Linux17-磁盘分区、文件系统、逻辑卷管理LVM
目录
一、磁盘分区、文件系统、永久挂载
1.1、MBR分区方案
1.2、使用fdisk、mkfs、partprobe、blkid、lsblk等命令管理MBR分区
1.3、swap分区
1.4、GPT分区方案、使用gdisk管理GPT分区
二、逻辑卷LVM(Logical Volume Management)
2.1、物理卷PV、卷组VG、逻辑卷LV
2.2、使用vgextend、lvextend、xfs_growfs、resize2fs扩展逻辑卷
2.3、虚拟机上使用pvresize扩充磁盘
一、磁盘分区、文件系统、永久挂载
磁盘分区可以将磁盘分为多个逻辑存储单元,这些单元称为分区。通过将磁盘划分为多个分区,系统管理员可以使用不同的分区执行不同的任务。主要有
MBR(Master Boot Recorder)分区方案,主引导记录分区方案。
GPT(GUID Partition Table)分区方案,全局唯一标识分区表分区方案。
1.1、MBR分区方案
由于历史原因MBR存在诸多限制。
MBR分区方案可以将磁盘分为主分区和扩展分区(合计不超过4个),扩展分区上再建立逻辑分区。
主分区+扩展分区 最多分4个分区,这是历史原因造成的。
因此,3个主分区 + 1个扩展分区 + 在扩展分区之上逻辑分区 = 最多15个分区。
由于分区大小数据以32位存储,每个块大小不超过512字节,单个分区和单块磁盘的大小不能超过2TB。
1.2、使用fdisk、mkfs、partprobe、blkid、lsblk等命令管理MBR分区
fdisk -l 查看分区表。fdisk /dev/vdb 键入m查看帮助。
fdisk /dev/vdb
Command (m for help): m
Command action
……m print this menu # 帮助菜单n add a new partition # 新建分区o create a new empty DOS partition tablep print the partition table # 列出分区q quit without saving changes # 退出不保存s create a new empty Sun disklabelt change a partition's system id # 修改分区类型,进入后键入L可以列出所有分区类型u change display/entry unitsv verify the partition tablew write table to disk and exit # 保存并退出x extra functionality (experts only)
分区的流程:fdisk分区→mkfs格式化xfs、ext4→mount挂载→写入/etc/fstab。
用fdisk给/dev/vdb建立2个主分区/dev/vdb1和/dev/vdb2、1个扩展分区/dev/vdb3。在扩展分区上建立几个逻辑分区,逻辑分区从/dev/vdb5开始。
fdisk建立分区,定义好分区大小和类型。
以相应的文件系统mkfs进行格式化。
运行partprobe命令,将磁盘设备作为参数,强制重新读取其分区表。
不要忘记写入/etc/fstab文件永久生效,使用blkid命令查看分区的UUID,因为UUID不会因重启而发生变化。查看/etc/fstab各字段含义直接man 5 fstab。
如果/etc/fstab内容错误可能导致系统无法启动。应使用mount -a读取/etc/fstab进行挂载,确认无误。
重新读取分区表
[root@server0 ~]# partprobe /dev/vdb列出所有分区
[root@server0 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 253:0 0 10G 0 disk
└─vda1 253:1 0 10G 0 part /
vdb 253:16 0 10G 0 disk
├─vdb1 253:17 0 2G 0 part
├─vdb2 253:18 0 2G 0 part
├─vdb3 253:19 0 1K 0 part
├─vdb5 253:21 0 100M 0 part
├─vdb6 253:22 0 100M 0 part
├─vdb7 253:23 0 100M 0 part
├─vdb8 253:24 0 100M 0 part
├─vdb9 253:25 0 100M 0 part
├─vdb10 253:26 0 100M 0 part
