10行代码爬取全国所有A股/港股/新三板上市公司信息

参加 2018 AI开发者大会,请点击 ↑↑↑
作者 | 高级农民工
本文已获原作者授权,如需转载,请联系原作者。
摘要: 我们平常在浏览网页中会遇到一些表格型的数据信息,除了表格本身体现的内容以外,可能还想透过表格背后再挖掘些有意思或者有价值的信息。这时,可用python爬虫来实现。本文采用pandas库中的read_html方法来快速准确地抓取网页中的表格数据。
由于本文中含有一些超链接,微信中无法直接打开,所以建议复制链接到浏览器打开:
https://www.makcyun.top/web_scraping_withpython2.html
本文知识点:
Table型表格抓取
DataFrame.read_html函数使用
MySQL数据库存储
Navicat数据库的使用
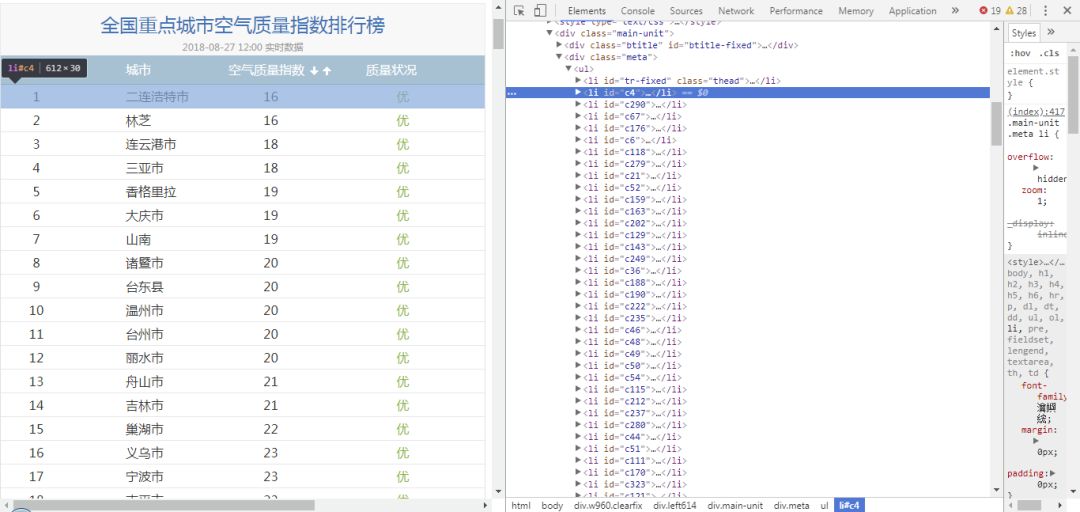
1. table型表格
我们在网页上会经常看到这样一些表格,比如:
QS2018世界大学排名:
财富世界500强企业排名:
IMDB世界电影票房排行榜:
中国A股上市公司信息:
它们除了都是表格以外,还一个共同点就是当点击右键-定位时,可以看到它们都是table类型的表格。
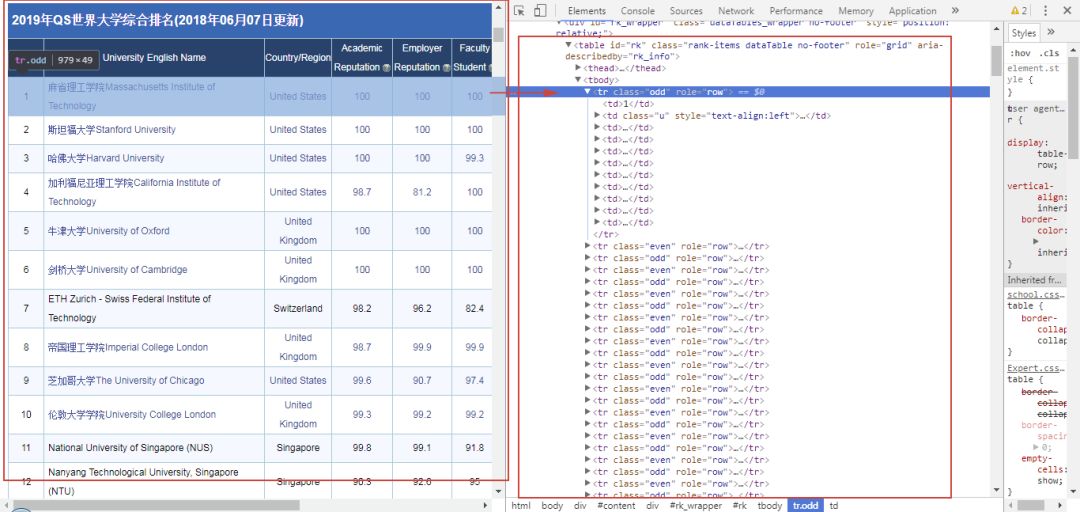
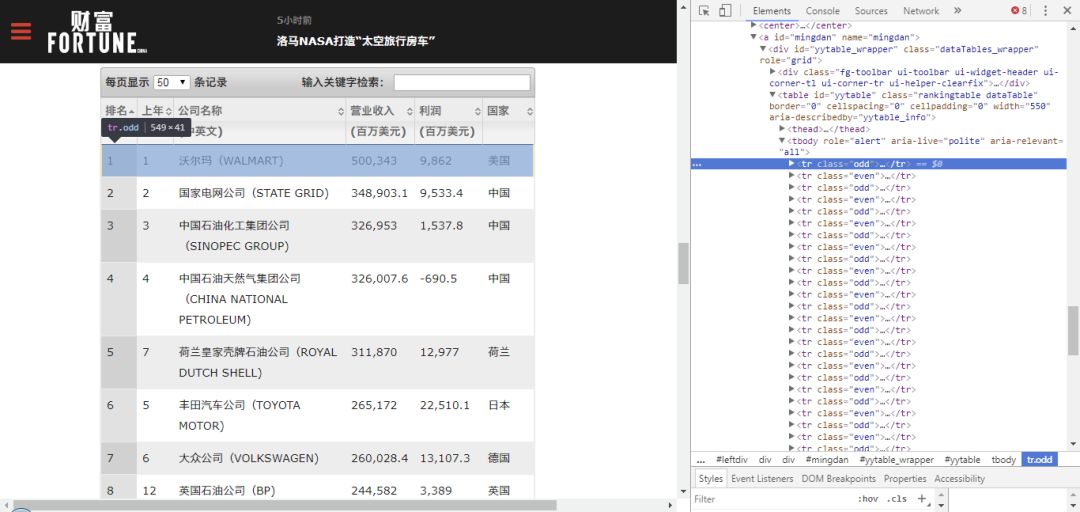
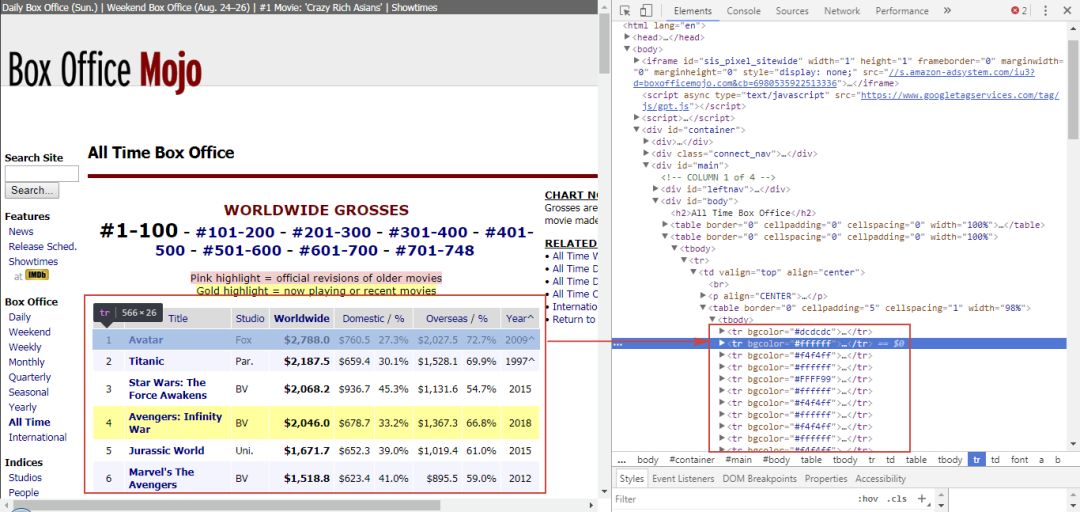
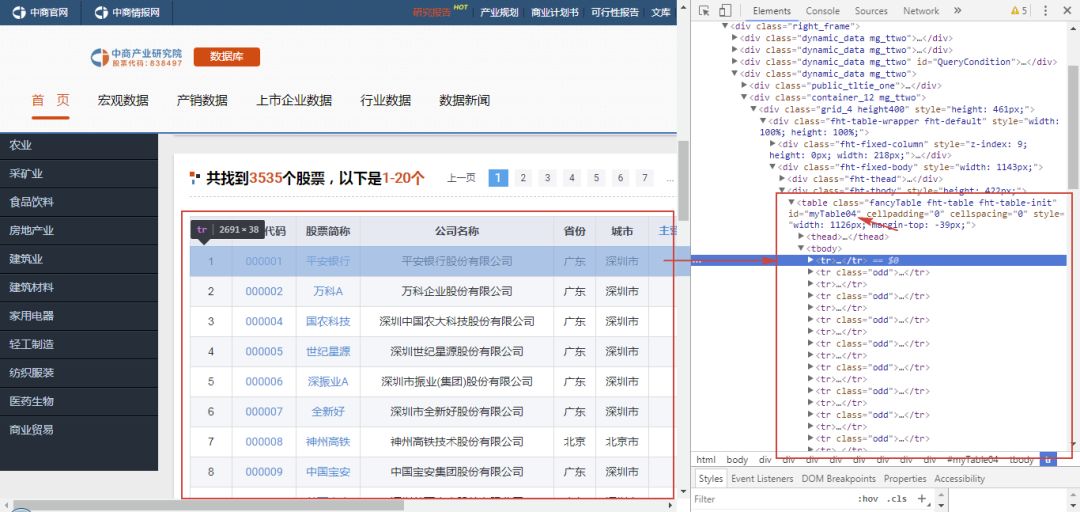
从中可以看到table类型的表格网页结构大致如下:
1<table class="..." id="...">
2 <thead>
3 <tr>
4 <th>...</th>
5 </tr>
6 </thead>
7 <tbody>
8 <tr>
9 <td>...</td>
10 </tr>
11 <tr>...</tr>
12 <tr>...</tr>
13 <tr>...</tr>
14 <tr>...</tr>
15 ...
16 <tr>...</tr>
17 <tr>...</tr>
18 <tr>...</tr>
19 <tr>...</tr>
20 </tbody>
21</table>
先来简单解释一下上文出现的几种标签含义:
1<table> : 定义表格
2<thead> : 定义表格的页眉
3<tbody> : 定义表格的主体
4<tr> : 定义表格的行
5<th> : 定义表格的表头
6<td> : 定义表格单元
这样的表格数据,就可以利用pandas模块里的read_html函数方便快捷地抓取下来。下面我们就来操作一下。
2. 快速抓取
下面以中国上市公司信息这个网页中的表格为例,感受一下read_html函数的强大之处。
1import pandas as pd
2import csv
3
4for i in range(1,178): # 爬取全部177页数据
5 url = 'http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum=%s' % (str(i))
6 tb = pd.read_html(url)[3] #经观察发现所需表格是网页中第4个表格,故为[3]
7 tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)
8 print('第'+str(i)+'页抓取完成')
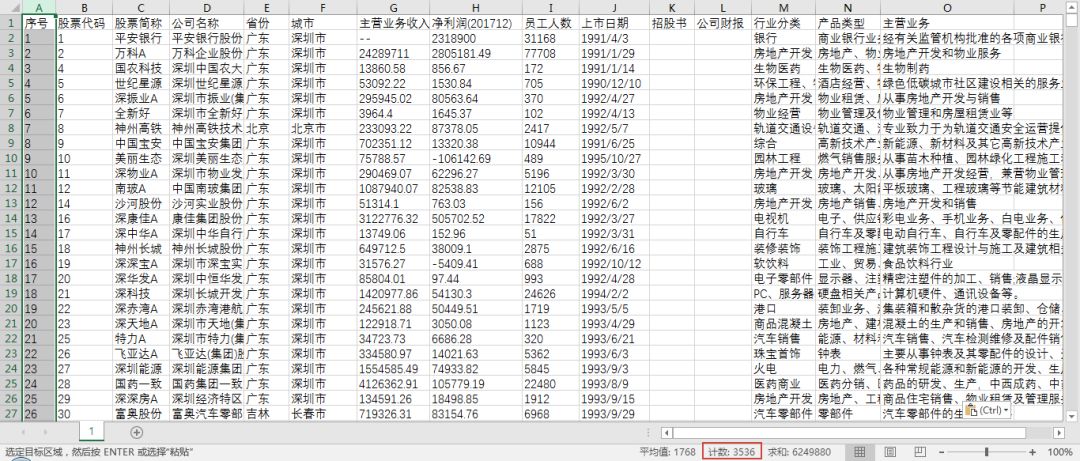
只需不到十行代码,1分钟左右就可以将全部178页共3535家A股上市公司的信息干净整齐地抓取下来。比采用正则表达式、xpath这类常规方法要省心省力地多。如果采取人工一页页地复制粘贴到excel中,就得操作到猴年马月去了。
上述代码除了能爬上市公司表格以外,其他几个网页的表格都可以爬,只需做简单的修改即可。因此,可作为一个简单通用的代码模板。但是,为了让代码更健壮更通用一些,接下来,以爬取177页的A股上市公司信息为目标,讲解一下详细的代码实现步骤。
3. 详细代码实现
3.1. read_html函数
先来了解一下read_html函数的api:
