朴素贝叶斯分类器详解及中文文本舆情分析(附代码实践)

参加 2018 AI开发者大会,请点击 ↑↑↑
作者 | 杨秀璋(笔名:Eastmount),贵州财经大学信息学院老师,硕士毕业于北京理工大学,主要研究方向是Web数据挖掘、知识图谱、Python数据分析、图像识别等。著有《Python网络数据爬取及分析从入门到精通》等书籍,五年来在CSDN原创近300篇文章、12个专栏。
本文主要讲述朴素贝叶斯分类算法并实现中文数据集的舆情分析案例,希望这篇文章对大家有所帮助,提供些思路。内容包括:
1.朴素贝叶斯数学原理知识
2.naive_bayes用法及简单案例
3.中文文本数据集预处理
4.朴素贝叶斯中文文本舆情分析
本篇文章为基础性文章,希望对你有所帮助,如果文章中存在错误或不足之处,还请海涵。同时,推荐大家阅读我以前的文章了解基础知识。
▌一. 朴素贝叶斯数学原理知识
该基础知识部分引用文章"机器学习之朴素贝叶斯(NB)分类算法与Python实现"(https://blog.csdn.net/moxigandashu/article/details/71480251),也强烈推荐大家阅读博主moxigandashu的文章,写得很好。同时作者也结合概率论讲解,提升下自己较差的数学。
朴素贝叶斯(Naive Bayesian)是基于贝叶斯定理和特征条件独立假设的分类方法,它通过特征计算分类的概率,选取概率大的情况,是基于概率论的一种机器学习分类(监督学习)方法,被广泛应用于情感分类领域的分类器。
下面简单回顾下概率论知识:
1.什么是基于概率论的方法?
通过概率来衡量事件发生的可能性。概率论和统计学是两个相反的概念,统计学是抽取部分样本统计来估算总体情况,而概率论是通过总体情况来估计单个事件或部分事情的发生情况。概率论需要已知数据去预测未知的事件。
例如,我们看到天气乌云密布,电闪雷鸣并阵阵狂风,在这样的天气特征(F)下,我们推断下雨的概率比不下雨的概率大,也就是p(下雨)>p(不下雨),所以认为待会儿会下雨,这个从经验上看对概率进行判断。而气象局通过多年长期积累的数据,经过计算,今天下雨的概率p(下雨)=85%、p(不下雨)=15%,同样的 p(下雨)>p(不下雨),因此今天的天气预报肯定预报下雨。这是通过一定的方法计算概率从而对下雨事件进行判断。
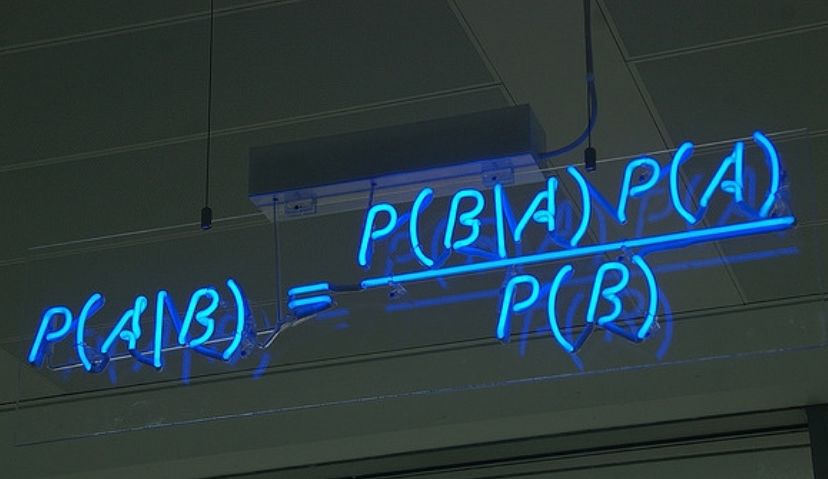
2.条件概率
若Ω是全集,A、B是其中的事件(子集),P表示事件发生的概率,则条件概率表示某个事件发生时另一个事件发生的概率。假设事件B发生后事件A发生的概率为:
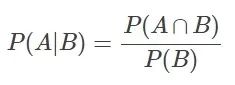
设P(A)>0,则有 P(AB) = P(B|A)P(A) = P(A|B)P(B)。
设A、B、C为事件,且P(AB)>0,则有 P(ABC) = P(A)P(B|A)P(C|AB)。
现在A和B是两个相互独立的事件,其相交概率为 P(A∩B) = P(A)P(B)。
3.全概率公式
设Ω为试验E的样本空间,A为E的事件,B1、B2、....、Bn为Ω的一个划分,且P(Bi)>0,其中i=1,2,...,n,则:

P(A) = P(AB1)+P(AB2)+...+P(ABn)
= P(A|B1)P(B1)+P(A|B2)P(B2)+...+P(A|Bn)P(Bn)
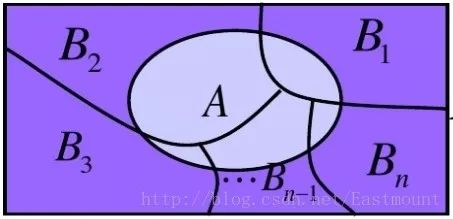
全概率公式主要用途在于它可以将一个复杂的概率计算问题,分解为若干个简单事件的概率计算问题,最后应用概率的可加性求出最终结果。
示例:有一批同一型号的产品,已知其中由一厂生成的占30%,二厂生成的占50%,三长生成的占20%,又知这三个厂的产品次品概率分别为2%、1%、1%,问这批产品中任取一件是次品的概率是多少?
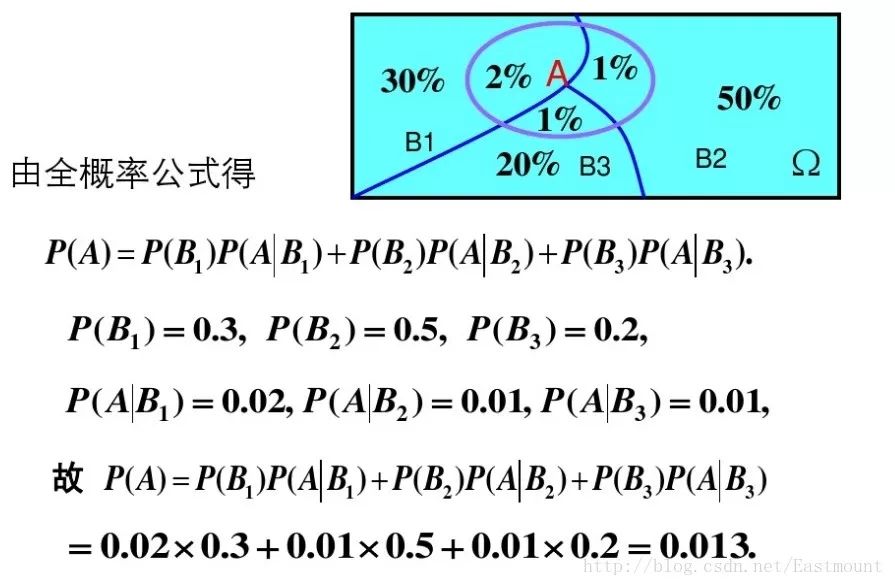
参考百度文库资料:
https://wenku.baidu.com/view/05d0e30e856a561253d36fdb.html
4.贝叶斯公式
设Ω为试验E的样本空间,A为E的事件,如果有k个互斥且有穷个事件,即B1、B2、....、Bk为Ω的一个划分,且P(B1)+P(B2)+...+P(Bk)=1,P(Bi)>0(i=1,2,...,k),则:
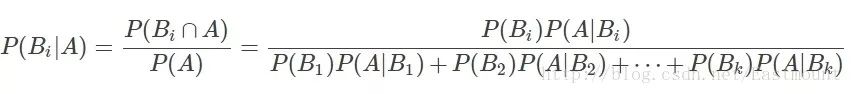
P(A):事件A发生的概率;
P(A∩B):事件A和事件B同时发生的概率;
P(A|B):事件A在时间B发生的条件下发生的概率;
意义:现在已知时间A确实已经发生,若要估计它是由原因Bi所导致的概率,则可用Bayes公式求出。
5.先验概率和后验概率
先验概率是由以往的数据分析得到的概率,泛指一类事物发生的概率,根据历史资料或主观判断未经证实所确定的概率。后验概率而是在得到信息之后再重新加以修正的概率,是某个特定条件下一个具体事物发生的概率。

6.朴素贝叶斯分类
贝叶斯分类器通过预测一个对象属于某个类别的概率,再预测其类别,是基于贝叶斯定理而构成出来的。在处理大规模数据集时,贝叶斯分类器表现出较高的分类准确性。
假设存在两种分类:
1) 如果p1(x,y)>p2(x,y),那么分入类别1
2) 如果p1(x,y)<p2(x,y),那么分入类别2
引入贝叶斯定理即为:
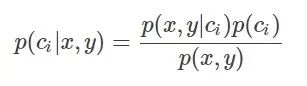
其中,x、y表示特征变量,ci表示分类,p(ci|x,y)表示在特征为x,y的情况下分入类别ci的概率,因此,结合条件概率和贝叶斯定理有:
1) 如果p(c1|x,y)>p(c2,|x,y),那么分类应当属于类别c1
2) 如果p(c1|x,y)<p(c2,|x,y),那么分类应当属于类别c2
贝叶斯定理最大的好处是可以用已知的概率去计算未知的概率,而如果仅仅是为了比较p(ci|x,y)和p(cj|x,y)的大小,只需要已知两个概率即可,分母相同,比较p(x,y|ci)p(ci)和p(x,y|cj)p(cj)即可。

