要选择 对于数据库/存储 领域来说 好像“如日中天”的io_uring呢。
我们先来看看aio 的大体实现,没有涉及到源代码。
aio 主要提供了三个系统调用:
io_setup初始化一些内核态的数据结构io_submit用于用户态提交io 请求io_getevents用于io 请求处理完成之后的io 收割
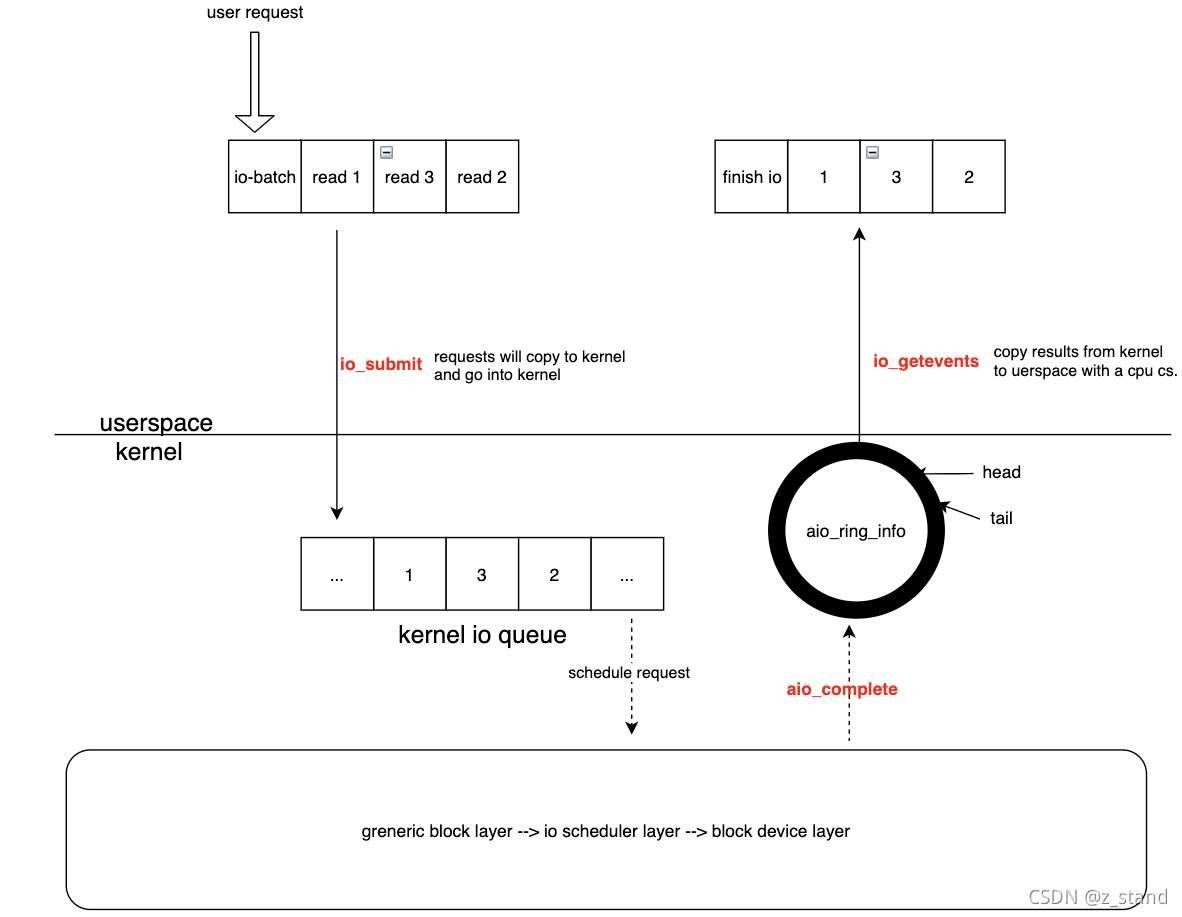
大体的IO调度过程如下:
- io_setup 完成一些内核数据结构的初始化(包括内核中的 aio 调度队列,aio_ring_info 的ring-buffer缓冲区)
- 用户态构造一批io请求,通过io_submit 拷贝请求到内核态io 队列(文件系统之上,上图没有体现出来)之后返回到用户态。
- 内核态继续通过内核i/o 栈处理io请求,处理完成之后 通过 aio_complete 函数将处理完成的请求放入到 aio_ring_info,每一个io请求是一个io_event。
- 用户态通过 io_getevents 系统调用 从 aio_ring_info(ring-buffer) 的head 拿处理完成的io_event,如果head==tail,则表示这个ring-buffer是空的。拿到之后,将拿到的io_event 一批从内核态拷贝到用户态。
如果单纯看 谁能将磁盘性能完整发挥出来,那毋庸置疑,大家都可以;那为什么做存储的对io_uring 的出现如此热衷呢?我们就得结合实际的应用场景来看看两者之间的差异了:
使用AIO的话,请求调度都需要直接由通用块层来调度处理,所以需要
O_DIRECT标记。这就意味着,使用AIO的应用都无法享受os cache,这对与存储应用来说并不友好,cache都得自己来维护,而且显然没有os page-cache性能以及稳定性有优势。而使用io_uring 则没有这样的限制,当然,io_uring在 buffer I/O下显然没有太大的优势。
延时上的开销。AIO 提交用户请求的时候 通过
io_submit调用,收割用户请求的时候通过io_getevents,正常应用的时候每一个请求都意味着至少两次系统调用(I/O提交和I/O收割),而对于io_uring来说,I/O 提交和I/O收割都可以 offload 给内核。这样相比于AIO 来说,io_uring能够极大得减少 系统调用引入的上下文切换。io_uring 能够支持针对submit queue的polling,启动一个内核线程进行polling,加速请求的提交和收割;对于aio来说,这里就没有这样的机制。
总的来说,io_uring 能够保证上层应用 对系统资源(cache)正常使用的同时 ,降低应用 下发的请求延时和CPU的开销,在单实例高队深下,能够显著优于同等队深下的AIO性能。
io_ring 使用
io_uring 基本接口
io_uring的用户态API 提供了三个系统调用,io_uring_setup,io_uring_enter,io_uring_register。
int io_uring_setup(u32 entries, struct io_uring_params *p);这个接口 用于创建 拥有entries个请求的 提交队列(SQ) 和 完成队列(CQ),并且返回给用户一个fd。这个fd可以用做在同一个uring实例上 用户空间和内核空间共享sq和cq 队列,这样能够避免在请求完成时不需要从完成队列拷贝数据到用户态了。io_uring_params主要是根据用户的配置来设置uring 实例的创建行为。包括 单不限于开启IORING_SETUP_IOPOLL和IORING_SETUP_SQPOLL两种 poll 模式。 后面会细说。int io_uring_register(unsigned int fd, unsigned int opcode, void *arg, unsigned int nr_args);这个接口主要用于注册用户态和内核态共享的缓冲区,即将 setup 返回的fd中的数据结构 映射到共享内存,从而进一步减少用户I/O 提交到uring 队列中的开销。
int io_uring_enter(unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t *sig);这个接口既能够提交 新的I/O请求 ,又能够支持I/O收割。
liburing 的使用
可以从上面的几个系统调用能够简单看到 用户在自主使用这三个系统调用来调度 I/O请求时 还是比较麻烦的,像io_uring_setup 之后的fd,我们用户层想要使用创建好的sq/cq ,则需要自主进行mmap,并且维护用户态的sq/cq 数据结构,并在后续的 enter 中自主进行用户态的sq 的填充。这个过程相对来说还是比较麻烦的。更不要说用三个系统调用中数十个的flags的灵活配置,如果全部结合起来,对于刚接触io_uring的用户来说还是需要较大的学习成本。
比如,我想启动io_uring,并初始化好用户态的sq/cq 数据结构,就需要写下面这一些代码:
int app_setup_uring(struct submitter *s) {struct app_io_sq_ring *sring = &s->sq_ring;struct app_io_cq_ring *cring = &s->cq_ring;struct io_uring_params p;void *sq_ptr, *cq_ptr;/** We need to pass in the io_uring_params structure to the io_uring_setup()* call zeroed out. We could set any flags if we need to, but for this* example, we don't.* */memset(&p, 0, sizeof(p));s->ring_fd = io_uring_setup(QUEUE_DEPTH, &p);if (s->ring_fd < 0) {perror("io_uring_setup");return 1;}/** io_uring communication happens via 2 shared kernel-user space ring buffers,* which can be jointly mapped with a single mmap() call in recent kernels.* While the completion queue is directly manipulated, the submission queue* has an indirection array in between. We map that in as well.