1pandas.read_html(io, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, tupleize_cols=None, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
2
3常用的参数:
4io:可以是url、html文本、本地文件等;
5flavor:解析器;
6header:标题行;
7skiprows:跳过的行;
8attrs:属性,比如 attrs = {'id': 'table'};
9parse_dates:解析日期
10
11注意:返回的结果是**DataFrame**组成的**list**。
参考:
1 http://pandas.pydata.org/pandas-docs/stable/io.html#io-read-html
2 http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_html.html
3.2. 分析网页url
首先,观察一下中商情报网第1页和第2页的网址:
1http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum=1#QueryCondition
2http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum=2#QueryCondition
可以发现,只有pageNum的值随着翻页而变化,所以基本可以断定pageNum=1代表第1页,pageNum=10代表第10页,以此类推。这样比较容易用for循环构造爬取的网址。
试着把#QueryCondition删除,看网页是否同样能够打开,经尝试发现网页依然能正常打开,因此在构造url时,可以使用这样的格式:
http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum=i
再注意一下其他参数:
a:表示A股,把a替换为h,表示港股;把a替换为xsb,则表示新三板。那么,在网址分页for循环外部再加一个for循环,就可以爬取这三个股市的股票了。
3.3. 定义函数
将整个爬取分为网页提取、内容解析、数据存储等步骤,依次建立相应的函数。
1# 网页提取函数
2def get_one_page(i):
3 try:
4 headers = {
5 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
6 }
7 paras = {
8 'reportTime': '2017-12-31',
9 #可以改报告日期,比如2018-6-30获得的就是该季度的信息
10 'pageNum': i #页码
11 }
12 url = 'http://s.askci.com/stock/a/?' + urlencode(paras)
13 response = requests.get(url,headers = headers)
14 if response.status_code == 200:
15 return response.text
16 return None
17 except RequestException:
18 print('爬取失败')
19
20# beatutiful soup解析然后提取表格
21def parse_one_page(html):
22 soup = BeautifulSoup(html,'lxml')
23 content = soup.select('#myTable04')[0] #[0]将返回的list改为bs4类型
24 tbl = pd.read_html(content.prettify(),header = 0)[0]
25 # prettify()优化代码,[0]从pd.read_html返回的list中提取出DataFrame
26
27 tbl.rename(columns = {'序号':'serial_number', '股票代码':'stock_code', '股票简称':'stock_abbre', '公司名称':'company_name', '省份':'province', '城市':'city', '主营业务收入(201712)':'main_bussiness_income', '净利润(201712)':'net_profit', '员工人数':'employees', '上市日期':'listing_date', '招股书':'zhaogushu', '公司财报':'financial_report', '行业分类':'industry_classification', '产品类型':'industry_type', '主营业务':'main_business'},inplace = True)