7.示例讲解
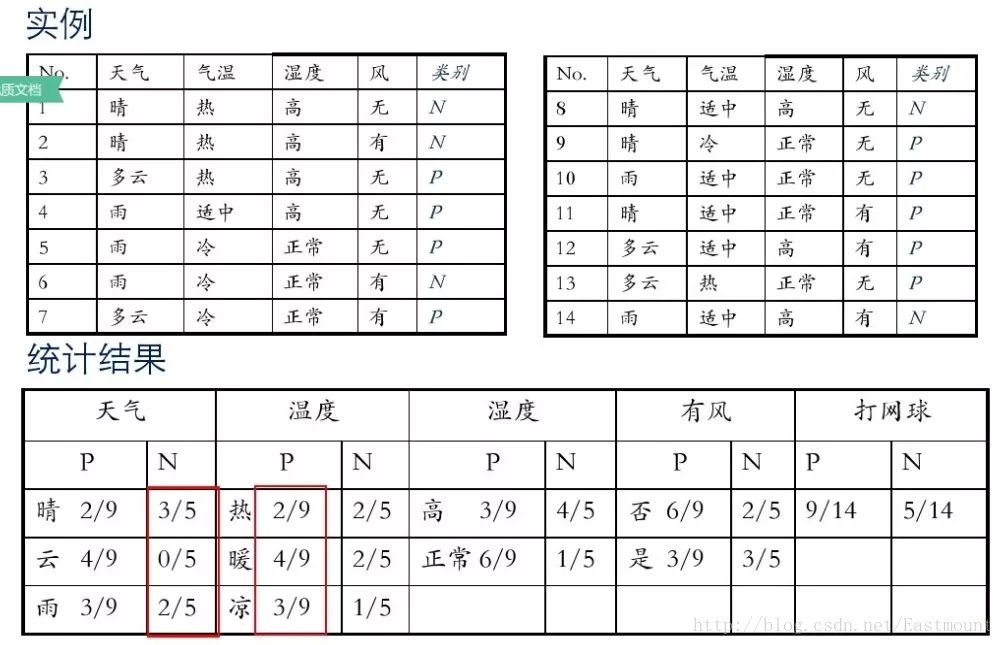
假设存在14天的天气情况和是否能打网球,包括天气、气温、湿度、风等,现在给出新的一天天气情况,需要判断我们这一天可以打网球吗?首先统计出各种天气情况下打网球的概率,如下图所示。
接下来是分析过程,其中包括打网球yse和不打网球no的计算方法。
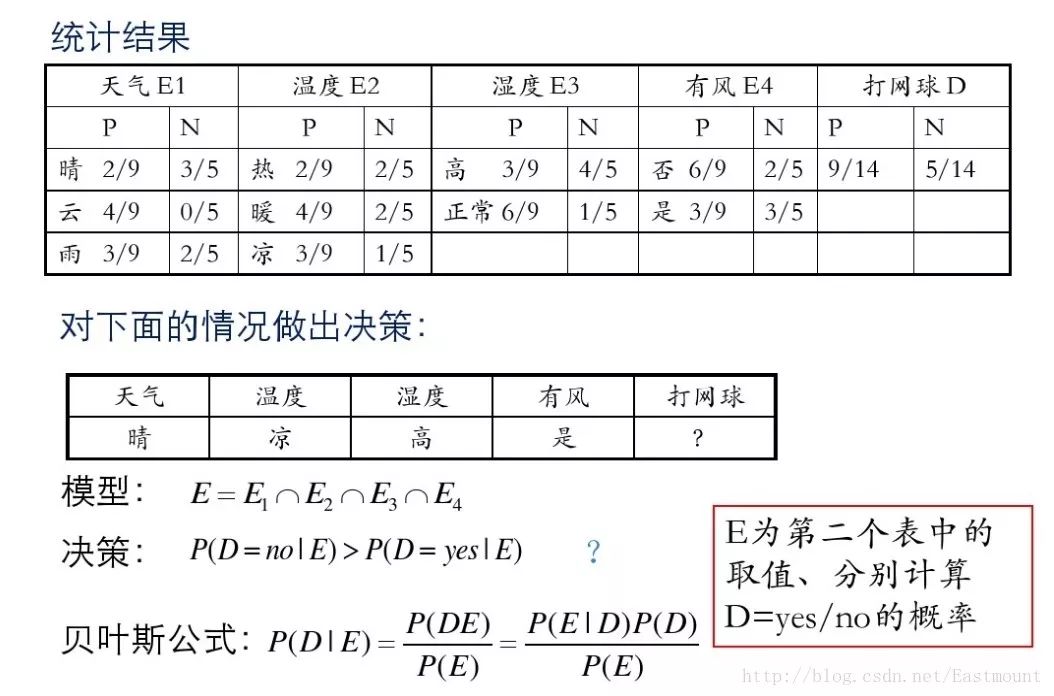
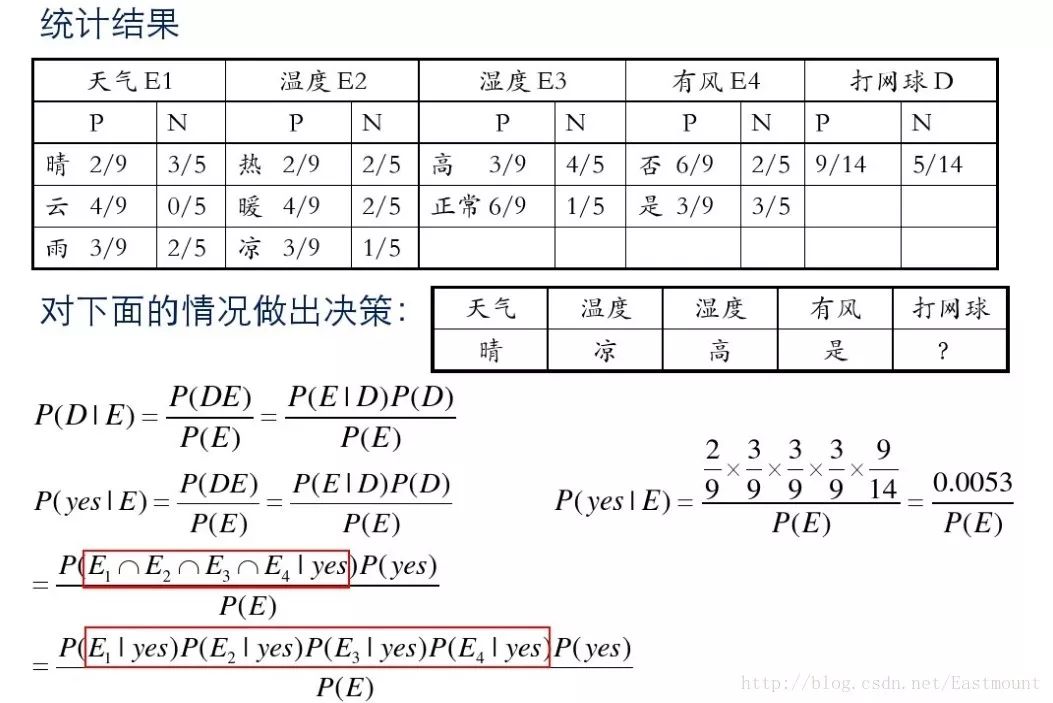
最后计算结果如下,不去打网球概率为79.5%。

