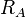一、SQL Interface
1.Select ... Where vs. Select + Check
用Select … Where语句效率比Select + Check语句要高,例如:
SELECT * FROM SBOOK INTO SBOOK_WA
WHERE CARRID = 'LH' AND
CONNID = '0400'.
ENDSELECT.
SELECT * FROM SBOOK INTO SBOOK_WA.
CHECK: SBOOK_WA-CARRID = 'LH' AND
SBOOK_WA-CONNID = '0400'.
ENDSELECT.
2.Test Existence
检查满足某个(些)条件的记录是否存在时,使用Select Single效率最高;例如:
SELECT SINGLE * FROM SBOOK
WHERE CARRID = 'LH'.
SELECT * FROM SBOOK INTO SBOOK_WA
WHERE CARRID = 'LH'.
EXIT.
ENDSELECT.
3.Select aggregates
需要对数据库某列求最大,最小,和,平均值或者记录数量时,请使用聚集函数来代替Select … Where + Check的方法,这样效率高而且网络流量小。
DATA: MAX_MSGNR type t100-msgnr.
SELECT MAX( MSGNR ) FROM T100 INTO max_msgnr
WHERE SPRSL = 'D' AND
ARBGB = '00'.
4.Select with select list
取数时请使用Select + 指定的列名称 into,而不要使用Select * into。显示的指定列名称只取出需要的列,不会像Select *会取出相应表的所有的列。
SELECT DOMNAME FROM DD01L
INTO DD01L_WA-DOMNAME
WHERE DOMNAME LIKE 'CHAR%'
AND AS4LOCAL = 'A'.
ENDSELECT.
SELECT * FROM DD01L INTO DD01L_WA
WHERE DOMNAME LIKE 'CHAR%'
AND AS4LOCAL = 'A'.
ENDSELECT.
5.Column Update
尽可能的使用字段(column updates)更新来代替行记录(single-row updates)更新数据库表,这样可以减少网络负载。
UPDATE SFLIGHT
SET SEATSOCC = SEATSOCC - 1.
6.Index and Buffer Support
6.1.Select with index support
Select语句在Where条件中尽量使用索引字段
6.2.Select with buffer support
对于最常用的只读的数据读取,使用SAP Buffering,不要使用BYPASSING BUFFER,例如:
SELECT SINGLE * FROM T100 INTO T100_WA
BYPASSING BUFFER
WHERE SPRSL = 'D'
AND ARBGB = '00'
AND MSGNR = '999'.
7.Array Operations (internal tables)
7.1.Select ... Into Table t
使用Into Table版本的Select 语句要比使用 Append 的方式速度更快,例如:
SELECT * FROM T006 INTO TABLE X006.
DATA T006_WA TYPE T006.
CLEAR X006.
SELECT * FROM T006 INTO T006_WA.
APPEND T006_WA TO X006.
ENDSELECT.
7.2.Array Insert VS Single-row Insert
向数据库中插入数据时,使用内表代替单行操作,减少应用服务与数据库的交互次数,能够有效地减少系统负荷。
INSERT CUSTOMERS FROM TABLE TAB.
LOOP AT TAB INTO TAB_WA.
INSERT INTO CUSTOMERS VALUES TAB_WA.
ENDLOOP.
7.3.Select-Endselect vs. Array-Select
对于只需要使用一次的数据,使用Select-Endselect-loop来代替Select Into Table。内表需要更多的内存空间。例如:
SELECT * FROM T006 INTO X006_WA.
ENDSELECT.
SELECT * FROM T006
INTO TABLE X006.
LOOP AT X006 INTO X006_WA.
ENDLOOP.
注:个人认为还是取出数据到内表的方式要好,牺牲存储空间,换取时间上的性能。
二、Context
1.Supply/Demand vs. SELECT
三、Internal Tables
1. Using explicit work areas(显示的使用工作区)
显示的指定工作区可以避免不必要的Move操作。见下列内表操作的语句:
APPEND wa TO itab. INSERT wa INTO itab. COLLECT wa INTO itab. MODIFY itab FROM wa. READ TABLE itab INTO wa. LOOP AT itab INTO wa.