28
29 print(tbl)
30 # return tbl
31 # rename将表格15列的中文名改为英文名,便于存储到mysql及后期进行数据分析
32 # tbl = pd.DataFrame(tbl,dtype = 'object') #dtype可统一修改列格式为文本
33
34# 主函数
35def main(page):
36 for i in range(1,page): # page表示提取页数
37 html = get_one_page(i)
38 parse_one_page(html)
39
40# 单进程
41if __name__ == '__main__':
42 main(178) #共提取n页
上面两个函数相比于快速抓取的方法代码要多一些,如果需要抓的表格很少或只需要抓一次,那么推荐快速抓取法。如果页数比较多,这种方法就更保险一些。解析函数用了BeautifulSoup和css选择器,这种方法定位提取表格所在的id为#myTable04的table代码段,更为准确。
3.4. 存储到MySQL
接下来,我们可以将结果保存到本地csv文件,也可以保存到MySQL数据库中。这里为了练习一下MySQL,因此选择保存到MySQL中。
首先,需要先在数据库建立存放数据的表格,这里命名为listed_company。代码如下:
1import pymysql
2
3def generate_mysql():
4 conn = pymysql.connect(
5 host='localhost', # 本地服务器
6 user='root',
7 password='******', # 你的数据库密码
8 port=3306, # 默认端口
9 charset = 'utf8',
10 db = 'wade')
11 cursor = conn.cursor()
12
13 sql = 'CREATE TABLE IF NOT EXISTS listed_company2 (serial_number INT(30) NOT NULL,stock_code INT(30) ,stock_abbre VARCHAR(30) ,company_name VARCHAR(30) ,province VARCHAR(30) ,city VARCHAR(30) ,main_bussiness_income VARCHAR(30) ,net_profit VARCHAR(30) ,employees INT(30) ,listing_date DATETIME(0) ,zhaogushu VARCHAR(30) ,financial_report VARCHAR(30) , industry_classification VARCHAR(255) ,industry_type VARCHAR(255) ,main_business VARCHAR(255) ,PRIMARY KEY (serial_number))'
14 # listed_company是要在wade数据库中建立的表,用于存放数据
15
16 cursor.execute(sql)
17 conn.close()
18
19generate_mysql()
上述代码定义了generate_mysql()函数,用于在MySQL中wade数据库下生成一个listed_company的表。表格包含15个列字段。根据每列字段的属性,分别设置为INT整形(长度为30)、VARCHAR字符型(长度为30) 、DATETIME(0) 日期型等。
在Navicat中查看建立好之后的表格:
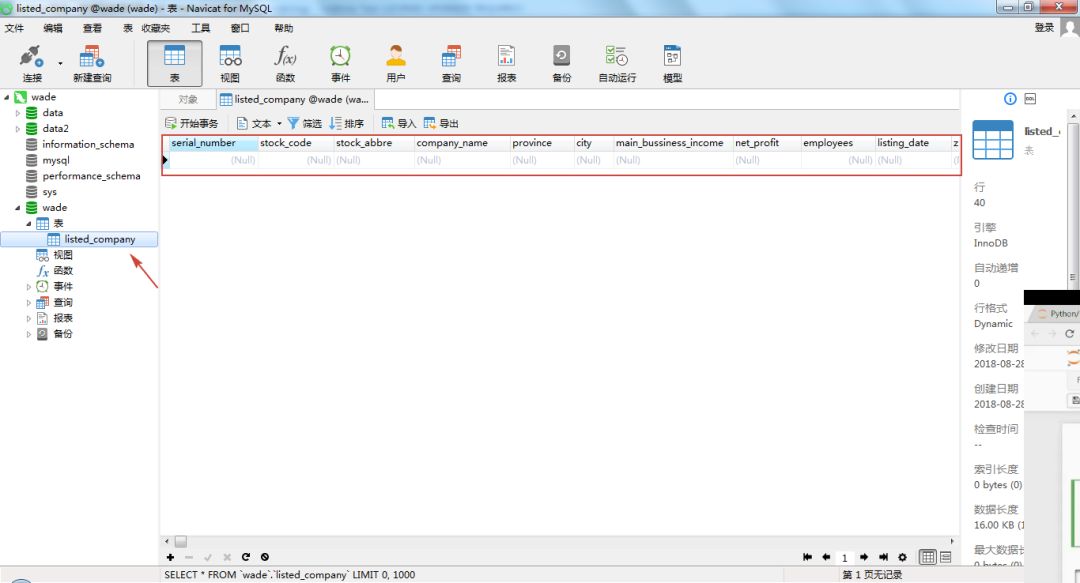
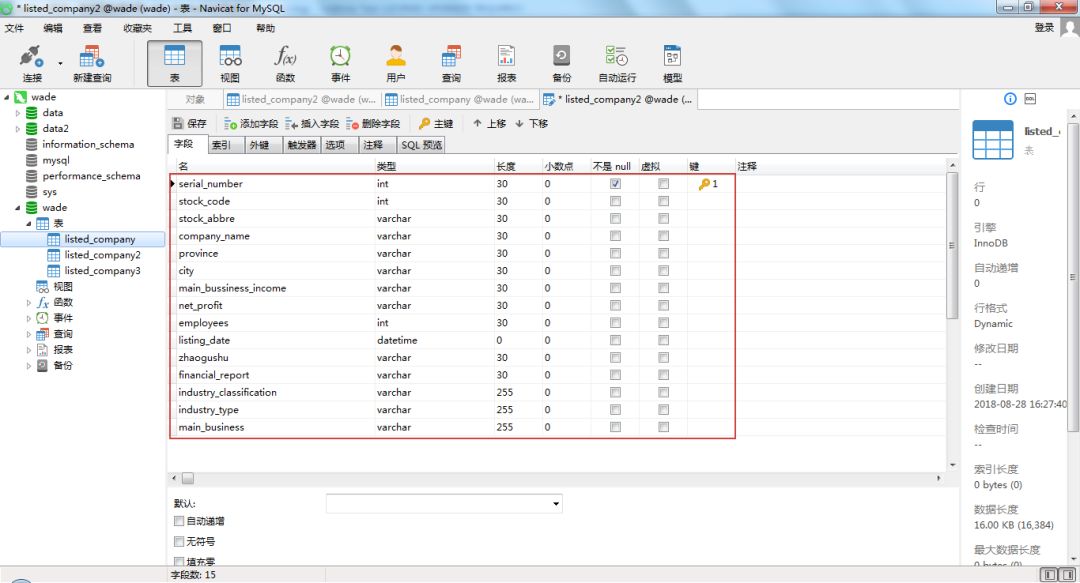
接下来就可以往这个表中写入数据,代码如下:
1import pymysql
2from sqlalchemy import create_engine
3
4def write_to_sql(tbl, db = 'wade'):
5 engine = create_engine('mysql+pymysql://root:******@localhost:3306/{0}?charset=utf8'.format(db))
