TensorFlow支持Unicode,中文NLP终于省心了

整理 | 非主流
出品 | AI科技大本营
终于,TensorFlow 增加了对 Unicode 的支持。
什么是 Unicode?Unicode 是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
在处理自然语言时,了解字符串中字符的编码方式非常重要。因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字。最早的计算机在设计时采用 8 个比特(bit)作为一个字节(byte),所以一个字节能表示的最大的整数就是 255(二进制 11111111 = 十进制 255),0 - 255 被用来表示大小写英文字母、数字和一些符号,这个编码表被称为 ASCII 编码,比如大写字母 A 的编码是 65,小写字母 z 的编码是 122。
如果要表示中文,显然一个字节是不够的,至少需要两个字节,而且还不能和 ASCII 编码冲突,所以,中国制定了 GB2312 编码,用来把中文编进去。
类似的,日文和韩文等其他语言也有这个问题。为了统一所有文字的编码,Unicode 应运而生。Unicode 把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode 几乎支持所有的语言,是字符编码最常用的标准。Unicode 规定,每个字符使用唯一的整数代码点(code point)表示,其值介于 0 和 0x10FFFF 之间。把代码点按顺序放置,就能得到一个 Unicode 字符串。
因此,TensorFlow 支持 Unicode 对中文 NLP 的研究人员来说绝对算得上是一大利好。与此同时,TensorFlow 社区也推出了新的 Unicode colab 教程,展示了如何在 TensorFlow 中表示 Unicode 字符串。
在使用 TensorFlow 时,有两种标准方式来表示 Unicode 字符串:
作为整数向量,其中每个位置包含一个代码点。
作为字符串,使用字符编码将代码点序列编码到字符串中,包括最常见的 UTF-8、UTF-16 等字符编码。
以下代码分别为使用代码点 UTF-8 和 UTF-16 显示字符串“语言处理”的编码。
# Unicode string, represented as a vector of code points.
text_chars = tf.constant([35821, 35328, 22788, 29702])
# Unicode string, represented as a UTF-8-encoded string scalar.
text_utf8 = tf.constant('\xe8\xaf\xad\xe8\xa8\x80\xe5\xa4\x84\xe7\x90\x86')
# Unicode string, represented as a UTF-16-BE-encoded string scalar.
text_utf16be = tf.constant('\x8b\xed\x8a\x00Y\x04t\x06')```
当然,你可能经常需要在不同的表示之间进行转换,而 TensorFlow 1.13 已添加了执行此操作的函数:
tf.strings.unicode_decode:将编码的字符串标量转换为代码点的向量。
tf.strings.unicode_encode:将代码点向量转换为编码的字符串标量。
tf.strings.unicode_transcode:将编码的字符串标量转换为不同的编码。
例如,如果要将上述示例中的 UTF-8 表示解码为代码点向量,则可以执行以下操作:
> tf.strings.unicode_decode(text_utf8, input_encoding='UTF-8')
tf.Tensor([35821 35328 22788 29702], shape=(4,), dtype=int32)
当对包含多个字符串的 Tensor 进行解码时,字符串可能具有不同的长度。unicode_decode 将结果作为 RaggedTensor 返回,其内部维度的长度根据每个字符串中的字符数而变化。
>>> hello = [b"Hello", b"你好", b"こんにちは", b"Bonjour"]
>>> tf.strings.unicode_decode(hello, input_encoding='UTF-8')
<tf.RaggedTensor [[72, 101, 108, 108, 111],
[20320, 22909],
[12371, 12435, 12395, 12385, 12399],
[66, 111, 110, 106, 111, 117, 114]]>
以下是 Unicode 使用方法的详细介绍,希望对大家能有所帮助。
!pip install -q tf-nightly
from __future__ import absolute_import, division, print_function
import tensorflow as tf
tf.enable_eager_execution()
tf.string
通过基本的 TensorFlow tf.string dtype,你可以构建字节字符串的张量(tensor)。Unicode 字符串默认为 utf-8 编码。
tf.constant(u"Thanks ?")
<tf.Tensor: id=0, shape=(), dtype=string, numpy=b'Thanks \xf0\x9f\x98\x8a'>
tf.string 张量可以保存不同长度的字节串,因为字节串被视为原子单位。字符串长度不包括在张量尺寸中。
f.constant([u"You're", u"welcome!"]).shape
TensorShape([Dimension(2)])
Unicode 表示
在 TensorFlow 中有两种表示 Unicode 字符串的标准方法:
字符串标量,使用已知字符编码对代码点序列进行编码。
int32 vector,每个位置包含一个代码点。
例如,以下三个值都表示 Unicode 字符串“语言处理”。
# Unicode string, represented as a UTF-8 encoded string scalar.
text_utf8 = tf.constant(u"语言处理")
text_utf8
<tf.Tensor: id=3, shape=(), dtype=string, numpy=b'\xe8\xaf\xad\xe8\xa8\x80\xe5\xa4\x84\xe7\x90\x86'>