├─vdb11 253:27 0 100M 0 part
├─vdb12 253:28 0 100M 0 part
├─vdb13 253:29 0 100M 0 part
├─vdb14 253:30 0 100M 0 part
└─vdb15 253:31 0 100M 0 part创建文件系统
[root@server0 ~]# mkfs.xfs /dev/vdb1
[root@server0 ~]# mkfs.xfs /dev/vdb2
[root@server0 ~]# mkfs.xfs /dev/vdb5
[root@server0 ~]# mkfs.xfs /dev/vdb6读取分区UUID,用于挂载
[root@server0 ~]# blkid
/dev/vda1: UUID="9bf6b9f7-92ad-441b-848e-0257cbb883d1" TYPE="xfs"
/dev/vdb1: UUID="52038709-8194-4900-af39-521ccb528bdc" TYPE="xfs"
/dev/vdb2: UUID="4e40127c-7105-4806-948b-30e0a177dbd2" TYPE="xfs"
/dev/vdb5: UUID="dba17f96-198f-4383-9cb6-47c368a28108" TYPE="xfs"
/dev/vdb6: UUID="8b1bea51-f910-4cf2-8374-db5b0653a04b" TYPE="xfs"挂载点
[root@server0 ~]# mkdir /data_vdb{1,2,5,6}写入/etc/fstab
[root@server0 ~]# vim /etc/fstab
UUID=52038709-8194-4900-af39-521ccb528bdc /data_vdb1 xfs defaults 1 1
UUID=4e40127c-7105-4806-948b-30e0a177dbd2 /data_vdb2 xfs defaults 2 2
UUID=dba17f96-198f-4383-9cb6-47c368a28108 /data_vdb5 xfs defaults 3 3
UUID=8b1bea51-f910-4cf2-8374-db5b0653a04b /data_vdb6 xfs defaults 4 4使用mount -a读取/etc/fstab进行挂载
[root@server0 ~]# mount -a
[root@server0 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 253:0 0 10G 0 disk
└─vda1 253:1 0 10G 0 part /
vdb 253:16 0 10G 0 disk
├─vdb1 253:17 0 2G 0 part /data_vdb1
├─vdb2 253:18 0 2G 0 part /data_vdb2
├─vdb3 253:19 0 1K 0 part
├─vdb5 253:21 0 100M 0 part /data_vdb5
├─vdb6 253:22 0 100M 0 part /data_vdb6
├─vdb7 253:23 0 100M 0 part
├─vdb8 253:24 0 100M 0 part
├─vdb9 253:25 0 100M 0 part
├─vdb10 253:26 0 100M 0 part
├─vdb11 253:27 0 100M 0 part
├─vdb12 253:28 0 100M 0 part
├─vdb13 253:29 0 100M 0 part
├─vdb14 253:30 0 100M 0 part
└─vdb15 253:31 0 100M 0 part1.3、swap分区
linux特殊的一个分区swap分区,也就是交换分区。swap相当于windows虚拟内存。swap分区实际是内存的一个临时的补充,把暂时不用的数据写到swap上,把内存空间腾出来给其他程序使用。交换分区没有挂载点,mount和mount -a不适用于swap。
创建swap分区流程:fdisk→修改分区类型为82 Linux Swap→mkswap→swapon→/etc/fstab
[root@server0 ~]# partprobe /dev/vdb
[root@server0 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 253:0 0 10G 0 disk
