完整代码+实操!手把手教你操作Faster R-CNN和Mask R-CNN
 点击上方↑↑↑蓝字关注我们~
点击上方↑↑↑蓝字关注我们~
「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑
机器视觉领域的核心问题之一就是目标检测(Object Detection),它的任务是找出图像当中所有感兴趣的目标(物体),确定其位置和大小。
作为经典的目标检测框架Faster R-CNN,虽然是2015年的论文,但是它至今仍然是许多目标检测算法的基础,这在飞速发展的深度学习领域十分难得。而在Faster R-CNN的基础上改进的Mask R-CNN在2018年被提出,并斩获了ICCV2017年的最佳论文。Mask R-CNN可以应用到人体姿势识别,并且在实例分割、目标检测、人体关键点检测三个任务都取得了很好的效果。
因此,一些深度学习框架如百度PaddlePaddle开源了用于目标检测的RCNN模型,从而可以快速构建满足各种场景的应用,包括但不仅限于安防监控、医学图像识别、交通车辆检测、信号灯识别、食品检测等等。
目标检测(Object Detection)与实例分割(Instance Segmentation)
目标检测的任务就是确定图像当中是否有感兴趣的目标存在,接着对感兴趣的目标进行精准定位。当下非常火热的无人驾驶汽车,就非常依赖目标检测和识别,这需要非常高的检测精度和定位精度。
目前,用于目标检测的方法通常属于基于机器学习的方法或基于深度学习的方法。 对于机器学习方法,首先使用SIFT、HOG等方法定义特征,然后使用支持向量机(SVM)、Adaboost等技术进行分类。 对于深度学习方法,深度学习技术能够在没有专门定义特征的情况下进行端到端目标检测,并且通常基于卷积神经网络(CNN)。但是传统的目标检测方法有如下几个问题:光线变化较快时,算法效果不好;缓慢运动和背景颜色一致时不能提取出特征像素点;时间复杂度高;抗噪性能差。
因此,基于深度学习的目标检测方法得到了广泛应用,该框架包含有Faster R-CNN,Yolo,Mask R-CNN等,图1和图2分别显示的是基于PaddlePaddle深度学习框架训练的Faster R-CNN和Mask R-CNN模型对图片中的物体进行目标检测。
从图1中可以看出,目标检测主要是检测一张图片中有哪些目标,并且使用方框表示出来,方框中包含的信息有目标所属类别。图2与图1的最大区别在于,图2除了把每一个物体的方框标注出来,并且把每个方框中像素所属的类别也标记了出来。

图1 基于paddlepaddle训练的Faster R-CNN模型预测结果

