KVell 单机k/v引擎:用最少的CPU 来调度Nvme的极致性能
文章目录
- 前言
- KVell背景
- 业界引擎使用Nvme的问题
- CPU 会是 LSM-kv 存储的瓶颈
- CPU 也会是 Btree-kv 存储的瓶颈
- KVell 设计亮点 及 总体架构实现
- KVell 设计亮点
- 1. Share nothing
- 2. Do not sorted on disk, but keep indexes in memory
- 3. Aim for fewer syscalls , not for sequential I/O
- 4. No commit log
- KVell 详细架构及实现
- 1. Client SDK
- 2. 磁盘数据结构
- 3. 内存数据结构
- 3.1 index
- 3.2 Page Cache
- 3.3 Free List
- 4. 高效的I/O调度
- 5. 请求调度的实现
- 5.1 Get
- 5.2 Update
- 5.3 Scan
- 6. 存在的问题
- 性能测试
- kvell性能
- kvell本身 pagecache的压测
- Kvell 内存索引的压测
前言
这是SOSP’19 中 结合NVMe-ssd 推出的高性能 单机K/V 存储的设计。让大家眼前一亮的是它对 on NVME单机存储性能瓶颈的探索 以及 解决性能瓶颈问题的几点思考,值得学习。
而且 最近也在做 on-nvme 的hash-engine,也跑了一下论文中的代码 并且 大体翻了一遍其中对nvme的优化设计,觉得还是有很多可以借鉴学习的。 实际的测试结果呢,64core cpu + 3T 三星nvme下,仅用8个worker,2个模拟的disk,就能跑满整个写带宽/读带宽,而且cpu的话也就8个core(8个worker) + 4个core(ycsb会起4个分发请求的线程),cpu还有大量的空闲(52个core)。而想要跑到这样的吞吐,rocksdb/wt 在我这个环境下需要至少60%的cpu。
在看到这个测试数据和论文中的差异并不是特别大的时候就很感兴趣了,所以就仔细看了一些论文中提到的设计细节并扒了对应的代码,在本文这里做一个简短的总结。
KVell 提出的主体的 单机 on-nvme 的k/v存储 设计原则是:
- Shared-nothing。所有的数据结构的操作(内存/磁盘)都绑定在指定的cpu core上处理,这样整个操作链路能够实现无锁化。
- Do not sort on disk, but keep indexes in memory。在磁盘上的数据存储是无序的,内存中的部分有序的索引的存在只是为了加速scan的性能。
- Aim for fewer sys calls, not for sequential I/O。磁盘的随机访问已经接近顺序访问的性能,可以通过batch 操作尽可能得避免系统调用,从而减少cpu的开销。
- No commit log。不需要wal,数据落盘再更新索引,能够避免WAL 的I/O开销。
kvell 是针对高性能存储的nvme推出的, 所以它的优化前提是硬件性能已经不再是主要瓶颈。所以,对于当下的大数据量的分布式存储领域来说(块/文件系统/对象)还是可借鉴的地方有限,他们可能因为成本问题更原因选择lsm/btree的成熟引擎。而且KVell 使用的是AIO来调度i/o,所以在这种实现下只能使用o_direct 进行操作,os-cache基本上是用不了了,只能像kvell一样实现自己的cache,这对于存储系统来说其实代价挺大的(稳定/高性能的cache 实现还是不容易的)。
KVell背景
磁盘性能是越来越快了。
从hdd --> sata ssd --> nvme ssd --> optane ssd --> optane pmem ,不论是带宽还是延时,都在以量级的方式不断得被优化。