ITAB = WA.
APPEND ITAB.
2.Linear search vs. binary search
如果内表的数据超过20条,由于线性检索会遍历整个内表,这将会非常耗时。将内表排序并使用Binary Search,或者使用SORTED TABLE类型的内表。如果内表有n条记录,线性查找的次数为O( n ),Binary Search的查找次数为O( log2( n ) ).
READ TABLE ITAB INTO WA WITH KEY K = 'X'
BINARY SEARCH.
READ TABLE ITAB INTO WA
WITH KEY K = 'X'.
3.Dynamic vs. static key access
动态键值的读取比静态键值的读取要慢,
READ TABLE ITAB INTO WA
WITH KEY K = 'X'.
READ TABLE ITAB INTO WA
WITH KEY (NAME) = 'X'.
4.Secondary indices
If you need to access an internal table with different keys repeatedly, keep your own secondary indices. With a secondary index, you can replace a linear search with a binary search plus an index access.
READ TABLE SEC_IDX INTO SEC_IDX_WA
WITH KEY DATE = SY-DATUM
BINARY SEARCH.
IF SY-SUBRC = 0.
READ TABLE ITAB INTO WA
INDEX SEC_IDX_WA-INDX.
" ...
ENDIF.
READ TABLE ITAB INTO WA
WITH KEY DATE = SY-DATUM.
IF SY-SUBRC = 0.
" ...
ENDIF.
5.Key access to multiple lines
LOOP ... WHERE比 LOOP/CHECK更快,因为LOOP ... WHERE只处理满足特定条件的数据。如果LOOP ... WHERE和FROM i1 and/or TO i2条件一起使用,性能会更好。
LOOP AT ITAB INTO WA WHERE K = 'X'.
" ...
ENDLOOP.
LOOP AT ITAB INTO WA.
CHECK WA-K = 'X'.
" ...
ENDLOOP.
6.Sorted and Hashed Tables
6.1.Single Read: Sorted vs. hashed tables
数据在SORTED TABLE类型的内表中按照Binary Search方式组织,检索数据的时间维度为(O (log n))。
数据在HASDED TABLE类型内表中按照hash-algorithm组织,检索数据的时间维度为(O (1))。
HASHED TABLE为单条记录的存取进行了优化,它没有索引(index),而SORTED TABLE优化为loop操作的部分顺序数据的存取。
DO 250 TIMES.
N = 4 * SY-INDEX.
READ TABLE HTAB INTO WA WITH TABLE KEY K = N.
IF SY-SUBRC = 0.
" ...
ENDIF.
ENDDO.
DO 250 TIMES.
N = 4 * SY-INDEX.
READ TABLE STAB INTO WA WITH KEY K = N.
IF SY-SUBRC = 0.
" ...
ENDIF.
ENDDO.
注:根据实测,Hashed Table的Read Table操作比Sorted Table + Binary Search大约快1倍。
6.2.Part. seq. access: Hashed vs. sorted
Hashed tables优化为单条记录的存取,数据在内表中没有特定的顺序,内表没有索引(sy-tabix),而且它必须是UNIQUE KEY。
SORTED TABLE内表中数据按照Key字段升序排序。
LOOP AT STAB INTO WA WHERE K = SUBKEY.
" ...
ENDLOOP.
LOOP AT HTAB INTO WA WHERE K = SUBKEY.
" ...
ENDLOOP.
7.Building unique standard tables(如何建立有唯一主键的标准内表)
如果内表的记录数量较少(<20),或者在填充内表的同时你需要访问它,那么使用Read/Insert比较合适。但是,如果你内表数据量很大,并且你只需要读取已经填充的内表,那么使用后面三步法。
REFRESH ITAB2.
LOOP AT ITAB1 INTO WA.