# Unicode string, represented as a UTF-16-BE encoded string scalar.
text_utf16be = tf.constant(u"语言处理".encode("UTF-16-BE"))
text_utf16be
<tf.Tensor: id=5, shape=(), dtype=string, numpy=b'\x8b\xed\x8a\x00Y\x04t\x06'>
# Unicode string, represented as a vector of Unicode code points.
text_chars = tf.constant([ord(char) for char in u"语言处理"])
text_chars
<tf.Tensor: id=7, shape=(4,), dtype=int32, numpy=array([35821, 35328, 22788, 29702], dtype=int32)>
表示之间的转换
TensorFlow 提供了在这些不同表示之间进行转换的操作:
tf.strings.unicode_decode:将编码的字符串标量转换为代码点的向量。
tf.strings.unicode_encode:将代码点向量转换为编码的字符串标量。
tf.strings.unicode_transcode:将编码的字符串标量转换为不同的编码。
tf.strings.unicode_decode(text_utf8,
input_encoding='UTF-8')
<tf.Tensor: id=12, shape=(4,), dtype=int32, numpy=array([35821, 35328, 22788, 29702], dtype=int32)>
tf.strings.unicode_encode(text_chars,
output_encoding='UTF-8')
<tf.Tensor: id=23, shape=(), dtype=string, numpy=b'\xe8\xaf\xad\xe8\xa8\x80\xe5\xa4\x84\xe7\x90\x86'>
tf.strings.unicode_transcode(text_utf8,
input_encoding='UTF8',
output_encoding='UTF-16-BE')
<tf.Tensor: id=25, shape=(), dtype=string, numpy=b'\x8b\xed\x8a\x00Y\x04t\x06'>
Batch dimensions
解码多个字符串时,每个字符串中的字符数可能不相等。 其返回结果是 tf.RaggedTensor,其中最里面的维度的长度根据每个字符串中的字符数而变化。
# A batch of Unicode strings, each represented as a UTF8-encoded string.
batch_utf8 = [s.encode('UTF-8') for s in
[u'hÃllo', u'What is the weather tomorrow', u'Göödnight', u'?']]
batch_chars_ragged = tf.strings.unicode_decode(batch_utf8,
input_encoding='UTF-8')
for sentence_chars in batch_chars_ragged.to_list():
print(sentence_chars)
[104, 195, 108, 108, 111]
[87, 104, 97, 116, 32, 105, 115, 32, 116, 104, 101, 32, 119, 101, 97, 116, 104, 101, 114, 32, 116, 111, 109, 111, 114, 114, 111, 119]
[71, 246, 246, 100, 110, 105, 103, 104, 116]
[128522]
你既可以直接使用 tf.RaggedTensor,也可以用 tf.RaggedTensor.to_tensor 将其转换为有填充的密集 tf.Tensor,或者用 tf.RaggedTensor.to_sparse 将其转换为 tf.SparseTensor。
batch_chars_padded = batch_chars_ragged.to_tensor(default_value=-1)
print(batch_chars_padded.numpy())
[[ 104 195 108 108 111 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]
[ 87 104 97 116 32 105 115 32 116 104 101 32 119 101 97 116 104 101 114 32 116 111 109 111 114 114 111 119]
[ 71 246 246 100 110 105 103 104 116 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]
[128522 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]]
batch_chars_sparse = batch_chars_ragged.to_sparse()
编码多个相同长度的字符串时,可以使用 tf.Tensor 作为输入:
tf.strings.unicode_encode([[99, 97, 116], [100, 111, 103], [ 99, 111, 119]], output_encoding='UTF-8')
<tf.Tensor: id=129, shape=(3,), dtype=string, numpy=array([b'cat', b'dog', b'cow'], dtype=object)>
编码多个不同长度的字符串时,应使用 tf.RaggedTensor 作为输入:
tf.strings.unicode_encode(batch_chars_ragged, output_encoding='UTF-8')
<tf.Tensor: id=131, shape=(4,), dtype=string, numpy=array([b'h\xc3\x83llo', b'What is the weather tomorrow', b'G\xc3\xb6\xc3\xb6dnight', b'\xf0\x9f\x98\x8a'], dtype=object)>
如果你有一个带填充或稀疏格式的多个字符串的张量,那么在调用 unicode_encode 之前应将其转换为 tf.RaggedTensor:
tf.strings.unicode_encode(tf.RaggedTensor.from_sparse(batch_chars_sparse), output_encoding='UTF-8')
<tf.Tensor: id=214, shape=(4,), dtype=string, numpy=array([b'h\xc3\x83llo', b'What is the weather tomorrow', b'G\xc3\xb6\xc3\xb6dnight', b'\xf0\x9f\x98\x8a'], dtype=object)>
tf.strings.unicode_encode(tf.RaggedTensor.from_tensor(batch_chars_padded, padding=-1), output_encoding='UTF-8')
<tf.Tensor: id=288, shape=(4,), dtype=string, numpy=array([b'h\xc3\x83llo', b'What is the weather tomorrow', b'G\xc3\xb6\xc3\xb6dnight', b'\xf0\x9f\x98\x8a'], dtype=object)>
Unicode操作
字符长度
tf.strings.length 操作有一个参数单元,它指示应该如何计算长度。 unit 默认为“BYTE”,但可以设置为其他值,例如“UTF8_CHAR”或“UTF16_CHAR”,以确定每个编码字符串中的 Unicode代码点数。
# Note that the final character takes up 4 bytes in UTF8.
thanks = u'Thanks ?'.encode('UTF-8')
num_bytes = tf.strings.length(thanks).numpy()
num_chars = tf.strings.length(thanks, unit='UTF8_CHAR').numpy()
print('{} bytes; {} UTF-8 characters'.format(num_bytes, num_chars))
11 bytes; 8 UTF-8 characters
字符子串
类似地,tf.strings.substr 操作接受“unit”参数,并使用它来确定“pos”和“len”参数包含哪种偏移。
# default: unit='BYTE'. With len=1, we return a single byte.
tf.strings.substr(thanks, pos=7, len=1).numpy()
b'\xf0'
# Specifying unit='UTF8_CHAR', we return a single character, which in this case
# is 4 bytes.
print(tf.strings.substr(thanks, pos=7, len=1, unit='UTF8_CHAR').numpy())
b'\xf0\x9f\x98\x8a'
拆分 Unicode 字符串
tf.strings.unicode_split 操作将 unicode 字符串拆分为单个字符的子字符串:
tf.strings.unicode_split(thanks, 'UTF-8').numpy()
array([b'T', b'h', b'a', b'n', b'k', b's', b' ', b'\xf0\x9f\x98\x8a'], dtype=object)
字符的字节偏移量
要将 tf.strings.unicode_decode 生成的字符张量与原始字符串对齐,了解每个字符开始位置的偏移量很非常有用。除了会返回包含每个字符的起始偏移量的第二张量,方法 tf.strings.unicode_decode_with_offsets 与 unicode_decode 非常类似。
codepoints, offsets = tf.strings.unicode_decode_with_offsets(u"???", 'UTF-8')
for (codepoint, offset) in zip(codepoints.numpy(), offsets.numpy()):
print("At byte offset {}: codepoint {}".format(offset, codepoint))
At byte offset 0: codepoint 127880
At byte offset 4: codepoint 127881
At byte offset 8: codepoint 127882
Unicode 脚本
每个 Unicode 代码点都属于一个称为脚本的代码点集合。字符的脚本有助于确定字符可能属于哪种语言。例如,我们知道'Б'是西里尔文字,那就表示包含该字符的现代文本可能来自斯拉夫语言,如俄语或乌克兰语。
TensorFlow 提供 tf.strings.unicode_script 操作以确定给定代码点使用哪个脚本。 脚本代码是对应于 International Components for Unicode(ICU)UScriptCode 值的 int32 值。
uscript = tf.strings.unicode_script([33464, 1041]) # ['芸', 'Б']
print(uscript.numpy()) # [17, 8] == [USCRIPT_HAN, USCRIPT_CYRILLIC]
[17 8]
tf.strings.unicode_script 操作也可以应用于代码点的多维 tf.Tensors 或 tf.RaggedTensors:
print(tf.strings.unicode_script(batch_chars_ragged))
<tf.RaggedTensor [[25, 25, 25, 25, 25], [25, 25, 25, 25, 0, 25, 25, 0, 25, 25, 25, 0, 25, 25, 25, 25, 25, 25, 25, 0, 25, 25, 25, 25, 25, 25, 25, 25], [25, 25, 25, 25, 25, 25, 25, 25, 25], [0]]>
参考链接:
https://medium.com/tensorflow/adding-unicode-support-in-tensorflow-6a04fb983b63
https://www.tensorflow.org/tutorials/representation/unicode
(*本文由AI科技大本营整理,转载请联系微信1092722531)
公开课预告
◆
报名中
◆