而且,从 Nvme-ssd 开始,随机I/O 和 顺序I/O 的性能差异并没有那么大了,甚至基本接近。

那rocksdb/wiredtiger 到现在也快10年了,他们当时推出的是on-sata ssd的 k/v设计,不论是append-only b-tree 还是 append-only lsm-tree的提出, 其实都是因 随机I/O 和顺序I/O 之间有较大的性能差异。而从nvme协议推出之后,两者之间的性能差异并没有那么大了, 还是用之前的存储引擎架构,并无法完全发挥硬件性能。
在这个硬件环境的背景下,KVell 就是为了当前nvme及更高性能的磁盘 设备设计的高性能 k/v 存储。
业界引擎使用Nvme的问题
lsm-tree 和 b-tree 是主要的单机存储引擎的架构。而在如今的高性能硬件中(Optane nvme-ssd / Optane pmem),cpu 将是这两种架构引擎的主要瓶颈。
CPU 会是 LSM-kv 存储的瓶颈
LSM 为了保证写性能,使用了Append-only,又为了不降低读性能,又维护了on磁盘的一个全序 k/v。所以需要compaction来解决 append-only 引入的key多版本问题 并且还需要继续维持全序结构。在KVell的测试中,在数据量足够大且key-range 重叠度较高的时候 compaction会消耗60%的cpu,而其中28% 消耗在归并排序,15% 消耗在创建index-filter/bloom filter, 剩下的才是I/O操作。所以,在LSM-tree中,因为compaction的存在,新型存储介质中 cpu是一定会先到瓶颈。
CPU 也会是 Btree-kv 存储的瓶颈
B+ 树的数据是存放在叶子节点,而且叶子结点是有序的,中间一般通过双向链表链接,加速scan性能。索引存放在中间节点,大多数场景下,叶子结点都会被持久化,索引节点会在内存中。为了加速读取,减少I/O操作,也会维护一个cache,Update操作会先写入commit-log,再写入到cache,cache会有自己的evict操作,来将脏数据刷盘。
在Wired-tiger中,实际测试插入的时候发现47%的cpu会被消耗在busy-wait,因为wired-tiger的写请求是需要全局递增的一个seq-num,而这个seq-num 会通过锁机制保证唯一性,因为其分配不够快,多线程竞争下很多cpu就处于非常消耗cpu的busy-wait了。
在wiredtiger的Update的过程中cpu需要调度后台的 cache-evict,大概消耗12%的cpu,commit-log大概是5%,只有25%的cpu是在处理i/o,剩下的cpu还是处于busy-wait 去竞争那个唯一的seq-number来维持全序。
综上可见,不论是LSM-tree 还是 B-tree 都在维护自己的全序结构 以及 某一个方面的高性能(lsm-tree的append-only 的write性能 以及 b-tree cache的读性能)的同时牺牲了大量的cpu,从而导致在新型存储介质中无法让 这一些硬件的性能完全发挥出来(无法让他们在大压力下时刻处于峰值qps状态),这确实是对新型硬件存储的不尊重。。。
KVell 设计亮点 及 总体架构实现
KVell 大体架构如下:

每一个workthread 都有一套自己独立的内存结构和磁盘结构,不同workthread之间的操作互不影响。
来来来,我们一起看看KVell的设计亮点,如何用最少的CPU 完全发挥出硬件存储的性能,让他们时刻都在绽放属于自己的峰值光芒。(fio能跑出来的稳定上限性能)
KVell 设计亮点
1. Share nothing
这里是说kvell 允许用户指定不同的work thread,每一个work thread 会绑定一个cpu-core 来单独处理一批ke y。线程内部空间独享存储的key相关的数据结构如下:
- 轻量级的内存索引。能够支持从内存索引一个key到对应的磁盘位置上。
- I/O队列。支持高效的读取请求和写入请求 到磁盘。
- free list。管理磁盘块的部分列表,包含用于存储k/v 的空闲位置。
- a pagecache。自实现了一个类似于操作系统的Pagecache缓存page,加速热点读性能,而不是依赖操作系统本身的pagecache。
这个 shared-nothing 的架构是KVell 和其他 k/v 存储主要的一个差异,它独享自己的数据结构,从而避免了多线程之间同步数据结构的开销,尤其是NUMA架构下的跨NUMA的内存访问,对于多线程下的内存操作的性能影响还是很大的。
2. Do not sorted on disk, but keep indexes in memory
每一个workthread 维护的磁盘存储数据集是无序的,这样能够完全释放之前的LSM / B-tree 为了维护有序的磁盘数据结构而产生的CPU开销。
3. Aim for fewer syscalls , not for sequential I/O
KVell 的操作都是随机I/O,因为 on -nvme的随机I/O和顺序I/O的性能差不多,这个时候不需要消耗额外的CPU去维护顺序I/O。和 LSM-tree 的k/v存储一样,kvell也提供batch操作,不过kvell的目的是为了减少系统调用的次数,尽可能得减少线程陷入内核的次数。
如果想要让磁盘的吞吐维持在他们的峰值qps,那就需要让磁盘支持的队列深度有足够多的可调度的请求,这个时候batch-size的大小设置就需要trade-off,一般是小于磁盘的最大队列深度,否则会导致请求的排队时间过长,增加长尾延时。所以KVell 调度过程的建议是每一个workthread 只操作一个磁盘,因为不同的workthread之间是独立处理请求的,他们之间并不能感知对底层磁盘队列深度的压力。
当然,多个workthread 操作同一个磁盘的时候,可能需要一个比较合理的batch-size 来进行压力上限的调整。在热点场景下(频繁调度一个workthread)的时候, 自实现的内部pagecache能够扛住大多数的读请求,从而一定程度得减少了系统调用的I/O操作。
4. No commit log
KVell 的更新完成是指持久化的磁盘,并更新了内存的索引之后才会返回,这样的话也就不需要WAL的参与了。一旦一个请求已经提交给当前的workthread,那它会在下一个bacth中持久化到磁盘。通过移除了commit log,能够更进一步得由用户请求独占磁盘带宽。
而且KVell 在磁盘上的更新是随机写入(update场景直接更新对应的slab-file),并不会有为了解决 append-only产生的多版本问题 而 引入compaction 操作,所以磁盘资源基本都贡献给了上层的用户请求。
KVell 详细架构及实现
1. Client SDK
- Update(K,V),当key-value被持久化到磁盘的时候才返回用户成功。
- Get(K),返回一个最新版本key 对应的value
- Scan(K1, K2),返回从K1到K2之间所有的keys-values.
2. 磁盘数据结构
KVell为了避免磁盘空间的碎片化,每一个写入的k/v请求都会按照其大小写入到不同的文件中,比如1K的kv对会写入到1K的文件中,200B的kv对会写入到专门存储200B的文件中。只不过最后的数据访问都是以磁盘page(一般的nvme-ssd默认是4K)为粒度进行访问的。
此时,如果访问的k/v数据是小于4K大小的,直接读对应的block即可,每一个item的存储都会有一个类似header的内容,包括这个item中的key-size,value-size 以及 key的timestamp,从而唯一标识一个key。这个timestamp 的好处除了支持snapshot/事物 之外 还可以在k/v数据大于4K的时候标识多个block属于当前k/v item。
3. 内存数据结构
因为索引结构都是在内存中,所以很明显的一个问题就是异常恢复的时候,需要扫描磁盘数据重建内存索引,这在数据量较大的时候会是分钟级别的重启时间。
3.1 index
通过上面的架构图可以看到,index是内存中的最上层。主要的作用是加速读场景下的数据索引,提升读性能。因为index不用持久化,所以可以做的很轻量,同时为了进一步支持Scan性能,Kvell的index 默认使用的是B-tree(高效的查找和scan)。
3.2 Page Cache
KVell维护了自己的page cache,采用的是LRU淘汰策略。支持缓存从磁盘中读上来的block,能够根据数据热度 加速热点场景的读性能,缩短读链路。关于这里使用 自实现的PageCache的原因如下:
多个workthread共享操作系统层级的page-cache会有I/O调度的性能问题,当page-cache发生缺页异常时,只能从一个磁盘调度读请求。而这里做成自实现的pagecache,在各自内部的workthread独享,则多个workthread可以同时读多个磁盘,这样能够完全利用整个操作系统的磁盘性能。
3.3 Free List
当一个k/v item从一个slab文件中删除之后,空闲的位置会被添加到free-list中,每一个slab文件会有一个对应的free-list,free-list的实现是双线链表。为了防止free-list占据内存过大,能够通过配置控制free-list最大缓存的空闲位置的个数。
Free-list的更新是按照队列的方式,从链表头部插入,链表尾部淘汰。
4. 高效的I/O调度
KVell 本身依赖linux 的aync I/O调度请求,每一次调度会batch 64个request一起进行调度,这个batch也可以自行配置。
Linux 本身除了AIO之外还有其他的I/O 调度方式:
- Mmap。这个调度本事会依赖os 的pagecache,对于KVell自实现的pagecache来说就没有必要了
- direct I/O。Direct I/O本身对性能不友好,无法使用cache进行加速。
这几种I/O 调度方式的性能对比如下:

可以看到,AIO在使用batch 方式调度请求的时候性能非常给力。
所以,KVell 高效调度I/O的优化策略如下:
自实现pagecache。这样的主要好处在前面介绍pagecache的时候已经说了,
a. 能够多个workthread独享page-cache,从而达到同时利用不同的磁盘I/O。
b. 同时,操作系统原生的pagecache在内存不足的时候会使用spinlock 进行页面的换出(防止其他线程读),这个锁代价在磁盘数据容量大于内存时会极大得消耗cpu资源。而自实现的pagecache因为是线程独享的,不需要这一些繁重的锁代价。
利用AIO + batch 调度请求。前面的性能表哥已经非常清晰得展示了AIO + batch得优势。之所以加batch是因为想要让磁盘繁忙起来,并时刻处于自己的峰值qps,则需要让磁盘待处理的请求的队列深度足够大(自己峰值qps时的队列深度即可)。而direct i/o 在一个workthread内部 一次只能处理一个,对磁盘来说此时的请求队列深度仅为1,远远无法发挥nvme磁盘的性能优势。
5. 请求调度的实现
5.1 Get
- Key hash到对应的workthread
- 读当前workthread的index(b-tree),确认key的value所在slab的page
- 读page-cache,如果这个page存在,则直接返回客户端
- 否则,将读请求放入到AIO 队列进行调度。
代码实现如下

