一文掌握常用的机器学习模型(文末福利)

AI 科技大本营按:本文节选自微软亚洲研究院机器学习研究团队刘铁岩、陈薇、王太峰、高飞合著的《分布式机器学习:算法、理论与实践》一书。为了让大家更好地理解分布式机器学习,AI科技大本营联合华章科技特别邀请到了本书的作者之一——微软亚洲研究院副院长刘铁岩老师进行在线公开课分享,详情请见文末信息,还有福利哦~~
分布式机器学习并非分布式处理技术与机器学习的简单结合。一方面,它必须考虑机器学习模型构成与算法流程本身的特点,否则分布式处理的结果可能失之毫厘、谬以千里;另一方面,机器学习内含的算法随机性、参数冗余性等,又会带来一般分布式处理过程所不具备的、宜于专门利用的便利。
——节选自周志华老师对该书的推荐语
线性模型
线性模型是最简单的,也是最基本的机器学习模型。其数学形式如下:g(x;w)= 。有时,我们还会在的基础上额外加入一个偏置项b,不过只要把x扩展出一维常数分量,就可以把带偏置项的线性函数归并到的形式之中。线性模型非常简单明了,参数的每一维对应了相应特征维度的重要性。但是很显然,线性模型也存在一定的局限性。
。有时,我们还会在的基础上额外加入一个偏置项b,不过只要把x扩展出一维常数分量,就可以把带偏置项的线性函数归并到的形式之中。线性模型非常简单明了,参数的每一维对应了相应特征维度的重要性。但是很显然,线性模型也存在一定的局限性。
首先,线性模型的取值范围是不受限的,依据w和x的具体取值,它的输出可以是非常大的正数或者非常小的负数。然而,在进行分类的时候,我们预期得到的模型输出是某个样本属于正类(如正面评价)的可能性,这个可能性通常是取值在0和1之间的一个概率值。为了解决这二者之间的差距,人们通常会使用一个对数几率函数对线性模型的输出进行变换,得到如下公式:
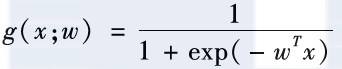
经过变换,严格地讲,g(x;w)已经不再是一个线性函数,而是由一个线性函数派生出来的非线性函数,我们通常称这类函数为广义线性函数。对数几率模型本身是一个概率形式,非常适合用对数似然损失或者交叉熵损失进行训练。
其次,线性模型只能挖掘特征之间的线性组合关系,无法对更加复杂、更加强大的非线性组合关系进行建模。为了解决这个问题,我们可以对输入的各维特征进行一些显式的非线性预变换(如单维特征的指数、对数、多项式变换,以及多维特征的交叉乘积等),或者采用核方法把原特征空间隐式地映射到一个高维的非线性空间,再在高维空间里构建线性模型。
核方法与支持向量机
核方法的基本思想是通过一个非线性变换,把输入数据映射到高维的希尔伯特空间中,在这个高维空间里,那些在原始输入空间中线性不可分的问题变得更加容易解决,甚至线性可分。支持向量机(Support Vector Machine,SVM)[10]是一类最典型的核方法,下面将以支持向量机为例,对核方法进行简单的介绍。
支持向量机的基本思想是通过核函数将原始输入空间变换成一个高维(甚至是无穷维)的空间,在这个空间里寻找一个超平面,它可以把训练集里的正例和负例尽最大可能地分开(用更加学术的语言描述,就是正负例之间的间隔最大化)。那么如何才能通过核函数实现空间的非线性映射呢?让我们从头谈起。
假设存在一个非线性映射函数Φ,可以帮我们把原始输入空间变换成高维非线性空间。我们的目的是在变换后的空间里,寻找一个线性超平面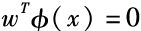 ,它能够把所有正例和负例分开,并且距离该超平面最近的正例和负例之间的间隔最大。这个诉求可以用数学语言表述如下:
,它能够把所有正例和负例分开,并且距离该超平面最近的正例和负例之间的间隔最大。这个诉求可以用数学语言表述如下:

其中, 是离超平面最近的正例和负例之间的间隔(如图2.6所示)。
是离超平面最近的正例和负例之间的间隔(如图2.6所示)。

图2.6 最大化间隔与支持向量机
以上的数学描述等价于如下的优化问题:min12w2

上式中的约束条件要求所有的正例和负例分别位于超平面的两侧。某些情况下,这种约束可能过强,因为我们所拥有的训练集有时是不可分的。这时候,就需要引入松弛变量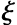 ,把上述优化问题改写为:
,把上述优化问题改写为:
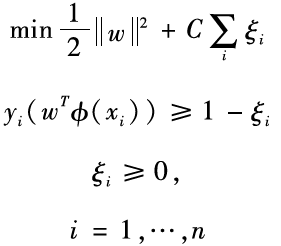
其实这种新的表述等价于最小化一个加了正则项 的Hinge损失函数。这是因为当
的Hinge损失函数。这是因为当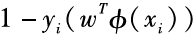 小于0的时候,样本
小于0的时候,样本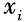 被超平面正确地分到相应的类别里,ξi=0;反之,ξi将大于0,且是的上界:最小化ξi就相应地最小化了。基于以上讨论,其实支持向量机在最小化如下的目标函数:
被超平面正确地分到相应的类别里,ξi=0;反之,ξi将大于0,且是的上界:最小化ξi就相应地最小化了。基于以上讨论,其实支持向量机在最小化如下的目标函数:
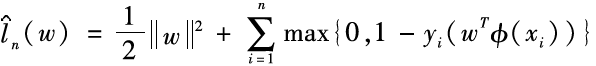
其中,是正则项,对它的最小化可以限制模型的空间,有效提高模型的泛化能力(也就是使模型在训练集和测试集上的性能更加接近)。
为了求解上述有约束的优化问题,一种常用的技巧是使用拉格朗日乘数法将其转换成对偶问题进行求解。具体来讲,支持向量机对应的对偶问题如下:

在对偶空间里,该优化问题的描述只与 和
和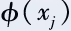 的内积有关,而与映射函数本身的具体形式无关。因此,我们只需定义两个样本和
的内积有关,而与映射函数本身的具体形式无关。因此,我们只需定义两个样本和 之间的核函数k(xi,xj),用以表征其映射到高维空间之后的内积即可:
之间的核函数k(xi,xj),用以表征其映射到高维空间之后的内积即可:

至此,我们弄清楚了核函数是如何和空间变换发生联系的。核函数可以有很多不同的选择,表2.1列出了几种常用的核函数。

事实上,只要一个对称函数所对应的核矩阵满足半正定的条件,它就能作为核函数使用,并总能找到一个与之对应的空间映射 。换言之,任何一个核函数都隐式地定义了一个“再生核希尔伯特空间”(Reproducing Kernel Hilbert Space,RKHS)。在这个空间里,两个向量的内积等于对应核函数的值。
。换言之,任何一个核函数都隐式地定义了一个“再生核希尔伯特空间”(Reproducing Kernel Hilbert Space,RKHS)。在这个空间里,两个向量的内积等于对应核函数的值。
决策树与Boosting
决策树也是一类常见的机器学习模型,它的基本思想是根据数据的属性构造出树状结构的决策模型。一棵决策树包含一个根节点、若干内部节点,以及若干叶子节点。叶子节点对应最终的决策结果,而其他节点则针对数据的某种属性进行判断与分支:在这样的节点上,会对数据的某个属性(特征)进行检测,依据检测结果把样本划分到该节点的某棵子树之中。通过决策树,我们可以从根节点出发,把一个具体的样本最终分配到某个叶子节点上,实现相应的预测功能。
因为在每个节点上的分支操作是非线性的,因此决策树可以实现比较复杂的非线性映射。决策树算法的目的是根据训练数据,学习出一棵泛化能力较强的决策树,也就是说,它能够很好地把未知样本分到正确的叶子节点上。为了达到这个目的,我们在训练过程中构建的决策树不能太复杂,否则可能会过拟合到训练数据上,而无法正确地处理未知的测试数据。常见的决策树算法包括:分类及回归树(CART)[21],ID3算法[11],C4.5算法[22],决策树桩(Decision Stump)[23]等。这些算法的基本流程都比较类似,包括划分选择和剪枝处理两个基本步骤。
划分选择要解决的问题是如何根据某种准则在某个节点上把数据集里的样本分到它的一棵子树上。常用的准则有:信息增益、增益率、基尼系数等。其具体数学形式虽有差别,但是核心思想大同小异。这里我们就以信息增益为例进行介绍。所谓信息增益,指的是在某个节点上,用特征j对数据集D进行划分得到的样本集合的纯度提升的程度。信息增益的具体数学定义如下:

其中, 是特征
是特征 的取值集合,而
的取值集合,而 是特征取值为
是特征取值为 的那些样本所组成的子集;Entropy(D)是样本集合D的信息熵,描述的是D中来自不同类别的样本的分布情况。不同类别的样本分布越平均,则信息熵越大,集合纯度越低;相反,样本分布越集中,则信息熵越小,集合纯度越高。样本划分的目的是找到使得划分后平均信息熵变得最小的特征,从而使得信息增益最大。
的那些样本所组成的子集;Entropy(D)是样本集合D的信息熵,描述的是D中来自不同类别的样本的分布情况。不同类别的样本分布越平均,则信息熵越大,集合纯度越低;相反,样本分布越集中,则信息熵越小,集合纯度越高。样本划分的目的是找到使得划分后平均信息熵变得最小的特征,从而使得信息增益最大。
剪枝处理要解决的问题是抑制过拟合。如果决策树非常复杂,每个叶子节点上只对应一个训练样本,一定可以实现信息增益最大化,可这样的后果是对训练数据的过拟合,将导致在测试数据上的精度损失。为了解决这个问题,可以采取剪枝的操作降低决策树的复杂度。剪枝处理有预剪枝和后剪枝之分:预剪枝指的是在决策树生成过程中,对每个节点在划分前先进行估计,如果当前节点的划分不能带来决策树泛化性能的提升(通常可以通过一个交叉验证集来评估泛化能力),则停止划分并且将当前节点标记为叶子节点;后剪枝指的是先从训练集中生成一棵完整的决策树,然后自底向上地考察去掉每个节点(即将该节点及其子树合并成为一个叶子节点)以后泛化能力是否有所提高,若有提高,则进行剪枝。
在某些情况下,由于学习任务难度大,单棵决策树的性能会捉襟见肘,这时人们常常会使用集成学习来提升最终的学习能力。集成学习有很多方法,如Bagging[24]、Boosting[25]等。Boosting的基本思路是先训练出一个弱学习器 ,再根据弱学习器的表现对训练样本的分布进行调整,使得原来弱学习器无法搞定的错误样本在后续的学习过程中得到更多的关注,然后再根据调整后的样本分布来训练下一个弱学习器
,再根据弱学习器的表现对训练样本的分布进行调整,使得原来弱学习器无法搞定的错误样本在后续的学习过程中得到更多的关注,然后再根据调整后的样本分布来训练下一个弱学习器 。如此循环往复,直到最终学到的弱学习器的数目达到预设的上限,或者弱学习器的加权组合能够达到预期的精度为止。最终的预测模型是所有这些弱学习器的加权求和:
。如此循环往复,直到最终学到的弱学习器的数目达到预设的上限,或者弱学习器的加权组合能够达到预期的精度为止。最终的预测模型是所有这些弱学习器的加权求和:

其中,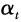 是加权系数,它既可以在训练过程中根据当前弱学习器的准确程度利用经验公式求得,也可以在训练过程结束后(各个弱学习器都已经训练好以后),再利用新的学习目标通过额外的优化手段求得。
是加权系数,它既可以在训练过程中根据当前弱学习器的准确程度利用经验公式求得,也可以在训练过程结束后(各个弱学习器都已经训练好以后),再利用新的学习目标通过额外的优化手段求得。
有研究表明Boosting在抵抗过拟合方面有非常好的表现,也就是说,随着训练过程的推进,即便在训练集上已经把误差降到0,更多的迭代还是可以提高模型在测试集上的性能。人们用间隔定理(Margin Theory)[26]来解释这种现象——随着迭代进一步推进,虽然训练集上的误差已经不再变化,但是训练样本上的分类置信度(对应于每个样本点上的间隔)却仍在不断变大。到今天为止,Boosting算法,尤其是与决策树相结合的算法如梯度提升决策树(GBDT)[27]仍然在实际应用中挑着大梁,是很多数据挖掘比赛的夺冠热门。
神经网络
神经网络是一类典型的非线性模型,它的设计受到生物神经网络的启发。人们通过对大脑生物机理的研究,发现其基本单元是神经元,每个神经元通过树突从上游的神经元那里获取输入信号,经过自身的加工处理后,再通过轴突将输出信号传递给下游的神经元。当神经元的输入信号总和达到一定强度时,就会激活一个输出信号,否则就没有输出信号(如图2.7a所示)。
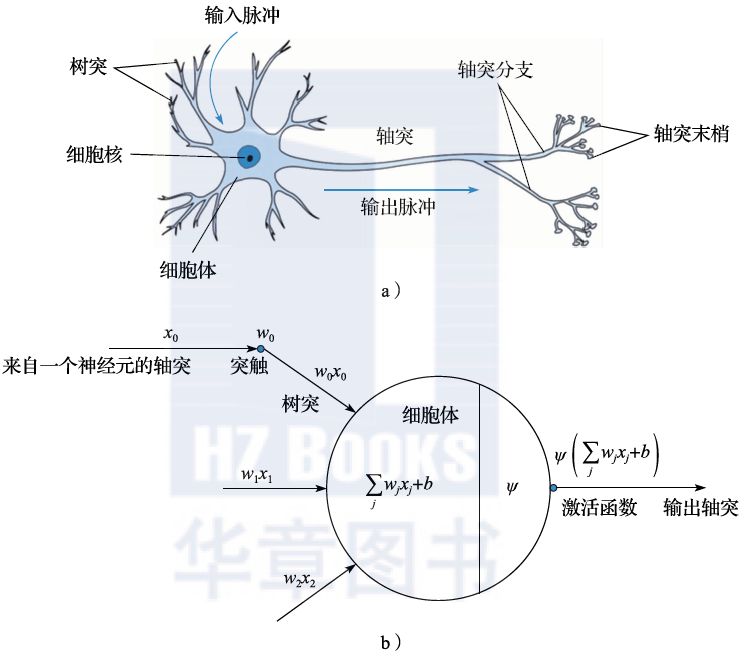
图2.7 神经元结构与人工神经网络
这种生物学原理如果用数学语言进行表达,就如图2.7b所示。神经元对输入的信号 进行线性加权求和:
进行线性加权求和: ,然后依据求和结果的大小来驱动一个激活函数ψ,用以生成输出信号。生物系统中的激活函数类似于阶跃函数:
,然后依据求和结果的大小来驱动一个激活函数ψ,用以生成输出信号。生物系统中的激活函数类似于阶跃函数:

但是,由于阶跃函数本身不连续,对于机器学习而言不是一个好的选择,因此在人们设计人工神经网络的时候通常采用连续的激活函数,比如Sigmoid函数、双曲正切函数(tanh)、校正线性单元(ReLU)等。它们的数学形式和函数形状分别如图2.8所示。
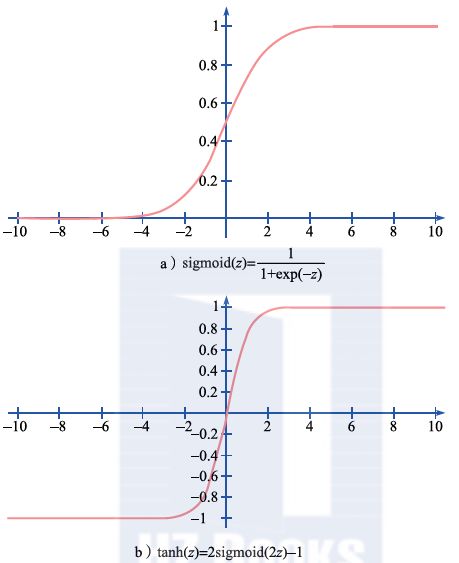

图2.8 常用的激活函数
1.全连接神经网络
最基本的神经网络就是把前面描述的神经元互相连接起来,形成层次结构(如图2.9所示),我们称之为全连接神经网络。对于图2.9中这个网络而言,最左边对应的是输入节点,最右边对应的是输出节点,中间的三层节点都是隐含节点(我们把相应的层称为隐含层)。每一个隐含节点都会把来自上一层节点的输出进行加权求和,再经过一个非线性的激活函数,输出给下一层。而输出层则一般采用简单的线性函数,或者进一步使用softmax函数将输出变成概率形式。