READ TABLE ITAB2 WITH KEY K = WA-K
BINARY SEARCH
TRANSPORTING NO FIELDS.
IF SY-SUBRC <> 0.
INSERT WA INTO ITAB2
INDEX SY-TABIX.
ENDIF.
ENDLOOP.
ITAB2[] = ITAB1[].
SORT ITAB2 BY K.
DELETE ADJACENT DUPLICATES FROM ITAB2
COMPARING K.
8.Building unique sorted/hashed tables
9.Modifying single lines
使用"MODIFY itab ... TRANSPORTING f1 f2 ..."语句更新一个内表的行可以提高效率,内表的table line越长,那么效率提高越多。该语句对于拥有复杂行类型的内表效率提升最明显。
WA-DATE = SY-DATUM.
MODIFY ITAB FROM WA INDEX 1.
WA-DATE = SY-DATUM.
MODIFY ITAB FROM WA INDEX 1 TRANSPORTING DATE.
10.Using the Assigning Comand
10.1.Modifying a set of lines directly(批量修改内表数据)
使用"LOOP ... ASSIGNING ..."可以直接修改内表中的数据,而不需要先将内表数据复制到相应工作区,然后再更新回去。
LOOP AT ITAB INTO WA.
I = SY-TABIX MOD 2.
IF I = 0.
WA-FLAG = 'X'.
MODIFY ITAB FROM WA.
ENDIF.
ENDLOOP.
Field-Symboles:<WA> like ITAB.
LOOP AT ITAB ASSIGNING <WA>.
I = SY-TABIX MOD 2.
IF I = 0.
<WA>-FLAG = 'X'.
ENDIF.
ENDLOOP.
10.2.Filling nested internal tables(填充嵌套的内表)
采用自底向上的策略填充嵌套内表,需要多付出很多次move操作的时间,嵌套中内部inner内表的内容会被moved到上一层的数据结构中。
相反,采用自顶向下的策略,首先填充外部outer内表,再采用"LOOP ... ASSIGNING"可以直接更新内部内表,这样,inner tables的内容只会被移动一次。
DO 50 TIMES.
CLEAR WA.
DO 10 TIMES.
APPEND N TO WA-INTTAB.
ADD 1 TO N.
ENDDO.
APPEND WA TO ITAB.
ENDDO.
DO 50 TIMES.
APPEND INITIAL LINE TO ITAB.
ENDDO.
LOOP AT ITAB ASSIGNING <F>.
DO 10 TIMES.
APPEND N TO <F>-INTTAB.
ADD 1 TO N.
ENDDO.
ENDLOOP.
11.Building condensed tables
COLLECT使用一种HASH算法,因此它不依赖内表的记录数而且不需要维护表索引sy-tabix,如果你需要最终的内表是排序的,那么在所有数据都Collect完以后再排序内表。
如果内表的记录数量较少,可以使用READ/INSERT的方法,也可以取得较好的效率,但是如果数据量大于1000,那么还是使用Collect效率更好些。
注意:在使用Collect填充一个内表时,不要混合使用其他操作内表的语句,例如 (APPEND, INSERT, MODIFY, SELECT * INTO TABLE and/or SELECT * APPENDING TABLE)。如果你将Collect与这些语句混合使用操作操作内表,那么Collect就不会使用HASH算法,在这种情况下,COLLECT会重新排序为一个普通的线性搜索,性能会显著的降低为O(n).
LOOP AT ITAB1 INTO WA1.
READ TABLE ITAB2 INTO WA2 WITH KEY K = WA1-K BINARY SEARCH.
IF SY-SUBRC = 0.
ADD: WA1-VAL1 TO WA2-VAL1,
WA1-VAL2 TO WA2-VAL2.
MODIFY ITAB2 FROM WA2 INDEX SY-TABIX TRANSPORTING VAL1 VAL2.
ELSE.
INSERT WA1 INTO ITAB2 INDEX SY-TABIX.
