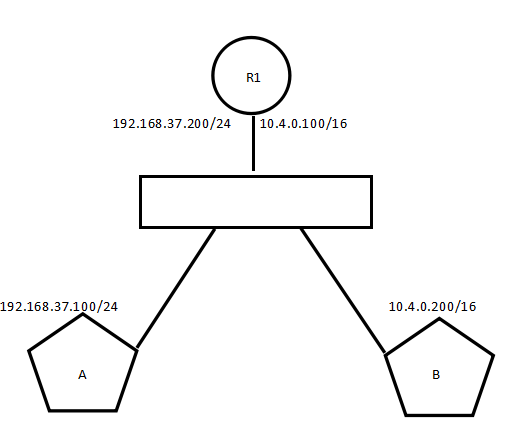
题目描述
在中国,很多人都把6和8视为是幸运数字!lxhgww也这样认为,于是他定义自己的“幸运号码”是十进制表示中只包含数字6和8的那些号码,比如68,666,888都是“幸运号码”!但是这种“幸运号码”总是太少了,比如在[1,100]的区间内就只有6个(6,8,66,68,86,88),于是他又定义了一种“近似幸运号码”。lxhgww规定,凡是“幸运号码”的倍数都是“近似幸运号码”,当然,任何的“幸运号码”也都是“近似幸运号码”,比如12,16,666都是“近似幸运号码”。 现在lxhgww想知道在一段闭区间[a, b]内,“近似幸运号码”的个数。
输入
输入数据是一行,包括2个数字a和b
输出
输出数据是一行,包括1个数字,表示在闭区间[a, b]内“近似幸运号码”的个数
样例输入
【样例输入1】
1 10
【样例输入2】
1234 4321
样例输出
【样例输出1】
2
【样例输出2】
809
题解
容斥原理+搜索
首先“幸运号码”最多只有$2^1+2^2+...+2^{10}$个,因此可以把它们预处理出来。
然后要统计的就是这些数中是某数倍数的数,可以考虑容斥,无限制的-必须是1个的倍数的+必须是2个的倍数的-...得到不符合条件的。
而$[1,n]$中$x$的倍数有$\lfloor\frac nx\rfloor$个,因此可以直接$O(1)$得出。
那么直接搜索+Lcm即可。
但是这样做会TLE,需要优化。
考虑:如果$x$是$y$的倍数,那么$x$对答案的贡献一定为0。因此可以先筛掉所有倍数,然后再dfs即可。
时间复杂度$O(玄学)=O(能过)$
由于求Lcm可能会爆long long,因此使用了long double。
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
typedef long long ll;
ll w[5000] , a , b , ans;
int n = -1;
bool cmp(ll a , ll b) {return a > b;}
void init(ll x)
{if(x > b) return;w[++n] = x;init(x * 10 + 6) , init(x * 10 + 8);
}
ll gcd(ll a , ll b)
{return b ? gcd(b , a % b) : a;
}
void calc(int p , long double now , int flag)
{if(now > b) return;ll t = now;long double tmp;ans += (b / t - a / t) * flag;int i;for(i = p + 1 ; i <= n ; i ++ )if((tmp = now * w[i] / gcd(t , w[i])) <= b)calc(i , tmp , -flag);
}
int main()
{int i , j;scanf("%lld%lld" , &a , &b) , a -- ;init(0);for(i = 1 ; i <= n ; i ++ )for(j = 1 ; j <= n ; j ++ )if(i != j && w[j] && w[i] % w[j] == 0)w[i] = 0;sort(w + 1 , w + n + 1 , cmp);for(n = 0 ; w[n + 1] ; n ++ );calc(0 , 1 , 1);printf("%lld\n" , b - a - ans);return 0;
}