5.2 Update
- 先读取取之前最新的key(从 index + page cache中读)
- 如果发现从index索引不到这个key,则这个update的key/value 是新的数据,直接通过AIO 调度写入
- 如果读到了,读上来的value大小和即将写入的value大小不匹配,则删除旧的item,将新的item写入到新的slab中。
- 如果读到了,value大小也匹配,则直接修改原地page-cache,并异步刷脏页。
- 如果page-cache没有读到,则调度AIO ,让Get请求入队进行后续的调度。
因为代码较长,大体的伪代码如下

5.3 Scan
Scan操作是KVell唯一一个需要跨不同的workthread的操作,大体就是根据输入的一批key,逐个进行Get操作,Get的话回hash到不同的workthread,当拿到对应的value之后会在多个workthread之间统一做一个聚合操作,返回一个value列表给用户。
6. 存在的问题
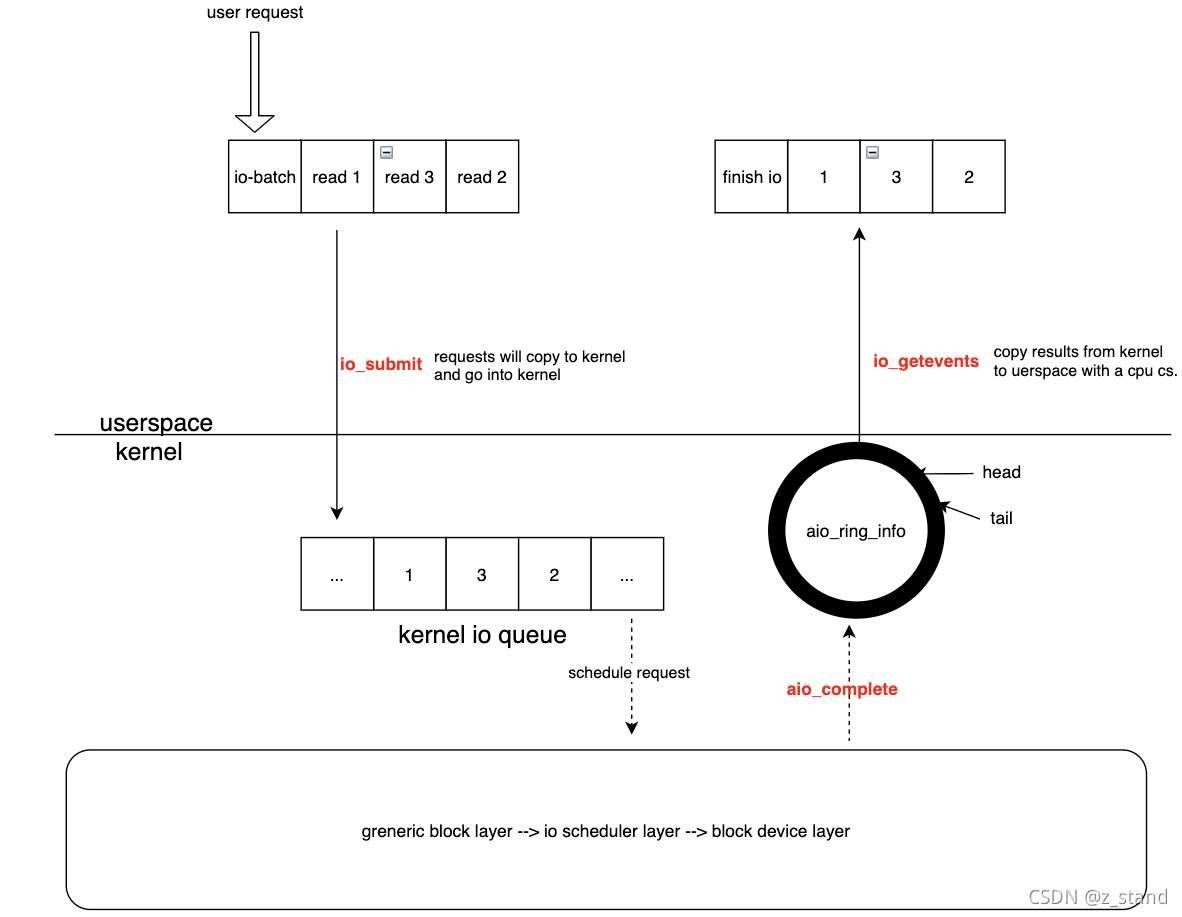
虽然说 KVell 能够从底向上考虑单机引擎的整体架构设计,也确实利用了AIO 能够发挥出底层存储硬件的性能上限,但是问题也很明显(这也是KVell 作者建议想要上生产环境的话需要长时间的稳定性测试),也就是AIO的问题:
- 对于分布式存储/数据库引擎来说,cache 的性能和稳定性 是一个至关重要的一部分。AIO 则直接让应用无法使用os的page-cache,这也就意味着开发者想要引入AIO,那就得花费更多的经历打磨自己cache的性能和稳定性了。
- 长尾问题。AIO 提交用户请求的时候 通过io_submit调用,收割用户请求的时候通过io_getevents,正常应用的时候每一个请求都意味着至少两次系统调用(I/O提交和I/O收割),对于一些延时敏感的应用并不友好(数据库)。
性能测试
kvell性能
kvell本身自实现了ycsdb的几种workload,压测也是调度它本身的用户接口进行的。
YCSB的A,B,C,E的读比例是通过如下代码进行控制的:

在本地的测试中,因为没法利用多个磁盘,就只使用了一个磁盘来进行测试,也就是多个worker操作同一块磁盘。
改了一下 slab-on-disk 的文件路径为当前磁盘路径:

运行性能测试:
./main 1 8 # 使用1个disk,8个workthread
硬件:64core 5218至强CPU + 256G内存 + 三星nvme-ssd 3T
软件:value大小是1024B
最终的性能结果如下:

对应的磁盘I/O 基本已经到带宽上限(如下是纯写的场景)

对应的CPU仅仅占用了12个core,其中四个是ycsb的压测core,剩下的八个是开了8个workthread的消耗。

最关键的是延时和吞吐非常稳定,使用了最少的CPU将磁盘性能发挥到了极限。总之很明显,(1KB的value-size下)Rocksdb是完全无法稳定跑这个性能的,感兴趣的同学可以使用db_bench压测rocksdb上限 中最后的配置来简单测试一波就知道了。
kvell本身 pagecache的压测
$ ./benchcomponents
#Reserving memory for page cache...
(page_cache_init,29) [ 1462ms] Page cache initialization
(bench_pagecache,21) [ 139ms] Filling the page cache: 786432 ops, 5627460 ops/s(bench_pagecache,30) [ 3023ms] Accessing existing pages 10000000 ops, 3307935 ops/s(bench_pagecache,39) [ 8624ms] Accessing non cached pages 10000000 ops, 1159494 ops/s
Kvell 内存索引的压测
adaptive radix tree的压测性能是优于btree的,但是之所以选择b-tree作为默认索引,应该还是考虑了scan性能的问题。这里的测试仅仅是数据结构的点查,并不包括scan。
$ ./microbench
(bench_data_structures,227) [ 9180ms] RBTREE - Time for 10000000 inserts/replace (1089267 inserts/s)
(bench_data_structures,234) [ 8907ms] RBTREE - Time for 10000000 finds (1122661 finds/s)
(bench_data_structures,236) [388 MB total - 385 MB since last measure] RBTREE
(bench_data_structures,251) [ 6779ms] RAX - Time for 10000000 inserts/replace (1475062 inserts/s)
(bench_data_structures,258) [ 4248ms] RAX - Time for 10000000 finds (2353730 finds/s)
(bench_data_structures,260) [1152 MB total - 764 MB since last measure] RAX
(bench_data_structures,276) [ 2959ms] ART - Time for 10000000 inserts/replace (3379450 inserts/s)
(bench_data_structures,283) [ 1277ms] ART - Time for 10000000 finds (7825283 finds/s)
(bench_data_structures,285) [1782 MB total - 629 MB since last measure] ART
(bench_data_structures,298) [ 5249ms] BTREE - Time for 10000000 inserts/replace (1905004 inserts/s)
(bench_data_structures,306) [ 4710ms] BTREE - Time for 10000000 finds (2122852 finds/s)
(bench_data_structures,308) [1990 MB total - 208 MB since last measure] BTREE
为microbech 补充了scan workload,可以看看ART 和 Btree在scan上的差异,随着scan长度的增大,差异会越来越明显
// 1. scan 10条key的时候
bench_data_structures,276) [ 3301ms] ART - Time for 10000000 inserts/replace (3029198 inserts/s)
(bench_data_structures,283) [ 1610ms] ART - Time for 10000000 finds (6208480 finds/s)
(bench_data_structures,290) [ 15984ms] ART - Time for 10000000 scan 10 (625586 scan/s)
(bench_data_structures,292) [4376 MB total - 3223 MB since last measure] ART(bench_data_structures,305) [ 5260ms] BTREE - Time for 10000000 inserts/replace (1900817 inserts/s)
(bench_data_structures,313) [ 4804ms] BTREE - Time for 10000000 finds (2081343 finds/s)
(bench_data_structures,320) [ 9307ms] BTREE - Time for 10000000 scan 10 (1074363 scan/s)
(bench_data_structures,322) [7178 MB total - 2802 MB since last measure] BTREE// 2. scan 50条key的时候
(bench_data_structures,276) [ 2835ms] ART - Time for 10000000 inserts/replace (3527024 inserts/s)
(bench_data_structures,283) [ 1262ms] ART - Time for 10000000 finds (7923384 finds/s)
(bench_data_structures,290) [ 54052ms] ART - Time for 10000000 scan 50 (185005 scan/s)
(bench_data_structures,292) [13531 MB total - 12379 MB since last measure] ART(bench_data_structures,305) [ 5176ms] BTREE - Time for 10000000 inserts/replace (1931987 inserts/s)
(bench_data_structures,313) [ 4605ms] BTREE - Time for 10000000 finds (2171451 finds/s)
(bench_data_structures,320) [ 22256ms] BTREE - Time for 10000000 scan 50 (449301 scan/s)
(bench_data_structures,322) [25489 MB total - 11957 MB since last measure] BTREE
相关文章:

android录像增加时间记录(源码里修改)
需要做一个功能,录像和播放时都显示录时的时间,参考文章链接找不到了,不好意思,这里记录一下,防止下次找不到了。另一篇关于源码录像的流程请参考 http://www.verydemo.com/demo_c131_i79000.html 在源码CameraSource.…
Java项目:在线旅游系统(java+jsp+SSM+Spring+mysql+maven)
源码获取:博客首页 "资源" 里下载! 一、项目简述 功能:用户的登录注册,旅游景点的展示,旅游预订,收藏,购买,以及酒店住宿留言等等,后台管理员,订单…
混合式APP开发中中间件方案Rexsee
发现Rexsee时,他已经一年多没有更新过了,最后版本是2012年的。 他的实现思路是通过Android自带的Java - Javascript 桥机制,在WebView中的JavaScript同Java进行通信,而这样的话即Javascript可以直接创建原生UI界面,以获…
vue 前端框架 (三)
VUE 生命周期 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><script type"text/javascript" src"js/vue.js"></script><link rel"stylesheet" type"te…
Rocksdb 的 MergeOperator 简单使用记录
本篇仅仅是一个记录 MergeOperator 的使用方式。 Rocksdb 使用MergeOperator 来代替Update 场景中的读改写操作,即用户的一个Update 操作需要调用rocksdb的 Get Put 接口才能完成。 而这种情况下会引入一些额外的读写放大,对于支持SQL这种update 频繁的…
Java项目:考试系统Java基础Gui(java+Gui)
源码获取:博客首页 "资源" 里下载! 功能简介: 所属课程、题目内容、题目选项、题目答案、题目等级、学生管理、试卷管理、题目管理、时间控制 服务页面: public class ServerClient extends javax.swing.JFrame {/** …

软件工程需求设计说明书
Java即时通聊天程序 设计需求说明书 专业班级: 计本班1202班 项目组成员: 杨宗坤 刘瑞 满亚洲 指导教师: 张利峰 开始日期: 完成日期: 编写目的: 本说明书是在充分理解系统需求分析…
Nagios 安装文档
安装前的装备工作(1)解决安装Nagios的依赖关系:Nagios基本组件的运行依赖于httpd、gcc和gd。可以通过以下命令来检查nagios所依赖的rpm包是否已经安装完成:#yum -y install httpd gcc glibc glibc-common *gd* php php-mysql mysql mysql-server --skip-…

Comprehensive Guide to build a Recommendation Engine from scratch (in Python) / 从0开始搭建推荐系统...
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-recommendation-engine-python/, 一篇详细的入门级的推荐系统的文章,这篇文章内容详实,格式漂亮,推荐给大家. 下面是翻译,翻译关注的是意思&#x…

关于std::string 在 并发场景下 __grow_by_and_replace free was not allocated 的异常问题
使用string时发现了一些坑。 我们知道stl 容器并不是线程安全的,所以在使用它们的过程中往往需要一些同步机制来保证并发场景下的同步更新。 应该踩的坑还是一个不拉的踩了进去,所以还是记录一下吧。 string作为一个容器,随着我们的append 或…