ENDIF.
ENDLOOP.
LOOP AT ITAB1 INTO WA.
COLLECT WA INTO ITAB2.
ENDLOOP.
SORT ITAB2 BY K.
12. Array Operations
12.1. Appending tables
使用"APPEND LINES OF itab1 TO itab2" 将itab1的所有行添加到内表itab2。
LOOP AT ITAB1 INTO WA.
APPEND WA TO ITAB2.
ENDLOOP.
APPEND LINES OF ITAB1 TO ITAB2.
12.2.Inserting tables
使用"INSERT LINES OF itab1 INTO itab2 INDEX idx" 语句将内表itab1从内表itab2的索引idx处插入。 I = 250.
LOOP AT ITAB1 INTO WA.
INSERT WA INTO ITAB2 INDEX I.
ADD 1 TO I.
ENDLOOP.
I = 250.
INSERT LINES OF ITAB1 INTO ITAB2
INDEX I.
12.3.Deleting duplicates(删除内表中重复的记录)
使用 "DELETE ADJACENT DUPLICATES" 语句删除重复记录。
READ TABLE ITAB INDEX 1 INTO PREV_LINE.
LOOP AT ITAB FROM 2 INTO WA.
IF WA = PREV_LINE.
DELETE ITAB.
ELSE.
PREV_LINE = WA.
ENDIF.
ENDLOOP.
DELETE ADJACENT DUPLICATES FROM ITAB
COMPARING K.
12.4.Deleting a sequence of lines(删除内表中连续的数据)
使用 "DELETE itab FROM ... TO ..." 删除一批连续数据。
DO 101 TIMES.
DELETE ITAB INDEX 450.
ENDDO.
DELETE ITAB FROM 450 TO 550.
12.5.Copying internal tables(内表复制)
内表可以像其他对象一样,使用MOVE语句进行内表的复制。
如果内表有Header Line,那么使用itab[]存取内表。
REFRESH ITAB2.
LOOP AT ITAB1 INTO WA.
APPEND WA TO ITAB2.
ENDLOOP.
ITAB2[] = ITAB1[].
12.6.Comparing internal tables(内表比较)
内表可以像其他对象一样在逻辑表达式中进行比较,如果两个内表相同,那么它们:
- 有相同的行记录数量
- 每对相应的行相同
如果内表有Header Line,那么可以使用itab[]方式访问内表本身。
DESCRIBE TABLE: ITAB1 LINES L1,
ITAB2 LINES L2.
IF L1 <> L2.
TAB_DIFFERENT = 'X'.
ELSE.
TAB_DIFFERENT = SPACE.
LOOP AT ITAB1 INTO WA1.
READ TABLE ITAB2 INTO WA2 INDEX SY-TABIX.
IF WA1 <> WA2.
TAB_DIFFERENT = 'X'. EXIT.
ENDIF.
ENDLOOP.
ENDIF.
IF TAB_DIFFERENT = SPACE.
" ...
ENDIF.
IF ITAB1[] = ITAB2[].
" ...
ENDIF.
13.Sorting internal tables
内表中指定的排序键限制越严格,程序运行得就越快。所以,尽可能的指定约束越多的排序键值。
SORT ITAB.
SORT ITAB BY K.
14.Simple Algorithms
14.1.Joining internal tables(内表连接Join)
如果ITAB1有n1条记录,ITAB2有n2条记录, 那么straightforward算法连接ITAB1和ITAB2需要O( n1 * log2( n2 ) )次运算,而parallel cursor approach仅需要O( n1 + n2 ) 次运算。 parallel cursor算法假定ITAB2为从表且只包含在主表ITAB1中才有的记录. If this assumption does not hold, the parallel cursor algorithm gets slightly more complicated, but its performance characteristics remain the same.
LOOP AT ITAB1 INTO WA1.
READ TABLE ITAB2 INTO WA2
WITH KEY K = WA1-K BINARY SEARCH.