* */int sring_sz = p.sq_off.array + p.sq_entries * sizeof(unsigned);int cring_sz = p.cq_off.cqes + p.cq_entries * sizeof(struct io_uring_cqe);/* In kernel version 5.4 and above, it is possible to map the submission and* completion buffers with a single mmap() call. Rather than check for kernel* versions, the recommended way is to just check the features field of the* io_uring_params structure, which is a bit mask. If the* IORING_FEAT_SINGLE_MMAP is set, then we can do away with the second mmap()* call to map the completion ring.* */if (p.features & IORING_FEAT_SINGLE_MMAP) {if (cring_sz > sring_sz) {sring_sz = cring_sz;}cring_sz = sring_sz;}/* Map in the submission and completion queue ring buffers.* Older kernels only map in the submission queue, though.* */sq_ptr = mmap(0, sring_sz, PROT_READ | PROT_WRITE,MAP_SHARED | MAP_POPULATE,s->ring_fd, IORING_OFF_SQ_RING);if (sq_ptr == MAP_FAILED) {perror("mmap");return 1;}if (p.features & IORING_FEAT_SINGLE_MMAP) {cq_ptr = sq_ptr;} else {/* Map in the completion queue ring buffer in older kernels separately */// 放置内存被page faultcq_ptr = mmap(0, cring_sz, PROT_READ | PROT_WRITE,MAP_SHARED | MAP_POPULATE,s->ring_fd, IORING_OFF_CQ_RING);if (cq_ptr == MAP_FAILED) {perror("mmap");return 1;}}/* Save useful fields in a global app_io_sq_ring struct for later* easy reference */sring->head = sq_ptr + p.sq_off.head;sring->tail = sq_ptr + p.sq_off.tail;sring->ring_mask = sq_ptr + p.sq_off.ring_mask;sring->ring_entries = sq_ptr + p.sq_off.ring_entries;sring->flags = sq_ptr + p.sq_off.flags;sring->array = sq_ptr + p.sq_off.array;/* Map in the submission queue entries array */s->sqes = mmap(0, p.sq_entries * sizeof(struct io_uring_sqe),PROT_READ | PROT_WRITE, MAP_SHARED | MAP_POPULATE,s->ring_fd, IORING_OFF_SQES);if (s->sqes == MAP_FAILED) {perror("mmap");return 1;}/* Save useful fields in a global app_io_cq_ring struct for later* easy reference */cring->head = cq_ptr + p.cq_off.head;cring->tail = cq_ptr + p.cq_off.tail;cring->ring_mask = cq_ptr + p.cq_off.ring_mask;cring->ring_entries = cq_ptr + p.cq_off.ring_entries;cring->cqes = cq_ptr + p.cq_off.cqes;return 0;
}
所以Jens Axboe 将三个系统调用做了一个封装,形成了liburing,在这里面我想要初始化一个uring实例,并完成用户态的数据结构的映射,只需要调用下面io_uring_queue_init 这个接口:
struct io_uring ring;struct io_uring_params p = { };int ret;ret = io_uring_queue_init(IORING_MAX_ENTRIES, &ring, IORING_SETUP_IOPOLL);
关于liburing的使用,可以看下面这个100行的小案例:
大体的功能就是利用io_uring 去读一个用户输入的文件,每次读请求的大小是4K,读完整个文件结束。
#include <stdio.h>
#include <fcntl.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include "liburing.h"#define QD 4int main(int argc, char *argv[])
{struct io_uring ring;int i, fd, ret, pending, done;struct io_uring_sqe *sqe;struct io_uring_cqe *cqe;struct iovec *iovecs;struct stat sb;ssize_t fsize;off_t offset;void *buf;if (argc < 2) {printf("%s: file\n", argv[0]);return 1;}// 初始化io_uring,并拿到初始化的结果,0是成功的,小于0 是失败的ret = io_uring_queue_init(QD, &ring, 0);if (ret < 0) {fprintf(stderr, "queue_init: %s\n", strerror(-ret));return 1;}// 打开用户输入的文件fd = open(argv[1], O_RDONLY | O_DIRECT);if (fd < 0) {perror("open");return 1;}// 将文件属性放在sb中,主要是获取文件的大小if (fstat(fd, &sb) < 0) {perror("fstat");return 1;}// 拆分成 设置的 io_uring支持的最大队列深度 个请求,4个fsize = 0;iovecs = calloc(QD, sizeof(struct iovec));for (i = 0; i < QD; i++) {if (posix_memalign(&buf, 4096, 4096))return 