8.优缺点
监督学习,需要确定分类的目标
对缺失数据不敏感,在数据较少的情况下依然可以使用该方法
可以处理多个类别 的分类问题
适用于标称型数据
对输入数据的形势比较敏感
由于用先验数据去预测分类,因此存在误差
▌二. naive_bayes用法及简单案例
scikit-learn机器学习包提供了3个朴素贝叶斯分类算法:
GaussianNB(高斯朴素贝叶斯)
MultinomialNB(多项式朴素贝叶斯)
BernoulliNB(伯努利朴素贝叶斯)
1.高斯朴素贝叶斯
调用方法为:sklearn.naive_bayes.GaussianNB(priors=None)。
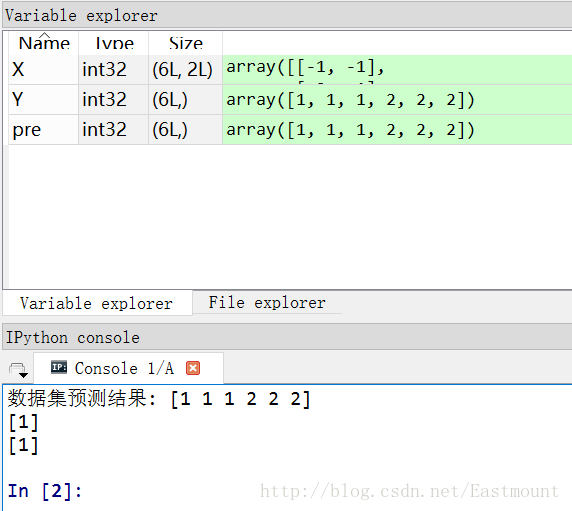
下面随机生成六个坐标点,其中x坐标和y坐标同为正数时对应类标为2,x坐标和y坐标同为负数时对应类标为1。通过高斯朴素贝叶斯分类分析的代码如下:
1# -*- coding: utf-8 -*-
2import numpy as np
3from sklearn.naive_bayes import GaussianNB
4X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
5Y = np.array([1, 1, 1, 2, 2, 2])
6clf = GaussianNB()
7clf.fit(X, Y)
8pre = clf.predict(X)
9print u"数据集预测结果:", pre
10print clf.predict([[-0.8, -1]])
11
12clf_pf = GaussianNB()
13clf_pf.partial_fit(X, Y, np.unique(Y)) #增加一部分样本
14print clf_pf.predict([[-0.8, -1]])
输出如下图所示,可以看到[-0.8, -1]预测结果为1类,即x坐标和y坐标同为负数。
2.多项式朴素贝叶斯
多项式朴素贝叶斯:sklearn.naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)主要用于离散特征分类,例如文本分类单词统计,以出现的次数作为特征值。
参数说明:alpha为可选项,默认1.0,添加拉普拉修/Lidstone平滑参数;fit_prior默认True,表示是否学习先验概率,参数为False表示所有类标记具有相同的先验概率;class_prior类似数组,数组大小为(n_classes,),默认None,类先验概率。
3.伯努利朴素贝叶斯
伯努利朴素贝叶斯:sklearn.naive_bayes.BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True,class_prior=None)。类似于多项式朴素贝叶斯,也主要用于离散特征分类,和MultinomialNB的区别是:MultinomialNB以出现的次数为特征值,BernoulliNB为二进制或布尔型特性
下面是朴素贝叶斯算法常见的属性和方法。
1) class_prior_属性
观察各类标记对应的先验概率,主要是class_prior_属性,返回数组。代码如下:
1print clf.class_prior_
2#[ 0.5 0.5]
2) class_count_属性
获取各类标记对应的训练样本数,代码如下:
1print clf.class_count_
2#[ 3. 3.]
3) theta_属性
获取各个类标记在各个特征上的均值,代码如下:
1print clf.theta_
2#[[-2. -1.33333333]
3# [ 2. 1.33333333]]
4) sigma_属性
获取各个类标记在各个特征上的方差,代码如下:
1print clf.theta_
2#[[-2. -1.33333333]
3# [ 2. 1.33333333]]
5) fit(X, y, sample_weight=None)
训练样本,X表示特征向量,y类标记,sample_weight表各样本权重数组。
1#设置样本不同的权重
2clf.fit(X,Y,np.array([0.05,0.05,0.1,0.1,0.1,0.2,0.2,0.2]))
3print clf
4print clf.theta_
5print clf.sigma_
输出结果如下所示:
1GaussianNB()
2[[-2.25 -1.5 ]
3 [ 2.25 1.5 ]]
4[[ 0.6875 0.25 ]
5 [ 0.6875 0.25 ]]
6) partial_fit(X, y, classes=None, sample_weight=None)
增量式训练,当训练数据集数据量非常大,不能一次性全部载入内存时,可以将数据集划分若干份,重复调用partial_fit在线学习模型参数,在第一次调用partial_fit函数时,必须制定classes参数,在随后的调用可以忽略。
1import numpy as np
2from sklearn.naive_bayes import GaussianNB
3X = np.array([[-1,-1], [-2,-2], [-3,-3], [-4,-4], [-5,-5],
4 [1,1], [2,2], [3,3]])
5y = np.array([1, 1, 1, 1, 1, 2, 2, 2])
6clf = GaussianNB()
7clf.partial_fit(X,y,classes=[1,2],
8 sample_weight=np.array([0.05,0.05,0.1,0.1,0.1,0.2,0.2,0.2]))
9print clf.class_prior_
10print clf.predict([[-6,-6],[4,5],[2,5]])
11print clf.predict_proba([[-6,-6],[4,5],[2,5]])
输出结果如下所示:
1[ 0.4 0.6]
2[1 2 2]
3[[ 1.00000000e+00 4.21207358e-40]
4 [ 1.12585521e-12 1.00000000e+00]
5 [ 8.73474886e-11 1.00000000e+00]]
可以看到点[-6,-6]预测结果为1,[4,5]预测结果为2,[2,5]预测结果为2。同时,predict_proba(X)输出测试样本在各个类标记预测概率值。
7) score(X, y, sample_weight=None)
返回测试样本映射到指定类标记上的得分或准确率。
1pre = clf.predict([[-6,-6],[4,5],[2,5]])
2print clf.score([[-6,-6],[4,5],[2,5]],pre)
3#1.0
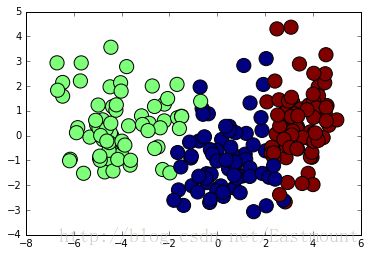
最后给出一个高斯朴素贝叶斯算法分析小麦数据集案例,代码如下:
1# -*- coding: utf-8 -*-
2#第一部分 载入数据集
3import pandas as pd
4X = pd.read_csv("seed_x.csv")
5Y = pd.read_csv("seed_y.csv")
6print X
7print Y
8
9#第二部分 导入模型
10from sklearn.naive_bayes import GaussianNB
11clf = GaussianNB()
12clf.fit(X, Y)
13pre = clf.predict(X)
14print u"数据集预测结果:", pre
15
16#第三部分 降维处理
17from sklearn.decomposition import PCA
18pca = PCA(n_components=2)
19newData = pca.fit_transform(X)
20print newData[:4]
21
22#第四部分 绘制图形
23import matplotlib.pyplot as plt
24L1 = [n[0] for n in newData]
25L2 = [n[1] for n in newData]
26plt.scatter(L1,L2,c=pre,s=200)
27plt.show()
输出如下图所示:
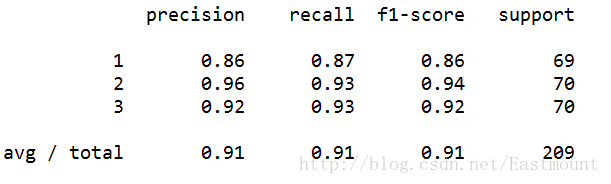
最后对数据集进行评估,主要调用sklearn.metrics类中classification_report函数实现的,代码如下:
1from sklearn.metrics import classification_report
2print(classification_report(Y, pre))
运行结果如下所示,准确率、召回率和F特征为91%。
补充下Sklearn机器学习包常用的扩展类。
1#监督学习
2sklearn.neighbors #近邻算法
3sklearn.svm #支持向量机
4sklearn.kernel_ridge #核-岭回归
5sklearn.discriminant_analysis #判别分析
6sklearn.linear_model #广义线性模型
7sklearn.ensemble #集成学习
8sklearn.tree #决策树
9sklearn.naive_bayes #朴素贝叶斯
10sklearn.cross_decomposition #交叉分解
11sklearn.gaussian_process #高斯过程
12sklearn.neural_network #神经网络
13sklearn.calibration #概率校准
14sklearn.isotonic #保守回归
15sklearn.feature_selection #特征选择
16sklearn.multiclass #多类多标签算法
17
18#无监督学习
19sklearn.decomposition #矩阵因子分解sklearn.cluster # 聚类
20sklearn.manifold # 流形学习
21sklearn.mixture # 高斯混合模型
22sklearn.neural_network # 无监督神经网络
23sklearn.covariance # 协方差估计
24
25#数据变换
26sklearn.feature_extraction # 特征提取sklearn.feature_selection # 特征选择
27sklearn.preprocessing # 预处理
28sklearn.random_projection # 随机投影
29sklearn.kernel_approximation # 核逼近
▌三. 中文文本数据集预处理
假设现在需要判断一封邮件是不是垃圾邮件,其步骤如下:
数据集拆分成单词,中文分词技术
计算句子中总共多少单词,确定词向量大小
句子中的单词转换成向量,BagofWordsVec
计算P(Ci),P(Ci|w)=P(w|Ci)P(Ci)/P(w),表示w特征出现时,该样本被分为Ci类的条件概率
判断P(w[i]C[0])和P(w[i]C[1])概率大小,两个集合中概率高的为分类类标
下面讲解一个具体的实例。
1.数据集读取
假设存在如下所示10条Python书籍订单评价信息,每条评价信息对应一个结果(好评和差评),如下图所示:
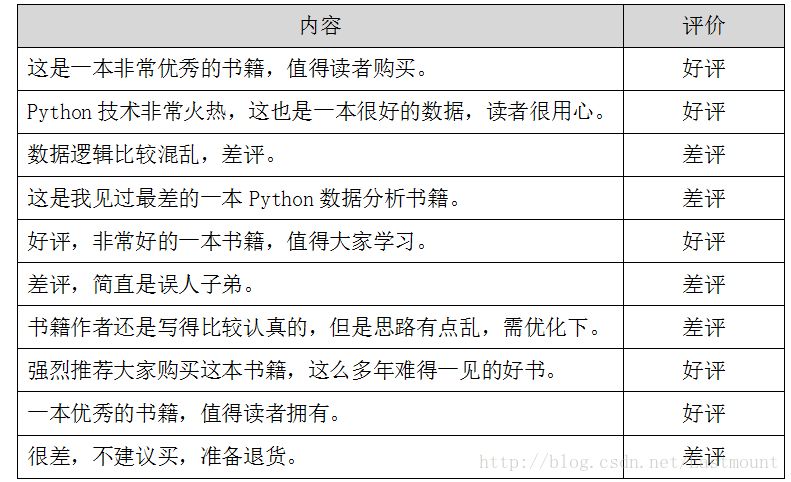
数据存储至CSV文件中,如下图所示。