IF SY-SUBRC = 0.
" ...
ENDIF.
ENDLOOP.
<Naive join>
DATA: I TYPE I.
I = 1.
LOOP AT ITAB1 INTO WA1.
READ TABLE ITAB2 INTO WA2 INDEX I.
IF SY-SUBRC <> 0. EXIT. ENDIF.
IF WA2-K = WA1-K.
" ...
ENDIF.
ENDLOOP.
注:经过本人测试,这段程序是错误的,不能成立,不知道正确的应该如何。
<More sophisticated: use parallel cursors>
14.2.Nested loops
如果ITAB1有n1条记录,ITAB2有n2条记录,那么嵌套loop的straightforward算法需要的时间为O(n1 * n2),而parallel cursor approach 需要的时间是O(n1 + n2).
parallel cursor算法假定 ITAB2仅包含ITAB1才有的记录。如果假定不成立, parallel cursor算法显得比较复杂,但是性能特性却保持不变。
LOOP AT ITAB1 INTO WA1.
LOOP AT ITAB2 INTO WA2
WHERE K = WA1-K.
" ...
ENDLOOP.
ENDLOOP.
<Straightforward nested loop>
I = 1.
LOOP AT ITAB1 INTO WA1.
LOOP AT ITAB2 INTO WA2 FROM I.
IF WA2-K <> WA1-K.
I = SY-TABIX.
EXIT.
ENDIF.
" ...
ENDLOOP.
ENDLOOP.
< More sophisticated loop: parallel cursors >
14.3.Intersection of internal tables
数据源表 ITAB1 和ITAB2都是STANDARD TABLES,假定ITAB1比ITAB2包含更多的记录。 否则,需要使用 "DESCRIBE TABLE ... LINES ..."语句计算内表包含的记录数。假定2个内表中的记录都遵从主键K唯一。
算法在计算中需要使用一个有唯一主键K的临时内表,该内表是ITAB1数据的复制,匹配的数据被复制到ITAB3,以下两个示例的区别在于临时内表分别为SORTED TABLE和HASHED TABLE,对于LOOP中的READ语句,HASHED TABLE比SORTED TABLE更快。
STAB1 = ITAB1.REFRESH ITAB3.
LOOP AT ITAB2 ASSIGNING <WA>.
READ TABLE STAB1 FROM <WA>
TRANSPORTING NO FIELDS.
IF SY-SUBRC = 0.
APPEND <WA> TO ITAB3.
ENDIF.
ENDLOOP.
FREE STAB1.
<Using a sorted table temporarily >
HTAB1 = ITAB1.
REFRESH ITAB3.
LOOP AT ITAB2 ASSIGNING <WA>.
READ TABLE HTAB1 FROM <WA>
TRANSPORTING NO FIELDS.
IF SY-SUBRC = 0.
APPEND <WA> TO ITAB3.
ENDIF.
ENDLOOP.
FREE HTAB1.
<Using a hashed table temporarily>
四、Typing
1.Typed vs. untyped Parameters<类型化与非类型化参数>
如果你在源程序中指定了参数的类型,那么ABAP/4编译器能够彻底的对代码进行优化。另外,使用错误顺序参数的风险更少。
PERFORM UP1 USING 10 M6-DIMID M6-ZAEHL M6-ISOCODE M6-ANDEC M6-PRIMARY.FORM UP1 USING
REPEAT
DIMID
ZAEHL
ISOCODE
ANDEC
PRIMARY.
* Identical source code left and right:
DO REPEAT TIMES.
T006_WA-DIMID = DIMID.
T006_WA-ZAEHL = ZAEHL.
T006_WA-ISOCODE = ISOCODE.
T006_WA-ANDEC = ANDEC.
T006_WA-PRIMARY = PRIMARY.
ENDDO.
ENDFORM.
PERFORM UP2 USING 10 M6-DIMID M6-ZAEHL M6-ISOCODE M6-ANDEC M6-PRIMARY.