└─vda1 253:1 0 10G 0 part /
vdb 253:16 0 10G 0 disk
├─vdb1 253:17 0 2G 0 part /data_vdb1
├─vdb2 253:18 0 2G 0 part /data_vdb2
├─vdb3 253:19 0 1K 0 part
├─vdb5 253:21 0 100M 0 part /data_vdb5
├─vdb6 253:22 0 100M 0 part /data_vdb6
└─vdb7 253:23 0 256M 0 part[root@server0 ~]# mkswap /dev/vdb7
Setting up swapspace version 1, size = 262140 KiB
no label, UUID=a77184ff-cb43-44cf-96f4-d445fc9f065f[root@server0 ~]# blkid
/dev/vda1: UUID="9bf6b9f7-92ad-441b-848e-0257cbb883d1" TYPE="xfs"
/dev/vdb1: UUID="52038709-8194-4900-af39-521ccb528bdc" TYPE="xfs"
/dev/vdb2: UUID="4e40127c-7105-4806-948b-30e0a177dbd2" TYPE="xfs"
/dev/vdb5: UUID="bcdc178e-d05b-4ad7-ab41-f40f9b12f22d" TYPE="xfs"
/dev/vdb6: UUID="43708e5f-f04b-4ccc-bf16-716d980d3764" TYPE="xfs"
/dev/vdb7: UUID="a77184ff-cb43-44cf-96f4-d445fc9f065f" TYPE="swap"[root@server0 ~]# vim /etc/fstab
UUID=a77184ff-cb43-44cf-96f4-d445fc9f065f swap swap defaults 0 0[root@server0 ~]# free -mtotal used free shared buffers cached
Mem: 1841 767 1073 16 2 287
-/+ buffers/cache: 478 1362
Swap: 0 0 0[root@server0 ~]# swapon /dev/vdb7[root@server0 ~]# free -mtotal used free shared buffers cached
Mem: 1841 768 1072 16 2 287
-/+ buffers/cache: 478 1362
Swap: 255 0 255
使用命令swapon -s可以看到swap分区的优先级。优先级越高,越优先使用这个分区。用户定义的优先级是正数,内核定义的优先级是负数。
[root@server0 ~]# swapon -s
Filename Type Size Used Priority
/dev/vdb7 partition 262140 0 -1
1.4、GPT分区方案、使用gdisk管理GPT分区
由于MBR方案有诸多限制,需要一个新的工具,这就是GPT。
GPT默认情况下支持最多128个分区,按照块大小不超过512字节计算,GPT支持8ZB分区和磁盘。
块大小转为4096字节计算,GPT支持64ZB分区和磁盘。
gdisk的用法和fdisk用法类似。
二、逻辑卷LVM(Logical Volume Management)
2.1、物理卷PV、卷组VG、逻辑卷LV
前面提到的MBR、GPT等分区方案实现的是静态的磁盘分区管理。有一种更牛逼的方式——动态磁盘:逻辑卷通过软件的方式来实现,让你的分区看似是活动的。
逻辑卷产生的三个过程PV VG LV
PV:物理卷,是构成LVM的最小化的最基本的单位pvcreate。
VG:把物理卷变成卷组的过程 vgcreate,PV + PV + PV …… = 虚拟的大磁盘 = VG。
LV:卷组,从VG上切蛋糕lvcreate,提供使用。
PE:物理区块,一个数据块的大小,LV管理数据的时候,是以PE为单位的,默认大小4M,用2的n次方。
创建和使用LVM的过程是:创建分区,修改分区类型为8e LVM类型→pvcreate创建物理卷→vgcreate创建卷组→lvcreate创建逻辑卷→mkfs文件系统→/etc/fstab和mount -a挂载。
举例