下面采用pandas扩展包读取数据集。代码如下所示:
1# -*- coding: utf-8 -*-
2import numpy as np
3import pandas as pd
4
5data = pd.read_csv("data.csv",encoding='gbk')
6print data
7
8#取表中的第1列的所有值
9print u"获取第一列内容"
10col = data.iloc[:,0]
11#取表中所有值
12arrs = col.values
13for a in arrs:
14 print a
输出结果如下图所示,同时可以通过data.iloc[:,0]获取第一列的内容。

2.中文分词及过滤停用词
接下来作者采用jieba工具进行分词,并定义了停用词表,即:
stopwords = {}.fromkeys([',', '。', '!', '这', '我', '非常'])
完整代码如下所示:
1# -*- coding: utf-8 -*-
2import numpy as np
3import pandas as pd
4import jieba
5
6data = pd.read_csv("data.csv",encoding='gbk')
7print data
8
9#取表中的第1列的所有值
10print u"获取第一列内容"
11col = data.iloc[:,0]
12#取表中所有值
13arrs = col.values
14#去除停用词
15stopwords = {}.fromkeys([',', '。', '!', '这', '我', '非常'])
16
17print u"\n中文分词后结果:"
18for a in arrs:
19 #print a
20 seglist = jieba.cut(a,cut_all=False) #精确模式
21 final = ''
22 for seg in seglist:
23 seg = seg.encode('utf-8')
24 if seg not in stopwords: #不是停用词的保留
25 final += seg
26 seg_list = jieba.cut(final, cut_all=False)
27 output = ' '.join(list(seg_list)) #空格拼接
28 print output
然后分词后的数据如下所示,可以看到标点符号及“这”、“我”等词已经过滤。