6 # db = 'wade'表示存储到wade这个数据库中,root后面的*是密码
7 try:
8 tbl.to_sql('listed_company',con = engine,if_exists='append',index=False)
9 # 因为要循环网页不断数据库写入内容,所以if_exists选择append,同时该表要有表头,parse_one_page()方法中df.rename已设置
10 except Exception as e:
11 print(e)
以上就完成了单个页面的表格爬取和存储工作,接下来只要在main()函数进行for循环,就可以完成所有总共178页表格的爬取和存储,完整代码如下:
1import requests
2import pandas as pd
3from bs4 import BeautifulSoup
4from lxml import etree
5import time
6import pymysql
7from sqlalchemy import create_engine
8from urllib.parse import urlencode # 编码 URL 字符串
9
10start_time = time.time() #计算程序运行时间
11
12def get_one_page(i):
13 try:
14 headers = {
15 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
16 }
17 paras = {
18 'reportTime': '2017-12-31',
19 #可以改报告日期,比如2018-6-30获得的就是该季度的信息
20 'pageNum': i #页码
21 }
22 url = 'http://s.askci.com/stock/a/?' + urlencode(paras)
23 response = requests.get(url,headers = headers)
24 if response.status_code == 200:
25 return response.text
26 return None
27 except RequestException:
28 print('爬取失败')
29
30
31def parse_one_page(html):
32 soup = BeautifulSoup(html,'lxml')
33 content = soup.select('#myTable04')[0] #[0]将返回的list改为bs4类型
34 tbl = pd.read_html(content.prettify(),header = 0)[0]
35 # prettify()优化代码,[0]从pd.read_html返回的list中提取出DataFrame
36 tbl.rename(columns = {'序号':'serial_number', '股票代码':'stock_code', '股票简称':'stock_abbre', '公司名称':'company_name', '省份':'province', '城市':'city', '主营业务收入(201712)':'main_bussiness_income', '净利润(201712)':'net_profit', '员工人数':'employees', '上市日期':'listing_date', '招股书':'zhaogushu', '公司财报':'financial_report', '行业分类':'industry_classification', '产品类型':'industry_type', '主营业务':'main_business'},inplace = True)
37
38 # print(tbl)
39 return tbl
40 # rename将中文名改为英文名,便于存储到mysql及后期进行数据分析
41 # tbl = pd.DataFrame(tbl,dtype = 'object') #dtype可统一修改列格式为文本
42
43def generate_mysql():
44 conn = pymysql.connect(
45 host='localhost',
46 user='root',