图2.9 全连接神经网络
全连接神经网络虽然看起来简单,但它有着非常强大的表达能力。早在20世纪80年代,人们就证明了著名的通用逼近定理(Universal Approximation Theorem[28])。最早的通用逼近定理是针对Sigmoid激活函数证明的,一般情况下的通用逼近定理在2001年被证明[29]。其数学描述是,在激活函数满足一定条件的前提下,任意给定输入空间中的一个连续函数和近似精度ε,存在自然数Nε和一个隐含节点数为Nε的单隐层全连接神经网络,对这个连续函数的 -逼近精度小于ε。这个定理非常重要,它告诉我们全连接神经网络可以用来解决非常复杂的问题,当其他的模型(如线性模型、支持向量机等)无法逼近这类问题的分类界面时,神经网络仍然可以所向披靡、得心应手。近年来,人们指出深层网络的表达力更强,即表达某些逻辑函数,深层网络需要的隐含节点数比浅层网络少很多[30]。这对于模型存储和优化而言都是比较有利的,因此人们越来越关注和使用更深层的神经网络。
-逼近精度小于ε。这个定理非常重要,它告诉我们全连接神经网络可以用来解决非常复杂的问题,当其他的模型(如线性模型、支持向量机等)无法逼近这类问题的分类界面时,神经网络仍然可以所向披靡、得心应手。近年来,人们指出深层网络的表达力更强,即表达某些逻辑函数,深层网络需要的隐含节点数比浅层网络少很多[30]。这对于模型存储和优化而言都是比较有利的,因此人们越来越关注和使用更深层的神经网络。
全连接神经网络在训练过程中常常选取交叉熵损失函数,并且使用梯度下降法来求解模型参数(实际中为了减少每次模型更新的代价,使用的是小批量的随机梯度下降法)。要注意的是,虽然交叉熵损失是个凸函数,但由于多层神经网络本身的非线性和非凸本质,损失函数对于模型参数而言其实是严重非凸的。在这种情况下,使用梯度下降法求解通常只能找到局部最优解。为了解决这个问题,人们在实践中常常采用多次随机初始化或者模拟退火等技术来寻找全局意义下更优的解。近年有研究表明,在满足一定条件时,如果神经网络足够深,它的所有局部最优解其实都和全局最优解具有非常类似的损失函数值[31]。换言之,对于深层神经网络而言,“只能找到局部最优解”未见得是一个致命的缺陷,在很多时候这个局部最优解已经足够好,可以达到非常不错的实际预测精度。
除了局部最优解和全局最优解的忧虑之外,其实关于使用深层神经网络还有另外两个困难。
首先,因为深层神经网络的表达能力太强,很容易过拟合到训练数据上,导致其在测试数据上表现欠佳。为了解决这个问题,人们提出了很多方法,包括DropOut[32]、数据扩张(Data Augmentation)[33]、批量归一化(Batch Normalization)[34]、权值衰减(Weight Decay)[35]、提前终止(Early Stopping)[36]等,通过在训练过程中引入随机性、伪训练样本或限定模型空间来提高模型的泛化能力。
其次,当网络很深时,输出层的预测误差很难顺利地逐层传递下去,从而使得靠近输入层的那些隐含层无法得到充分的训练。这个问题又称为“梯度消减”问题\[37\]。研究表明,梯度消减主要是由神经网络的非线性激活函数带来的,因为非线性激活函数导数的模都不太大,在使用梯度下降法进行优化的时候,非线性激活函数导数的逐层连乘会出现在梯度的计算公式中,从而使梯度的幅度逐层减小。为了解决这个问题,人们在跨层之间引入了线性直连,或者由门电路控制的线性通路[38],以期为梯度信息的顺利回传提供便利。
2.卷积神经网络
除了全连接神经网络以外,卷积神经网络(Convolutional Neural Network,CNN)[13]也是十分常用的网络结构,尤其适用于处理图像数据。
卷积神经网络的设计是受生物视觉系统的启发。研究表明每个视觉细胞只对于局部的小区域敏感,而大量视觉细胞平铺在视野中,可以很好地利用自然图像的空间局部相关性。与此类似,卷积神经网络也引入局部连接的概念,并且在空间上平铺具有同样参数结构的滤波器(也称为卷积核)。这些滤波器之间有很大的重叠区域,相当于有个空域滑窗,在滑窗滑到不同空间位置时,对这个窗内的信息使用同样的滤波器进行分析。这样虽然网络很大,但是由于不同位置的滤波器共享参数,其实模型参数的个数并不多,参数效率很高。
图2.10描述了一个2×2的卷积核将输入图像进行卷积的例子。所谓卷积就是卷积核的各个参数和图像中空间位置对应的像素值进行点乘再求和。经过了卷积操作之后,会得到一个和原图像类似大小的新图层,其中的每个点都是卷积核在某空间局部区域的作用结果(可能对应于提取图像的边缘或抽取更加高级的语义信息)。我们通常称这个新图层为特征映射(feature map)。对于一幅图像,可以在一个卷积层里使用多个不同的卷积核,从而形成多维的特征映射;还可以把多个卷积层级联起来,不断抽取越来越复杂的语义信息。
图2.10 卷积过程示意图
除了卷积以外,池化也是卷积神经网络的重要组成部分。池化的目的是对原特征映射进行压缩,从而更好地体现图像识别的平移不变性,并且有效扩大后续卷积操作的感受野。池化与卷积不同,一般不是参数化的模块,而是用确定性的方法求出局部区域内的平均值、中位数,或最大值、最小值(近年来,也有一些学者开始研究参数化的池化算子[39])。图2.11描述了对图像局部进行2×2的最大值池化操作后的效果。

图2.11 池化操作示意图
在实际操作中,可以把多个卷积层和多个池化层交替级联,从而实现从原始图像中不断抽取高层语义特征的目的。在此之后,还可以再级联一个全连接网络,在这些高层语义特征的基础上进行模式识别或预测。这个过程如图2.12所示。

图2.12 多层卷积神经网络(N1,N2,N3表示对应单元重复的次数)
实践中,人们开始尝试使用越来越深的卷积神经网络,以达到越来越好的图像分类效果。图2.13描述了近年来人们在ImageNet数据集上不断通过增加网络深度刷新错误率的历程。其中2015年来自微软研究院的深达152层的ResNet网络[40],在ImageNet数据集上取得了低达3.57%的Top-5错误率,在特定任务上超越了普通人类的图像识别能力。

图2.13 卷积神经网络不断刷新ImageNet数据集的识别结果

图2.14残差学习
随着卷积神经网络变得越来越深,前面提到的梯度消减问题也随之变得越来越显著,给模型的训练带来了很大难度。为了解决这个问题,近年来人们提出了一系列的方法,包括残差学习[40-41](如图2.14所示)、高密度网络[42](如图2.15所示)等。实验表明:这些方法可以有效地把训练误差传递到靠近输入层的地方,为深层卷积神经网络的训练奠定了坚实的实践基础。

图2.15 高密度网络
3.循环神经网络
循环神经网络(Recurrent Neural Network,RNN)[14]的设计也有很强的仿生学基础。我们可以联想一下自己如何读书看报。当我们阅读一个句子时,不会单纯地理解当前看到的那个字本身,相反我们之前读到的文字会在脑海里形成记忆,而这些记忆会帮助我们更好地理解当前看到的文字。这个过程是递归的,我们在看下一个文字时,当前文字和历史记忆又会共同成为我们新的记忆,并对我们理解下一个文字提供帮助。其实,循环神经网络的设计基本就是依照这个思想。我们用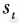 表示在
表示在 时刻的记忆,它是由t时刻看到的输入
时刻的记忆,它是由t时刻看到的输入 和
和 时刻的记忆st-1共同作用产生的。这个过程可以用下式加以表示:
时刻的记忆st-1共同作用产生的。这个过程可以用下式加以表示:

很显然,这个式子里蕴含着对于记忆单元的循环迭代。在实际应用中,无限长时间的循环迭代并没有太大意义。比如,当我们阅读文字的时候,每个句子的平均长度可能只有十几个字。因此,我们完全可以把循环神经网络在时域上展开,然后在展开的网络上利用梯度下降法来求得参数矩阵U、W、V,如图2.16所示。用循环神经网络的术语,我们称之为时域反向传播(Back Propagation Through Time,BPTT)。
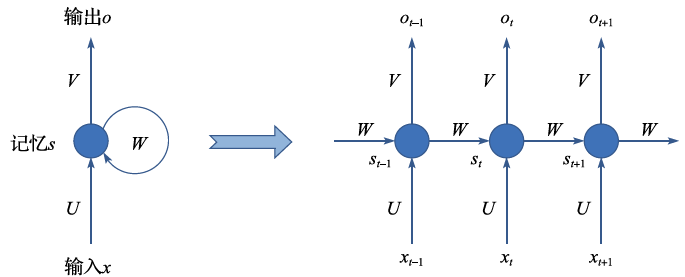
图2.16 循环神经网络的展开
和全连接神经网络、卷积神经网络类似,当循环神经网络时域展开以后,也会遇到梯度消减的问题。为了解决这个问题,人们提出了一套依靠门电路来控制信息流通的方法。也就是说,在循环神经网络的两层之间同时存在线性和非线性通路,而哪个通路开、哪个通路关或者多大程度上开关则由一组门电路来控制。这个门电路也是带参数并且这些参数在神经网络的优化过程中是可学习的。比较著名的两类方法是LSTM[43]和GRU[44](如图2.17所示)。GRU相比LSTM更加简单一些,LSTM有三个门电路(输入门、忘记门、输出门),而GRU则有两个门电路(重置门、更新门),二者在实际中的效果类似,但GRU的训练速度要快一些,因此近年来有变得更加流行的趋势。