图2 基于paddlepaddle训练的Mask R-CNN模型预测结果
从R-CNN到Mask R-CNN
Mask R-CNN是承继于Faster R-CNN,Mask R-CNN只是在Faster R-CNN上面增加了一个Mask Prediction Branch(Mask预测分支),并且在ROI Pooling的基础之上提出了ROI Align。所以要想理解Mask R-CNN,就要先熟悉Faster R-CNN。同样的,Faster R-CNN是承继于Fast R-CNN,而Fast R-CNN又承继于R-CNN,因此,为了能让大家更好的理解基于CNN的目标检测方法,我们从R-CNN开始切入,一直介绍到Mask R-CNN。
R-CNN
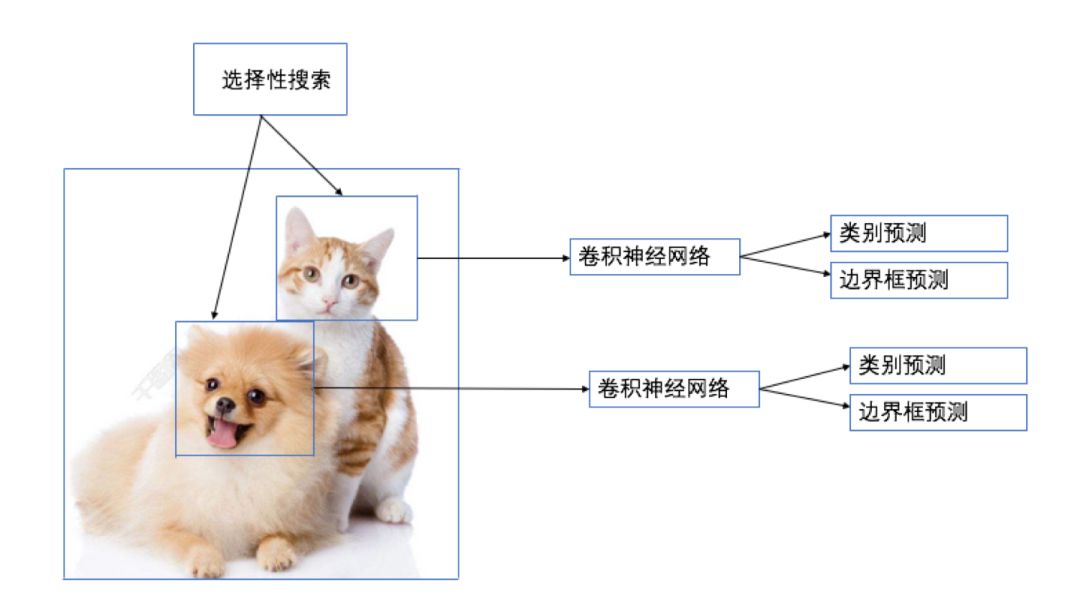
区域卷积神经网络(Regions with CNN features)使用深度模型来解决目标检测。
R-CNN的操作步骤
Selective search(选择性搜索):首先对每一张输入图像使用选择性搜索来选取多个高质量的提议区域(region proposal),大约提取2000个左右的提议区域;
Resize(图像尺寸调整):接着对每一个提议区域,将其缩放(warp)成卷积神经网络需要的输入尺寸(277*277);
特征抽取:选取一个预先训练好的卷积神经网络,去掉最后的输出层来作为特征抽取模块;
SVM(类别预测):将每一个提议区域提出的CNN特征输入到支持向量机(SVM)来进行物体类别分类。注:这里第 i 个 SVM 用来预测样本是否属于第 i 类;
Bounding Box Regression(边框预测):对于支持向量机分好类的提议区域做边框回归,训练一个线性回归模型来预测真实边界框,校正原来的建议窗口,生成预测窗口坐标。
R-CNN优缺点分析
优点:R-CNN 对之前物体识别算法的主要改进是使用了预先训练好的卷积神经网络来抽取特征,有效的提升了识别精度。
缺点:速度慢。对一张图像我们可能选出上千个兴趣区域,这样导致每张图像需要对卷积网络做上千次的前向计算。
Fast R-CNN
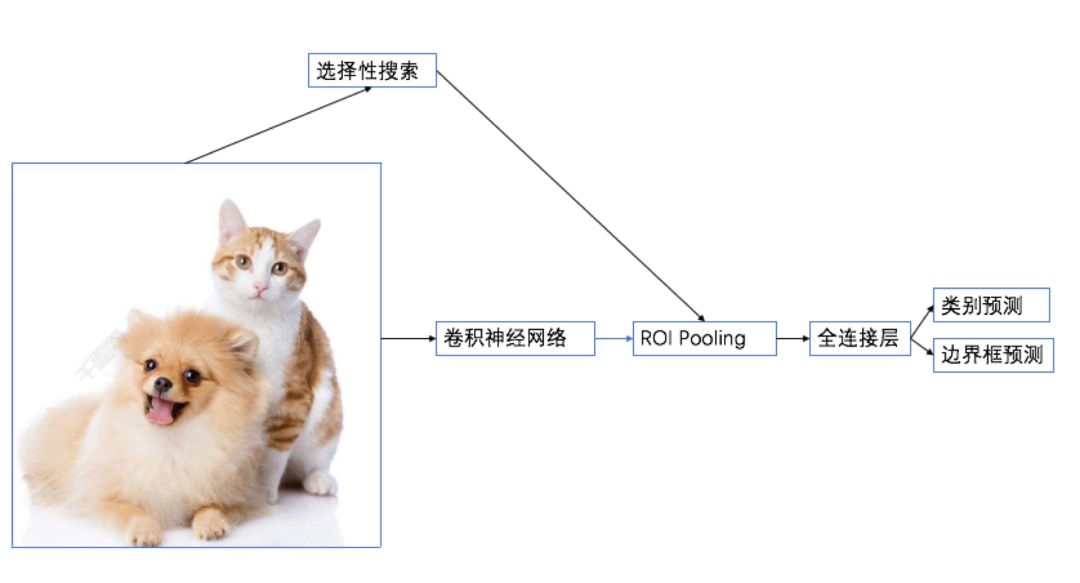
R-CNN 的主要性能瓶颈在于需要对每个提议区域(region proposal)独立的抽取特征,这会造成区域会有大量重叠,独立的特征抽取导致了大量的重复计算。因此,Fast R-CNN 对 R-CNN 的一个主要改进在于首先对整个图像进行特征抽取,然后再选取提议区域,从而减少重复计算。
Fast R-CNN 的操作步骤