扫码报名,参加以下公开课
公开课一:《详解百度基于模板的文字识别(OCR)结果结构化处理技术》
直播时间:今晚8点
本课程从百度自定义模板文字识别展开,从理论到案例,详细介绍OCR结构化的相关技术,并理清OCR和结构化之间的关系和适用场景。
公开课二:《达观数据个性化推荐系统实践》
直播时间:12月27日晚8点
本次分享带你揭开个性化推荐的神秘面纱,从推荐算法到大型系统架构进行全面剖析。
公开课三:《全双工语音对话以及在智能硬件上的应用》
直播时间:1月17日晚8点
微软小冰全球首席架构师及研发总监周力博士将介绍微软小冰在全双工语音对话方面的最新成果,及其在智能硬件上的应用和未来将面临的更多技术产品挑战。

推荐阅读
自古英雄出少年,22岁中国小哥哥入选Nature十大人物
凭什么老程序员被裁,应届生却能月薪 1.3 万?
美团回应大规模裁员;ofo 戴威要为欠钱负责;高通要求禁售 iPhone X 系列
6:1又怎样? 这20位区块链女神都是佼佼者, 她们也能撑起一片天!
“车联网”最强科普!据说它是未来五年5G兴衰的晴雨表?
特斯拉加速“国产化”,上海工厂一期建设曝光
让你崩溃无语的程序命名有哪些?
点击“阅读原文”,打开APP 阅读更顺畅。
相关文章:

C#:String.Format数字格式化输出
C#:String.Format数字格式化输出 inta 12345678; //格式为sring输出//Label1.Text string.Format("asdfadsf{0}adsfasdf",a);//Label2.Text "asdfadsf"a.ToString()"adsfasdf";//Label1.Text string.Format("asdfadsf{0:C}adsfasdf&…

OpenStack如何实现高可用集群介绍
OpenStack是目前基于开源的,一个非常流行的云管理平台项目。这个项目由几个主要的组件组合起来完成一些具体的工作。因此它的集群比较复杂,也有多种选择方式。OpenStack 作为一个类似于 Amazon EC2 和 S3 的云基础架构服务(Infrastructure as a Service,…
accp8.0html作业,Accp8.0HTML标签
第一章1、HTML超文本标记语言2、网页3、网页头部4、网页标题5、网页主体6、DOCTYPE声明3种级别:(1)Strict 严格类型(2)Transitional过渡类型(3)Frameset框架类型7、网页摘要标签8、字符编码:gb2312简体中文ISO-885901纯英文big5繁体UTF-8国际通用编码9、…

向iOS越狱彻底说再见!
老牌第三方软件商店 Cydia 关闭在即,iPhone 越狱时代又见落日归途?作者 | 仲培艺出品 | CSDNCydia 线上商店是针对完成越狱的 iOS 设备的一种破解软件,在越狱过程中被装入到系统,为 iOS 设备提供第三方 App 的服务平台,…

ArrayList的subList方法
李说: ArrayList的subList方法获取到的是ArrayList的一段list,只是其中的一段视图。所以修改subList ,ArrayList同时会修改,因为本来就是同一个东西。 jdk文档中是这样说的: List<E> subList(int fromIndex, int toIndex) …

男孩子学计算机和学医哪个好,你认为学医好还是读211大学的电子信息好?
学医的好处。社会的地位和社会认可度较高。无可否认无论是在过去还是在将来,医生因为其救死扶伤的职业特点而被广泛大众所接受和认可。较高的社会地位会让你在将来的择偶、人际关系处理方面显得更有吸引力和话语权。工作稳定有保障。这点其实还是看题主的水平和实力…
Error Creating Control when creating a custom control
如果你在创建ASP.NET的Server Control 是遇到报错: "Error Creating Control" when creating a custom control 原因是 ToolboxData 元数据中的控件名称和控件的类(class)名不同,改为相同即可解决问题。转载于:https://www.cnblogs.com/DotNet…