图2.17 循环神经网络中的门电路
循环神经网络可以对时间序列进行有效建模,根据它所处理的序列的不同情况,可以把循环神经网络的应用场景分为点到序列、序列到点和序列到序列等类型(如图2.18所示)。
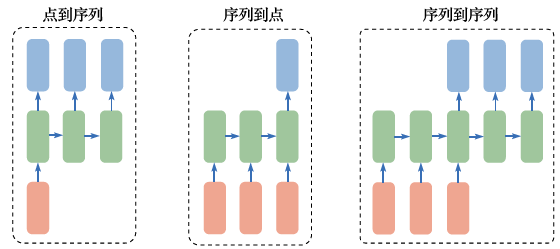
图2.18 循环神经网络的不同应用
下面分别介绍几种循环神经网络的应用场景。
(1)图像配文字:点到序列的循环神经网络应用
在这个应用中,输入的是图像的编码信息(可以通过卷积神经网络的中间层获得,也可以直接采用卷积神经网络预测得到的类别标签),输出则是靠循环神经网络来驱动产生的一句自然语言文本,用以描述该图像包含的内容。
(2)情感分类:序列到点的循环神经网络应用
在这个应用中,输入的是一段文本信息(时序序列),而输出的是情感分类的标签(正向情感或反向情感)。循环神经网络用于分析输入的文本,其隐含节点包含了整个输入语句的编码信息,再通过一个全连接的分类器把该编码信息映射到合适的情感类别之中。
(3)机器翻译:序列到序列的循环神经网络应用
在这个应用中,输入的是一个语言的文本(时序序列),而输出的则是另一个语言的文本(时序序列)。循环神经网络在这个应用中被使用了两次:第一次是用来对输入的源语言文本进行分析和编码;而第二次则是利用这个编码信息驱动输出目标语言的一段文本。
在使用序列到序列的循环神经网络实现机器翻译时,在实践中会遇到一个问题。输出端翻译结果中的某个词其实对于输入端各个词汇的依赖程度是不同的,通过把整个输入句子编码到一个向量来驱动输出的句子,会导致信息粒度太粗糙,或者长线的依赖关系被忽视。为了解决这个问题,人们在标准的序列到序列循环神经网络的基础上引入了所谓“注意力机制”。在它的帮助下,输出端的每个词的产生会利用到输入端不同词汇的编码信息。而这种注意力机制也是带参数的,可以在整个循环神经网络的训练过程中自动习得。
神经网络尤其是深层神经网络是一个高速发展的研究领域。随着整个学术界和工业界的持续关注,这个领域比其他的机器学习领域获得了更多的发展机会,不断有新的网络结构或优化方法被提出。如果读者对于这个领域感兴趣,请关注每年发表在机器学习主流学术会议上的最新论文。
参考文献
[1]Cao Z, Qin T, Liu T Y, et al. Learning to Rank: From Pairwise Approach to Listwise Approach\[C\]//Proceedings of the 24th international conference on Machine learning. ACM, 2007: 129-136.
[2]Liu T Y. Learning to rank for information retrieval\[J\]. Foundations and Trends in Information Retrieval, 2009, 3(3): 225-331.
[3]Kotsiantis S B, Zaharakis I, Pintelas P. Supervised Machine Learning: A Review of Classification Techniques\[J\]. Emerging Artificial Intelligence Applications in Computer Engineering, 2007, 160: 3-24.
[4]Chapelle O, Scholkopf B, Zien A. Semi-supervised Learning (chapelle, o. et al., eds.; 2006)\[J\]. IEEE Transactions on Neural Networks, 2009, 20(3): 542-542.
[5]He D, Xia Y, Qin T, et al. Dual learning for machine translation\[C\]//Advances in Neural Information Processing Systems. 2016: 820-828.
[6]Hastie T, Tibshirani R, Friedman J. Unsupervised Learning\[M\]//The Elements of Statistical Learning. New York: Springer, 2009: 485-585.
[7]Sutton R S, Barto A G. Reinforcement Learning: An Introduction\[M\]. Cambridge: MIT press, 1998.
[8]Seber G A F, Lee A J. Linear Regression Analysis\[M\]. John Wiley & Sons, 2012.
[9]Harrell F E. Ordinal Logistic Regression\[M\]//Regression modeling strategies. New York: Springer, 2001: 331-343.
[10]Cortes C, Vapnik V. Support-Vector Networks\[J\]. Machine Learning, 1995, 20(3): 273-297.
[11]Quinlan J R. Induction of Decision Trees\[J\]. Machine Learning, 1986, 1(1): 81-106.
[12]McCulloch, Warren; Walter Pitts (1943). "A Logical Calculus of Ideas Immanent in Nervous Activity" \[EB\]. Bulletin of Mathematical Biophysics. 5(4): 115-133.
[13]LeCun Y, Jackel L D, Bottou L, et al. Learning Algorithms for Classification: A Comparison on Handwritten Digit Recognition\[J\]. Neural networks: The Statistical Mechanics Perspective, 1995, 261: 276.
[14]Elman J L. Finding structure in time\[J\]. Cognitive Science, 1990, 14(2): 179-211.
[15]周志华. 机器学习[M]. 北京:清华大学出版社,2017.
[16]Tom Mitchell. Machine Learning\[M\]. McGraw-Hill, 1997.
[17]Nasrabadi N M. Pattern Recognition and Machine Learning\[J\]. Journal of Electronic Imaging, 2007, 16(4): 049901.
[18]Voorhees E M. The TREC-8 Question Answering Track Report\[C\]//Trec. 1999, 99: 77-82.
[19]Wang Y, Wang L, Li Y, et al. A Theoretical Analysis of Ndcg Type Ranking Measures\[C\]//Conference on Learning Theory. 2013: 25-54.
[20]Devroye L, Gyrfi L, Lugosi G. A Probabilistic Theory of Pattern Recognition\[M\]. Springer Science & Business Media, 2013.
[21]Breiman L, Friedman J, Olshen R A, et al. Classification and Regression Trees\[J\]. 1984.
[22]Quinlan J R. C4. 5: Programs for Machine Learning\[M\]. Morgan Kaufmann, 1993.
[23]Iba W, Langley P. Induction of One-level Decision Trees\[J\]//Machine Learning Proceedings 1992. 1992: 233-240.
[24]Breiman L. Bagging predictors\[J\]. Machine Learning, 1996, 24(2): 123-140.
[25]Schapire R E. The Strength of Weak Learnability\[J\]. Machine Learning, 1990, 5(2): 197-227.
[26]Schapire R E, Freund Y, Bartlett P, et al. Boosting the Margin: A New Explanation for The Effectiveness of Voting Methods\[J\]. Annals of Statistics, 1998: 1651-1686.
[27]Friedman J H. Greedy Function Approximation: A Gradient Boosting Machine\[J\]. Annals of statistics, 2001: 1189-1232.
[28]Gybenko G. Approximation by Superposition of Sigmoidal Functions\[J\]. Mathematics of Control, Signals and Systems, 1989, 2(4): 303-314.
[29]Csáji B C. Approximation with Artificial Neural Networks\[J\]. Faculty of Sciences, Etvs Lornd University, Hungary, 2001, 24: 48.
[30]Sun S, Chen W, Wang L, et al. On the Depth of Deep Neural Networks: A Theoretical View\[C\]//AAAI. 2016: 2066-2072.
[31]Kawaguchi K. Deep Learning Without Poor Local Minima\[C\]//Advances in Neural Information Processing Systems. 2016: 586-594.
[32]Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: A Simple Way to Prevent Neural Networks from Overfitting\[J\]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
[33]Tanner M A, Wong W H. The Calculation of Posterior Distributions by Data Augmentation\[J\]. Journal of the American statistical Association, 1987, 82(398): 528-540.
[34] Ioffe S, Szegedy C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift\[C\]//International Conference on Machine Learning. 2015: 448-456.
[35]Krogh A, Hertz J A. A Simple Weight Decay Can Improve Generalization\[C\]//Advances in neural information processing systems. 1992: 950-957.
[36]Prechelt L. Automatic Early Stopping Using Cross Validation: Quantifying the Criteria\[J\]. Neural Networks, 1998, 11(4): 761-767.
[37]Bengio Y, Simard P, Frasconi P. Learning Long-term Dependencies with Gradient Descent is Difficult\[J\]. IEEE Transactions on Neural Networks, 1994, 5(2): 157-166.
[38]Srivastava R K, Greff K, Schmidhuber J. Highway networks\[J\]. arXiv preprint arXiv:1505.00387, 2015.
[39]Lin M, Chen Q, Yan S. Network in Network\[J\]. arXiv preprint arXiv:1312.4400, 2013.
[40]He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition\[C\]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 770-778.
[41]He K, Zhang X, Ren S, et al. Identity Mappings in Deep Residual Networks\[C\]//European Conference on Computer Vision. Springer, 2016: 630-645.
[42]Huang G, Liu Z, Weinberger K Q, et al. Densely Connected Convolutional Networks\[C\]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017, 1(2): 3.
[43]Hochreiter S, Schmidhuber J. Long Short-term Memory\[J\]. Neural Computation, 1997, 9(8): 1735-1780.
[44]Cho K, Van Merrinboer B, Gulcehre C, et al. Learning Phrase Representations Using RNN Encoder-decoder for Statistical Machine Translation\[J\]. arXiv preprint arXiv:1406.1078, 2014.
[45]Cauchy A. Méthode générale pour la résolution des systemes d’équations simultanées\[J\]. Comp. Rend. Sci. Paris, 1847, 25(1847): 536-538.
[46]Hestenes M R, Stiefel E. Methods of Conjugate Gradients for Solving Linear Systems\[M\]. Washington, DC: NBS, 1952.
[47]Wright S J. Coordinate Descent Algorithms\[J\]. Mathematical Programming, 2015, 151(1): 3-34.
[48]Polyak B T. Newton’s Method and Its Use in Optimization\[J\]. European Journal of Operational Research, 2007, 181(3): 1086-1096.
[49]Dennis, Jr J E, Moré J J. Quasi-Newton Methods, Motivation and Theory\[J\]. SIAM Review, 1977, 19(1): 46-89.
[50]Frank M, Wolfe P. An Algorithm for Quadratic Programming\[J\]. Naval Research Logistics (NRL), 1956, 3(1-2): 95-110.
[51]Nesterov, Yurii. A method of solving a convex programming problem with convergence rate O (1/k2)\[J\]. Soviet Mathematics Doklady, 1983, 27(2).
[52]Karmarkar N. A New Polynomial-time Algorithm for Linear Programming\[C\]//Proceedings of the Sixteenth Annual ACM Symposium on Theory of Computing. ACM, 1984: 302-311.
[53]Geoffrion A M. Duality in Nonlinear Programming: A Simplified Applications-oriented Development\[J\]. SIAM Review, 1971, 13(1): 1-37.
[54]Johnson R, Zhang T. Accelerating Stochastic Gradient Descent Using Predictive Variance Reduction\[C\]//Advances in Neural Information Processing Systems. 2013: 315-323.
[55]Sutskever I, Martens J, Dahl G, et al. On the Importance of Initialization and Momentum in Deep Learning\[C\]//International Conference on Machine Learning. 2013: 1139-1147.
[56]Duchi J, Hazan E, Singer Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization\[J\]. Journal of Machine Learning Research, 2011, 12(7): 2121-2159.
[57]Tieleman T, Hinton G. Lecture 6.5-rmsprop: Divide the Gradient By a Running Average of Its Recent Magnitude\[J\]. COURSERA: Neural networks for machine learning, 2012, 4(2): 26-31.
[58]Zeiler M D. ADADELTA: An Adaptive Learning Rate Method\[J\]. arXiv preprint arXiv:1212.5701, 2012.
[59]Kingma D P, Ba J. Adam: A Method for Stochastic Optimization\[J\]. arXiv preprint arXiv:1412.6980, 2014.
[60]Reddi S, Kale S, Kumar S. On the Convergence of Adam and Beyond\[C\]// International Conference on Learning Representations, 2018.
[61]Hazan E, Levy K Y, Shalev-Shwartz S. On Graduated Optimization for Stochastic Non-convex Problems\[C\]//International Conference on Machine Learning. 2016: 1833-1841.
想要获得这本书,可参加AI科技大本营在线公开课,将在公开课微信群中抽出5名用户送出《分布式机器学习:算法、理论与实践》一书(添加小助手微信csdnai,回复:机器学习,加入课程交流群)