创建两个500M大小的物理卷/dev/vdb5和/dev/vdb6
将这两个物理卷组成卷组vg_data
从vg_data上切片一个300M大小的逻辑卷datafile和另一个400M大小的逻辑卷archivelog,注意-n选项指定逻辑卷名字,-L选项指定逻辑卷大小
[root@server0 ~]# fdisk /dev/vdbDevice Boot Start End Blocks Id System
/dev/vdb1 2048 20971519 10484736 5 Extended
/dev/vdb5 4096 1028095 512000 8e Linux LVM
/dev/vdb6 1030144 2054143 512000 8e Linux LVM[root@server0 ~]# pvcreate /dev/vdb5 /dev/vdb6Physical volume "/dev/vdb5" successfully createdPhysical volume "/dev/vdb6" successfully created
[root@server0 ~]# pvsPV VG Fmt Attr PSize PFree/dev/vdb5 lvm2 a-- 500.00m 500.00m/dev/vdb6 lvm2 a-- 500.00m 500.00m[root@server0 ~]# vgcreate vg_data /dev/vdb5 /dev/vdb6Volume group "vg_data" successfully created
[root@server0 ~]# vgsVG #PV #LV #SN Attr VSize VFreevg_data 2 0 0 wz--n- 992.00m 992.00m[root@server0 ~]# lvcreate -n datafile -L 300M vg_dataLogical volume "datafile" created
[root@server0 ~]# lvcreate -n archivelog -L 400M vg_dataLogical volume "archivelog" created
[root@server0 ~]# lvsLV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convertarchivelog vg_data -wi-a----- 400.00mdatafile vg_data -wi-a----- 300.00m[root@server0 ~]# mkfs.xfs /dev/vg_data/datafile
[root@server0 ~]# mkfs.xfs /dev/vg_data/archivelog
[root@server0 ~]# blkid
/dev/vda1: UUID="9bf6b9f7-92ad-441b-848e-0257cbb883d1" TYPE="xfs"
/dev/vdb5: UUID="8SrLUK-Dk3Y-uZqH-GWQv-3Q1s-3SEm-PmonIe" TYPE="LVM2_member"
/dev/vdb6: UUID="4lgBt3-TAqF-Yh0S-3Ta5-dFnZ-4mVb-e39f5B" TYPE="LVM2_member"
/dev/mapper/vg_data-datafile: UUID="51f84323-139d-44da-9c0f-c520b61cbdd2" TYPE="xfs"
/dev/mapper/vg_data-archivelog: UUID="46a29911-059c-48bb-8958-fa40b40b09f9" TYPE="xfs"[root@server0 ~]# mkdir /datafile /archivelog
[root@server0 ~]# vim /etc/fstab
UUID=51f84323-139d-44da-9c0f-c520b61cbdd2 /datafile xfs defaults 2 2
UUID=46a29911-059c-48bb-8958-fa40b40b09f9 /archivelog xfs defaults 3 3
[root@server0 ~]# mount -a
[root@server0 ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/vda1 xfs 10G 3.0G 7.1G 30% /