Selective Search(选择性搜索):首先对每一张输入图像使用选择性搜索(selective search)算法来选取多个高质量的提议区域(region proposal),大约提取2000个左右的提议区域;
将整张图片输入卷积神经网络,对全图进行特征提取;
把提议区域映射到卷积神经网络的最后一层卷积(feature map)上;
RoI Pooling:引入了兴趣区域池化层(Region of Interest Pooling)来对每个提议区域提取同样大小的输出;
Softmax:在物体分类时,Fast R-CNN 不再使用多个 SVM,而是像之前图像分类那样使用 Softmax 回归来进行多类预测。
Fast R-CNN优缺点分析
优点:对整个图像进行特征抽取,然后再选取提议区域,从而减少重复计算;
缺点:选择性搜索费时;
缺点:不用Resize,不适合求导;
Faster R-CNN
Faster R-CNN 对 Fast R-CNN 做了进一步改进,它将 Fast R-CNN 中的选择性搜索替换成区域提议网络(region proposal network)。RPN 以锚框(anchors)为起始点,通过一个小神经网络来选择区域提议。
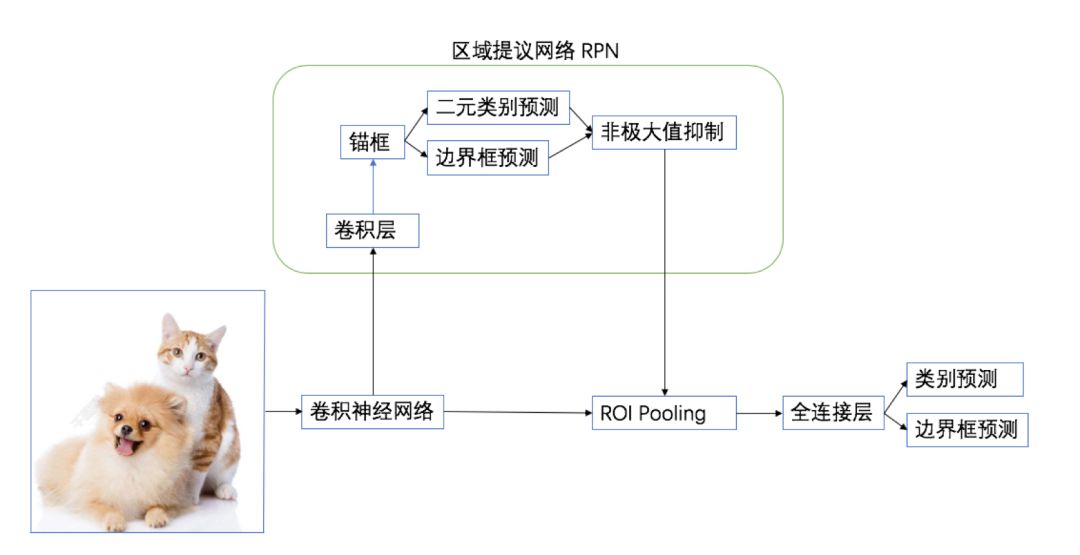
Faster R-CNN整体网络可以分为4个主要内容:
基础卷积层(CNN):作为一种卷积神经网络目标检测方法,Faster R-CNN首先使用一组基础的卷积网络提取图像的特征图。特征图被后续RPN层和全连接层共享。本示例采用ResNet-50作为基础卷积层。
区域生成网络(RPN):RPN网络用于生成候选区域(proposals)。该层通过一组固定的尺寸和比例得到一组锚点(anchors), 通过softmax判断锚点属于前景或者背景,再利用区域回归修正锚点从而获得精确的候选区域。
RoI Pooling:该层收集输入的特征图和候选区域,将候选区域映射到特征图中并池化为统一大小的区域特征图,送入全连接层判定目标类别, 该层可选用RoIPool和RoIAlign两种方式,在config.py中设置roi_func。
检测层:利用区域特征图计算候选区域的类别,同时再次通过区域回归获得检测框最终的精确位置。
Faster R-CNN优缺点分析
优点:RPN 通过标注来学习预测跟真实边界框更相近的提议区域,从而减小提议区域的数量同时保证最终模型的预测精度。
缺点:无法达到实时目标检测。
Mask R-CNN