精选180+Python开源项目,随你选!做项目何愁没代码
编辑 | Jane出品 | Python大本营每一位程序员,每天大部分时间都是在和代码打交道。但是对于广大的普通用户来说,最重要的不是代码,而是代码最终生成的应用程序。但是,每个项目都从头开始自己一行一行码代码,是非常不现…
八年级计算机网络公开课,计算机网络公开课教案.doc
计算机网络公开课教案公开课教案科目:计算机网络课题: 交换机配置文件备份与恢复知识目标:1、在本次课中要向学生传授交换机上传、下载服务器的安装和配置;2.学生学习交换机上传配置命令,完成交换机Flash内存中保存的配置文件上传…
Centos6.5升级系统自带gcc4.4.7到gcc4.8.0
下载 wget http://ftp.gnu.org/gnu/gcc/gcc-4.8.0/gcc-4.8.0.tar.bz2 解压 tar -xjvf gcc-4.8.0.tar.bz2 进入 cd gcc-4.8.0 下载所需软件( ftp://gcc.gnu.org/pub/gcc/infrastructure/mpfr-2.4.2.tar.bz2 ftp://gcc.gnu.org/pub/gcc/infrastructure/gmp-4.3.2.tar.…
photofunia
存个链接用~~~[url]http://www.photofunia.com/[/url]转载于:https://blog.51cto.com/wangyublues/120301

学计算机应用好还是汽车维修好,大学汽车运用与维修专业怎么样_学什么_前景好吗-520吉他网...
时间:2019-06-23 来源:网络资源 汽车运用与维修专业怎么样_学什么_前景好吗2019高考填报志愿时,汽车运用与维修专业怎么样、学什么、前景好吗等是广大考生和家长朋友们十分关心的问题。以下是大学生必备网整理的汽车运用与维修专业介绍、…

20T数据、百万奖金,同济和武大摘得开放数据创新应用大赛桂冠!
整理 | Jane出品 | AI科技大本营中国华录杯城市开放数据创新应用大赛,18 日在天津迎来了收官的决赛之战。本次大赛由中国华录集团有限公司和天津市津南区人民政府共同举办。利用天津市人民政府、企业开放的数据资源,吸引了众多国内高校科研团队和科技企业…
rrdtool报错
参考文档: http://serverfault.com/questions/662161/rrdtool-illegal-attempt-to-updatehttps://emacstragic.net/collectd-causing-rrd-illegal-attempt-to-update-using-time-errors/https://support.nagios.com/forum/viewtopic.php?f7&t26087 报错信息&am…

Grid R-CNN解读:商汤最新目标检测算法,定位精度超越Faster R-CNN
作者 | 周强来源 | 我爱计算机视觉Grid R-CNN是商汤科技最新发表于arXiv的一篇目标检测的论文,对Faster R-CNN架构的目标坐标回归部分进行了替换,取得了更加精确的定位精度,是最近非常值得一读的论文。今天就跟大家一起来细品此文妙处。一、作…
河南信息工程学校计算机协会申请书,协会成立申请书范文15篇.docx
协会成立申请书范文15篇协会成立申请书(一): 尊敬的系团委领导: 摄影作为一门艺术不仅仅能够丰富同学们的学习生活,同时对学院的建设也起到一个不可黙灭的作用。为了发挥自身优势,参加学校社团文化建设,培养同学…
Luna的大学读书史(1,Intro)
Luna看了看自己的屋子,乱乱的一大摊,地上有的地方的灰都已经是厚厚的一层,有的角落甚至还结了蜘蛛网。床上的被子和衣服搅在一起,书桌上散乱的摆着几根笔和一个大号笔记本,草稿纸上画了若干莫名其妙的符号,…
【BIEE】数据透视表格第一列添加序号
现在有这么一个需求,需要在数据透视图的表格前面条件一列序号,作为行号,如下图:那么实现这个如何实现呢?只需要在BIEE分析编辑界面,新建一列,然后公式定义为:RCOUNT(RSUM(1)) &#…