3.词频统计
接下来需要将分词后的语句转换为向量的形式,这里使用CountVectorizer实现转换为词频。如果需要转换为TF-IDF值可以使用TfidfTransformer类。词频统计完整代码如下所示:
1# -*- coding: utf-8 -*-
2import numpy as np
3import pandas as pd
4import jieba
5
6data = pd.read_csv("data.csv",encoding='gbk')
7print data
8
9#取表中的第1列的所有值
10print u"获取第一列内容"
11col = data.iloc[:,0]
12#取表中所有值
13arrs = col.values
14#去除停用词
15stopwords = {}.fromkeys([',', '。', '!', '这', '我', '非常'])
16
17print u"\n中文分词后结果:"
18corpus = []
19for a in arrs:
20 #print a
21 seglist = jieba.cut(a,cut_all=False) #精确模式
22 final = ''
23 for seg in seglist:
24 seg = seg.encode('utf-8')
25 if seg not in stopwords: #不是停用词的保留
26 final += seg
27 seg_list = jieba.cut(final, cut_all=False)
28 output = ' '.join(list(seg_list)) #空格拼接
29 print output
30 corpus.append(output)
31
32#计算词频
33from sklearn.feature_extraction.text import CountVectorizer
34from sklearn.feature_extraction.text import TfidfTransformer
35
36vectorizer = CountVectorizer() #将文本中的词语转换为词频矩阵
37X = vectorizer.fit_transform(corpus) #计算个词语出现的次数
38word = vectorizer.get_feature_names() #获取词袋中所有文本关键词
39for w in word: #查看词频结果
40 print w,
41print ''
42print X.toarray()
输出结果如下所示,包括特征词及对应的10行数据的向量,这就将中文文本数据集转换为了数学向量的形式,接下来就是对应的数据分析了。
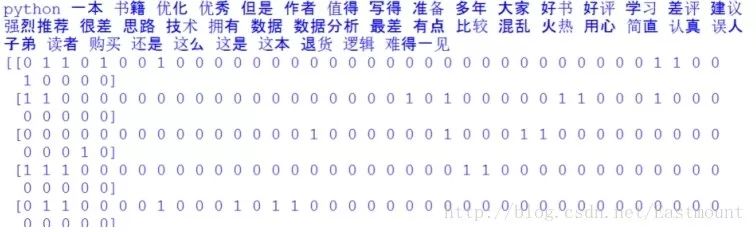
如下所示得到一个词频矩阵,每行数据集对应一个分类类标,可以预测新的文档属于哪一类。
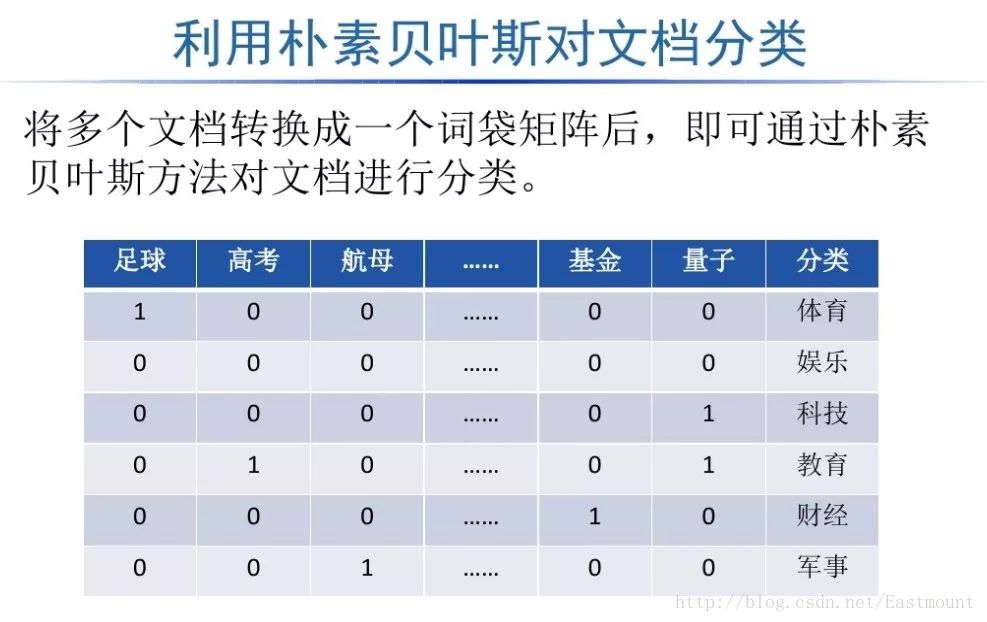
TF-IDF相关知识推荐我的文章: [python] 使用scikit-learn工具计算文本TF-IDF值(https://blog.csdn.net/eastmount/article/details/50323063)
▌四. 朴素贝叶斯中文文本舆情分析
最后给出朴素贝叶斯分类算法分析中文文本数据集的完整代码。
1# -*- coding: utf-8 -*-
2import numpy as np
3import pandas as pd
4import jieba
5
6#http://blog.csdn.net/eastmount/article/details/50323063
7#http://blog.csdn.net/eastmount/article/details/50256163
8#http://blog.csdn.net/lsldd/article/details/41542107
9
10####################################
11# 第一步 读取数据及分词
12#
13data = pd.read_csv("data.csv",encoding='gbk')
14print data
15
16#取表中的第1列的所有值
17print u"获取第一列内容"
18col = data.iloc[:,0]
19#取表中所有值
20arrs = col.values
21
22#去除停用词
23stopwords = {}.fromkeys([',', '。', '!', '这', '我', '非常'])
24
25print u"\n中文分词后结果:"
26corpus = []
27for a in arrs:
28 #print a
29 seglist = jieba.cut(a,cut_all=False) #精确模式
30 final = ''
31 for seg in seglist:
32 seg = seg.encode('utf-8')
33 if seg not in stopwords: #不是停用词的保留
34 final += seg
35 seg_list = jieba.cut(final, cut_all=False)
36 output = ' '.join(list(seg_list)) #空格拼接
37 print output
38 corpus.append(output)
39
40####################################
41# 第二步 计算词频
42#
43from sklearn.feature_extraction.text import CountVectorizer
44from sklearn.feature_extraction.text import TfidfTransformer
45
46vectorizer = CountVectorizer() #将文本中的词语转换为词频矩阵
47X = vectorizer.fit_transform(corpus) #计算个词语出现的次数
48word = vectorizer.get_feature_names() #获取词袋中所有文本关键词
49for w in word: #查看词频结果
50 print w,
51print ''
52print X.toarray()
53
54
55####################################
56# 第三步 数据分析
57#
58from sklearn.naive_bayes import MultinomialNB
59from sklearn.metrics import precision_recall_curve
60from sklearn.metrics import classification_report
61
62#使用前8行数据集进行训练,最后两行数据集用于预测
63print u"\n\n数据分析:"
64X = X.toarray()
65x_train = X[:8]
66x_test = X[8:]
67#1表示好评 0表示差评
68y_train = [1,1,0,0,1,0,0,1]
69y_test = [1,0]
70
71#调用MultinomialNB分类器
72clf = MultinomialNB().fit(x_train, y_train)
73pre = clf.predict(x_test)
74print u"预测结果:",pre
75print u"真实结果:",y_test
76
77from sklearn.metrics import classification_report
78print(classification_report(y_test, pre))
输出结果如下所示,可以看到预测的两个值都是正确的。即“一本优秀的书籍,值得读者拥有。”预测结果为好评(类标1),“很差,不建议买,准备退货。”结果为差评(类标0)。
1数据分析:
2预测结果: [1 0]
3真实结果: [1, 0]
4 precision recall f1-score support
5
6 0 1.00 1.00 1.00 1
7 1 1.00 1.00 1.00 1
8
9avg / total 1.00 1.00 1.00 2
但存在一个问题,由于数据量较小不具备代表性,而真实分析中会使用海量数据进行舆情分析,预测结果肯定页不是100%的正确,但是需要让实验结果尽可能的好。最后补充一段降维绘制图形的代码,如下:
1#降维绘制图形
2from sklearn.decomposition import PCA
3pca = PCA(n_components=2)
4newData = pca.fit_transform(X)
5print newData
6
7pre = clf.predict(X)
8Y = [1,1,0,0,1,0,0,1,1,0]
9import matplotlib.pyplot as plt
10L1 = [n[0] for n in newData]
11L2 = [n[1] for n in newData]
12plt.scatter(L1,L2,c=pre,s=200)
13plt.show()
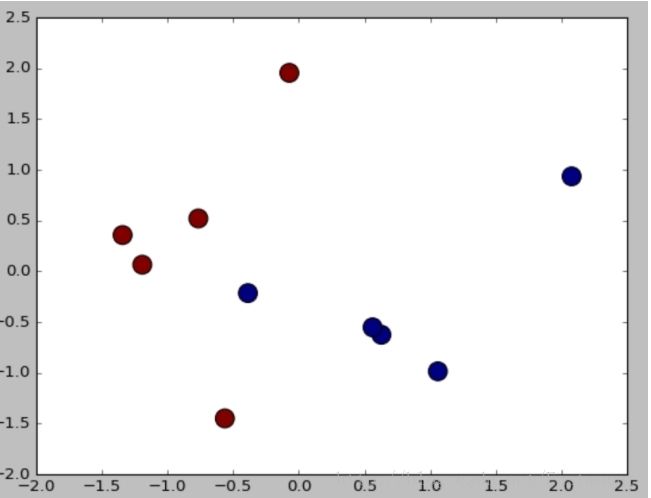
输出结果如图所示,预测结果和真实结果都是一样的,即[1,1,0,0,1,0,0,1,1,0]。
点击阅读全文,查看作者更多精彩文章
【完】
2018 AI开发者大会
◆
只讲技术,拒绝空谈
◆
2018 AI开发者大会是一场由中美人工智能技术高手联袂打造的AI技术与产业的年度盛会!是一场以技术落地为导向的干货会议!大会设置了10场技术专题论坛,力邀15+硅谷实力讲师团和80+AI领军企业技术核心人物,多位一线经验大咖带你将AI从云端落地。
大会日程以及嘉宾议题请查看下方海报
(点击查看大图)