Java项目:银行管理系统+文档Java基础Gui(java+Gui)
源码获取:博客首页 "资源" 里下载! 功能介绍: 登录、打印、取款、改密、转账、查询、挂失、存款、退卡 服务模块: public class atmFrame extends JFrame {private JPanel contentPane;private user user; // private…

ie旋转滤镜Matrix
旋转一个元素算是一个比较常见的需求了吧,在支持CSS3的浏览器中可以使用transform很容易地实现,这里有介绍:http://www.css88.com/archives/2168,这里有演示http://www.css88.com/tool/css3Preview/Transform.html,就不…
音频(3):iPod Library Access Programming Guide:Introduction
NextIntroduction介绍iPod库访问(iPod Library Access)让应用程序可以播放用户的歌曲、有声书、和播客。这个API设计使得基本播放变得非常简单,同时也支持高级的搜索和播放控制功能。iPod library access 通过打开iOS允许的音乐相关的广阔范围…
【2019/4/30】周进度报告
冲刺可以推迟了,但这不妨碍知识储备(另外这周看了看梦断代码,感觉还是很有意思的一本书)。 第七周所花时间约9个小时代码量700多行,主要是阅读代码为主(框架内代码)博客量1篇了解到的知识点 1.y…

关于 智能指针 的线程安全问题
先说结论,智能指针都是非线程安全的。 多线程调度智能指针 这里案例使用的是shared_ptr,其他的unique_ptr或者weak_ptr的结果都是类似的,如下多线程调度代码: #include <memory> #include <thread> #include <v…

Java项目:无库版商品管理系统(java+Gui+文档)
源码获取:博客首页 "资源" 里下载! 功能介绍: 添加商品、修改商品、删除商品、进货出货、查看流水、注册 登录业务处理: public class LoginView extends JFrame implements ComponentListener{private JPanel center…
LTE QCI分类 QoS
http://blog.163.com/gzf_lte/blog/static/20840310620130140057204/ http://blog.163.com/gzf_lte/blog/static/208403106201301403652527/ http://blog.sina.com.cn/u/1731932381 lte2010 QCI (QoS Class Identifier)同时应用于GBR和Non-GBR承载。一个QCI是一个值࿰…
CSS 单行溢出文本只显示部分内容
.cc-item div { width:175px; text-overflow:clip; //该属性适用于IE6,IE7 max-width:175px; //该属性适用于IE8,FF,谷歌}
Audio声音
转载于:https://www.cnblogs.com/kubll/p/10799187.html

Rocksdb Ribbon Filter : 结合 XOR-filter 以及 高斯消元算法 实现的 高效filter
文章目录前言XOR-filter 实现原理xor filter 的构造原理xor filter 构造总结XOR-filter 和 ADD-filter对比XOR-filter 在计算上的优化Ribbon filter高斯消元法总结参考前言 还是起源于前几天的Rocksdb meetup,其中Peter C. Dillinger 这位大佬分享了自己为rocksdb实…

Java项目:无库版银行管理系统(java+Gui+文档)
源码获取:博客首页 "资源" 里下载! 功能介绍: 注册用户、编辑用户、删除用户、存取款、查看流水 存入业务处理: public class depositFrame extends JFrame {private JPanel contentPane;private JTextField inputFiel…
iptables-save和iptables-restore
iptables-save用来把当前的规则存入一个文件里以备iptables-restore使用。它的使用很简单,只有两个参数:iptables-save [-c] [-t table]参数-c的作用是保存包和字节计数器的值。这可以使我们在重启防火墙后不丢失对包和字节的统计。带-c参数的iptables-s…

代码之美——Doom3源代码赏析2
http://www.csdn.net/article/2013-01-17/2813778-the-beauty-of-doom3-source-code/2 摘要:Dyad作者、资深C工程师Shawn McGrathz在空闲时翻看了Doom3的源代码,发出了这样的惊叹:“这是我见过的最整洁、最优美的代码!”“Doom 3的…
什么是JavaBean
按着Sun公司的定义,JavaBean是一个可重复使用的软件组件。实际上JavaBean是一种Java类,通过封装属性和方法成为具有某种功能或者处理某个业务的对象,简称bean。由于javabean是基于java语言的,因此javabean不依赖平台,具…
关于 linux io_uring 性能测试 及其 实现原理的一些探索
文章目录先看看性能AIO 的基本实现io_ring 使用io_uring 基本接口liburing 的使用io_uring 非poll 模式下 的实现io_uring poll模式下的实现io_uring 在 rocksdb 中的应用总结参考先看看性能 io_uring 需要内核版本在5.1 及以上才支持,liburing的编译安装 很简单&am…