devtmpfs devtmpfs 906M 0 906M 0% /dev
tmpfs tmpfs 921M 80K 921M 1% /dev/shm
tmpfs tmpfs 921M 17M 904M 2% /run
tmpfs tmpfs 921M 0 921M 0% /sys/fs/cgroup
/dev/mapper/vg_data-datafile xfs 297M 16M 282M 6% /datafile
/dev/mapper/vg_data-archivelog xfs 397M 21M 377M 6% /archivelog
2.2、使用vgextend、lvextend、xfs_growfs、resize2fs扩展逻辑卷
如果存储空间不够了,就需要扩展。从PV、VG、LV到文件系统一层一层的扩展。
新建物理卷
[root@server0 ~]# pvcreate /dev/vdb7Physical volume "/dev/vdb7" successfully created
[root@server0 ~]# pvsPV VG Fmt Attr PSize PFree/dev/vdb5 vg_data lvm2 a-- 496.00m 196.00m/dev/vdb6 vg_data lvm2 a-- 496.00m 96.00m/dev/vdb7 lvm2 a-- 500.00m 500.00m
扩展卷组,将新的物理卷加入既有卷组。
[root@server0 ~]# vgextend vg_data /dev/vdb7Volume group "vg_data" successfully extended
[root@server0 ~]# vgsVG #PV #LV #SN Attr VSize VFreevg_data 3 2 0 wz--n- 1.45g 788.00m扩展逻辑卷,先扩展软件层,再扩展文件系统层。
lvextend -L +200M /dev/vg_data/datafile 扩大200M
lvextend -L 600M /dev/vg_data/archivelog 扩大到600M
[root@server0 ~]# lvsLV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convertarchivelog vg_data -wi-ao---- 400.00mdatafile vg_data -wi-ao---- 300.00m[root@server0 ~]# lvextend -L +200M /dev/vg_data/datafileExtending logical volume datafile to 500.00 MiBLogical volume datafile successfully resized
[root@server0 ~]# lvextend -L 600M /dev/vg_data/archivelogExtending logical volume archivelog to 600.00 MiBLogical volume archivelog successfully resized[root@server0 ~]# lvsLV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convertarchivelog vg_data -wi-ao---- 600.00mdatafile vg_data -wi-ao---- 500.00m扩展文件系统,这样才是真正把空间扩展了。
需要根据文件系统的类型来选择不同的命令
xfs_growfs /dev/vg_data/archivelog 适用于xfs
resize2fs /dev/vg0/lv0 适用于ext3/ext4
[root@server0 ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/vda1 xfs 10G 3.0G 7.1G 30% /
devtmpfs devtmpfs 906M 0 906M 0% /dev
tmpfs tmpfs 921M 80K 921M 1% /dev/shm
tmpfs tmpfs 921M 17M 904M 2% /run
tmpfs tmpfs 921M 0 921M 0% /sys/fs/cgroup
/dev/mapper/vg_data-datafile xfs 297M 16M 282M 6% /datafile