1;iovecs[i].iov_base = buf;iovecs[i].iov_len = 4096;fsize += 4096;}// 构造请求,并存放在 seq中offset = 0;i = 0;do {sqe = io_uring_get_sqe(&ring);if (!sqe)break;io_uring_prep_readv(sqe, fd, &iovecs[i], 1, offset);offset += iovecs[i].iov_len;i++;if (offset > sb.st_size)break;} while (1);// 提交请求sqe 中的请求到内核ret = io_uring_submit(&ring);if (ret < 0) {fprintf(stderr, "io_uring_submit: %s\n", strerror(-ret));return 1;} else if (ret != i) {fprintf(stderr, "io_uring_submit submitted less %d\n", ret);return 1;}done = 0;pending = ret;fsize = 0;// 等待内核处理完所有的请求,并由用户态拿到cqe,表示请求处理完成for (i = 0; i < pending; i++) {ret = io_uring_wait_cqe(&ring, &cqe);if (ret < 0) {fprintf(stderr, "io_uring_wait_cqe: %s\n", strerror(-ret));return 1;}done++;ret = 0;if (cqe->res != 4096 && cqe->res + fsize != sb.st_size) {fprintf(stderr, "ret=%d, wanted 4096\n", cqe->res);ret = 1;}fsize += cqe->res;io_uring_cqe_seen(&ring, cqe);if (ret)break;}// 最后输出 提交的请求的个数(4k),完成请求的个数,总共处理的请求大小printf("Submitted=%d, completed=%d, bytes=%lu\n", pending, done,(unsigned long) fsize);close(fd);io_uring_queue_exit(&ring);return 0;
}
编译: gcc -O2 -D_GNU_SOURCE -o io_uring-test io_uring-test.c -luring
运行: ./io_uring-test test-file.txt
io_uring 非poll 模式下 的实现
接下来记录一下io_uring的实现,来填之前说到的一些小坑,当然…这里描述的内容也是站在前人的肩膀 以及 自己经过一些测试验证总体来看的。
io_uring 能够支持其他多种I/O相关的请求:
- 文件I/O:read, write, remove, update, link,unlink, fadivse, allocate, rename, fsync等
- 网络I/O:send, recv, socket, connet, accept等
- 进程间通信:pipe
- …
还是以 上面案例中 io_uring 处理read 请求为例, 通过io_uring_prep_readv 来填充之前已经创建好的sqe。
static inline void io_uring_prep_readv(struct io_uring_sqe *sqe, int fd,const struct iovec *iovecs,unsigned nr_vecs, __u64 offset)
{// 调度读请求,将构造好的iovecs 中的内容填充到sqe中。io_uring_prep_rw(IORING_OP_READV, sqe, fd, iovecs, nr_vecs, offset);
}static inline void io_uring_prep_rw(int op, struct io_uring_sqe *sqe, int fd,const void *addr, unsigned len,__u64 offset)
{sqe->opcode = (__u8) op;...sqe->fd = fd;sqe->off = offset;sqe->addr = (unsigned long) addr;sqe->len = len;...sqe->__pad2[0] = sqe->__pad2[1] = 0;
}
那我们需要先回到最开始的io_uring_setup 以及 后续的mmap setup返回的结果 之后 用户态和内核态共享的数据结构内容。
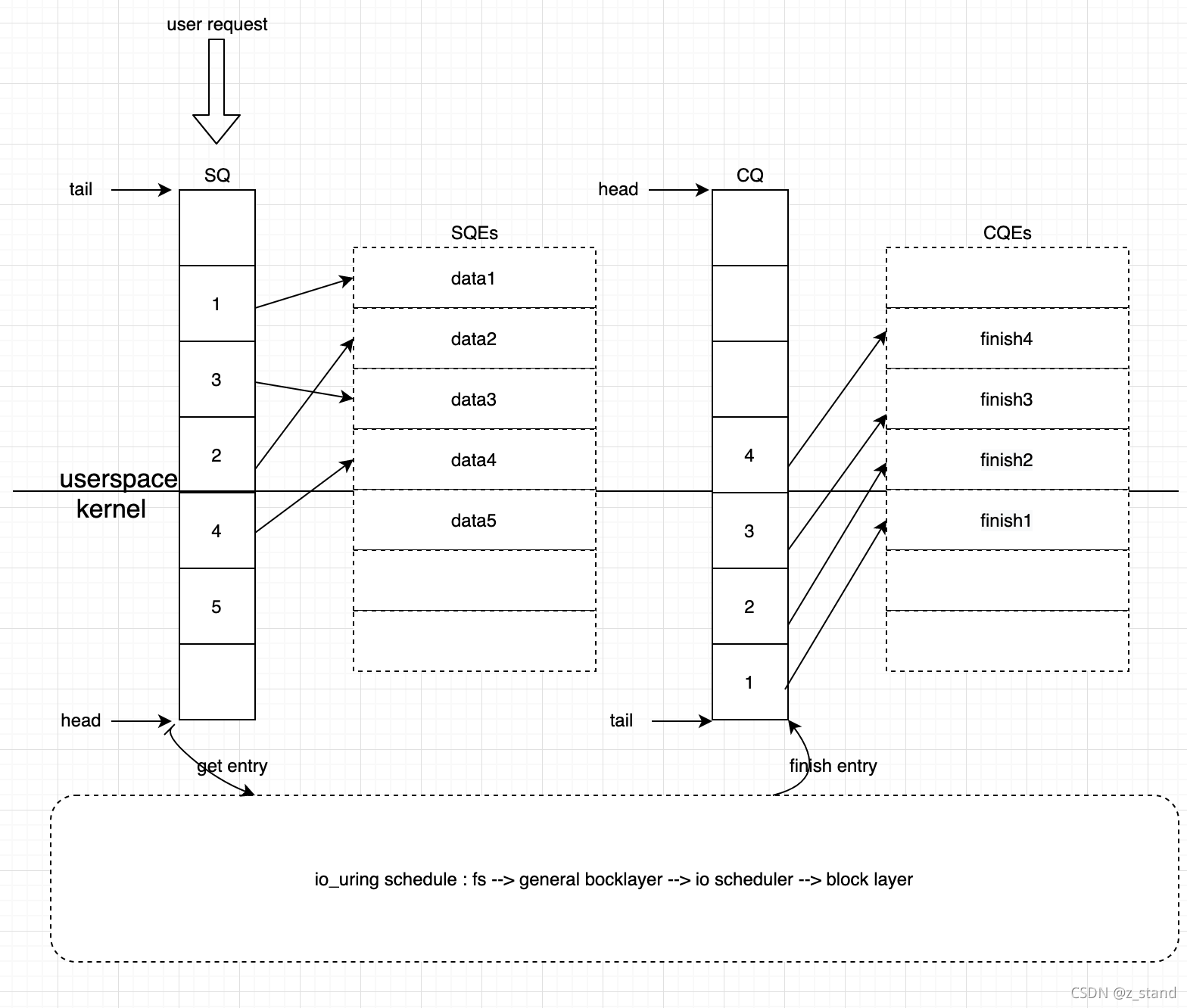
数据结构 在内存中的分布 如上图:
io_uring_setup之后,会将内核中创建好的一块内存区域 用fd标识 以及各个数据结构在这个内存区域中的偏移量存放在io_uring_params中, 通过mmap 来将这部分内存区域的数据结构映射到用用户空间。其中
io_uring_params中的 关键数据结构如下:struct io_uring_params {__u32 sq_entries; // sq 队列的个数__u32 cq_entries; // cq 队列的个数__u32 flags; // setup设置的一些标识,比如是否开启内核的io_poll 或者 sq_poll等__u32 sq_thread_cpu; // 设置sq_poll 模式下 轮询的cpu 编号__u32 sq_thread_idle; __u32 features;__u32 wq_fd;__u32 resv[3];struct io_sqring_offsets sq_off; // sq的偏移量struct io_cqring_offsets cq_off; // cq的偏移量 };Mmap 之后的内存形态就是上图中的数据结构形态,mmap的过程就是填充用户态可访问的sq/cq。
SQ ,submission queue,保存用户空间提交的请求的地址,实际的用户请求会存放在
io_uring_sqe的sqes中。struct io_uring_sq {unsigned *khead;unsigned *ktail;...struct io_uring_sqe *sqes; // 较为复杂的数据结构,保存请求的实际内容unsigned sqe_head;unsigned sqe_tail;... };用户空间的sq更新会追加到SQ 的队尾部,内核空间消费 SQ 时则会消费队头。
CQ, complete queue,保存内核空间完成请求的地址,实际的完成请求的数据会存放在
io_uring_cqe的cqes中。struct io_uring_cq {unsigned *khead;unsigned *ktail;...struct io_uring_cqe *cqes;... };内核完成IO 收割之后会将请求填充到cqes 中,并更新cq 的队尾,用户空间则会从cq的队头消费 处理完成的请求。