公开课介绍
嘉宾:刘铁岩
主题:推进机器学习发展:技术前沿与未来展望
时间:11月29日20-21点
嘉宾简介
刘铁岩,博士,人工智能领域国际知名学者。现任微软亚洲研究院副院长,IEEE会士,ACM杰出会员,美国卡内基梅隆大学客座教授,英国诺丁汉大学荣誉教授,中国科技大学教授、博导。在AI领域发表论文200余篇。最新著作《分布式机器学习》现已出版。

相关文章:

MYSQL替换语句
update dede_art set titlereplace(title, <IMG border0 srcImages/hot.gif>,);update 表名(比如我案例中的dede_art) set 要修改字段名 replace (要修改字段名,被替换的特定字符,替换成的字符) SELECT * FROM supe_spaceitems where subject like %狐狸天空% update …
phpstudy+phpstorm+debug
文:phpstudyphpstormdebug 一、配置前说明: 1、phpStudy集成了XDebug扩展,所以不用单独下载XDebug。 2、打开XDebug扩展:其它选项菜单 > PHP扩展 > Xdebug 二、配置步骤: 1、phpStudy当前版本: 2、修改php.ini…
java 卖票问题_Java之多线程窗口卖票问题(Thread)
/**** 例子:创建三个窗口卖票,总票数为100张.使用继承Thread类的方式** 存在线程的安全问题,待解决。**/class Window extends Thread{private static int ticket 100;Overridepublic void run() {while(true){if(ticket > 0){System.out…

雷军深情告白:在我心里,武汉大学是全球最好的大学
武汉大学将在 11 月 29 迎来 125 周年校庆,作为杰出校友,小米创始人雷军参加了昨天举行的第五届校友珞珈论坛。现场,雷军对武大深情表白:“马云在几个场合说过,杭州师范大学在他心里是全球最好的大学,没有之…
java中抽象接口_一篇文章让你彻底理解java中抽象类和接口
相信大家都有这种感觉:抽象类与接口这两者有太多相似的地方,又有太多不同的地方。往往这二者可以让初学者摸不着头脑,无论是在实际编程的时候,还是在面试的时候,抽象类与接口都显得格外重要!希望看完这篇博…

linux proc
/proc文件系统下的多种文件提供的系统信息不是针对某个特定进程的,而是能够在整个系统范围的上下文中使用。可以使用的文件随系统配置的变化而变化。 /proc/cmdline 这个文件给出了内核启动的命令行。 /proc/cpuinfo 这个文件提供了有关系统CPU的多种信息。 /proc/d…

专访英特尔AIPG全球研究负责人Casimir Wierzynski:物理学、隐私和大脑将根本性塑造AI
出品| AI 科技大本营 在 11 月 14 日至 15 日在北京召开的英特尔人工智能大会(AIDC)上,英特尔人工智能产品事业部(AIPG)全球研究负责人 Casimir Wierzynski 发表了主题为《人工智能研究——物理学、隐私和大脑》的演讲…
微软OOXML申请国际文档标准已获通过 中国投反对票
51CTO.com北京时间3月28日中午通过消息灵通人士获悉,微软新一代文档标准OOXML已经获得国际标准化组织(ISO)的通过。中国依然投反对票。 ISO共有104个成员,其中包括41个技术能力强、参与标准化活动多的“P成员”。若微软文档标准想…
java中的匿名类方法覆盖_Java技巧:用匿名类来实现简化程序调试
Java技巧:用匿名类来实现简化程序调试在Java中,匿名类(Anonymous inner classes)多用来处理事件(event handle)。但其实,它们对于debug也很有帮助。本文将介绍如何利用匿名类来简化你的debug。我们该如何调试那些非自己源码的方法调用呢&…

记录第一次在egret项目中使用Puremvc
这几天跟着另一个前端在做一个小游戏,使用的是egret引擎和puremvc框架,这对于我来说还是个比较大的突破吧,特此记录下。 因为在此项目中真是的用到了mvc及面向对象编程,值得学习 记录第一次在egret项目中使用Puremvc: …
使用CSS制作圆角效果
Web2.0中,圆角效果是很常见的,以前都是用图片来模仿,现在直接用css就能实现,例子代码如下 Html代码: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> &…
知识图谱升温之势已现,不要错失下一个AI风口
近年来,随着大家对高级认知能力的积极探索,知识图谱因为表达能力强,扩展性好,并能兼顾人类认知与机器自动处理,引起了学术界、工业界以及政府部门的高度关注。 最先被大家熟知的应用领域应属搜索引擎,为了…