Faster R-CNN 在物体检测中已达到非常好的性能,Mask R-CNN在此基础上更进一步:得到像素级别的检测结果。 对每一个目标物体,不仅给出其边界框,并且对边界框内的各个像素是否属于该物体进行标记。Mask R-CNN同样为两阶段框架,第一阶段扫描图像生成候选框;第二阶段根据候选框得到分类结果,边界框,同时在原有Faster R-CNN模型基础上添加分割分支,得到掩码结果,实现了掩码和类别预测关系的解藕。
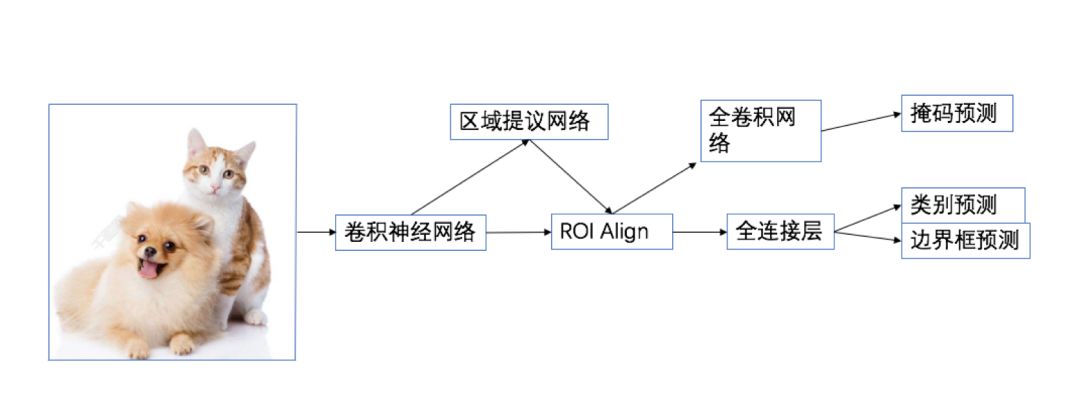
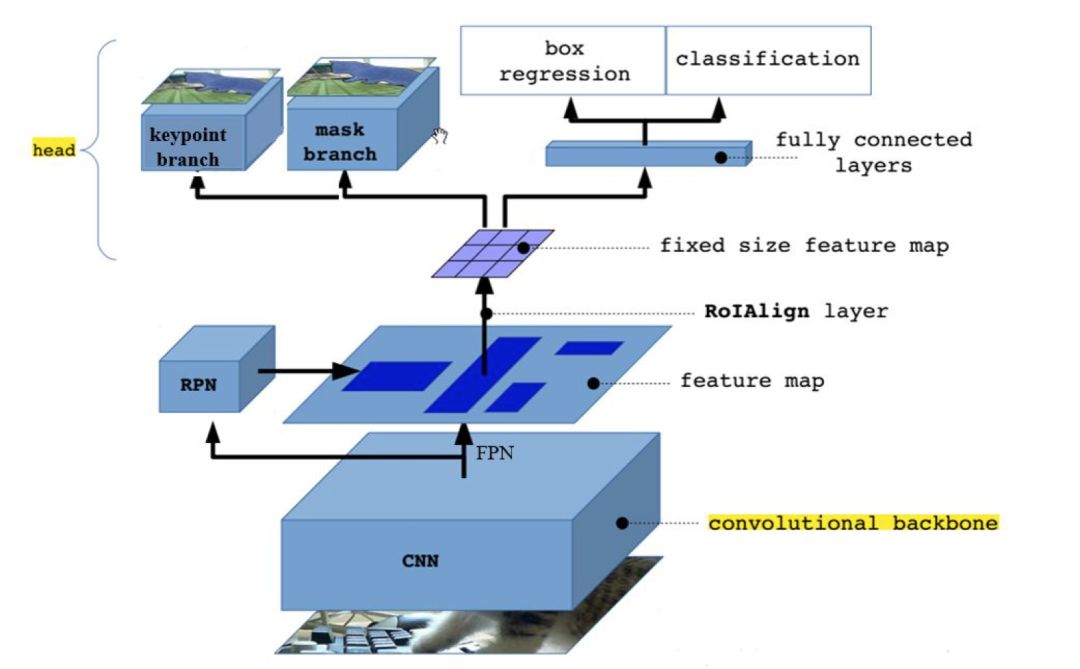
图3 Mask R-CNN网络结构泛化图
Mask R-CNN的创新点
解决特征图与原始图像上的RoI不对准问题:在Faster R-CNN中,没有设计网络的输入和输出的像素级别的对齐机制(pixel to pixel)。为了解决特征不对准的问题,文章作者提出了RoIAlign层来解决这个问题,它能准确的保存空间位置,进而提高mask的准确率。
将掩模预测(mask prediction)和分类预测(class prediction)拆解:该框架结构对每个类别独立的预测一个二值mask,不依赖分类(classification)分支的预测结果
掩模表示(mask representation):有别于类别,框回归,这几个的输出都可以是一个向量,但是mask必须要保持一定的空间结构信息,因此作者采用全连接层(FCN)对每一个RoI中预测一个m*m的掩模。
图4展示了Mask R-CNN在像素级别的目标检测结果:

图4 Mask R-CNN:像素级别的目标检测
基于PaddlePaddle的实战
环境准备:需要PaddlePaddle Fluid的v.1.3.0或以上的版本。如果你的运行环境中的PaddlePaddle低于此版本,请根据安装文档中的说明来更新PaddlePaddle。
数据准备:在MS-COCO数据集上进行训练,可以通过脚本来直接下载数据集:
cd dataset/coco
./download.sh
数据目录结构如下:
data/coco/
├── annotations
│ ├── instances_train2014.json
│ ├── instances_train2017.json
│ ├── instances_val2014.json
│ ├── instances_val2017.json
| ...
├── train2017
│ ├── 000000000009.jpg
│ ├── 000000580008.jpg
| ...
├── val2017
│ ├── 000000000139.jpg
│ ├── 000000000285.jpg
| ...