/dev/mapper/vg_data-archivelog xfs 397M 21M 377M 6% /archivelog[root@server0 ~]# xfs_growfs /dev/vg_data/datafile
[root@server0 ~]# xfs_growfs /dev/vg_data/archivelog[root@server0 ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/vda1 xfs 10G 3.0G 7.1G 30% /
devtmpfs devtmpfs 906M 0 906M 0% /dev
tmpfs tmpfs 921M 80K 921M 1% /dev/shm
tmpfs tmpfs 921M 17M 904M 2% /run
tmpfs tmpfs 921M 0 921M 0% /sys/fs/cgroup
/dev/mapper/vg_data-datafile xfs 497M 16M 482M 4% /datafile
/dev/mapper/vg_data-archivelog xfs 597M 21M 577M 4% /archivelog
2.3、虚拟机上使用pvresize扩充磁盘
虚拟机从模板上生成,因为模板的/dev/sdb只有50G,但是做出的虚拟机/dev/sdb磁盘是500G,怎么使用者500G呢?
用pvs、vgs、lvs查看,看到的/dev/sdb/、vg0、lv_data都是50G。
先扩充物理卷,物理卷扩充会让卷组自动扩充,再扩充逻辑卷,最后扩充文件系统。
pvresize /dev/sdb
pvs
vgs
lvextend -l +100%FREE /dev/vg0/lv_data
xfs_growfs /dev/vg0/lv_data
相关文章:

javascript基础 之 json
1,json是用于存储和传输的数据格式 全称:JSON 英文全称 JavaScript Object Notation json转化为javascript的规则: 数据为 键/值 对。数据由逗号分隔。大括号保存对象方括号保存数组<body> <p id"hehe"></p> <…
List常用方法总结 遍历集合的方法
List接口继承Collection接口,该接口属于数据结构中的线性结构,用户可以根据元素的整数索引来访问元素,换句话说就是List集合是按照存储的顺序保存的,且从0开始数,说白了就是就相当于一个数组,不同的是数组要…

ubuntu下载安装MaskRCNN-benchmark
在window下,配个环境,一堆错误,一周多都没解决。换到ubuntu下,不到一天就配好了 强烈建议直接去ubuntu下配置,千万别在window环境下配置。 一、下载anaconda,创建虚拟环境 下载anaconda的步骤读者可以去…

积跬步,聚小流------ps有用小技巧,改变png图标颜色
积跬步,聚小流------ps有用小技巧,改变png图标颜色 * 实现效果: 原图: 改动后: * 实现目的: 满足为实现不同界面色彩搭配改动png图标的颜色 * 实现方法: 1、打开Photoshop工具,导…
linux常用运维工具uptime、iostat、vmstat、sar
目录 一、uptime 二、iostat 三、vmstat 四、sar 一、uptime uptime可以告诉你系统已经运行了多久。uptime命令回显一行信息,包括:系统运行了多久,目前有多少用户在登录,过去1、5、15分钟系统平均负载。这些内容和命令w回显的…
《人类简史》八、融合统一(下)——宗教的法则、历史的混沌
在前面,我们说了金钱和帝国,今天我们聊一聊宗教。宗教的话题算是比较敏感的,必定很多人是拥有自己的宗教信仰的,如果在下面的论述过程之中,让您觉得有什么不妥的地方,还希望能够理解。我并没有贬低或者蔑视…
Set集合常用方法 遍历Set集合的方法
Set接口继承Collection接口,它与List集合有一个区别就是:List集合可以保存重复的数据,而Set集合不可以。Set接口有三个常用实现类: HashSet,特点: 它不按照存储的顺序保存,具有不确定性&#…
ubuntu下使用conda出现solving environment失败
更换anaconda的源(注意是anaconda的源,不是ubuntu的源) sudo gedit ./.condarc在出现的空文档中写入 channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free- htt…