FORM UP2 USING
REPEAT TYPE I
DIMID LIKE T006-DIMID
ZAEHL LIKE T006-ZAEHL
ISOCODE LIKE T006-ISOCODE
ANDEC LIKE T006-ANDEC
PRIMARY LIKE T006-PRIMARY.
* Identical source code left and right:
DO REPEAT TIMES.
T006_WA-DIMID = DIMID.
T006_WA-ZAEHL = ZAEHL.
T006_WA-ISOCODE = ISOCODE.
T006_WA-ANDEC = ANDEC.
T006_WA-PRIMARY = PRIMARY.
ENDDO.
ENDFORM.
2.Typed vs untyped Field-Symbols
如果你在源程序中指定了类型化的field-symbols,那么ABAP/4编译器能够更好的对代码进行优化
FIELD-SYMBOLS: <F> TYPE ANY.DATA: I1 TYPE I, I2 TYPE I.
ASSIGN I1 TO <F>.
I2 = <F>.
FIELD-SYMBOLS: <I> TYPE I.
DATA: I1 TYPE I, I2 TYPE I.
ASSIGN I1 TO <I>.
I2 = <I>.
五、If, Case……
1.If vs. Case
Case语句比IF语句更清晰并且稍微快些
2.Comparison of I and C
C和C类型比较 比 C与I比较的速度更快
3.While vs. Do
While语句比Do-Exit语句更容易理解,并且执行的更快
4.Case vs. Perform i Of ...
六、Field Conversion
1.Field Types I and P
在需要使用整数的时候(例如SY-TABIX)使用I类型
2.Literals Type C and Type I
3.Constants Type F
使用正确类型的常量.
DATA:
FLOAT TYPE F.
FLOAT = '3.1415926535897932'.
CONSTANTS:
PI TYPE F VALUE '3.1415926535897932'.
DATA:
FLOAT TYPE F.
FLOAT = PI.
4.Arithmetic
在算术运算的时候使用数字类型变量。类型N仅仅用在不需要计算的纯数字字符串中,例如:电话号码,日期或时间的部分内容。
DATA:
N1(15) TYPE N VALUE '123456789012345',
N2(15) TYPE N VALUE '543210987654321',
N3(15) TYPE N.
N3 = N1 + N2.
DATA:
P1 TYPE P VALUE '123456789012345',
P2 TYPE P VALUE '543210987654321',
P3 TYPE P.
P3 = P1 + P2.
5.Mixed Types
不要混合使用数据类型,除非绝对必要。
DATA: F1 TYPE I VALUE 2,
F2 TYPE P DECIMALS 2 VALUE '3.14',
F3 TYPE F.
F3 = F1 * F2.
DATA: F1 TYPE F VALUE 2,
F2 TYPE F VALUE '3.14',
F3 TYPE F.
F3 = F1 * F2.
七、Character/String Manipulation
1.fixed and unfixed length strings
字符串连接运算Concatenate需要扫描固定长度字符(fixed character fields)从第一个非空字符到最后。由于依赖于字符字段的长度,字符串string操作可能更快些。
*data c1(200) type c.
*data c2(200) type c.
*data c3(400) type c.
c1 = 'mysap'.
c2 = '.com'.
concatenate c1 c2 into c3.
*data string1 type string.
*data string2 type string.
*data string3 type string.
string1 = 'mysap'.
string2 = '.com'.
concatenate string1 string2 into string3.
八、ABAP Objects
1.Methods vs Subroutines
调用本地方法PERORM和调用本地子程序CALL性能上没有差异。
2.Methods vs Function Modules
调用全局类(Global Classes)比调用Function Modules要快
call function 'FUNCTION1'.
call method CL_PERFORMANCE_TEST=>M1.
3.Local Methods vs global Methods
调用全局方法不比调用本地方法要慢多少.
call method C1=>M1. “Local
call method CL_PERFORMANCE_TEST=>M1. “Global