模型训练:下载预训练模型: 本示例提供Resnet-50预训练模型,该模性转换自Caffe,并对批标准化层(Batch Normalization Layer)进行参数融合。采用如下命令下载预训练模型。
sh ./pretrained/download.sh
通过初始化pretrained_model 加载预训练模型。同时在参数微调时也采用该设置加载已训练模型。 请在训练前确认预训练模型下载与加载正确,否则训练过程中损失可能会出现NAN。
安装cocoapi:
训练前需要首先下载cocoapi:
git clone https://github.com/cocodataset/cocoapi.git
cd cocoapi/PythonAPI
# if cython is not installed
pip install Cython
# Install into global site-packages
make install
# Alternatively, if you do not have permissions or prefer
# not to install the COCO API into global site-packages
python2 setup.py install --user
数据准备完毕后,可以通过如下的方式启动训练:
Faster RCNN
python train.py \
--model_save_dir=output/ \
--pretrained_model=${path_to_pretrain_model} \
--data_dir=${path_to_data} \
--MASK_ON=False
Mask RCNN
python train.py \
--model_save_dir=output/ \
--pretrained_model=${path_to_pretrain_model} \
--data_dir=${path_to_data} \
--MASK_ON=False
通过设置export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7指定8卡GPU训练。
通过设置MASK_ON选择Faster RCNN和Mask RCNN模型。
可选参数见:
python train.py –help
数据读取器说明:
数据读取器定义在reader.py中。所有图像将短边等比例缩放至scales,若长边大于max_size, 则再次将长边等比例缩放至max_size。在训练阶段,对图像采用水平翻转。支持将同一个batch内的图像padding为相同尺寸。
模型设置:
分别使用RoIAlign和RoIPool两种方法。
训练过程pre_nms=12000,post_nms=2000,测试过程pre_nms=6000, post_nms=1000。nms阈值为0.7。
RPN网络得到labels的过程中,fg_fraction=0.25,fg_thresh=0.5,bg_thresh_hi=0.5,bg_thresh_lo=0.0
RPN选择anchor时,rpn_fg_fraction=0.5,rpn_positive_overlap=0.7,rpn_negative_overlap=0.3
训练策略:
采用momentum优化算法训练,momentum=0.9。
权重衰减系数为0.0001,前500轮学习率从0.00333线性增加至0.01。在120000,160000轮时使用0.1,0.01乘子进行学习率衰减,最大训练180000轮。同时我们也提供了2x模型,该模型采用更多的迭代轮数进行训练,训练360000轮,学习率在240000,320000轮衰减,其他参数不变,训练最大轮数和学习率策略可以在config.py中对max_iter和lr_steps进行设置。
非基础卷积层卷积bias学习率为整体学习率2倍。
基础卷积层中,affine_layers参数不更新,res2层参数不更新。
模型评估:模型评估是指对训练完毕的模型评估各类性能指标。本示例采用COCO官方评估。eval_coco_map.py是评估模块的主要执行程序,调用示例如下:
Faster RCNN
python eval_coco_map.py \
--dataset=coco2017 \
--pretrained_model=${path_to_trained_model} \
--MASK_ON=False
Mask RCNN
python eval_coco_map.py \
--dataset=coco2017 \
--pretrained_model=${path_to_trained_model} \
--MASK_ON=True
通过设置--pretrained_model=${path_to_trained_model}指定训练好的模型,注意不是初始化的模型。
通过设置export CUDA\_VISIBLE\_DEVICES=0指定单卡GPU评估。
通过设置MASK_ON选择Faster RCNN和Mask RCNN模型。
模型精度:下表为模型评估结果。
Faster RCNN:
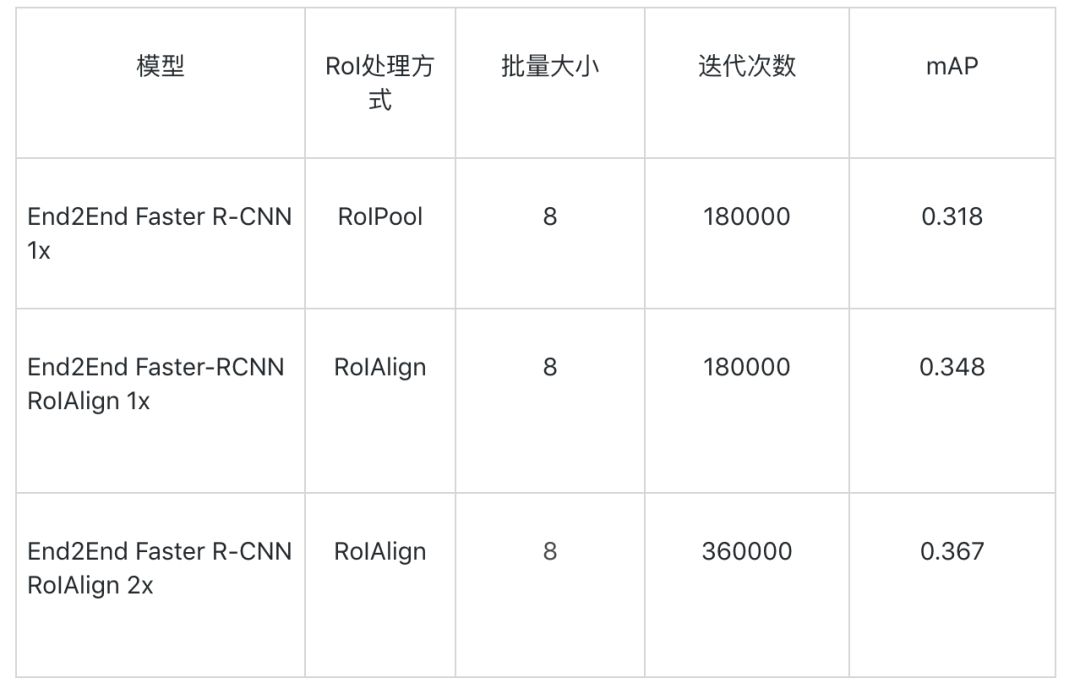
End2End Faster R-CNN: 使用RoIPool,不对图像做填充处理。
End2End Faster R-CNN RoIAlign 1x:使用RoIAlign,不对图像做填充处理。
End2End Faster R-CNN RoIAlign 2x:使用RoIAlign,不对图像做填充处理。训练360000轮,学习率在240000,320000轮衰减。
Mask RCNN:
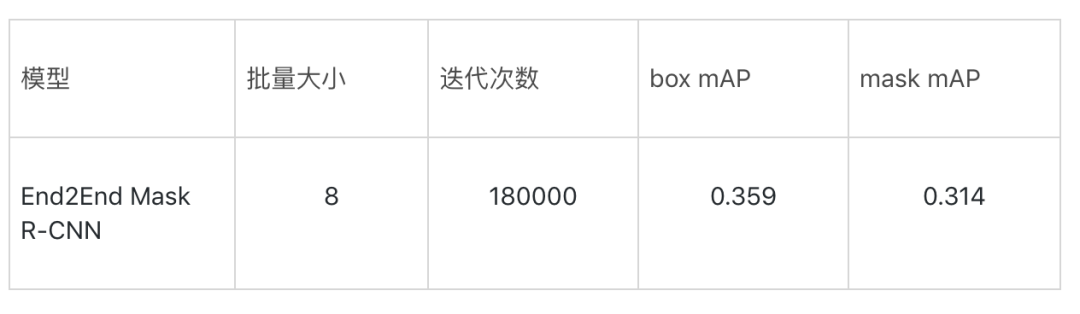
End2End Mask R-CNN: 使用RoIAlign,不对图像做填充处理。
模型推断:模型推断可以获取图像中的物体及其对应的类别,infer.py是主要执行程序,调用示例如下:
python infer.py \