相关文章:

计算机应用基础试题及答案试卷号7074,阅读文章,完成试题。后来才知道,在这千钧一发的时刻,是郝副营长划着了火柴,点燃了那本书,举得高高的, - 学进去中小学试卷试题库...
阅读《苏州园林》(节选),回答问题。苏州园林(节选)叶圣陶①苏州园林据说有一百多处,我到过的不过十多处。其他地方的园林我也到过一些。倘若要我说说总的印象,我觉得苏州园林是我国各地园林的标本。②设计者和匠师们因地制宜,自出…
解决“由于应用程序的配置不正确,应用程序未能启动,重新安装应用程序可能会纠正这个问题”...
[VS2005]解决“由于应用程序的配置不正确,应用程序未能启动,重新安装应用程序可能会纠正这个问题” 今天在准备发布用VS2005写的那个程序时,拷贝到我同事机器上,双击突然出现了“由于应用程序的配置不正确,应用程序未能…
PHP实时生成并下载超大数据量的EXCEL文件
最近接到一个需求,通过选择的时间段导出对应的用户访问日志到excel中, 由于用户量较大,经常会有导出50万加数据的情况。而常用的PHPexcel包需要把所有数据拿到后才能生成excel, 在面对生成超大数据量的excel文件时这显然是会造成内…
小学三年级上册计算机计划书,小学三年级班主任工作计划书
教学计划是教师个人制定的工作计划,通常为一个学期,内容主要包括制定教学计划的指导思想、教学内容以及教学目标,最重要的是每个教师要针对自己所带的学生特点来制定计划,因材施教才是对我们学生最好的教育.一、指导思想端正学习态…
10行代码爬取全国所有A股/港股/新三板上市公司信息
参加 2018 AI开发者大会,请点击 ↑↑↑作者 | 高级农民工本文已获原作者授权,如需转载,请联系原作者。摘要: 我们平常在浏览网页中会遇到一些表格型的数据信息,除了表格本身体现的内容以外,可能还想透过表格…
阿里云前端周刊 - 第 29 期
推荐 1. RESTful API 设计最佳实践 https://blog.philipphauer.de/... 项目资源的URL应该如何设计?用名词复数还是用名词单数?一个资源需要多少个URL?用哪种HTTP方法来创建一个新的资源?可选参数应该放在哪里?那些不涉…
Flash传值给asp页面
1.LoadVars的load方法-----在flash中写一个拉出两个动态文件框,变量名为myName与myPsd,拉出一组件button,名为:submit_button,用于提交,再拉出一T…
《深度学习500问》,川大优秀毕业生的诚意之作
前端工程师掌握这18招,就能在浏览器里玩转深度学习基于知识图谱的人机对话系统 | 公开课笔记来呀!AI喊你斗地主美团大脑:知识图谱的建模方法及其应用 | 公开课笔记60天,4位诺奖得主,他们将这样改造区块链程序员的江湖,务必掌握这些…

UC阿里鱼卡全网免流活动正在进行
UC&阿里鱼卡全网免流活动正在进行 优酷、虾米、高德、书旗应用专属流量免费 赠送100分钟国内通话、1G全国流量 扫码立即免费申请

普渡大学计算机硕士申请条件,普渡大学计算机与信息技术理学硕士研究生申请要求及申请材料要求清单...
2020年普渡大学计算机与信息技术理学硕士申请要求及普渡大学计算机与信息技术理学硕士申请材料要求清单是学生很感兴趣的问题,下面指南者留学整理2020年普渡大学计算机与信息技术理学硕士研究生申请要求及申请材料要求清单供大家参考。其中包括2020年普渡大学计算机…

object.ReferenceEquals(a,b)
code1 Assert.IsFalse(object.ReferenceEquals(10, 10));//比较时,要把比较的东西Box成Object,二个Ojbec地址是不一样的。 2 3 int value 10; 4 object one value; 5 object two value; 6 As…