47 password='******',
48 port=3306,
49 charset = 'utf8',
50 db = 'wade')
51 cursor = conn.cursor()
52
53 sql = 'CREATE TABLE IF NOT EXISTS listed_company (serial_number INT(20) NOT NULL,stock_code INT(20) ,stock_abbre VARCHAR(20) ,company_name VARCHAR(20) ,province VARCHAR(20) ,city VARCHAR(20) ,main_bussiness_income VARCHAR(20) ,net_profit VARCHAR(20) ,employees INT(20) ,listing_date DATETIME(0) ,zhaogushu VARCHAR(20) ,financial_report VARCHAR(20) , industry_classification VARCHAR(20) ,industry_type VARCHAR(100) ,main_business VARCHAR(200) ,PRIMARY KEY (serial_number))'
54 # listed_company是要在wade数据库中建立的表,用于存放数据
55
56 cursor.execute(sql)
57 conn.close()
58
59
60def write_to_sql(tbl, db = 'wade'):
61 engine = create_engine('mysql+pymysql://root:******@localhost:3306/{0}?charset=utf8'.format(db))
62 try:
63 # df = pd.read_csv(df)
64 tbl.to_sql('listed_company2',con = engine,if_exists='append',index=False)
65 # append表示在原有表基础上增加,但该表要有表头
66 except Exception as e:
67 print(e)
68
69
70def main(page):
71 generate_mysql()
72 for i in range(1,page):
73 html = get_one_page(i)
74 tbl = parse_one_page(html)
75 write_to_sql(tbl)
76
77# # 单进程
78if __name__ == '__main__':
79 main(178)
80
81 endtime = time.time()-start_time
82 print('程序运行了%.2f秒' %endtime)
83
84
85# 多进程
86# from multiprocessing import Pool
87# if __name__ == '__main__':
88# pool = Pool(4)
89# pool.map(main, [i for i in range(1,178)]) #共有178页
90
91# endtime = time.time()-start_time
92# print('程序运行了%.2f秒' %(time.time()-start_time))
最终,A股所有3535家企业的信息已经爬取到mysql中,如下图:
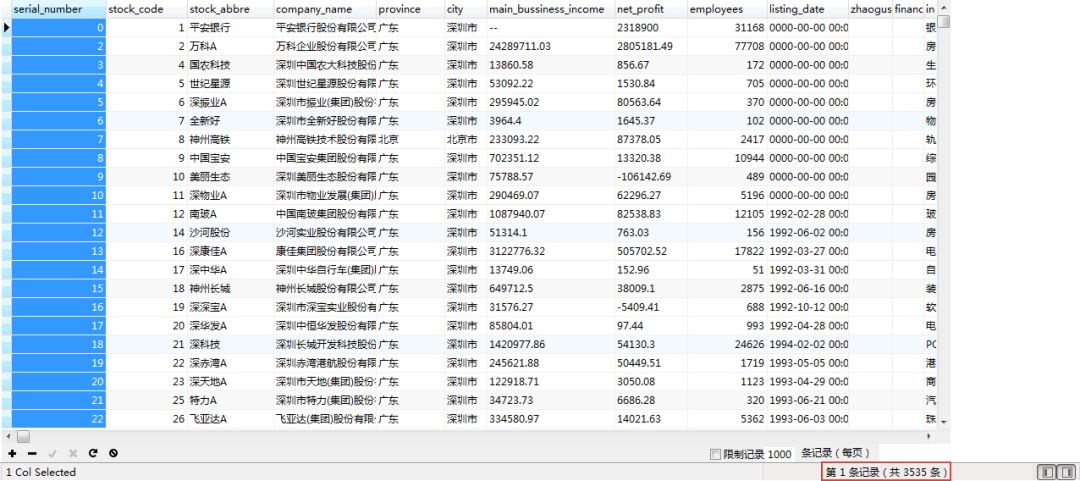
除了A股,还可以顺便再把港股和新三板所有的上市公司也爬了。后期,将会对爬取的数据做一下简单的数据分析。
最后,需说明不是所有表格都可以用这种方法爬取,比如这个网站中的表格,表面是看起来是表格,但在html中不是前面的table格式,而是list列表格式。这种表格则不适用read_html爬取。得用其他的方法,比如selenium,以后再进行介绍。
本文完。
【完】
2018 AI开发者大会
◆
只讲技术,拒绝空谈
◆
2018 AI开发者大会是一场由中美人工智能技术高手联袂打造的AI技术与产业的年度盛会!是一场以技术落地为导向的干货会议!大会设置了10场技术专题论坛,力邀15+硅谷实力讲师团和80+AI领军企业技术核心人物,多位一线经验大咖带你将AI从云端落地。
大会日程以及嘉宾议题请查看下方海报
(点击查看大图)