--pretrained_model=${path_to_trained_model} \
--image_path=dataset/coco/val2017/000000000139.jpg \
--draw_threshold=0.6
注意,请正确设置模型路径${path_to_trained_model}和预测图片路径。默认使用GPU设备,也可通过设置--use_gpu=False使用CPU设备。可通过设置draw_threshold调节得分阈值控制检测框的个数。
传送门:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/rcnn
Reference:
Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
https://arxiv.org/abs/1311.2524
Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE international conference on computer vision. 2015.
https://arxiv.org/abs/1504.08083
Ren, Shaoqing, et al. "Faster r-cnn: Towards real-time object detection with region proposal networks." Advances in neural information processing systems. 2015.
https://arxiv.org/abs/1506.01497
He, Kaiming, et al. "Mask r-cnn." Proceedings of the IEEE international conference on computer vision. 2017.
https://arxiv.org/abs/1703.06870
(本文为 AI大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
「2019 Python开发者日」演讲议题全揭晓!这一次我们依然“只讲技术,拒绝空谈”10余位一线Python技术专家共同打造一场硬核技术大会。更有深度培训实操环节,为开发者们带来更多深度实战机会。更多详细信息请咨询13581782348(微信同号)。

推荐阅读:
萌新养成 | AI科技大本营实习生招募计划
80+机器学习数据集,还不快收藏
推荐收藏 | Python爬虫干货资料,内含入门、实战、视频
GitHub超全机器学习工程师成长路线图,开源两日收获3700+Star!
靠找Bug赚了6,700,000元!他凭什么?
移动开发或将被颠覆?
他曾主导世界上第一台安卓智能机, 如今能否靠区块链手机找回昔日的光荣?|人物志
轻松了解面试官心理!ElasticSearch写入数据的工作原理是什么? | 技术头条
程序员与程序媛的神仙爱情 | 程序员有话说

❤点击“阅读原文”,查看历史精彩文章。
相关文章:

【Dlib】使用dlib_face_recognition_resnet_model_v1.dat无法实现微调fune-tuning
1、问题描述 dlib官方使用resnet训练人脸识别,训练了300万的数据,网络参数保存在dlib_face_recognition_resnet_model_v1.dat中。 测试中识别lfw数据时,准确率能达到99.13%,但是在识别自己的数据时,准确率有点低&…
Visual Studio 2017 - Windows应用程序打包成exe文件(1)- 工具简单总结
最近有对一个Windows应用程序少许维护和修改。修改之后要发布新的exe安装文件,打包exe文件时,遇到了很头疼的问题,还好最后解决了,记录一下。 Visual Studio版本:Visual Studio 2017 Visual Studio 2017 打包插件 新建…

NET也有闭包
NET也有闭包在.NET中,函数并不是第一级成员,所以并不能像JavaScript那样通过在函数中内嵌子函数的方式实现闭包,通常而言,形成闭包有一些值得总结的非必要条件: 嵌套定义的函数。 匿名函数。 将函数作为参数或…
【opencv】ubuntu14.04上编译opencv2.4
参考博客 https://blog.csdn.net/c406495762/article/details/62896035 1、安装依赖库 sudo apt-get install build-essential cmake libgtk2.0-dev pkg-config python-dev python-numpy libavcodec-dev libavformat-dev libswscale-dev sudo apt-get install libv4l-0 libv…
1024块TPU在燃烧!BERT训练从3天缩短到76分钟 | 技术头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑作者 | 琥珀出品 | AI科技大本营(ID:rgznai100)“Jeff Dean称赞,TensorFlow官方推特支持,BERT目前工业界最耗时的应用,计…
牵引力教育设计总监解密9大2018潮流UI设计趋向
作为一名紧跟时代潮流的UI设计师,设计的风格一定要紧跟上最新的设计趋势,因为更为有效且颇具趣味的响应式图标必将得到关注。同时,鲜艳丰富的色彩,精彩纷呈的插图设计都会博得用户眼球。这样你的设计更容易获得更多人的认可与热爱…
Android媒体相关开发应用程序接口
翻译自:http://developer.android.com/guide/topics/media/index.html MediaAndroid框架支持各种普通media类型的编解码,因此你可以很容易地把音频,视频和图片整合到你的应用程序中。通过使用MediaPlayer的接口,你可以播放各种音视…
Facebook开源图嵌入“神器”:无需GPU,高效处理数十亿级实体图形 | 极客头条...