2018最后一个月的Python热文Top10!赶紧学起来~
作者 | Mybridge译者 | linstancy整理 | Jane出品 | AI科技大本营过去一个月里,我们对近 1000 篇 Python 文章进行了排名,并挑选出热度前10的文章。这份清单的内容涵盖了包括 master python、REST APIs、twitter bot、random module、贝叶斯模型和线性回…
一处机房建设的败笔
第二个是关于空调的。是另一个机房,机房大概的布局如下图。左边空地是为日后扩展所留空间。右边有一排机柜,箭头所指为机柜前端方向。空调是一台艾默生的精密空调,被安装在机房的角落处。看出来什么问题吗?如果是你,你…

计算机组成原理实验pc,计算机组成原理实验报告5- PC实验
计算机组成原理实验报告5- PC实验2.5 PC实验姓名:孙坚 学号:134173733 班级:13计算机 日期:2015.5.15一.实验要求:利用CPTH 实验仪上的K16..K23 开关做为DBUS 的数据,其它开关做为控制信号&…
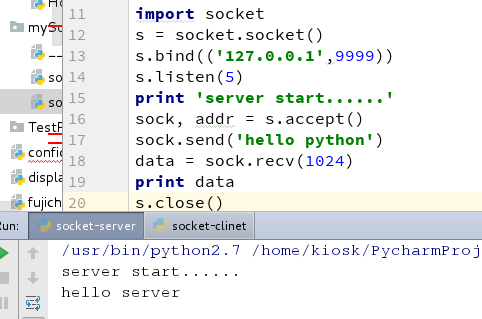
Python-socket编程
一.socket编程 Socket 是网络编程的一个抽象概念。通常我们用一个 Socket 表示“打开了一个网络链接”,而打开一个 Socket 需要知道目标计算机的 IP地址和端口号,再指定协议类型即可。 二.Python的socket编程实例 1.客户端操作 import socket s socket.socket()s.bind((, ))s.…

异步备份和还原数据库:.NET发现之旅(六)
信息系统是数据密集型的,数据的套帐,备份,还原是客户最希望有的功能,这一节课就讨论下C/S系统下数据库的异步备份和还原,B/S系统的数据备份和还原和这个类似。 既然是异步,首先会想到使用多线程技术。.NET平…

看动画轻松理解「链表」实现「LRU缓存淘汰算法」
作者 | 程序员小吴,哈工大学渣,目前正在学算法,开源项目 「 LeetCodeAnimation 」5500star,GitHub Trending 榜连续一月第一。本文为 AI科技大本营投稿文章(欢迎给我们投稿,投稿请联系微信1092722531&#…
东北师大计算机考研报名人数,东北师范大学考研难吗?一般要什么水平才可以进入?...
问:从东北师范大学毕业的学生就业怎么样?值不值得报考?答:想要了解东北师范大学更多毕业生就业情况见>>>东北师范大学总之,东北师范大学就业率相对来说是比较良好的,如果大家对此学校感兴趣的话&a…
2009-徘徊-开场白
徘徊 不知道该怎么走coding已经随风散去思想不复存在,9月应该是个很好的月份。步入一个公司,当时的部长很强,虽然是ASP招我进来5天,走了。进入后的第一个是做一个RPGmaker的游戏coding 没什么关系08年刚开始似乎就很少编码了窝在宿…
未获得计算机访问权限,如何获取文件夹的访问权限
有些系统文件夹打不开,显示信息“拒绝你访问该文件夹”,有点让人摸不着头脑,明明我是管理员账号,明明整台电脑都是我的,你凭什么不让我访问呢,原来系统内是有比较复杂的权限分配的,我们可以稍作…
生成验证码点击可刷新
我把生成验证码与生成验证码图片封装成一个静态方法,放到ValidateCode类里 /// <summary> /// 生成验证码的类 /// </summary> public static class ValidateCode { /// <summary> /// 生成验证码 /// </summary> ///…

redhat enterprise linux 下配置本地yum源
一、在linux 6.1中本地yum源配置:首先编辑yum源配置文件我们可以再这个目录中新创建一个配置文件, #cd /etc/yum.repos.d, #vim yum.repo配置文件内容简介:[ ]内的是仓库的名字 name是仓库的描述也可以说是名字 baseurl 仓库的位置 enabled…

2018年最后几天学什么?给你关注度最高的10篇文章
作者 | Mybridge译者 | Linstancy整理 | Jane出品 | AI科技大本营【导语】我们从 12 月里近1400篇机器学习文章进行了排名,并挑选出最受大家关注的十篇文章。这些文章的内容主要是由 Google、DeepMind、OpenAI 等科技公司发布的自家在机器学习领域最新技术研究&…