在前面的read 案例代码中,调用的
liburing的函数io_uring_get_sqe就是在用户空间更新sq的队尾部。struct io_uring_sqe *io_uring_get_sqe(struct io_uring *ring) {struct io_uring_sq *sq = &ring->sq;unsigned int head = io_uring_smp_load_acquire(sq->khead);unsigned int next = sq->sqe_tail + 1;struct io_uring_sqe *sqe = NULL;// 当前sq的 tail 和 head之间的容量满足sq的大小,则将当前请求的填充到sqe中// 并更新sq 的队尾,向上移动if (next - head <= *sq->kring_entries) {sqe = &sq->sqes[sq->sqe_tail & *sq->kring_mask];sq->sqe_tail = next;}return sqe; }后续,内核处理完成之后,用户空间从cq中获取 处理完成的请求时则会调用
io_uring_wait_cqe_nr进行收割。
io_uring 中的ring就是 上图中的io 链路,从sq队尾进入,最后请求从cq 队头出来,整个链路就是一个环形(ring)。而sq和cq在数据结构上被存放在了
io_uring中。加了uring 中的u猜测是指用户态(userspace)可访问的,目的是好的,不过读起来的单词谐音就让一些人略微尴尬(urine。。。)
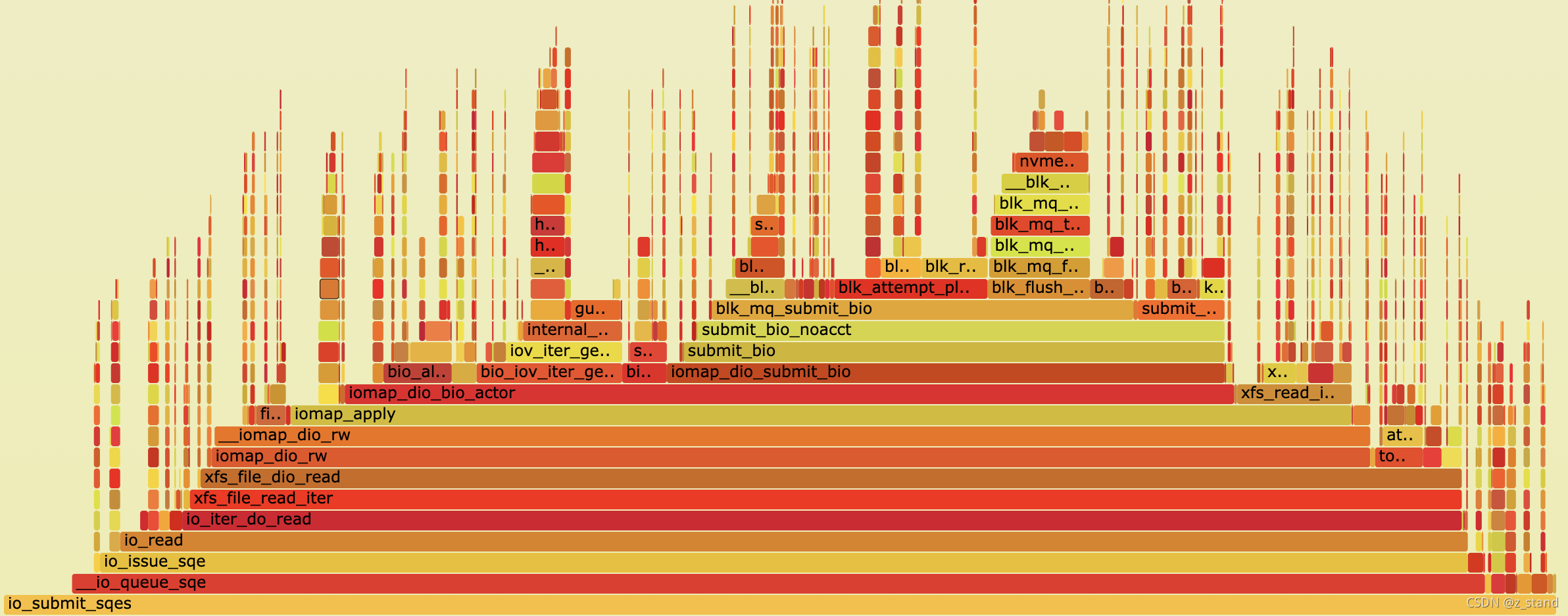
非poll 模式下的内核火焰图调用栈如下:
io_uring poll模式下的实现
我们在最开始的性能测试过程中可以看到在开启 poll 之后,io_uring的性能才能显著提高。
我们从前面 io_uring 内存分布图 中可以看到在内核调度两个队列请求的过程中 可以通过异步轮询的方式进行调度的,也就是io_uring的 poll模式。
io_uring 在io_uring_setup的时候可以通过设置flag 来开启poll模式,io-uring 支持两种方式poll模式。
IORING_SETUP_IOPOLL,这种方式是由nvme 驱动支持的 io_poll。即用户态通过io_uring_enter提交请求到内核的文件读写队列中即可,nvme驱动会不断得轮询文件读写队列进行io消费,同时用户态在设置IORING_ENTER_GETEVENTS得flag之后,还需要不断得调用io_uring_enter通过io_iopoll_check调用内核接口查看 nvme的io_poll 是否完成任务调度,从而进行填充 cqes。如果使用nvme驱动,则需要单独开启io_poll 才能真正让 IORING_SETUP_IOPOLL 配置生效。
开启的话,直接尝试 root 用户操作:echo 1 > /sys/block/nvme2n1/queue/io_poll,成功则表示开启。
如果出现bash: echo: write error: Invalid argument ,则表示当前nvme驱动还不支持,需要通过驱动层打开这个配置才行,可以尝试执行如下步骤:
如果执行之前,通过modinfo nvme 查看当前设备是否有nvme驱动失败,则需要先编译当前内核版本的nvme驱动才行,否则下面的操作没有nvme驱动都是无法进行的。
- umount fs , 卸载磁盘上挂载的文件系统
- echo 1 > /sys/block/nvme0n1/device/device/remove , 将设备从当前服务器移除
- rmmod nvme
- modprobe nvme poll_queues=1, 重新加载nvme驱动,来支持io_poll的队列深度为1
- echo 1 > /sys/bus/pci/rescan ,重新将磁盘加载回来
IORING_SETUP_SQPOLL,这种模式的poll则是我们fio测试下的sqthread_poll开启的配置。开启之后io_uring会启动一个内核线程,用来轮询submit queue,从而达到不需要系统调用的参与就可以提交请求。用户请求在用户空间提交到SQ 之后,这个内核线程处于唤醒状态时会不断得轮询SQ,也就可以立即捕获到这次请求。(我们前面的案例中会先在用户空间构造指定数量的SQ放到ring-buffer中,再由io_uring_enter一起提交到内核),这个时候有了sq_thread 的轮询,只要用户空间提交到SQ,内核就能够捕获到并进行处理。如果sq_thread 长时间捕获不到请求,则会进入休眠状态,需要通过调用io_uring_enter系统调用,并设置IORING_SQ_NEED_WAKEUP来唤醒sq_thread。
大体的调度方式如下图:
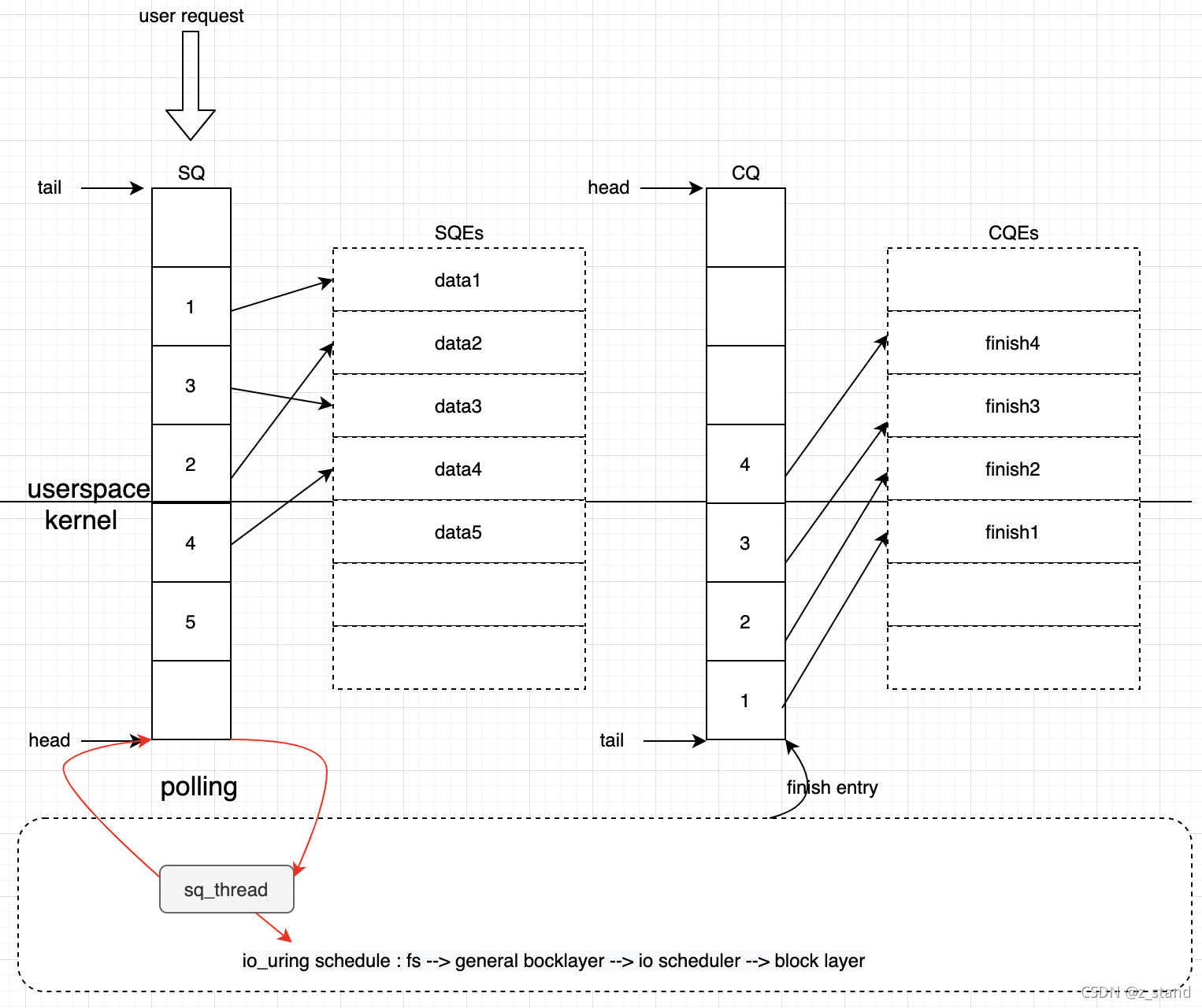
这种sq_thread 内核对SQ的轮询模式能够极大得减少请求在submit queue中的排队时间,同时减少了
io_uring_enter系统调用的开销。
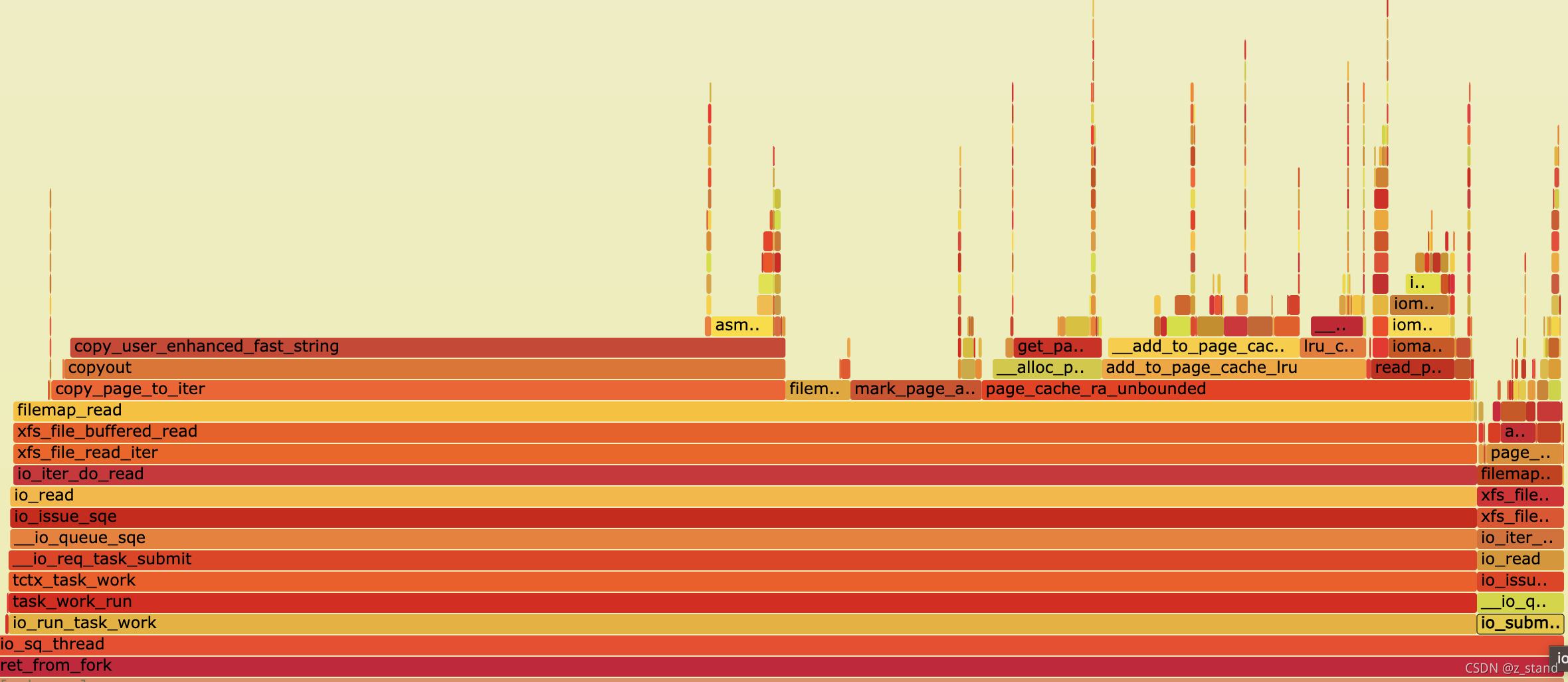
开启sq_thread之后的轮询模式可以看到 用户提交请求 对CPU消耗仅仅只占用了一小部分的cpu。
io_uring 在 rocksdb 中的应用
Rocksdb 针对io_uring的调用大体类似前面提到的使用liburing 接口实现的一个read 文件的案例,同样是调用io_uring_prep_readv 来实现对文件的读写。
Io_uring 的特性决定了在I/O层 的批量读才能体现它的优势,所以rocksdb 将io_uring集成到了 MultiGet 中的 MultiRead 接口之中。
需要注意的是 rocksdb 设置的 io_uring的SQ 队列深度大小是256,且setup的时候并没有开启sq_poll模式,而是默认开启io_poll,即flag是0;如果想要开启sq_poll模式,则需要变更这个接口的flags配置,比如将0设置为IORING_SETUP_SQPOLL,然后重新编译源代码即可。
inline struct io_uring* CreateIOUring() {struct io_uring* new_io_uring = new struct io_uring;int ret = io_uring_queue_init(kIoUringDepth, new_io_uring, 0);if (ret) {delete new_io_uring;new_io_uring = nullptr;}return new_io_uring;
}
大家在使用db_bench测试io_uring的时候 如果不变更rocksdb这里的io_uring_queue_init接口的话,需要保证自己的磁盘支持io_poll模式,也就是通过上一节说的那种查看/修改 nvme 驱动配置来支持io_poll。
在io_poll模式下,对MultiGet的接口测试性能数据大概如下:
我的环境不支持io_poll,大体收益应该和fio的poll模式下的性能收益差不了太多