干货 | 谷歌BERT模型fine-tune终极实践教程
作者 | 奇点机智从11月初开始,Google Research就陆续开源了BERT的各个版本。Google此次开源的BERT是通过TensorFlow高级API—— tf.estimator进行封装(wrapper)的。因此对于不同数据集的适配,只需要修改代码中的processor部分,就能进行代码的…
java简介 ppt 精_《JAVA》5选择结构精篇课件.ppt
《JAVA》5选择结构精篇课件选 择 结 构 if 语句 if – else语句 Switch语句 块作用域语句又被称为复合语句,其格式为:用一对花括号将若干条语句括起来,目的是从语法上可以将多条语句解释成一条语句。 { int temp; temp a; a b; …
UPDATE STATISTICS 有何妙用?
txlicenhe 马可 一直没有关注它,今天刚学到的一招,还没彻底弄清楚。 情况是这样,有一个视图,用到了好几个表,其中一个表改了一些资料,在前台操作时总是超时过期(前台设置超时时间不长 60s&#…
js with用法
1)简要说明 with 语句可以方便地用来引用某个特定对象中已有的属性,但是不能用来给对象添加属性。要给对象创建新的属性,必须明确地引用该对象。 2)语法格式 with(object instance) { //代码块 } 有…

大数据时代,谁的眼神锁定你?
数据时代当前,欢迎来到楚门的世界。双十一余韵未歇,刚处理完一波售后及退件等“剁手后遗症”的各方人马也已经为再战双十二做好了准备。截至 12 日零点,天猫双十一成交额达 2135 亿元。与此同时,据国家邮政局监测数据显示…

Java类Demo中存在_Java中的数据类型转换
先来看一个题:Java类Demo中存在方法func0、func1、func2、func3和func4,请问该方法中,哪些是不合法的定义?( )public class Demo{float func0(){byte i1;return i;}float func1(){int i1;return;}float func2(){short i2;return i…
Exchange2000需要创建的3个SMTP服务实例
前一阵搞了邮件系统的安全加固,前面说的SA是一个方面,总觉得在SMTP上还有文章可做。分析一下公司的系统环境,SMTP的访问大概分这么三类:1、来自客户端的访问。2、来自公司业务系统服务器的访问。3、来自外部其它邮件服务器的访问。…
小程序门店自提功能开启,酷客多带你玩转O2O模式
目前小程序的发展已经如火如荼,不管是新型行业还是传统行业,都进军小程序领域,由此为广大消费者带来了方便与快捷,现在许多商家品牌将线上线下结合互动起来,推广门店自提的模式,酷客多小程序(ht…

“基因编辑婴儿”惹争议,你或许不知道机器学习在脱靶效应中的作用?
作者|琥珀出品| AI科技大本营又一次,计算机科学家和生物学者站在一起,对抗人类向内探索的挑战——用机器学习预测基因编辑 CRISPR 中的脱靶效应。今年年初,发表在《自然》生物工程杂志上的一篇论文描述了 Elevation 这项工具。该工具由微软研…
Flash Player漏洞利用Exploiting Flash Reliably
以下消息来自幻影论坛[Ph4nt0m]邮件组前两天推荐过Mark Dowd的Paper “Exploiting Flash Reliably”[url]http://hi.baidu.com/secway/blog/item/242655971275376855fb96d8.html[/url]学习了一下,很好很强大。为以后Flash Player漏洞的利用开辟了一条崭新崭新的道路…
java好用的hbase库_Hbase入库基于java
计划每周写一篇博客,督促自己快点学习,懒惰会让人上瘾,努力奋斗,不忘初心。某天,忽然来任务,要做hbse入库,之前自学过hbase,感觉挺简单的,网上搜了些model直接撸码&#…

linux(ubuntu)环境下安装及配置JDK
安装完IDEA之后遇到了问题,发现jdk安装完之后配置环境变量好困难,下面总结一下我的安装及配置方式: JDK下载链接:http://download.oracle.com/otn-pub/java/jdk/8u144-b01/090f390dda5b47b9b721c7dfaa008135/jdk-8u144-linux-x64.tar.gz 作者…

专访英特尔AIPG全球研究负责人Casimir Wierzynski:物理学、隐私和大脑将根本性塑造AI...
记者|琥珀出品| AI 科技大本营在 11 月 14 日至 15 日在北京召开的英特尔人工智能大会(AIDC)上,英特尔人工智能产品事业部(AIPG)全球研究负责人 Casimir Wierzynski 发表了主题为《人工智能研究——物理学、隐私和大脑…
flash php socket通信_php与flash as3 socket通信传送文件实现代码
前段时间在flashseer看到有人提到:可以通过socket方式传送swf文件,让用户无法获取到swf文件… 当时还没有出as3的反编译,所以对程序的保护没有在意.随着反编译程序的平民化,不希望别人看到源代码的朋友就比较着急…通过socket方式传送swf文件来避免泄漏源代码的思路(只适用as3)…
全线衰退:PC产业一枝孤秀
之三:全线衰退:PC产业一枝孤秀 在3C中,也许个人电脑(PC)产业算是当今中国最有希望的。中国的计算机工业号称已有50年历程,但成为民用产品的起始点应在30年前,与改革开放同时起步。1978年,国家成立了计算机工…
用Gogs在Windows上搭建Git服务
1.下载并安装Git,如有需求,请重启服务器让Path中的环境变量生效。2.下载并安装Gogs,请注意,在Windows中部署时,请下载MiniWinService(mws)版本。3.在MariaDB中创建一个命名为Gogs的数据库&#…

wamp安装多版本php,WampServer安装多个php版本
早期的WampServer安装多个版本php很简单,只需要单击php下的Get more...就行了,WampServer会自动导航到http://www.wampserver.com/addons_php.php下去安装php,但目前这种方式好像不行了,该页面找不到了,那么我们只能手…
利用Windows自带服务架设免费邮件服务器
在Windows Server 2003中带有完整的SMTP和POP3服务,并且能够支持有域和无域两种环境,非常便于中小型企业实施。今天,小编就以Windows Server 2003企业版为例带领大家架设一台免费的邮件服务器,希望能够对各位朋友学习邮件服务器提…