添加引用方式抛出和捕获干净的WebService异常
转载:http://www.cnblogs.com/ahdung/p/3953431.html 说明:【干净】指的是客户端在捕获WebService(下称WS)抛出的异常时,得到的ex.Message就是WS方法中抛出的异常消息,不含任何“杂质”。 前提:…
Java项目:车租赁管理系统(java+Gui+文档)
源码获取:博客首页 "资源" 里下载! 功能介绍: 登陆界面、管理员界面、用户界面、汽车租赁文档 系统主页: SuppressWarnings("serial") public class SystemMainView extends JFrame implements ActionListe…
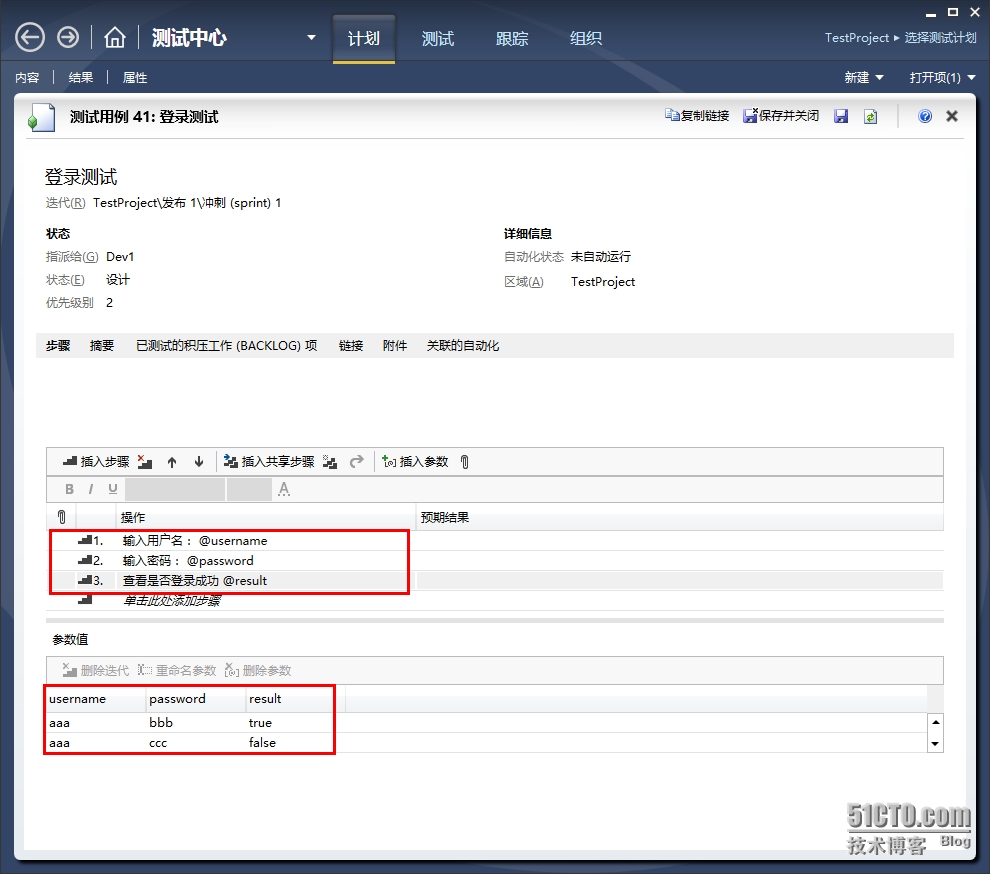
TFS中的测试计划(十)
现在有一个测试用例,用来测试登录,并且有两组测试数据。打开团队项目的web门户的测试。新建一个测试计划。命名为测试计划1添加完测试计划后,就可以向这个计划里添加测试用例了,选择登录测试。运行测试,就会生成下图左…

跟着Rocskdb 学 存储引擎:读写链路的代码极致优化
文章目录1. 读链路1.1 FileIndexer1.1.1 LevelDB sst查找实现1.1.2 Rocksdb FileIndexer实现1.2 PinnableSlice 减少内存拷贝1.3 Cache1.3.1 LRU Cache1.3.2 Clock Cache1.4 ThreadLocalPtr 线程私有存储1.4.1 version系统1.4.2 C thread_local vs ThreadLocalPtr1.4.3 ThreadL…

Java项目:人力管理系统(java+Gui+文档)
源码获取:博客首页 "资源" 里下载! 功能介绍: 角色员工、管理员,员工信息表,查询、更新,修改,移除、添加 用户管理控制层: /*** author yy*/Controller RequestMapping(…