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑编译 | Major、一一出品 | AI科技大本营(ID: rgznai100)有效处理大规模图对于促进人工智能的研究和应用至关重要,但特别是在工业应用中的图&…
【opencv】ubuntu14.04上编译opencv-4.0.1 + opencv_contrib-4.0.1
1、要求 编译器版本:c11 cmake版本:3.5.1 2、安装camke 2.1 官网下载:https://cmake.org/download/ 选择:Linux x86_64 cmake-3.14.1-Linux-x86_64.sh 2.2 安装: 将cmake-3.14.1-Linux-x86_64.sh拷贝考ubuntu中&…
软件开发文档模板 (学习)
1 可行性研究报告 可行性研究报告的编写目的是:说明该软件开发项目的实现在技术、经济和社会条件方面的可行性;评述为了合理地达到开发目标而可能先择的各种方案;说明论证所选定的方案。 可行性研究报告的编写内容要求如下: …
Unix数据中心主宠儿
曾几何时UNIX一直是除个人电脑之外的领域中应用最为广泛的操作系统,并且为现代操作系统的成型奠定了基础,可以说UNIX的历史就像应用程序本身一样耐人寻味。UNIX的过去回首1983年,肯.托马森和D.里奇由于对操作系统发展史以及UNIX操作系统应用所…
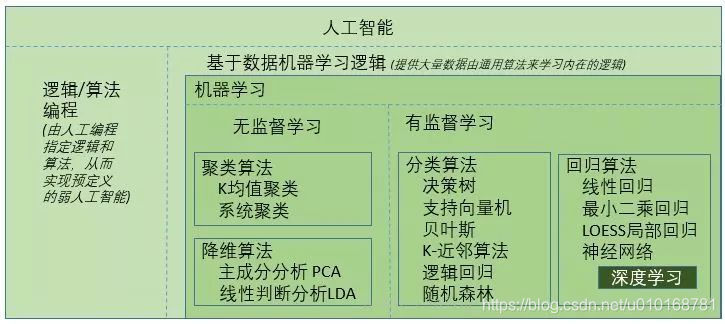
【AI】基本概念
1、什么是人工智能 人工智能(AI)是通过研究、开发,来找到用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的综合性的科学技术。其表现为,让计算机系统通过机器学习等方式,来获得可以履行原本只有依…

在浏览器中进行深度学习:TensorFlow.js (四)用基本模型对MNIST数据进行识别
2019独角兽企业重金招聘Python工程师标准>>> 在了解了TensorflowJS的一些基本模型的后,大家会问,这究竟有什么用呢?我们就用深度学习中被广泛使用的MINST数据集来进行一下手写识别的操作。 MINST数据集 MINST是一组0到9的手写数字…

不止临床应用,AI还要帮不懂编程的医生搞科研
近日,推想科技发布 AI 学者科研平台 InferScholar Center,该平台为更多的医生提供零门槛的 AI 科研能力,让医生可以快速将深度学习、影像组学以及文本数据处理相关的前沿技术应用到自己的临床科研实践中,他们将为平台上的医疗科研…

rhel6Inode详解
在Linux文件系统中,很多人对Inode都不太明白,今天我就和大家一起来分享一下我对Inode的认识,如果有理解错误的地方,请大家多多批评指点。在上一篇一天一点学习Linux之认识文件系统中,在最后给出了一张EXT3文件系统结构…
争论不休的TF 2.0与PyTorch,到底现在战局如何了? | 技术头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑作者 | Jeff Hale译者 | Jackey编辑 | Jane出品 | AI科技大本营(id:rgznai100)【导语】 TensorFlow 2.0 和 PyTorch 1.0 陆续发布后,…
struts2实验2:struts2.xml action中* ,{}以及${}
p.s 关键在于struts.xml中的匹配,使用* ,{}以及${}可以让代码更加简洁清晰 代码核心思路 在struts.xml中通过路由(url)去指定控制逻辑的Action中的方法,例如 <package name"admin" namespace"/admin" extends"struts-global">&…
【Ubuntu】dpkg-deb -c :查看deb文件中的内容
1、dpkg-deb -c :查看deb文件中的内容 $ dpkg-deb -c packageeg: $ dpkg-deb -c sogoupinyin_2.2.0.0108_amd64.deb drwxr-xr-x root/root 0 2018-04-18 16:50 ./ drwxr-xr-x root/root 0 2018-04-18 16:50 ./etc/ drwxr-xr-x root/root …
捕获Camera并保存图片到本地(照相功能) -samhy