深度文本匹配在智能客服中的应用
参加2018 AI开发者大会,请点击↑↑↑作者 | 云知声目录一. 深度文本匹配的简介1. 文本匹配的价值2. 深度文本匹配的优势3. 深度文本匹配的发展路线二. 智能客服的简介1. 智能客服的应用背景2. 智能客服的核心模块FAQ 库的构建语义召回相似度模型模型更新三. 深度文本…
计算机辅助焊接过程控制,重型车辆计算机辅助焊接工艺自动设计系统.pdf
金属学与金属工艺维普资讯第26卷 第10期 焊 接 学 报 v。1.26 N。.102005年 10月 TRANSACTIONSOFTHECHINAWELDINGINSTITUTION October 2005重型车辆计算机辅助焊接工艺 自动设计系统王克鸿, 韩 杰, 李 帅 王佳军(南京理工大学 材料…
Linux--文件管理以及权限的修改
一、文件属性查看ls -l filename 目录属性的大小(文件名的字符总和)-|rw-r--r--.|1| root| root| 46 |Oct 1 05:03 |filename— ————————— — ———— ———— —— ———————————— ———————— 1 …
Linux 之父归来!
参加2018 AI开发者大会,请点击↑↑↑作者 | 屠敏来源 | CSDN去修身养性的 Linux 之父 Linus Torvalds 在时隔一个余月后笑着归来,从曾临时接手 Linux 4.19 开发的稳定版维护者 Greg Kroah-Hartman 手中再次接过 Linux 内核开发的交接棒。这位向来天不怕地…
vscode断开调试服务器文件,vscode显示等待调试器断开连接
我正在尝试在vscode上调试量角器脚本。我编辑了launch.json文件,但是调试控制台抛出了下面的错误。vscode调试控制台输出:C:\Program Files\nodejs\node.exe --inspect-brk45448 conf.js C:\Users\abc\AppData\Roaming\npm\node_modules\protractor\example/conf.jsDebugger li…
深入理解Spring系列之六:bean初始化
《深入理解Spring系列之四:BeanDefinition装载前奏曲》中提到,对于非延迟单例bean的初始化在finishBeanFactoryInitialization(beanFactory)中完成。进入这个方法,代码如下。protected void finishBeanFactoryInitialization(ConfigurableLis…
webkit内核 css,纯CSS改变webkit内核浏览器的滚动条样式
基于webkit的浏览器现在可以自定义其滚动条的样式了,实现代码如下:复制代码代码如下:::-webkit-scrollbar/*整体部分*/{width: 10px;height:10px;}::-webkit-scrollbar-track/*滑动轨道*/{-webkit-box-shadow: inset 0 0 5px rgba(0,0,0,0.2);border-rad…

数据依赖症:当今AI领域的核心风险
在最近结束的2017年度AI星际争霸竞赛上,Facebook做出了一款人工智能“CherryPi”,参与到这项旨在让各路AI技术在星际争霸游戏中同场竞技的赛事之中。 但很遗憾的是,Facebook仅仅获得了赛事的第六名,最直接的原因,在于F…

1024程序员节,你是我们要找的那条锦鲤吗?
参加2018 AI开发者大会,请扫描海报二维码 叮咚,您有一封 #1024吐槽狂欢派对# 邀请函请查收。 ▌什么是程序员? 全员格子、黑框眼镜,还是等于创造力忍耐力? 刻板标签、思维定式,还是高阶自黑玩梗幽默&#…
虚拟机管理你的服务器,全面解析VMware的虚拟机管理解决方案
本教程将为你讲述VMware的虚拟机管理解决方案,说起虚拟机,VMware绝对可以算的上是个中翘楚了,并且VMware的虚拟桌面结构解决方案可以起到增强管理效率,降低成本等等效用,话不多说,这就为大家介绍。Vmware的…
针对抓win2003系统密码的诡计
命令行下卸载win2003 sp1/sp2 %systemroot%\$NtServicePackUninstall$\spuninst\spuninst /U 按无人参与模式删除 service pack。如果使用此选项,那么在卸载 SP1 的过程中,只有出现致命错误才会显示提示。 /Q 按安静模式删除 SP1,此模式与无人…

那个曾经为美国NASA开发火星大脑的AI公司,现在和华为合作了
2010 年,美国航天航空局 NASA 敲响了一家创业公司的大门,希望他们参与火星探测器“大脑”的研发项目。这家公司就是 Neurala,一家专注于深度学习技术的波士顿初创公司。 NASA 的要求是一个艰难的挑战,因为火星探测器自身计算能力…

艾伦人工智能研究院开源AllenNLP,基于PyTorch轻松构建NLP模型
艾伦人工智能研究院(AI2)开源AllenNLP,它是一个基于PyTorch的NLP研究库,利用深度学习来进行自然语言理解,通过处理低层次的细节、提供高质量的参考实现,能轻松快速地帮助研究员构建新的语言理解模型。 Alle…
3650服务器性能,全新联想System x3650 M4服务器性能出色
系统支持Microsoft Windows Server 2008 R2Microsoft Windows Server 2008,Datacenter x64 EditionMicrosoft Windows Server 2008,Datacenter x86 EditionMicrosoft Windows Server 2008,Enterprise x64 EditionMicrosoft Windows Server 20…

不只翻译机,搜狗将在半年内推数款智能硬件产品
10月24日已是昨日,但属于开发者的1024一直都在——2018 AI开发者大会就是你的1024。11月8-9日,现场聆听国内外AI大牛的深知灼见,与工业界AI应用思维紧密同步,收获60技术大咖的干货分享。扫码填写大会注册信息表,就有可…

Windows Embedded Standard开发初体验(四)
添加文件、依赖组件、注册表 接下来我们就要进入创建组件最重要的一环了,添加文件。为什么说重要,因为这里有一个大坑,我在Windows Embedded Standard产品组施卫娟老师的指导下,花了两周的时间才勉强爬出来,可见该坑之…

Windows 2003 + ISA 2006+单网卡×××配置(4)
(接上)图13 然后下一步,用户集默认所有用户,不用改变,直接下一步,完成,然后会出现如图14图14照样还是点击应用。。。好了,都配置完了,下面我们做个测试。。。我本机的IP地…

科大讯飞全新1024:3大计划,200项A.I.能力,全链路驱动应用场景创新!
10月24日,2018届科大讯飞全球1024开发者节在合肥奥林匹克体育中心综合馆如约举行,重磅发布了全新升级的科大讯飞《1024计划》!原中国科学技术部副部长张来武、科大讯飞董事长刘庆峰、科大讯飞轮值总裁胡郁、讯飞听见事业部总经理王玮分别发表…
SQL基本语句
掌握SQL四条最基本的数据操作语句:Insert,Select,Update和Delete。练掌握SQL是数据库用户的宝贵财 富。在本文中,我们将引导你掌握四条最基本的数据操作语句—SQL的核心功能—来依次介绍比较操作符、选择断言以及三值逻辑。当你完…