点击「阅读原文」,查看大会更多详情。2018 AI开发者大会——摆脱焦虑,拥抱技术前沿。
相关文章:

阿里云前端周刊 - 第 29 期
推荐 1. RESTful API 设计最佳实践 https://blog.philipphauer.de/... 项目资源的URL应该如何设计?用名词复数还是用名词单数?一个资源需要多少个URL?用哪种HTTP方法来创建一个新的资源?可选参数应该放在哪里?那些不涉…
Flash传值给asp页面
1.LoadVars的load方法-----在flash中写一个拉出两个动态文件框,变量名为myName与myPsd,拉出一组件button,名为:submit_button,用于提交,再拉出一T…
《深度学习500问》,川大优秀毕业生的诚意之作
前端工程师掌握这18招,就能在浏览器里玩转深度学习基于知识图谱的人机对话系统 | 公开课笔记来呀!AI喊你斗地主美团大脑:知识图谱的建模方法及其应用 | 公开课笔记60天,4位诺奖得主,他们将这样改造区块链程序员的江湖,务必掌握这些…

UC阿里鱼卡全网免流活动正在进行
UC&阿里鱼卡全网免流活动正在进行 优酷、虾米、高德、书旗应用专属流量免费 赠送100分钟国内通话、1G全国流量 扫码立即免费申请