Flex博文 捕获Camera并保存图片到本地(照相功能) -samhy作者:admin 日期:2010-07-12字体大小: 小 中 大捕获Camera并保存图片到本地(照相功能)这几天对Camera类进行了一下规整,并利用JPGEncoder类实现了照相的功能,代码如下: XML/HTML代码import flash.m…
【C++】模板函数的声明和定义必须在同一个文件中
1、问题描述 习惯性的将函数的定义和实现,分别写在头文件和源文件(.cpp)中。今天也按照这个习惯实现了一个模板函数。然后编译时报错 ... error: undefined reference to ...2、原因分析 c中模板的声明和定义不能分开。C中每一个对象所占用…

基于AWS-ELK部署系统日志告警系统
前言 运维故障排障速度往往与监控系统体系颗粒度成正比,监控到位才能快速排障 在部署这套系统之前,平台所有系统日志都由GraylogZabbix,针对日志出现的错误关键字进行告警,这种做法在运维工作开展过程中暴露出多个不足点ÿ…
《周志华机器学习详细公式推导版》发布,Datawhale开源项目pumpkin-book
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑来源 | Datawhale(ID:Datawhale) 如果让你推荐两本国内机器学习的入门经典作,你会推荐哪些呢?相信大家同我一样ÿ…
JVM内存泄漏检测与处理
JVM内存泄漏检测与处理(JVM Memory Leak detection and handling) JVM垃圾回收机制的原则和方法 JVM垃圾回收中一个基本原则是对象没有被引用或则引用其它对象,换句话说当一个对象在heap 中是隔离(isolation)状态的时候,垃圾回收器…
【Dlib】dlib和opencv的互转
一、dlib::matrix转换成cv::Mat 1、注意事项: 1)将dlib::matrix转成BGR格式后,再转换成cv::Mat,因为cv::Mat中是按照BGR顺序存储 2)注意最后添加的cv::Mat::clone()函数,因为dlib::toMat(tmp)返回的mat数…
原创 人物志|山东省临沭县 - 一位身残志坚的奋斗青年 - 吴忠军
原创 人物志|山东省临沭县 - 一位身残志坚的奋斗青年 - 吴忠军 02972018-04-29 16:15:27 人物志|山东省临沭县 - 一位身残志坚的奋斗青年 - 吴忠军 齐鲁晚报 2018年04月29日 2018年4月29日,山东省临沂市临沭县,一位年轻的小伙子。吴忠军,山东…
百度SLG拿下前锤子科技CTO钱晨,还要合并小鱼在家? | 极客头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑整理 | 一一出品 | AI科技大本营(id:rgznai100)2016 年 7 月,锤子科技前 CTO 钱晨从该公司退休的消息被证实,关于其离职的…

【Dlib】dlib实现深度网络学习之 input层
1、 dlib::input 模板类,深度神经网络的简单输入层,它将某种图像作为输入并将其加载到网络中。 这是一个基本的输入层,它只是简单地将图像复制到一个张量中。 注意:dlib::input只支持输入dlib::matrix和dlib::array2d类型&#x…
首发 | 13篇京东CVPR 2019论文!你值得一读~ 技术头条
点击上方↑↑↑蓝字关注我们~「2019 Python开发者日」全日程揭晓,请扫码咨询 ↑↑↑编者按:计算机视觉和模式识别大会 CVPR(Conference on Computer Vision and Pattern Recognition)作为人工智能领域计算机视觉方向的重要学术会议…
Windows 活动目录(AD)服务器系统升级到2012之活动目录角色迁移(三)
4.5迁移服务器角色到AD20121. 打开powershell,使用命令迁移服务器角色到AD2008输入命令Ntdsutil输入命令Roles输入命令Connections输入命令Connect to server AD2012,连接AD2012控制器输入命令QUIT输入Transfer infrastructure master命令,转…

《星际争霸2》引擎技术解析
就在SIGGRAPH大会刚结束之后,AMD和暴雪在AMD官方网站上放出了《星际争霸II》的官方技术文档,通过游戏引擎技术的展示让星际迷们感受到越来越多的惊喜。画面优化给CPU带来考验着色方面,在使用原型的基础上利用3D Studio MAX让程序员对整体效果…