图片来自官方
db_bench的配置可以使用,直接用rocksdb的master, CMakeList.txt 默认会开启io_uring:
生成数据:
./db_bench_uring \--benchmarks=fillrandom,stats \--num=3000000000 \--threads=32 \--db=./db \--wal_dir=./db \--duration=3600 \-report_interval_seconds=1 \--stats_interval_seconds=10 \--key_size=16 \--value_size=128 \--max_write_buffer_number=16 \-max_background_compactions=32 \-max_background_flushes=7 \-subcompactions=8 \-compression_type=none \
io_uring 测试MultiGet,不使用block_cache:
./db_bench_uring \--benchmarks=multireadrandom,stats \--num=3000000000 \--threads=32 \--db=./db \ --wal_dir=./db \--duration=3600 \-report_interval_seconds=1 \--stats_interval_seconds=10 \--key_size=16 \--value_size=128 \-compression_type=none \-cache_size=0 \-use_existing_db=1 \-batch_size=256 \ # 每次MultiGet的 请求总个数-multiread_batched=true \ # 使用 MultiGet 的新的API,支持MultiRead,否则就是逐个Get-multiread_stride=0 # 指定MultiGet 时生成的key之间的跨度,本来是连续的随机key,现在可以让上一个随机key和下一个随机key之间间隔指定的长度。
总结
总的来说,io_uring能够在内核的各个组件都能够正常运行的基础上进一步提升了性能,提升的部分包括 减少系统调用的开销,减少内核上下文的开销,以及支持io_poll和sq_poll 这样的高速轮询处理机制。而且相比于libaio 仅能够使用direct-io来调度,那这个限制本身就对存储应用软件不够友好了。
可见的未来,存储系统是内核的直接用户,随着未来硬件介质的超高速发展,互联网应用对存储系统的高性能需求就会反作用于内核,那内核的一些I/O链路的性能也需要不断得跟进提升,然而每一项on-linux kernel的更改都因为内核精密复杂高要求 的 标准都会比普通的应用复杂很多,io_uring 能够合入5系内核的upstream,那显然证明了其未来的发展潜力 以及 内核社区 对其潜力的认可。
参考
1. https://kernel.dk/io_uring.pdf
2. https://zhuanlan.zhihu.com/p/380726590
3. https://developers.mattermost.com/blog/hands-on-iouring-go/
相关文章:

添加引用方式抛出和捕获干净的WebService异常
转载:http://www.cnblogs.com/ahdung/p/3953431.html 说明:【干净】指的是客户端在捕获WebService(下称WS)抛出的异常时,得到的ex.Message就是WS方法中抛出的异常消息,不含任何“杂质”。 前提:…
Java项目:车租赁管理系统(java+Gui+文档)
源码获取:博客首页 "资源" 里下载! 功能介绍: 登陆界面、管理员界面、用户界面、汽车租赁文档 系统主页: SuppressWarnings("serial") public class SystemMainView extends JFrame implements ActionListe…
TFS中的测试计划(十)
现在有一个测试用例,用来测试登录,并且有两组测试数据。打开团队项目的web门户的测试。新建一个测试计划。命名为测试计划1添加完测试计划后,就可以向这个计划里添加测试用例了,选择登录测试。运行测试,就会生成下图左…

跟着Rocskdb 学 存储引擎:读写链路的代码极致优化
文章目录1. 读链路1.1 FileIndexer1.1.1 LevelDB sst查找实现1.1.2 Rocksdb FileIndexer实现1.2 PinnableSlice 减少内存拷贝1.3 Cache1.3.1 LRU Cache1.3.2 Clock Cache1.4 ThreadLocalPtr 线程私有存储1.4.1 version系统1.4.2 C thread_local vs ThreadLocalPtr1.4.3 ThreadL…