centos8编译openssl-1.0.2u、openssl-1.1.1k
目录 一、给openssl-1.0.2u打包rpm 二、编译安装openssl-1.1.1k 三、给openssl-1.1.1k打包rpm(不推荐!) 近日openssl爆出拒绝服务、证书绕过漏洞,CVE编号CVE-2021-3449、CVE-2021-3450。 解决方法: CentOS7默认ope…
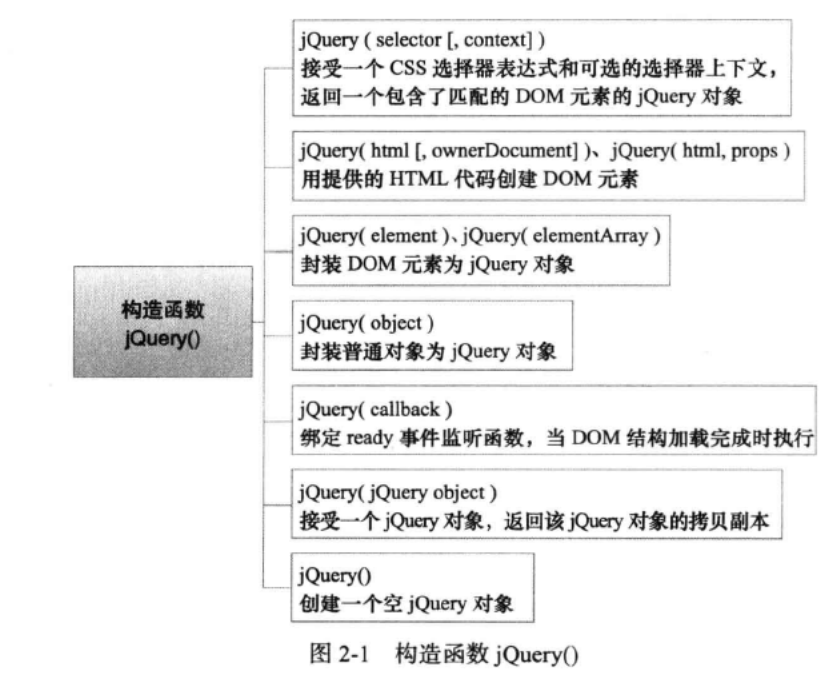
jquery 1.7.2源码解析(二)构造jquery对象
构造jquery对象 jQuery对象是一个类数组对象。 一)构造函数jQuery() 构造函数的7种用法: 1.jQuery(selector [, context ]) 传入字符串参数:检查该字符串是选择器表达式还是HTML代码。如果是选择器表达式,则遍历文档查找匹配的DOM元素&#x…
Map接口及其常用方法
Map集合基于键(key)和值(value)的映射,每个键只能映射一个值,也就是说key不可以重复(当然喽,重复的话就按最后一个为准)。键和值都可以是任何引用数据类型的值;且一对键值的存放是无序的。 Map常用的实现类…
C++计时函数
推荐使用chrono计时函数 #include<iostream> #include<vector> #include<algorithm> #include<chrono> using namespace std; class mycom { public:bool operator()(pair<int,int> p1,pair<int,int> p2){return p1.first < p2.first;…
最长递增子序列的两种解法
以LeetCode-300为例: O(n^2)解法: dp数组表示以i结尾的最长递增子序列的长度 class Solution { public:int lengthOfLIS(vector<int>& nums) {const int size nums.size();if (size 0) { return 0; } vector<int> dp(size, 1);int res…
【救援过程】升级openssl导致libcrypto.so.1.1动态库不可用
目录 一、故障重现 二、救援过程 一、故障重现 近日为了解决CVE-2021-3449: 拒绝服务漏洞、CVE-2021-3450: 证书校验漏洞,自己编译了openssl-1.1.1k。 亲测发现:只升级openssl的版本,动态库版本没有升级,系统可用。 升级openss…
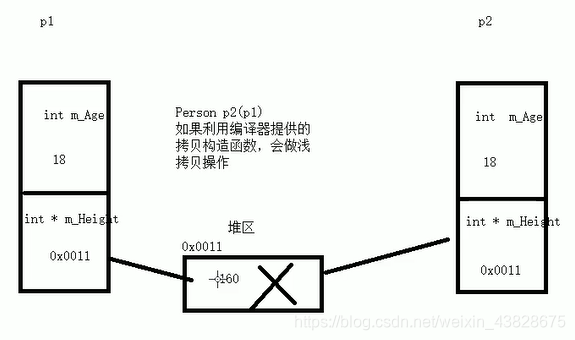
C++类class
一、定义 构造函数:在定义一个类对象时会自动调用,可用于实现一些功能,比如new一个内存。 构造函数,没有返回值也不写void函数名称与类名相同构造函数可以有参数,因此可以发生重载程序在调用对象时候会自动调用构造&…
pandas学习之Series结构
#!/usr/bin/env python # -*- coding:utf-8 -*- """ 系列(值的集合) DataFrame数据包(系列对象的集合) panel(数据文件对象的集合) 一个系列对象可以保存许多数据类型,包括 浮点数表示浮点数…
Java中的Map集合遍历总结(详尽版)
因为Map集合中的键值对排列无序,所以不能用传统的for循环来遍历,只能使用加强循环(for-each)和迭代器进行遍历。 让我们通过例子来了解Map集合的遍历: package gather; import java.util.HashMap; import java.util.Iterator; import java.…
Ansible01-Ansible基础和部署
目录 一、Ansible简介 二、安装部署Ansible 2.1、在控制节点安装ansible 2.2、对Linux和Unix受管节点要求 2.3、基于 Microsoft Windows 的受管主机 2.4、受管网络设备 三、Ansible配置文件 3.1、ansible.cfg配置文件推荐做法 3.2、ansible.cfg配置文件内容 四、Ansi…
C++/C文件读取
1、C文件操作 ofstream:写操作ifstream: 读操作fstream : 读写操作 打开方式解释ios::in为读文件而打开文件ios::out为写文件而打开文件ios::ate初始位置:文件尾ios::app追加方式写文件ios::trunc如果文件存在先删除,…