普渡大学计算机硕士申请条件,普渡大学计算机与信息技术理学硕士研究生申请要求及申请材料要求清单...
2020年普渡大学计算机与信息技术理学硕士申请要求及普渡大学计算机与信息技术理学硕士申请材料要求清单是学生很感兴趣的问题,下面指南者留学整理2020年普渡大学计算机与信息技术理学硕士研究生申请要求及申请材料要求清单供大家参考。其中包括2020年普渡大学计算机…

object.ReferenceEquals(a,b)
code1 Assert.IsFalse(object.ReferenceEquals(10, 10));//比较时,要把比较的东西Box成Object,二个Ojbec地址是不一样的。 2 3 int value 10; 4 object one value; 5 object two value; 6 As…

深度文本匹配在智能客服中的应用
参加2018 AI开发者大会,请点击↑↑↑作者 | 云知声目录一. 深度文本匹配的简介1. 文本匹配的价值2. 深度文本匹配的优势3. 深度文本匹配的发展路线二. 智能客服的简介1. 智能客服的应用背景2. 智能客服的核心模块FAQ 库的构建语义召回相似度模型模型更新三. 深度文本…
计算机辅助焊接过程控制,重型车辆计算机辅助焊接工艺自动设计系统.pdf
金属学与金属工艺维普资讯第26卷 第10期 焊 接 学 报 v。1.26 N。.102005年 10月 TRANSACTIONSOFTHECHINAWELDINGINSTITUTION October 2005重型车辆计算机辅助焊接工艺 自动设计系统王克鸿, 韩 杰, 李 帅 王佳军(南京理工大学 材料…
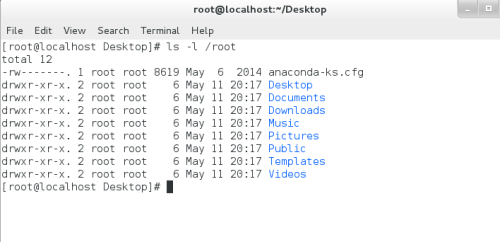
Linux--文件管理以及权限的修改
一、文件属性查看ls -l filename 目录属性的大小(文件名的字符总和)-|rw-r--r--.|1| root| root| 46 |Oct 1 05:03 |filename— ————————— — ———— ———— —— ———————————— ———————— 1 …
Linux 之父归来!
参加2018 AI开发者大会,请点击↑↑↑作者 | 屠敏来源 | CSDN去修身养性的 Linux 之父 Linus Torvalds 在时隔一个余月后笑着归来,从曾临时接手 Linux 4.19 开发的稳定版维护者 Greg Kroah-Hartman 手中再次接过 Linux 内核开发的交接棒。这位向来天不怕地…
vscode断开调试服务器文件,vscode显示等待调试器断开连接
我正在尝试在vscode上调试量角器脚本。我编辑了launch.json文件,但是调试控制台抛出了下面的错误。vscode调试控制台输出:C:\Program Files\nodejs\node.exe --inspect-brk45448 conf.js C:\Users\abc\AppData\Roaming\npm\node_modules\protractor\example/conf.jsDebugger li…
深入理解Spring系列之六:bean初始化
《深入理解Spring系列之四:BeanDefinition装载前奏曲》中提到,对于非延迟单例bean的初始化在finishBeanFactoryInitialization(beanFactory)中完成。进入这个方法,代码如下。protected void finishBeanFactoryInitialization(ConfigurableLis…
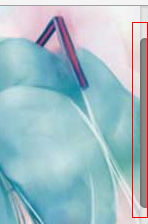
webkit内核 css,纯CSS改变webkit内核浏览器的滚动条样式
基于webkit的浏览器现在可以自定义其滚动条的样式了,实现代码如下:复制代码代码如下:::-webkit-scrollbar/*整体部分*/{width: 10px;height:10px;}::-webkit-scrollbar-track/*滑动轨道*/{-webkit-box-shadow: inset 0 0 5px rgba(0,0,0,0.2);border-rad…

数据依赖症:当今AI领域的核心风险
在最近结束的2017年度AI星际争霸竞赛上,Facebook做出了一款人工智能“CherryPi”,参与到这项旨在让各路AI技术在星际争霸游戏中同场竞技的赛事之中。 但很遗憾的是,Facebook仅仅获得了赛事的第六名,最直接的原因,在于F…