Java项目:人力管理系统(java+Gui+文档)
源码获取:博客首页 "资源" 里下载! 功能介绍: 角色员工、管理员,员工信息表,查询、更新,修改,移除、添加 用户管理控制层: /*** author yy*/Controller RequestMapping(…

senfile函数实例的运行过程截图
//要传输的文件内容如下所示: 启动服务器,等待客户端连接(在同一台主机上模拟的) 客户端远程登录,这里是在本地登录 这个要注意一点就是远程登陆的时候一定要带上端口号不然连接失败!!转载于:ht…

马年计划2014-2-21
新的一年到来了! 刚刚过去的一年里,我已浪费很多时光! 新年新气象,为避免重蹈覆辙,此时我必须要立个新年计划,马年计划! (1)一天必须做两道ACM题。 (2&#…
java jsp页面如何添加C标签
在https://mvnrepository.com/找两个jar包分别是: <dependency> <groupId>javax.servlet.jsp.jstl</groupId> <artifactId>jstl-api</artifactId> <version>1.2</version> </dependency> <dependency> <g…

如何用 ndctl/ipmctl 管理工具 配置不同访问模式的pmem设备
文章目录1 PMEM 底层架构2 PMEM 逻辑架构3 ipmctl 创建 不同模式的 region3.1 安装3.2 创建AppDirect mode的region3.3 创建 Memory Mode模式3.4 创建 混合模式3.5 查看创建的结果4 ndctl 创建不同类型的 namespaces4.1 安装4.2 创建/删除 一个任意类型的namespace4.3 指定类型…
[PHP]php基础练习题学习随笔
1、解释一下PHP中常量、变量、可变变量并举例说明;超级全局变量有哪些? 常量是单个值的标识符(名称),通过define()设置,在脚本中无法改变该值,常量自动全局。<?php #对大小写不敏感为true&a…

Java项目:进销存系统(java+Gui)
源码获取:博客首页 "资源" 里下载! 功能介绍: 基本信息管理、库存管理、销售管理、订单管理、日志管理、供应商基本信息、员工基本信息、商品信息、入库管理、出库管理、剩余库存 商品信息控制层: /*** <p>* 前…
IDP申请直到软件上架流程 - iOS
第一:IDP的申请 1.先在iPhone DevCenter上注册成为iphone developer 2.加入iPhone开发程序项目iPhone Developer Program Apply Now 3.打算收费的都建议选择99刀那个,QTY是个数的意思。1就好。 4.选择地区china,(很早之前没有china࿰…

灭霸—个人冲刺(4)
灵魂三问:昨天做了什么?1.手机验证码 2h 2.整体框架搭建尝试 2h 目标任务量:100% 完成任务量:100% 今天要做什么?1.数据库建立及连接 16h 遇到困难没有?2.整体框架搭建时因为连接服务器分为三类…

关于 Rocksdb 的 EnvWrapper 作用的小讨论
临下班前一位做引擎的小伙伴提了个小问题, Rocksdb 实现了非常多的Env backend 这一些backend 可以让用户根据自己需求创建不同 公共接口backend,来实现自己的文件操作或者公共线程池操作。 Env* env new rocksdb::HdfsEnv(FLAGS_hdfs) 问题是…

corepython第九章:文件和输入输出
学习笔记: OS模块代码示例: 1 import os2 for tmpdir in (/tmp,rc:\users\administrator\desktop):3 #如果存在括号里面的目录,则break4 if os.path.isdir(tmpdir):5 break6 #如果不存在,则tmpdir为空值,即False7 else:8 pri…
Java项目:学生管理系统(无库版)(java+打印控制台)
源码获取:博客首页 "资源" 里下载! 功能介绍: 学生成绩管理系统成绩表 用户管理操作: /*** 用户管理操作*/ Controller RequestMapping("/user") public class UserController {Autowiredprivate UserServi…
构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(12)-系统日志和异常的处理②...
原文:构建ASP.NET MVC4EF5EasyUIUnity2.x注入的后台管理系统(12)-系统日志和异常的处理② 上一讲我们做了日志与异常的结果显示列表,这一节我们讲要把他应用系统中来。 首先我们在App.Common类库中创建一个通用类ResultHelper,这个…