HashSet中的add()方法( 二 )(详尽版)
本篇接着上一篇:(详尽版)HashSet中的add()方法( 一 )(详尽版) 有些东西上一篇说过了,这里就不再赘述了,具体说一下再次添加与第一次添加的区别: import java.util.HashSet;public …
20155321 实验四 Android程序设计
20155321 实验四 Android程序设计 安装Android studio成功 任务一:Android Stuidio的安装测试: 参考《Java和Android开发学习指南(第二版)(EPUBIT,Java for Android 2nd)》第二十四章: 安装 Android Stuidio完成Hello World, 要求修改res目录…
Ansible02-实施playbook
一、编写和运行playbook 1.1、编写playbook play 是针对清单中选定的主机运行的一组有序任务。playbook 是一个文本文件,其中包含由一个或多个按特定顺序运行的 play 组成的列表。 playbook 是以 YAML 格式编写的文本文件,通常使用扩展名 .yml 保存。…
linux下解压缩文件中文乱码问题的解决
在windows上压缩的文件,是以系统默认编码中文来压缩文件。由于zip文件中没有声明其编码,所以linux上的unzip一般以默认编码解压,中文文件名会出现乱码。 虽然2005年就有人把这报告为bug, 但是info-zip的官方网站没有把自动识别编码列入计划&a…
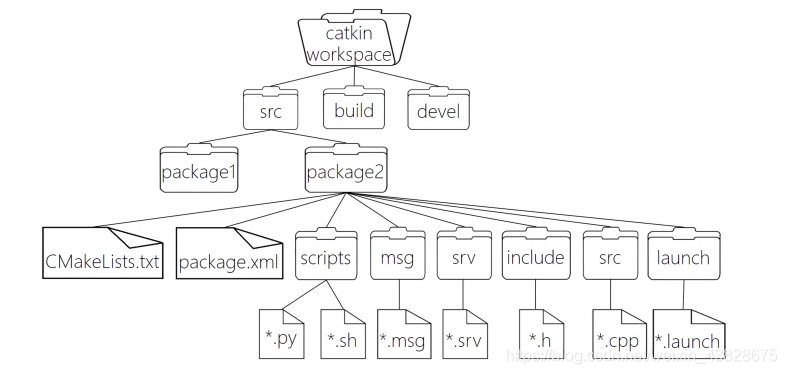
ROS知识点总结
1、ROS功能包的目录下不能有中文 2、 WorkSpace --- 自定义的工作空间|--- build:编译空间,用于存放CMake和catkin的缓存信息、配置信息和其他中间文件。|--- devel:开发空间,用于存放编译后生成的目标文件,包括头文件、动态&静态链接库…
Effective Java:对于全部对象都通用的方法
前言: 读这本书第1条规则的时候就感觉到这是一本非常好的书。可以把我们的Java功底提升一个档次,我还是比較推荐的。这里我主要就关于覆盖equals、hashCode和toString方法来做一个笔记总结。希望可以与君共勉。 概述: 这一章主要是说明一些对…
HashSet中的add()方法( 一 )(详尽版)
让我们用例子来理解add()方法的底层代码吧,Let’s go: import java.util.HashSet;public class Test {public static void main(String[] args) {HashSet<String> names new HashSet<String>();names.add("Jim");//向HashMap集合…
Ansible03-管理变量、加密、事实
目录 一、管理变量 1.1、变量的基本用法 1.2、使用已注册变量捕获命令输出 二、管理加密 2.1、ansible-vault常用场景 三、管理事实 3.1、事实基本用法 3.2、创建自定义事实 3.3、魔法变量hostvars、group_names、groups、inventory_hostname 一、管理变量 1.1、变量…
HashSet中的add()方法( 零 )(详尽版)
我们知道在使用HashSet集合时,也就是在用HashMap集合,这是因为HashSet的底层是HashMap, public HashSet() {map new HashMap<>(); }在详述HashSet中的add()方法之前,我们要知道HashMap中的hash,因为在add()的底…
layui上传图片接口
mvc中 前台调用接口 url:"../upload/uploadfiles/" 然后开始接口 代码: string a ""; try { HttpFileCollection file context.Request.Files;//获取选中的文件 for (int i 0; i < file.Count; i) { string cFileName Path.G…

shell与 .sh文件与 .bash文件
一、shell和bash shell是LInux系统下的解释器,类似于windows下的cmd。shell对用户输入到窗口中的命令行进行解释,输入到内核。 bash同样是Linux系统下的解释器,是bash的改进版。 二、.sh文件与.bash文件 .sh文件和.bash文件都是脚本文件&a…