1024程序员节,你是我们要找的那条锦鲤吗?
参加2018 AI开发者大会,请扫描海报二维码 叮咚,您有一封 #1024吐槽狂欢派对# 邀请函请查收。 ▌什么是程序员? 全员格子、黑框眼镜,还是等于创造力忍耐力? 刻板标签、思维定式,还是高阶自黑玩梗幽默&#…
虚拟机管理你的服务器,全面解析VMware的虚拟机管理解决方案
本教程将为你讲述VMware的虚拟机管理解决方案,说起虚拟机,VMware绝对可以算的上是个中翘楚了,并且VMware的虚拟桌面结构解决方案可以起到增强管理效率,降低成本等等效用,话不多说,这就为大家介绍。Vmware的…
针对抓win2003系统密码的诡计
命令行下卸载win2003 sp1/sp2 %systemroot%\$NtServicePackUninstall$\spuninst\spuninst /U 按无人参与模式删除 service pack。如果使用此选项,那么在卸载 SP1 的过程中,只有出现致命错误才会显示提示。 /Q 按安静模式删除 SP1,此模式与无人…

那个曾经为美国NASA开发火星大脑的AI公司,现在和华为合作了
2010 年,美国航天航空局 NASA 敲响了一家创业公司的大门,希望他们参与火星探测器“大脑”的研发项目。这家公司就是 Neurala,一家专注于深度学习技术的波士顿初创公司。 NASA 的要求是一个艰难的挑战,因为火星探测器自身计算能力…

艾伦人工智能研究院开源AllenNLP,基于PyTorch轻松构建NLP模型
艾伦人工智能研究院(AI2)开源AllenNLP,它是一个基于PyTorch的NLP研究库,利用深度学习来进行自然语言理解,通过处理低层次的细节、提供高质量的参考实现,能轻松快速地帮助研究员构建新的语言理解模型。 Alle…
3650服务器性能,全新联想System x3650 M4服务器性能出色
系统支持Microsoft Windows Server 2008 R2Microsoft Windows Server 2008,Datacenter x64 EditionMicrosoft Windows Server 2008,Datacenter x86 EditionMicrosoft Windows Server 2008,Enterprise x64 EditionMicrosoft Windows Server 20…

不只翻译机,搜狗将在半年内推数款智能硬件产品
10月24日已是昨日,但属于开发者的1024一直都在——2018 AI开发者大会就是你的1024。11月8-9日,现场聆听国内外AI大牛的深知灼见,与工业界AI应用思维紧密同步,收获60技术大咖的干货分享。扫码填写大会注册信息表,就有可…

Windows Embedded Standard开发初体验(四)
添加文件、依赖组件、注册表 接下来我们就要进入创建组件最重要的一环了,添加文件。为什么说重要,因为这里有一个大坑,我在Windows Embedded Standard产品组施卫娟老师的指导下,花了两周的时间才勉强爬出来,可见该坑之…

Windows 2003 + ISA 2006+单网卡×××配置(4)
(接上)图13 然后下一步,用户集默认所有用户,不用改变,直接下一步,完成,然后会出现如图14图14照样还是点击应用。。。好了,都配置完了,下面我们做个测试。。。我本机的IP地…

科大讯飞全新1024:3大计划,200项A.I.能力,全链路驱动应用场景创新!
10月24日,2018届科大讯飞全球1024开发者节在合肥奥林匹克体育中心综合馆如约举行,重磅发布了全新升级的科大讯飞《1024计划》!原中国科学技术部副部长张来武、科大讯飞董事长刘庆峰、科大讯飞轮值总裁胡郁、讯飞听见事业部总经理王玮分别发表…
SQL基本语句
掌握SQL四条最基本的数据操作语句:Insert,Select,Update和Delete。练掌握SQL是数据库用户的宝贵财 富。在本文中,我们将引导你掌握四条最基本的数据操作语句—SQL的核心功能—来依次介绍比较操作符、选择断言以及三值逻辑。当你完…
【TP3.2】路由匹配和规则
TP3.2框架的路由匹配和规则处理: 包括:静态路由,动态路由,多参数路由、正则路由 <?php return array(//配置项>配置值/* * 路由开启和匹配。首先开启路由匹配,然后根据相应的路由规则进行匹配* 1、静态路由* 2、…
soul一直显示正在登录聊天服务器,soul这个软件,为什么有些人在玩的时间很久以后(两百天以上),就不会再主动和其他人打招呼了?...
起首,说一下我本人接触soul的那些年。记得玩soul是17年开端,最初这个软件的营销目标是为了让人们更好地交换,停止跨时空的深度聊天,寻求魂魄的朋友,而不是皮郛的一时好感。可能说当时soul是打着"丢脸的皮郛千篇一…

构建插件式的应用程序框架(八)----视图服务的简单实现(ZT)
我在前一篇文章里提到,对于停靠工具栏或者是视图最好是不要将实例放到词典中,而是将工具栏或者视图的类型放到词典中,因为视图类型会经常的被重用,并且会经常被关闭或者再打开。当实例被关闭后,资源就被释放了…

服务器怎么设置网站写入权限,如何设置服务器写入权限设置方法
如何设置服务器写入权限设置方法 内容精选换一换将用户组添加至企业项目中,并为其设置一定的权限策略,该用户组中的用户即可拥有策略定义的对该企业项目中资源的使用权限。本小节指导您如何为企业项目添加用户组并授权。分辨率低的情况下单击页面右上方的…

CSDN蒋涛提出技术社区三倍速定律,称下一个20年全球开发者数量将过亿
10 月 24 日,科大讯飞 1024 开发者节在合肥举行,中国 IT 技术社区 CSDN 创始人&董事长、极客帮创投创始合伙人蒋涛受邀发表了主题演讲。 在演讲中,蒋涛提出了“技术社区三倍速定律”,如何理解? 2013 年 CSDN 上关于…