爬取猫眼怦然心动电影评论
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159 可以用pandas读出之前保存的数据: newsdf pd.read_csv(rF:\duym\gzccnews.csv) 一.把爬取的内容保存到数据库sqlite3 import sqlite3with sqlite3.connect(gzccnewsdb.sqli…
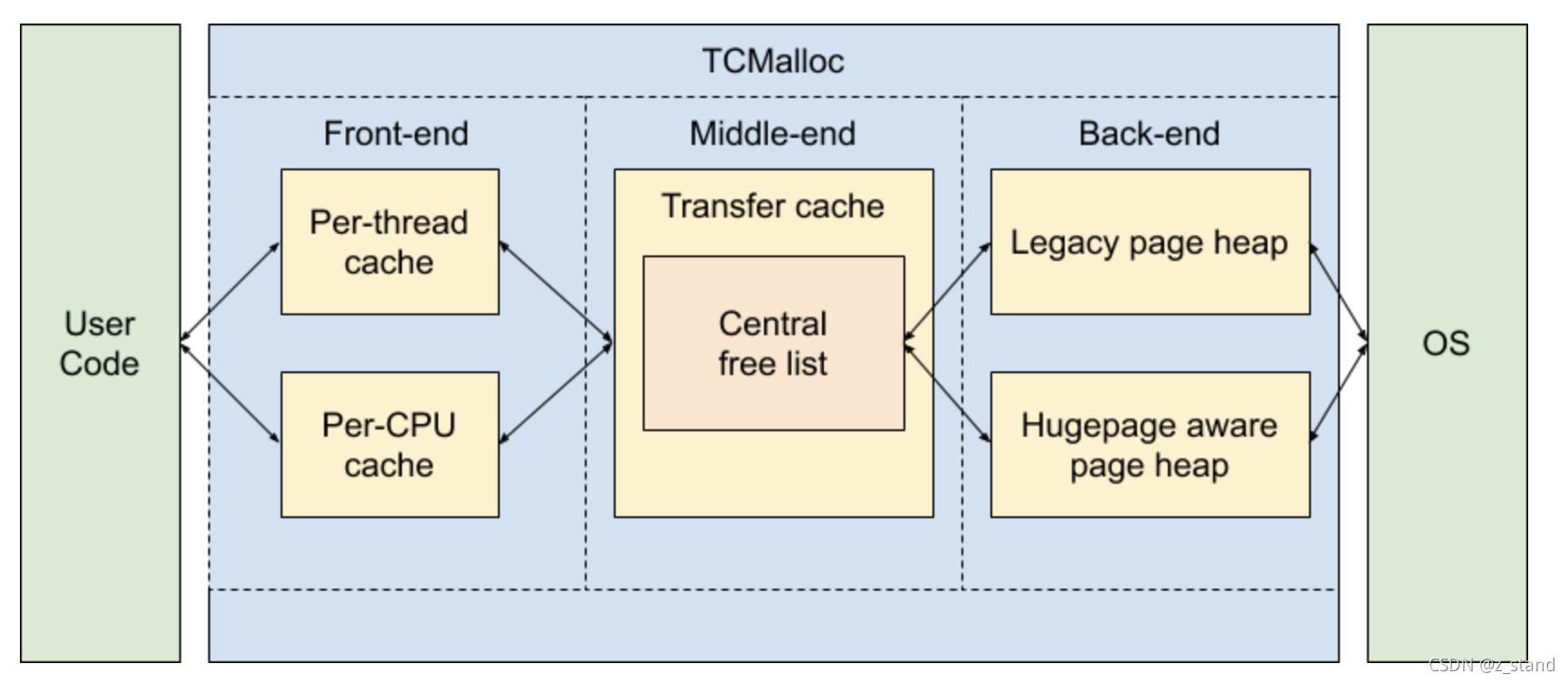
TCMalloc(Thread-Caching malloc) 基本设计原理
文章目录背景如何使用架构概览1. TCMalloc Front-end1.1 小对象和大对象的内存分配过程1.2 内存释放过程1.3 Per-CPU mode1.4 Per-thread mode1.5 per-cpu 和 per-thread 运行时内存管理算法对比2. TCMalloc Middle-end2.1 Transfer Cache2.2 Central Free List2.3 Pagemap 和 …
Java项目:控制台商城系统(java+打印控制台)
源码获取:博客首页 "资源" 里下载! 功能简介: 客户信息管理、商品信息管理、购物信息管理、退出系统 显示系统主菜单: public class SystemMenu {//显示系统主菜单public void showMainMenu(){System.out.println(&qu…
PAT (Basic Level) Practise (中文)-1025. 反转链表 (25)
PAT (Basic Level) Practise (中文)-1025. 反转链表 (25) http://www.patest.cn/contests/pat-b-practise/1025 给定一个常数K以及一个单链表L,请编写程序将L中每K个结点反转。例如:给定L为1→2→3→4→5→6,K为3&am…

初识Quartz(三)
为什么80%的码农都做不了架构师?>>> 简单作业: package quartz_project.example3;import java.util.Date;import org.quartz.Job; import org.quartz.JobExecutionContext; import org.quartz.JobExecutionException; import org.quartz.Job…

内存分配器设计的演进
文章目录栈内存空间是否够用系统调用申请内存最简单的内存分配器实现 -- bump allocator可扩容的 Bump alloactor通过free-list 管理的 allocator通过size-buckets 维护多个free-list 的 allocatorCache friendly allocator需要考虑更多问题的allocator性能易用性本文希望描述一…
Android OpenGL ES(十一)绘制一个20面体 .
前面介绍了OpenGL ES所有能够绘制的基本图形,点,线段和三角形。其它所有复杂的2D或3D图形都是由这些基本图形构成。 本例介绍如何使用三角形构造一个正20面体。一个正20面体,有12个顶点,20个面,30条边构成:…

Java项目:学生选课系统(java+javaweb+jdbc)
源码获取:博客首页 "资源" 里下载! 功能介绍: 用户菜单、学生管理、教师管理、课程管理、成绩排名查询 学生管理控制层: Controller RequestMapping("/student") public class StudentController {private …
Xtrabackup对mysql全备以及增量备份实施
Xtrabackup对mysql全备以及增量备份实施1.完全备份与恢复本文使用的是centos5.8 64位系统,mysql 使用5.5.35.如果要使用一个最小权限的用户进行备份,可基于以下:mysql> createuser bkuserlocalhost identified by redhat;mysql> grant …
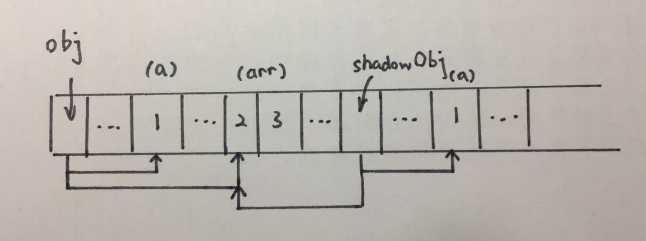
js浅拷贝和深拷贝
浅度拷贝:复制一层对象的属性,并不包括对象里面的为引用类型的数据,当改变拷贝的对象里面的引用类型时,源对象也会改变。 深度拷贝:重新开辟一个内存空间,需要递归拷贝对象里的引用,直到子属性都…
关于 fallocate 文件系统预分配 的一些细粒度测试
文章目录Rocksdb 中的预分配Fallocate in rocksdb 性能测试Fallocate 使用 以及 对应配置的行为API 使用不同 Mode 的行为分配磁盘空间释放磁盘空间折叠/裁剪 文件内容清零文件 扩容文件Rocksdb 中的预分配 预分配文件存储空间 在存储引擎中用的还是比较频繁的,尤…
mac 使用nvm安装node
1.curl https://raw.github.com/creationix/nvm/master/install.sh | sh2。vi ~/.bash_profile 添加:source /Users/dujie/.nvm/nvm.sh nvm install 0.10.24 nvm use 0.10.24 # 默認使用 0.10.24 版本,否則每次關掉 Terminal 就得重新 nvm use 一次 $…
Java项目:人事管理系统(java+javaweb+jdbc)
源码获取:博客首页 "资源" 里下载! 功能介绍: 登录、新增、修改、离职 员工管理控制层: Controller RequestMapping("/employee") public class EmployeeController {Autowiredprivate IEmployeeService em…